
基于画像建模的大学生精准课程思政及应用研究
2023-06-10 07:33:59何胜巢海远史航
电脑知识与技术 2023年12期
关键词:课程思政
何胜 巢海远 史航


关键词: 课程思政;课程画像;思政资源画像;资源推荐;画像建模
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2023)12-0064-03
2020年6月,教育部印发《高等学校课程思政建设指导纲要》的通知,提出高校课程思政建设要在所有高校、所有学科专业全面推进[1],使得以学科知识讲授和传播为核心的传统课程教学模式受到挑战,在全国范围内激发了课程思政教育研究的热潮。
在“互联网+”时代,如何应用信息技术,将丰富的互联网思政资源引入大学生课程学习过程,并实现课程学习内容和互联网思政资源精准匹配,从而提升课程思政教育的效率和效果,日益引起学界的关注[2]。
针对上述问题,本文将信息技术中的画像建模方法引入课程思政领域,分别抽取大学生课程特征和互联网思政资源的特征标签构建画像模型,并设计方案将二者关键特征进行匹配,从而实现课程思政资源的精准推荐。
1 研究回顾
画像建模方法一般包括用户画像建模和资源画像建模,用户画像建模依托用户人口和行为数据库,抽取用户行为特征,构建用户画像标签模型;资源画像则依托互联网资源,提取资源特征构建资源画像模型[3]。课程画像需要抽取用户(大学生)的人口特征和课程特征,属于用户画像;互联网思政资源画像需要分析文本(或视频)内容并抽取特征关键词,属于资源画像。
近年来,将画像建模应用于课程思政教育的探索已见诸研究文献,于卓言[4]以大学生群体画像为工具,提出应从群体情感倾向与极端化行为角度开展追踪和预测,寻找适合大学生思政教育的途径和方法。于祥成等[5]指出为提升高校思政教育的实效性和针对性,须在“定位、供给、联动、评价”等系列实践路径上实现画像的精准化。黄文林[6]提出依托教育大数据构建面向高校精准思政的学生画像方案,并从关键实施环节和技术伦理角度对精准思政工作模式加以总结。段媛媛[7]尝试对高职学生的敬业度画像,探索大思政视域下培养高职学生敬业观的思路。苗瑞丹[8]等讨论了大数据画像技术对于助推精准思政必要性,提出应提升画像精准度、确保画像“技术正义”并实现思政育人价值。
现有文献或强调应用画像建模方法开展高校思政研究的必要性,探讨实施的路径方法、技术伦理,或从某一独特角度(如群体情感与极端化行为、敬业度)寻找精准思政的实现途径。然而上述文献大多属于理论角度的分析,缺少针对性案例研究。有关大学生课程学习画像,特别是在如何利用丰富互联网思政资源辅助课程思政教育的研究方面,鲜有涉及。
鉴于此,本文提出基于画像建模的大学生精准课程思政教育方案,以大学生课程学习数据和互联网思政资源数据为基础,分别开展用户画像和资源画像,并将两类画像匹配后,开展个性化资源推荐,以“数据库原理与应用”课程思政教育为例给出研究案例。
2 大学生课程画像构建及应用框架
大学生课程思政画像模型构建及应用框架包括“数据收集”“画像建模”和“画像应用”三个部分,其中“画像建模”包括“课程画像”建模和“思政资源画像”建模两类,如图1所示。
2.1 数据收集
课程画像的基础数据主要来源于课程学习数据,包括人口信息和行为数据,其中人口信息有学生ID、姓名、性别、专业、年级等,行为数据一般指学生所学的课程名称及考核成绩等,一般从学校教务部门或学生工作部门的相关信息系统中获得。
课程思政资源数据库聚集了与思想政治教育相关的数据,一般包括专业资源和其他资源两类,前者如“学习强国”平台(https://www.xuexi.cn/,中宣部主管)、“大思政课云平台”(http://m.people.cn/305554/,人民网、中国青年报社、中国青年网等单位联合主办);后者如知乎平台和新浪微博上等有关课程思政的话题,各高校关于课程思政相关的微信公众号或链接网页,如中国人民大学校园网思政主页(https://news.ruc.edu.cn/20th) 等。
2.2 画像建模
在收集课程学习数据以及思政资源数据的基础上,以思政资源精准推荐为目标,抽取两类数据集的基础信息和相关特征开展画像建模,并将两类画像匹配。
1)“课程画像”建模。以教务、学工系统数据库为基础,“课程画像”需要抽取大学生人口属性及课程特征,画像标签包括“学生ID”“人口特征”“课程名称”和“课程特征”四个部分。其中“学生ID”标签唯一标记大学生的身份;“人口特征”标签包括姓名、性别、年龄、院系、专业、年级等;“课程名称”为系统运行期内对应的課程名,这三者皆从基础数据库直接抽取;“课程特征”标签体现课程内涵特点,由于专业课程特征千差万别,需要由课程教师利用专业知识对课程特征进行概括和凝练,并预先在数据库中填写并提交。
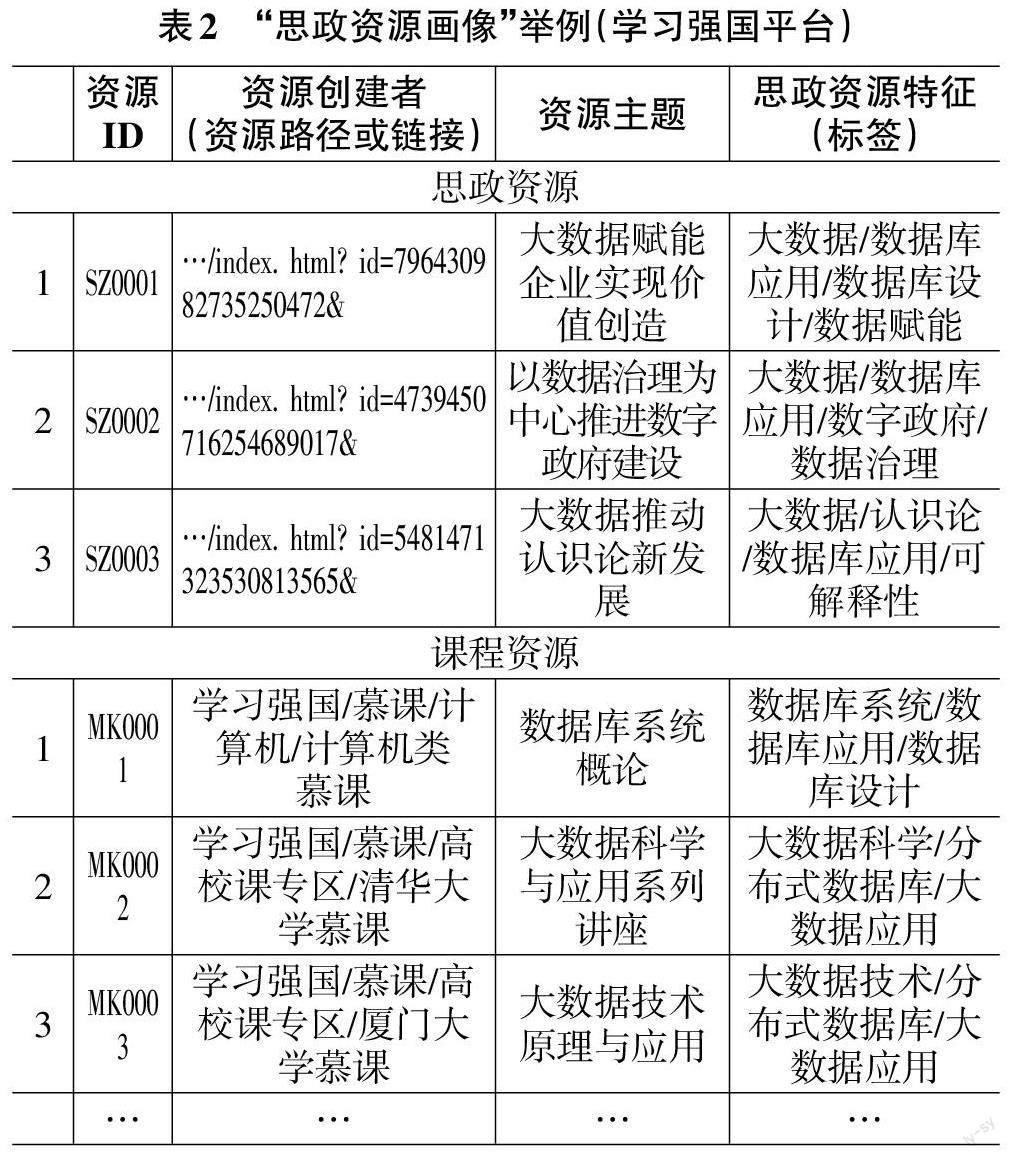
2)“思政资源画像”建模。以思政资源数据库为基础,“思政资源画像”需要应用语义计算的方法抽取特征,实现对思政资源画像建模。元数据包括“资源ID”“资源创建者”“资源主题”“思政资源特征”。其中“资源ID”标签唯一标记资源,由数据库系统软件自动生成;“资源创建者”标签记录该条资源的原创作者、链接或出处;“资源主题”标注该资源的名称;“思政资源特征”标签则需要提取能概括并凝练反映该资源内容的特征关键词。
3) 两类画像模型匹配。为了方便后期两类画像的匹配,“课程特征”与“思政资源特征”标签使用“共同标签库”(见图1) 。“共同标签库”采用精练且层次化的实词描述客体,对课程和思政资源这两个客体而言,“共同标签库”须完整且准确地反映二者知识组织架构,并具有较强的专业性,一般由课程教师或精通专业知识的人员提供。
2.3 画像应用
画像应用包括个性化“思政资源推荐”和“课程资源推荐”两类。提取课程特征和思政资源特征的标签后,应用余弦相似度算法,计算课程与思政资源的标签相似度,选择高相似度的思政资源推荐给用户。
2.4 应用案例
本节分别以“数据库原理与应用”等课程和“学习强国”思政平台为例,探讨二者画像模型的匹配融合方案及其在个性化思政资源推荐中的应用。“学习强国”是著名的思政平台,兼有思政资源和课程资源,思政资源有“学习理论”“党史频道”“红色中国”等板块,课程资源有“学习慕课”“学习科学”“学习文化”等板块,内容既经典权威,又极具时代感,非常适合作为大学生课程思政教育的资源。
1)“课程画像”举例。依据图1中的“课程画像”所包括的四个画像标签,列举了包括“数据库原理与应用”“软件工程”等课程画像的标签值,如表1所示。
2)“思政资源画像”举例。依据图1中的“思政资源画像”所包括的四个画像标签,结合“学习强国”平台,列举了各标签值,该平台的资源包括“思政资源”和“课程资源”两类,其中“思政资源”中的“资源创建者”标记了资源的网址链接,如“资源ID”为“SZ0001”的链接为https://www.xuexi.cn/lgpage/detail/index.html?id=796430982735250472,为避免文字烦冗,表格中共同的链接https://www.xuexi.cn/lgpage/detail/用“…”代替。值得注意的是,“课程特征”与“思政资源特征”标签来源于“共同标签库”,从其中选择了合适的关键词进行标注;“课程资源”中的“资源创建者”标记了资源的路径,如“资源ID”为“MK0001”的资源,其来源追溯路径为学习强国→慕课→计算机→计算机类慕课,如表2所示。
3) 标签相似度计算及推荐。假设学生当前课程名称为“数据库原理与应用”,查表1知该生的“课程特征”标签为“数据库原理、数据库应用、数据库设计”,推荐信息系统将计算该门课程与所有的“思政资源画像”中的“思政资源特征”标签的两两相似度,这里以资源主题“大数据赋能企业实现价值创造”为例,查表2知该资源的“思政资源特征”标签为“大数据、数据库应用、数据库设计、数据赋能”,采用通用余弦相似度方法计算二者的标签相似度,如图2所示。
首先将二者标签集合中的关键词唯一化,得到6个不重复的标签;接着统計每类标签在原集合中出现的词频,写出向量;最后根据余弦相似度公式计算,结果为0.6708,推荐系统将选取高相似度的思政资源推荐给用户。
3 结束语
依托大学生课程学习数据库和互联网资源数据库,一方面对大学生课程学习行为建模,抽取课程学习特征开展用户画像,另一方面抽取互联网思政资源特征开展资源画像,通过共同标签库将课程学习画像(用户画像)和资源画像进行匹配融合,以搭建用户画像和资源画像连接的桥梁,从而实现互联网思政资源向大学生用户的精准推荐,这为画像建模方法引入课程思政领域的研究提供可行的思路和应用方案。
猜你喜欢
商情(2017年33期)2018-01-24 22:01:46
教师·上(2017年12期)2018-01-13 22:09:08
科技视界(2017年27期)2018-01-04 14:39:05
科技视界(2017年23期)2017-12-09 10:55:55
大陆桥视野·下(2017年12期)2017-11-29 16:50:55
科技视界(2017年21期)2017-11-21 09:06:22
电脑知识与技术(2017年28期)2017-11-15 08:26:22
课程教育研究(2017年36期)2017-10-21 23:25:15
