
基于改进全卷积网络的临产母猪体态识别
2023-06-14 00:30侯岩松许海洋
贵州农业科学 2023年6期
王 萍,侯岩松,许海洋*,张 伟
(1.青岛农业大学 理学与信息科学学院,山东 青岛 264300;2.中国劳动关系学院 应用技术学院,北京 100048)
0 引言
【研究意义】猪肉是我国主要的肉类消费品,猪肉食品的安全供应关系到国计民生。据国家统计局数据显示,2021年我国的猪肉产量5 296万t,增长28.8%[1],猪肉产量仍占统计肉类产量的59%。生猪产业的发展直接影响国民健康和经济发展,为保障我国猪肉供应,应提高国内生猪的养殖效率。母猪往往是养殖场的核心资产,担任繁育仔猪的职责,因此,其行为及健康受到高度重视。目前,养殖场利用环境控制技术实现了对畜舍通风率、温度、湿度和有害气体等参数的动态调整,但对畜舍中动物行为的监测与识别却仍缺乏有效技术措施。母猪的体态行为可能受到骨骼和内脏疾病的影响,跛行是经产母猪淘汰的主要原因。猪的躺卧姿势也是其是否健康的表现,如猪“犬坐式”姿势表明其腹部疼痛,而四肢伸展、侧卧则表明其比较舒适。由于肢体的运动和视觉受脑部神经的控制,一些脑部疾病和失明现象的发生也与运动相关联,如因链球菌感染而导致的跛行或原地转圈行为。目前对生猪尤其是母猪行为的观察方法已由人工观察向电子测量、视频监测和声音监测等方向发展。数字图像处理技术通过对猪姿态、轮廓数据的计算,辅以运动的行为参数,用于判断猪形体姿态和行为趋势,该方法实时、客观,但易受到养殖场光照条件、视角及遮挡的影响。光照引起的环境变化增加了猪的体态识别难度,且算法易受背景颜色等因素的干扰,因此,研究如何有效地提取猪只表征并对其体态进行识别,对客观反映母猪的生理状态,有效预防母猪疾病具有现实意义。【前人研究进展】2015年,NASIRAHMADI等[2]利用机器视觉自动监测猪的躺卧行为和个体间的距离,提高了识别的准确性。为避免传感器监测的应激反应,HANSEN等[3]将VGG卷积神经网络用于猪脸的识别中,以期实现非侵入性测量。杨阿庆等[4]研究提出基于全卷积网络的哺乳母猪图像分割算法,实现了猪舍场景下哺乳母猪准确、快速分割。薛月菊等[5]在ZF网络中引入残差结构,提出了改进Faster R-CNN的哺乳母猪姿态识别算法,提高了识别的精度和速度。高云等[6]的研究优化了Mask R-CNN网络的深度和宽度,进行群猪图像的实例分割,实现单个猪只的分辨和定位。刘龙申等[7]的研究利用颜色和面积图像特征的运动目标检测方法,实现对第一头新生仔猪的图像识别算法,识别率达100%。目前,可使用机器视觉[8]监测猪只饮水行为,安装光电传感器监测母猪的站立或躺卧姿势,综合判断母猪分娩时间[9]。国内也有企业联合高校开展监控母猪分娩后仔猪的行为姿势,来判断其分娩的仔猪数、仔猪出生时间间隔、产程等方面的研究[10]。VGG是较为流行的卷积神经网络架构,其以较深的网络结构、较小的卷积核和池化采样域,获得更多图像特征的同时控制参数数量,避免计算量过多和网络结构过于复杂。而VGG16简化了神经网络结构,适用于迁移学习,其包含13个卷积层和3个全连接层,在实际应用中可将第一个全连接层改为7×7的卷积网络,后面2个全连接层改为1×1的卷积网络,使得整个VGG变成全卷积网络(FCN)。【研究切入点】关于母猪分割的研究多集于硬分割,即将图片的像素分成多个类别。如果是前背景分割,则分2个类别,一类代表前景,一类代表背景,属于分类任务,分割的二值性(即0和1)导致前景和背景周围出现严格边界,图像融合后的视觉效果不佳。图像对应像素点的颜色不仅是由前景本身颜色决定,而是前背景颜色融合的结果。目前,有关用软分割分离母猪图像前景和背景的研究鲜见报道。【拟解决的关键问题】基于改进全卷积网络(FCN)的母猪体态识别算法,构建FCN训练模型,采用自适应学习率进行训练,识别临产母猪体态,以期为客观反映母猪生理状态和有效预防母猪疾病提供参考。
1 材料与方法
1.1 数据采集与处理
试验数据来源于青岛农业大学试验猪场,为获取不同体态的临产母猪图像,于2020年4月至2021年6月分5个批次进行图像采集(图1)。采集设备为安装在猪舍顶部的监控摄像头,每间猪舍包含1头待产母猪,获取的视频质量为576 p和720 p。

图1 临产母猪体态视频图像Fig.1 Video image of parturient sow
使用OpenCV-Python从获取的视频中逐帧提取图像,通过人工筛选和图像自动标注技术批量生成1 000张掩膜图像,制作临产母猪体态分类数据集(表1)。该数据集包含临产母猪常见的5种体态,分别为踱步、躺卧、俯卧、蹲坐和站立,每种体态不少于100张图像。使用Tensor Flow将图像统一调整为224 px×224 px图片,并进行图像归一化处理,使数据分布在0~1,加快模型的训练速度。通过数据增强对图像进行随机裁剪、随机反转和随机亮度扩充数据集,提高模型的鲁棒性。扩充后的数据集包含6 000张图像样本,按8∶1∶1的比例将其划分为训练集、测试集和验证集。
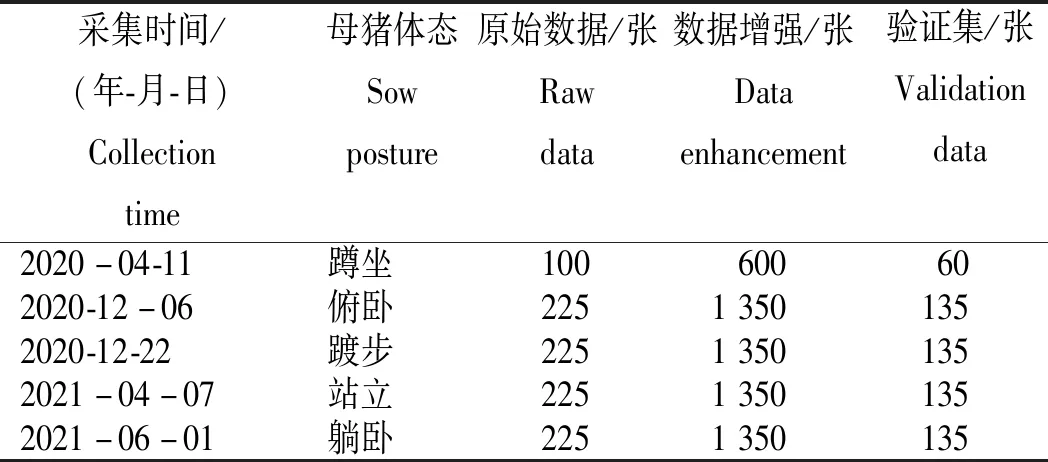
表1 临产母猪体态分类图像数据集Table 1 Collection of parturient sows posture image
1.2 临产母猪图像分割FCN网络
FCN是图像分割领域比较成功的算法,FCN将分类网络转换成用于分割任务的网络结构,并实现了端到端的网络训练,成为深度学习解决分割问题的基石。尽管分类网络可接收任意尺寸的图片作为输入,但由于网络的最后一层为全连接层,使其丢失了图像的空间信息。因此,FCN无法直接解决如图像分割等像素级的稠密任务估计问题。针对该问题,FCN使用卷积层和池化层代替分类网络中的全连接层,使网络可适应像素级的稠密预测任务。研究使用CNN经典架构VGG16搭建全卷积网络(图2),目的是预测图像中的每一个像素所属类别。
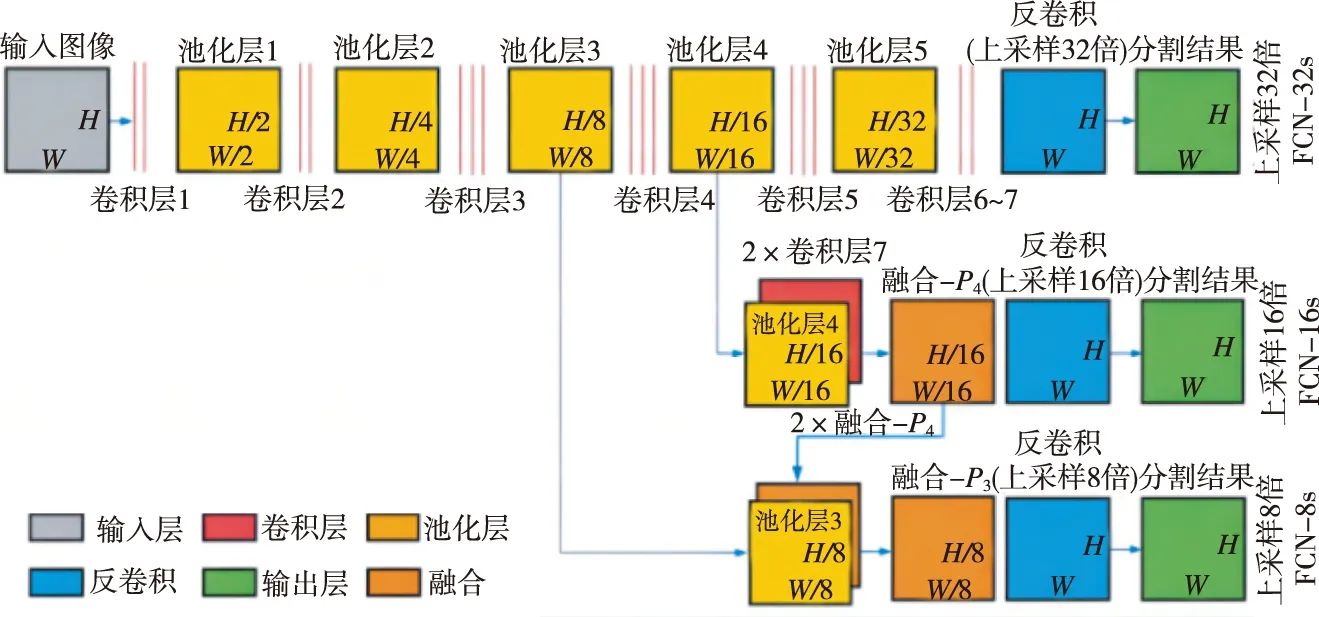
图2 FCN网络结构Fig.2 FCN network structure
1.2.1 卷积层代替全连接层 FCN采用卷积层代替CNN的全连接层,使得网络可接收超过规定尺寸的图片。FCN的输入为RGB图(h×w×3)或灰度图(h×w×1),利用与全连接层输入数据尺寸相同的卷积核,将VGG16的全连接层替换为卷积层conv6-7。然后在原有的FCN基础上增添两层卷积和批标准化,使用1×1的卷积核改变图像通道数量,对数据进行降维,引入更多的非线性,提高模型的泛化能力。批标准化有助于梯度传播,提高模型收敛速度,允许使用更大的学习率进行训练。最后使用sigmoid进行激活,使得模型输出归一化至0~1,输出图像的热力图。
1.2.2 增加反卷积 由于在卷积和池化过程中特征图会逐渐变小,为得到和原图相同大小的稠密像素预测图像,需对特征图进行上采样。输入图像通过VGG16网络,进行5次卷积和下采样,输出的特征图像变成原图像大小的1/32。FCN在特征图后使用转置卷积,通过对特征图进行上采样以恢复原图像尺寸。
1.2.3 增加跳级结构 若直接对网络最后一层pool5输出的特征图进行上采样,输出的分割图会丢失很多图像细节信息。VGG16通过浅层网络提取图像的局部特征,深层网络提取图像语义特征,直接对最后一层卷积进行32倍上采样的方式称为FCN-32s;为融合网络更浅层的局部信息,将底层(stride 32)的预测(FCN-32s)进行2倍的上采样,并与pool4层(stride 16)进行特征融合,称为FCN-16s;再将FCN-16s进行2倍的上采样与pool3层(stride 8)的特征结合起来,称为FCN-8S。将网络最后一层的预测(含有更丰富的全局信息)和更浅层的预测(含有更多的局部细节)结合,使网络可在遵守全局预测的同时进行局部预测。
1.3 FCN训练模型
模型训练使用华为云ModelArts平台的算力:NVIDIA V100 GPU单卡规格,32 GB显存[GPU:1*V100(32 GB)|CPU:8核 64 GB],基于TensorFlow2.1框架搭建FCN网络模型。语义分割是像素级别的分类,其常用的评价指标为统计像素准确率(Pixel Accuracy,PA):
式中,k表示类别数量,为便于解释,假设共有k+1个类(从L0到Lk,其中包含一个空类或背景);pii代表真正的数量;pij表示假正和假负,即本属于类i但是被预测为类j像素的数量,计算分类正确的像素占总像素的比例。使用VGG16在TensorFlow封装好的ImageNet权重训练FCN分割母猪图像的前景和背景,用Adam优化器的默认学习率0.001进行训练。
1.4 母猪体态识别
1.4.1 FCN注意力机制 在计算机视觉中,图像分类、图像分割、图像检测、视频处理和生成模型等相关领域均使用注意力机制。其共同点是利用相关特征学习权重分布,再把学习到的权重施加到特征上进一步提取相关特征。研究采用Bottom-up和Top-down结构,首先通过一系列的卷积层和池化层,逐渐增大模型的感受野提取图像语义特征,因为高层卷积所提取的特征激活的Pixel可反映Attention所在区域,再通过相同数量的up sample将feature map的尺寸放大到原始图像大小,并与输入图像相融合。其中,up sample通过Transposed Convolution实现。利用Transposed Convolution学习参数,将Attention的区域对应到输入图像的每一个pixel上,称为Attention mask(map)。Bottom-up和Top-down结构类似于encoder-decoder结构,相当于weakly-supervised的定位任务学习,因此,这种Attention的添加方式大多应用在图像检测和图像分割等监督问题上,如FCN。
利用VGG16作为卷积基构建FCN,用FCN提取母猪图像的Attention权重,再将FCN的输入和输出结合,FCN中每一个pixel的值对应原始feature map上每一个pixel权重,从而增强有意义特征,抑制无意义信息。如图3所示,将FCN输入和输出的feature map进行element-wised乘法,并进行特征融合,进而增加特征的判别性。计算公式:
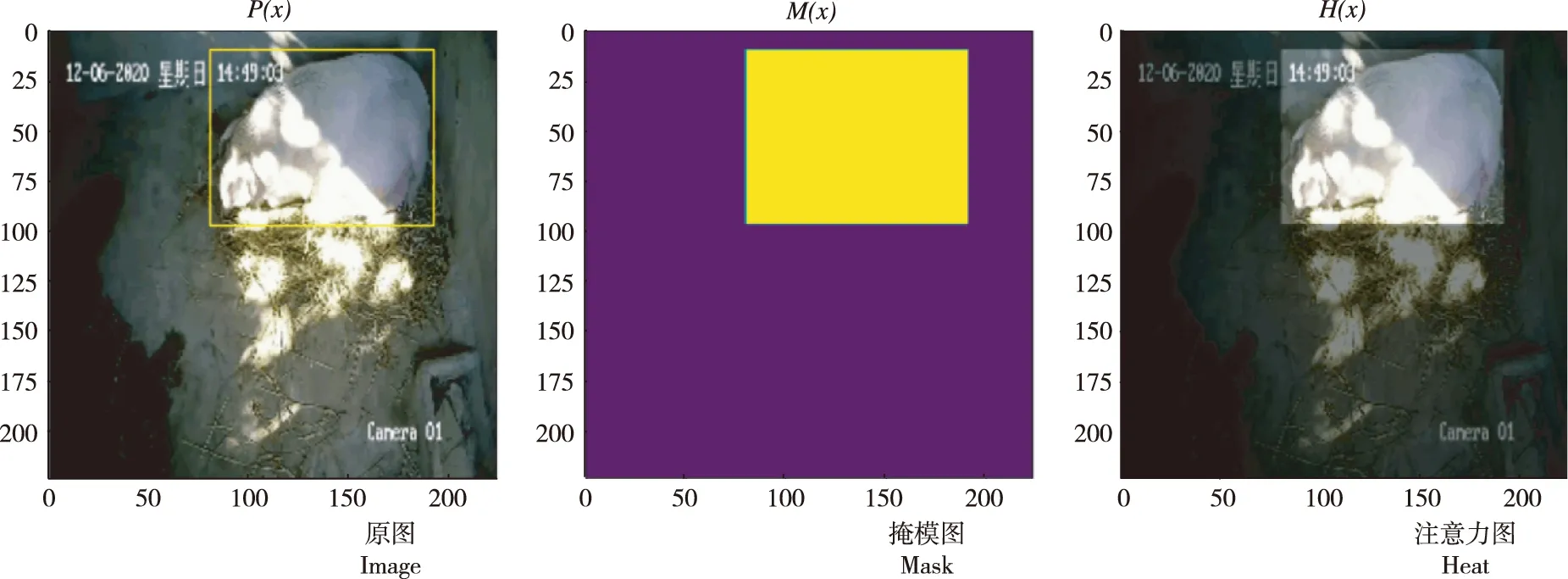
图3 FCN注意力机制Fig.3 FCN attention mechanism
H(x)=P(x)×[1+M(x)]
式中,P(x)为FCN的输入矩阵,M(x)为FCN的输出矩阵,H(x)为二者点乘相加结果。当M(x)=0,该层的输出就等于P(x)。因此,该层输入不可能比原始P(x)差。
1.4.2 体态识别模型 采用FCN构建母猪体态多输出模型(图4),FCN的卷积基为VGG16(covn1~pool5)。该模型引入注意力机制,使用FCN的卷积基提取图像特征。通过全局平均池化计算输入通道特征图像素的平均值,使用全连接层分别输出母猪的坐标位置和体态分类。模型使用自适应学习率进行训练,为更好地利用计算机资源,分批次进行训练,每批次包含32个训练样本,训练50轮,通过平均识别准确率和运行速度2个指标对模型进行评价。

图4 体态识别模型 Fig.4 Posture recognition model
1) 平均识别准确率。其表示验证集中分类正确的样本数与验证集总样本数之比。计算公式:
式中,A为平均识别准确率,Ns为样本的类别数量,Ns=5;Ni为第i类样本的数量;Nii为预测正确的第i类样本数量。
2) 运行速度。其是指模型处理一个样本所花费的时间,是评价模型性能的指标。
1.4.3 试验步骤 试验步骤一是模型训练,冻结模型的卷积层,使用只训练模型最后全连接层的迁移学习方法;步骤二是模型微调,解冻VGG16顶部的卷积层,冻结网络的最后3层。
2 结果与分析
2.1 模型训练
通过模型训练图像可知(图5),在模型训练前15轮模型loss和评价指标mae迅速下降,30轮时模型基本完全收敛,且模型在训练集和测试集上的准确率可达100%。

图5 模型训练结果Fig.5 Model training result
2.2 模型微调
对模型进行微调,即共同训练新添加的分类器层和部分或全部卷积层,通过微调基础模型中高阶特征表示,使其与特定任务更加相关。此外,刚开始训练的误差大,为保证卷积层学习到的特征不会被破坏,需在分类器训练好后才能微调卷积基的卷积层。对比微调前和微调后模型在验证集上的测试结果可看出(图6),模型的正确率基本维持在100%,loss仍有小范围下降,表明微调起一定效果。由于模型在前30轮验证集上的准确率已达100%,因此,对于模型预测结果的提升并不明显。

图6 模型微调结果 Fig.6 Model fine-tuning result
2.3 模型预测效果
为测试该研究算法的泛化能力,选择与训练集和测试集图像不同的验证集进行测试。从图7看出,在不同光照条件下,该模型可有效识别定位母猪的不同体态(踱步、躺卧、俯卧、蹲坐、站立),具有较强的鲁棒性。模型平均识别准确率为97%,说明模型能够较好地捕捉样本特征,预测框IOU为92.56%,运行速度为0.2 s,基本可达实时检测要求。

图7 模型预测效果 Fig.7 Model prediction
3 讨论
在模型预测时,输出图像的热力图及母猪的体态分类和坐标位置,为消除图像背景对体态识别的干扰,本研究将模型输出的热力图与输入图像融合,进行特征的点乘操作,将图像的背景像素置为0,目标像素置为1,再次进行预测,从而降低环境因素对母猪体态识别算法的干扰。参考GoogleNet构造辅助的分类器,将中间的结果输出对中间的结果进行优化。FCN虽精度较高,但参数量巨大,运算开销高,在边缘设备上难以达到实时检测的要求。参考LinkNet的网络结构进行优化,使用更高效的图像特征提取模块,并结合华为云ModelBox开发框架在RK3568上开发板上部署更高效AI应用,通过ModelBox框架,可快速实现AI推理业务的开发,同时增加推理的数据吞吐量,降低AI分析耗时。
关于改进全卷积网络注意力机制的实现,使用完全训练后的FCN下采样层权重提取母猪的表征,再送入全连接层进行母猪体态分类和位置回归。模型训练好后转换为onnx格式,使用ModelBox框架进行模型推理,之后可部署到华为云Hilens平台上。由于数据集的标注对于模型的预测精度影响较大。目前,对于数据集的标注还不够精细,改进后的模型精度仍有待验证,下一步可增加对比试验,同时使用ModelBox框架进行推理,提高数据的吞吐量。在小规模数据集下,使用图像增强方法扩充数据集,可有效提高模型的平均识别准确率,解决了小数据集容易出现过拟合的问题。目前,模型识别的速度较慢,难以部署在移动和边缘设备上,后续将考虑对模型进行压缩,研究轻量级的卷积神经网络模型,进一步提高模型实用价值。
4 结论
通过VGG16构建FCN分割母猪图像,并引入注意力机制进行母猪的体态识别和定位,使用迁移学习和微调模型的方法进行模型训练结果显示,训练前15轮模型loss和评价指标mae迅速下降,30轮时模型基本完全收敛,且模型在训练集和测试集上的准确率可达100%;模型微调后loss和mae仍有小范围下降,分类准确率基本维持在100%。不同光照条件下该模型可有效识别和定位母猪不同体态,具有较强鲁棒性,模型平均识别准确率为97%,且能较好地捕捉样本特征,预测框IOU为92.56%,运行速度为0.2 s,基本可实现实时检测要求。表明,该方法可在光照条件欠佳的猪舍环境中有效识别母猪体态,实现对临产母猪的实时监测。
猜你喜欢
运动精品(2022年3期)2022-08-12
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
中国自行车(2018年2期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
中国音乐教育(2017年10期)2017-05-20
