
基于PSO_WT与改进的CAGA_CNN算法的心音识别研究
2023-06-15 19:30李明辉赵鹏军李丕丁
计算机时代 2023年6期
李明辉 赵鹏军 李丕丁

摘 要: 为探究复杂场景下心音信号的准确识别方案,提出了基于PSO_WT与改进的CAGA_CNN算法融合的方案。首先构造PSO_WT对采集的心音数据集进行去噪;其次将去噪后的心音数据转化为波形图进行特征提取;再者基于改进的CAGA_CNN网络对心音信号进行识别。为了验证本文提出算法的有效性,进行了模型的性能分析以及基于不同的算法模型进行验证。实验结果表明,本文算法具有较好的降噪能力,以及更高的识别精度和收敛速度。
关键词: PSO_WT; CAGA_CNN; 心音识别; 智能诊断
中图分类号:TP306+.3 文献标识码:A 文章编号:1006-8228(2023)06-54-06
Research on heart sound recognition based on PSO_ WT
and improved CAGA_CNN algorithm
Li Minghui1, Zhao Pengjun2, Li Piding1
(1. School of Health Science and Engineering, Shanghai University of Technology, Shanghai 200082, China;
2. Xinhua Hospital, Affiliated to Shanghai Jiaotong University School of Medicine)
Absrtact: In order to explore the accurate recognition scheme of heart sound signals in complex scenes, a new method based on PSO_WT and improved CAGA_CNN algorithm fusion scheme is proposed. PSO_WT is constructed to denoise the collected heart sound data set, the de-noised heart sound data is converted into waveform for feature extraction, and the heart sound signal is recognized based on the improved CAGA_CNN network. The performance of the model is analyzed and verified based on different algorithm models to verify the effectiveness of the proposed algorithm. The experimental results show that it has better noise reduction ability, higher recognition accuracy and convergence speed.
Key words: PSO_WT; CAGA-CNN; heart sound recognition; intelligent diagnosis
0 引言
心血管疾病是死亡率較高的病症之一,有数据显示,全球有接近75%的国家受到心血管疾病的影响[1],美国每年死亡率中有将近34.3%的病症与心脑血管疾病有关[2,3]。在心音听诊方面,建立一套全面、完整的心音信息自动识别系统对心血管疾病的早期发现和准确治疗具有重要的研究意义[4]。随着人工智能的快速发展,智能化的诊断设备越来越符合人们的需求。
根据研究表明[5],心音信号蕴藏着大量心电图不能检测/反映出的信号,如果可以对将该信号进行充分挖掘以及整合和利用,就可以弥补医生听觉的局限性以及判断的主观性。文献[6]认为,对于冠状动脉阻塞类疾病只有当阻塞率较高时才会被检测出。对此,在对心脏相关疾病检测中,可以把心音信号作为一个重要的评价指标加以利用。
常用的心音分类数据集主要是PhysioNet/CinC2016[7]和PASCAL[8]。这两个数据集是通过不同数据采集设备以及存在不同程度的信号重叠噪声的原始数据。文献[9]基于PhysioNet数据集提出了一种轻量级的CNN网络模型,以较少的卷积层和全连接层来对心音图像数据进行特征提取。作者首先将心音图(PCG)信号分割成固定大小的窗口,并对窗口内的块信号通过时频分析转为时频图;然后对时频图进行特征提取;最后提出基于迁移学习的方式对PhysioNet数据集进行异常检测。K.Wo?k和A.Wo?k等人为了解决PASCAL数据集振幅低、噪声大等问题,基于ResNet网络对PASCAL数据集进行分类[10],其最高的识别精度只能达到59.78%。文献[11]将不同阶段的心音信号作为特征取得了一定的效果。文献[12]提出了心音信号分割算法以及根据信号能量对信号进行标定,最终提取出了不同周期在时域及频域上心音的特征数据,基于此特征对17中心音进行了精确的分类。文献[13]基于EMD进行信号特征提取,融合多个特征对5种异常信号进行识别取得了较好的识别性能。常用的心音分类模型有人工神经网络、高斯混合模型、支持向量机等。文献[14]提出一种加权可选择模糊C均值算法对GMM进行改进,其克服了传统GMM参数初始化K-means的缺陷。Christian Thomae[15]基于深度神经网络对心音信号进行识别取得了较好的识别效果。H.Hussain[16]等人对心音识别构建了隐马尔可夫模型取得了较高的识别精度。
对于心音识别的研究,研究者大多注重如何获取心音数据的表征特征和如何对噪声进行抑制。基于此,本文提出了改进的小波心音去噪算法,进而提出基于混沌算法与改进的自适应遗传算法相结合,优化卷积神经网络(CNN)对心音数据谱图进行识别。
1 算法描述
1.1 提出基于粒子群自适应阈值心音小波去噪算法研究
⑴ 去噪算法概述
由于心音信号是时变、非平稳信号,其主要包括第一、二、三、四心音,其中第一、二心音信号较强,第三、四心音信号较弱。心音信号波形图如图1所示。基于此,本文提出基于粒子群自适应阈值心音小波去噪算法。
⑵ 离散小波去噪原理
对含有噪声的心音信号可以用下式中⑴表示:
[yt=xt+n(t)] ⑴
其中,[y(t)]表示含噪的心音信号,[x(t)]表示真实心音信号,[n(t)]表示噪声信号,则离散的小波函数表示为[17]:
[φ?2-j,k?2-jt=2j2φ(2jt-k)] ⑵
其中,[2-j]表示尺度因子,[k?2-j]表示平移因子。则离散心音小波变换可以表示为:
[WTxj,k=2j2-∞+∞x(t)φ*(t)?(2j?t-k)dt] ⑶
其中,[φ*(t)]表示[φ(t)]的復共轭。
那么离散小波阈值去噪方法及过程如下:
① 首先,对包含噪声的心音信号进行小波变换时,选择较为合适的小波分解基以及对应的小波基函数;
② 对小波分级的参数进行阈值选择:
[wj,k=wj,k,|wj,k≥γ|0,|wj,k<γ|] ⑷
其中,[γ]表示参数阈值,[wj,k]是小波分解系数;
③ 基于公式⑷确定的去噪后的小波系数去对心音信号进行重构,得到重构后的心音信号[yt]。
通过以上分析可知,心音信号去噪算法最关键的是对阈值的合适选取,基于此,本文提出了基于粒子群算法对最优阈值进行选取。
⑶ 基于粒子群算法对心音去噪最优阈值选取
为了使得小波心音去噪算法获得最佳阈值、防止模型陷入局部最优值的情况,本文选取了具有全局搜索能力较好的粒子群算法进行全局寻优,并结合在最小均方误差条件下找到最佳的阈值[T]。粒子群算法优化搜索的流程如下所示[18]:
① 对所有的粒子进行初始化,即对粒子的速度及位置赋值,以及将个体的最优[pBest]当做当前的位置,群体中最有的粒子个体当作当前的[gBest];
② 在每一代的进化中,计算各个粒子的适应度函数值;
③ 若当前的适应度值优于历史值,则对历史的[pBest]进行更新;
④ 若当前适应度值更优与全局历史最优值,则对[gBest]进行更新;
⑤ 对每个粒子[i]的第[d]维的速度和位置分别基于式⑸进行更新。
[vdi=w×vdi+c1×randd1×pBestdi-xdi+randd2×(gBestd-xdi)] ⑸
[xdi=xdi+vdi] ⑹
其中,w是惯量权重,[c1]和[c2]是加速系数,[randd1]和[randd2]是在[0,1]上的随机数;
⑥ 判断算法是否达到了终止条件,若没有,则转到②继续执行。
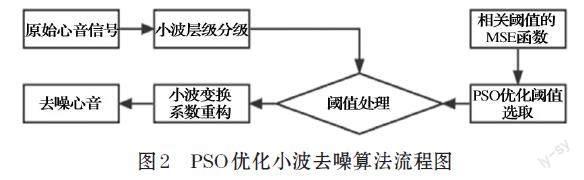
本文基于粒子群的小波去噪算法设计:首先,对采集的原始心音信号进行小波变换;然后,建立小波变换系数MSE下阈值计算函数;接着,基于粒子群算法对每层的小波系数进行最佳阈值选取;最后,基于逆变换得到去噪的心音信号。流程如图2所示。
1.2 提出基于改进的CAGA_CNN网络进行心音识别
⑴ 自适应遗传算法
为了获得较高的心音信号识别精度以及较快的收敛速度,本文引入遗传算法。其经典公式如下:
[Pc=k11fmax-favg,k1≤1.0Pm=k21fmax-favg,k2≤1.0] ⑺
其中,[Pc]为交叉概率,[Pm]为变异概率,[fmax]为种群的最大适应度,[favg]为种群的平均适应度,[k]是取值范围在(0,1)的常数。
通过式⑵发现,交叉概率[Pc]和变异概率[Pm]是根据种群的适应度的变化而变化的,但是也存在一些问题:例如当交叉概率和变异概率的增加会导致接近最优个体被破坏,使得永远不会收敛到全局最优解。因此,为了解决遗传算法存在的问题,研究者提出了自适应遗传算法(Adaptive Genetic Algorithm,AGA),它是对遗传算法的一种改进。具体改进如下:
[Pc=Pcmax-Pcmax-Pcmin-f'-favgfmax-favg,f'≥favgP'cmax, f' [Pm=Pmmax-Pmmax-Pmmin-f'-favgfmax-favg,f'≥favgP'mmax, f' 其中,[f]表示两个交叉个体中适应度较大的适应度。由式⑶和式⑷可以看出,本文算法可以较好的解决上述存在的问题。 ⑵ 改进的自适应遗传算法 虽然自适应遗传算法在一定程度上解决了交叉概率和变异概率停滞不前的状态,但是在超参数调优过程中仍然会陷入局部最优解[19,20]。 为了解决此问题,本文提出通过自适应遗传算法与混沌算法相融合。由于混沌算法自身具有全局遍历的特性,因此可以很好地解决上述问题。具体是将混沌算法与自适应算法相结合,对其中具有最高适应度的个体给予一定的步长混沌优化搜索,解决自适应遗传算法可能陷入局部最优解的情况,并加速搜索能力。logistic映射迭代公式为: [cxn+1=μ?xn?(1-cxn)] ⑽ ⑶ 提出改进的CAGA优化CNN进行心音识别 由于CNN在图像识别的相关领域具有较好的识別作用,因此本文选取了CNN作为心音识别的主干网络。同时,为了防止在小样本场景下模型的泛化能力差、收敛速度慢等问题提出了将混沌算法与自适应遗传算法相结合优化CNN的网络结构。此设计最大的难点在于如何将混沌自适应遗传算法应用到卷积神经网络当中,传统的做法是将不同神经元之间的权重与偏置当作一个染色体,若这样对每个参数都进行训练就失去了模型加速的意义[21],因此本文提出将网络中的卷积层和全连接层当作一个染色体进行调优,这样的设计大大的减少了染色体的结构规模,可以达到更快的收敛速度。具体的设计如图3所示。 改进的混沌自适应遗传算法优化CNN对心音信号进行识别流程图如图4所示。 2 实验结果与讨论 2.1 数据来源 常用的心音数据主要有两个,分别是PhysioNet/CinC Challenge2016[22](记为数据集1)以及PASCAL数据集[23](即为数据集2)。本文主要使用数据集1进行模型的训练与测试。数据集1是由训练集和测试集两个部分组成,来自于世界各地临床以及非临床环境下采集的3240条数据,其中正常的心音数据样本665个,异常样本2575个[24],心音的原始数据如图5所示。 2.2 基于PSO_WT对心音信号去噪 为了检验本文提出的PSO优化小波去噪算法的效果,本文选取了数据集1的两种信号对其加入随机噪声,并利用本文提出的算法进行去噪,再者将其与db5小波、bior5.5小波以及sym5小波进行对比并通过MSE进行分析去噪效果。利用构造的心音小波、db5小波、bior5.5小波、sym5小波四种小波对心音信号进行五层分解则: [s=d1+d2+d3+d4+d5+a5] ⑾ 其中,[dn]为n阶细节系数,[a5]是指5近似系数。由于实际的场景下,心音信号的频率以及噪声大多集中在高频段,因此本文拟使用[d1,d2,d3,d4,d5]进行重构,即为[24]: [s=d2+d3+d4+d5+a5] ⑿ 对数据集1中的正常心音信号与异常心音信号的原始图像进行四种小波去噪处理,处理结果如图6和图7所示。 经过MSE、互相关系数R以及信噪比SNR验证,MSE、互相关系数R和信噪比SNR表达式如式⒀~式⒂所示。 ① 均方误差(MSE) 将经过小波处理后的信号与同类原始未被处理的信号之间的均方误差: [MSE=1ni=1n|xi-x(i)2|] ⒀ ② 互相关系数(R) 将经过小波去噪后的信号与未被处理的信号之间的互相关系数: [R=cov(x,x)/σxσx] ⒁ ③ 信噪比(SNR) 将原始信号能量与噪声信号能力之比: [SNR=10logPsPN] ⒂ 其中,[Ps]表示原始心音信号的能量,[PN]表示噪声信号的能量。 通过式⒀~式⒂,去噪处理后的结果整理为表1和表2。 在对数据集1进行了四种小波去噪后发现,异常心音信噪比最大,且整体的误差较小,与原始信号互相关系数较好,其中本文提出的基于PSO_WT去噪算法效果达到了最佳,因此在后续的心音识别数据集本文基于提出的PSO_WT进行心音谱图转化。 2.3 基于CAGA优化CNN进行心音识别 ⑴ 实验环境 本实验在PyTorch1.8.1(Python3.7.10+cu10.2)上运行,并在NVIDIA GeForce RTX 2080Ti*2的图形处理单元(GPU)上训练了150个epoch。使用的是带有Intel?CoreTMi9-9820x CPU@3.30GHz x20处理器的台式机,64位linux操作系统Ubuntu18.04。具体实验环境信息如表3和表4所示。 ⑵ 心音识别结果 本实验模型训练和测试在数据集1上进行,训练集、验证集和测试集是按照5:3:2的比例随机划分,图像像素大小为256×256,迭代次数epoch为150次。首先,根据本文提出的CAGA_CNN网络框架进行模型训练;然后对训练好的模型进行微调,提高模型的识别性能,心音识别的结果如下所示: 由于PhysioNet数据集本身具有重叠噪声,因此会严重影响心音信号的识别效果。与正常的检测对比,该数据整体的识别准确率较低。通过表4可以发现,本文提出的CAGA优化CNN在识别的精确度上优于传统CNN,取得了较好的识别性能。 ⑶ 模型性能分析 为了对于模型的性能进行分析,本文分别对传统的CNN网络以及本文提出的CAGA_CNN网络进行迭代150次,探讨所提出网络模型与传统的网络模型的准确率、损失率和收敛速度的变化情况。分析结果如图8所示。 对心音识别精度及损失图对比图 通过图8发现,①本文提出的算法在识别的准确率上得到了大大的提高,模型的损失在一定的程度上有所改善;②本文提出的网络模型在迭代14次已经达到了收敛,表明提出的算法具有较快的收敛速度。 3 结论 为了提出较好的心音去噪算法及心音识别模型本文提出了基于PSO_WT与改进的CAGA_CNN算法对心音识别,主要工作如下: 首先,本文选取了不同场景下采集的、具有重叠噪声的PhysioNet数据集进行实验;其次,首次搭建PSO_WT算法对心音信号进行去噪处理;最后,提出改进的CAGA_CNN网络对心音信号进行识别;实验结果表明,本文提出的算法具有较好的识别性能和较快的收敛时间。 參考文献(References): [1] S. Latif, M. Y. Khan, A. Qayyum, J. Qadir, M. Usman, S. M. Ali, et al., "Mobile technologies for managing non-communicable diseases in developing countries," in Mobile applications and solutions for social inclusion, ed: IGI Global,2018:261-287 [2] M. E. Chowdhury, K. Alzoubi, A. Khandakar, R. Khallifa, R. Abouhasera, S. Koubaa, et al., "Wearable real-time heart attack detection and warning system to reduce road accidents," Sensors,2019,19:2780 [3] M. E. Chowdhury, A. Khandakar, K. Alzoubi, S. Mansoor, A. M Tahir, M. B. I. Reaz, et al., "Real-Time Smart-Digital stethoscope system for heart diseases monitoring," Sensors,2019,19:2781 [4] Kao W C,Wei C C.Automatic phonocardiograph signal analysis for detecting heart valve disorders[J].Expert Systems with Applications: An International Journal,2011,38(6):6458-6468 [5] 周酥.心音信号特征分析及其在辅助诊断中的价值[D]. 硕士,广州:华南理工大学,2012 [6] 罗键中,罗林.心脏听诊[M].北京:人民卫生出版社,2001: 3-35 [7] U. Alam, O. Asghar, S. Q. Khan, S. Hayat, and R. A. Malik, "Cardiac auscultation: an essential clinical skill in decline," British Journal of Cardiology,2010,17:8 [8] G. D. Clifford, C. Liu, B. Moody, D. Springer, I. Silva, Q. Li, et al., "Classification of normal/abnormal heart sound recordings: The PhysioNet/Computing in Cardiology Challenge 2016," in 2016 Computing in Cardiology Conference (CinC),2016:609-612 [9] Khan K N, Khan F A, Abid A, et al. Deep learning based classification of unsegmented phonocardiogram spectrograms leveraging transfer learning[J].Physiological Measurement,2021,42(9):095003(17pp) [10] K. Wo?k and A. Wo?k, "Early and remote detection of possible heartbeat problems with convolutional neural networks and multipart interactive training" IEEE Access,2019,7:145921-145927 [11] 成谢锋,陈亚敏.S1和S2共振峰频率在心音分类识别中的 应用[J].南京邮电大学学报(自然科学版),2017,37(5):7-12 [12] 吴云飞,周煜,陈天浩,等.基于自相关函数的心音周期提取 和识别[J].计算机与数字工程,2017,45(10):2068-2073 [13] 郭兴明,何彦青,卢德林,等.平移不变小波在心音信号去噪 中的应用[J].计算机工程与应用,2014,50(24):209-212 [14] 张文英,郭兴明,翁渐.改进的高斯混合模型在心音信号分 类识别中应用[J].振动与冲击,2014,33(6):29-34 [15] Thomae C, Dominik A. Using deep gated RNN with a convolutional front end for end-to-end classification of heart sound[C].Computing in Cardiology Conference. IEEE,2017 [16] Shhussain H, Mohamad M M, Zahilah R, et al. Classification of Heart Sound Signals Using Autoregressive Model and Hidden Markov Model[J]. Journal of Medical Imaging & Health Informatics,2017,7(4):755-763 [17] 周克良,邢素林,聶丛楠.基于自适应阈值小波变换的心音 去噪方法[J].广西师范大学学报(自然科学版),2016,34(1):19-25 [18] 何之煜.基于异构粒子群算法的LKJ辅助驾驶优化研究[J]. 铁道标准设计,2022(12):1-7 [19] Wang J D,Chen Y Q,Hao S J,et al.Deep learning for sensor-based activity recognition:A survey[J].Pa-ttern Recognition Letters,2019,119:11-13 [20] 万鹏,赵竣威,朱明,等.基于改进Res Net50模型的大宗淡 水鱼种类识别方法[J].农业工程学报,2021,37(12):159-168 [21] 蒋留兵,潘波,吴岷洋,等.基于FT_SSIM和ICAGA_CNN 在小样本场景下雷达动作识别方法研究[J].计算机应用研究,2022,39(4):1105-1110 [22] PhysioNet/CinC Challenge 2016. https://physionet.org/ physiobank/database/challenge/2016/. [23] Bentley, P. and Nordehn, G. and Coimbra, M. and Mannor, S.: The PASCAL Classifying Heart Sounds Challenge 2011(CHSC2011) Results.http://www.peterjbentley.com/heartchallenge/index.html. [24] 李天雅.基于深度学习网络的心音信号分类识别的研究[D]. 硕士,华南理工大学,2018 [25] S.-W. Deng and J.-Q. Han, "Towards heart sound classification without segmentation via autocorrelation feature and diffusion maps," Future Generation Computer Systems,2016,60:13-21 [26] W. Zhang, J. Han, and S. Deng, "Heart sound classification based on scaled spectrogram and tensor decomposition," Expert Systems with Applications,2017,84:220-231 [27] V. Sujadevi, K. Soman, R. Vinayakumar, and A. P. Sankar, "Deep models for phonocardiography (PCG) classification," in 2017 International Conference on Intelligent Communication and Computational Techniques (ICCT),2017:211-216 [28] W. Zhang and J. Han, "Towards heart sound classification without segmentation using convolutional neural network," in 2017 Computing in Cardiology (CinC),2017:1-4 [29] F. Chakir, A. Jilbab, C. Nacir, and A. Hammouch, "Phonocardiogram signals processing approach for PASCAL classifying heart sounds challenge," Signal, Image and Video Processing,2018,12:1149-1155 [30] F. Demir, A. ?engür, V. Bajaj, and K. Polat, "Towards the classification of heart sounds based on convolutional deep neural network," Health information science and systems,2019,7:16
