
基于高分辨率网络的轻量型人体姿态估计方法
2023-06-15 23:55:14朱宽堂吕晔
计算机时代 2023年6期
朱宽堂 吕晔
摘 要: 在高分辨率网络(HRNet)的基础上,提出一种融合Ghost卷积的轻量型高分辨率网络(GLHRNet)。首先使用Ghost卷积模块和极化自注意力(PSA)模块在HRNet中构建新的残差块结构,新的残差块结构可以在减少网络模型参数量和计算量的同时,建模高分辨率图像的长距离依赖关系。接着在新网络模型中引入IBN-Net的设计思想,在新网络模型的浅层同时使用批量归一化和实例归一化,为网络模型引入外观不变性,减小光照变化问题对模型的影响。算法在COCO人体姿态估计数据集上的实验结果表明,与HRNet相比新网络模型的参数量降低了36.1%,计算量降低了35.2%,人体姿态估计的平均准确率提高了1.4个百分点。
关键词: 人体姿态估计; 高分辨率网络; Ghost卷积; 极化自注意力; 批量归一化; 实例归一化
中图分类号:TP391.4 文献标识码:A 文章编号:1006-8228(2023)06-69-06
Lightweight human pose estimation method based on high-resolution network
Zhu Kuantang, Lv Ye
(Lenovo (Shanghai) Information Technology Co., Ltd., Shanghai 201203, China)
Abstract: Based on HRNet, a lightweight HRNet fused with Ghost convolution is proposed. Firstly, a new residual block structure is constructed in HRNet using Ghost convolution module and PSA module, which can model the long-distance dependence of high-resolution images while reducing the number of network model parameters and FLOPs. Then, the design idea of IBN-Net is introduced in the new network model, and both batch normalization and instance normalization are used in the shallow layer of the new network model, which can introduce appearance invariance for the network model and reduce the influence of lighting changes on the model. The experimental results on COCO human pose estimation dataset show that compared with HRNet, the number of parameters of the new network model is reduced by 36.1%, the FLOPs is reduced by 35.2%, and the average accuracy of human pose estimation is improved by 1.4 percentage points.
Key words: human pose estimation; high-resolution network (HRNet); Ghost convolution; polarized self-attention (PSA); batch normalization; instance normalization
0 引言
人体姿态估计是对图片中眼睛、手肘等人体关键点的位置估计。其对于描述人体姿态、人体行为等至关重要,有许多的计算机视觉任务都是以人体姿态估计任务作为基础的,如行为识别、行为检测等[1]。
人体姿态估计任务拥有以下几个困难点或挑战。①尺度问题,图片中不同人体的尺度可能不一样。②姿态问题,图片中不同人体的姿态会是多种多样的。③图片遮挡问题,图片中人体的关键点可能被遮挡,一般可分成被本人的其他部位遮挡、被其他的人体遮挡、被其他物体遮挡三种。④光照问题,不同环境中的光照可能不同,这可能会改变图像中人体的外观。⑤实用性问题,对于实时检测人体姿态的场景,算法对于模型的精度和大小都有一定的要求。
虽然高分辨率网络的精度是比较高的,但是其参数量和计算量也是比较高的,若要将其部署在嵌入式设备上是比较困难的。为了解决此问题,本文将Ghost卷积模块和极化自注意力模块融合进HRNet原有的残差块结构中得到新的GLneck模块和GLblock模块,新的残差块结构能在减少网络参数量和计算量的同时进一步提高网络的精度。针对光照问题对人体姿态估计任务的影响,接着将IBN-Net的设计引入新的网络模型中,让网络模型提取的特征具有外观不变性,从而进一步提高模型的泛化能力。
1 相关工作
2014年,Google提出了单人姿态估计算法DeepPose[2],其第一次将卷积神经网络引入人体姿态估计任务,该算法直接回归关键点的数值坐标,模型虽然不能得到很好的空间泛化能力,但是相对于传统算法取得了良好的效果。Tompson等[3]针对DeepPose的缺点,提出了基于热图(Heatmap)回归的人体姿态方法,该方法通过高斯函数,将姿态估计任务从回归问题转变为检测问题,其可以保留关键点坐标的空间信息,从而增加模型的空间泛化能力和算法的精度,之后大部分的人体姿态估计算法都使用基于热圖回归的方法。2016年,Newell等[4]提出了堆叠沙漏网络(Stacked Hourglass Networks, SHN),该网络由多个类似沙漏的结构堆叠而成,每个沙漏结构将特征图先下采样到低分率,再上采样恢复到高辨率,通过跨层连接将不同尺度的特征进行融合,从而提高人体姿态估计的精度。
单人姿态估计是多人姿态估计方法的基础,多人姿态估计有两种实现方法,一种是自顶向下(top-down)的多人姿态估计方法,另一种是自底向上(bottom-up)的多人姿态估计方法。自顶向下的多人姿态估计方法是先使用行人检测器检测出图片中所有行人的边界框,然后对每个行人进行单人姿态估计。2017年,旷视科技[5]提出的级联金字塔网络 (Cascaded Pyramid Networks,CPN),该算法使用GlobalNet定位简单的关键点,然后使用RefineNet集合GlobalNet提取的特征定位困难的关键点。2018年,微软亚洲研究院[6]提出了一个用于人体姿态估计任务的简单基线(Simple Baseline),该算法使用类似堆叠沙漏网络的结构,取消了跳跃连接,并使用反卷积操作实现上采样,模型的结构简单明了,却取得了当时最好的效果。2019年,微软亚洲研究院又提出了高分辨率网络HRNet[7],其是在以堆叠沙漏网络为代表的一系列多分辨率融合网络的进一步改进。整个HRNet模型采用并行子网的方式,实现了多个分辨率特征图的充分融合,增强了特征图的特征信息,但是,由于模型始终保持高分辨率特征图,在提高预测人体关键点精度的同时,也增加了模型的参数量和运算复杂度[8]。
自底向上的多人姿态估计方法是先检测出图片中所有的行人关键点,然后将这些关键点分组,进而组装成行人。2017年,卡梅隆大学的团队提出了多阶段的实时姿态估计算法Openpose[9],该算法同时预测部分置信图(Part Confidence Maps)和部分关系场(Part Affinity Fields),前者预测行人的关键点位置,后者在关键点之间建立的一个向量场,最终使用二分图最大权匹配算法来对关键点进行组装。Newell等人[10]提出了依赖于联系嵌入向量(Associative Embedding)的方法进行关键点分组,该算法为每一个关键点热图对应分配一个标记热图(TagHeatmap),其将每个检测与同一组中的其他检测相关联。
2 模型框架
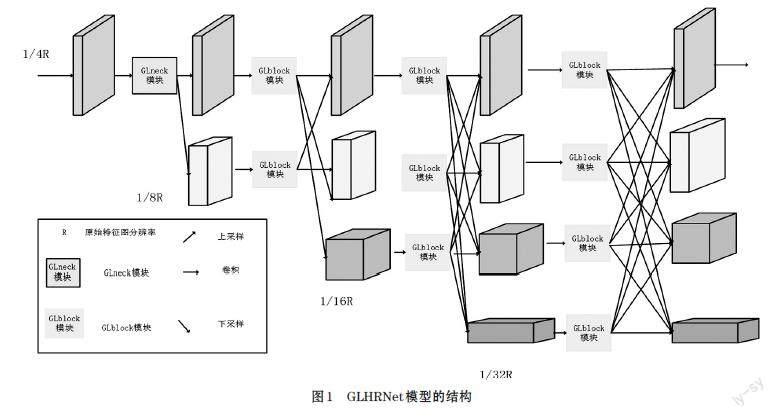
人体姿态估计是位置敏感的计算机视觉任务,为了使关键点的位置更加精准,维持高分辨率的特征图是常用的策略,一般是先将特征图下采样得到强的语义信息,然后再上采样将特征图恢复为高分辨率的特征图,从而得到关键点的位置信息,但是很多有用的信息会在下采样和上采样的过程中丢失。为了避免这种损失,本文以HRNet作为骨干网络,在此基础上构建了新的模型GLHRNet。新模型使用Ghost模块和极化自注意力模块构建新的残差块结构,并在新的网络模型中融入IBN-Net设计思想,其结构如图1所示。
输入图像首先经过二个卷积核大小为3×3的卷积层,将其分辨率变成原图大小的1/4、通道数变成64。接着将处理后的特征图送入由四个Stage组成的模型结构,在每个Stage中分别使用1、2、3、4个不同分辨率和通道数的平行分支得到不同分辨率的特征图,在中间进行不同分辨率特征的融合,从而进行不同分支之间的信息交互,得到的高分辨率特征图能同时含有很强的语义信息和位置信息。第一个Stage由四个GLneck模块组成,后三个Stage分别由四个GLblock模块组成。具体实现的模块有Ghost、极化自注意力、IBN-Net、GLneck和GLblock。
2.1 Ghost卷积
在卷积神经网络中,某一层输出的特征图中有许多是相似的,以前的想法是这些特征图是冗余的,HAN等人[11]从另一个角度出发,认为这些相似的特征图(Ghost对)可以增强网络模型的特征提取能力,不去避免产生相似的特征图,而是使用简单的线性操作获得更多的相似特征图。
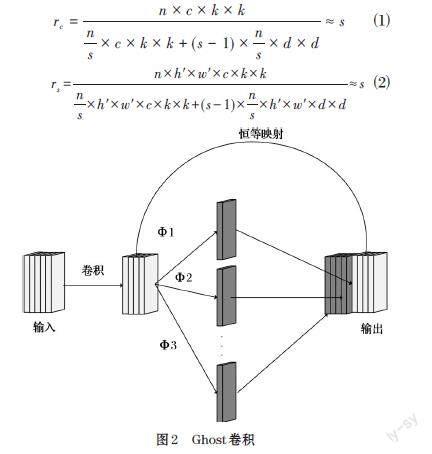
假设普通卷积的输入数据是[X∈Rh×w×c],c代表输入数据的通道数,h和w分别是输入数据的高和宽,输出数据是[Y∈Rh'×w'×n],n是輸出数据的通道数,h′和 w′代表输出数据的高和宽,卷积滤波器是[f∈Rc×k×k×n],k×k 代表卷积滤波器f的卷积核大小,此时每秒浮点运算量是[n×h'×w'×c×k×k],普通卷积的参数量是[n×c×k×k],由于滤波器和通道数非常大,因此 FLOPs通常高达数十万[12]。
为了得到与普通卷积相同大小的输出,Ghost卷积将普通的卷积操作分成了两个部分,其结构如图2所示。第一部分是通过普通卷积得到通道数为m的本征特征图(Intrinsic feature maps),m的值是小于等于n的,第二部分是使用线性操作将本征特征图变成s个Ghost特征图,最后将两部分得到的本征特征图和Ghost特征图拼接在一起作为Ghost卷积的输出结果。
为了比较Ghost卷积和普通卷积的性能,在以上基础上,假设线性变换的卷积核大小为d。普通卷积和Ghost卷积的参数量对比如公式⑴所示,普通卷积和Ghost卷积的计算量对比如公式⑵所示,从公式中可知,Ghost卷积的参数量和计算量都只有普通卷积的1/s。
[rc=n×c×k×kns×c×k×k+(s-1)×ns×d×d≈s] ⑴
[rs=n×h'×w'×c×k×kns×h'×w'×c×k×k+(s-1)×ns×h'×w'×d×d≈s] ⑵
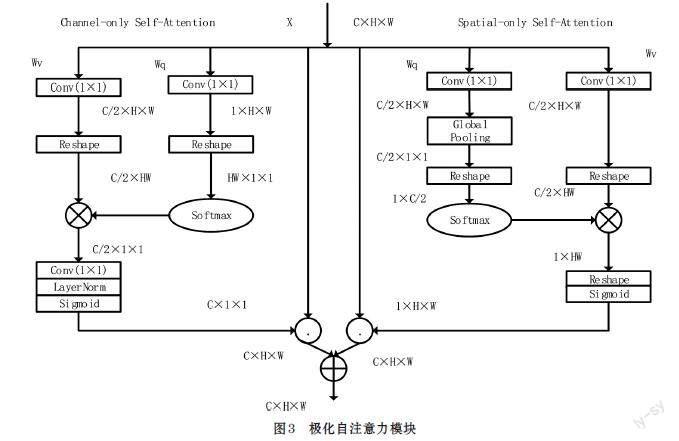
2.2 极化自注意力
针对人体姿态估计任务,极化自注意力(Polarized Self-Attention,PSA)[13]是结合空间注意力和通道注意力的双重注意力机制,在空间维度和通道维度上,都没有进行很大程度的压缩,图像的信息损失比较小,其结构如图3所示。极化自注意力由两个分支组成,一个分支是通道维度的自注意力机制,另一个分支是空间维度的自注意力机制,极化自注意力机制结构的最终结果由两个分支的输出融合而成。在通道分支中,输入特征X经过两个1×1的卷积分别得到特征Q和特征V,特征Q的通道维度被压缩为1,而特征V的通道维度只被压缩为原来的一半,接着使用softmax对Q的信息进行增强,让两个特征进行矩阵乘法,然后经过1×1卷积、LN和Sigmoid函数将特征通道恢复到原本的维度,并归一化到0到1之间,得到通道分支的特征权重,最后将特征权重乘以原特征图得到通道分支的输出。在空间分支中,与通道分支的操作类似,输入特征X同样经过1×1的卷积得到特征Q和特征V,不同的点在于,特征Q经过全局池化操作将特征图压缩为1×1大小,两个特征进行矩阵乘法之后经过reshape和sigmoid函数得到空间分支的特征权重,最后将同样特征权重乘以原特征图得到通道分支的输出。整个极化自注意力模块的输出是从两个分支输出的融合得到的。
相比于其他使用全连接层和卷积层得到注意力权重的注意力机制,极化自注意力机制使用自注意力结构得到注意力权重,可以充分利用自注意力结构的建模能力,且其他注意力机制一般只使用softmax函数和sigmoid函数,极化自注意力机制在两个分支都同时使用了softmax函数和sigmoid函数,从而可以拟合细粒度回归结果的输出分布。整个结构只增加了少量的计算量,可以建模高分辨率图像的长距离依赖关系。
2.3 IBN-Net
数据集通常是不同时间、不同环境中采集的,因现实场景复杂导致数据集中不同图像的光照可能不一样。在人体姿态估计任务中,光照变化可能导致人体的外观发生变化。2018年,Pan等人[14]提出了IBN-Net网络结构,该结构可以很容易的融入到ResNet等主流网络结构中,其可以在不增加模型计算量的同时,保存内容相关信息,为网络引入外观不变性,提高模型的泛化能力。批量归一化(BatchNormalization,BN)[15]是将每个Batch的数据归一化,其可以让模型保存更多的内容相关信息,并学习到有用的特征信息,但是会影响网络在外观上的转换,一般用于判别模型。实例归一化(InstanceNormalization,IN)[16]是将每张图像归一化,其可以让模型学习到具有外观不变性的特征信息,但是会损失图像中有用的特征信息,一般用于生成模型。IBN-Net研究发现如果同时将批量归一化和实例归一化应用在网络模型的浅层,只将批量归一化应用在网络的深层,可以让模型同时具有两种归一化操作的优点,避免其缺点。
2.4 GLneck模块和GLblock模块
本文将HRNet中Bottleneck模块和Basicblock模块重新改造为GLneck模块和GLblock模块,GLblock模块和GLneck模块的结构分别如图4(a)和图4(b)所示。首先使用Ghost卷积替换原本残差块结构中的普通3×3卷积,然后将PSA模块设置在第一个Ghost卷积后面,从而在减少模型参数量和计算复杂度的基础上,建模高分辨率图像的长距离依赖关系,增加模型的精度。为了降低光照变换对模型的影响,在模型中引入IBN-Net的设计思想,将批量归一化和实例归一化同时作用在模型的浅层能让模型提取的特征具有外观不变性且保存内容相关信息,所以本文只在Stage1的四个GLneck模块的第一个1×1卷积后面同时使用批量归一化和实例归一化,具体使用方法将把GLneck中第一个1×1卷积输出的特征按通道平均分成了两部分,分别进行批量归一化和实例归一化。
3 实验和结果分析
本文算法由Pytorch框架实现的,其实验是在64位Windows11系统、英伟达3070Ti的GPU上进行的。在COCO人体姿态估计数据集上进行算法的训练和测试。训练时,将数据集中的人体目标裁剪出来,将其缩放成固定的256×192大小,使用Adam优化器训练210个epoch,模型的初始学习率是1e-3,在第170个epoch和第200个epoch降低为之前的0.1倍,模型结构的基本通道数设置为32。测试使用COCO数据集的验证集,训练和测试的批量大小都设置为32。
3.1 数据集
COCO(Common Objects in COntext)人体姿态估计数据集[17]来源于微软举办的姿态估计挑战赛,数据集内含有超过200000张样本图片和250000个人体目标,训练集有118287张图片,验证集中有5000张图片,测试集中有33619张图片。完整的人体标注了17个姿态关键点,按顺序从0到16分别是:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左肘、右肘、左手腕、右手腕、左臀、右臀、表示左膝、右膝、左脚踝、右脚踝。并用mask标明关键点的状态,0表示没有标注,1表示标注了但不可见,2表示标注了且可见。
3.2 评估标准
COCO数据集使用平均准确率(Average Precision,AP)作为评价标准,其是根据关键点相似度(Object Keypoint Similarity,OKS)计算得到的,关键点相似度表示两个关键点之间的相似度,其如公式⑶所示。
[OKS=iexp(-d2i2s2k2i)δ(vi>0)iδ(vi>0)] ⑶
其中,[δ(vi>0)]表示数据集中这个关键点i是被标注的,[di]表示预测关键点与标注关键点之间的欧式距离,[s]是目标尺度因子,[ki]是关键点i的归一化因子。
在计算COCO数据集的评价指标时,若某个关键点的OKS大于一定的阈值,则这个关键点是正例。AP50表示关键点相似度阈值为0.5时预测关键点的准确率, AP75表示關键点相似度阈值为0.75时预测关键点的准确率,AP表示关键点相似度阈值为(0.5、0.55…0.90、0.95)时所有预测关键点准确率的平均值, APM表示人体尺度为中等时预测关键点的准确率, APL表示人体尺度为大时预测关键点的准确率,AR表示关键点相似度阈值为(0.5、0.55…0.90、0.95)时的平均召回率。
3.3 实验仿真与结构分析
3.3.1 与其他先进人体姿态估计算法的比较
为了验证本文算法的有效性,选择几个经典先进的人体姿态估计算法与本文算法进行比较,这些先进的人体姿态估计算法分别是Hourglass[4]、CPN[5]、CPN+ OHKM[5]、SimpleBaseLine[6]、HRNet[7]和SCANet[8],其结果如表1表所示。
如表1,在输入图像尺寸同为256×192情况下,本文提出的网络模型的参数量只有18.2×106且计算量只有4.6GFLOPs,相比于高分辨率网络HRNet,本文算法的参数量降低了36.1%,计算量降低了35.2%。本文算法的参数量和计算量降低了,而算法的平均准确率AP值进一步提升了1.4个百分点,其他设定OKS为不同阈值的AP值和平均召回率均有一定程度的提升。与Hourglass[4]、CPN[5]、CPN+OHKM[5]、SimpleBaseLine[6]和SCANet[8]网络模型相比,本文网络模型的平均准确率分别提高了8.9、7.2、6.4、5.4和3.5个百分点,证明了本文算法的先进性。
3.3.2 消融实验
为了验证本文算法加入的各个模块的有效性,本节将只把Ghost卷积模块融入HRNet定义为新结构1,将同时把Ghost卷积模块和极化自注意力机制模块融入HRNet定义为新结构2,在COCO数据集上进行相关消融实验,其结果如表2所示。
从表2可知,相比于高分辨率网络HRNet,新结构1的参数量从28.5×106降低到15.8×106,平均准确率却从74.4%降低到73.1%,虽然平均准确率降低了,但是模型的参数量也降低了,证明了Ghost卷积模块降低模型参数量的能力。相比于新结构1,新结构2的参数量从15.8×106增加到18.2×106,平均准确率从71.1%增加到74.9%,证明了Ghost极化自注意力模块可以在只增加少量模型参数量的情况下增加模型的精度。相比于结构二,GLHRNet的平均准确率从74.9%提升到75.8%,证明了IBN-Net的设计思想可以进一步提升模型的泛化能力。
4 结束语
本文针对如何在降低高分辨人体姿态估计网络模型参数量和计算复杂度的同时,提高模型精度的问题,使用Ghost卷积模块和极化自注意力模块重新构建高分辨率网络的残差块结构,并在此基础上,在模型中引用IBN-Net的思想,提升模型对图像外观变化的适应性,进一步提高模型的泛化能力,最后在COCO数据集中做了相关实验,证明了本文的算法的有效性。如何在大幅降低模型参数量的情况下,进一步提高人体姿态估计模型的精度是今后研究的重点。
参考文献(References):
[1] Zhao X, Liu Y, Fu Y. Exploring discriminative pose sub-
patterns for effective action classification. In: Proc. of the ACM Multimedia. Barcelona:ACM,2013:273?282
[2] TOSHEV A,SZEGEDY C. DeepPose:human pose
estimation via deep neural networks [C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2014:1653-1660
[3] Tompson J J, Jain A, LeCun Y, et al. Joint training of a
convolutional network and a graphical model for human pose estimation. Advances in neural information processing systems,2014,27:1799-1807
[4] Newell A, Yang K, Deng J. Stacked hourglass networks for
human pose estimation. European conference on computer vision. Springer, Cham,2016:483-499
[5] Chen Y, Wang Z, Peng Y, et al. Cascaded pyramid
network for multi-person pose estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018:7103-7112
[6] Xiao B, Wu H, Wei Y. Simple baselines for human pose
estimation and tracking. In: Proceedings of the European Conference on Computer Vision (ECCV),2018:466-481
[7] Sun K, Xiao B, Liu D, et al. Deep high-resolution
representation learning for human pose estimation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2019:5686-5696
[8] 李坤,侯慶.基于注意力机制的轻量型人体姿态估计[J].计算
机应用,2022,42(8):2407-2414
[9] Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2d
pose estimation using part affinity fields. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017: 7291-7299
[10] Newell A, Huang Z, Deng J. Associative embedding:
End-to-end learning for joint detection and grouping. Advances in Neural Information Processing Systems,2017:2277-2287
[11] HAN K,WANG Y H,TIAN Q,et al. GhostNet:more
features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2020:1577-1586
[12] 孫琪翔,何宁,张聪聪,等.基于轻量级图卷积的人体骨架动
作识别方法[J].计算机工程,2022,48(5):306-313
[13] Liu H, Liu F, Fan X, et al. Polarized self-attention:
towards high-quality pixel-wise regression[J]. arXiv preprint arXiv:2107.00782,2021
[14] Pan X, Luo P, Shi J, et al. Two at once: Enhancing
learning and generalization capacities via ibn-net[C]//Proceedings of the European Conference on Computer Vision (ECCV),2018:464-479
[15] Ioffe S, Szegedy C. Batch normalization: Accelerating
deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR,2015:448-456
[16] Ulyanov D, Vedaldi A, Lempitsky V. Instance
normalization: The missing ingredient for fast stylization[J]. arXiv preprint arXiv:1607.08022, 2016.
[17] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft
COCOcommon objects in context[C]// Proceedings of the 2018 European Conference on Computer Vision. Cham:Springer,2014:740-755
