
基于方面级情感分类的语义挖掘模型
2023-06-15 21:11刘璐瑶张换香张景惠丽峰
计算机时代 2023年6期
关键词:注意力机制
刘璐瑶 张换香 张景 惠丽峰
摘 要: 方面级情感分类旨在确定句子中特定方面的情感极性。获取深层次方面级语义情感信息和方面级标记数据的缺乏是本领域研究的两个难点。本文提出一种基于语义注意力机制和胶囊网络的混合模型(SATTCap)。运用方面级归纳式迁移方式,将易获取的文档级评论知识中的情感语义迁移到方面级情感语义中,辅助方面级情感分类。另外基于重构语义依存的注意力机制提取深层次特征信息,采用方面路由方法,将深层次的方面级语义表示封装到语义胶囊中,然后采用Softmax预测。在公共数据集SemEval2014上对本文方法进行评估,结果表明,该模型在方面级情感分类任务上的表现是有效的。
关键词: 方面级; 情感分类; 注意力机制; 胶囊网络
中图分类号:TP18 文献标识码:A 文章编号:1006-8228(2023)06-65-04
Semantic mining model based on aspect-level sentiment classification
Liu Luyao1, Zhang Huanxiang2, Zhang Jing3, Hui Lifeng2
(1. Inner Mongolia University of Science and Technology, School of Information Engineering, Baotou, Inner Mongolia 014010, China;
2. Inner Mongolia University of Science and Technology, School of Innovation and Entrepreneurship Education;
3. Inner Mongolia University of Science and Technology, School of Science)
Abstract: Aspect-level sentiment classification aims to determine the polarity of a particular aspect of a sentence. Obtaining deep aspect-level semantic sentiment information and the lack of aspect-level labeled data are two difficulties in this field. In this paper, a hybrid model based on semantic attention mechanism and capsule network (SATTCap) is proposed. The aspect-level inductive transfer method is used to transfer the sentiment semantics from easily accessible document-level comment knowledge to aspect-level sentiment semantics, which assists aspect-level sentiment classification. In addition, the deep feature information is extracted based on the attention mechanism of reconstructed semantic dependency. The deep aspect-level semantic representation is encapsulated into the semantic capsule by the aspect routing method, and then Softmax is used for sentiment prediction. The proposed method is evaluated on the public dataset SemEval 2014. Experimental results show that it is effective in the performance of aspect-level sentiment classification task.
Key words: aspect-level; sentiment classification; attention mechanism; capsule network
0 引言
方面級情感分析是细粒度情感分类任务。目的是预测句子相对特定方面的情感极性。传统的方面级情感分类任务通常忽略了词间语义的重要性,难以准确地对方面级文本进行分类。鉴于此,本文提出了一种基于语义注意力机制和胶囊网络的方面级情感分类模型(SATTCap)。通过句法依赖关系获得句子的局部注意信息,可有效地提取句子的特征信息。进一步,为获取深层次方面级语义情感信息,本文提出基于重构语义依存的注意力机制来提取深层次特征信息,进行方面级情感分类。此外,基于方面级标记数据的缺乏是本领域研究的一个难点,因此,本文从在线网站轻松获取文档级标记的数据,将文档级评论知识中的情感语义迁移到方面级情感语义中,辅助方面级情感分类。在两个公开数据集上评估了该模型,实验结果证明了我们的模型的有效性。
1 相关工作
近年来,一些基于深度学习的方面级情感分类方法被提出,取得了良好的结果。例如,Tang等人[1]提出一种目标依赖LSTM (TD-LSTM)模型来捕捉方面词与其上下文之间的关联。Li等人[2]提出一种迁移网络,该网络从双向RNN层产生信息中提取和方面相关的特征。为进一步考虑词间的语义相关性。Ma等人[3]将常识知识结合到深度注意神经序列模型中以提升方面级情感分析性能。Bao等人[4]在注意模型中利用词典信息强化了关键信息,使模型变得更灵活和健壮。Pu等人[5]设计了一种以多任务学习方式将依赖知识转移到方面级情感分析的注意机制模型。
许多研究将胶囊神经网络及图卷积网络模型运用到了情感分析中。如Gong等人[6]在胶囊网络的基础上设计了两种动态路由策略,来获得上下文表征。Chen等人[7]采用胶囊网络及迁移学习来共同学习方面上下文信息。Chen等人[8]结合词汇依赖图通过自注意网络的潜在图的信息获得方面表征。Hou等人[9]将依赖树等句法结构与图神经网络结合,通过依赖关系学习方面情感信息。He等人[10]基于LSTM模型提出了一个多任务框架,将方面级任务与文档级任务结合在一起。受此启发,本文运用归纳迁移方法,将易获取的文档级评论知识中的情感语义迁移到方面级情感语义中,辅助方面级情感分类。
2 情感分析模型
2.1 模型定义
给定句子[S=w1,…,wa,…,wL],其中[L]表示单词数量,[wa]是句子的一个方面,方面级情感分类任务目的是确定句子相对于方面[wa]的情感极性。
2.2 SATTCap模型
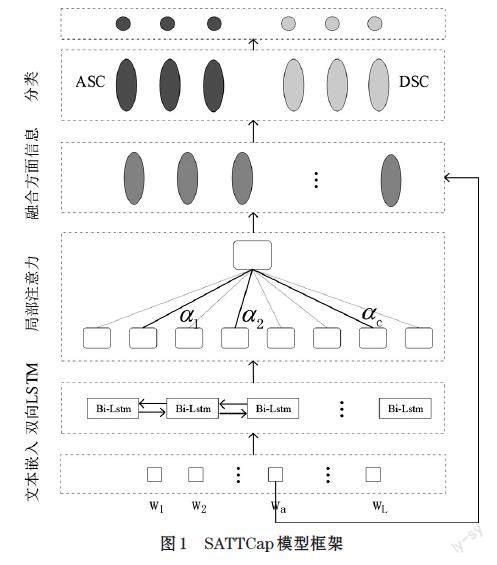
SATTCap模型如图1所示,由文本嵌入、特征提取、方面信息融合和情感预测四部分构成。文本嵌入是将句子转换成输入向量。特征提取是通过BiLSTM(双向长短期记忆)和局部Attention提取重要的上下文特征。方面信息融合旨在根据上下文融合卷积提取的含有方面的特征,计算上下文的方面权重。情感分类是生成类胶囊对情感极性进行预测。
2.2.1 文本嵌入
文本嵌入是将输入的句子转换成向量,本文分为单词查找层和位置查找层,這两层分别映射成两个向量列表,将其拼接形成最终的输入向量。设[Ew]为预先训练好的单词嵌入查找表,由此将句子[S]中单词序列映射成单词向量列表[e1,…,ea,…,eL]。此外使用了另一个位置查找层。对于方面级任务,通过计算从每个上下文单词到方面[wa]的绝对距离,我们可以得到[S]的附加位置序列。对于文档级任务位置序列为零序列。设[Ep]是具有随机初始化的位置嵌入查找表,位置查找层将位置序列映射到位置向量列表[p1,…,pa,…,pL]。每一个单词的最终表示形式为[xi=ei⊕pi1≤i≤L],句子的输入向量表示为[X=x1,…,xL]。
2.2.2 特征提取
⑴ 句子编码层
为了获取句子的上下文信息,通过BiLSTM网络,对输入句子进行编码。对于前向LSTM,给出隐藏状态[ht-1]和单词嵌入[xi],计算出隐含状态[ht=lstmxi,ht-i]。后向LSTM与前向LSTM类似,只是输入序列相反。将二者的隐藏状态拼接,形成每个单词的隐藏状态,[ht=tanhht;ht],最终获得句子的上下文表征为[H=h1,…,hn]。
⑵ 基于语义距离的局部注意力层
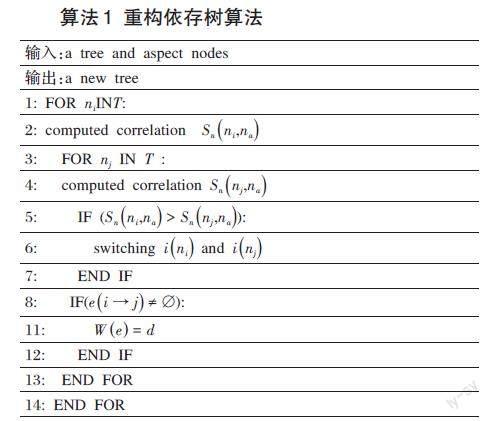
考虑到语义相关性对语义依存分析的重要性,基于传统的语义依存树中的依存关系,本文增加了节点之间的相似度信息,计算方面词及所有与其连通的词之间的相关性,根据词间相关性大小调整依存树的结构。假设依存树由[T=R,N,E]给出,其中[N]是包括根节点[R]在内的节点集合,[N=nr,n1,…,na,…,nL],其中[na]表示方面节点,[N]的每个节点[ n]包含节点信息[in=v,p,la∈N],其中[v]表示节点值,[p]表示该节点的词性,[la]表示节点相对方面节点[na]的位置。[E]是有向加权边的集合。每条[ei→j∈E]有一个权值[We=d],其中[d]表示[ei]和[ej]之间的依存关系。重构依存树的算法详见算法1,部分过程如下:
l 引入相关性函数[Snni,na=ni?nani×na]计算节点[na]其他所有节点的相关性。
l 如果[Snni,na>Snnj,na],则[ini]和[inj]进行节点信息交换。
l 对于T中任意两个节点[ni]和[nj],如果[ei→j≠?],则更新[We]。
算法1 重构依存树算法
[输入:a tree and aspect nodes 输出:a new tree 1: FOR [ni]IN[T]: 2: computed correlation [Snni,na] 3: FOR [nj] IN [T] : 4: computed correlation [Snnj,na] 5: IF ([Snni,na>Snnj,na]): 6: switching [ini] and [inj] 7: END IF 8: IF([ei→j≠?]): 11: [We=d] 12: END IF 13: END FOR 14: END FOR ]
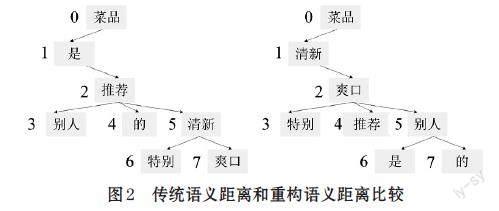
图2中,基于传统语义和基于重构语义距离在句子“菜品是别人推荐的特别清新爽口”中方面词“菜品”的比较,“清新”和“爽口”是表示情感的关键词,基于位置的距离标记分别为6和7,基于传统语义距离标记分别为5和7,基于重构语义距离标记分别为1和2,由此可见,基于重构语义的距离能够更好的整合语义信息。
引入注意力机制,选取语义距离内[C]个词[ei],[i∈1,C]计算注意力权重。[M=tanhWhHWeei⊕eN],[ α=softmaxWTM],[ r=HαT], 获得句子最终的特征为[R=r1,…,rc]。计算每个词[ei]与隐藏信息[H]的注意力权重[α=α1,…,αc],对于没有含有目标词的文档级句子,注意力权重[αi]设为1。进行[C]次迭代来获取文档级句子特征[R]。
⑶ 方面信息融合
將上一层得到的特征聚合为一组与方面相关的语义胶囊,用方面路由的方法来计算方面权重[βi=sigmoidR+T*Ea+b],[Ea]是方面嵌入,[T]是一个传递矩阵,用于将[Ea]映射为标量值和基本偏差。生成的路由权重[βi]将方面信息与其上下文相融合。
对于文档级任务,文档中没有方面信息,所以将文档级任务中的[βi]设置为1。计算得到方面路由权重[β=β1,…, βC],然后与上一层的特征信息进行元素乘法得到与方面相关的特征[M=R⊙β]。
⑷ 情感分类
引入了两种类型的类胶囊共六个。每个类胶囊分别用于计算两个任务每个类的分类概率。语义胶囊[i]生成指向类胶囊[j]的“预测向量”[uji=WijMi],[Wij]是权重矩阵,[Mi]是上一层到分类层的输入向量,将上一层生成的所有“预测向量”与耦合系数[Cij]相乘求和,获得类胶囊[j]的向量表示[Sj],最后使用非线性挤压函数,得到类胶囊[j]的最终表示[vj=squashSj]即情感预测值。
3 实验及结果分析
3.1 实验数据集
本文使用的数据集是SemEval2014 Task 4中公开的Restaurant和Laptop,分别带有三种极性标签:积极、中立、消极。20%作为测试集,剩余80%进行训练。另外,文档级数据集是Yelp、Amazon和Twitter,其所有文档都附带了五星评级(1-5)。我们设定得分<3的是消极,=3的为中立,>3的积极。每个数据集包含30000个具有平衡类标签的样本。模型中分成两种组合:{Restaurant+Yelp, Laptop+Amazon},{Restaurant+Twitter,Laptop+Twitter}。本文研究模型在各种类型的辅助信息的执行情况。表1显示了这些数据集的统计情况。
3.2 实验参数设置
本实验使用840B的Glove作为预训练的词向量,使用学习率为0.001,批量为128的Adam优化器如果在5次运行中性能没有改善,就停止训练。以准确度(Acc)和F1-score值(F1)作为评价指标,指标值越高性能越好。
3.3 实验及结果分析
为评估本文模型的有效性,我们将与基线模型ATAE-LSTM,IAN,PBAN,RAM,CEA,IARM,GCAE,TransCap进行对比。实验结果如表2所示。
本文模型在两个数据集上都优于其他基线。在基于LSTM的模型中,PBAN和IAN是注意力机制方法获得了较高的性能,IAN是通过对方面应用注意机制而不是简单地平均词嵌入来加强目标特征。GCAE是基于CNN的模型,无法捕捉上下文单词之间的长期依赖关系,表现最差。我们的模型可以有效提高评论文本情感分析的精度与准确度。另外,为了评估语义距离的有效性,以目标词为中心,在固定的[C]个窗口内按位置选择注意的词。实验结果如表3所示,可以发现基于语义距离的词注意比基于位置距离更有效。
为评估文档级任务对模型的影响,通过加载不同文档级数据,得到性能变化如表4所示。结果显示{Restaurant+Yelp, Laptop+Amazon}提供了有用的领域的知识,但它们的标签不太准确,所以影响较小。{Restaurant+Twitter, Laptop+Twitter}中的标签是手动注释的,比较可靠,性能表现明显。
4 总结
本文基于方面级情感分析任务,提出了一种基于语义注意机制和胶囊网络的混合模型。使用语义距离更好地建模局部上下文,更好的提取语义特征。引用了一个迁移学习框架,将文档中情感信息迁移到方面级任务辅助情感分类。另外采用胶囊网络中动态路由进行方面信息表示。在两个SemEval数据集的实验表明,我们的模型具有较好的性能。
参考文献(References):
[1] D. Tang, B. Qin, X. Feng, et al, Effective LSTMs for
target-dependent sentiment classification[J].Computer Science,2015:3298-3307
[2] X. Li, L. Bing, W. Lam, et al, Transformation networks for
target-oriented sentiment classification[J]. 56th Annual Meeting of the Association for Computational Linguistics, ACL, Melbourne, Australia,2018:946-956
[3] Y. Ma, H. Peng, T. Khan, et al, Sentic LSTM: a hybrid
network for targeted aspect-based sentiment analysis[J].Cogn. Comput,2018,10(4):639-650
[4] L. Bao, P. Lambert, Attention and lexicon regularized
LSTM for aspect-based sentiment analysis[C]//57th Annual Meeting of the Association for Computational Linguistics,2019:253-259
[5] L. Pu, Y. Zou, J. Zhang, et al., Using dependency
information to enhance attention mechanism for aspect-based sentiment analysis[M], Natural Language Processing and Chinese Computing-8th {CCF} International Conference,2019:672-684
[6] J. Gong, X. Qiu, S. Wang, and X. Huang. 2018.
Information aggregation via dynamic routing for sequence encoding[C]//in Conference on Computational Linguistics (COLING 2018),2018:2742-2752
[7] Z. Chen, T. Qian. Transfer capsule network for aspect level
sentiment classification[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics,2019:547-556
[8] C. Chen, Z. Teng, and Y. Zhang, Inducing target specific
latent structures for aspect sentiment classification[C]//Proceedings of the 2020 Conference on Empirical Methods in NaturalLanguage Processing,2020:5596-5607
[9] X. Hou, P. Qi, G. Wang, et al, Graph ensemble learning
over multiple dependency trees for aspect-level sentiment classification[C]//Proceedings of the 2021 Conference of the North American Chapter ofthe Association for Computational Linguistics,2021:2884-2894
[10] R. He,W S. Lee,H T. Ng, et al. Exploiting Document
knowledge for aspect-level sentiment classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,2018:579-585
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
