
面向无线传感器网络节点定位的移动锚节点路径规划
2023-06-20 12:19:40牛龙生郭瑛
青岛科技大学学报(自然科学版) 2023年3期
牛龙生,张 瑞,郭瑛
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
在无线传感器网络中,只有传感器节点的位置已知,节点采集的数据才有意义[1]。然而,受限于传感器节点的成本,为每一个节点配置GPS设备是不现实的[2]。通常,待定位的传感器节点将少量配有GPS装置、位置已知的锚节点视为参考节点[3],通过与锚节点间的通信估计或计算自身位置[4-5]。锚节点的成本高,部署位置对于定位精度影响较大,采用移动锚节点可以有效的降低部署的成本,提高定位精度。
按照锚节点的移动路径不同,可分为基于静态路径的定位算法和基于动态路径的定位算法[6]。在基于静态路径的算法中,锚节点循着静态路径对整个部署区域进行全局扫描。典型的静态路径包括SCAN[7]、HILBERT[7]、Z-Curve[8]、M-Curve[9]等。其中SCAN 路径简单但存在信标分布的共线性问题;HILBERT、Z-Curve、M-Curve解决了这个问题而增大了路径长度。在实际环境中,传感器节点部署不均匀,且分布受外力影响[10]。这时,锚节点无法避开空白区域,从而发送无效信标,消耗了能量。
移动锚节点动态路径规划的基本原理是利用网络中局部邻居信息来决定锚节点的下一步前进方向。FU等[11]基于人工势场法,利用6个定向天线,选择虚拟力最大的那个方向作为下一步的移动方向;WEI等[12]同样使用虚拟力机制,设计了基于未知节点密度权重的改进虚拟力模型及回退方案,并讨论了最优的移动步长。算法总是可以使每个未知节点周围的三个信标节点呈正三角形分布,定位误差较小;李洪峻等[13]利用图论,将路径规划问题转化为图的遍历问题,他们提出了一种宽度优先(BRF)算法和回溯贪心(BTG)算法,将通信范围内的节点划分为内部节点和边缘节点,在生成树的建立过程中只考虑边缘节点,这减小了路径长度但也导致部分内部节点无法定位;LI等[14]提出了一种启发式运动策略和局部最小生成树的优化技术,并进一步研究了多移动信标协作定位。这些算法都使用了生成树的深度优先遍历(depth-first traversal,DFT),回溯代价较大。李松生等[15]提出了一种动态选择前进方向的策略,但定位率不高。ABDULLAH等[16]应用模糊逻辑,综合考虑未知节点的RSSI、邻居的数量,选出下一步的前进方向,而这对锚节点的计算能力有更高的要求。
基于边界的方法[17-18]是机器人环境探索领域的一种重要方法,其中边界指的是已知与未知区域的边界。NAGALAJU等[19]首次在无线传感器网络中使用该方法进行区域探测和节点定位,是一种比较新的视角。受此影响,本工作首先设计了锚节点和传感器节点之间的通信过程,并引入了两种新的数据结构,边缘点与探索点,不仅提高了定位率,而且避免了对生成树的逐层回溯,提高了算法的效率。进而提出了一种动态、静态路径相结合的锚节点移动方案:锚节点采用正六边形轨迹或菱形轨迹来覆盖某一局部区域,这使得该局部区域内,节点接近完全定位;覆盖完一个区域后根据局部邻居信息动态选择并移动到下一个覆盖区域。相比静态路径,这种路径因可以避开空白区域而更加灵活;相比传统的动态路径方案,这种路径方案通过区域覆盖定位局部子区域的大部分节点,也大大减少了对同一子区域的重复访问,从而避免不必要的能量消耗。仿真结果表明本设计的路径较短,基于这种路径的定位算法定位率更高。
1 通信过程设计
锚节点和普通的传感器节点存在功能、制作成本等方面的差异,因此可以有不同的通信范围。能量优化是无线传感器网络研究中最重要的问题之一。有研究表明,使两种节点的通信范围保持一致可以建立双向连接并节省能量[20]。因此在本工作的设计中,令锚节点和普通的传感器节点通信范围相同。
锚节点在其移动过程中发送包含自身当前位置的信标。当锚节点移动到一个新位置时,其通信范围内的节点分为3类:未定位节点、新定位的节点、先前已定位节点。其中新定位节点指的是通过锚节点这次移动引入的新的位置信息而完成定位的那些节点;先前已定位节点指的是已经完成定位的节点,锚节点这次新的移动没有改变它的已定位状态;未定位节点指的是在锚节点这次移动后依然无法完成定位计算的节点。随着锚节点的移动、定位的进行,每个节点都会由未定位状态变成新定位状态,之后再由新定位状态变成先前已定位状态。不同的状态下传感器节点需要处理的数据包也不尽相同。新定位的节点需要与其一跳邻居以及锚节点通信:收集邻居的信息,然后回复锚节点;先前定位的节点回复新定位的节点的询问消息;而未定位的节点只与锚节点进行通信。
首先,网络中所有节点经历一个邻居发现过程,每个传感器节点广播一条自身是否已被定位的消息,过程中传感器节点广播后只被动的接收信号,而不转发。这样每个传感器节点都只获得它的一跳邻居信息。此信息包含了邻居的数目以及某个邻居是否已经完成定位。每个节点都维护一个“未定位邻居列表”{unloc_nb_num,nb_id1,nb_id2,…},其中第一项是未定位邻居的数量,后面的项是其邻居的id集合。
随着锚节点的移动并发出信标,引入了新的位置信息,一些未定位节点可以通过计算确定自身位置,这些节点的状态变成了新定位状态。每个新定位的节点会广播一条消息,告知其所有的一跳邻居节点自身已定位。对于这个新定位节点的每个一跳邻居节点,在收到此消息后,把这个新定位的节点id从它们的未定位邻居列表中删除,并且相应的unloc_nb_num减1。如果这个邻居节点为已定位状态,则向新定位的节点回复最新的unloc_nb_num信息,否则不回复消息。
锚节点维护两个列表,边缘列表和探索列表。如果节点已定位,但其unloc_nb_num不为零,则称之为边缘点。这样的节点组成了边缘列表。探索列表记录所有探索点,探索点存储了未定位节点通信范围内的一个信标发出点位置,用来标记那些还未定位、但曾经接收到至少一个信标的节点。边缘点定义为{node_id,cal(x),cal(y),NFP(x),NFP(y),unloc_nb_num},探索点定义为{node_id,ref_beacon(x),ref_beacon(y)}。其中,cal(x)和cal(y)表示计算出的节点坐标,NFP主要用于推断局部区域哪一侧尚未访问,将在2.2.3节介绍的过程中用到。ref_beacon是未定位节点接收到的第一个信标的信标发出点位置。
新定位节点向锚节点的回复消息定义为{node_id,cal(x),cal(y),unloc_nb_num,Map
一般来说,发送信号的能量消耗远远大于接收信号,所以这里主要考虑上述通信过程中每个节点发送信号的能量消耗。首先每个节点在邻居发现阶段都要经历一次广播。定位开始后,每个节点在第一次收到信标时回复锚节点;在新定位时广播消息、向锚节点回复邻居的信息;以及作为先前已定位节点向其新定位的邻居节点回复消息。先前已定位状态下回复新定位邻居的次数与网络的连通度有关。节点度[21]是衡量网络连通度的重要指标,指的是网络中节点的平均连接数,定义如下,
其中V_links指的是网络中的总连接数,V_nodes指总的节点数。假设网络的节点度为n,这样,每个节点需要进行2次广播和(n+2)次单播。
2 移动锚节点路径规划
2.1 定位方法
假设锚节点的通信范围为R,则其发出的信标的覆盖区域为一个圆,该圆以锚节点的当前位置为中心,R为半径。对于定位问题,常用的方法是三边测量法。在此方法中,节点通过3个非共线信标的坐标与到它们的距离计算自身位置,即
其中,(xi1,yi1),(xi2,yi2)和(xi3,yi3)是节点收到的3个信标的发出点坐标,d1,d2,d3是到它们的距离。∈表示不规则信号传输引起的误差。求解此线性方程组,即可得待定位节点的坐标。
2.2 移动路径设计
2.2.1 初始覆盖(Initialize)
李石坚等[22]指出,为了保证完全定位,锚节点所发出的各个信标的分布应满足对部署区域达到三重覆盖。即当锚节点沿某一路径移动时,该路径需要使得部署区域中任意点均至少可以接收到3个不同的信标数据包,这样可以保证无论节点如何分布均可进行定位[22]。前面说明,信标的通信范围在二维平面上是一个圆,那么部署区域的任意子区域都需要被至少3个圆覆盖。图1为三重覆盖问题与初始覆盖轨迹图,对于中间的圆,所有子区域都被3个圆覆盖,这样这个圆就达到了三重覆盖,处于这个圆内任何位置的节点均可被定位。

图1 三重覆盖问题与初始覆盖轨迹Fig. 1 3-coverage problem and initial trajectory
图1中,为保证中间圆的三重覆盖,每个圆心都要作为一个信标发出点,连接所有圆心,便得到了初始覆盖轨迹。显然,这类正六边形型轨迹的六边形边长为R。
2.2.2 步进(Step by step)
初始覆盖后,位于这个初始覆盖区域内的节点都被定位了,这样产生了一批已定位节点。之后,锚节点将选择向unloc_nb_num最大的已定位的一跳邻居的方向移动,在该方向上,锚节点移动长度R,移动后的位置将作为下一个覆盖区域的中心。图2为步进图,以图2(a)为例,在圆1的初始覆盖之后,它发现了当前覆盖区域内有一个节点Q0,该节点unloc_nb_num最大。因此沿着的Q0方向,锚点移动到Q1,并且Q1被确定为下一覆盖区域圆2的中心。
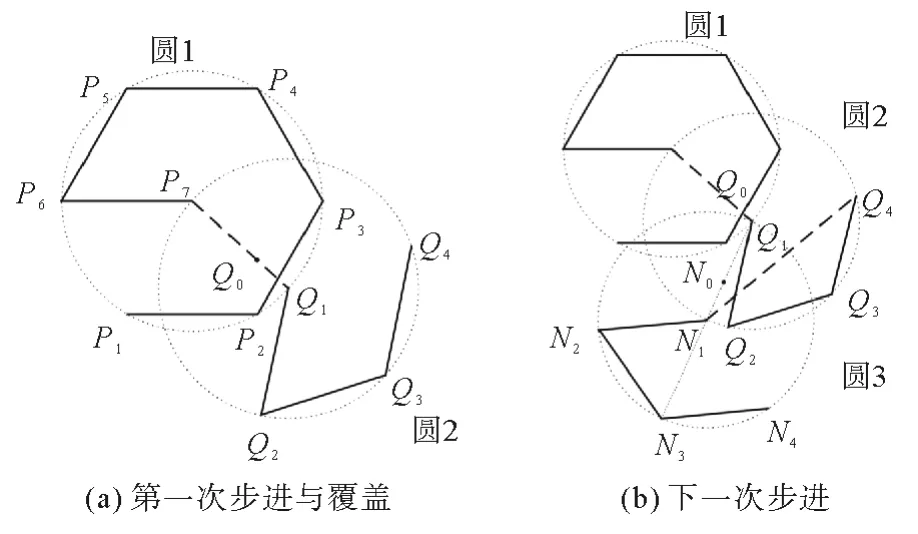
图2 步进图Fig. 2 Map of step
在圆2中,与圆1相交区域中的节点已被覆盖和定位。为了覆盖圆2的剩余区域,设计了菱形轨迹,菱形边长也为R。在设计的路径中,称正六边形的中心或菱形的起点为前进点,如图2(a)中P7和Q1。上一个前进点、当前前进点及其在菱形中的对点三点共线。
与六边形轨迹类似,菱形的每个顶点也都是一个信标发出点。显然位于菱形内的所有节点都可以接收到3个信标并定位,而对于圆2中剩余的未覆盖区域,可以通过结合前后两个圆中的部分信标来进行定位。这样,对于圆2也可以实现近似的完全定位。若某个节点收到的信标不足以完成定位,则第1节所述的通信过程保证了该节点附近的一个信标发出点一定在探索列表中,算法保证如果某个探索点对应的节点没有定位,则该探索点在后面的过程一定会被访问。
由第1节通信过程可以推出,锚节点在访问第4个顶点后获得的信息足以涵盖所有对当前覆盖范围内已定位节点的更新,于是在这个信标发出点处锚节点便可以决定下一步移动方向了。这样,锚节点可以直接从第4个顶点移动到新的前进点,而无需重访菱形第一个顶点。以图2(b)为例,锚节点可以从Q4移动到N1,无需通过Q1中转。
只要当前覆盖区域内存在一个unloc_nb_num不为零的已定位节点,本节所述的过程会重复执行下去。在每一步中,都会由当前覆盖区域内的一个已定位节点确定方向,锚节点沿着该方向移动到下一个前进点,并开始新一步的菱形覆盖。
2.2.3 跳转(Jump)
在前进过程中,每一步选择一个已定位邻居节点来确定方向,而其他unloc_nb_num不为零的已定位节点则存储在边缘列表中。当当前覆盖区域内没有unloc_nb_num不为零的节点时,则从边缘列表中选择v最小的边缘点。式(3)中定义了V。
其中Vdist_to_it表示锚节点的当前位置与边缘点之间的距离,也就是说锚节点这时倾向于选择未定位邻居数目多而距离当前位置近的边缘点。选择完成后,锚节点将直接移动到所选边缘点的位置(即(cal(x),cal(y)))并执行前一节的步进过程。这里,边缘点定义中的NFP被视为上一个前进点的所在位置,用于判断哪一侧尚未访问,以便计算出新菱形的四个顶点位置,然后可将该边缘点从边缘列表中删除。
2.2.4 重置(Reset)
当锚节点的当前覆盖范围内没有unloc_nb_num不为零的节点并且边缘列表也为空时,如果探索列表不为空,将从探索列表中选择(按照距离的远近,类似2.2.3节dist_to_it)一个探索点。探索点存储的是距离某个待定位节点最近的信标发出点位置。在这一步中,需要进行一次六边形覆盖过程。六边形轨迹以ref_beacon为中心,可以确保该区域中所有节点完全定位。可见这一步骤包含了探索点选择过程以及在选定的探索点附近的六边形覆盖过程。
这个过程结束后,也从探索列表中删除所选探索点,然后进入2.2.2节的步进过程。当锚节点的当前覆盖范围内没有unloc_nb_num不为零的节点且边缘列表与探索列表均为空时,算法结束。算法的伪代码描述如下:
算法描述
在求解式(2)时,其中两个信标之间相距太近会使计算误差过大。为了提高定位精度,可以消除节点接收到的一些相距太近的信标。探索列表保证了每个节点总能接收至少3个合适的定位信标。
定理1对于一个连通的网络,本算法可以保证完全定位。
证明(反证法)如果算法执行结束,还有一个节点未定位,根据连通性的定义,它一定有一个知道这一信息的邻居,记为A。当锚节点对A进行定位时,A会将此信息发送给移动锚节点。A要么作为一个边缘点加入边缘列表,要么是下一步前进方向。对于前者,边缘列表不为空,算法会继续执行;对于后者,这时锚节点在A周围进行菱形覆盖,节点可能通过这次覆盖直接完成定位,否则节点收到的第一个信标发出点位置会被添加到探索列表中,(只有该节点完成定位时,才能从探索列表中移出)探索列表不为空,算法也将继续执行。在两种情况下,都与原假设矛盾(即算法执行结束)。证毕。
3 仿真
3.1 设置
本节使用Matlab R2020a对本算法的表现进行验证。若干个节点分布在1 000 m*1 000 m区域内,通信范围R为150 m。假设距离的测量值遵循实际距离为平均值,实际距离的2%[23]为标准差的正态分布。节点的数量由网络的节点度确定。
为方便表述,这里取2.2节4个步骤对应英文单词的首字母作为本算法的名称,即ISJR(Initialize,Step by step,Jump,Reset)。与基于静态路径的M-Curve[9]、基于虚拟力的VFMS[12]和基于启发式运动的DREAMS[14]进行了比较。M-Curve使用静态路径,后两种使用动态路径。定位方法均采用三边测量法。分别比较了这4种算法的定位率、平均定位误差、路径长度以及信标数量。其中定位率为算法结束后已定位节点的数目与总节点数目的比值。定位误差定义为节点的估计位置与实际位置的欧几里得距离。平均定位误差为所有已定位节点的定位误差的算术平均值。锚节点的路径长度是指锚节点在整个定位过程中的总移动距离。信标数目指的是定位过程中锚节点需要发出信标的数量。因为在不同的节点度下,不同的算法定位率不同,这对路径长度及信标节点的数目也造成影响。为部分抵消这种影响,路径长度及信标节点的数目的仿真结果都除以对应算法的定位率作为该指标的最终值。
图3 锚节点的生成路径Fig. 3 Generated path of anchor
3.2 仿真结果与分析
3.2.1 定位率与平均定位误差
本节比较了C型分布时的定位率与定位误差,如图4所示。M-Curve是静态路径,对区域进行全局扫描,因此总能够定位区域内所有节点。ISJR 及另外两种基于动态路径的算法受到网络连通性的影响,在节点度低时无法实现完全定位。

图4 定位率与定位误差Fig. 4 Localization ratios and localization errors
在节点度较低时,网络不连通,包含多个连通的子网。由1.1节的通信过程可知,如果一个待定位节点到某个信标发出点的距离小于通信范围,那么这个待定位节点就会作为未定位节点与锚节点进行通信,这个信标发出点的位置会作为一个探索点并存入探索列表。在定位一个子网时,可能另一个子网的某个传感器节点与锚节点的某个信标发出点之间的距离小于通信范围。这样,在完成当前子网的定位过程后,探索列表不为空,算法将继续执行,从而可进一步定位另一个连通的子网。结合定理1,ISJR确保至少可完全定位一个连通的子网,并且有机会通过某个探索点进一步发现另一个子网,因此在定位率方面多次运行的平均表现好于VFMS和DREAMS。
4种算法均采用三边测量法进行定位计算,定位精度的差异主要源于信标发出点的分布。ISJR、M-Curve和VFMS 在定位误差方面差距不大。VFMS总是可以使信标分布均匀,有最佳的定位精度,随之而来的是该算法锚节点移动不够灵活、路径较长,这将在下一小节中展示。
3.2.2 路径长度与信标数量
本节评估了在C 型分布和矩形分布时关于这两个指标的各个算法的表现。图5 为C 型与矩形分布时不同节点度下锚节点路径长度,在C 型分布时,当节点度为5时,定位率较低,VFMS和DREAMS算法运行时的生成树是一棵包含少数已定位节点的生成树,树的高度较低,除以定位率进行的修正不过是对这种短路径的简单加和,因而这时表现为路径短,但这于该算法的实际效果并无意义;当节点度进一步增加时,这些算法定位率接近100%,这时VFMS和DREAMS生成树变高,造成回溯的成本增加。ISJR 利用边缘列表和探索列表存储了需要回溯的节点位置,这部分是直线移动,相比DREAMS和VFMS的逐层回溯,有更高的效率、路径也更短。M-Curve是静态路径,不能避开空白区域,在这种分布下表现不如ISJR和DREAMS。
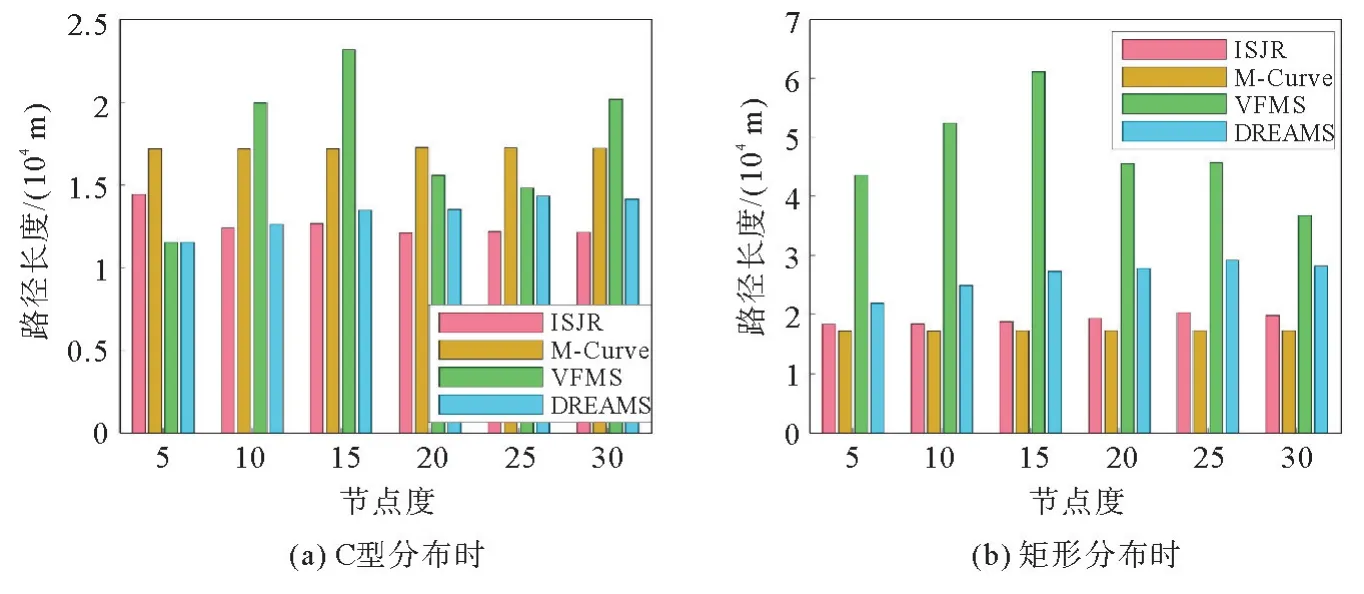
图5 C型与矩形分布时不同节点度下锚节点路径长度Fig. 5 Path lengths under C-type and rectangle distribution
如果传感器节点均匀分布在矩形区域,对整个区域进行全局扫描是合理且高效的,图5(b)显示了此时M-Curve路径长度最短。矩形分布下这些算法的定位率都接近100%,路径长度方面本工作算法表现优于VFMS 和DREAMS 而稍差于MCurve,长度约比M-Curve高15%。可以说在传感器节点矩形内均匀分布的场景,本工作提出的路径方案提供的结果也是可接受的。
信标数目和锚节点的路径长度基本上是呈正相关的。图6显示了这4种算法完成定位时锚节点所需要发送的信标数量。M-Curve是静态路径,在不同的网络节点分布下需要发出的信标数目固定,路径上也存在一些冗余信标。VFMS 回溯时需要重复发出信标,同时受网络拓扑与节点度的影响明显,有较大起伏,而总体上处于较高的水平。DREAMS采取启发式移动的策略,需要不断地发出信标试错,同时也存在DFT 的回溯过程,因此信标数目较高。在这个指标上,本算法采取动态、静态路径相结合的路径方案,所需的信标数目总能维持在一个较低的水平。
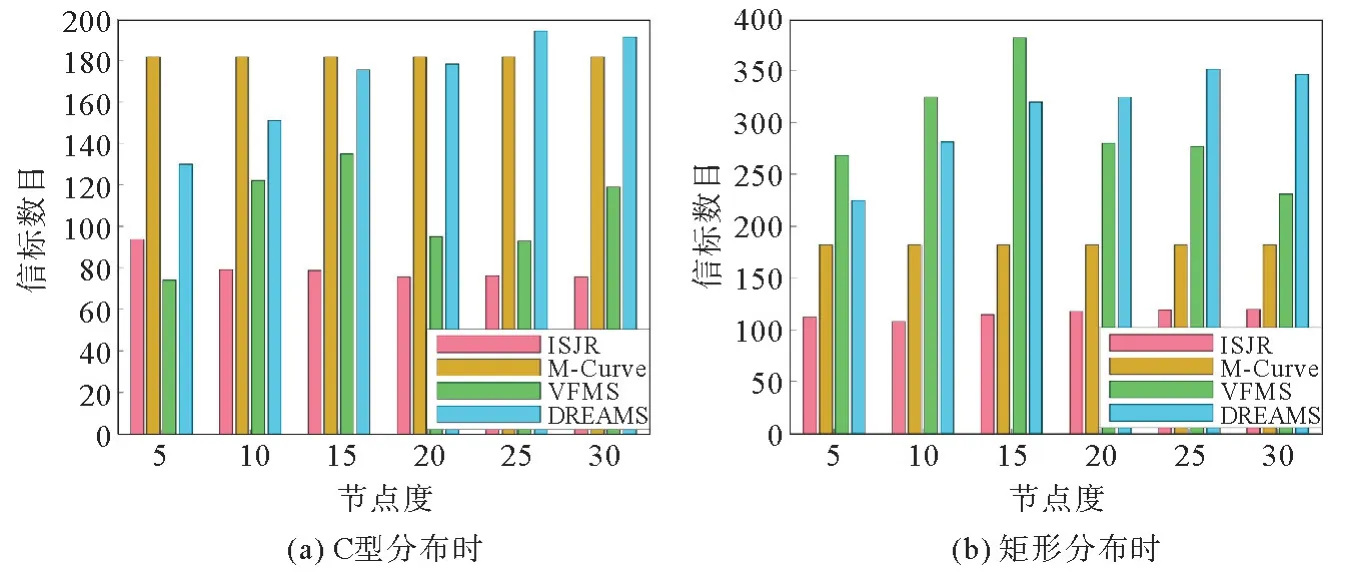
图6 C型与矩形分布时不同节点度下的信标数目Fig. 6 Number of beacons under C-type and rectangle distribution
4 结语
提出了一种新的锚节点路径规划算法用于节点定位。首先设计了锚节点与待定位节点间的通信过程,并分析了通信负载。在定位过程中,锚节点每次前进的方向都是基于局部邻居信息实时确定的,而对于某个局部区域,算法采用类菱形轨迹或正六边形轨迹进行覆盖,这使得一个局部区域中,大部分节点可以被定位,这样尽可能地避免重复访问同一区域。同时引入了边缘点和探索点两种数据结构,避免了DFT 的回溯,也提高了定位率。本工作的路径方案是一个动态、静态路径相结合的方案:锚节点动态的从一个子区域移动到另一个子区域,这样可以高效避开空白区域;在子区域内部的静态路径(菱形轨迹、六边形轨迹)提升了算法的稳定性。在未来的工作中,将考虑在实际环境中验证本工作的算法。
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
铁道通信信号(2018年3期)2018-04-19 02:32:56
通信产业报(2016年44期)2017-03-13 08:41:45
长春理工大学学报(自然科学版)(2015年4期)2015-12-07 06:57:06
水道港口(2015年1期)2015-02-06 01:25:45
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
电视技术(2012年12期)2012-06-26 09:51:46
雕塑(1999年2期)1999-06-28 05:01:42
