
基于改进SSD卷积神经网络的苹果定位与分级方法
2023-06-20 04:51:48张立杰周舒骅张延强陈广毅
农业机械学报 2023年6期
张立杰 周舒骅 李 娜 张延强 陈广毅 高 笑
(河北农业大学机电工程学院, 保定 071001)
0 引言
随着科技的发展,水果自动化分级设备日益完善,视觉识别系统作为水果自动化分级设备的一部分,其目标检测的速度与分级准确率对水果自动化分级的工作效率和工作时长有较大影响。稳定快速的水果识别分级视觉系统可以让水果自动化分级设备长时间稳定而快速的工作,压缩劳动成本,提高生产效率。高精度且高效率的苹果定位分级算法对提高农业生产力有较大的应用价值和现实意义。
目前水果视觉定位与分级方面的研究已经取得了一定的进展[1]。李先锋等[2]通过D-S证据理论进行决策级融合,对苹果形状和颜色进行分级,分级正确率达93.75%。夏卿等[3]提出基于粒子群优化 (Particle swarm optimization, PSO) 改进算法的最小二乘向量机 (LS-SVM) 的苹果分级方法,分级准确率达到96%。相比于常规方法,深度卷积神经网络在苹果识别领域显现出巨大的优越性[4-8],卷积神经网络由于其对目标高维特征的提取,使得对各等级苹果的快速在线识别变成可能。何进荣等[9]提出了基于多卷积神经网络融合DXNet模型的苹果外部品质分级方法,分级准确率达到97.84%。目前的目标检测与分类卷积神经网络主要分为两种,一种是基于区域预测的目标检测算法,典型的算法有RCNN[10]、Fast R-CNN[11]和Faster R-CNN[12-13],称为两步法 (Two-stage) 目标检测,核心思想是先获得建议区域然后在当前区域内进行分类。另一种方法是无区域预测的目标检测算法,典型算法有YOLO[14-15]、SSD[16],称为一步法 (One-stage) 目标检测,核心思想是用单一的卷积神经网络直接使用整幅图像来预测目标的位置及其种类。
本文提出用改进型SSD算法来实现苹果自动化高速分级与定位,在不影响精度的情况下压缩网络规模来加快检测速度[17-21],在不同的输入层条件下分别进行网络的识别实验,以验证不同输入层对检测精度的影响,在相同输入层条件下进行网络的检测实验,以检测网络的效果,并实验验证实时性。
1 目标识别分级算法
1.1 识别分级对象分析
实验所用苹果均为产自陕西省洛川市的红富士苹果,图像采集使用苹果自动化分级设备中的视觉采集装置,其具有LED补光灯,通过ZED双目立体相机采集苹果顶部的RGB图像与深度图像。根据表1中的各项指标将苹果分为特等果、一等果、二等果、等外果4个等级,分别采集人工分级后苹果顶部的RGB图像与其对应的深度图像。

表1 苹果等级分级标准Tab.1 Apple classification standard
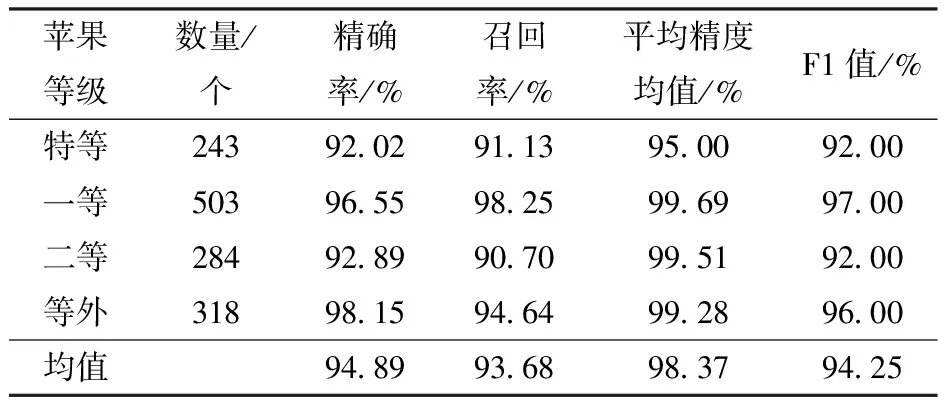
表2 基于改进型SSD的苹果定位分级结果Tab.2 Apple positioning and grading results based on improved SSD
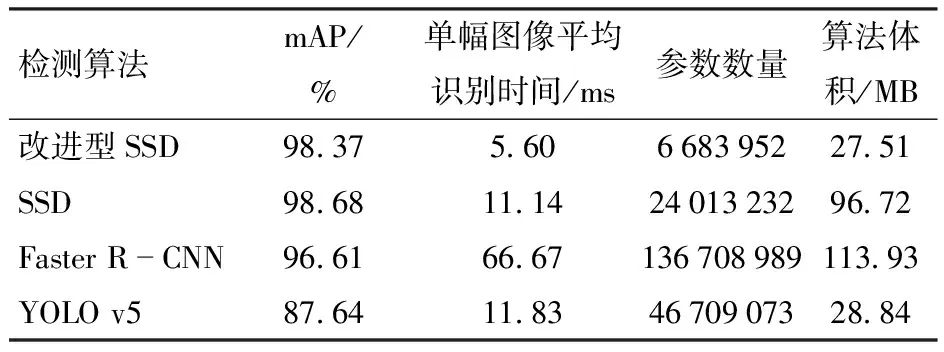
表3 不同目标检测网络识别性能对比Tab.3 Performance comparison of various target detection networks
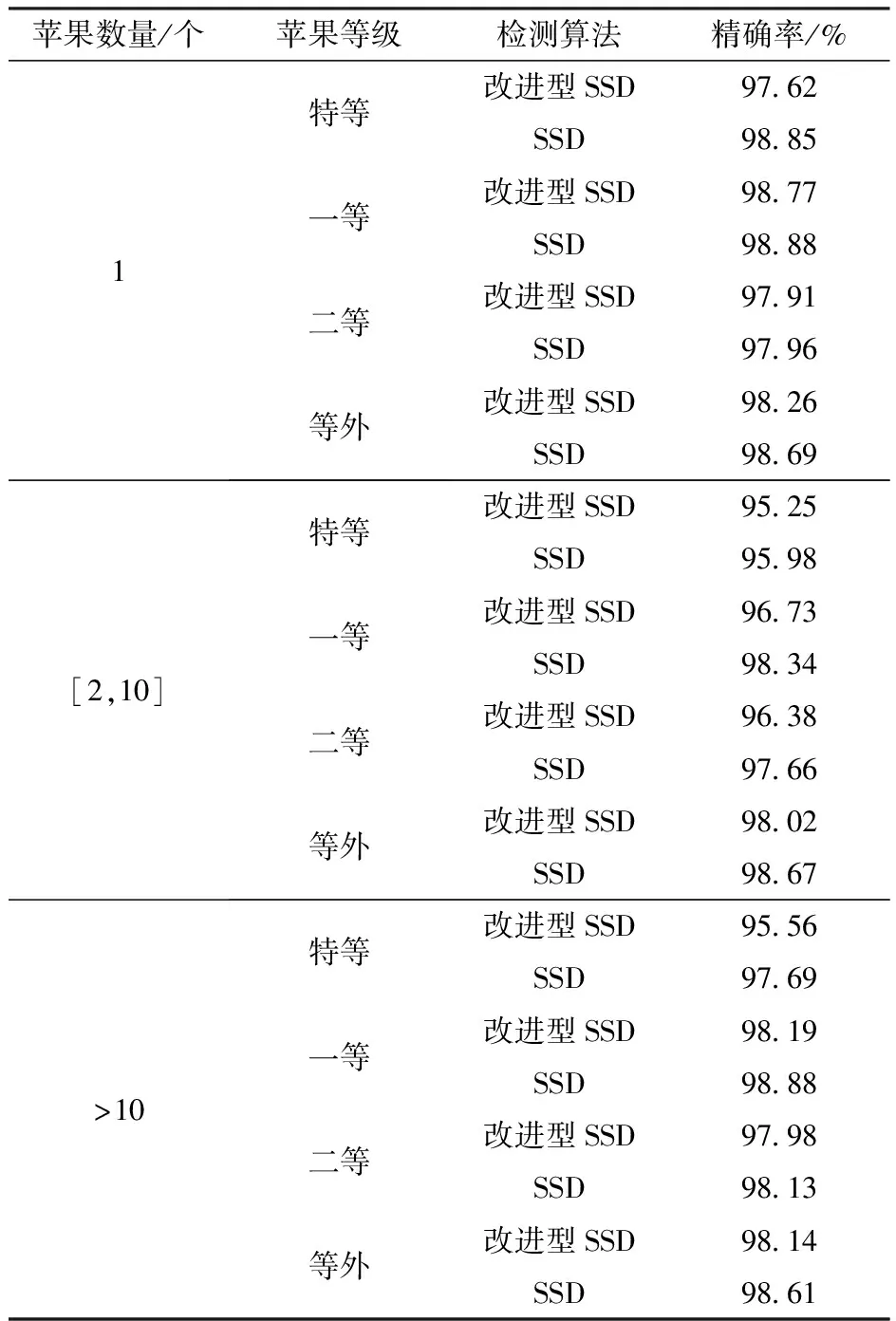
表4 不同果实数目条件下各等级苹果分级精确率Tab.4 Classification accuracy of apples of different grades under different fruit numbers
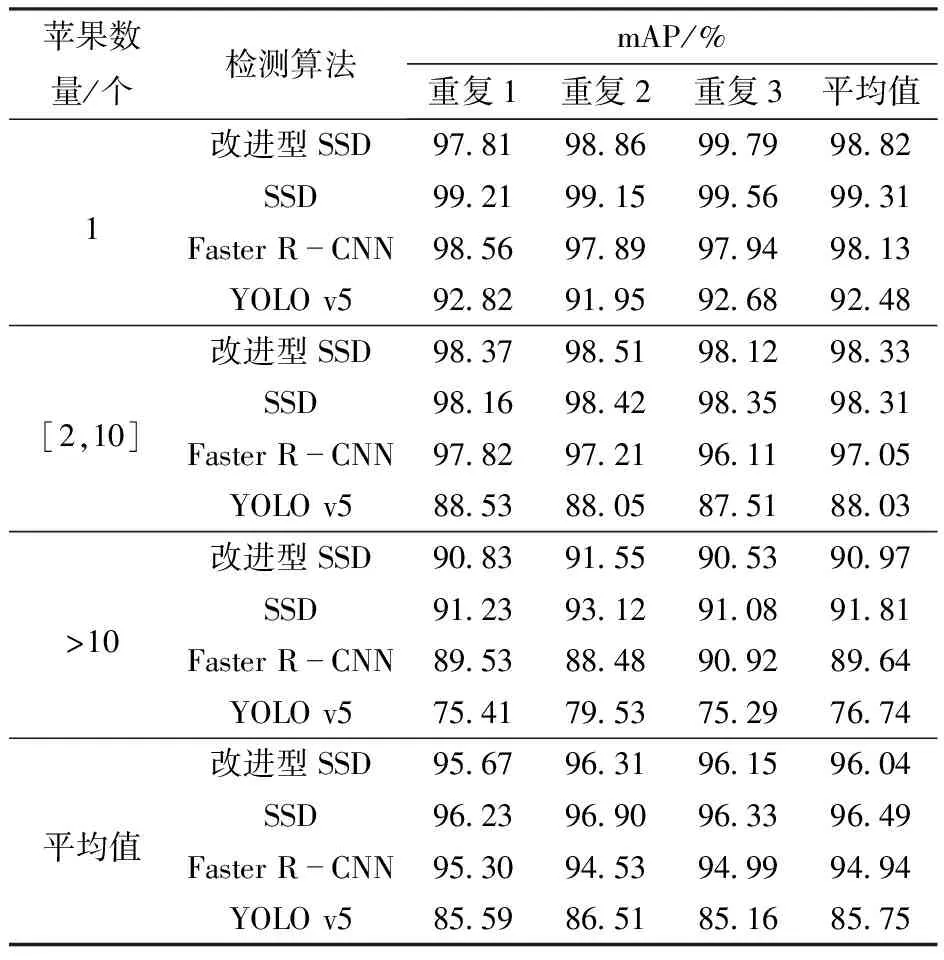
表5 4种算法对不同数量苹果图像的实验结果Tab.5 Experimental results of four algorithms for images with different numbers of apples
4种等级苹果顶部的RGB图像与深度图像如图1所示,苹果均顶部朝上,并随机地分布在传送带上,RGB图像中苹果的形状特征清晰,并与绿色的传送带形成鲜明对比,深度图像中苹果表面的深度信息完整,与传送带形成明显的距离差。

图1 4种等级苹果的RGB图像与深度图像Fig.1 Four levels of apple’s RGB image and depth image
如果仅使用苹果顶部的RGB图像对苹果进行分级,只能通过苹果的果径特征对苹果进行分类。为了对苹果的果形特征进行分级,一般需要同时采集苹果的侧面RGB图像获取苹果纵径来计算果形系数,对于这种随机分布在传送带上的苹果,无法对其侧面图像进行获取,因此无法对其果径与果形进行综合分级操作。
因此本文考虑用RGB图像与深度图像进行特征融合后的图像,通过卷积神经网络来提取苹果特征,采用端到端的整体训练让神经网络自适应地学习不同等级苹果的特征,实现对随机分布在传送带上苹果的识别和分级。
1.2 SSD算法
SSD算法是目前为止最先进的目标检测方案之一,它能够在一幅图像中同时检测和分类对象。
1.2.1基于SSD算法的苹果识别分级
本文提出的基于改进型SSD算法的苹果定位与分级方法能够定位并分级视频中的苹果并返回其坐标与对应等级。不同于区域预测的目标检测算法 (Faster R-CNN),SSD算法通过单个卷积神经网络检测整个图像回归目标的类别和位置,SSD算法采用CNN直接来进行检测,而不是像YOLO那样在全连接层之后进行检测。为让卷积神经网络遍历整幅图像后能够得到固定格式的预测尺寸,首先将图像调整为固定尺寸300像素×300像素,再分成6种不同尺寸的网格;然后在这些网格上面的每一个点构造6个不同尺度的默认框 (Default boxes),分别进行检测和分类,生成多个初步符合条件的默认框;最后,将不同尺寸网格获得的默认框结合起来,经过非极大抑制 (Non-maximum suppression, NMS) 方法过滤掉一部分重叠或者不正确的默认框,生成最终检测结果,具体包含5个预测参数:代表目标坐标x、y,目标外包矩形的宽度w和高度h,用来通过阈值对预测结果进行取舍的置信度。
1.2.2神经网络改进设计
原SSD算法卷积层主要由VGG-Base、Extra-Layers、Pred-Layers 3部分组成。VGG-Base作为基础框架用来提取图像的特征,Extra-Layers对VGG的feature做进一步处理,增加算法对图像的感受野,使得Extra-Layers得到的特征图承载更多抽象信息。待预测的特征图由6种特征图组成,最终通过Pred-Layer得到6种特征图预测框的坐标、置信度、类别信息。为了提高算法的检测效率,运用一种深度可分离卷积块替代VGG-Base中的标准卷积以减小算法数据量和算法检测所用时间。同时本文对苹果的分级条件是苹果的果径和果形这两个因素,并且仅通过苹果的顶部图像进行分级,需要引入与苹果纵径相关的图像信息,所以对输入层进行修改,同时输入RGB图像与深度图像。深度图像与RGB图像通道融合,将RGB图像的3个通道进行分离并去除对目标检测影响最小的通道,使用深度图代替去除的通道将融合后的三通道图像作为输入层输入网络进行检测[22],通道融合过程如图2所示。融合后的图像包含2个颜色通道和1个深度通道,其中深度通道用于引入深度信息实现对纵径的预测,由于ZED双目立体相机与传送带之间的距离是固定的,所以深度图中可以通过苹果顶部深度特征来预测苹果纵径。而结合保留的GB两个通道所具备的颜色与果径特征可以通过卷积神经网络对苹果的位置与等级进行综合预测。
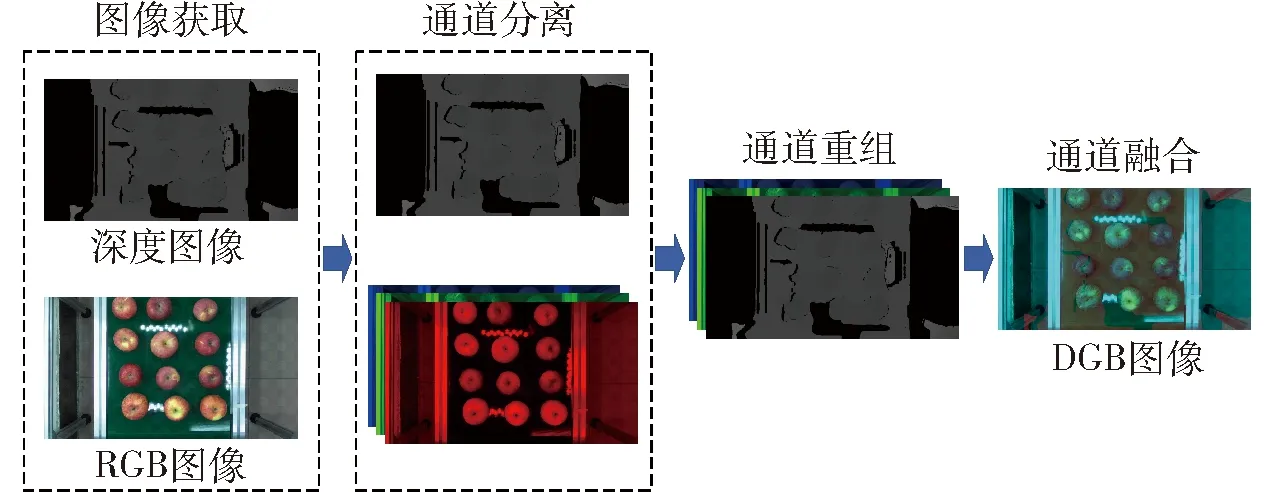
图2 输入层信息融合过程示意图Fig.2 Schematic of input layer information fusion process
本文设计的神经网络使用1层卷积核为3×3、步长为2的标准卷积对输入层的图像进行初步特征提取,输出为150×150×64,继续用13层深度可分离卷积块对图像特征进行提取,最后输出为19×19×1 024,深度可分离卷积块的结构如图3所示。首先,逐通道卷积(Depthwise convolution) 分别对每个输入通道进行3×3卷积,并对其进行归一化,使用ReLU函数进行激活。然后,逐点卷积(Pointwise convolution) 进行1×1卷积,以调整输出通道数,使深度可分离卷积块与标准卷积具有相同的输出维度,同样进行归一化并使用ReLU函数进行激活[23-24]。接着使用4层标准卷积继续进行特征提取,最后输出张量为1×1×16。分别将输出张量为38×38×256、19×19×1 024、10×10×512、5×5×256、3×3×256、1×1×256的6个特征层上的每个像素映射到输入图像上产生若干个默认框,然后对每个默认框进行分类和回归,该分类和回归操作是通过3×3×n×(classes+4)的卷积操作完成的。其中n代表6个特征层上每个像素生成的默认框数量,在大小为38×38、3×3、1×1的特征层上数量为4,其余3个特征层上数量为6;classes为类别数量,本文设置为4。对每个默认框逐级分类和回归后进行非极大抑制操作,即得出目标检测结果。具体结构如图4所示。
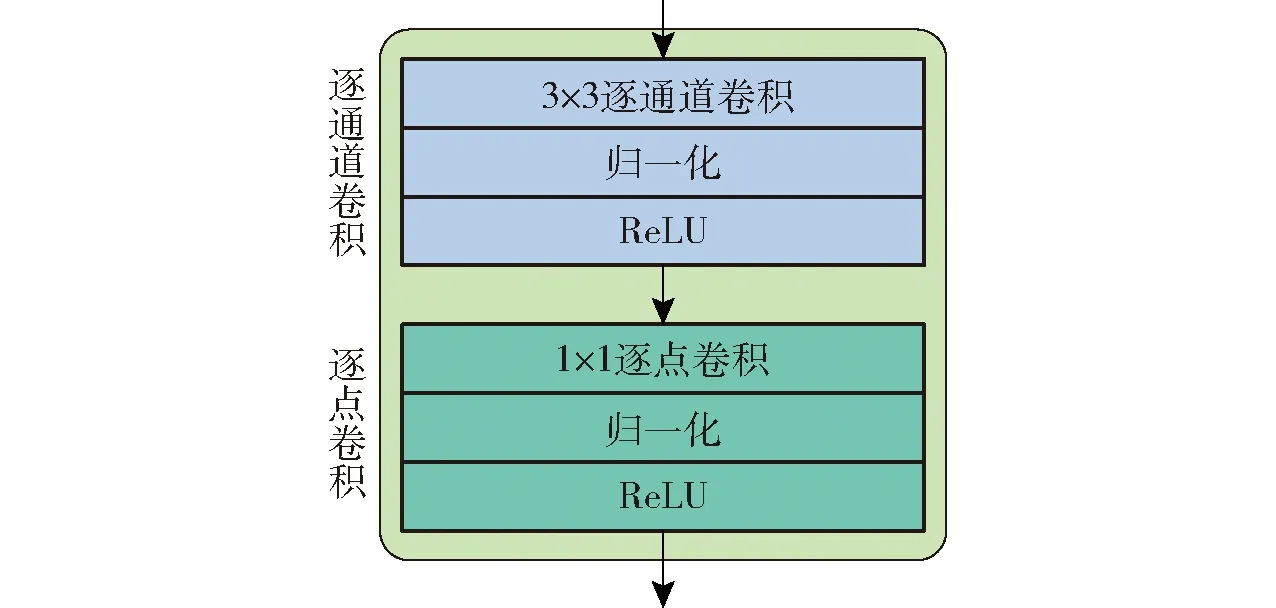
图3 深度可分离卷积块Fig.3 Depthwise separable convolution
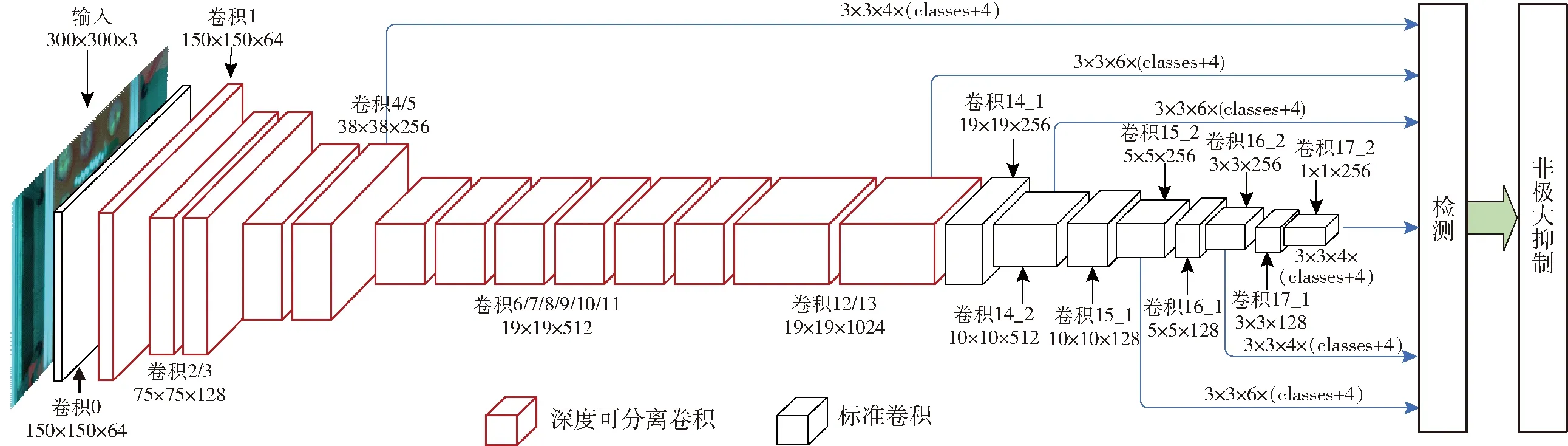
图4 算法框架图Fig.4 Algorithm frame diagram

表6 4种算法对使用不同硬件的检测速度Tab.6 Four algorithms for detection speed by using different hardwares
1.2.3SSD算法损失函数
SSD算法的损失函数包含两部分,分别为对目标位置进行预测的位置误差(Localization loss, loc)与对目标分类进行预测的置信度误差(Confidence loss, conf)的加权和,分别采用Smooth loss和Softmax loss进行计算,总的系统损失计算式为
(1)
式中r——预测框与真实框的匹配结果,如果匹配则设为1,不匹配设为0
c——Softmax函数对每一个类别的置信度
l——预测标签框
g——实际标签框
N——默认框数量
Lconf、Lloc——类别置信损失函数和位置损失函数
α——加权系数,设置分类损失和位置损失的比例
损失函数会遍历所有默认框,如果默认框与真实框的标签匹配,就对损失函数进行计算,否则损失函数值为0。
1.2.4预测过程
预测过程是对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度,并滤除属于背景的预测框。然后根据置信度阈值过滤掉阈值较低的预测框。对留下的预测框进行解码,根据默认框得到其真实的位置参数。最后进行NMS,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果。
1.3 苹果分级设备
分级设备如图5所示,苹果是顶部朝上并随机排列的,通过传送带送入分级设备然后进行分级。在实际应用中设备运行是按照以下过程:将苹果顶部朝上随机放在传送带上→输送苹果进入分级框→ZED双目立体相机图像采集→改进型SSD网络识别与分级→Delta机器人分拣。

图5 系统的硬件结构Fig.5 Hardware structure of system1.传送带 2.苹果 3.视觉采集箱 4.ZED双目立体相机 5.Delta机器人 6.工作站
2 算法训练与调整
采集得到的苹果图像为2 624幅,其中特等果图像480幅,一等果图像1 024幅,二等果图像558幅,等外果图像562幅。其中2 362幅图像用来训练算法,262幅图像用来验证算法,比例约为9∶1。
2.1 实验运行平台
本文中所有的训练和测试均在同一台工作站进行,工作站的主要配置为Intel Core (TM) i7-11700k CPU@3.6 GHz、8 GB的GPU GeForce RTX 3060 Ti和16 GB的运行内存。所有程序均是由Python语言编写并调用CUDA、Cudnn、OpenCV、Tensorflow 1.15、Keras 2.3.1库并在Ubuntu 20.04系统下运行,训练和测试算法时分别单独使用CPU和GPU。
训练时采用16个样本作为一个处理单元,每次更新权值时用BN (Batch normalization) 进行正则化,并且在每层中加入丢弃层 (Dropout),以保持每层和提取特征的相互独立,其丢弃比例为0.5,动量 (Momentum) 设置为0.937,权值衰减 (Decay) 设置为5×10-4,优化器 (Optimizer) 选用Adam,最大学习率 (Max learning rate) 设置为 0.002,最小学习率 (Min learning rate) 设置为2×10-5,学习率衰减遵循余弦退火 (Cosine annealing),实际计算式为
(2)
式中ηt——学习率
i——训练运行次数
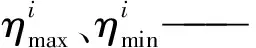
Tcur——当前迭代周期(Epoch)数
Ti——迭代周期总数
2.2 数据集预处理
选取经人工分级的不同等级苹果图像计算每个像素点对应的深度值获取深度图,分辨率与RGB图像相同。将RGB图像的GB通道提取出来并将深度图像与其重新组合得到DGB图像作为训练图像。为了更精准地对DGB图像中的苹果进行标注,首先使用LabelImg对RGB图像中的苹果位置进行准确标注,标注信息采用PASCAL VOC数据集的格式进行保存,其中包含目标苹果的类别信息和外包边框。然后将RGB图像替换为DGB图像,其中DGB图像的苹果位置和等级与RGB图像中的完全相同。接着进行归一化处理,将目标的实际数据除以图像的宽度和高度,得到的数据都在0~1的范围之内,使得训练时能够更快地读取数据,并且能够训练不同尺寸的图像,其具体格式为5个参数作一组数据,分别包含index(类别的序列),x(目标中心的x坐标),y(目标中心的y坐标),w(目标的宽),h(目标的高)。各参数的计算公式为
(3)
式中xmax、ymax——边框右下角坐标值
xmin、ymin——边框左上角坐标值
wi、hi——图像宽和高
深度学习需要大量的数据进行训练,2 600幅图像数据量较少。训练前对数据进行数据增强来增加数据,其中旋转角度的变化范围从45°到315°,并对其进行镜像,最终生成了11 200幅图像以供训练使用。
2.3 算法测试与评估
最终算法一共训练700个迭代周期(Epoch),每个迭代周期进行467次训练 (Iteration),训练共使用了7 840 000幅图像(在11 200幅图像中随机抽取并重复使用),其训练的损失值 (Loss) 变化图如图6所示,可以看出算法在前50个迭代周期中迅速拟合,Loss值快速变小,在200个迭代周期后逐渐稳定,只有稍许振荡。
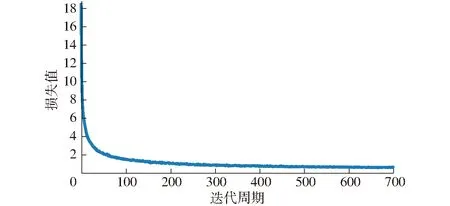
图6 网络训练损失曲线Fig.6 Network training loss curve
在训练中,平均每隔10个迭代周期输出一次权值 (Weights),算法性能并不是迭代的次数越多越好,过多的训练可能导致过拟合,所以需要对训练出来的权值进行测试和评估。
本文采用客观评价标准来评估苹果识别与分级系统,使用精确率 (Precision)、召回率 (Recall) 和平均精度均值 (Mean average precision, mAP) 来评估算法。并且为算法找出合适的阈值 (Threshold),通过算法预测的置信度来选择合适的目标。
首先找到mAP最高的权值文件,以筛选出整体性能足够高的权值。然后在单独找出的权值中不断地调整阈值,衡量精确率、召回率和平均精度,使之能按照自身需求去检测当前环境下的苹果。
如果阈值选择不合适下,会出现如图7所示结果,当阈值过低时会出现误识别与重复识别,当阈值过高时会漏识别。

图7 阈值对检测的影响Fig.7 Impact of threshold on detection
3 实验结果与分析
算法训练好后需要对其性能进行评估以找到最优权值,用mAP评估算法的整体性能,然后在mAP最高的权值中通过对比不同阈值下精确率、召回率和mAP的变化选择最优阈值。之后对不同输入层下的苹果识别与分级效果进行实验,并与其他算法进行比较。
3.1 最优权值寻找
在本文的实验中,对4种不同的输入层组合分别进行训练,每种输入层训练迭代700个迭代周期,每10个迭代周期输出一次权值,所以每种输入层得到70个权值,需要在这70个权值中找出一个mAP最高的输入层组合。计算出来的实验结果如图8所示。
从图8中可以看出,当迭代周期数分别达到400、500、400、300时输入层分别为RGB、RGD、DGB、RDB的算法mAP已经稳定,不再发生变化,其中输入层组合为DGB时mAP总体大于其它输入层组合,mAP最大为98.37%,此为本文选用的权值。
3.2 类别阈值选择
算法预测出目标的置信度后需要使用预设的阈值对其进行筛选。通过调整置信度阈值,比较衡量算法在不同阈值下对测试集中4个等级苹果识别与分级的精确率、召回率、F1值和mAP的变化,结合自动化分级设备对苹果进行分级的实际需求,确定算法的最佳阈值。经实验测试,不同置信度阈值下算法的精确率、召回率、F1值、mAP曲线如图9所示。
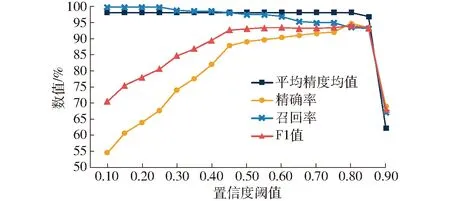
图9 不同阈值下参数的变化Fig.9 Changes in various parameters at different thresholds
对于面向自动化分级设备的苹果等级,需要对传送带识别区内的苹果进行实时识别,同时对识别到的苹果进行分级,因而在算法识别的精确率和召回率之间需要优先考虑精确率。另一方面,在选择阈值时需要辅助参考用于评估算法综合性能的指标F1值和mAP,其能同时兼顾精确率和召回率。
由图9可知,当置信度小于0.8时,识别精确率较低,不足90%;当置信度阈值高于0.8时,识别算法的mAP降低至90%以下;因而综合考虑算法的识别精确率与mAP,当置信度为0.8时,算法的性能表现最好,此时算法的精确率、召回率、F1值、mAP分别为94.89%、93.68%、94.28%和98.37%。
3.3 实际效果检验
3.3.1苹果等级识别结果与分析
为了验证所设计的苹果等级识别算法的性能,对该算法在测试集图像上的识别结果进行进一步分析。测试集262幅图像中共有1 348个苹果目标,其中特等果、一等果、二等果、等外果的数量分别为243、503、284、318个。
算法的具体识别结果如表2所示,可以看出,针对特等、一等、二等、等外果,本文所提出的算法对其识别的精确率及F1值分别为95.00%、99.69%、99.51%、99.28%及92.00%、97.00%、92.00%、96.00%,总体的识别精确率、召回率、mAP(4个等级苹果的平均精度)及F1值均在90%以上,分别为94.89%、93.68%、98.37%、94.25%,满足苹果识别分级的精度要求。
3.3.2不同目标检测算法识别结果对比
为了进一步分析所提出的苹果定位与分级算法的性能,将改进型SSD算法与原SSD、Faster R-CNN、YOLO v5算法在测试集图像上进行了识别结果对比。以mAP、平均识别耗时等作为评价指标,各算法的识别结果、算法体积(存储空间占用量)及参数数量如表3所示。
由表3可以看出,本文提出的改进型SSD算法的mAP仅比原SSD算法降低0.31个百分点,与Faster R-CNN、YOLO v5[25-28]算法相比分别高1.76、10.73个百分点。针对算法的识别耗时,本文提出的改进型SSD算法在测试集上单幅图像平均识别时间可达5.60 ms(177.5 f/s),能够满足实时高速识别的要求,比原SSD算法检测耗时减少49.73%,与Faster R-CNN、YOLO v5算法相比分别减少91.60%、52.66%。另一方面还可以看出,本文所提出算法的存储空间占用量为27.51 MB,为原SSD算法的43.64%,说明所提出的网络在保证精度的同时有效地实现了网络的轻量化。
3.3.3不同果实数目下各等级苹果的分级精确率对比实验
因为在实际分级过程中苹果数量在不断变化,为验证改进前后在不同果实数目条件下不同等级苹果的分级情况,因此设置改进前后网络对不同果实数目条件下各等级苹果的分级精确率进行对比实验,分别对4个等级的苹果设置单个苹果、多个苹果和密集苹果,对比改进前后的识别精确率。
实验中测试集共有300幅图像,其中根据图像所包含苹果数量为单个、2~10个以及10个以上3种,每种数量的图像均包含4种等级的苹果图像各25幅,每幅图像中只包含一个等级的苹果,将不同数目的苹果分别使用改进前后的SSD算法进行识别,对比不同果实数目下各等级苹果的分级精确率,其最终结果如表4所示。
从表4可以看出,不同数目果实条件下,各等级苹果的分级精确率均高于95%,且改进后的算法与原SSD算法相比,精确率仅有略微降低,最大相差仅2.13个百分点,完全满足苹果分级要求。
3.3.4随机分布条件下不同果实数目的对比实验
在自动化分级设备运行过程中,随着苹果的随机上料,进入视觉采集区域的苹果数量与等级会随机变化,数目较多时识别难度将会增大。因此设置不同数目下随机分布苹果检测的对比实验,分别分单个苹果、多个苹果和密集苹果,对比4种算法在不同数目苹果下随机分布苹果的检测性能,检测效果如图10所示。

图10 4种算法对不同数量苹果的检测效果Fig.10 Detection effect of four algorithms on different numbers of apples
实验测试集共320幅图像,包含2 030个苹果,按照果实数量分为3类,其中单个苹果80幅图像包含80个苹果,多个苹果186幅图像,包含1 302个苹果,密集苹果54幅图像包含648个苹果。每类随机抽取30幅图像作为实验测试集,用4种不同的算法进行检测,计算出mAP。重复以上步骤3次,取平均值,最后将3类结果取平均得到综合效果,其最终结果如表5所示。
从表5可以看出,改进型SSD算法mAP仅比原SSD算法降低0.09个百分点,且均高于其余2个算法,苹果数量越少,mAP越高,数量由1增加到10以下时mAP下降不多。但是遇到密集苹果时,mAP降低近10个百分点,因为密集苹果的图像中苹果尺寸不一,导致有些苹果没有被识别,同时因为卷积神经网络本身固有的特性,不断地卷积会在深层网络中丢失高分辨率时小目标的特征,而Faster R-CNN是基于区域推荐的算法,在RPN网络输出矩形候选区域时就已丢失了小目标区域,进行分类并输出预测结果时自然不会出现小苹果。但是改进型SSD在浅层网络中提取出特征用于定位与分类,并输出更小的栅格预测结果,降低了深层卷积对小目标的影响,因此在密集苹果上mAP高出Faster R-CNN 1.33个百分点。而YOLO v5虽定位准确度很高,但在遇到多个苹果和密集苹果时分类准确率很低,会错误识别苹果的等级。从综合结果来看,改进型SSD算法能够胜任不同数目苹果的检测。
3.4 实际检测时间测试
为了验证改进型SSD在检测速度上的优势,对4种算法分别在使用GPU与CPU的情况下的检测速度进行测试,统计结果如表6所示。
由于4种算法在做卷积运算前需要对图像进行缩放到固定尺寸,所以不同分辨率图像在本文算法下检测时间的差异只与缩放过程所用的时间有关,其余流程并没有区别。本文实验测试用的图像尺寸均为1 920像素×1 080像素,考虑到苹果识别与分级系统是搭载在苹果分级设备的工作站中,有的工作站只有CPU,为了减少硬件成本,需要在单CPU的情况下运行,所以分别在GPU和CPU下进行了测试,检测的精度没有变化,CPU检测时长较GPU长。
在GPU下算法检测200幅图像用时1.18 s,在CPU下检测200幅图像耗时3.19 s,即为175.17 f/s和62.64 f/s,每幅图像平均检测时间为5.71 ms和15.96 ms,与原SSD算法相比检测用时分别减少39.45%和78.28%。该检测速度能够满足自动化分级设备的实时且高速分拣需求。
4 结论
(1)针对苹果果径与果形自动化分级,提出了基于改进型SSD算法的苹果识别与分级方法。实验表明该算法的检测精度高、速度快,选用的网络在真实环境下进行检测,在GPU和CPU下每幅图像的平均检测时间分别达到5.71 ms和15.96 ms,即检测视频的帧率分别达到175.17 f/s和62.64 f/s,召回率、精确率、mAP和F1值分别达到93.68%、94.89%、98.37%和94.25%。
(2)针对自动化分级设备上高速识别环境,提出用改进型SSD网络定位并分级苹果,与原SSD算法相比mAP仅下降0.31个百分点,检测用时减少49.73%,算法体积压缩至原SSD算法的43.64%。
(3)对比了在不同输入层组合下的检测结果,当使用DGB图像组合作为输入层时,其mAP总体高于其他3种输入层组合,且仅使用带有颜色信息的图像作为输入层时,其mAP明显低于引入深度信息后的输入层组合。
(4)对比了改进型SSD网络与原SSD网络在不同果实数量下,对各等级苹果的分级准确率,其分级准确率与原SSD网络相差不大,准确率均在95%以上,分级准确率最多仅比原SSD算法下降2.13个百分点,满足苹果分级要求。
(5)对比了原SSD、Faster R-CNN、YOLO v5和改进型SSD在不同苹果数目下随机分布苹果的检测结果,其mAP总体比Faster R-CNN高1.10个百分点,比YOLO v5高10.29个百分点,并且在密集苹果的图像检测中,改进型SSD的mAP比Faster R-CNN 高1.33个百分点,比YOLO v5高14.23个百分点,本文算法检测精度优势更为明显。
(6)由于深度学习需要大量的计算能力,在实际使用中还需要考虑功耗和稳定的问题,因此对比了原SSD、Faster R-CNN、YOLO v5算法和改进型SSD算法分别在使用GPU与CPU的硬件条件下的检测速度。与原SSD算法相比,本文所提出的改进算法检测用时在硬件为GPU和CPU时分别减少39.45%和78.28%。与Faster R-CNN、YOLO v5算法相比,无论是GPU还是CPU下检测用时均大幅减少,且检测精度也高于这2种算法。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
核科学与工程(2021年4期)2022-01-12 06:30:22
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
计算机应用(2018年5期)2018-07-25 07:41:26
中国医疗保险(2017年6期)2017-07-18 11:28:19
自动化学报(2017年7期)2017-04-18 13:41:02
中国卫生(2016年5期)2016-11-12 13:25:50
中国卫生(2015年10期)2015-11-10 03:14:22
中国卫生(2015年6期)2015-11-08 12:02:44
