
融合情感与语义的多模态对话生成方法
2023-06-25 08:27:56张翼英马彩霞柳依阳王德龙
天津科技大学学报 2023年3期
张翼英,马彩霞,张 楠,柳依阳,王德龙
(天津科技大学人工智能学院,天津 300457)
开放域对话由于应用范围广而受到产业界和学术界普遍关注[1],语音对话具有省时、高效等优势,在开放域对话中发挥着越来越重要的作用.语音模态是指以音频形式存储的说话内容,由于其中包括振幅、频率等多种音频特征,这些特征包含说话人的重要信息,因此仅利用文本单模态生成对话往往无法满足要求.如何利用音频和文本特征生成信息丰富且流畅的对话响应是值得探究的问题.
在文本单模态对话生成方面,基于门控循环单元(gate recurrent unit,GRU)构建Seq2Seq对话模型,其编码器将上下文文本编码至一个向量,解码器将该向量作为输入,并对信息解码,从而输出响应序列[2].但Seq2Seq不能很好地捕捉到上下文信息[3],于是HRED(hierarchical recurrent encoder-decoder)模型应运而生,该模型通过额外增加一个编码器对上下文建模,减少了相邻句子间的计算步骤,促进信息的传播[4].为了提升回复的多样性并控制回复的情感倾向,条件变分自动编码(conditional variational auto encoder,CVAE)模型往往结合注意力机制或Seq2Seq模型实现指定情绪的响应生成[5-6].但Seq2Seq模型和HRED模型对长句的生成效果较差,为解决这一问题,Google团队于2017年提出自注意力机制和Transformer序列到序列模型[7].该模型能够并行提取其他位置的信息,并将信息进行加权平均化,再和当前位置进行融合,在对话生成、情感识别等多种任务上的运行效果均有较大提升;在多模态对话任务中,研究人员应用CVAE模型根据多模态条件和给定情感信息生成连贯的对话响应[8],但该研究仅仅将模态间进行线性连接,未考虑不同模式之间的交叉融合,不能深入挖掘模态内部的关联.文献[9]利用音频辅助文本进行对话生成,提出融合音频的Audio-Seq2Seq文本对话生成模型,将文本嵌入向量和音频向量同时输入注意力模块,探究振幅及响度对于对话生成情感的重要性.由于该研究的基础是Seq2Seq模型,因此仍存在对话较为通用、多样性较差等问题.此外,不少学者致力于研究多模态Transformer,其中有研究[10]采用基于Transformer的自监督多模态表示学习框架VATT(video-audio-text transformer)实现了多模态视频的有效监督,但该方法常被应用于图像相关的下游任务;文献[11]提出了视听场景感知对话(audio-visual scene-aware dialog,AVSD),通过引入多任务学习实现多模态对话生成,但该方法将语音模态进行了单向映射,未将音频特征与文本特征充分融合,因此生成的对话不能囊括音频特征中丰富的情感信息.
为了解决上述问题,本文提出文本音频Transformer(audio text transformer,AT-Transformer)模型实现音频和文本双模态的对话生成,该模型的编码器将文本和音频双模态进行模态间和模态内部特征融合,区别于已有的线性连接方法,实现了模态间特征关联性的深入挖掘.为了验证模型的有效性,在IEMOCAP数据集[12]上进行了实验,通过与基于纯文本的Transformer模型和基于音频、文本多模态的Audio-Seq2Seq、VATT和AVSD模型进行困惑度及生成多样性比较,并从语义相关性、流畅度和情感匹配性3个方面进行人工评估.实验结果表明,本文模型能够生成内容丰富、情感适宜的响应.
本文的主要工作如下:
(1)提出多模态注意力机制,探究文本特征和音频特征之间的深入关联,使得文本生成任务能够充分融入音频特征所包含的潜在信息.
(2)从语句生成的多样性方面提升对话生成效果,避免生成通用性、无意义的回复.
(3)通过灰度对数功率谱图、Mel频谱图、Mel频率倒谱系数(Mel frequency cepstrum coefficient,MFCC)图与注意力热力图的对比验证了语音频率、基频、共振与注意力之间的正向关系,表明语音模态能够明显促进对话生成质量的提升.
1 相关研究
1.1 对话生成
随着深度学习技术的快速发展和算力的提升,许多学者致力于研究对话生成技术,按生成的依据可以将这些技术划分为纯文本对话生成和多模态对话生成两种方式.纯文本对话生成通过对文本数据的分析和处理,进而生成响应的过程.传统的Seq2Seq模型对上下文信息的依赖有限,生成的响应存在无意义、内容不丰富等问题,而HRED模型将Seq2Seq模型进行层次化改进,提升了对上下文信息的关注度,进而提高了多轮对话的生成效率.变分自编码器(variational auto encoder,VAE)通过将潜在特征表述为概率分布的方式更适合对话上下文内部状态的表示,条件变分自编码器(CVAE)结合双重注意力机制能够将上下文响应和随机的潜在变量连接,有效地控制响应的情感倾向[13].为了解决Seq2Seq模型和HRED模型对长句及多轮对话生成效果不佳的问题,Transformer模型通过多头注意力机制关注当前的词和句子中的其他词,可以有效获取上下文语义信息[7].尽管这些模型取得了较好的对话效果,但是并未考虑语音模态,可能会存在对上下文语义感知不准确的问题,故而对对话生成质量造成影响.
多模态对话生成以视频、音频、微表情、文本等多种模态特征为依据,通过模态融合建模不同模态之间的关系,进而生成适合不同场景的回复,具有广阔的研究前景[14].Wang等[2]通过视觉模型提取视觉特征,并将其输入序列到序列的对话生成中,学习在给定文本和视觉上下文情况下生成下一语句的概率.Chen等[5]使用文本实体定位图像中的相关对象,建立文本与对象之间的映射,并通过跨模态注意力机制构建多模态Transformer,从而生成与视觉和文本上下文一致的响应.除了视频模态之外,文献[9]对音频上下文进行建模,并提出音频增强的Seq2Seq模型,实现对话生成任务,验证了音频特征对于对话生成的有效性.上述研究虽然能够产生效果较好的响应,但是未对语音模态进行考虑,并且序列到序列的模型存在生成多样性较差、语义不丰富等问题.本文工作区别于已有工作,通过应用多模态融合实现音频和文本模态间特征的深度挖掘,从而构建多模态注意力机制AT-Transformer模型,经验证双模态特征比纯文本特征实现了对话质量和情感匹配度的显著提升.
1.2 多模态融合
多模态融合是将音频、视频、微表情等多形态数据进行综合处理的过程,是多模态对话生成的基础[13].模型相关的融合方法虽然复杂性较高,但具有较强的实用性和较高的准确率.Rohanian等[15]使用长短期记忆(long short-term memory,LSTM)网络对文本中的词汇信息和音频中的声学特征进行顺序建模,实现阿尔茨海默病的检测.Shen等[16]通过构建LSTM网络交互单元,对音频和文本之间的动态交互进行建模,实现语音情感的准确分类.由于上述研究对文本和音频特征进行顺序建模,未考虑特征间的深层交互关系,并且LSTM网络仍存在梯度消失及梯度爆炸问题.Saha等[17]提出基于自身、模态间和任务间注意力机制的多模态多任务深度神经网络,实现情感和任务类别的联合学习.该模型实现了对话行为及情感的准确分类以及模态间的深层融合,但未对主要关联部分进行探究,并且对话生成任务还需补充解码器部分.本文通过将Transformer的编码器部分的多头注意力机制部分进行跨模态设计,并通过实验分析不同参数的重要性程度,促进对话生成质量的进一步提升.
2 任务定义
本文的目标是通过音频、对话上下文两种模态信息生成内容丰富、具有一定情感并且流畅的回复.该任务定义为:DA(dialogue audio)表示当前对话单位音频片段;DT(dialogue text)为当前对话音频DA所对应的文本;R(response)表示在给定对话单位音频片段DA和对话文本DT的前提下生成的对话响应文本,其中包含m个单词,即R={r1,r2,…,rm}.则在给定对话音频片段DA和对应文本DT的情况下生成响应文本R的概率表示为
其中:r<i表示响应文本R中的前i-1个单词,θ为可训练的参数.
3 模型描述
本文提出一种基于多模态注意力机制的ATTransformer模型,综合考虑文本、音频双模态,旨在探究语音模态对于对话生成效果的影响.实验证明,利用该生成模型能够生成内容丰富、情感适宜并且流畅的对话回复.该模型在传统Transformer的基础上提出多模态注意力机制,并设计情感和内容相关的目标函数,采用核采样算法提升回复的多样性,整体架构如图1所示.

图1 AT-Transformer模型整体结构Fig.1 Overall structure of AT-Transformer model
该模型主要分为3个部分:第1部分对数据进行预处理,将音频数据缺失的数据进行过滤,通过计算Mel声谱,进行卷积操作获得嵌入向量,同时对文本数据设置最大单词长度,进行特征提取,然后将其进行嵌入向量表示;第2部分将文本嵌入向量和音频嵌入向量输入生成模型进行训练,在训练过程中通过多模态注意力机制实现音频和文本特征的融合;第3部分通过多样性损失函数提升对话生成质量.
4 AT-Transformer模型
4.1 多模态融合
对音频中的特征进行提取,需要考虑说话者的态度、情感色彩的变化、对应的声音形式、语调及说话节奏等特征[18],而Mel频谱图更接近人类感知音高的方式,因此本文使用VGGish对该特征进行提取,并通过卷积操作获取音频向量的嵌入表示,最后使用主成分分析法进行特征降维,从而在编码器中实现特征融合.
为了使对话文本向量携带相应的顺序信息,文本表示由单词(w)嵌入和位置嵌入构成,具体如图1中的输入部分所示.
4.2 多模态注意力机制
目前已有的多模态注意力机制主要是将不同的模态进行一维卷积操作,并将不同的模态进行跨模态操作并投影至同一模态,然后将该模态下的所有特征进行连接,再进行自注意力操作实现多模态特征融合[19].虽然该方法实现了特征的有效融合,但是这种方法进行了两次跨模态操作,计算复杂度较高.
为了使音频特征和文本特征进行有效融合,本文使用多模态注意力计算的方法,将文本和音频分别进行嵌入向量表示,并通过注意力分数体现二者之间的关系.本文在Transformer模型[7]的基础上对其中的多头注意力机制进行改进,其中Q、K和V分别代表注意力中的查询、键和值,多模态注意力机制的结构如图2所示,其中的蓝色圆形表示输入的文本向量,橙色圆形表示输入的音频向量.

图2 多模态注意力机制Fig.2 Multimodal attention mechanism
其中:Qc、Kc和Vc分别是文本模态所对应的查询、键和值,Qa、Ka和Va为音频模态所对应的查询、键和值,权重矩阵模态内部和模态之间的多头注意力表示为
其中:Cc和Aa分别为文本和音频模态内部计算所得注意力,Ac和Ca为文本和音频两种方式的跨模态注意力,dk为输入向量的维度.然后,将式(5)—式(8)与对应模态的值进行向量乘积,此处以Ac为例,赋值后A'c为
公式(9)将文本和音频两种方式的跨模态注意力分别与对应模态的值进行向量乘积,分别求取每部分的最终注意力值,实现模态之间的深度融合[7].同时,受文献[20]的启发,将模态之间的注意力向量进行连接,实现语音与文本之间注意力机制的深度挖掘,保证了模态融合的完整性,公式为
式中:RMM为最终的语音文本模态注意力计算结果,Mc和Ma分别为文本模态和音频模态的注意力,Cc、Ac、Aa和Ca分别为依据式(9)进行向量乘积之后的计算结果.
4.3 多样性损失函数
对话生成任务通常以softmax交叉熵作为损失函数,倾向于从候选集中生成频率最高的语句作为响应,从而出现生成的语句无意义、重复性较高等问题.为了提高生成语句的多样性,在原损失函数的基础上考虑了单词的频率,同时通过动态调整参数实现对目标单词索引权重的配置,进而控制损失函数Le的收敛速度,其中该部分模型架构图1中的全连接层FC,公式为
其中:Ls为softmax交叉熵损失函数,x是softmax层之前预测层的输出,xi是x集合(x∈R|V|)中的第i个单词,t是目标单词的索引.wt是 t所对应的权重,tt是t所对应的单词,f(tt)是tokent在训练集中出现的频率,λ为控制频率影响大小的超参数.在公式(12)中,由于eλ能够通过调整λ的大小控制权重wt的变化速度,进而控制损失函数的收敛速度,同时当λ=0时,该损失函数与softmax交叉熵损失函数相同.
5 实 验
5.1 数据集
本研究使用IEMOCAP作为数据集,该数据集包含12h的试听数据,参与者在其中进行即兴表演或根据脚本场景表演,其中包含5个会话.由于该数据集包含文本和音频双模态并且具有情感标签,探讨音频特征对于对话生成文本是否具有情感因素方面的作用有一定的帮助,本研究将后4个session作为训练集,session1作为测试集,IEMOCAP数据集的初始对话数、预处理后的对话数和词汇大小见表1.

表1 IEMOCAP数据集的初始对话数、预处理后的对话数和词汇大小Tab.1Initial utterance number,preprocessed utterance number and vocabulary size of the IEMOCAP dataset
5.2 数据预处理
首先对IEMOCAP中的不规范文本数据及相对应的音频数据进行过滤,然后对不完整的音频数据及对应的文本数据进行过滤,通过观察音频数据的时长及文本特征长度,将特征维度进行对齐,其中文本数据的维度为90,音频数据的维度为90×128,学习率设置为1×10-4.
5.3 实验评估
5.3.1 困惑度和多样性评估
开放域对话生成任务的自动评估方法一直以来都面临着挑战,而人工评估方法成为一个较为可靠的评估标准.
本实验主要进行了困惑度(perplexity,PPL)[21]和多样性两方面的自动评估.对于一个由词语序列组成的句子,困惑度计算公式为
其中:s为候选句子,N为候选句子s的长度,P(wi)为第i个词的概率,第一个词为P(w1|w0),w0为句子开始占位符.该方法用于估算模型的信息密度,检测对话生成语句相对于已有参考语句的平均生成质量,困惑度越小,语言模型越好.
回复多样性作为影响对话质量的关键要素之一,在开放式对话任务中备受关注,传统的Seq2Seq模型产生的回复往往会面临回复语句单一、枯燥乏味等问题,这严重影响用户体验,而Transformer模型能够在一定程度上缓解这一问题.本实验主要采用Distinct[22]方法对回复多样性Dn进行评估.
其中:ND为回复语句中不重复的n-gram的数量,NS为回复语句中n-gram词语的总数目.式(15)分别对回复中不同的单个单词和两个单词进行统计,并将该数目分别除以各自相对应的总数,本实验中主要采用D1和D2计算回复中的内容多样性.
为了验证所提模型的对话生成质量及对话多样性效果,本文选取模型Transformer、Audio-Seq2Seq、VATT、AVSD进行实验比较,分别对其进行困惑度及多样性评估,其中Transformer模型未考虑音频模态,而Audio-Seq2Seq、VATT、AVSD模型均考虑了文本和音频模型,具体比较数据见表2.实验结果表明,基于AT-Transformer模型相较于传统Transformer及其他各类多模态模型在困惑度和多样性均有一定提升,与表2中标红的其他模型的最佳实验结果相比,困惑度降低了0.2%,D1和D2分别提升了0.06和2.7%.总体来看,本文提出的模型在困惑度和D2上的性能提升较为明显.
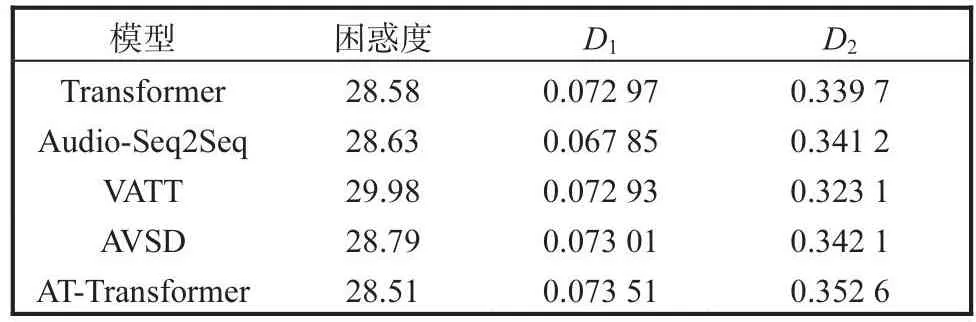
表2 不同模型在IEMOCAP数据集上的困惑度和多样性比较Tab.2 Comparison of AT-Transformer’s perplexity and diversity on IEMOCAP data sets with different models
5.3.2 人工评估
由于情感相关性与内容相关性很难通过自动评估方法进行考量,为了验证文中模型的效果,从语义相关性、流畅度和情感匹配度三方面进行评估[13],邀请5名具有对话相关工作经验的人进行评分,根据语句与人工回复语句的近似程度及内容丰富性评分,其中分数分别为0、1、2,如果语句中包含的内容较多但不偏离核心话题,那么其得分越高;对于流畅度,人工主要依据其可读性将其分数判定为0、1、2;情感匹配度主要是由评分者判定生成语句情感和对话数据本身情感是否匹配,如果强匹配则评分为2,若情感倾向一致,但有一点偏离,则评分为1,若情感倾向完全不同则评分为0.回复在语义相关性、流畅度和情感匹配度中的达标程度见表3.
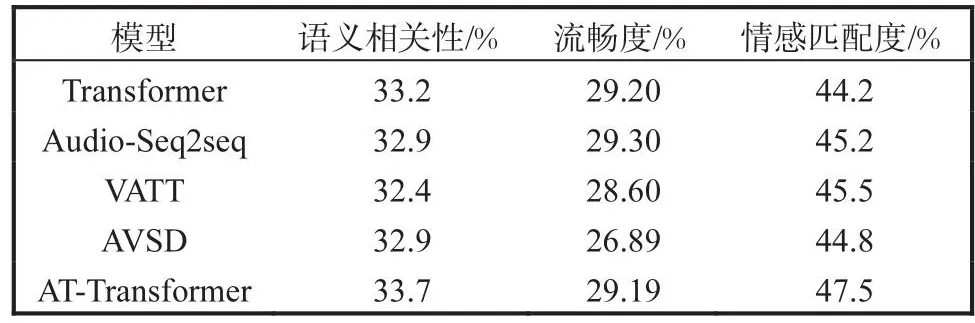
表3 回复在语义相关性、流畅度和情感匹配度中的达标程度Tab.3Degree to which the response meets the criteria for semantic relevance,fluency and emotional matching
实验数据表明,相较于最优基准模型,本文模型在情感匹配度上提升2%,在流畅度及语义相关性方面与纯文本特征生成的回复效果基本持平,表现为语义相关性提升0.5%,而流畅度则下降0.11%.由此可看出音频特征的增加对于提升对话的情感匹配度有一定的作用,而文本特征嵌入向量具有充分的表示能力,因此增加音频特征之后并不能使流畅度显著提升.Transformer模型与AT-Transformer模型生成的回复对比见表4.

表4 Transformer模型和AT-Transformer模型在系统中生成的回复对比Tab.4 Comparison of responses generated by Transformer model and AT-Transformer model
在表4中分别针对4组上下文将 Transformer模型和AT-Tranformer模型生成的回复进行对比,从中可以看出本文所提出的模型包含的内容较为丰富,例如,针对第4组上下文Transformer模型产生的响应对于上文进行了同义表述然后进行了反问,而ATTransformer模型在承接上文语义之后,又进行了话题的延展,增强了内容丰富性,同时情感与上文较为一致.
5.3.3 对话音频频率对注意力机制的影响
音频特征在一定程度上能够体现说话者所强调的语义重点及情绪特征,对于生成语义契合、情感匹配的回复具有一定的意义.为了探究音频频率在对话生成中的作用,选用session1中的第5个会话中的音频片段,其对应表述为“Okay.But I didn’t tell you to get in this,line if you are filling out this particular form.”,其中图3—图5分别为该语句所对应的灰度对数功率谱图、Mel频谱图和MFCC图.综合3个图可以看出,在0.5~4s之间的频率较高,与此同时该音频对应的音频-文本和文本-音频注意力强度如图6所示.
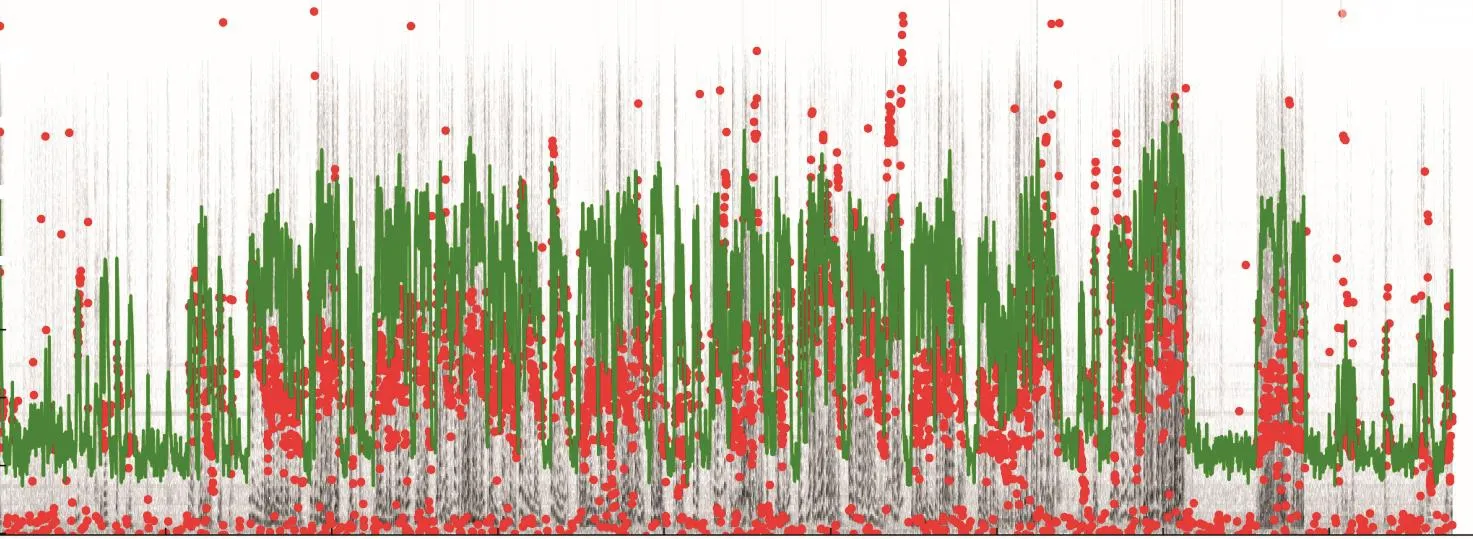
图3 “Okay.But I didn’t tell you to get in this line if you are filling out this particular form.”音频对应的灰度对数功率谱图Fig.3 Gray logarithmic power spectrum corresponding to “Okay.But I didn’t tell you to get in this line if you are filling out this particular form.”
图3中的红色圆点为基频f0,绿色区域为每帧语音在空气中的声压级(SPL为对数功率谱),将图3与图6对比可以发现绿色及红色原点部分越密集,图6中注意力分数越高,这也就证明了模型的注意力与基频f0、声压级具有对应关系.Log-Mel Spectrogram特征通过构建Mel频率的维度和时间帧长度,实现了不同时频下音频信号特征表示(图4).将图4和图6对比可以发现文本-音频注意力机制与Mel时频的变化趋势较为一致.
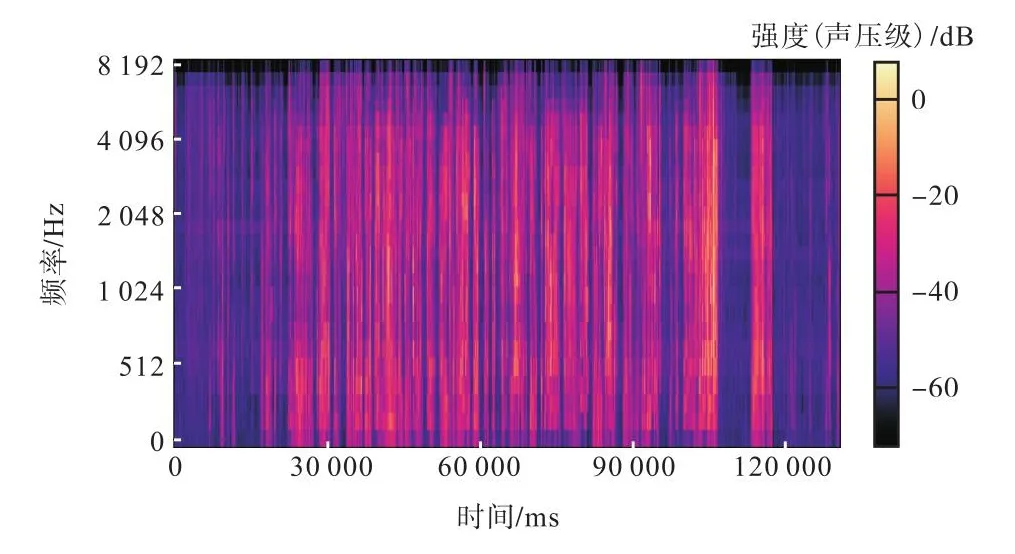
图4 Mel频谱图Fig.4 Mel spectrogram
由图5可知:MFCC特征能够充分体现说话者的声音特点,考虑到人耳对不同频率的感受程度,常用于语音辨识.

图5 MFCC图Fig.5 MFCC diagram
MFCC特征包括音高、过零率、共振峰等,能够在一定程度上体现说话者的情感特点,比如开怀大笑时声音会高一些,而心情不好则声音低迷.通过对比图5与图6,可以发现文本-音频注意力机制能够捕捉MFCC所体现的这些特征.
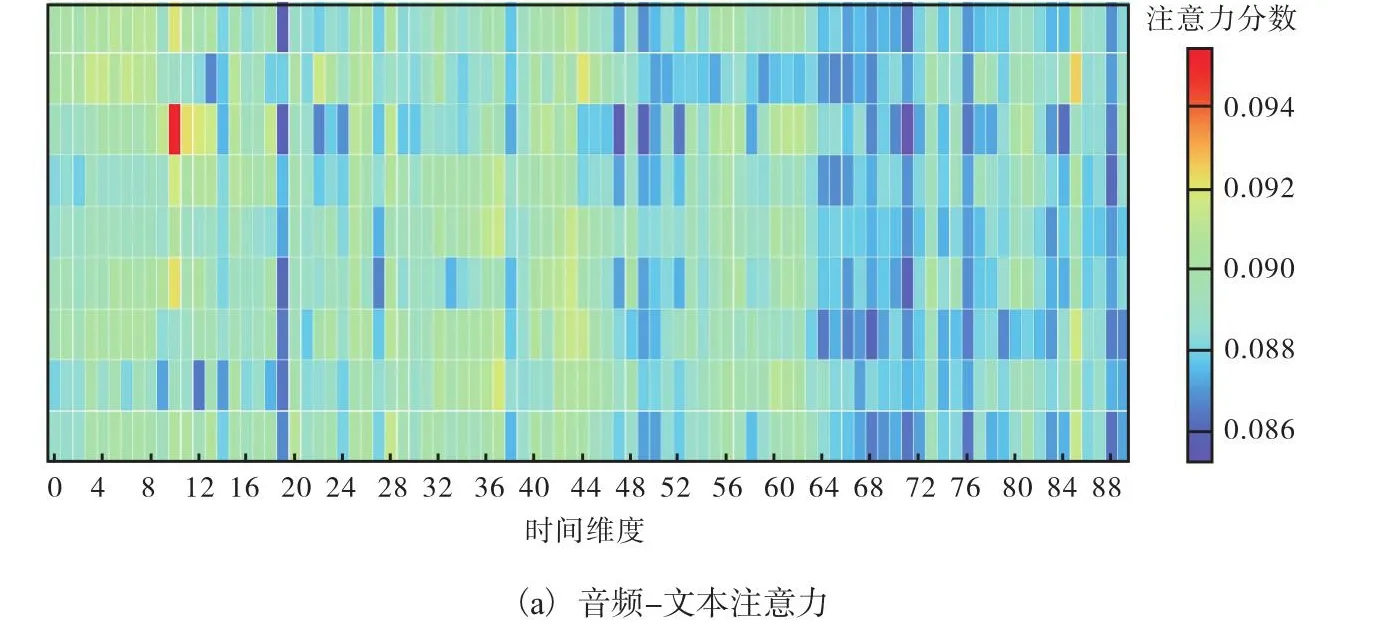
图6 基于AT-Attention模型的音频-文本注意力和文本-音频注意力示意图,该图所对应的语句为“Okay.But I didn’t tell you to get in this line if you are filling out this particular form.”Fig.6 Audio-context attention and context-audio attention schematic diagram based on AT-Attention model,the corresponding sentence of which is “Okay.But I didn’t tell you to get in this line if you are filling out this particular form.”
图6中的文本-音频注意力热力图直观地显示出不同时间的注意力强度变化,对比图3—图6可发现注意力分数与音频的振幅、基频、共振峰相关特征、MFCC系数均有关系,并且随着时间变化,注意力分数与Mel频谱图中的频率和对数功率谱呈明显的正向关系,与音频强度和MFCC具有一定的正向对应关系.
6 结 论
本文提出了基于AT-Transformer的语音文本多模态对话生成模型,该模型通过VGGish实现对对话上下文的音频特征进行提取,并通过WordEmbedding计算文本嵌入向量,通过将其与位置编码进行加和融入位置信息,并将二者作为模型的输入.在编码阶段,通过多头注意力机制对文本和语音模态内、模态间关系计算,实现模态之间关系的深入挖掘,实验表明文本-音频注意力分数更能反映音频上下文的重要性程度.语音模态对于感知对话上下文的语义重要性有着不可或缺的作用,并且从多样性方面提升对话生成质量,与纯文本对话生成任务相比较,生成语句的流畅度基本持平,情感匹配度和语义相关性均有一定的提升.此外,由于现实生活中的音频数据具有时长差异性较大、不均衡的特点,如何对信息量较小的音频段进行过滤,实现高效的音频特征处理是下一步值得研究的问题.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
传媒评论(2017年3期)2017-06-13 09:18:10
电子制作(2017年9期)2017-04-17 03:00:46
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
人间(2015年8期)2016-01-09 13:12:42
语文知识(2014年4期)2014-02-28 21:59:52
