
浅谈Mahout在个性化推荐系统中的应用
2016-11-16 14:41邓秀娟
电脑知识与技术 2016年25期
邓秀娟
摘要:面对当今信息过载的问题,推荐系统发挥了重要的作用,构建一种基于Mahout的推荐引擎使推荐系统发挥更优的推荐效果。本文介绍了Mahout中的各种推荐算法的基本特点,基于某约会网站的数据示例,对几种推荐算法进行尝试性测试,从而找出最优的算法组合方案实现一个推荐引擎。
关键词:推荐系统;Mahout;单机内存算法;组件
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)25-0171-02
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代进入了信息过载的时代。推荐系统的出现可以帮助用户发现对自己有价值的信息,同时能够让信息展现在对它感兴趣的用户面前。个性化推荐系统依赖于用户的行为数据,目前被广泛地应用在包括电子商务、社交网络、电影和视频、音乐、个性化邮件和广告、基于位置的服务、阅读等领域中,从而提高相关网站的点击率和转化率。Mahout是来自Apache的、开源的机器学习软件库,主要提供了机器学习领域的推荐引擎(协同过滤)、聚类和分类算法的实现,为推荐系统的应用和研究提供了支持。
本文通过对Mahout中的推荐算法进行研究,使用一个示例对推荐算法进行评估,从而找到一个有效的推荐程序应用到示例中,为用户实现推荐。
1 Mahout的推荐算法
基于Hadoop分布式框架的机器学习算法库Mahout封装了多种机器学习算法的分布式实现,由多个组件混搭而成,各个组件的组合可以定制,从而针对特定应用提供理想的推荐。通常包括的组件如下:数据模型由DataModel实现;用户间的相似性度量由UserSimilarity实现;用户近邻的定义由UserNeighborhood实现;推荐引擎由一个Reommender实现。从数据处理能力上,Mahout推荐算法可以分为单机内存算法和基于Hadoop的分布式算法,本文仅讨论单机内存算法。
1.1 推荐数据的表示
推荐引擎的输入是偏好数据(preference data),通常用(用户ID,物品ID,偏好值)的元组集合来表示。在Mahout中使用DataModel对推荐程序的输入数据进行封装,GernericDataModel是现有DataModel实现中最简单的,它通过程序在内存中构造数据表示形式,将偏好作为输入,将用户ID映射到这些用户数据所在的PreferenceArray(一个接口,表示一个偏好的聚合)上。若用户和物品的数据无偏好值时,可以使用GenericBooleanPrefDataModel来实现。基于文件的数据使用FileDataModel,从文件中读取数据,将所得的偏好数据存储到内存,即GernericDataModel中。基于数据库的数据用JDBCDataModel实现,若使用MySQL数据库,可以使用其子类MySQLJDBCDataModel。
1.2 相似性度量
基于用户的推荐程序和基于物品的推荐程序都依赖于UserSimilarity这个组件,及用户或物品之间的相似性,缺乏对用户或物品的相似性定义的推荐方法是毫无意义的。相似度算法包括了欧氏距离相似度(EuclideanDistanceSimilarity)、皮尔逊相关系数相似度(PearsonCorrelationSimilarity)、曼哈顿距离相似度(CityBlockSimilarity)、对数似然相似度(LogLikehoodSimilarity)、谷本系数相似度(TanimotoCoefficientSimilarity)等
1.3 用户近邻
近邻算法适用于基于用户的协同过滤算法,选出前N个最相似的用户构成邻域,作为最终推荐参考的用户。近邻算法分为2种:基于固定大小和基于阈值的。NearestNUserNeighborhood实现基于固定大小的邻域,指定N的个数,如选出前10个最相似的用户;ThresholdUserNerghborhood实现基于阈值的邻域,指定比例,如选择前10%最相似的用户。
1.4 推荐算法
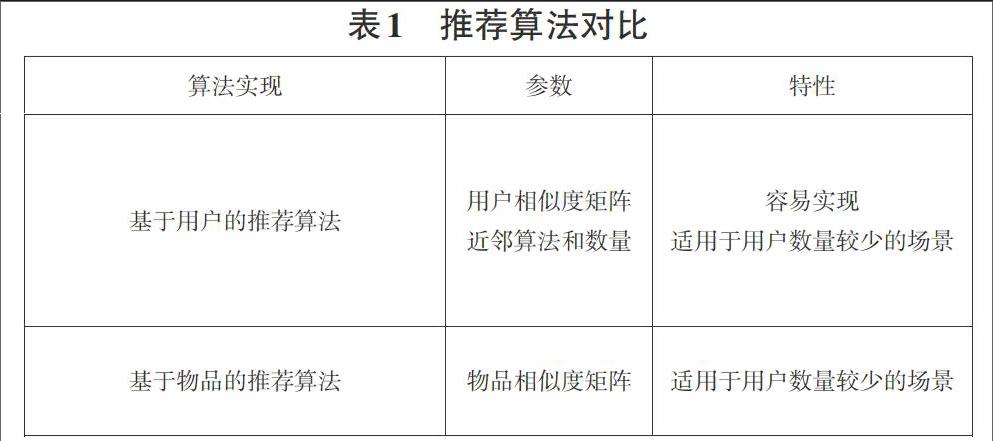
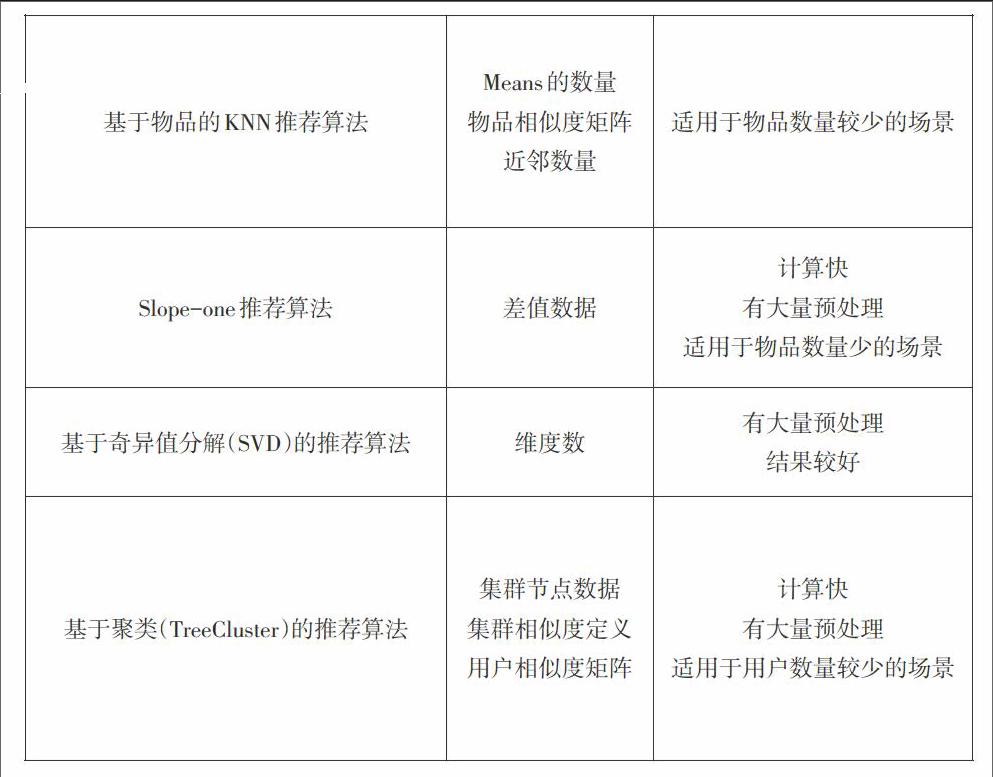
Mahout的推荐算法以Recommender作为基础父类,实现类有基于用户的推荐算法、基于物品的推荐算法、基于物品的KNN的推荐算法、Slope-one推荐算法、基于奇异值分解(SVD)的推荐算法、基于聚类(TreeCluster)的推荐算法。推荐算法对比如表1所示。
2 Mahout在推荐系统中的应用
上节介绍了Mahout提供的推荐算法,接下来讲述如何在数据集上使用Mahout开发推荐系统。首先分析样本数据,对数据做预处理,然后选取一个方法,收集数据、评估结果,多次重复这个过程,找到最优的推荐算法创建一个推荐引擎。
本示例数据来自捷克的一个约会网站(http://libimseti.cz)。该网站的用户可以对其他用户的档案进行评分,分值从1到10不等,分值1代表“喜欢”,分值10代表“不喜欢”。
2.1 数据的输入
示例数据集有17359346份评分,存储为ratings.dat文件,是一个简单地以逗号分界的文件,包含用户ID、档案ID和评分,档案是指其他用户的档案。每行代表一个用户对另一个用户档案的一次评分,如:1,133,8,表示用户ID为“1”的用户对档案ID为“133”的评分值为8。输入数据的格式直接可以用于Mahout的FileDataModel。即用户和档案是数字,文件按字段依次以逗号分隔:用户ID,物品ID,偏好值。
2.2 寻找一个有效的推荐程序
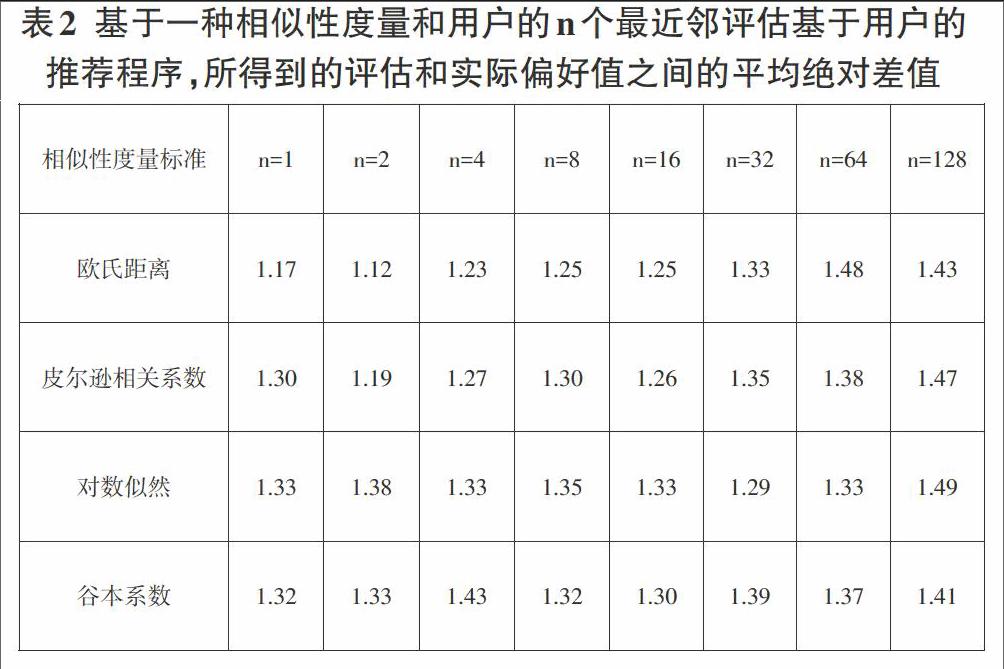
为了创建一个推荐引擎来处理示例数据,需要从Mahout中挑选一个推荐程序。通过在基于用户的推荐程序和基于物品的推荐程序下选择几种不同的相似性度量和邻域定义进行尝试性测试,测试结果如表2、表3所示。
以上的结果较为理想。这些推荐程序估计的用户偏好平均偏差在1.12~1.56之间,而取值范围为1~10。最佳的方案是选择基于欧氏距离相似性度量和2个最近邻域的基于用户的推荐程序,其评分估值为1.12。
从结果看出,平均误差,即估计值和实际值的平均差值翻了大概2倍,具体值超过了2,显然基于物品的推荐方法相较于基于用户的推荐方法效果不佳。
Slope-one推荐程序在数据模型中的大多数物品对之间求得一个差值。示例数据集中有168791个物品(档案),意味着潜在存储了280亿个差值,它太庞大因而无法存入内存。可以考虑在数据库中存储这些差值,但会极大地降低性能。对于示例数据集,Slope-one推荐程序也并非最佳选择。
读者还可以尝试更多的组合进行测试,经过目前所做的测试进行对比分析,这里在Mahout中选择最佳方案:基于用户的推荐程序,采用欧氏距离测度且邻域为2。
2.3 评估性能
使用Mahout的LoadEvaluator类评估该数据集上使用的推荐程序,采用如下的标识类参数:-server –d64 –XmX2048 –XX:+UseParallelGC –XX:+UserParallelOldGC。在测试机上平均每次推荐会用218ms。这个程序在运行时仅占用1GB左右的堆空间。这些测试结果是否可被接受,依赖于应用的需求和可用的硬件资源。对于许多应用而言,这些测试数据应该还是符合要求的。
3 结束语
本文通过使用一个来自约会网站的数据作为示例,分析了数据的格式,使之成为适合Mahout应用的数据输入格式。通过尝试性测试不同算法组件的组合进行对比,找出最佳的推荐程序,并对推荐程序进行性能评估,使读者了解在Mahout选择和创建一个推荐引擎的基本过程。本文仅讨论了基于单机内存的算法,基于Hadoop的分布式算法将是今后考虑的研究方向。
参考文献:
[1] 朱倩,钱立.基于Mahout的推荐系统的分析与设计[J].科技通报,2013(6):35-36.
[2] 韩怀梅,李淑琴.基于Mahout的个性化推荐系统架构[J].北京信息科技大学学报:自然科学版,2014(4):51-54.
[3] 陶维成,王婷婷,姚琪.基于Mahout的推荐系统构建[J].重庆科技学院学报:自然科学版,2014(2):143-146.
[4] 奉国和,黄家兴.基于Hadoop与Mahout的协同过滤图书推荐研究[J].图书情报工作,2013(18):116-121.
猜你喜欢
能源工程(2022年2期)2022-05-23
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
中国公路(2017年16期)2017-10-14
计算机应用(2016年12期)2017-01-13
太阳能(2015年11期)2015-04-10
太阳能(2015年5期)2015-02-28
