
商品推荐系统中的效用估计
2023-06-21 07:31:15朱启杰
上海管理科学 2023年2期
朱启杰


摘 要: 在零售商的角度,通常希望推荐系统的推荐产品能使商家的收益最大化。在以期望收益最大化为目标的产品组合优化模型中,商品效用是必不可少的参数。论文主要探究推荐系统中商品效用的估计方法,通过评估由商品效用计算得到的商品被点击概率,来验证效用估计的准确性。通过数值试验,将单值排序模型预估的点击概率与通过MNL模型估计商品效用计算的点击概率进行对比,结果证明MNL模型估计的商品效用具备与单值排序模型相当的准确率。此外,论文进一步构建了神经网络模型估计商品效用,并且另外构建了一个直接计算商品点击概率的attention选择模型作为对比。结果证明使用神经网络模型代替MNL来估计商品效用,能够更进一步提升效用预估的准确性。
关键词: 推荐系统;产品组合优化;MNL;神经网络;效用估计
中图分类号: G 206
文献标志码: A
Utility Estimation in Recommendation System
ZHU Qijie
(Antai College of Economics & Management, Shanghai Jiao Tong University, Shanghai 200030, China)
Abstract: From the retailer's perspective, it is usually hoped that the recommended products of the recommendation system can maximize the profit of the assortment. In the assortment optimization model aiming at maximizing expected revenues, product utility is an indispensable parameter. This article mainly explores the estimation method of product utility in the recommendation system, and verifies the accuracy of utility estimation by evaluating the click probability of the product calculated by the product utility. Through numerical experiments, the estimated click probability of the point-wise model is compared with the click probability calculated by the product utility estimated by the MNL model. The result proves that the product utility estimated by the MNL model has a good accuracy. In addition, this paper further builds a neural network model to estimate the utility of goods, and additionally builds an attention choice model that directly calculates the click probability of goods as a comparison. The results prove that using neural network model instead of MNL to estimate the utility of the commodity can further improve the accuracy of the utility prediction.
Key words: recommender system; assortment; Multinominal Logit Model; neural network; utility estimation
本文选择机票订单点击数据作为研究数据集,首先建立机器学习模型预测单个产品的用户点击概率,选择被点击概率最高的商品作为被点击的商品的预测;另一方面,本文选择经典的MNL(Multinomial Logit)模型作为选择模型,该模型使用特征的线性组合来估计商品的效用,根据该模型估计的商品效用,选择效用最高的商品作为被点击的商品的预测;为了解决一些线性模型存在的缺陷,本文构建了一种神经网络模型,使用其代替MNL模型估计商品效用,后续步骤不变,依然选择效用最高的商品作为被点击的商品的预测;最后,本文将构建一种考虑商品之间交互作用的预测模型(attention选择模型),用于与前述模型进行比较。本文通过实验证明,通过估计效用的方式估计商品被点击的概率能够取得不错的准确率,且使用复杂模型代替线性模型可以使准确率得到一定的提升。
1 文献综述
近年来,深度学习被广泛运用于推荐系统领域的研究中。基于深度学习的算法主要分为两类:一类是通过算法进行特征提取,另一类是通过算法直接计算用户对产品的点击概率。第一类算法主要是通过类似于自然语言处理中获取词向量的方式获取产品在空间上的向量表示,如Perozzi等人提出了DeepWalk模型,该模型利用用户的点击序列构建图,在图中随机游走获得产品的点击序列,再利用Skip-Gram以及Hierarchical Softmax等算法获取产品的向量表示;Wang等人提出了构建带权重的图的方法获得产品的点击序列,在训练产品的向量的同时训练其他产品所属类别特征的向量,该方法能夠在一定程度上解决冷启动问题。第二类算法将用户与产品作为输入,通过计算得到用户点击相关产品的概率,如Rendle等人提出FM模型,该模型除线性部分外,使用了特征之间的交互信息,可以很好地解决部分参数因数据稀疏的原因无法学习的问题;Juan等人提出FFM模型,该模型在FM模型的基础上做了一定的改进,每个特征不再只由单个向量表示,在与不同的特征交互时,根据交互特征的类型使用不同的语义向量,在保持参数量大致相同的同时,加快了训练速度,提升了训练效率与准确率;Cheng等人提出了Wide&Deep模型,该模型结合了传统的线性模型与神经网络各自的优势,平衡模型的记忆能力与泛化能力,取得了较好的效果。
另一方面,以往也有大量关于顾客选择模型以及对应的产品组合问题的研究。Vulcano等学者通过使用EM算法代替最大似然估计,估计MNL模型的参数,并通过实验说明了在收益管理领域使用选择模型是可行的,并且在实际场景下能够取得理想的收益;Davis等学者证明了基于MNL的产品选择问题,在多种限制条件下,均可转化为线性规划问题求解;Gallego等学者提出了针对嵌套的产品组合问题的一种近似算法,该算法能自提升速度的同时保证结果的有效性;Feldman等学者则通过线上对比实验比较了机器学习的算法以及基于MNL模型的产品组合优化算法,后者比前者取得了更高的收益。
2 算法模型
2.1 MNL选择模型
MNL模型假定顾客与给定的商品产生关联、产生效用,并且顾客最终只会购买效用最高的商品。在MNL模型中,顾客t对商品j的效用如下式所示:
Ujt=Vjt+εt
其中,Vjt为效用估计函数根据特征输出的效用估计值,为一确定值,而εt则为一个服从Gumbel分布的独立同分布变量。在MNL模型中,为了关联顾客与商品之间的特征,一般使用线性组合的方式以计算效用:
Vjt=∑ K k=1 wk xj,t,k
其中,xj,t,k代表了顾客t与商品j的各种特征,而wk则表示各个特征的权重。假设商品总集合为N={1, …, n},该集合包含了产品组合中所有可选择的商品,除了这n个商品,再假设有一编号为0的商品选项,该选项代表顾客没有点击购买商品组合任何一个商品。在本文中,我们将不失一般性地假设对任意顾客t,V0t=0。基于以上假设,在MNL模型中,对任意顾客t,将产品组合StN推荐给顾客,顾客点击产品组合中任意商品j∈St的概率为:
Pjt (St,Vt)= exp(Vjt) 1+∑i∈Stexp(Vit)
根据上式可以得出,任意商品的点击购买概率既与商品和用户本身的属性特征相关,同时也与产品组合中的其他商品相关。
在MNL模型中,各个特征的权重wk通常使用极大似然估计获得。假定历史点击数据D={(St,Xt,zt ):t=1,2,…,T},其中Xt={Xjt:j∈St},Xjt={xj,t,k,k=1,…,K},zt表示顾客最终点击商品的编码,若顾客未点击任何商品则zt=0。根据历史点击数据,通过极大似然估计得到权重:
W=argmaxw LL(W|D)
其中
LL(W|D)=∑ T t=0 lg exp(Vzt t) 1+∑i∈Stexp(Vit)
W={wk:k=1,…,K}
由于数据量较大,本文采用梯度下降的方法求解权重。
根据上述算法可知,MNL选择模型通过线性组合的简单形式计算商品效用,该模型参数量少、速度快并且具备可解释性,但在另一方面,该模型仅考虑了特征对商品效用的一阶的线性影响,并未考虑特征的高阶影响以及特征之间的交互作用,若使用一些基于深度学习的神经网络模型,则可以在一定程度上解决这一类的问题。
2.2 神经网络选择模型
在估计商品效用时,一些隐式的特征交互通常会对商品效用产生影响。比如顾客通常会在冬季点击购买外套,在夏季点击购买T恤,这是商品种类与时间两种因素对商品效用的交互影响;若再考虑年龄要素,年轻人通常会更喜欢潮流的服饰,而中老年人则通常偏好于成熟稳重的衣物。商品的效用可能还包括商品种类、时间以及消费者年龄三种因素之间的三阶交互影响。为了更好地学习到高阶特征以及特征之间的交互作用,本文将采用神经网络模型估计商品效用。
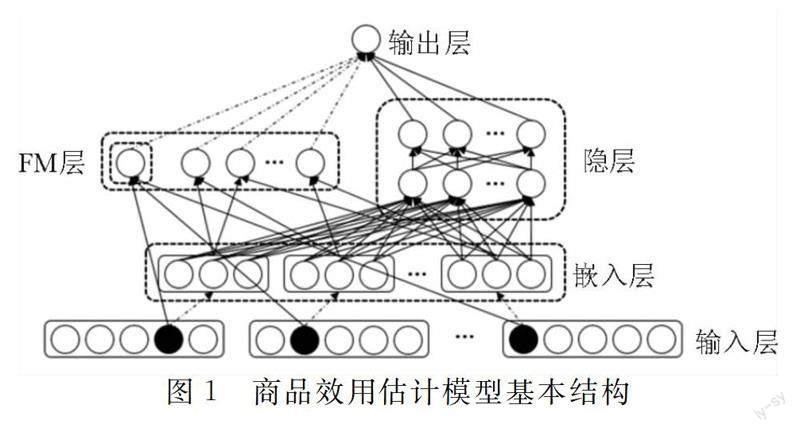
本文所采用的模型大致如图1所示,模型的基本架构使用了Guo等人提出的DeepFM模型。模型的输入主要分为两种类型的特征:连续特征以及离散的类别特征。连续特征的取值具备实际意义,可以进行大小比较以及加减运算;而类别特征的取值通常无实际意义,一般的做法是对类别特征采用独热编码(One-Hot Encoding)进行预处理,经过独热编码处理的数据只有0与1两种取值。
由于我们希望模型能够同时学习到不同特征之间的低阶以及高阶的交互,因此模型分为因子分解机(FM)与深度神经网络(DNN)两个部分。这里假定经过预处理的输入为X={xi:i=1,…,N}。
在FM部分,对于每个输入xi,模型都会赋予其一个参数wi以及一个隐向量vi,wi表示xi的一阶线性影响,而vi则用于计算特征之间的交互作用。FM部分主要通过不同特征对应的隐向量vi之间的内积来计算特征之间的二阶交互作用,在输入端数据十分稀疏的情况下,这种做法比给每一对输入特征的交互作用单赋予一个参数来计算交互作用更为有效以及可靠。这是因为若对每一对输入特征的交互作用单赋予一个参数,则只有这一对特征均不为0的情况下,该参数才能被学习;而在使用隐向量的方法时,在对应特征以及任意其他特征不为0的情况下,该特征对应的隐向量的参数都可以被学习。FM部分的输出为:
y1=∑ N i=1 wi xi
y2=∑ N-1 i1=1 ∑ N i2=i1+1 〈vi1,vi2〉xi1xi2
其中,y1表示特征的一階线性作用,y2表示特征的二阶交互作用。
在DNN部分,将所有不为0的输入按顺序找到每一个输入所对应的隐向量vi,在将隐向量乘对应的输入后,通过向量拼接得到输入a(0)=[v1,v2,…,vK]。这里a(0)的维度为d×K,其中d表示隐向量的维度,K表示预处理前特征的总个数。DNN部分为一个前馈神经网络,由于神经网络具备自动学习特征交互能力,模型该部分用于学习特征之间的高阶交互作用,前馈神经网络的计算方式如下:
a(l+1)=σ(W(l) a(l)+b(l))
其中,a(l)为神经网络上一层的输出,W(l)为l层的权重参数,b(l)为l层的偏移参数,a(l+1)为输出,σ为激活函数。模型的DNN部分的输出y3=a(L+1),L为前馈神经网络的总层数。
模型计算的效用为V=w0+y1+y2+y3,w0为偏置项。与MNL模型计算一样,假设V0t=0,通过Pjt(St,Vt)= exp(Vjt) 1+∑i∈Stexp(Vit) 计算顾客点击产品组合中任意商品j∈St的概率。沿用MNL模型相同的损失函数,通过梯度下降的方式估计模型参数。
2.3 考虑商品交互作用的attention选择模型
对于商品集合中每个商品点击概率预测的问题,目前的最优做法是通过神经网络结构对商品特征进行编码,将每一个候选集中的商品通过神经网络生成一个可以代表该商品所有特征的向量,再使用attention等方法将不同的商品间的交互特征结合进来,最终输出候选集中每个商品被点击的概率。
在本次研究中,为了更好地评估通过效用估计的商品点击概率的准确性,防止因为使用不同的网络结构影响到结果的准确性,因此在这个部分使用的神经网络模型依然为前述的神经网络模型,仅去除最后的输出层,将最后的隐层拼接作为网络学习到的商品的向量表示。
在这里,假设商品i的向量表示为di,通过attention的方法计算不同商品之间的交互作用,最终得到商品i的输出向量oi=∑Nj=1wijdj。这里wij计算的是商品j对商品i的输出向量的贡献,其计算方式为:
wij= cij ∑Nj=1cij
其中,
cij=vT (Wq di+Wv dj)
在這里,Wq, Wv∈Rd×d, di, v∈RN。最后,每个商品通过前馈神经网络得到对应的输出,再使用前述相同的方式计算每个商品被点击的概率。
该模型充分考虑了产品组合中不同商品的相互交互作用,是目前最优的选择模型构建思路,但也由于其考虑到了其他商品对于单个商品的影响,没有估计单个商品产生的效用,因此无法与优化模型相结合来得到最优产品组合。
3 数值实验
本文的实验数据来源于全球分销系统Amadeus收集的机票预订数据。在顾客预订机票时,顾客进行一些搜索,系统返回不同的航班信息,顾客选择点击这些航班中的一个。本文选择部分数据集,共16861条数据作为训练集,1000条数据作为测试集,每条数据含三十个备选航线。每条航线包含数值特征与类别特征,如表1所示。出于法律上的原因,数据并未包含乘客的相关信息。
对于中转时间、总价格以及飞行时间等连续型变量,数值的取值范围过大,若单个特征对应数值过大,很可能会直接影响模型结果。因此,对中转时间,总价格以及飞行时间三个变量,计算每个变量在所有样本中的最大值max以及最小值min,采用归一化的方式进行预处理,加快模型的收敛速度:
x′= x-min max-min
对于出发时间以及到达时间,将时间特征投影到极坐标,00:00(0分钟)对应0,24:00(1440分钟)对应2π。根据时间的特性可知,两个时间对应的角度夹角越小,则表示这两个时间越接近,因此采用计算sin与cos的方式转换对应的时间特征:
xsin=sin x 1440 ×2π
xcos=cos x 1440 ×2π
本文使用上述仿真数据,采用了LightGBM、MNL选择模型、神经网络选择模型以及attention选择模型4种模型对用户可能点击的商品进行预测。
LightGBM是一种基于分类回归树的梯度提升树改进算法,在本次研究中,将所有训练数据中的所有商品作为样本,使用每个商品被点击的概率作为标签,训练LightGBM模型。在测试阶段,对商品候选集里的所有商品都预测一个点击概率,选择预测概率最高的商品作为预测的被点击对象。
MNL选择模型、神经网络选择模型的训练过程与LightGBM不同,其输入为产品组合中的一个商品,通过模型计算商品的效用,最后将产品组合中所有商品的效用进行归一化处理,计算产品组合中每个商品的点击概率,并通过梯度下降的方式训练模型。在测试阶段,使用模型估计商品候选集中每个商品的效用,选择效用最高的商品作为预测的被点击对象。
Attention选择模型的输入是一个产品组合,其中的每个商品通过网络被编码为一个向量,再通过这些向量计算交互因素,最终通过归一化的方式输出商品在该产品组合中被点击的概率。在测试阶段,选择被点击概率最高的商品作为预测的被点击对象。
本次实验的评价指标为被点击概率top K商品的被点击率,实验结果如表2和图2所示。由表2可以看出,尽管MNL模型结构简单,拟合能力不强,但通过其预估的商品效用具备一定的准确性,通过效用计算的被点击概率能够取得与LightGBM模型相近的结果,并且MNL模型还具备可解释性以及高效快速等优势。而使用神经网络模型来估计效用,同样也是根据效用来推荐商品,其表现明显好于MNL模型,说明优化模型的结构、考虑更多特征的交互能够显著提升效用估计的准确性。最后,使用attention选择模型的表现则略微好于前述估计单个商品效用的模型,说明在该场景下,前述模型对于商品效用的估计还是比较准确的,可以通过将效用估计和优化模型结合的方式来确定最优的产品组合。
4 总结
本文从如何进行产品组合推荐才能使得商家期望收益最大化这一背景出发,对如何准确估计商品对顾客产生的效用这一问题进行了探究。本文使用了LightGBM、MNL选择模型、神经网络选择模型以及attention选择模型4种模型,通过数值实验,得到了如下结论:(1)通过线性模型估计的商品效用可以取得令人满意的准确率,并且线性模型还具备可解释性等优势。(2)通过神经网络来估计商品效用,能够解决线性模型存在的问题,大大提升了估计的准确性,并且通过其计算得到的商品点击概率与attention选择模型相比差距不大。因此,使用神经网络模型估计商品效用具备一定的实际意义,可以将其运用于产品组合优化模型中,这对商家的推荐系统如何进行商品推荐具备一定的参考意义。
參考文献:
[1] MCFADDEN D. Conditional logit analysis of qualitative choice behavior[J]. 1973.
[2] GUO H, TANG R, YE Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
[3] MOTTINI A, ACUNA-AGOST R. Deep choice model using pointer networks for airline itinerary prediction[C]//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2017: 1575-1583.
[4] KE G, MENG Q, FINLEY T, et al. Lightgbm: a highly efficient gradient boosting decision tree[C]//Advances in neural information processing systems. 2017: 3146-3154.
[5] PEROZZI B, AL-RFOU R, SKIENA S. Deepwalk: online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 701-710.
[6] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[7] WANG J, HUANG P, ZHAO H, et al. Billion-scale commodity embedding for e-commerce recommendation in alibaba[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018: 839-848.
[8] RENDLE S. Factorization machines[C]//2010 IEEE International Conference on Data Mining. IEEE, 2010: 995-1000.
[9] JUAN Y, ZHUANG Y, CHIN W S, et al. Field-aware factorization machines for CTR prediction[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 43-50.
[10] CHENG H T, KOC L, HARMSEN J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. ACM, 2016: 7-10.
[11] VULCANO G, VAN RYZIN G, CHAAR W. Om practice—choice-based revenue management: an empirical study of estimation and optimization[J]. Manufacturing & Service Operations Management, 2010, 12(3): 371-392.
[12] DAVIS J, GALLEGO G, TOPALOGLU H. Assortment planning under the multinomial logit model with totally unimodular constraint structures[J]. Work in Progress, 2013.
[13] GALLEGO G, TOPALOGLU H. Constrained assortment optimization for the nested logit model[J]. Management Science, 2014, 60(10): 2583-2601.
[14] FELDMAN J, ZHANG D, LIU X, et al. Taking assortment optimization from theory to practice: evidence from large field experiments on alibaba[J].
[15] FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. Annals of Statistics, 2001: 1189-1232.
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
软件(2016年4期)2017-01-20 10:09:33
计算机应用(2016年12期)2017-01-13 20:37:46
电脑知识与技术(2016年28期)2016-12-21 11:09:59
电脑知识与技术(2016年27期)2016-12-15 19:46:14
电脑知识与技术(2016年25期)2016-11-16 14:41:13
商(2016年29期)2016-10-29 15:22:08
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
