
模仿学习综述:传统与新进展
2023-06-20 10:14张超白文松杜歆柳伟杰周晨浩钱徽
中国图象图形学报 2023年6期
张超,白文松,杜歆,柳伟杰,周晨浩,钱徽
1.浙江大学计算机科学与技术学院,杭州 310027;2.浙江大学信息与电子工程学院,杭州 310027
0 引言
深度强化学习(deep reinforcement learning,DRL)有着样本效率低的问题。通常情况下,智能体为了解决一个并不复杂的任务,需要远远超越人类进行学习所需的样本数。人类和动物天生就有着模仿其他同类个体的能力。研究表明,人类婴儿在观察父母完成一项任务之后,可以更快地学会该项任务(Meltzoff,1999)。基于神经元的研究也表明,一类称为镜像神经元的神经元,在动物执行某一特定任务和观察另一个体执行该任务的时候都会被激活(Ferrari 等,2005)。这些现象启发研究者希望智能体能通过模仿其他个体的行为来学习策略,提出了模仿学习(imitation learning,IL)的概念。模仿学习通过引入额外的信息,使用带有倾向性的专家示范,更快地实现策略优化,为缓解样本低效问题提供了一种可行的解决途径。
由于模仿学习较高的实用性,自出现以来一直是强化学习重要的研究方向。传统模仿学习方法主要包括行为克隆(Bain 和Sammut,1999)、逆强化学习(Ng 和Russell,2000)和对抗式模仿学习(Ho 和Ermon,2016)等,这类方法技术路线相对简单,框架相对单一,通常在一些简单任务上能取得较好效果(Attia 和Dayan,2018;Levine,2018)。近年来,随着计算能力的大幅提高以及上游图形图像任务(如物体识别、场景理解等)的快速发展,融合了多种技术的模仿学习方法不断涌现,广泛应用到了复杂任务,相关领域的新进展主要包括基于观察量的模仿学习(Kidambi 等,2021)和跨领域模仿学习(Raychaudhuri等,2021;Fickinger等,2022)等。
基于观察量的模仿学习(imitation learning from observation,ILfO)放松了对专家示范数据的要求,仅从可被观察到的专家示范信息(如汽车行驶的视频信息)进行模仿学习,而不需要获得专家的具体动作数据(如人开车的方向盘、油门控制数据)(Torabi等,2019)。这一设定使模仿学习更贴近现实情况,使相关算法更具备实际运用价值。根据是否需要建模任务的环境状态转移动力学(又称为“模型”),ILfO 类算法可以分为有模型和无模型两类。其中,有模型方法依照对智能体与环境交互过程中构建模型的方式,进一步分为正向动态模型(forward dynamics models)(Edwards 等,2019;Kidambi 等,2021)和逆向动态模型(inverse dynamics models)(Nair 等,2017;Torabi 等,2018;Guo 等,2019;Radosavovic 等,2021)。无模型的方法主要包括对抗式方法(Merel 等,2017;Stadie 等,2017;Henderson等,2018)和奖励函数工程法(Gupta 等,2017;Aytar等,2018;Schmeckpeper等,2020)。
跨领域模仿学习(cross domain imitation learning,CDIL)主要聚焦于研究智能体与专家处于不同领域(例如不同的马尔可夫决策过程)的模仿学习方法。当前的CDIL 研究主要聚焦于以下3 个方面的领域差异性(Kim 等,2020)。1)状态转移差异(Liu等,2020c),即环境的状态转移不同;2)形态学差异(Gupta等,2017),即专家与智能体的状态、动作空间不同;3)视角差异(Stadie 等,2017;Sharma 等,2019;Zweig 和Bruna,2020),即专家与智能体的观察量不同。根据算法依赖的主要技术路径,解决方案主要可以分为4 种。1)直接法(Taylor 等,2007),该类方法通过关注形态学差异来进行跨领域模仿,通常使用简单关系函数(如线性函数)建立状态到状态之间的直接对应关系;2)映射法(Gupta 等,2017;Sermanet 等,2018;Liu 等,2018),该类方法寻求不同领域间的深层相似性,利用复杂的非线性函数(如深度神经网络)完成不同任务空间中的信息转移,实现跨领域模仿;3)对抗式方法(Sharma 等,2019;Kim 等,2020),该类方法通常包含专家行为判别器与跨领域生成器,通过交替求解最小—最大化问题来训练判别器和生成器,实现领域信息传递;4)最优传输法(Papagiannis 和Li,2020;Dadashi 等,2021;Nguyen等,2021;Fickinger 等,2022),该类方法聚焦专家领域专家策略占用测度(occupancy measure)与目标领域智能体策略占用测度间的跨领域信息转移,通过最优传输度量来构建策略迁移模型。
当前,模仿学习的应用主要集中在游戏人工智能(artificial intelligence,AI)、机器人控制和自动驾驶等智能体控制领域。图形图像学方向的最新研究成果,如目标检测(Feng等,2021;Li等,2022a)、视频理解(Lin 等,2019;Bertasius 等,2021)、视频分类(Tran 等,2019)和视频识别(Feichtenhofer,2020)等,都极大地提升了智能体的识别、感知能力,是模仿学习取得新进展与新应用的重要基石。此外,也有研究者开始探索直接使用IL 提高图形/图像任务的性能,如3D/2D 模型与图像配准(Toth 等,2018)、医学影像衰减校正(Kläser 等,2021)和图像显著性预测(Xu 等,2021)等。总体来说,模仿学习与图像处理的有机结合极大地拓展了相关领域的科研范围,为许多困难问题的解决提供了全新的可能性。
本文的主要内容如下:首先简要介绍模仿学习概念,同时回顾必要的基础知识;然后选取模仿学习在国际上的主要成果,介绍传统模仿学习与模仿学习最新进展,展现国外最新的研究现状;接着选取国内高校与机构的研究成果,介绍模仿学习的具体应用,比较国内外研究的现状;最后进行总结并展望模仿学习的未来发展方向与趋势,为研究者提供潜在的研究思路。本文是首篇对模仿学习最新进展(即基于观察量的模仿学习与跨领域模仿学习)进行详细调研的综述。除本文以外,Ghavamzadeh 等人(2015)、Osa 等人(2018)、Attia 和Dayan(2018)、Levine(2018)、Arora 和Doshi(2021)也对模仿学习的其他细分领域进行了调研。
一直以来,研究者广泛使用马尔可夫决策过程来描述强化学习任务环境的基本信息。定义片段式(episodic)有限距离(finite-horizon)的马尔可夫决策过程(Markov decision process,MDP)。其中,P*为真实的状态转移矩阵,c:S×A→[0,1]是环境真实的代价函数(也可用奖励函数r代替)。对于任意给定的代价函数f:S→[0,1],为策略π在模型P下对应的代价函数,。定义状态动作对的占用度为,。定义轨迹τ={s0,a0,s1,a1,…,sH}。定义专家的策略为πe,专家使用的状态转移为P*。定义智能体策略与专家策略之间的悔恨度为。模仿学习的目标可以表示为最小化智能体策略与专家策略之间悔恨度的问题,即模仿学习希望智能体学习到这样一个策略,具体为
式中,ψ是之间的某一距离的度量,λH(π)是带有权重的正则化项,例如折扣因果熵:H(π)=Eπ[-logπ(s,a)]。
根据智能体与专家/环境交互的程度,模仿学习主要可以分为3 种设定。1)完全离线式。智能体可以使用的全部数据仅是专家示范数据集,而无法与环境进行进一步交互。2)环境增强式。智能体可以使用专家示范数据,同时可以与环境进行进一步交互,例如智能体可以获得真实的状态转移。3)专家交互式。智能体可以随时与专家进行交互,即智能体可以随时获得专家策略,此外智能体还可能被允许获得所处环境的真实奖励函数。
总体来说,不同的模仿学习方法都需要解决如下3 个方面的问题。1)专家信息利用。即确定处理和使用专家数据的方式。模仿学习方法需要解决专家数据中可能存在的非最优性和与智能体所处环境不同等问题。常见处理方法包括置信感知(Zhang等,2021)、因果感知(Park 等,2021)、目标感知(Finn 等,2016b;Kim 等,2021)和策略感知(Henderson 等,2018)等。2)相似性度量选择。即确定衡量智能体策略与专家策略相似性的度量ψ,常见的度量有Wasserstein 距离(Mémoli,2011;Dadashi 等,2021)和Sinkhorn 距离(Papagiannis 和Li,2020)。3)学习框架确定。即确定底层的智能体学习方法框架,包括使用有模型类还是无模型类方法、基于价值还是基于策略进行学习、是否需要逆向学习奖励、优化算法如何选取以及探索与模仿平衡机制选择等。
综合上述内容,本文将模仿学习要点分类总结为关键设定、核心思想、重要组件和难点挑战4 个方面,具体内容如图1 所示。此外,图2 展示了该领域相关技术的热点词频。

图1 模仿学习宏观结构图Fig.1 Technical framework of imitation learning

图2 模仿学习相关领域技术热点词频Fig.2 Frequency of technical hot words in IL
1 传统模仿学习
本文提到的传统模仿学习主要指行为克隆、逆强化学习与对抗式模仿学习这3 种范式中较为成熟的部分。许多最新的模仿学习方法都是基于这3 种模仿学习范式的思想不断发展、衍生而来。本节涉及这3 种模仿学习方法的概念、问题定义和代表算法等,但更多的基于这些思想的早期算法由于已被众多综述调研,所以不在本文过多提及。本节与下一节主要介绍模仿学习理论方面的工作,仅选取有代表性、国际性的工作进行介绍。
1.1 行为克隆
早期的模仿学习研究可以追溯到控制学领域中让机器人模仿人类行为的研究(Bain 和Sammut,1999),也正是在这时提出了行为克隆(behavioral cloning,BC)这一概念。BC 从有监督学习的角度来看待模仿学习任务,专家示范数据可看做是为专家数据集中的每个状态分配一个动作作为标签,智能体使用专家遇到的状态和动作作为训练数据,然后使用分类器或回归器来复制专家的策略(Ross 和Bagnell,2010)。特别是当环境的状态转移满足马尔可夫性的时候,最优策略一定是稳态策略(即当前策略只与当前状态有关,与历史轨迹无关),这就使得专家示范数据的顺序可被打乱,从而专家示范数据就是状态—动作对的集合。假设专家数据集为De=,智能体的策略表示为πθ(s),其中,θ为该参数化策略的参数。那么行为克隆可以简单表示为如下的优化问题,即
Ross 和Bagnell(2010)以及Agarwal 等人(2022)证明了完全离线情况下模仿学习的界限,传统模仿学习的误差与马尔可夫决策过程的视界H或是有效视界1/(1-λ)二次相关,这一相关性主要是由累积误差造成的。由于该依赖项在完全离线模仿学习设定下是严格的,那么可否借助其他设定来提升行为克隆的性能就成为模仿学习研究的主要方向。
Ross等人(2011)提出了DAgger(dataset aggregation)算法,这是一种专家交互式模仿学习设置下的在线学习算法,这意味着它会在训练过程中随时从真实环境中生成新样本并查询专家策略(但DAgger不使用真实的奖励信号)。DAgger 通过在当前策略下的每次迭代收集一个数据集,并在所有收集的数据集的聚合下训练下一个策略。该算法背后的思想是,在迭代过程中,根据先前的经验(训练迭代)构建策略在执行过程中可能遇到的输入。该算法的主要优点是专家会指导智能体如何从过去的错误中恢复(Attia 和Dayan,2018)。DAgger 是一种无悔算法,即该算法生成的一系列策略π1,π2,…,πN,当采样量N(轨迹的数量)趋近于无穷的时候,最佳策略的平均悔恨度趋近于0。
Ross 和Bagnell(2014)进一步改进DAgger 算法,并提出了AggreVaTe(aggregate values to imitate)算法。AggreVaTe 源于DAgger,也是一种专家交互式模仿学习设置下的在线学习算法,但它允许智能体访问真实的奖励函数。AggreVaTe 旨在选择能够最小化专家成本(总成本)的动作,而不是选择使得模仿专家动作的0~1 分类损失最小的动作。Aggre-VaTe 通过与专家交互来获得最优策略,通过与环境交互来获得真实奖励。
DAgger 与AggreVaTe 算法都是基于专家交互式模仿学习的设定,然而交互式的专家在现实环境中非常难获得。为了使算法更具可实现性,Agarwal 等人(2022)提出了DM-ST(distribution matching with Scheffe tournament)算法。DM-ST是一种基于环境增强式模仿学习设定的算法,该算法可以与环境交互,但无法随时询问专家策略。已知转移的主要好处是,算法可以使用状态转移来测试当前策略,以比较当前策略与专家示范间的距离,从而来靠近专家策略。相较于经典行为克隆算法,该算法的复杂度与MDP 的有效视界1/(1-λ)为线性相关,这也从侧面体现出已知状态转移的好处。
行为克隆作为一种最基础的模仿学习范式,面临诸多挑战。1)协变量漂移。这是有监督学习中的常见问题,表现为测试数据在训练数据中没有遇到的数据上表现不佳。对于模仿学习,虽然智能体在与专家示范数据集相似的样本上表现良好,但对于训练过程中未见过的样本,泛化性能可能很差,因为专家数据集只包含有限数量的示范数据。2)复合误差。强化学习是一个序贯决策问题,通过BC学习的策略在与环境的交互过程中不能保证完全最优。一旦发生很小的偏差,会导致智能体进入专家数据集中不存在的状态。此时,由于尚未在类似状态下训练,该策略可能会选择一个随机动作,从而导致下一个状态进一步偏离专家策略遇到的数据分布。序列从开始时的小错误,随着马尔科夫决策过程的不断积累和放大,最终会导致策略在真实环境中无法取得好的效果。3)因果混淆。端到端行为克隆可能会受到因果混淆(de Haan 等,2019)的影响,即除非使用明确的因果模型或策略演示,否则无法在观察到的演示中将虚假相关与真实原因区分开。例如,在驾驶任务中,专家演示显示了在红灯处停车的趋势。自动驾驶智能体可能会高估该条件下的任何特征与停车动作之间的相关性。智能体可能会错误地学会在任何红色信号处停下来,即智能体无法正确理解导致专家策略的真实原因(Codevilla 等,2019)。4)数据偏见。模仿学习像所有其他学习方法一样容易受到数据集偏差的影响。在驾驶等现实世界任务中,这种情况会更加严重。由于大多数现实世界的任务要么包含处理一般事件的简单动作,要么包含处理罕见事件的大量复杂反应,而这两种情况在数据集中是极不平衡的。因此,数据集的增大反而可能会导致训练得到的策略性能下降,因为与示范数据中的主要行为模式相比,数据集多样性的增长速度并不够快(Codevilla 等,2019)。5)方差较高。使用固定的离线训练数据集,人们会期望BC学习到的最优策略是相同的。然而,代价函数是通过随机梯度下降的方法进行优化,它假设数据是独立且同分布的i.i.d.(independent and identically distributed)(Bottou 和Bousquet,2007)。然而,在从包含较长人类演示轨迹的数据集中截取状态—动作对来训练策略时,i.i.d.的假设并不成立。因此,可能会观察到训练结果对初始化方式和训练期间样本出现的顺序高度敏感(Codevilla等,2019)。
1.2 逆强化学习
逆强化学习(inverse reinforcement learning,IRL)由Ng 和Russell(2000)提出,逆强化学习的问题核心是找到一个可以解释专家行为的奖励函数。强化学习的思路是通过与环境正向交互获得轨迹(s,a,r,s')来学习最优策略,逆强化学习将这一学习过程反转,通过专家示范的轨迹数据来学习一个能最优解释该行为的奖励函数(Ng 和Russell,2000)。作为模仿学习的一种基本范式,IRL 首先尝试通过专家演示恢复底层环境的代价(或奖励)函数,然后使用恢复的代价信号指导智能体进行强化学习。由于该方法首先将专家策略转换为代价信号,从而使IRL成为一种间接模仿专家行为的方式。
逆强化学习面临的最大问题是奖励函数的歧义性(Ng 和Russell,2000),即通过专家示范恢复出的奖励函数并不是唯一的。通常情况下,存在多个奖励函数,其中甚至包括一些严重退化的奖励函数(例如全0 奖励函数)都可以解释输入的专家示范。造成这一现象的原因是专家的示范数据只包含整个状态—动作空间上的有限且很小的部分轨迹(或策略),这就允许奖励函数集中的多个奖励函数都可以实现专家演示对应的策略。奖励函数的歧义性启发人们通过衡量智能体策略价值函数与真正专家策略价值函数之间的差异,来评估一个恢复出的奖励函数的性能。具体来说,定义逆学习误差(inverse learning error)为,其中是真实专家策略对应的价值函数,是通过逆强化学习模仿专家策略而得到的策略的价值函数,‖·‖p为p-范数。除此之外,逆强化学习与行为克隆一样,也面临泛化性的问题。拥有良好泛化性的奖励函数应反映出专家策略对整个任务的总体偏好,挑战在于使用仅覆盖部分空间的专家示范数据来正确概括整个(包括未观察到的)空间。可以通过简单地对智能体保留一些专家示范轨迹,用来评估奖励函数的泛化性,这些专家示范轨迹可以看做是标记过的测试数据,用于与智能体策略在未经训练过的状态—动作对上的输出进行比较(Arora和Doshi,2021)。
为了解决奖励函数歧义的问题,Ziebart 等人(2008)提出最大熵逆强化学习(maximum entropy inverse reinforcement learning,MaxEnt-IRL),最初的MaxEnt-IRL 专注于确定性MDP 和轨迹上的派生分布(Ziebart 等,2008)。后来Ziebart 等人(2010)进一步提出了基于最大因果熵的框架,将最大熵逆强化学习的思想拓展到具备随机状态转移的MDP 上。最大熵原理在强化学习中是普遍存在的,在最优控制(Toussaint,2009;Rawlik 等,2013)、指导性策略搜索(guided policy search)(Levine 和Koltun,2013;Levine 等,2016)、Q-learning(Haarnoja 等,2017)和SAC(soft actor aritic)(Haarnoja 等,2018)中都取得了显著成效。MaxEnt-IRL 通过引入最大熵的概念来确保奖励函数的唯一性。具体表达式为
另一种解决逆强化学习的可行路径是使用贝叶斯方法(Ramachandran 和Amir,2007;Ghavamzadeh等,2015)。贝叶斯逆强化学习(Bayesian IRL,BIRL)的概念最早由Ramachandran 和Amir(2007)提出。BIRL 将奖励函数的偏好编码为先验,将行为数据的最优置信度编码为似然度。BIRL 使用马尔可夫链蒙特卡罗(Markov chain Monte Carlo,MCMC)算法计算奖励函数的后验均值。假设奖励函数是独立同分布,BIRL 通过P(R)=计算其先验(R(s,a)表示智能体在状态s下执行动作a所获得的奖励,R为奖励函数矩阵)。多种分布函数都可以用做先验分布,如果对奖励函数除了其范围之外的信息一无所知,则可以使用均匀的先验,如果希望奖励接近某些特定值,则可以使用高斯或拉普拉斯先验。BIRL 中的似然度定义为类似于softmax 函数的独立指数分布,即
式中,X表示观察到的状态—动作序列。然后使用贝叶斯定理通过结合先验和似然来制定奖励函数的后验P(R|X) ∝P(X|R)P(R)。
除此之外,与BC 一样,IRL 也可以被间接地看做是多元分类问题或是回归问题。对于每个状态,专家执行的动作可以看做是它的标签。然而,基于此的方法通常更具挑战性,因为IRL 并不是一个直接的有监督学习问题。Levine 等人(2010)提出了用于逆强化学习的特征构造(feature construction for inverse reinforcement learning,FIRL),该方法通过构建与示例策略最相关组件特征的逻辑连接来构建奖励特征,避免了直接使用海量组件特征来构建奖励特征的麻烦。Klein 等人(2012)提出了基于结构化分类的逆强化学习(structured classification based inverse reinforcement learning,SCIRL),该方法使用专家数据训练分类器,但该方法假设存在一个转换模型,以用来计算奖励函数。为了改变这一假设,Klein 等人(2013)随后改进了SCIRL,并提出了级联监督逆强化学习(cascaded supervised IRL,CSI)。CSI 首先利用模拟演示数据集上的标准回归来估计转换模型,然后再使用SCIRL学习奖励函数。
随着深度神经网络的发展,结合深度神经网络的逆强化学习算法被广泛提出(Wulfmeier 等,2015;Finn 等,2016a;Wulfmeier 等,2017;You 等,2019)。其中,较为典型的是Finn等人(2016a)提出的指导性代价学习(guided cost learning,GCL)。GCL 通过在MaxEnt IRL框架中引入一种基于采样的迭代方法来估计MaxEnt IRL 中的Z值,并且可以扩展到高维状态和动作空间以及非线性的代价函数。该方法训练一个全新的采样分布q(τ),随后结合重要性采样方法来近似分布Z,具体为
GCL 交替进行如下步骤:1)使用式(6)来优化cθ;2)最小化式(7)来最小化重要性采样估计的差异以优化q(τ)。
1.3 对抗式模仿学习
Goodfellow 等人(2014)提出了生成式对抗网络(generative adversarial network,GAN),并且在图像任务中取得了优秀的表现。很快,GAN 中对抗的思想用于模仿学习领域。Ho和Ermon(2016)首次提出了对抗式模仿学习(adversarial imitation learning,AIL)的概念。AIL 假设智能体可以与环境交互,目标是学习到一个策略,智能体使用该策略生成的轨迹与专家策略生成的轨迹无法被判别器区别。为了实现该方法,首先智能体会随机初始化策略并与环境交互获得当前策略下的轨迹,同时训练一个判别器网络D来区分来自智能体的采样(st,at,st+1)~Dπ与来自专家示范数据集的采样(st,at,st+1)~De。随后使用判别器的预测定义一个奖励函数,例如r(s,a)=-ln(1-D(s,a)),其中D(s,a)表示判别器将状态—动作对分类成专家的概率。然后使用RL(reinforcement learning)算法对智能体进行训练,以最大化此奖励,从而欺骗鉴别器。与GAN 一样,鉴别器和智能体(这里作为生成器)的训练是交替的。因此,基于对抗式模仿学习的算法通常会重复以下步骤:1)使用当前策略与环境交互,并将轨迹存储在经验缓存区中;2)更新鉴别器;3)根据使用的RL 算法执行RL更新(Orsini等,2021)。
Ho 和Ermon(2016)提出的AIL 算法为生成式对抗模仿学习算法(generative adversarial imitation learning,GAIL)。GAIL 通过最小化自身策略状态动作占用度ρπ与专家策略状态动作占用度间的J-S散度(Jensen-Shannon divergence)来寻找策略,即
式中,H为因果熵,ψ函数为一个凸的代价函数正则化器。GAIL使用J-S散度来度量分布之间的距离,与之类似,使用不同度量的算法也被广泛提出。例如使用沃瑟斯坦距离(Sun等,2019)、f散度(Ke等,2021)等。虽然这些对抗性IL方法在环境增强式IL设定下表现良好,但在纯离线IL的设定下,AIL有时不能胜过一些简单的算法,例如行为克隆(Brantley等,2020)。
对抗式逆强化学习(adversarial inverse reinforcement learning,AIRL)融合了对抗式的思想与逆强化学习的思想,也成为了一种可行的对抗式模仿学习方法。AIRL 的框架首先由Finn 等人(2016a)提出,并将AIRL 算法命名为GAN-GCL(generalized adversarial network guided cost learning)。在该方法中,判别器被表示为幂奖励函数与策略的比值,即
式中,fθ(τ)为学习到的奖励函数。此外,策略通过最大化R(τ)=log(1-D(τ))-logD(τ)来训练。更新判别器可以视为更新奖励函数,更新策略可以视为改进用于估计分区函数的抽样分布。该方法与GAIL有一定的相似性,但是由于GAIL没有对判别器作特殊设置,因此GAIL无法像GAN-GCL一样恢复出奖励函数。除GAN-GCL以外,其他一些工作(Fu等,2017;Sun 等,2019;Ke 等,2021)也对基于AIRL 的方法进行了研究。
表1 按时间归类展示了本节提及的传统模仿学习算法。
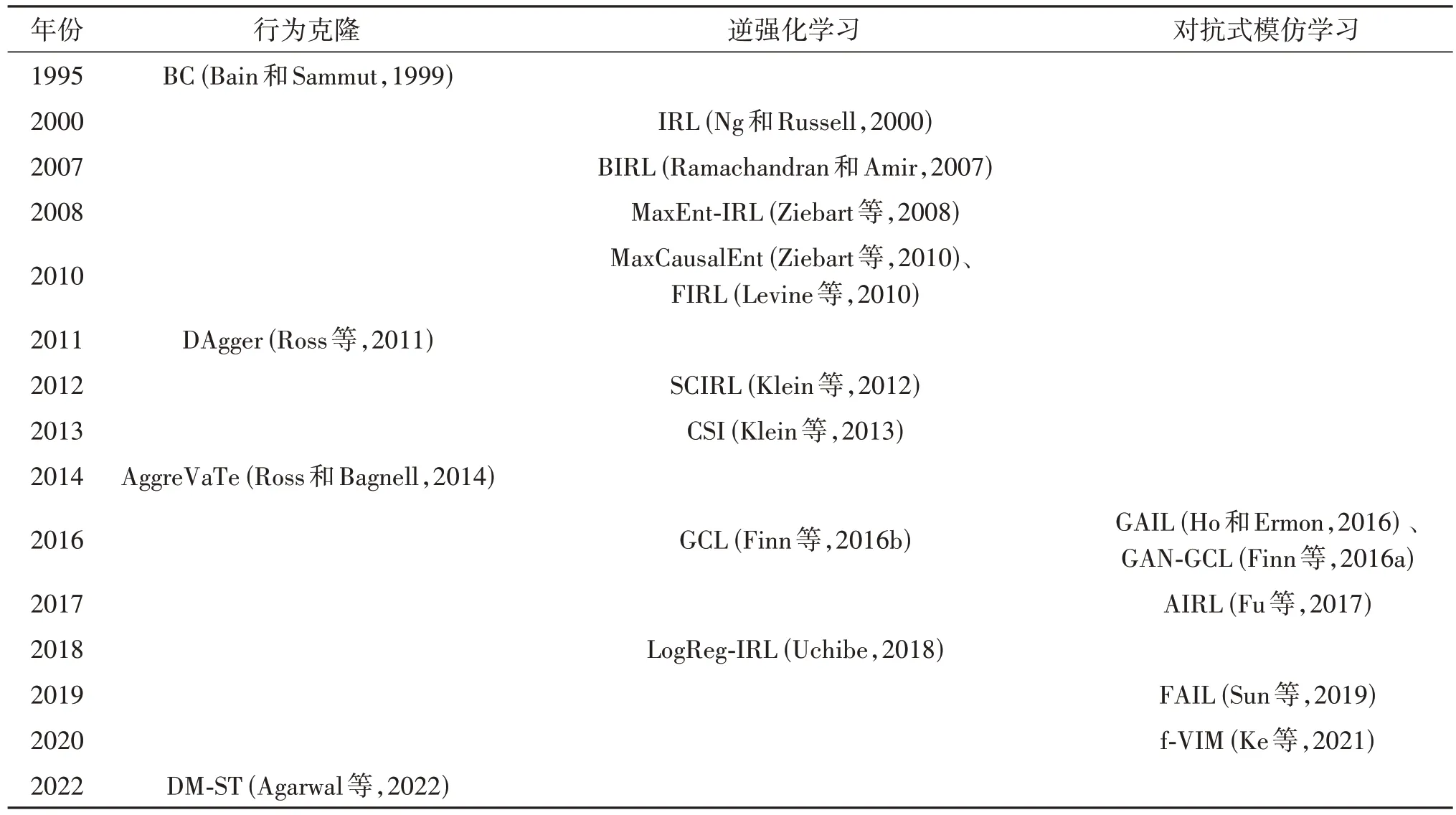
表1 传统模仿学习算法Table 1 Traditional IL algorithms
2 模仿学习新进展
随着强化学习与模仿学习领域研究的不断深入,近些年模仿学习领域的研究取得了一些瞩目的新进展,相关的研究不再局限于理论分析与模拟环境,而是转向更贴近实际的方向。例如,基于观察量的模仿学习、跨领域模仿学习等。在这些领域的许多工作考虑了使用实际数据集进行模仿学习训练,同时其目标也并非局限于完成Gym 等模拟环境上提供的标准任务,而是进一步转向模仿学习算法在机器人控制、自动驾驶等领域的实际应用,为“模拟到现实”做出了坚实的推进。
2.1 基于观察量的模仿学习
当智能体试图仅通过“观察”来模仿专家的策略时,就会出现基于观察量的模仿学习(imitation learning from observation,IlfO)这一任务(Torabi 等,2019)。所谓“观察”,指的是仅包含状态信息而不包含动作信息的专家示范,可以是仅包含状态信息的轨迹τe={si}Mi=1,也可以是单纯的图像或视频。相较于传统模仿学习中既可以获得专家所处的状态,又可以获得专家在当前状态下的策略(动作)的设定,ILfO放松了对专家示范数据的要求,从而成为一种更贴近现实情况、更具备实际运用价值的设定。值得注意的是,ILfO 可以直接使用专家行为的图像数据作为输入(Liu 等,2018;Torabi 等,2019;Karnan等,2022),这在引入海量数据集的同时,也将模仿学习与图像图形学、计算机视觉等领域有机地结合起来,从而极大地拓展了相关领域的潜在研究方向,为相关领域的进一步发展开辟了新的空间。
与IL 的目标类似,ILfO 的目标是使智能体通过模仿仅包含状态信息的专家示范数据,输出一个具有相同行为的策略。既然ILfO 是一种更贴近现实的设定,如何从现实的专家行为中获得示范数据是首先要解决的问题。一些早期的工作通过直接在专家身上设置传感器的方式记录专家的行为数据(Ijspeert 等,2001;Ijspeert 等,2002;Calinon 和Billard,2007)。上述方法的升级版本是采用动作捕捉技术,专家需要佩戴专业的动作捕捉设备,这样做的好处是计算机系统可以直接对专家的行为进行3 维建模,从而转换成模拟系统易于识别的输入(Field等,2009;Merel 等,2017)。随着前些年卷积神经网络在处理图像数据上大放异彩,现在较为常见的是直接使用摄像头拍摄专家行为,进而直接使用图像、视频数据作为输入(Liu 等,2018;Sharma 等,2019;Torabi等,2019;Karnan等,2022)。
由于ILfO 无法获得专家动作,因此将专家动作视为状态标签的方法将不再适用,这也使得ILfO 变成了更具挑战的任务。一般来说,基于ILfO 设定的算法可以分为有模型和无模型两类。所谓的“模型”,一般指的是环境的状态转移,通过对智能体与环境交互过程中学习模型的方式进行区分,可以进一步将有模型的方法分为正向动态模型(forward dynamics models)与逆向动态模型(inverse dynamics models);无模型的方法主要包括对抗式方法与奖励函数工程法。
2.1.1 有模型方法
模型描述了智能体与环境交互的过程,有模型的方法需要对环境状态转移动力学进行建模,通常情况下这一过程涉及智能体的探索过程,因此对于该类方法,探索与模仿的平衡是必须考虑的问题。
正向动态模型描述的是智能体与环境交互的正向过程,即从当前状态—动作对{(st,at)}到下一状态{st+1}的映射。Edwards等人(2019)提出了一种正向ILfO 算法ILPO(imitating latent policies from observation),ILPO通过学习潜在策略π(z|st)为模仿策略创建一个初始假设,该潜在策略π(z|st)会估计给定当前状态st后潜在(非真实)动作z的概率。由于并不需要实际的动作数据,因此该过程可以离线完成,而无需与环境进行任何交互。为了学习潜在策略π(z|st),ILPO 使用潜在的前向动力学模型预测st+1和给定st在z上的先验。然后算法通过与环境交互学习一个能够将潜在动作与相应的正确动作相关联的动作映射网络。由于该算法的大部分过程都是离线进行的,因此与环境交互的次数相对较少。Kidambi 等人(2021)提出了MobILE(model-based imitation learning and exploring)算法,该算法是一种基于专家交互式模仿学习设定的在线正向动态有模型算法,即该算法在训练过程中可以随时访问专家策略。MobILE 首先通过与环境交互获得,并以此来估计状态转移P,随后该方法通过在探索过程中利用不确定性度量和在模仿过程中精心设计奖励来实现探索和模仿的权衡。
逆向动态模型描述的是使用状态—下一状态对{(st,st+1)}来恢复出智能体动作{at}的反向过程(Hanna 和Stone,2017)。Nair 等人(2017)提出了一种基于逆向动态模型的ILfO 算法,该算法假设每个观察到的转换{(st,st+1)}都可以通过单个动作来实现。算法首先通过与环境交互来获得状态转移数据,然后使用收集的数据集训练一个从{(st,st+1)}到{at}的逆向映射,最后使用该映射恢复出专家示范对应的动作,从而可以使智能体模仿该策略。Torabi 等人(2018)提出BCO(behavioral cloning from observation)算法,该方法是一种基于环境增强式IL 设定的在线逆向动态模型无监督学习方法,智能体首先学习逆向模型来推断专家示范中缺失的动作信息,然后使用修改后的行为克隆方法进行模仿学习(Torabi等,2018)。Guo等人(2019)首先使用基于张量的模型来推断专家状态序列对应的未观察动作,然后使用结合强化学习与模仿学习的混合目标函数来优化智能体的策略。与Nair等人(2017)提出的方法类似,Pavse 等人(2020)提出了Ridm 算法(reinforced inverse dynamics modeling),该方法同样假设状态转换{(st,st+1)}可由单个动作来实现,不过Ridm 在学习到逆向模型后,会使用稀疏奖励来对该逆向模型进行优化(Pavse等,2020)。Radosavovic 等人(2021)将逆向动态模仿学习运用在通过视频专家示范数据进行手臂的灵巧控制上,并提出了SOIL(state only imitation learning)算法(Radosavovic 等,2021)。SOIL 的核心思想是同时训练策略与逆向动态模型,策略使用强化学习方法和带有预测动作的示范进行训练,而逆向动态模型使用自监督的方法训练。虽然基于逆向动力学的方法取得了一定的效果,但是与逆强化学习面临的问题一样,逆动力学模型在许多问题实例中无法被准确定义,除非MDP 的动力学是单射的(即没有两个动作可以从当前状态导致相同的下一个状态)(Zhu等,2020)。
2.1.2 无模型方法
无模型的方法指的是算法不包含任何对环境建模的步骤。受对抗式模仿学习(Ho 和Ermon,2016)思想的启发,人们提出了很多使用生成器与判别器框架的ILfO 算法。Merel 等人(2017)提出了一种改进的GAIL算法,可以适用于ILfO的设定。该算法假设专家的示范数据为,即包含观察与奖励信息,判别器接收来自智能体策略的观察—奖励对作为输入,并被训练去区分这一观察—奖励对的来源。随后判别器的输出会作为奖励函数来更新智能体的策略,该奖励为rt=-log(1-Dϕ(ot,rt))。Stadie等人(2017)考虑了专家示范数据与智能体状态空间拥有不同视角的情况,并且提出了TpIL(thirdperson imitation learning)(该项工作同时也属于跨领域模仿学习的范畴)。为了解决视角不同的挑战,TpIL 引入了一个新的分类器,使用判别器网络早期层的输出作为输入,并尝试区分来自不同视角的数据,目的是使判别器的早期层对不同视角保持不变。Henderson 等人(2018)提出了OptionGAN 方法,该方法结合逆强化学习与对抗式模仿学习,通过引入的option learning思想来学习可能导致专家示范的一组奖励函数(而不是单个奖励函数),并且最终在ILfO任务上取得了不错的结果(Henderson 等,2018)。Sun 等人(2019)提出了一种适用于大规模MDP 的ILfO 方 法FAIL(forward adversarial imitation learning)。该项工作的主要贡献是理论证明了FAIL算法在ILFO 任务中复杂度为,即与主要参数均为多项式相关,这间接说明了ILfO设定下的算法可以是高效的(Sun等,2019)。
奖励函数工程法指的是基于专家示范数据,人为定义一个奖励函数,然后使用强化学习的方式训练策略。该方法与逆强化学习最大的不同之处在于逆强化学习恢复出的奖励函数能够解释专家的策略,而奖励函数工程法中设计的奖励函数并不一定能解释专家的行为,它旨在指导智能体向某种人为设定的目标去靠近。例如,Gupta等人(2017)提出的代理任务法(proxy task),该方法适用于专家环境与智能体所处环境不同的设定,首先使用代理任务学习一个不变的特征空间,然后将该空间上智能体特征与专家示范特征之间的距离定义为奖励,从而指导智能体模仿专家策略。Aytar 等人(2018)提出了一种从Youtube 视频网站上进行IL 的方法,其任务目标是通过专家通关游戏的视频指导智能体学会通关该游戏。该项工作的发表也进一步展示了IL 与图像图形学之间的紧密联系。该方法首先使用自监督学习的方式将多源未对齐的视频数据映射到一个通用的表达,随后再将单个视频数据嵌入到该表达中以构建一个鼓励智能体模仿视频中专家策略的奖励函数。Schmeckpeper 等人(2020)提出了一种从离线视频数据集中进行IL 的框架,并将其命名为RLV(reinforcement learning with videos)。RLV 使用Reddy等人(2020)提出的基于判别(s,s')中s'是否为终止状态的方式,来给(s,s')赋奖励值。若s'为终止状态,则R(s,s')较大,反之R(s,s')较小。使用该种奖励函数,可以鼓励智能体尽量到达专家视频示范的最终状态,从而完成IL。可以看出,基于奖励函数工程法的算法,虽然在具体任务上取得了不错的效果,但是这种框架高度依赖人为设计的奖励函数,算法性能与设计者在该领域的专业经验高度相关。同时基于该框架的算法往往缺乏泛化性,仅能对特定任务生效,而无法轻易推广到其他任务上。
虽然ILfO 问题有着上述诸多解决方案,但同时也面临巨大的挑战(Torabi 等,2019)。首先是形态学不同,当智能体与专家的表现形式(形态学)有差异时,会为ILfO 带来一定的困难。所谓形态学不同,包括但不限于外表、状态转移、特征上的差异。举例来说,当一个多臂机器人想要通过模仿人类行为而完成一系列动作时,由于机器人的机械结构与人体的肌肉结构差异过大,人类的部分动作可能根本无法用机械臂实现,这就给机器人模仿该任务带来了很大困难。除此之外,视角差异也是ILfO 面临的另一大挑战。所谓视角差异,主要指的是智能体将要模仿的专家示范与自己探索环境得到的轨迹有着视角上的差异,即便是在完全相同的环境中做完全相同的动作,视角差异所导致的图像差异也会十分巨大。
2.2 跨领域模仿学习
跨领域模仿学习(CDIL)相关领域的研究最早可以追溯到机器人控制领域通过观察来让机器人学习策略(Kuniyoshi 等,1994;Argall 等,2009)。后来随着对ILfO 研究的深入,CDIL 的相关研究也越来越受重视。与传统设定下的IL 相比,跨领域模仿学习与现实世界中的学习过程兼容性更好(Raychaudhuri等,2021)。传统的IL 假设智能体和专家在完全相同的环境中决策,而这一要求几乎只可能在模拟系统(包括游戏)中得到满足。这一缺点严重限制了传统IL 在现实生活中可能的应用场景,并且将研究者的工作的重心转移到对场景的准确建模,而并非算法本身的性能上。CDIL 的产生打破了这一枷锁,因为智能体可以使用不同于自身领域的专家示范来学习策略。当前CDIL 所研究的领域差异主要集中在3 个方面(Kim 等,2020)。1)状态转移差异(Liu 等,2020c);2)形态学差异(Gupta等,2017);3)视角差异(Stadie 等,2017;Sharma 等,2019;Zweig 和Bruna,2020)。这些差异也对应ILfO面临的挑战。
模仿学习在人们熟知之前,这一研究领域更广泛地称为迁移学习(Taylor 等,2008)。例如,Konidaris 和Barto(2006)通过在任务之间共享的状态集上学习价值函数,从而为目标任务提供塑性后奖励。Taylor 等人(2007)人工设计了一个可以将某一MDP对应的动作价值函数转移到另一MDP 中的映射来实现知识迁移。直观地说,为了克服智能体环境和专家环境之间的差异,需要在它们之间建立一个转移或映射。Taylor 等人(2008)介绍了一种“直接映射”的方法来直接学习状态到状态之间的映射关系。然而,在不同领域中建立状态之间的直接映射只能提供有限的转移,因为两个形态学上不同的智能体之间通常没有完整的对应关系,但这种方法却不得不学习从一个状态空间到另一个状态空间的映射(Gupta 等,2017),从而导致该映射关系是病态的。早期的这些方法大多都需要特定领域的知识,或是人工构建不同空间之间的映射,这通常会使研究变得烦琐且泛化性较差,因此必须借助更为先进的算法来提升性能。
随着深度神经网络的发展,更具表达性的神经网络得到广泛运用,CDIL 也迎来了较快的发展。Gupta 等人(2017)、Sermanet 等人(2018)和Liu 等人(2018)研究机器人从视频观察中学习策略,为了解决专家示范与智能体所处领域不同的问题,他们的方法借助不同领域间成对的、时间对齐的示范来获得状态之间的对应关系,并且这些方法通常涉及与环境进行交互的RL 步骤。相较于“直接映射”的方法,这些方法学习的映射并不是简单的状态对之间的关系,而更多地利用了神经网络强大的表达性能,从而取得更好的实验效果。但不幸的是,成对且时间对齐的数据集很难获得,从而降低了该种方法的可实现性(Kim等,2020)。
随后,基于GAN 的方式在图像生成领域大放异彩,考虑到ILfO 和CDIL 与图像领域的诸多联系,对抗式的思想也很自然地引入到CDIL 中(Sharma 等,2019;Kim 等,2020)。Kim 等人(2020)提出了一种可以使用非配对、非时间对齐示范数据进行跨多领域模仿学习的框架,并将其命名为GAMA(generative adversarial MDP alignment)。GAMA 首先解决MDP 对齐问题,然后结合对抗式训练,利用对齐进行零次(zero-shot)模仿专家领域的策略,其目标为求解如下问题
虽然GAMA 避免了Gupta 等人(2017)方法中智能体已学会部分专家策略的假设,但该方法需要获得专家的动作数据,这与ILfO 的设定不兼容,并且GAMA 是一种专家交互式IL 设定下的算法,不断询问专家策略在很多情况下都会使算法变得烦琐。此外,对抗式方法常见的最小—最大化问题经常导致训练不稳定。上述弊端严重限制了该算法及类似算法的性能。为克服上述缺点,Raychaudhuri 等人(2021)提出一种两步框架来解决从观察量进行跨领域模仿学习(cross domain imitation learning from observation,CDILfO)问题。首先使用代理任务学习跨领域的转换,然后进行转移过程与策略学习过程。该方法不假设对专家策略有任何访问权限,并且仅使用未配对和未对齐的状态观察量来进行模仿学习。
如式(2)所示,模仿学习本质上是智能体与专家策略的占用度匹配问题,即IL 是解决分布之间匹配与转移的问题。从这个角度出发,越来越多的研究者发现模仿学习与最优传输(optimal transport,OT)之间有着紧密的联系。受最优传输研究的启发,近些年提出了大量基于该类思想的CDIL 方法(Papagiannis 和Li,2020;Dadashi 等,2021;Nguyen 等,2021;Fickinger等,2022)。考虑两个数据空间XA和XB,对应的数据分布为PA和PB,设hA:XA→Y△是一个可以准确估计通过PA在XA上采样得到实例的分类器。基于OT 的IL 的目标是通过模仿分类器hA在XA上的行为,得到一个可以准确预测通过PB在XB上采样得到实例所属分类的分类器hB(简单来说,可以将分类器理解成策略函数)。针对这一目标,Nguyen 等人(2021)提出了MOST(multi-source domain adaptation via OT for student-teacher learning)算法,考虑将知识从多个不同领域转移到单个未标记目标领域的任务目标,并使用沃瑟斯坦距离作为度量(Wasserstein metirc)。Fickinger 等人(2022)提出了GWIL(Gromov-Wasserstein imitation learning),使用格罗莫夫—沃瑟斯坦距离,对于两个测度空间(X,dX,μX)和(Y,dY,μY),其对应的格罗莫夫—沃瑟斯坦距离为
格罗莫夫—沃瑟斯坦距离通过比较每个空间内的成对元素间的距离来比较两个测度空间的结构,以找到空间之间的最佳等距。相较于Gupta 等人(2017)提出的基于示范数据对齐的方法,基于OT的方法不需要依赖代理任务,相较于Sharma 等人(2019)和Kim 等人(2020)提出的基于GAN 的方法,基于OT 的方法又可以避免最小—最大化问题导致的训练不稳定,因此就目前的研究而言,属于IL 领域较为优秀的解决方案。
表2 从算法关键组件的3 个方面展示了模仿学习新进展阶段的典型算法。其中,使用简单距离度量的均在表中使用LP范数作为相似性度量。BCO,FAIL,GAMA 分别使用最大似然估计(maximum like-lihood estimation,MLE)、积分概率度量(integral probability metric,IPM)和KL 散度(Kullback-Leibler divergence)作为相似性度量。

表2 模仿学习新进展算法重要组件Table 2 Important components of new advanced IL algorithms
3 模仿学习应用
随着基于观察量的模仿学习与跨领域模仿学习的不断发展,基于IL的算法也越来越符合现实场景的应用要求,此外,图形图像学上的诸多最新研究成果,也为IL的现实应用进一步赋能。模仿学习的主要应用领域包括但不限于游戏AI、机器人控制、自动驾驶和图像图形学等。本节列举有代表性的模仿学习应用类工作,由于现阶段国内关于模仿学习的研究主要集中在应用领域,因此着重介绍国内高校、机构的工作成果,进而为国内该领域的研究者提供一些参考。
Gym(Brockman 等,2016)和Mujoco(Todorov 等,2012)是强化学习领域最广泛使用的训练环境,其为强化学习领域的研究提供了标准环境与基准任务,使不同算法能在相同设定下比较性能的优劣。模仿学习作为强化学习最为热门的分支领域,也广泛使用Gym 与Mujoco 作为训练/测试环境。Gym 包含多个基础游戏环境以及雅达利游戏环境,Mujoco 包含多个智能体控制环境同时支持自建任务。值得注意的是,Gym 与Mujoco 都包含大量的图像环境,即以图像的形式承载环境的全部信息,这就使得图像图形学的众多最新成果直接推动了模仿学习的应用。考虑到Gym 与Mujoco 的虚拟仿真特性,可将其归类为游戏环境。这些使用Gym 与Mujoco 进行训练或验证的模仿学习算法,都能在一定程度上推广到其他游戏领域的应用,国内诸多高校都在该方面做出了贡献。清华大学的Yang 等人(2019)探究了基于逆向动态模型的IL算法性能,Jing等人(2021)验证了分层模仿学习的性能;上海交通大学的Liu 等人(2021a)探究基于能量的模仿学习算法性能,Liu等人(2021b)探究离线模仿学习算法COIL(curriculum offline imitation learning)的性能,Liu等人(2022)探究通过解耦策略优化进行模仿学习。南京大学的Zhang 等人(2022)探究生成式对抗模仿学习的性能,Xu 等人(2020)探究模仿策略的误差界限,Jiang等人(2020)探究带误差的模拟器中的离线模仿学习。
除Gym 与Mujoco 环境外,模仿学习也广泛用于训练棋类与即时战略类游戏AI。这类游戏任务的难度显著增加,且通常包含较大信息量的图像数据,因此也会更依赖于先进的图像处理方法(例如目标检测)。对于这些复杂游戏环境,状态动作空间过于庞大,奖励信息过于稀疏,智能体通常无法直接通过强化学习获得策略。进而,智能体首先通过模仿人类选手的对局示范来学习较为基础的策略,然后使用强化学习与自我博弈等方式进一步提升策略。其中最有代表性的是Google 公司开发的围棋游戏AI AlphaGo(Silver 等,2016)以及星际争霸AI Alphastar(Vinyals 等,2019)。与国外的情况相似,国内工业界也十分重视该类游戏AI 的开发,包括腾讯公司开发的王者荣耀(复杂的多智能体对抗环境)游戏AI(Ye 等,2020)、华为公司基于多模式对抗模仿学习开发的即时战略游戏AI(Fei等,2020),如图3 所示。考虑到该类游戏的超高复杂性,人工智能在如此复杂的任务中完胜人类对手,可以预见人工智能在游戏领域完全超越人类已经只是时间问题。

图3 模仿学习智能体在即时战略游戏中的决策(Fei等,2020)Fig.3 Decision making process of IL agent in RTS game(Fei et al.,2020)
在机器人控制领域,由于机器人的价格昂贵、部件易损且可能具备一定危险性,因此需要一种稳定的方式获得策略,模仿学习让机器人直接模仿专家的行为,可以快速、稳定地使其掌握技能,而不依赖于过多的探索。美国斯坦福大学的Abbeel 等人(2006)早在2006 年就将逆强化学习方法用于直升机控制任务(如图4 所示)。美国加州大学伯克利分校的Nair等人(2017)结合自监督学习与模仿学习的方法,让机器人通过模仿专家行为的视频数据,学习完成简单的任务(如图5 所示)。国内高校也在该领域做出了一定的贡献。清华大学的Fang 等人(2019)调研了模仿学习在机器人操控方面的研究。中国科学院大学的Li 等人(2022b)通过视频数据进行元模仿学习以控制机器(如图6 所示)。中国科学院自动化研究所的Li 等人(2021)通过视频数据进行模仿学习以精确操控机器手臂的位置。

图4 智能体通过模仿专家策略后控制飞机完成的一系列飞行动作(Abbeel等,2006)Fig.4 The IL agent controls the aircraft to complete a series of flight actions by imitating the expert strategy(Abbeel et al.,2006)
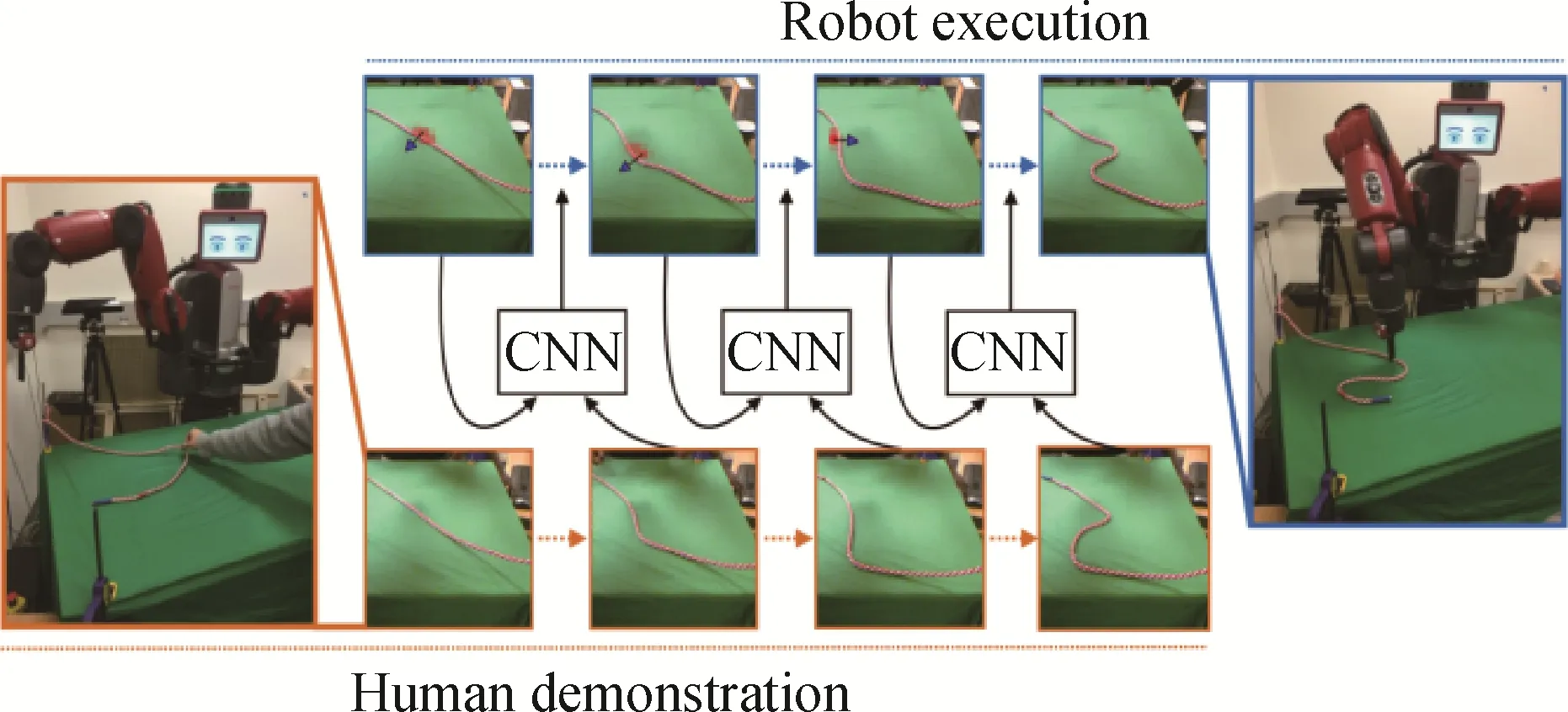
图5 智能体通过模仿专家策略后操控机械手臂移动物体(Nair等,2017)Fig.5 The agent controls the robotic arm to move the object by imitating the expert strategy(Nair et al.,2017)

图6 智能体通过模仿专家策略后操控机械手臂抓取物体(Li等,2021)Fig.6 The agent manipulates the robotic arm to grab the object by imitating the expert strategy(Li et al.,2021)
自动驾驶是当前人工智能最重要的应用领域(Grigorescu 等,2020;Kiran 等,2022),模仿学习凭借其优秀的性能也在该领域占据一席之地,特别是基于观察量的模仿学习与跨领域模仿学习兼容自动驾驶的绝大部分现实需求,使IL 在该领域大放异彩(Codevilla 等,2018;Bhattacharyya 等,2018;Liang 等,2018;Chen 等,2019;Kebria 等,2020;Pan 等,2020)。国内高校与企业也十分重视模仿学习在自动驾驶领域的研究。清华大学的Wu 等人(2019)结合模仿学习进行水下无人设备训练。浙江大学的Li 等人(2020)探究了用于视觉导航的基于无监督强化学习的可转移元技能;Wang等人(2021)探究从分层的驾驶模型中进行模仿学习(如图7 所示);百度公司的Zhou 等人(2021)使用模仿学习实现自动驾驶。北京大学的Zhu和Zhao(2022)针对深度强化学习与模仿学习在自动驾驶领域的应用进行了综述。

图7 通过IL训练的自动驾驶智能体执行路径规划与驾驶行为(Wang等,2021)Fig.7 Autonomous driving agent trained by IL performs path planning and driving(Wang et al.,2021)((a)straight;(b)turn;(c)stop)
近年来,模仿学习也直接用于图像处理,在图形图像领域发挥出独特的价值。Toth等人(2018)探究模仿学习在心脏手术的3D/2D 模型与图像配准上的应用。Kläser 等人(2021)研究模仿学习在改进3D PET/MR(positron emission tomography and magnetic resonance)衰减校正上的应用。北京航空航天大学的Xu 等人(2021)探究了生成对抗模仿学习在全景图像显著性预测上的应用。
在其他领域,模仿学习也有着广泛的应用,包括电子有限集模型预测控制系统(Novak和Dragicevic,2021)、云机器人系统(Liu等,2020a)、异构移动平台的动态资源管理(Mandal 等,2019)、多智能体合作环境中的应用(Hao 等,2019)、信息检索(Dai 等,2021)、移动通信信息时效性(Wang 等,2022)、黎曼流形(Zeestraten 等,2017)、运筹学(Ingimundardottir和Runarsson,2018)以及缓存替换(Liu等,2020b)等。
4 国内外研究进展比较
为比较当前国内外模仿学习及相关领域的总体科研水平,本文调研了该领域在英文核心期刊及重要会议上的论文发表情况(统计数据由Aminer 提供),如图8 和图9 所示。图8 反映了相关领域科研热度的总体发展趋势,3 条曲线分别对应论文、专利和项目产出数量依据年份做归一化后的分布(2022年由于统计数据暂未完全公布不做参考)。可以看出,3条曲线总体都呈现上升趋势,并于2020年前后达到顶峰,后随新冠疫情与互联网金融降温而略有下降。图9 展示了各国论文发表情况,由下往上色块分别对应中国、美国和德国等。可以看出,从2019 年开始,国内论文发表量超越美国并稳居世界第一,且从同年开始,国内论文发表量占到世界总量的一半,国内在模仿学习领域的研究取得了突飞猛进的发展。图9 右侧为统计到的各国论文发表总数,截止2021 年,国内在相关领域的论文发表总量已经达到世界第一。不过差距依然存在,特别是从学者数量以及论文平均引用量来看(如图10 所示),国内论文平均引用量远低于美国,有待进一步提升。

图8 模仿学习及相关领域整体研究热度趋势Fig.8 Overall research trends in imitation learning and related fields
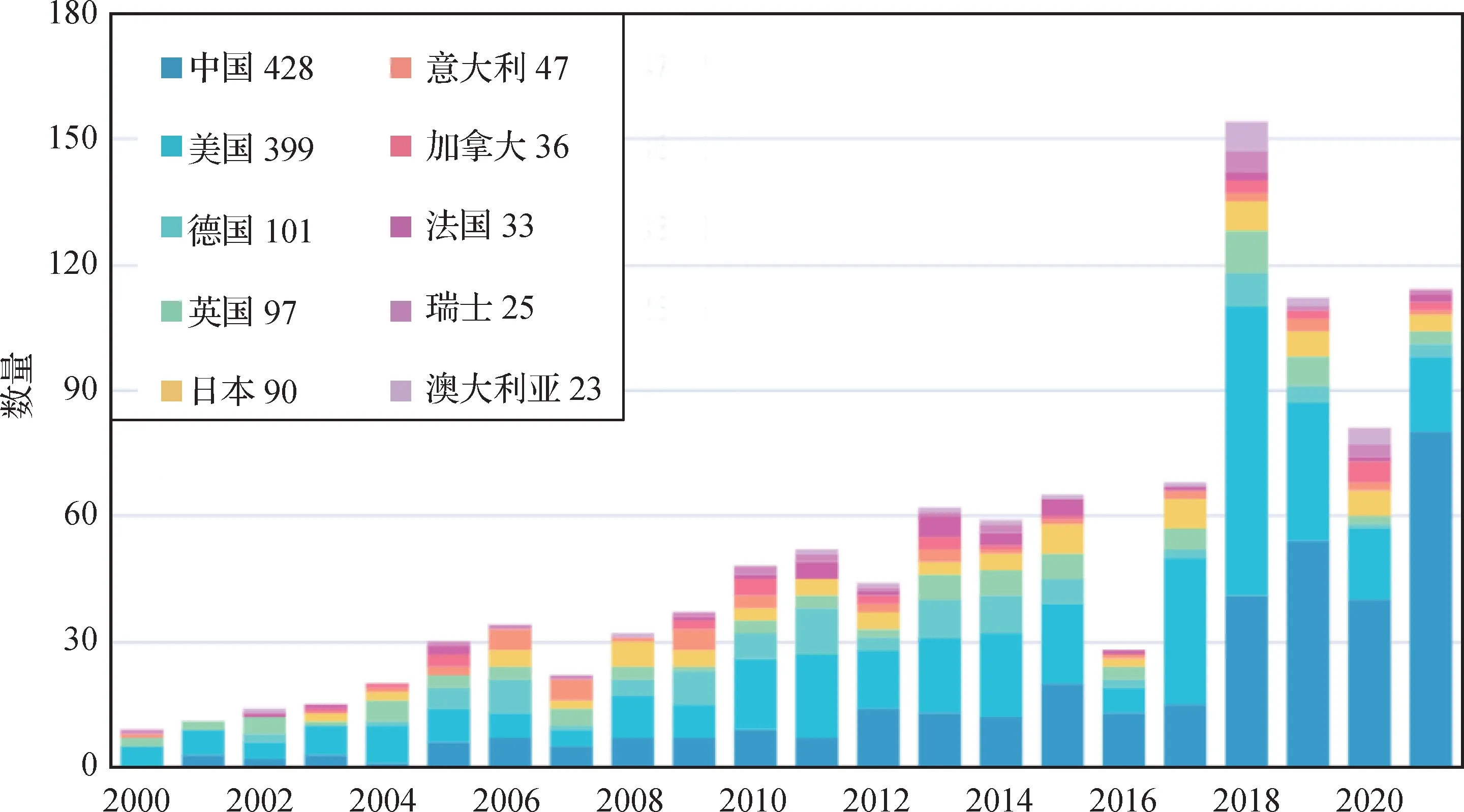
图9 各国论文发表量情况Fig.9 The number of papers published by each country

图10 各国研究实力比较Fig.10 Comparison of research strength from different countries
依照研究的侧重点,模仿学习及相关领域的工作可以分为理论类工作与应用类工作。理论类工作主要研究模仿学习基础理论、算法性能、采样复杂度、算法收敛性和算法上下界等。通常涉及大量的数学证明与严格的数学推导。在这方面,国际级的研究成果(Buccino 等,2004;Ross 等,2011;Ho 和Ermon,2016)主要来自于国外高校,其中较为有代表性的是美国顶尖大学的研究。相比之下,国内在模仿学习理论方面的研究处于发展阶段,国内一些高校也提出了一些较为新颖的模仿学习算法与框架(Liu 等,2021a;Xu 等,2021),但这些研究相对来说聚焦于特定领域,泛化性有待提高。不过从国际顶尖学术会议的投稿数据来看,近年来国内越来越多的课题组也开始关注模仿学习理论方面的研究,整体呈现追赶态势。应用类工作主要研究模仿学习在具体任务上的应用,例如游戏AI、机器人控制、自动驾驶和图像处理等。该类工作的显著特点是算法以完成具体任务为目标。在这方面,除国外顶尖高校以外,头部互联网公司(如谷歌、微软和脸书)也贡献了相当多的杰出成果(Silver 等,2016;Vinyals 等,2019)。虽然国内研究在模仿学习理论方面有所欠缺,但就应用方面,国内高校、科研机构以及相关企业基本能达到行业头部水平(Ye 等,2020;Zhou 等,2021),在一定程度上反映了我国互联网技术的蓬勃生命力与发展潜力。
聚焦于国内研究,浙江大学钱徽团队长期研究优化与控制问题,后将该领域的知识与模仿学习相结合。该团队的Jin 等人(2011)提出了一种处理在线逆强化学习的增量方法,并研究了该方法的收敛性、误差界与悔恨度界。北京工业大学的阮晓钢团队,长期进行模仿学习与机器人控制领域相结合的研究,取得了不错的进展。其他团队及相关工作在前文已做过介绍,不再赘述。
5 结语
强化学习是目前人工智能研究领域最主流的方向之一,而模仿学习又是其最为重要的分支。本文调研模仿学习的最新进展,将该领域与生成式对抗神经网络、最优传输和图像图形学等领域的关联系统性地呈现,对相关领域的研究以及学科融合都有着重要的意义。本文首先回顾了传统模仿学习的3种主要范式,包括行为克隆,逆强化学习与对抗式强化学习;随后调研了模仿学习领域的最新进展,主要概括为从观察量进行模仿学习与跨领域模仿学习;最后总结了模仿学习在游戏AI、机器人控制、自动驾驶和图像图形学等领域的重点应用。
模仿学习面临的诸多挑战,本文在给出一系列解决方案的同时,提出亟待探索、解决的开放性问题。1)在专家利用方面。包括:如何处理专家数据集中的非最优、无用和有害数据;对策略分布不均匀、复杂动作稀疏的专家示范如何进行模仿学习;从多专家跨多领域进行模仿学习,如何对不同形式的专家数据进行融合以及如何从融合后的专家示范学习;如何从人类的非最优策略中获取经验。2)从学习任务角度。包括:如何进行任务维度扩充;如何处理状态空间更大、动作更多以及难度更高的任务。3)从性能提升角度。包括:如何构建更加实用化的模仿学习策略相似性评价标准;如何构建更加高效鲁棒的学习算法;如何构建模仿学习方法统一测评基准,系统化比较不同方法之间的性能差异以支撑起性能提升的验证。
模仿学习在机器人控制乃至整个人工智能落地领域都预示了极其广阔的前景,对上述问题的进一步深入研究有着重要意义。这里给出一些参考性意见:1)相较于早些年机器学习过于“黑盒”的设定,强化学习涉及大量的数学证明与推导,其对数理统计、概率论与随机过程、矩阵分析以及最优化理论等基础数学都有着较高的要求。因此对于未来的研究工作,更应该关注模仿学习的数学本质,减少在细枝末节上的精力投入。2)以大数据驱动的人工智能掀起了人工智能革命,也带来了数据量、存储量和计算量的挑战。普通研究者无法承担处理如此庞大的数据开销。模仿学习起源于人类模仿的本能,而人类只需要少量的样本和能源就能完成学习与迭代,因此对于模仿学习的深入探究,在数据驱动的同时,也要着眼于有限专家示范下取得的性能提升。
科学的进步伴随着时代的发展。目前人工智能正走向新一轮的高潮,乘上此趟发展的列车,对模仿学习乃至整个强化学习领域都有着重要意义。
致 谢本文由中国图象图形学学会视觉感知智能系统专业委员会组织撰写,该专委会链接为http://www.csig.org.cn/detail/2449。
猜你喜欢
计算机应用(2022年2期)2022-03-01
青年生活(2019年23期)2019-09-10
小学生作文(低年级适用)(2019年5期)2019-07-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
宠物世界·猫迷(2016年3期)2016-04-23
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年3期)2015-07-07
中共南宁市委党校学报(2015年4期)2015-02-28
中国音乐教育(2014年7期)2014-02-06
杭州科技(2013年5期)2013-03-11
