
基于图像的自动驾驶3D目标检测综述
——基准、制约因素和误差分析
2023-06-20 10:14李熙莹叶芝桧韦世奎陈泽陈小彤田永鸿党建武付树军赵耀
中国图象图形学报 2023年6期
李熙莹,叶芝桧,韦世奎,陈泽,陈小彤,田永鸿,党建武,付树军,赵耀
1.中山大学智能工程学院,深圳 518107;2.中山大学·深圳,深圳 518107;3.广东省智能交通系统(ITS)重点实验室,深圳 518107;4.北京交通大学信息科学研究所,北京 100044;5.北京大学信息科学技术学院,北京 100871;6.兰州交通大学电子与信息工程学院,兰州 730070;7.山东大学数学学院,济南 250100
0 引言
随着高分辨率相机、激光雷达和毫米波雷达等传感器的发展,自动驾驶汽车对环境的感知能力越来越强,高度自动驾驶甚至完全自动驾驶越来越成为可能。作为环境感知的核心技术之一,基于图像的2D 目标检测技术(Redmon 等,2016;Girshick 等,2014;Girshick,2015;Ren 等,2017;Liu 等,2016;Zhou 等,2019)发展相对成熟,但其缺少对目标物体在3 维世界中位置、姿态和尺寸信息的准确估计,限制了自动驾驶汽车的感知精度和安全性。为此,3D目标检测逐渐成为工业界和学术界的研究热点,相关的数据集和评价基准(Geiger 等,2012;Caesar 等,2020;Sun 等,2020)也不断建立和完善。3D 目标检测是一种通过利用高分辨率相机、立体相机、激光雷达和毫米波雷达等传感器的一种或多种数据来预测目标3维属性信息的技术。通常,3维属性信息包括目标类别(c)、目标3 维坐标(x,y,z)、3 维尺寸(长l、宽w、高h)和姿态(俯仰角、滚动角、偏航角),可利用目标的最小外接立方体的信息来表示。由于汽车位于地平面且无翻转,只需要考虑汽车在地平面的偏航角(θ)。因此,自动驾驶的3D 目标检测本质上是关于c,x,y,z,l,w,h,θ这8 个参数的回归优化问题。当投影到鸟瞰图视角下进行3D目标检测时,该问题可以进一步简化为回归目标物体的类别和鸟瞰图视角下的3维信息(c,x,y,w,l,θ)(Novák,2017)。
在工业界,3D 目标检测可分为两类技术路线,即基于多传感器融合的技术路线和基于纯视觉的技术路线。以百度、谷歌、小马智行、华为和滴滴等厂商为代表,采用基于多传感器融合的技术路线。百度自动驾驶平台Apollo(Baidu,2022)在其Apollo1.5版本中增加了激光雷达设备,构成了一个综合GPS/IMU(global positioning system/inertial measurement unit)、高分辨率相机、激光雷达和毫米波雷达的环境感知系统,使其自动驾驶车辆对周围环境有了更高的感知能力。Apollo2.0 版本对Apollo1.5 进行升级,使车辆能够在简单的城市道路上自主驾驶。更进一步,Apollo3.5 版本已经能够实现车辆的360°感知。目前Apollo 已经升级到Apollo7.0 版本,通过搭载多传感器能够实现对复杂城市道路环境的感知与车辆行为决策。谷歌旗下Waymo 采用以激光雷达为主的多传感器融合方案,感知系统包括激光雷达、毫米波雷达、高分辨率相机和补充传感器,能够实现全时段360°监控(池娟,2021)。小马智行(Pony.ai,2022)的第3 代自动驾驶方案Pony Alpha 在感知层采用了多传感器融合的方案,感知系统包括高分辨率相机、激光雷达和毫米波雷达等传感器,并在其自研的域控制器上实现了对相机、雷达的精准耦合,实现了全天候感知车身周围360°环境的能力。华为ADS(autonomous driving solution)高阶自动驾驶全栈解决方案同样采用多传感器融合方案,感知系统包括自研的激光雷达、毫米波雷达和高分辨率相机等传感器,不同的数据间采用后融合算法获得障碍物的分布信息(WorldAuto,2022)。滴滴出行的双子星自动驾驶系统同样采用多传感器融合的方案,感知系统包括远、中、近距的激光雷达、相机、雷达和红外相机等传感器,前向视角可实现12 层传感器冗余覆盖叠加(孟醒,2021)。
以特斯拉为代表的厂商,采用纯视觉为主导的技术路线。特斯拉的完全自动驾驶(full self-drive,FSD)摒弃了昂贵的激光雷达等非视觉传感器,环绕车身构建了以可见光相机为主的感知系统,并通过多头神经网络HydraNet 构建出真实世界的3 维向量空间(Talpes等,2020)。安途AutoX在其第一代无人驾驶方案Gen1中采用纯视觉感知方案,虽然在后续几代版本中加入了激光雷达、毫米波雷达等传感器,但其始终坚持以相机为主导的多传感器感知方案(郭文佳,2021)。百度也推出了纯视觉城市道路自动驾驶闭环解决方案Apollo Lite,能够实现360°道路环境感知,为合作伙伴提供轻传感器、轻算力需求的轻量化产品解决方案,并基于该技术打造了智能领航辅助驾驶产品ANP(Apollo navigation pilot)(陈念航,2020)。丰田汽车旗下子公司Woven Planet 在其辅助驾驶和更高级别的自动驾驶项目中,统一采用纯视觉方案开发自动驾驶(李琳,2022)。
在学术界,学者们提出了很多通用的3D目标检测理论和框架(Brazil 和Liu,2019;Chen 等,2020b;Wang 等,2021b;Luo 等,2021;Liu 等,2020;Weng 和Kitani,2019;You 等,2020)。如图1 所示,有学者从输入数据来源和方法论两个维度对目前的3D 目标检测进行了层次化分类(Mao等,2022)。

图1 用于自动驾驶3D目标检测的层次结构分类法(Mao等,2022)Fig.1 A hierarchical taxonomy for 3D object detection in autonomous driving(Mao et al.,2022)
目前,多线束激光雷达和雷达系统价格高昂,限制了其在车辆上的大规模部署与应用。与激光雷达和雷达系统相比,高分辨率相机、立体相机等视觉传感器具备经济实惠和便于车载的优势。因此,基于视觉图像来感知物体的3 维信息逐渐成为研究的热点。由于物体通过相机投影到图像平面时会造成深度信息的丢失,所以从2维图像中获取3维信息是一个病态的问题,这导致基于图像的3D目标检测算法与基于激光雷达点云或多模态数据融合算法相比仍存在较大的性能差距。即便如此,许多学者和科技公司仍在此领域进行了深入研究,并取得了激励人心的结果。本文从数据集及评价基准、制约因素和误差分析3 个方面来分析和总结基于图像的自动驾驶领域3D目标检测的已有成果,并对未来的发展方向进行展望,以期帮助从业者了解该领域的发展水平和未来发展方向。
本文主要贡献如下:1)对目前基于图像的自动驾驶领域3D 目标检测算法常用的数据集和评价基准进行分析和总结,并指出需要完善之处。虽然已有多个公开数据集,并建立了诸多具有一定通用性的检测标准,但评价标准仍有改进空间。2)对制约基于图像的3D 目标检测算法性能的主要因素进行总结,并对其误差进行分析。尽管现在已经有很多通用的理论和检测框架,但是当算法落地到应用时依然存在诸如深度预测不准确、目标类别之间的差异等问题。3)从多角度对基于图像的3D 目标检测的发展方向进行展望。
1 数据集及评价基准
数据集及评价基准对于设计和评测基于图像的3D 目标检测算法至关重要。本节从数据采集设备、通用数据集构成和算法评价指标等方面进行分析和总结。一般来说,基于图像的3D目标检测算法在训练和测试评价阶段只需要包含目标类别、属性信息以及目标外接立方体等标注信息的图像数据。然而,为了更准确地从图像中检测3D 目标,一些算法在训练阶段引入2D标注信息、激光点云或深度图作为监督信号进行优化学习。因此,一些多传感器融合的数据集也可以用来训练和测试基于图像的3D目标检测算法。事实上,主流的数据集大多包含多个传感器的数据。
1.1 数据采集设备
由于图像采集设备的精度对感知能力影响较大,所以自动驾驶系统对车载传感器有较为严苛的要求。以车载相机为例,自动驾驶系统对相机数量、分辨率、视距范围、视场角、自身尺寸和复杂工况下的稳定性等有严格的规范。依据车规级约束,车载相机需要在高低温、湿热、强微光和振动等复杂工况下保持工作稳定。
特斯拉的Autopilot 系统从HW2.0 开始,设计搭载了8 个相机、12 个远程超声波传感器和1 个前置毫米波雷达,并在后续升级版本保持这一设计。在该系统中,后置相机采用了豪威科技OV10635 型80 万像素CMOS 相机,其余相机则采用安森美半导体公司的120 万像素CMOS 相机,整个系统最远有效视距为250 m、单个相机的最大视场角120°。Autopilot HW2.0 处理器搭载了Nvidia PG418 MXM模块,包含一个GP106 GPU 和4 GB 的GDDR5 内存,可实现L4 级别的自动驾驶(程增木,2022)。理想ONE 使用了全世界第一个量产车载 800 万像素相机,同时搭载4 颗200 万像素环视相机、12 颗超声波雷达、4颗毫米波雷达以及1颗前向毫米波雷达。其中,前置相机的水平视场达到120°,视距达200 m,并可以持续跟踪目标。安途(AutoX,2021)第5 代系统采用了28 个车规级800 万像素相机,总像素达到2.2亿像素/帧。高分辨率的相机带来了对系统算力和算法的更高要求(刘岸泽,2022)。安途第5 代系统采纳英特尔32 核双CPU 架构,主频率3.4 GHz。在车规级GPU 方面,XCU 域控制器算力更是达到2 200 TOPS(Tera operations per second)。表1 列出了一些自动驾驶数据采集平台常用设备及性能。
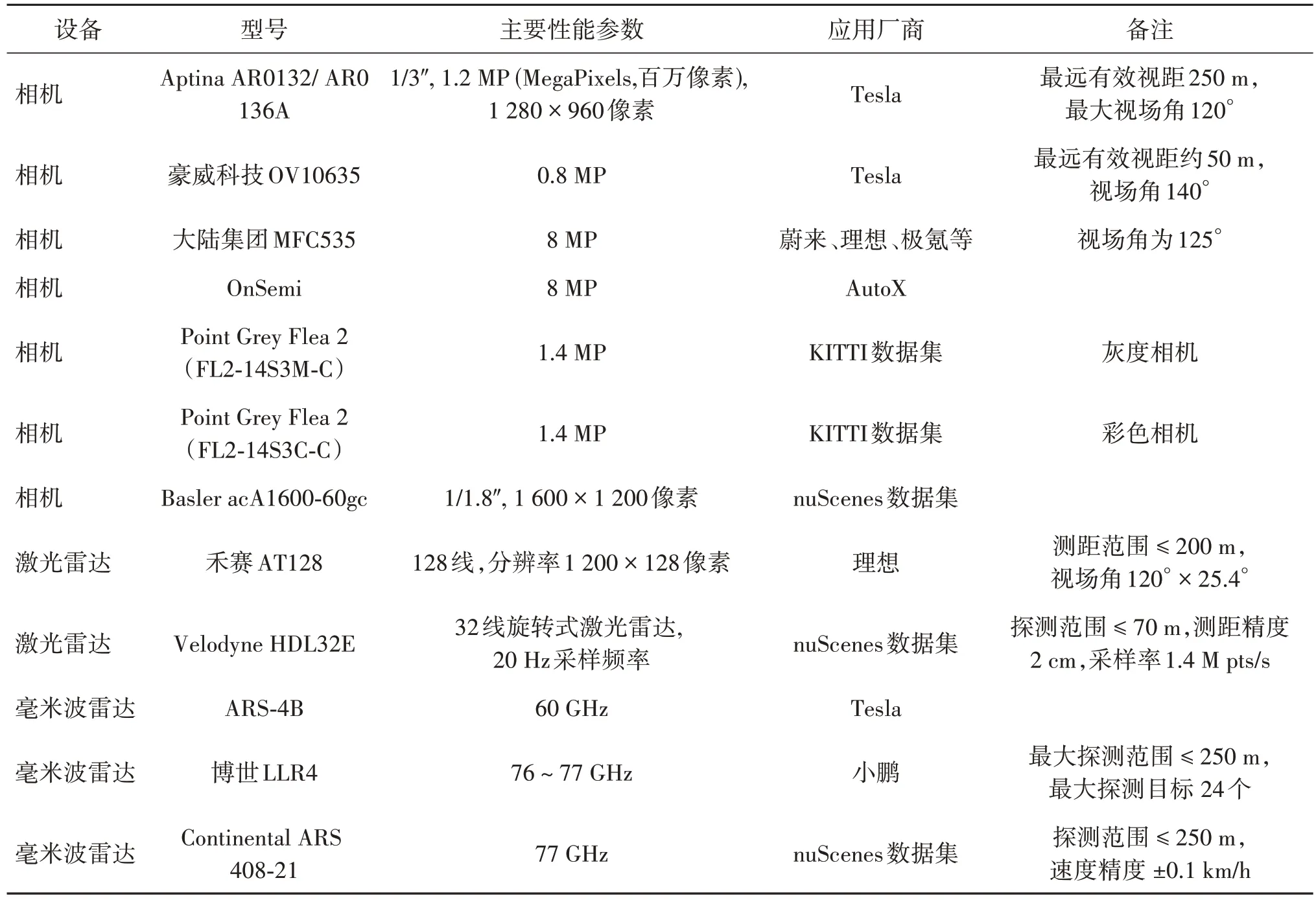
表1 一些数据采集设备信息Table 1 Information on data collection equipment
1.2 通用数据集
1.2.1 KITTI 3D数据集
KITTI(Karlsruhe Institute of Technolgoy and Toyota Technological Institute at Chicago)数据集(Geiger 等,2012)是自动驾驶领域最受欢迎的数据集之一,由装载了高分辨率的彩色相机和灰度相机、激光雷达等传感器的采集系统收集。根据标注信息不同,分为2D 目标检测数据集和3D 目标检测数据集(即KITTI 3D)等(Liao 等,2023)。KITTI 3D 数据集是最受欢迎的3D目标检测数据集之一,具体的数据精度如表2 所示,其中,KITTI 官网图像标称分辨率为1 382×512 像素,实际下载图像分辨率不等,以1 242×375 像素最多。采集设备参数如表3 所示。KITTI 数据集的收集场景包括中等城市、农村地区和高速公路,其目标检测数据集包含7 481幅训练图像和7 518 幅测试图像以及对应的点云数据,共有80 256 个标记物体。KITTI 数据集的目标类别包括小汽车、面包车、卡车、行人、坐着的人、骑行者和有轨电车共7 类,常用于3D 目标检测的类别为小汽车(car)、行人(pedestrian)和骑行者(cyclist)3 类。KITTI 数据集根据边界框(bounding box)高度、遮挡和截断程度指标将标注目标划分为简单、中等和困难3 个难度级别。KITTI 3D 数据集的标注信息如表4 所示。图2 给出了KITTI 3D 数据集的采集设备坐标系定义及标注信息中目标的观测角Alpha(红色)和航向角Rotation_y(蓝色)的定义示意图。KITTI数据集的测试集不提供具体标注信息,算法性能测试需要上传到官方网页进行。为了在本地进行模型性能测试,有学者将KITTI 3D数据集的训练集划分为训练集和验证集,常用的划分标准是将数据集的7 481幅训练集图像划分为3 712 幅训练图像和3 769 幅验证图像(Chen等,2015),或者划分为3 682幅训练图像和3 799幅验证图像(Xiang等,2017)。

表2 KITTI 3D数据集的数据精度Table 2 Data accuracy of KITTI 3D dataset
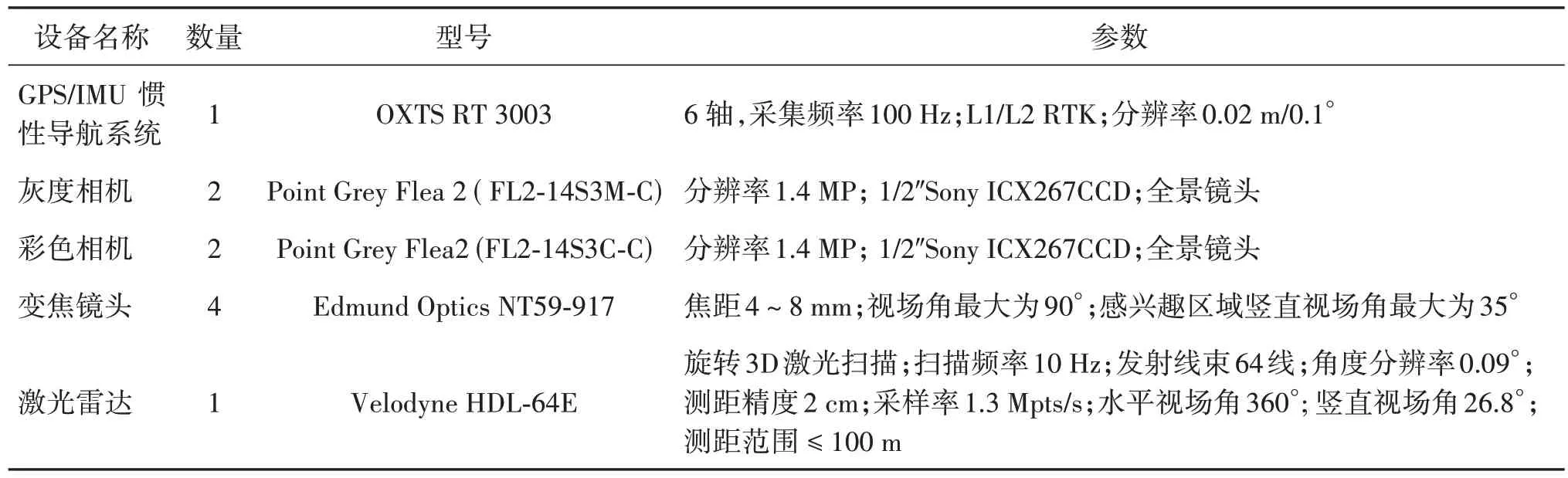
表3 KITTI数据集采集设备信息Table 3 Sensors used to setup KITTI dataset

表4 KITTI 3D数据集标注信息Table 4 Annotation information in KITTI 3D dataset

图2 KITTI数据集坐标系、目标的观测角和航向角定义Fig.2 Definitions of coordinate system,alpha and rotation_y of KITTI dataset((a)equipment coordinate system of KITTI dataset(Geiger et al.,2022);(b)definitions of alpha and rotation_y)
1.2.2 nuScenes数据集
nuScenes 数据集(nuTonomy scenes)(Caesar 等,2020)发表于2019 年,也是自动驾驶领域比较常用的数据集之一。数据集采集系统包含1 个激光雷达、5 个雷达、6 个彩色相机和1 个惯性导航系统,提供360°的扫描结果,主要的数据精度如表5 所示,各采集设备参数如表6 所示。nuScenes 数据集包含1 000 个驾驶场景,每个场景的采集时间为20 s,包含各种驾驶行为、交通状况和意外行为。数据集收集地点为美国波士顿的海港(Seaport)和南波士顿(South Boston)地区、新加坡的纬壹科技城(One North)、女王镇(Queenstown)和荷兰村(Holland Village)地区。这两个城市交通密集,驾驶环境复杂,车辆类型、植被、道路标志和交通规则(分属左右手交通)都各不相同。数据集收集场景涵盖不同的地点、不同的时间(白天和黑夜)和不同的天气条件(晴天、雨天和多云),对研究算法的通用性很有帮助。数据集包含约140 万帧图像、39 万帧激光雷达扫描帧、140 万帧雷达扫描帧,标注了4 万个关键帧中的140 万个目标边界框,标注数据量约为KITTI 数据集的7 倍。nuScenes 数据集是以2 Hz 采样率对图像、激光雷达和雷达数据抽取关键帧进行标注,采用了层次分类法,最底层共定义了小汽车(vehicle.car)、成年人(human.pedestrian.adult)等23 个物体类。所有物体都标注有一个语义类别、属性(如可见性、活动和姿势)和3D边界框(x,y,z,w,l,h,θ)。具体标注信息如表7所示。

表5 nuScenes数据集数据精度Table 5 Data accuracy of nuScenes dataset

表6 nuScenes数据集采集设备信息Table 6 Sensors used to setup nuScenes dataset

表7 nuScenes数据集3D标注信息Table 7 3D annotation information in nuScenes dataset
1.2.3 Waymo Open Dataset数据集
Waymo Open Dataset(Sun 等,2020)发布于2019年,由装载有5个激光雷达和5个高分辨率针孔相机的数据采集车采集得到,其中激光雷达和针孔相机均进行了同步和标定处理,采集数据精度在表8 中给出,各采集设备参数如表9 所示。数据集的采集地点为美国凤凰城(Phoenix)、山景城(Mountain View)和旧金山(San Francisco)3 个城市,采集时间段包括白天、夜晚和黄昏。最初发布的数据集(Sun等,2020)包含1 150个场景,每个场景的采集时间为20 s,划分为训练集场景798 个,验证集场景202 个,测试集场景150 个,后续一直有更新。数据集包含约1 200 万个有激光雷达数据的3D 边界框(对应11.3 万个激光雷达跟踪ID)以及约1 200 万个图像2D 边界框(对应25.4 万个图像跟踪ID)。标注类别包括小汽车、行人、交通标志和骑行者。对于激光雷达数据,每个目标有唯一的跟踪ID,采用7个自由度的3D 边界框(cx,cy,cz,l,w,h,θ)标注,其中cx,cy,cz代表3D 边界框的中心坐标,l,w,h代表目标的尺寸长宽高,θ表示目标的航向角。除了激光雷达标签,在所有图像中分别对小汽车、行人和骑行者进行目标的2D 边界框(x,y,l,w)标注,分别代表2D 边界框的中心坐标以及长宽,这与3D 边界框在图像的2D 投影保持一致。根据目标对应的激光雷达点云数量,数据集将目标划分为LEVEL_1 和LEVEL_2 两个级别。LEVEL_1 级别的目标对应的点云数大于5 个,LEVEL_2级别的目标对应的点云数小于等于5个。

表8 Waymo Open Dataset数据集数据精度Table 8 Data accuracy of Waymo Open Dataset

表9 Waymo Open Dataset数据集采集设备信息表Table 9 Sensors used to setup Waymo Open Dataset
1.2.4 DAIR-V2X数据集
DAIR-V2X 数据集(Yu 等,2022)是目前全球首个用于车路协同自动驾驶研究的大规模、多模态及多视角数据集,由装载有激光雷达、高分辨率相机和GPS/IMU 惯性导航系统等传感器的自动驾驶车辆端和路侧设备端采集的数据组成,主要数据精度在表10中列出,各采集设备的参数如表11 所示。数据集覆盖了10 km 的城市道路、10 km 的高速公路、28 个十字路口和38平方公里的不同天气与照明变化的驾驶区域。包含71 254 帧点云数据和71 254 帧图像数据,其中40%的数据从路侧端传感器采集,60%帧的数据从车端传感器采集,并在基准算法测验验证中按照5∶2∶3的比例将数据集划分成训练集、验证集和测试集。所有数据均进行了人工修正。标记的目标类别涵盖小汽车(car)、卡车(truck)、面包车(van)、公交车(bus)、行人(pedestrian)、自行车(cyclist)、三轮车(tricyclist)、摩托车(motorcyclist)、手推车(barrowlist)和交通锥桶(trafficcone),具体的数据集标注信息主要分为单侧标注(表12)和融合标注(表13)。

表10 DAIR-V2X数据集数据精度Table 10 Data accuracy of DAIR-V2X dataset

表11 DAIR-V2X数据集采集设备信息Table 11 Sensors used to setup DAIR-V2X dataset

表12 DAIR-V2X数据集单侧标注信息Table 12 One-sided annotation information in DAIR-V2X dataset

表13 DAIR-V2X数据集融合标注信息Table 13 Fused annotation information in DAIR-V2X dataset
1.2.5 其他数据集
除上述4 个常用的数据集外,还有能为3D 目标检测提供额外信息的其他数据集及基准。如,ApolloCar3D(Song 等,2019)数据集包含5 277 幅驾驶图像和超过6 万辆汽车样本,并且为每辆汽车标注了模型尺寸和配备行业级3D CAD(computer aided design)模型。该数据集还结合车辆的3 维位姿和3维形状开发了一种新的3维度量。
1.3 评价基准——常用评价指标
在3D 目标检测领域,平均精度(average precision,AP)(Everingham 等,2010)是考察算法性能的最主要评价指标。然而,根据预测结果与真值之间的匹配标准,不同的数据集关于平均精度的计算方式有所差别。本节详细介绍KITTI 3D 数据集、nuScenes 数据集以及Waymo Open Dataset 数据集的3D目标检测算法评价基准。
1.3.1 KITTI 3D数据集评价基准
在KITTI 3D数据集中,对3D边界框匹配和方向回归分别设立了不同的评价指标。边界框匹配性能采用AP来衡量,而方向回归性能则采用平均方向相似性(average orientation similarity,AOS)来评估。在计算AP 时,要求真正例(true positive,TP)的交并比(intersection-over-union,IoU)(Everingham 等,2010)超过50%,其中对小汽车(car)类别要求正例的IoU超过70%。KITTI 3D 数据集根据3D 预测框和3D 真值框之间的交并比计算IoU。
平均方向相似性(AOS)定义为
式中,r=TP/TP+FN是PASCAL(pattern analysis,statical modeling and computational learning)目标检测的召回率(recall)(Geiger 等,2012);是大于等于r的召回率值;s∈[0,1]是方向相似性,其定义为
式中,D(r)表示在召回率为r时的集合,表示目标i的预测值与真值之间的角度差。为了惩罚多个检出匹配到同一个真值,如果检出目标i已经匹配到真值(IoU至少50%)则设定δi=1,否则δi=0。
1.3.2 nuScenes数据集评价基准
在nuScenes数据集中,定义目标检测是在t时刻进行,并使用[t-0.5 s,t]时间内的传感器数据进行检测。nuScenes 数据集的检测性能只使用10 类目标进行计算。这10 个类别是nuScenes 数据集标注的23个类别的子集。
同样,nuScenes 数据集也使用平均精度AP 作为目标检测的主要评价指标。然而,与KITTI 3D 不同,nuScenes 数据集通过预测框和真值框在鸟瞰图投影的2D 中心距离d来评价目标匹配度。这样做的目的是将目标定位指标独立出来,与尺寸回归和方向估计指标进行分离。通过计算召回率和准确率(precision)均超过10%的PR(precision-recall)曲线下的归一化面积来计算平均精度均值(mean average precision,mAP)。去除召回率或准确率低于10%的部分,能够将低精度和低召回率区间的噪声的影响降至最低。设定集合D为{D|d=0.5 m,1 m,2 m,4 m},集合C为{C|d≤D},即可计算最终的mAP 指标。具体为
除了平均精度AP度量之外,该数据集中还提出多个TP 误差度量指标,对满足d≤2 m 的所有TP 检测结果进行计算。这些指标对每个类别独立进行计算,首先对每个类计算各自的PR 曲线,去掉召回率小于10%的部分,再求平均。如果某一个类别的召回率达不到10%,则该类别的所有TP 误差度量指标误差均为1。
TP误差度量指标主要有5个。1)平均平移误差(average translation error,ATE),使用2 维欧几里得距离进行定义;2)平均比例误差(average scale error,ASE),在方向对齐和平移对齐后,采用预测框和真值框的鸟瞰图投影IoU来定义,即“1-IoU”;3)平均方位误差(average orientation error,AOE),其定义为预测和真值之间的最小偏航角,单位为弧度,除了那些只在180°测量(对称)的障碍物以外,所有的角度都是在360°的范围内进行测量;4)平均速度误差(average velocity error,AVE),其定义为绝对速度误差,使用的是2 维平面的速度差的L2范数;5)平均属性误差(average attribute error,AAE),其定义为1 减去分类精度。
对每一个TP 误差度量指标,可以计算所有类别的平均TP 误差度量指标(mean true positive,mTP)。具体为
式中,TPc指类别为c的TP 误差度量指标,C是类别集合。如果一些指标在某些类别物体上没有明确定义,那么不进行计算。比如,对于一些静止的障碍物不计算其速度误差。
在nuScenes 数据集基准中,将不同的误差类型合并成一个标量分数,即nuScenes 检测分数(nuScenes detection score,NDS),其定义为
尽管mAVE、mAOE 和mATE 的计算结果都可能大于1,但NDS将每一个度量都限制在[0,1]范围之间。NDS 既考虑了目标检测性能,又结合了基于边界框的位置、大小、方向、属性和速度的量化检测质量。
1.3.3 Waymo Open Dataset数据集评价基准
与其他数据集相比,Waymo Open Dataset 数据集关于目标检测的评价指标除了AP之外,还提出了一个新的度量APH,将航向信息合并到目标检测度量AP中,定义为
式中,h(r')是一个类似PR 曲线中的p(r)的参数,其融合了加权的航向信息。每个TP 目标的航向信息取和θ分别为预测航向角和真值航向角,单位为弧度,且定义在[-π,π]之间。
1.3.4 评价指标比较
由上述定义可以看出,KITTI 3D 数据集将3D 边界框匹配与方向回归分离开来,设置了两个不同的评价指标。nuScenes 数据集则认为应当分离每一个损失项并独立优化,将目标定位、目标尺寸回归和方向预测分别独立并设置了不同的评价指标。另外,nuScenes 数据集认为通过IoU 指标来评价算法的定位性能是不恰当的,特别是当鸟瞰投影为长条状矩形时。如图3 所示,其中实线边界框为真值框,虚线框为预测框。当采取2 维边界框中心距离作为定位性能指标时,预测框的定位与真值框完全匹配;当采取IoU 作为定位性能指标时,预测框定位与真值框相差较大。Waymo Open Dataset 数据集则认为不应将方向回归与目标定位和尺寸回归分开计算平均精度,应该考虑每个组成部分与最终结果的相关性,将它们合并到一起建立新的评价标准来评估3D 目标检测。
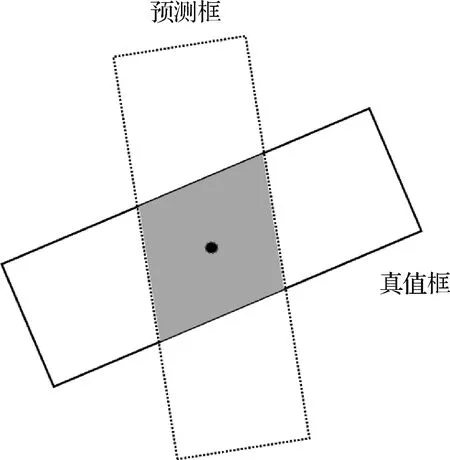
图3 基于交并比进行定位评价的缺点Fig.3 Disadvantage of IoU-based location evaluation
2 制约因素与误差分析
2.1 数据制约因素
数据是制约基于图像3D 目标检测方法性能的一个重要因素,主要体现在训练数据的精度、样本差异、标注数据量和标注规范等方面。本节将分析和讨论这些因素带来的影响。
2.1.1 数据精度
数据精度涉及两个问题,即采集设备综合成像性能和可检测范围。受硬件设施的制约,车载相机的分辨率大多为百万级像素,远低于其他一些领域应用的高分辨率相机。由于目标成像尺寸与距离成反比,当目标成像面积小于一定值(如面积 <50 像素)时,目标检测准确率将大幅下降。对于车载相机,成像的范围(即视场角、可视距离和景深)取决于成像芯片尺寸、镜头焦距和光圈等综合设备参数。在固定分辨率和光圈的条件下,焦距越长,可视距离越远,视场角越小,能够采样的范围越小;焦距越短,可视距离越近,视场角越大,能够采样的范围越大。为了平衡视场和目标成像尺度的关系,进行全视角的感知,目前的数据采集平台使用全景摄像机或装载多个相机解决采样视场角的问题。
2.1.2 样本差异
图像是现实世界物体通过成像系统在传感器像平面上的投影。由于现实世界中物体间的几何关系和投影变换的限制,3 维世界中的物体投影到图像平面时会导致诸多样本差异。其中,较为明显的样本差异有成像尺寸不一、成像角度变化、物体间遮挡、自遮挡以及截断(即部分区域在图像之外)。图4 给出了一些示例(红框框出)。图4(a)(b)为同一车辆在不同距离上的视觉表现。图4(a)中车辆距离设备较近,成像尺寸较大;图4(b)中车辆距离设备较远,成像尺寸较小。图4(c)中靠近图像边界的车辆被图像截断;图4(d)中路边的车辆被其他车辆遮挡。为了体现这些差异,一些数据集添加了相应的属性标注。在KITTI 数据集中,根据目标在图像上2D 边界框的高所对应的最大像素值、遮挡程度以及截断程度,将数据集分为简单、中等以及困难3 个子集。Waymo Open Dataset 数据集中,则根据目标对应的激光雷达点云数目,划分为LEVEL_1 和LEVEL_2 两个级别。由于点云是由激光雷达扫描得到,同样大小的物体,在近处的点云数较多,而在远处的点云数会较少,因此可以认为这是按照物体与收集设备之间的距离进行简单划分。

图4 物体远近大小变化、截断和遮挡示例Fig.4 Examples of object distance and size change,truncation and occlusion((a)close object;(b)distant object;(c)truncated object;(d)occluded object)
在方法论上,很多学者针对样本间的差异提出了自己的见解和解决方案,这些将在2.2.2 节进行详细的探讨。
2.1.3 标注数据量
多方面原因造成已标注的3D 数据集的数据量远少于已标注的2D数据集(如ImageNet等)。首先,采集3D数据集需要构建包含高分辨率相机、激光雷达、毫米波雷达和惯性导航系统等传感器的专用采集平台。相比于只需要一台摄像机的2D 数据集采集系统,3D 数据采集系统造价昂贵。其次,2D 数据集常在设备固定的情况下进行数据采集,而用于自动驾驶的3D数据集则是在设备随车运动的情况下采集,成像质量容易受到运动、气候和光照等诸多因素影响。最后,相比于2D数据的简单标注(使用矩形框标注等),3D 数据需要在3 维空间中进行标注,标注信息更多,并且需要对不同传感器的数据进行时间和空间上的匹配校正,对标注人员的技能要求较高。因此3D数据集的数据采集和标注都十分困难,需要投入大量的人力物力。这也是目前制约3D目标检测发展的重要原因。表14展示了一些数据集的数据量对比情况,其中×n表示有n个相机的数据,2D数据集中的数据规模为ISLVRC2012比赛的数据。
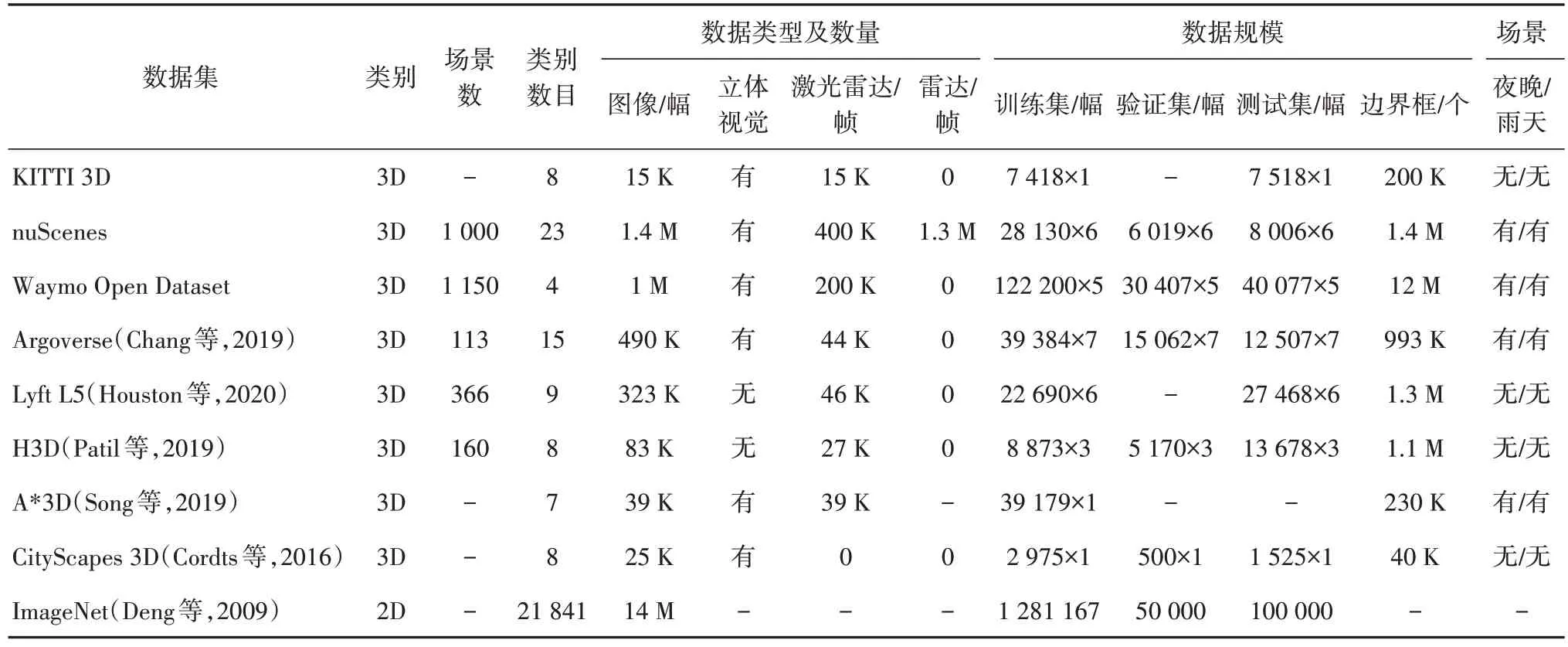
表14 数据集规模对比Table 14 Size comparison of datasets
2.1.4 标注规范
现有3D 数据集的标注方式主要包含点云分割标注和3D 边界框标注。点云分割主要针对的是点云数据,将扫描得到的点云数据归属于不同的物体,这种方法适用于利用点云数据进行目标检测(Aghdam 等,2021;Xu 等,2022;Ku 等,2018;Chen 等,2017;Dou 等,2019;Chen 等,2020a;Nabati 和Qi,2021;Lu 等,2019),但不适合基于图像的3D 目标检测。由于点云数据能够提供精确的深度信息,现有部分算法尝试将点云数据作为辅助数据应用到基于图像的3D目标检测的训练阶段(Feng等,2021)。
基于图像的3D 目标检测使用的图像标注主要为3D 边界框。现实世界中的物体运动可以看做6 个自由度的问题,一般的3D 边界框的标注信息包括3D边界框的中心点坐标(x,y,z)、长宽高(l,w,h),以及偏转角(俯仰角、滚动角、偏航角θ)。由于交通场景下的目标是在道路平面上运动的,因此不考虑目标的俯仰角和滚动角(认为取值为0),通常使用7 个参数(x,y,z,l,w,h,θ)标注3D 边界框的3D 位置、尺寸和姿态信息(Geiger 等,2012;Caesar 等,2020;Sun 等,2020)。3D 目标检测可以认为是一个多任务学习的问题,其目标就是对目标类别以及3D边界框的位置、尺寸和姿态信息进行回归预测。
在实际的检测任务中,由于不同类别目标的外观和运动差异性,采用以上标注方式会出现不同程度的方向估计偏差。Ku 等人(2019a)对KITTI 数据集中目标方向估计进行统计,发现一般算法对于小汽车和骑行者的方向预测精度远高于对于行人的方向预测精度。小汽车和骑行者的平均方向估计偏差(average angular errors,AAE)分别小于7°和20°,而行人的接近56°,其原因可能是3D 边界框的标注方式忽略了目标类别之间的差异。具体来说,小汽车和摩托车/自行车作为刚性物体,其外形一般不会发生太大的改变,很容易定义其朝向,适合用一个有明确方向的3D 立方体框进行标注;而行人是非刚性的,姿态多变,很多情况下行人的朝向难以定义,使用立方体状的3D 边界框标注会导致不同个体间方向差异变大,从而影响到标注数据的质量和检测算法的方向预测结果。
考虑到行人的特殊性,采取新的标注方式(Dong和Isler,2020;Li等,2021a)可能提高其预测精度。比如,Dong 和Isler(2020)通过椭球框回归预测物体的3 维位置和尺寸(如图5 所示)。结合几何图形形状特性和行人特性,可以对行人采取圆柱体加方向矢量的标注方式(如图6 所示)。这种标注的潜在优势包括:1)采取圆柱体或者椭球体的标注方式可以适应行人的外形多变的特性,克服立方体标注导致方向预测误差较大的问题;2)采取圆柱体的标注方式可以减少回归参数,标注的参数只涉及物体类别c、圆柱体底部圆心(x,y)、半径r和圆柱体的高h,将立方体边界框的7个参数(x,y,z,w,h,l,θ)减少到圆柱体标注的4 个参数(x,y,r,h),参数量得到削减,同时不影响对行人定位和尺寸的预测;3)采取圆柱体的标注方式还可以进一步减少不同标注者对同一行人进行标注产生的差异。

图5 使用椭球进行物体3D目标检测示例(Dong和Isler,2020)Fig.5 Examples of 3D object detection using ellipsoid in the literature(Dong and Isler,2020)

图6 使用圆柱体对行人进行3D标注示例Fig.6 Example of 3D annotation of pedestrians using cylinder
2.2 方法论制约因素和误差分析
2.2.1 通用框架
与2D 目标检测算法的分类类似(Redmon 等,2016;Girshick等,2014;Girshick,2015;Ren等,2017;Liu 等,2016;Zhou 等,2019),基于图像的3D 目标检测算法根据在算法执行过程中是否使用中间表示,可以将算法分类为单阶段(one-stage)算法(Brazil 和Liu,2019;Chen 等,2020b;Wang 等,2021b;Luo 等,2021;Liu 等,2020)和两阶段(two-stage)算法(Weng和Kitani,2019;You等,2020),如图7所示。

图7 单阶段和两阶段算法流程图Fig.7 Flow chart of one-stage and two-stage algorithms((a)one-stage algorithm;(b)two-stage algorithm)
单阶段算法根据投影关系,利用卷积神经网络(convolutional neural network,CNN)直接在图像平面回归目标的3D 信息。在算法执行过程中可能会使用深度提示(Brazil 和Liu,2019;Gao 等,2022;Wang等,2021a;Ku 等,2019b)等信息来辅助目标3D 信息的回归,但不会引入深度图或者伪激光雷达点云等中间表示。
两阶段算法在算法过程中会对图像域内的所有物体或者对2D推荐区域内的物体进行深度预测,生成深度图,利用深度图辅助3D 目标检测(Reading等,2021;Badki 等,2020;Chen 等,2020c)。某些算法(Weng 和Kitani,2019;You 等,2020;Ma 等,2019)还将深度图反投影到3 维世界,生成伪激光雷达点云表示,然后利用目前比较成熟的基于激光雷达点云的3D 目标检测算法(Qi 等,2017a,b;Zhou 和Tuzel,2018;Lang 等,2019;Zhang 等,2022;Mao 等,2021;Xu 等,2021;Zheng 等,2021)在生成的伪激光雷达点云上对3D目标进行检测。
单阶段算法直接在2 维图像平面上预测目标的3维信息,两阶段算法的第1阶段从图像反向预测深度图或伪激光雷达点云。由于存在3 维空间到2 维像平面的投影,如何有效利用投影变换和物体位置等几何关系成为提高基于图像的3D 目标检测性能的关键因素之一。
由于维度坍塌导致图像缺少深度信息,单阶段目标检测算法会生成利用深度提示等辅助3D 目标检测,两阶段算法则会进一步生成深度图或伪激光雷达点云等中间表示。无论是单阶段算法还是两阶段算法都会隐式或显式地利用深度信息。因此,对深度预测的精度直接影响3D目标检测算法的性能。
依靠深度学习算法生成的深度提示或深度信息精度不佳,而点云数据或者立体图像能够提供更准确的深度信息。在算法过程中模拟激光雷达点云(两阶段算法)或立体视觉,或直接使用立体视觉作为输入,或使用低线数激光雷达点云数据作为监督训练信号,都可以提高基于图像的3D目标检测的性能。此外,通过使用时空序列数据,如视频等手段也能够提高3D目标检测的性能。因此,选择合适的数据模态成为提高3D目标检测性能的一个途径。
以下将从几何关系、深度预测精度和数据模态3方面制约因素总结分析基于图像的3D目标检测的研究现状,以期能够启迪未来工作。
2.2.2 几何关系
要提高基于图像的3D目标检测性能,可以利用的几何关系包括3D 目标投影到2D 图像上的2D—3D 几何约束和物体间的成像位置关系。2D—3D 几何约束主要表现为2D 图像与3D 透视图直接的几何关系互相约束。由于投影变换,2 维图像缺少距离维信息,信息维度的提升面临一对多、甚至无解的情况,这属于视觉领域的不适定问题(杨步一 等,2021)。物体间的成像位置关系主要包括目标之间的遮挡、目标截断和成像尺寸大小变化。
有许多学者对如何利用2D—3D 几何约束来提高3D 目标检测精度提出了独特的见解。Brazil 和Liu(2019)提出了一个独立的基于区域推荐的3D 目标检测网络M3D-RPN(monocular 3D region proposal network),利用2D 和3D 透视图的几何关系,允许3D检测框利用图像空间中生成的强大的卷积特征。Mousavian 等人(2017)提出使用深度卷积神经网络回归相对稳定的3 维目标属性,然后将这些估计与目标的2 维边界框提供的几何约束相结合,生成完整的3 维边界框。Ku 等人(2019b)提出一种利用候选框和形状重建的单目3D 目标检测方法MonoPSR,使用2D 目标检测器的检测来生成场景中每一个目标的3D 候选框,回归以实例为中心的3D候选框,生成3维边界框,同时估计实例点云以恢复局部形状与比例,增强2D—3D的一致性。
使用2D—3D 几何约束会存在特征失配等问题。为了缓解这些问题,Luo 等人(2021)提出了一种具有特征对齐和非对称非局部注意的单目3D 单级目标检测器M3DSSD(monocular 3D single stage object detector)。M3DSSD 采取两步特征对齐的策略:第1 步,执行形状对齐以便特征图的感受野能够聚焦于具有高度置信度的预定义锚框;第2 步,使用中心对齐来执行2D/3D 中心特征对齐。Li 等人(2019a)提出了一个单目3D 目标检测框架GS3D,旨在从2D 图像中提取底层的3D 信息,在没有点云或立体视觉数据的情况下确定物体的精确3 维边界框。该方法可以为每个预测的2D 长方形获取一个粗长方体,用来指导细化确定目标对象的3D预测框输出。与仅使用2D 边界框提取的特征进行预测框细化的方法不同,该方法通过利用可见表面的视觉特征来探索目标对象的3D结构信息,利用曲面的新特征来消除仅使用2 维边界框带来的表示模糊的问题。张峻宁等人(2020)提出一种基于透视投影的单目3D 目标检测网络。首先,利用世界坐标系、相机坐标系以及目标坐标系三者之间的转换关系,建立一种利用消失点(vanishing point,VP)求解目标3 维边界框的模型。其次,运用空间几何关系和先验尺寸信息,将其简化为方位角、目标尺寸与3 维边界框的约束关系。最终,根据物体尺寸约束的单峰和易回归优势,进一步提出一种学习型的方位角—尺寸的损失函数,提高网络学习效率和检测精度。严娟等人(2020)针对3D检测任务中存在的特征间依赖关系利用不足的问题,提出了一种结合混合域注意力与空洞卷积的3D目标检测方法。该方法使用了融入混合注意力机制的特征提取器,即关注特征的通道域和空间域的注意力机制,有效突出了特征的通道与空间两个方面的关键特征。同时利用特征空洞卷积,增大了特征的感受野,获得了高分辨率的特征图。
目前,大多数涉及2D—3D 几何约束的3D 目标检测算法将从3 维边界框到2 维边界框的投影约束作为一个重要的辅助检测手段。考虑到2 维边界框4个边缘仅提供了4个约束,微小的误差都会导致性能的降低,加入更多的约束能够促进3D目标检测网络的性能。Liu等人(2021a)提出了一种具有启发性的方法,引入了地平面预测作为额外的先验知识指导深度预测和下游的3D 目标检测任务。Li 等人(2020)提出了一个关键点检测辅助3D目标检测的算法,预测图像空间中3维边界框的9个透视关键点,然后利用3维和2维透视的几何关系来恢复3维空间中的尺寸、位置和方向。实验证明,即使在关键点估计非常嘈杂的情况下也可以稳定地预测目标的属性,这使得该方法能够以较小的模型实现快速的检测。
然而,有学者认为在3D 目标检测过程中使用2D—3D 先验是非必要的。Wang 等人(2021b)通过建立在全卷积单级检测器上的实践来研究2D 检测器在3D目标检测中的应用,并提出了一个通用框架FCOS3D(fully convolutional one-stage monocular 3D object detection)。该框架将通常定义的7 个自由度3 维目标转换到图像域,并将其解耦为2 维和3 维属性。然后,考虑物体的2 维比例,仅根据训练过程的投影3 维中心将物体分布到不同的特征级别。此外,还使用基于3维中心的2维高斯分布重新定义中心度,以适应3D目标检测公式。这些操作使得该框架脱离了任何2D 检测或者2D—3D 对应先验。Liu等人(2020)认为2D 检测网络是冗余的,并且会为3D 检测引入不可忽略的噪声。为此,提出了一种新的3D 目标检测方法SMOKE(single-stage monocular 3D object detection via keypoint estimation),通过将单个关键点估计与回归的3 维变量相结合来预测每个检测到的目标的3D边界框。
由于投影关系的限制以及图像视域有限,图像中的物体相比现实中的物体往往存在截断、遮挡、自遮挡和成像尺寸变化等问题。有许多学者针对这些问题提出了改进办法。目前,大多数检测器将每个3D 物体视为独立的训练目标,导致缺少遮挡样本的有用信息。Chabot等人(2017)提出使用车辆的特征点对3 维车辆信息进行编码,其基本思想是使用单目图像恢复3 维车辆信息。首先,使用由真实尺寸的3 维网格组成的3 维车辆数据集,为每一个3 维模型标注了几个顶点,这些顶点对应车辆的不同的零部件(如车轮、照明灯等),并且为每一个3D 模型定义了3D形状。然后,通过恢复每一个检测到的车辆输入图像中的3D点的投影,为每一个检测框选择最佳对应的3 维模型,在2D—3D 之间进行匹配,最终恢复车辆方向、3 维位置和尺寸(如图8 所示)。Xu等人(2020)提出了一种新的基于立体图像的3D 目标检测框架ZoomNet(part-aware adaptive zooming neural network),并引入了学习零部件位置作为补充特征来提高抗遮挡能力。Chen 等人(2020b)则提出了一种具有启发性的方法,通过考虑配对样本关系来改进单目3D目标检测。首先,对相邻样本对的位置和3D 距离计算不确定性预测;然后,将单阶段不确定性感知预测结构和后优化模块集成在一起,以保证运行效率。如图9 所示,对于任意的样本对,通过将其2 维边界框中心的距离设置为直径来定义范围圆,如果该样本对包含其他物体中心,则忽略该样本对(如图9(a)所示)。实验证明,在难识别样本检测性能上,该方法取得较好的效果。

图8 车辆关键部分特征点编码示例(Chabot等,2017)Fig.8 Examples of feature point coding for key parts of the vehicle(Chabot et al.,2017)

图9 样本对及范围圆示例(Chen等,2020b)Fig.9 Examples of sample pair and range circle(Chen et al.,2020b)((a)pair matching strategy for training and interence;(b)example image with all effective sample pairs)
Ma 等人(2021)通过密集诊断实验发现,基于现有技术水平,精确定位远处的物体是几乎不可能的,而这些样本的存在将会误导网络的学习。因此,建议从训练集中删除远处的小目标样本以提高检测器的性能。在自动驾驶领域往往更关注近处的物体,所以该建议具有一定的现实意义。Xu 等人(2020)引入了一种自适应缩放模块,将2D实例边界框调整为统一的分辨率,并相应地调整相机的内在参数,通过这种方式可以从调整大小的长方形图像中估计出更高质量的视差图,进而为附近和远处的物体构建密集的点云。Roddick 等人(2018)认为现有的系统大多受基于透视图像的表示法的局限,目标的外观和比例随深度而急剧变化,很难在图像域中推断出有意义的距离(即深度预测)。他们认为3D 目标检测的一个基本任务是在3D空间中理解世界,因此引入了正交特征变换,通过将基于图像的特征映射到一个正交的3 维空间,跳出图像域的限制,从而能够在尺度一致且目标之间的距离有意义的域中整体地理解场景的空间结构。
由于大多数现有方法对所有目标采用相同的处理方式,而不管其在图像中位置的分布不同,从而导致对于截断物体的检测性能有限。为了解决这一问题,Zhang 等人(2021)提出了一种灵活的单目3D 目标检测框架,解耦了截断物体,并能自适应地结合多种物体深度估计方法。该方法根据物体投影的3D中心是在图像内部还是外部,将物体分为内部物体和外部物体两组,并将内部物体和外部物体的表示和偏移解耦。对于投影中心在图像内的对象,由其中心投影xc直接识别;对于投影中心在图像外的物体,为了解耦表示,该方法通过2 维边界框中心xb与3 维边界框中心投影xc的连线和图像边缘的交点xi来识别表示外部物体(如图10(a)所示)。其中,xi的预测通过1 维高斯分布生成的边缘热图来实现(如图10(b)所示),对于严重截断的物体,xi比xb有更好的表示(如图10(c)所示)。
尽管目前在利用几何关系辅助目标检测方面取得了不错的效果,但是图像中蕴含的道路标线标志等大量细节所提供的几何信息、不同距离物体成像大小隐含的深度信息等仍有待挖掘。当前基于图像的3D 目标检测算法精度仍然较低,2D—3D 投影关系的有效利用和难识别样本的检测仍是限制目前算法性能的关键因素和今后研究的重点方向。
2.2.3 深度预测精度
无论是在算法过程中引入深度信息的单阶段3D 目标检测算法,还是生成深度图或者伪激光雷达点云等中间表示的两阶段3D目标检测算法,其中关键一步是对于目标深度的预测。然而,图像数据天然地缺少深度信息,因此深度预测是基于图像的3D目标检测算法最为重大的挑战,也是造成与基于激光雷达点云的3D 目标检测算法检测性能差异的主要原因。Ma等人(2021)的研究表明,深度预测的准确与否将会极大地影响下游检测任务的精度。当前,基于图像的深度预测算法主要存在两方面的问题。1)受投影关系的影响,深度预测往往不够准确;2)连续性的深度预测在图像的深度突变处对深度预测性能往往不佳,而对预测深度离散化之后,则存在着深度的分类比较粗糙,精度类别不能任意划分的问题。
为了解决第1 个问题,学者们考虑增强深度特征信息,或者使用深度提示线索,进一步对场景进行深度预测,生成深度图来辅助下游的目标检测任务。Brazil和Liu(2019)在所提出的单阶段目标检测网络M3D-RPN 中引入了深度感知卷积层,以开发特定位置的特征,从而提高网络对3D 场景的理解。Luo 等人(2021)提出了一种具有多尺度采样的非对称非局部注意模块来提取深度特征。周大可等人(2021)提出了一种基于局部平面参数预测的方法。该方法以U-Net 为基础网络,主要功能模块有3 个:1)基于ResNet50(residual network 50)的编码网络;2)加入了串联双注意力机制的解码网络;3)利用局部平面参数估计的多尺度预测模块。预测模块能将深度图预测任务转化为平面参数预测问题,即将多个尺度的特征图输入转换成多个标准尺度的深度图,最后计算深度图合成的双目视图来与真实视图的重建误差。Gao 等人(2022)提出了一个深度提示增强策略,为了提供特征化的深度模式作为深度估计的提示,设计了一个专用的深度提示模块来生成称为深度提示的行特征,以分格方式显式监督模型训练。Liu 等人(2021b)提出了一种具有启发性的方法,旨在确定地平面如何在驾驶场景的3 维检测中提供深度推理的额外线索。Eigen 等人(2014)提出了一种从单目图像中预测深度的方法,通过使用两个深度网络堆栈来解决深度预测的问题,其中一个深度网络基于整个图像进行粗略的全局预测,另一个深度网络则局部细化此预测,应用比例不变误差来帮助测量深度关系。王泉德等人(2022)提出了一种强化边缘的单目图像深度预测方法,利用单目RGB 图像通过深度估计网络得到预测深度图。由于预测深度图边缘变化过于平缓,再将预测深度图和RGB 图像输入至深度补偿网络中,基于输入的单目RGB 图像得到对应的深度补偿图。之后将预测深度图与深度补偿图进行融合,得到边缘清晰的深度图。
为了能够更好地从2D 图像中获取深度信息,Ding 等人(2020)改进了传统的2 维卷积,提出了一个深度引导动态深度扩展局部卷积网络D4LCN(depth-guided dynamic-depthwise-dilated LCN),该网络可以从基于图像的深度图中自动学习滤波器及其感受域,使不同图像的不同像素具有不同的滤波器。该方法克服了传统2 维卷积的限制,缩小了图像表示和3D 点云表示之间的差距。Qin 等人(2019a)提出了一个由4 个特定子任务网络构成的单目3D 目标检测网络MonoGRNet(monocular geometric reasoning network)。该网络包含一个实例深度估计(instance depth estimation,IDE)子网络,使用稀疏监督直接预测目标3 维边界框的深度,通过估计水平和垂直维度中的位置,进一步实现了3 维定位,最后在全局环境中优化3 维边界框和位姿联合学习。Peng 等人(2020)在所提方法中引入一个实例深度感知模块(instance depth aware,IDA)来进行深度预测,用于辅助基于立体视觉的3D目标检测。该模块能够通过实例深度感知、视差自适应和匹配加权来准确预测3 维边界框中心的深度。Zhang 等人(2021)则将直接回归的目标深度和来自不同关键点组的求解深度进行组合,作为目标的深度估计输出。Wang 等人(2021a)提出一种深度调节的动态信息传播网络DDMP(denoising diffusion probabilistic models),有效地将多尺度深度信息与图像上下文信息集成。该方法首先在图像中自适应地采样上下文感知节点,然后动态预测用于传播信息的混合深度相关滤波器权重和相似性矩阵,并通过增加中心感知深度编码(center-aware depth encoding,CDE)任务,成功地缓解了不准确的深度先验。王秋晨等人(2022)提出一个递归特征融合的单目深度累积估计方法。单目图像通过特征提取模块产生不同尺度的特征,之后通过递归特征融合模块充分融合多尺度信息。该递归特征融合模块借助卷积的GRU(gated recurrent units)的更新和遗忘机制,按照潜在的顺序对特征进行有规律的融合。在解码器阶段,深度重建过程被分解为多层,不同层分别预测不同细粒度的深度图,最终将不同细粒度的深度图累计生成最终的深度估计结果。张竞澜等人(2022)提出一种基于动态空间金字塔池化(dynamic spatial pyramid pooling,DSPP)的单目图像深度估计方法。首先针对单目图像提取不同分辨率的特征图,之后通过一个动态密集的DSPP模块进行特征融合,最后再通过解码器将最终的特征图变为场景深度图。其中,DSPP 模块基于空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)思想,通过结合通道注意力充分利用每一层特征,在减少网络参数量的前提下,提升了模型整体的准确率。阮晓钢等人(2022)提出一种基于双鉴别器生成对抗网络的单目深度估计方法,利用生成对抗网络来生成准确的视差。该方法的生成对抗网络包含一个生成器和两个判别器,生成器用来生成视差图,真实图像与视差图合成重建图像。重建的左右目图像与真实左右目图像分别作为判别器的输入,由判别器来辨别输入是真实图像还是重建图像,交替训练生成器和判别器,直到判别器无法辨别哪些是重建图像和真实图像,这样网络可得到较为准确的深度。张聪等人(2022)提出一种基于通道注意力机制的单目深度估计网络SEDenseDepth(squeeze-and-excitation dense depth),解决细节估计不准确、同一平面距离估计错误的问题。该网络在编码器中嵌入通道注意力机制,依据不同通道对深度信息不同的贡献度对通道进行编码,提高编码器对图像特征的表征能力。同时,为了获取精细的图像深度信息,建立编码器到解码器的跳跃连接,从而可以挖掘更多的低层信息。杨蕙同等人(2022)针对复杂场景深度估计常出现的误匹配现象,提出一种多尺度注意力特征融合立体匹配算法MGNet。该算法提出了一个轻量级的相关注意力模块,捕获全局上下文信息和远距离通道依赖关系;设计了一个多尺度卷积全局注意力模块,捕获多尺度上下文和全局上下文信息;在代价聚合阶段引入通道注意力,抑制具有歧义的匹配信息,提取有区别性的特征。通过以上操作,该算法在具有反射区域、重复纹理等复杂场景中均有优异的表现。
因为在物体的轮廓边界处的深度会发生突变,采用连续的深度值进行深度预测会产生较大的误差,导致轮廓边界处模糊不清,不利于将前景的目标物体与背景分离开。Weng 和Kitani(2019)发现,由预测深度生成的伪激光雷达点云信号通常存在着“长尾”等问题,如图11 所示。图11(a)为激光雷达点云数据,图11(b)为根据深度图生成的伪激光雷达点云数据,图11(c)为激光雷达点云数据与伪激光雷达点云数据对比。根据深度图生成的伪激光雷达点云数据在目标的轮廓边界处存在“长尾”和错位,即图11(b)(c)中椭圆框出的区域。其原因之一就是估计的深度在目标边界不准确。考虑到这种不准确可能是由在2D 目标检测时使用2 维边界框导致的,因此建议使用实例掩膜代替2 维边界框作为目标的候选区域,通过这样的处理,生成伪激光雷达点云的“长尾”问题可以得到一定的缓解。

图11 伪激光雷达点云“长尾”等问题可视化(Weng和Kitani,2019)Fig.11 Visualization of the “long tail” of the pseudo-LiDAR point cloud(Weng and Kitani,2019)((a)LiDAR point cloud;(b)pseudo-LiDAR point cloud;(c)comparison between the LiDAR point cloud and pseudo-LiDAR point cloud)
也有学者提出将深度离散化处理,将深度预测问题转变为深度分类问题。Reading 等人(2021)提出了一个分类深度分布网络CaDDN(categorical depth distribution network)。该方法将深度进行离散化,将深度预测问题变为一个深度分类问题,对每一个像素预测其离散化的深度分类,将丰富的上下文特征信息投影到3 维空间中的适当深度间隔,然后使用计算效率高的鸟瞰投影和单级检测器来产生最终的输出检测。不过,这类深度离散化策略的精度难以任意调整。因此,Badki等人(2020)提出了一种通过一系列二元分类来估计深度的方法Bi3D 。该方法不预测目标是否处于特定的深度D,而是通过二分类的方法,将目标分类为比深度D更近或者更远。使用二分类的方法大幅提高了网络的检测速度,而且通过多次二分类,该算法能够实现任意精度的深度估计。Garg等人(2021)使用了一个能够输出任意深度值的新神经网络构架,提出了一个从真实分布和预测分布之间的Wasserstein距离导出的新损失函数来缓解这个问题。
由于3D 目标检测通常包含有深度预测和目标检测两个相对独立的部分,目前大多数的算法都是独立优化这两个子任务。一些学者认为,不应该将深度预测与下游的检测任务分离开来,而应该在两者之间建立联系,以根据任务需求联合优化。Wang等人(2021c)提出了一个基于立体视觉的3D 目标检测方法PLUMENet,对于基于立体图像进行深度估计生成伪激光雷达点云和基于伪激光雷达点云进行3D 目标检测两个任务,直接在3 维空间中构建一个伪激光雷达特征体,用于解决两个子任务在不同的度量空间中分别优化导致整体结果次优的问题。Qian 等人(2020)提出了一种基于可微变化(change of representation,CoR)模块的新框架,对基于伪激光雷达点云表示的3D 目标检测算法进行端到端的训练,弥补了两个任务之间的割裂性,并且能够与大多数先进算法兼容。
虽然深度预测在单目3D 目标检测中具有重要的辅助作用,且目前大多数的算法都是在深度预测的基础上进一步进行目标检测的,然而,Simonelli 等人(2020)认为深度预测辅助3D 目标检测是非必要的,并在所提方法中引入了一种用于单目3D目标检测的新型单级深度结构MoVi-3D(monocular visualinertial 3D object detection)。该方法利用几何信息在训练和测试时生成虚拟视图,并对目标外观与距离关系进行了标准化,显著减少距离带来的视觉外观变化影响。通过生成虚拟视图这种方式,深度模型不再需要学习深度特定表示,大幅降低了算法的复杂性。
2.2.4 数据模态
数据模态涉及两个方面,1)在算法过程中模拟激光雷达点云(两阶段算法)或者立体视觉;2)使用立体视觉、多模态数据等作为辅助输入或者监督信号。
一般认为,基于图像的3D目标检测算法性能较差的原因是基于图像的深度预测性能不佳,但是Wang 等人(2019)认为造成基于图像的3D 目标检测算法与基于激光雷达点云的3D 目标检测算法性能差异的主要原因不是数据的质量,而是数据的表示,提出将基于图像的深度图转换为伪激光雷达点云表示,这实际上是模拟激光雷达点云信号。通过这样的转换表示,目前性能较好的基于激光雷达点云的3D 目标检测算法可以应用到伪激光雷达点云信号处理中。Weng和Kitani(2019)也使用伪激光雷达点云作为3D 目标检测中间表示。该方法按照两阶段3D 目标检测的流程,首先检测输入图像的2D 目标候选区域,从生成的伪激光雷达点云中为每一个推荐区域提取点云截锥体,并为每个截锥体检测一个定向的3 维边界框。为了处理伪激光雷达点云中的大量噪声,提出了两点创新,1)使用2D/3D 边界框一致性约束,保证3 维边界框投影与对应的2D 候选区域具有较高的重叠度;2)使用实例掩膜而不是2 维边界框作为2D候选区域的表示,以减少不属于点云截锥体的数据。Ma 等人(2019)利用一个独立的模块将输入数据从2维图像平面转换到3维点云空间,以获得更好的输入表示;然后使用点云主干网络进行3D 目标检测,以获得目标的3 维位置、尺寸和方向。除此之外,为了增强点云的识别能力,还提出一种多模式的特征融合模块,将互补的图像RGB 特征线索嵌入到生成的点云表示中。
目前使用伪激光雷达点云表示的基于图像的3D 目标检测算法显示出了强大的能力,但是该类方法过度依赖独立的深度估计器,在训练阶段需要大量的像素注释,在推理阶段则需要大量计算,限制了其现实应用。Li等人(2021b)提出一种高效、准确的立体图像3D 目标检测方法RTS3D(real-time stereo 3D detection)。与伪激光雷达方法中的3 维表征空间不同,该方法引入了一种新的4D特征一致傅里叶轮廓嵌入(Fourier contour embedding,FCE)空间作为3 维场景的中间表示。FCE 空间通过探索从立体对扭曲的多尺度特征一致性来编码目标的结构和语义信息,从而无需深度监督。此外,该方法还设计了语义引导径向基函数(radial basis functions,RBF)和结构感知注意模块,以减少FCE空间噪声的影响,而无需实例掩膜监督。
除了模拟3D点云数据以外,还有学者提出模拟立体视觉的方法。Zhou 等人(2022)提出一种立体引导的单目3D 目标检测框架SGM3D(stereo-guided monocular 3D object detection network),使用从立体输入中学习到的鲁棒的3 维特征来增强单目检测的特征。该方法提出了一种多粒度域自适应(multigranularity domain adaptation,MG-DA)机制,使网络能够从单目图像生成模拟立体视觉的特征,包括粗鸟瞰图级和精细的锚框级特征。该方法还引入了一种基于IoU 匹配的对齐方式,补偿锚级别域自适应过程中存在的失配问题,以在立体和单目预测之间实现目标级域自适应。Chen 等人(2022)提出一种伪立体3D目标检测框架,从单目图像输入中模拟立体图像特征,其中包含3 种新的虚拟视图生成方法,分别是图像级生成、特征级生成和特征克隆,用于辅助从单个图像中检测3 维目标。此外,还提出一种基于视差特征映射的动态核的视差方向动态卷积,用于自适应地从单个图像中过滤特征,以生成虚拟图像特征,从而缓解了深度估计误差引起的特征退化。Chen 等人(2020c)提出一个深度立体几何网络DSGN(deep stereo geometry network),通过可微体积表示法,有效编码了3D 规则空间中的3D 几何结构,从而可以同时学习到深度信息和语义线索。
提升基于单目视觉的3D 目标检测算法性能的一个重要方法是使用多模态数据。激光雷达点云数据能够提供精确的深度信息,但是目前激光雷达价格昂贵,不适用于在大规模的自动驾驶车辆上进行部署。一个经济实惠的折中方案是使用立体视觉图像或者使用低线数的激光雷达点云数据作为辅助数据输入。
基于立体视觉进行3D 目标检测主要利用的是双目视差信息。双目视差原理如图12所示。

图12 双目视差成像原理图Fig.12 Binocular parallax imaging schematic
根据成像原理,可以得到深度估计与视差估计之间的函数关系,它们之间的关系为
式中,(u,v)代表图像中的像素坐标,D(u,v)为像素点(u,v)的视差估计,f为相机焦距(左右相机使用同一焦距的镜头),b为左右相机的水平距离(默认左右相机在同一水平线上),z(u,v)为像素点(u,v)的深度估计。
从立体图像中检测3 维物体的关键挑战是如何有效利用立体图像中密集的语义和几何信息。Li等人(2019b)提出一种基于立体视觉的3D目标检测算法Stereo R-CNN(stereo region convolutional neural network),扩展了Faster RCNN。该方法同时检测和关联左右图像中的目标对象,并在立体区域推荐网络(region proposal network,RPN)之后添加额外的分支来预测稀疏关键点、视点和目标维度。接着,把这些关键点、视点和目标维度与左右2 维边界框相结合,粗略计算目标3 维边界框。然后,通过使用左右感兴趣区域(region of interest,ROI)的基于区域的光度对齐来恢复精确的3维边界框。Chen等人(2018)提出通过利用立体图像实现3D目标检测的方法,构建了一个能量函数,对目标的大小先验、目标在地平面上的位置以及几个与自由空间、点云密度和到地面距离有关的深度信息特征进行编码,并利用此函数最小化结果生成一组高质量的3D 目标候选。然后,在此基础上使用卷积神经网络进行目标检测,利用上下文和深度信息联合回归3D 边界框坐标和目标位姿。与使用像素级的深度图的方法不同,Qin等人(2019b)建议使用3D锚框来明确构建立体图像中感兴趣区域的目标级对应关系,指导深度神经网络从中学习检测和三角测量3 维空间中的目标对象。该方法中还介绍了一种经济高效的特征通道重加权策略,增强了代表性特征并削弱了噪声信号以促进学习的过程。Liu等人(2021a)为了解决基于立体视觉的3D目标检测速度较慢的问题,提出了一个基于立体视觉的3D 目标检测框架YOLOStereo3D。该方法从基于2D图像的检测框架中获得特征信息,并且使用立体特征增强它们。YOLOStereo3D 结合了实时的单级2D/3D 目标检测器的知识和推理结构,引入了一个轻量级的立体匹配模块,使算法具有较高的运行速度。王一强和陶洋(2022)提出一种基于立体区域卷积神经网络改进的立体视觉3D 目标检测网络FR-CNN。该方法首先在特征提取网络中加入频域通道注意力模块,使算法可以关注更多与目标相关的语义信息,减少深层残差网络权重变化所带来的影响。此外,网络中还加入了统一动态样本加权策略,在网络训练时为“困难”样本和“简单”样本进行合理的损失权重分配,提取目标更为全面的关键特征信息。王康如等人(2020)提出一种迭代式自主学习的立体视觉3D目标检测算法。首先,利用迭代式自主学习的视差估计算法来进行目标区域的视差估计。随后,通过相机内外参将视差信息转换为场景点云,利用自适应特征融合模块将RGB 信息和点云进行融合以实现精准的目标检测。张羽丰等人(2021)提出一个基于立体图像的目标检测与目标距离估计网络。首先,利用R-CNN 网络搭建基本网络,然后使用双目候选框提取网络代替原有的候选框提取网络。为解决直接利用边界框计算目标距离的误差较大问题,该网络加入了一个专门的视差回归分支,合并了基准框内的左右视图的图像特征,最后对左右视图合并的目标框与该基准框的视差进行回归。于洁潇等人(2021)认为利用左右目视图和校准信息之间的关系以及左右视差图的一致性可以获取更加精准的深度信息,提出一种改进的立体区域卷积神经网络算法,以确定性网络DetNet(deterministic networking)作为骨干网络,提升对远景目标的检测效果,并基于左右目视图的关键点,建立左右视图关键点一致性损失函数,提高潜在关键点的位置精度和算法的检测准确性。赵邢等人(2019)提出一种基于立体视觉的车辆目标检测算法。首先利用基于深度学习的目标检测方法获取车辆在2 维图像上的信息,结合深度相机利用立体视觉获取车辆的关键3 维空间信息;然后综合2 维与3 维信息建立3 维空间坐标,计算实现车辆的3 维边界框绘制,辅助区分车辆空间方位。该方法为端到端方法,不需要其他额外的输入信息。迟旭然等人(2022)针对自动驾驶场景提出一种基于Stereo-RCNN 的Fast Stereo-RCNN 的3D 目标检测算法。首先,用单分支网络获得目标3 维边界框的多个角点来重构目标3维中心点,利用轻量级区域生成网络固化3维关键点,采用二分支关键点检测网络锐化算法的目标辨别能力,再结合双层特征融合网络缩短底层特征到高层特征的传递路径。曹杰程和陶重犇(2021)提出一种基于锚框引导的立体视觉两阶段3D 目标检测算法FGAS RCNN。在第1 阶段,双目RGB 图像分别生成前景概率图并根据获得的稀疏锚点预测物体形状,根据预测锚点未知和锚框形状输出相应的ROI建议框。第2 阶段的关键点生成网络利用稀疏锚点信息生成关键点热力图,并结合3 维立体回归生成目标3 维预选框。苏凯祺等人(2022)提出一种基于立体图像的多路径特征金字塔3D 目标检测网络MpFPN(multi-path feature pyramid network)。该网络在特征提取模块增加自底向上,由上至下的路径以及输入特征图至输出特征图之间的连接,为后续联合区域推荐网络提供了更高级的语义信息以及细粒度的多尺度空间信息,从而提高网络的检测精度。
除了使用深度图作为监督信号外,有学者提出利用价格低廉的低线数激光雷达点云数据作为深度预测的监督信号。Feng 等人(2021)提出一种新型的两级网络FusionDepth,通过利用低成本的4 线激光雷达点云数据,促进自监督单目视觉密集深度学习。该方法首先融合单目图像特征和稀疏激光雷达点云特征来预测初始深度图,然后设计一个高效的前馈优化网络,实时纠正伪3 维空间中初始深度图的错误。秦超等人(2022)提出一个利用低线数激光雷达和相机实现的3D 目标检测算法。首先将64 线激光雷达点云采样量降至原始点云数量的10%,将稀疏点云和RGB 图像输入至深度补全网络中获得深度图,以生成激光点云。之后将深度图转为点云俯视图,再通过基于关键点特征金字塔的3D目标检测网络得到物体边界框的几何信息、类别信息等。
运动信息是人类视觉用于检测、跟踪和深度感知的重要依据。目前的大多数基于图像的3D 目标检测算法都是基于静态的图像,没有充分利用运动的时间序列信息。Brazil 等人(2020)提出了一种新的基于单目视频的3D目标检测方法,利用运动来提取场景动力学特征并提高了定位精度。
此外,赵华卿等人(2019)认为对于3D 目标检测来说,其方向角的先验信息并未得到充分利用,据此提出了一种基于2 维图像估计先验方向角的3D 目标检测算法。算法通过颜色信息和深度信息得到2 维的分割实例,并在分割实例上提取关键点。然后,通过关键点的优化过程排除不确定点和修正误判点,通过点云重建得到关键点的3 维坐标,根据关键点坐标估计目标的方向角,并将其作为初始化3 维边界框的方向角。最后,将2 维RGB 图像与深度图进行特征融合,对初始化的3 维边界框以及方向角进行回归,以得到更好的检测效果。
事实上,基于图像的3D目标检测方法中的各种限制因素并不是各自完全独立的,很多学者通过综合克服或者缓解多方面的算法难点,获得了性能的提升。
3 国内外研究对比
如果从双目视觉领域看,3D 目标检测的研究很早就开始了,但是在自动驾驶的3D目标检测的研究和应用领域上,国内外学者更倾向于采用以图像为主的多模态数据融合方式来实现。从这个角度来看,虽然国外的研究起步较早,但国内外的研究差距并不大。
在数据集方面,本文所列的4 个主要数据集发布时间依次为2012、2019、2019、2022 年,跨度约10年。KITTI 3D 数据集发布于2012 年,是最为广泛使用的数据集,由于其发布时间早,也是各种算法研究论文中使用最多的数据集。而我国研究人员于2022 年2 月发布的DAIR-V2X 数据集,则有着更加丰富的标注信息。表15 对各个数据集的发布时间、场景多样性、数据精度、图像数据量和标注信息等各方面进行了对比。可以看出,数据精度基本上与采集设备的发展水平正相关,研究者都采用了当时主流的、较为高端的采集设备。

表15 4个数据集的图像数据对比Table 15 Comparison of image data from 4 datasets
从评价基准看,各个数据集给出的评价指标不尽相同。我国的DAIR-V2X 沿用了目标检测领域常用的mAP 指标,数据也类似KITTI 那样分为简单、中等和困难3 级。针对车路协同应用,增加了数据传输消耗这个指标,使用位数(bit)评估通信成本,以衡量在车路协同 3D 目标检测中使用了多少路端数据。目标检测方面,没有给出更多的评价指标。
在算法研究上,国内外学者的差距很小,各个技术路线上都有国内学者发表顶级论文。以KITTI 数据集3D 目标检测Car 类别的中等检测结果为基准,根据统计(Paperswithcode,2023b),至2023 年1 月30日,基于单目3D 目标检测方法性能top20的论文中,第一作者为国内单位的论文12 篇,第一作者为国外单位的论文8 篇。性能最佳的方法为浙江大学的Hong 等人(2022)提出的CMKD(cross-model knowledge distillation),使用了约4.2 万幅未标注的KITTI数据作为额外的训练数据,Car 类别的AP 指标检测结果在简单、中等和困难数据上分别可以达到28.55%、18.69%和16.77%,中等的AP 指标比第2名(Liu等,2022)高出2.23%。可以看出,目前基于单目3D 目标的检测精度仍处于较低水平。在基于立体视觉3D 目标检测性能top10 的论文中(Paperswithcode,2023a),第一作者为国内单位的论文5篇,第一作者为国外单位的论文5篇。性能最佳的方法是香港中文大学计算机科学与工程系的Chen等人(2023)提出的DSGN++,Car 类别的AP 指标检测结果在简单、中等和困难数据上分别为82.21%、67.37%和59.91%,检测结果的AP75为67.37%,比第2 名(Guo 等,2021)高2.71%。可以看出,目前基于立体视觉3D 目标的检测精度处于一个比较有限的水平。从以上研究成果看,国内外研究水平相差不大。表16 给出了一些3D 目标检测算法的性能对比,表中算法性能均是在KITTI数据集上对Car类别进行测试得到,取IoU 阈值为0.7,-/-/-表示在验证集Val1(Chen 等,2015)/Val2(Xiang 等,2017)/Test 上测试得到的性能,带*数据表示AP|R40指标,不带*数据表示AP|R11指标。数据模态栏中,M表示monocular、S表示stereo、M1 表示monocular+LiDAR supv、M2 表示monocular video、PC表示point cloud。
在产业应用上,目前国内在自动驾驶领域领先的企业或研究机构主要有百度(Baidu,2022)、小马智行(Pony.ai,2022)和华为(WorldAuto,2022)等,其车载感知设备主要为激光雷达、高分辨率相机和毫米波雷达等,在感知模块使用的数据以激光雷达点云为主,图像等数据为辅。百度公司最新的Apollo RT6第6代无人驾驶车辆配备了38个激光雷达和高相机等传感器硬件,配合最新一代的Apollo 自动驾驶系统和1 200 TOPS 高算力计算单元,具备了L4级自动驾驶能力,实现了在复杂的城市道路自动驾驶。小马智行与上汽集团推出的Aion LX 车型配备了激光雷达、高分辨率相机等17 个传感器硬件,车辆的可视范围达到360°和最远200 m,其第3代自动驾驶软硬件方案PonyAlpha 已经具备了L4级自动驾驶能力。极狐阿尔法S 华为HI 版车型配备了3 路126 线车规级激光雷达、13 个高分辨率相机、6路毫米波雷达和12个超声波雷达传感器,搭载了华为ADS 高阶自动驾驶全栈解决方案,芯片运算能力可达400 TOPS,具备了L4 级别的自动驾驶能力,能够在复杂的城市环境中无人驾驶。
国外在自动驾驶领域领先的企业或研究机构主要有谷歌Waymo(池娟,2021)和Tesla(Talpes 等,2020)等。谷歌Waymo 的自动驾驶车辆配备了激光雷达、高分辨率相机和毫米波雷达等20 多个传感器硬件,实现了对周围环境的全面感知,其第5 代Waymo driver自动驾驶方案已经具备了L4级别的自动驾驶能力,在公共道路上完成了2 000万英里的自动驾驶测试和超过100 亿公里的模拟驾驶测试。Tesla 自动驾驶车辆采用纯视觉的自动驾驶感知方案,其自动驾驶车辆配备了8 个相机,车辆可视范围达到360°和最远250 m,基于其自研的多头神经网络HydraNet 的FSD 构架具备了L2+的自动驾驶能力。
目前部分自动驾驶车辆已经在不同路况、天气和环境的复杂场景下实现高度的自动化,如百度Apollo 自动驾驶车辆在雄安、上海多地完成了自动无人驾驶测试,小马智行在北京、广州等地完成了自动驾驶测试,谷歌Waymo 自动驾驶车辆在美国凤凰城、旧金山等地区完成了自动无人驾驶测试。虽然部分车型已经具备了L4级别的自动驾驶能力,但是目前已经产业化的自动驾驶水平基本都在L2—L3级别,即辅助驾驶的水平,实现高度自动化仍任重道远。
4 结语
本文回顾了基于图像的自动驾驶领域3D 目标检测常用的数据集及基准,总结了目前制约该领域发展的一些主要因素及学者在此方面的研究,并对该领域涉及到的误差进行了分析。
现有的3D 目标检测框架都是在特定的数据集(KITTI、nuScenes、Waymo Open Dataset 等)上训练并在该数据集的测试集上进行测试。然而,由于各个国家的道路设计、交通规则、驾驶习惯甚至车辆尺寸都有差异,所以我国的研究发展应该更加重视本土的道路场景,并在国内多种复杂场景中采集构建更加适宜的数据集。
研究中采用的评测指标大多沿袭2D 目标检测的指标,往往是在一个确定数据集的测试效果。针对自动驾驶的落地应用,还面临更多的挑战,需要更多指向关键影响要素的评测指标,以适应复杂的应用场景。
目前,基于图像进行深度感知或预测仍是限制基于图像的3D 目标检测算法性能的关键因素。由于使用的单目图像天然地缺少深度的信息,所以目前基于单目图像的3D 目标检测性能仍然较差。除此之外,在实际操作过程中还会遇到物体大小变化、遮挡、自遮挡和截断的问题,这也是目前影响算法性能的一个重要因素。虽然使用立体视觉能够提高深度预测的准确性,但立体视觉在实际操作过程中仍会遇到特征匹配不准确导致视差估计不准的问题。如何提高从图像中进行深度预测的精度仍是一个亟待解决的难题和未来研究的主要方向。
致 谢本文由中国图象图形学学会交通视频专业委员会组织撰写,该专委会链接为http://www.csig.org.cn/detail/2392。
猜你喜欢
北京测绘(2022年5期)2022-11-22
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
汽车观察(2021年8期)2021-09-01
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中国交通信息化(2019年1期)2019-03-26
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
电子制作(2018年16期)2018-09-26
