
基于改进BiSeNet 的非结构化道路分割算法研究
2023-06-05 09:22:14谷玉海石文天
应用光学 2023年3期
宋 亮,谷玉海,石文天
(1.北京信息科技大学 北京市机电系统测控重点实验室,北京 100192;2.北京工商大学 材料与机械工程学院,北京 100148)
引言
交通的便利极大地促进了经济的发展,改善了人民的生活,但随之而来的交通事故也造成了诸多损失。绝大部分交通事故通常源于人为因素,如超速行驶、疲劳驾驶等。无人驾驶技术则可有效地避免这些问题。在过去的几年里,无人驾驶得到了飞速发展,其核心技术之一是道路场景的语义分割[1-2]技术。目前无人车行驶的道路场景可分为两类:一类是城市主干道、高速公路等边界清晰、形状规则的结构化道路,该类道路的分割技术已经比较成熟[3-4];另一类是乡村街道、城市非主干道等边界模糊、形状不规则甚至部分损坏的非结构化道路。该类道路场景下车道保持功能不可靠、分割难度大,更容易出现交通堵塞或其他事故。因此有效地识别出非结构化道路的可通行区域,对无人驾驶技术的实际应用具有较大的意义。
传统的非结构化道路分割算法主要依赖道路纹理、颜色、边缘等表层特征。黄俊提出一种根据道路方向纹理检测消失点的方法,使用局部方向模式特征计算响应幅值并确定投票点,根据幅值确定纹理主方向,对投票点进行局部自适应软投票并选取最大值作为消失点[5];郭昕刚则先在RGB空间中进行初始分割,之后使用聚类得出像素类别并根据预设范围加以修改得到最终分割结果[6];王翔提出一种基于最大熵阈值分割和边缘检测相结合的非结构化道路分割算法,首先根据熵的阈值大小对道路图像进行初步分割,之后使用边缘检测对初步分割的错误区域重新修正,最后根据经验扫描图像中央区域像素,提取最大连通域作为道路[7]。上述方法在实际应用时易受环境影响,难以满足无人驾驶的鲁棒性要求。基于纹理的消失点检测方法往往计算量较大,实时性不能得到保障;基于RGB 的方法对环境条件要求较高,易受天气变化、光影等条件的影响;基于边缘检测的方法受限于道路类型,对弯道场景不够敏感。
近年来,基于深度学习的语义分割取得了巨大成就。FCN(fully convolutional networks)首次实现像素级别分割,开启了语义分割端到端的时代[8]。在FCN 的基础上一系列新方法应运而生,如基于扩大感受野的ENet、基于编码器和解码器结构的UNet 及SegNet、基于特征融合的DeepLabV3 等[9]。曹富强提出一种针对缺陷检测的分割算法,对神经网络中空洞卷积的空洞率加以调整,并使用多尺度融合的方式提高分割精度[10]。汪水源则利用自适应模板对分割效果进行更新,同样引入多特征融合方法[11]。经研究人员的不断优化改进,Deep-LabV3+、DANNet、PSPNet 等网络在Cityscapes 数据集上针对道路场景分割时的MIOU(mean intersection over union)值均大于0.8,但由于网络结构较为复杂,因而实时性不佳[12]。为了保证无人驾驶的安全性,道路分割的速度尤为重要,因此轻量级的网络逐渐问世。BiSeNet 就是其中之一,BiSeNet使用双分支结构并引入特征融合,降低计算复杂度,保障了快速性,常应用于无人驾驶、增强现实等对实时性要求较高的领域。综上,本文选择使用基于深度学习的像素级分割方法并对BiSeNet网络加以改进,采用更轻量的主干提取网络,引入注意力机制和深度可分离卷积,在保证分割速度的同时进一步提高精度,得到适用于非结构化道路场景下的高水平语义分割模型。
1 语义分割网络结构
1.1 BiSeNet 网络
BiSeNet[13]网络设计了空间路径和上下文路径2 个分支,分别用于编码空间信息和获取语义信息,由于空间路径输出的空间信息较为低级,上下文路径的输出为高级语义信息,因此使用特征融合模块对空间信息和语义信息进行融合,最后经8 倍上采样完成分割操作,如图1 所示。

图1 BiseNet 网络结构Fig.1 Structure diagram of BiseNet network
1.2 改进的空间路径
有效的空间信息编码和足够的感受野对于分割准确性而言至关重要。文献[14]引入ASPP(atrous spatial pyramid pooling),使用空洞卷积编码空间信息,通过池化操作和不同的空洞率实现了多尺度提取特征。文献[15]引入大尺寸的卷积核,借此捕获较大的感受野。原BiSeNet 网络则设计了包含3 层标准卷积的空间路径,该结构可以编码丰富的空间信息,但却伴随着大量的参数量。
传统的标准卷积同时兼顾特征图空间上的相关性和通道上的相关性,输入特征经一步操作得到输出。而深度可分离卷积(depthwise separable convolution,DSConv)分为2 个步骤:第1 步对输入的特征图进行深度卷积(depthwise convolution),仅考虑空间关系,对每个通道单独卷积;第2 步进行逐点卷积(pointwise convolution)获取通道相关性,卷积核尺寸为1×1,如图2 所示。
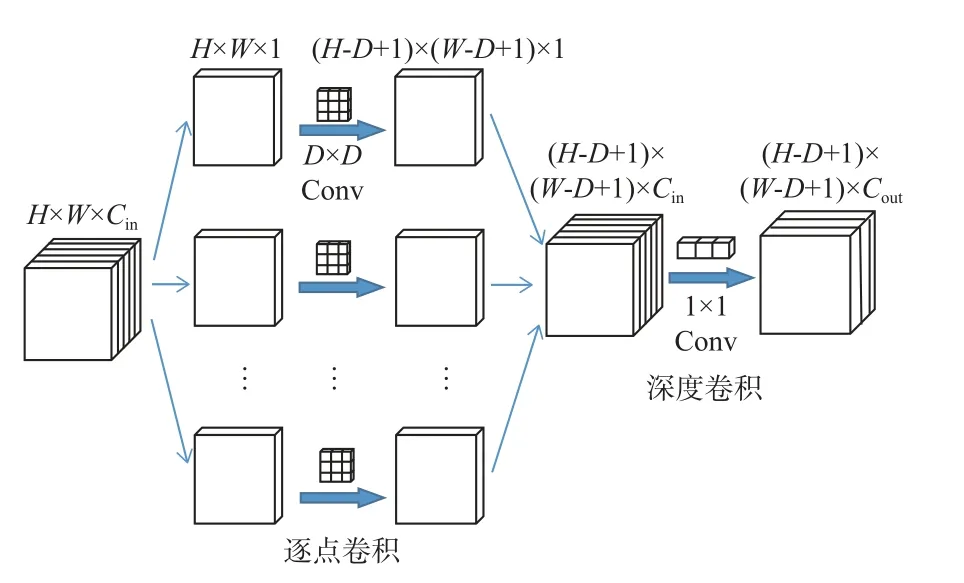
图2 深度可分离卷积Fig.2 Schematic of depthwise separable convolution
同等输入输出条件下,深度可分离卷积的参数量与标准卷积的参数量比值为
式中:Ndepth、Npoint、N分别表示深度卷积、逐点卷积、标准卷积的参数量;D×D为卷积核大小;Cin表示输入特征通道数;Cout为输出特征通道数。
由式(1)可知,相同条件下,标准卷积的参数量更大,这将消耗大量的内存资源,因此对空间路径进行改进,引入深度可分离卷积减少参数量,控制内存消耗,使网络更加轻量化。改进后的空间路径总共有4 层,如图3 所示。第1 层包括步长为2 的卷积,然后是批量归一化(batch normalization,BN)和 ReLU(rectified linear unit)激活;第2、3 层使用步长为2 的深度可分离卷积,舍弃BN 和ReLU操作,进一步减少参数量;第4 层与第1 层类似,不同的是卷积核大小为1×1,步长为1。改进后的空间路径依然保留了较大的空间尺寸,输出具有丰富的空间信息的低层次特征。同时深度可分离卷积的使用减少了模型参数量,显著降低了运算成本,在保证准确性的基础上提高了非结构化道路的分割速度。
图3 改进后的空间路径Fig.3 Schematic of improved spatial path
1.3 改进的上下文路径
原BiSeNet 使用轻量化模型Xception 作为上下文路径的主干提取网络,但该轻量化模型往往会因为通道不断的修剪而损坏感受野,在早期阶段尤为明显[16]。针对非结构化道路分割要求的准确性和实时性,对上下文路径进行改进,使用Mobile-NetV3-large[17]代替Xception。MobileNetV3-large 采用独特的Bneck 结构,如图4 所示。综合了V1 和V2版本的优势,Bneck 采用线性瓶颈的逆残差结构并融入SE(squeeze-and-excitation)注意力,对比Bise-Net 的下采样具备更好的特征提取效果,对参数量和速度控制都更加理想和高效。对MobileNetV3-large 网络结构进行部分调整;首先进行1 次步长为2 的卷积;之后经过7 个Bneck 块快速下采样,得到输入特征图1/16 大小的特征输出;再经过8 个Bneck 块,得到1/32 大小的特征,调整后的MobileNetV3-large 特征提取网络如表1 所示;之后对该1/32 大小的特征进行全局平均池化,用于提供较大的感受野和全局上下文信息;最后将不同等级的特征经过注意力细化模块后进行融合得到上下文路径的高级语义信息。改进后的上下文路径如图5 所示,图5(a)为改进上下文路径的结构,图5(b)为注意力细化模块的结构。
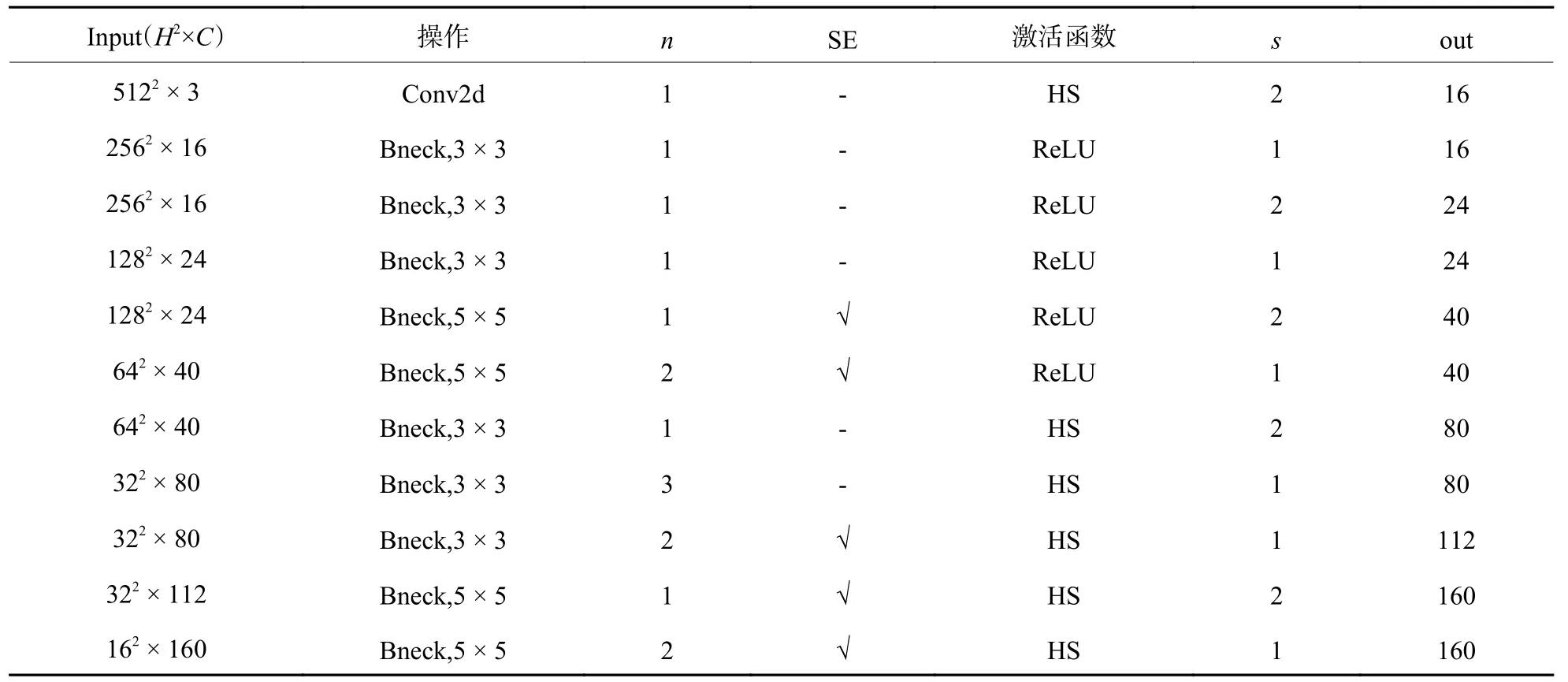
表1 调整后的MobileNetV3-large 特征提取网络Table 1 MobileNetV3-large feature extraction network after adjustment
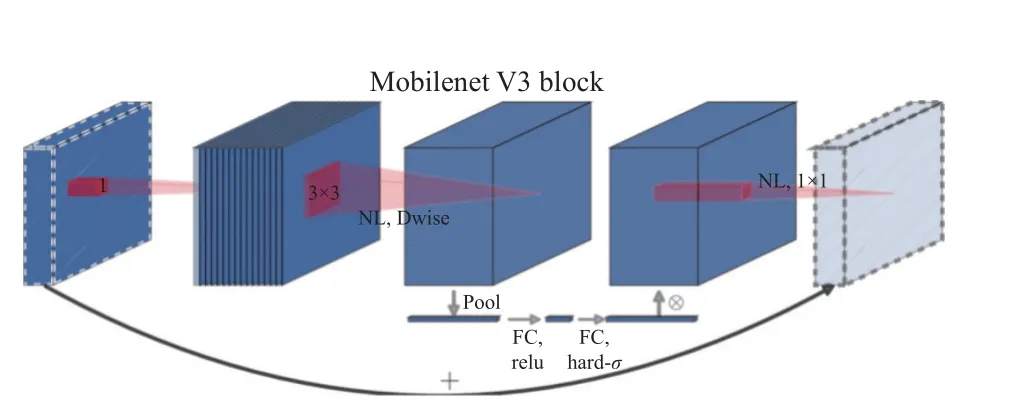
图4 Bneck 结构图Fig.4 Structure diagram of Bneck

图5 改进后的上下文路径Fig.5 Schematic of improved context path
1.4 基于注意力的特征融合模块
空间路径捕获的特征主要为包含空间细节的低级特征,而上下文路径捕获的大多是高级的语义信息特征。由于空间信息和语义信息之间层级的差距,直接进行特征融合效果较差。因此,本文设计了通道注意力特征融合模块(channel attention feature fusion module,CAFFM)来缩小空间层和语义层特征之间的差距,保证不同层级特征的有效融合,如图6 所示。

图6 通道注意力特征融合模块Fig.6 Schematic of channel attention feature fusion module
首先对不同层级的特征进行连接,完成初步融合,得到特征Y,然后对初步融合的特征分别进行全局平均池化和最大池化,得到全局上下文的特征向量Yavgpool和Ymaxpool,公式为
式中:H、W表示特征图的高和宽;Y(i,j)表示在第(i,j)位置上的元素;
然后分别对Yavgpool和Ymaxpool进行1×1 卷积通道降维、引入非线性ReLU 函数、1×1 卷积通道升维还原维度,再利用sigmoid 函数对卷积结果进行激活,得到Favgpool和Fmaxopool2 个特征,最后与特征Y融合得到最终输出Fout,公式为
式中:σ 表示sigmoid 激活函数;fconv1、fconv2、fconv分别表示降维卷积、升维卷积、标准卷积;fRelu表示ReLU 激活函数;fbn表示批量归一化操作;⊗表示逐元素矩阵点乘。
通道注意力特征融合模块引入了全局池化操作来捕捉特征的全局上下文,使用最大池化提取特征映射的局部特征信息,从而更好地推断特征映射的通道重要性。从空间层特征和语义层特征中自适应地选择重要信息或显著信息,抑制冗余信息,最后将重新加权的特征进行连接得到最终输出,大大提高了网络的特征表示能力。
2 数据集
印度驾驶数据集(Indian driving dataset,IDD)[18]是世界上第一个开源的非结构化驾驶场景数据集,具有高度不确定性和模糊性的非结构化驾驶环境,混合了城市和农村的场景。它由10 004 张图像组成,大部分图像为1 920 × 1 080 像素,少部分为1 080 × 720 像素,包含道路场景的34 个类别精细标注,原图及标签图示例如图7(a)、图7(b)所示。针对本文的实际需求,对IDD 数据集进行筛选,共选取7 688 张精细标注用于非结构化道路语义分割的图片,并对其类别重新划分,分别为可行驶区域以及不可行驶区域,如图7(c)所示,可行驶区域为绿色部分,不可行驶区域为黑色部分。按照7∶2∶1 的比例对调整后的数据集随机分配,分别用于训练、验证及测试。
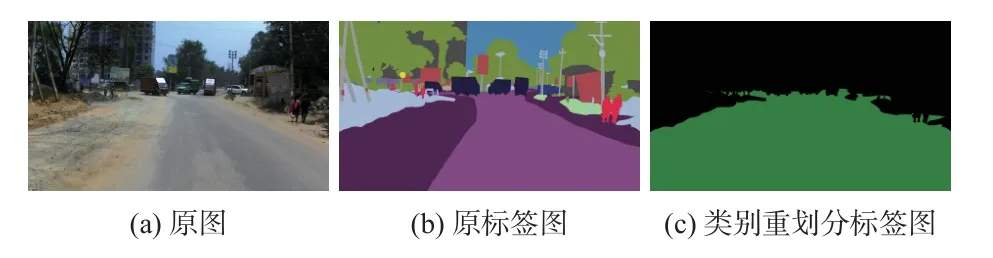
图7 IDD 数据集类别重新划分示意图Fig.7 Schematic of category reclassification of IDD dataset
因为非结构化道路复杂多变,相关数据集较少、制作难度大,无法满足数据多样性的要求。使用未经数据增强的数据集对模型训练,无法学习到足够丰富的特征,对种类繁多的非结构化道路识别没有普适性。所以对数据集进行预处理操作,消除模型训练容易产生的欠拟合和过拟合等问题,让模型可以得到更好的训练,从而具备更高的泛化能力。预处理操作包括:
1)动态模糊,用于模拟车辆颠簸导致摄像头采集图像模糊的情况,如图8(b)所示;

图8 预处理结果图Fig.8 Preprocessing results graph
2)水平翻转,用于增强网络模型方向上的不变性,如图8(c)所示;
3)亮度调整,不同天气条件下摄像头采集图像的颜色、纹理特征有所差别,对图像做随机亮度调整,以适应不同的环境光照条件,如图8(d)、图8(e)所示;
4)添加随机噪声,用于增强相机失真的不变性,如图8(f)所示;
数据增强预处理结果图如图8 所示。
3 实验结果与分析
本文使用的实验平台为 Linux 内核的台式计算机,操作系统为 Ubuntu18.04,CPU 处理器为Inter i3-3220,运行内存16 GB,GPU 为GeForce RTX 2080Ti,显存11 GB。使用pytorch 深度学习框架搭建语义分割网络模型,使用python 语言编程。统一计算设备架构版本选择Cuda10.0,神经网络GPU 加速库版本选择cudnn7.6.5。
3.1 模型训练及参数设置
训练过程中批尺寸大小batch_size 设置为4,语义分割网络每次接收4 张图片。全部数据集进行1 次训练为1 个epoch,共训练100 个epoch。使用Adam(adaptive moment estimation)优化器更新网络权重[19],初始学习率设为1e-4。Adam 表达式为
式中:mt、nt表示梯度的一阶矩和二阶矩;β1、β2表示衰减系数,设置 β1=0.9、β2=0.999;J表示目标函数对模型参数的偏导数;表示mt的修正项,表示nt的修正项;Wt表示迭代第t次的模型参数;α为0.001;ε为10-8。
训练过程中训练集和验证集的F1-score 和loss曲线变化如图9 所示。模型的验证集损失函数loss 在前10 个epoch 快速下降,随后缓慢下降,到第80 个epoch 趋于稳定,最终收敛于0.075,F1-socre稳定在0.97。
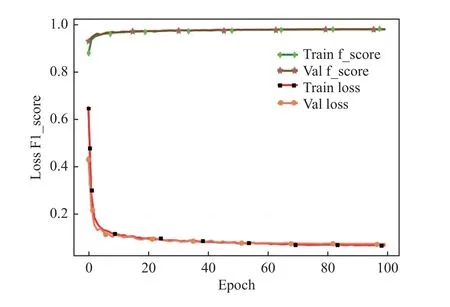
图9 F1-score 和loss 训练过程曲线变化图Fig.9 Variation curves of F1-score and loss during training
3.2 损失函数
文献[20]总结了图像语义分割常见的损失函数。一些研究人员将Dice 相似系数损失和交叉熵(cross entropy,CE)损失组合使用,获得了较为理想的分割效果,因此本文选用Dice 相似系数与Cross Entropy 组合的损失函数。本文模型的损失函数L如下:
式中:LDice表示Dice 损失;LCE表示CE 损失;X表示真实标签像素集合;Y表示预测分割结果像素集合;y代表像素的真实值;代表像素的预测结果。
3.3 评价指标
本文设计的分割模型采用F1-score、像素准确率(pixel accuracy,PA)、平均交并比(MIOU)、检测速度、模型参数量(Params)5 个指标进行性能评估[21]。设Tp、Fp、Tn、Fn分别表示正确预测可行驶区域、错误预测可行驶区域、正确预测不可行驶区域、错误预测不可行驶区域的像素数量。F1-score是衡量语义分割模型精确度常用指标,通过对精准率LPrecision和召回率LRecall加权平均得出,公式如式(11)~式(13)所示:
使用F1-score 可以有效地平衡精准率和召回率两个指标,防止某一指标很高但模型整体效果不佳的情况发生。PA 反应了模型预测图像像素与真实标签像素的误差,为正确预测像素占全部像素的比例,公式如下:
MIOU 反应了预测值与真实值的重叠程度,为预测值与真实值集合的交并比均值,本文的MIOU公式如下:
3.4 改进模型有效性验证
为验证本文改进模型的有效性,设计消融实验测试各改进部分对模型的影响。构建原始版本BiSeNet 网络模型(空间路径使用标准卷积Conv,上下文路径主干提取网络为Xception 或ResNet,特征融合使用FFM 模块)。在原BiSeNet 网络模型的基础上逐步加入MobileNetv3 特征提取网络、深度可分离卷积(DSConv)、通道注意力特征融合模块(CAFFM)构成改进后的模型,使用MIOU、F1-score、Params 3 个指标评估模型性能。在测试集上的运行结果如表2 所示。
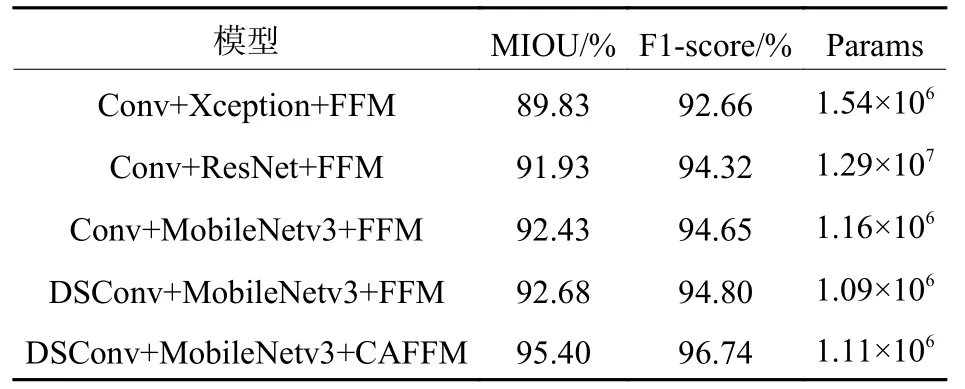
表2 不同改进措施的模型性能Table 2 Model performance with different improvement measures
可以看到,上下文路径采用轻量级网络Mobile-Netv3 代替Xception 或ResNet,使模型的MIOU 和F1-score 提高到92.43%和94.65%,同时参数量下降至1.16×106,说明MobileNetv3 的Bneck 结构逆残差和注意力机制使得特征得到有效判别,模型的分割效果得到提升;空间路径重新设计的DSConv将模型参数进一步降低至1.09×106,模型更为轻量化;CAFFM 模块融入通道注意力,利用最大池化提取局部特征、全局池化捕获特征的全局上下文,大大提高了模型的特征表达能力,虽然参数量有些许增加,但MIOU 和F1-score 提高到95.40%和96.74%,说明了该结构的有效性。
3.5 不同网络模型性能对比
选择U-Net、DeepLabV3+、FCN-32S、BiSeNet_resnet、BiSeNet_xception 等经典语义分割网络模型与本文模型进行性能对比。上述模型分别基于本文筛选并重新分类的IDD 数据集进行训练,并在测试集上使用F1-Score、PA、MIOU、模型参数量Params、检测速度Speed 5 个评价指标进行评估,不同网络模型性能对比如表3。
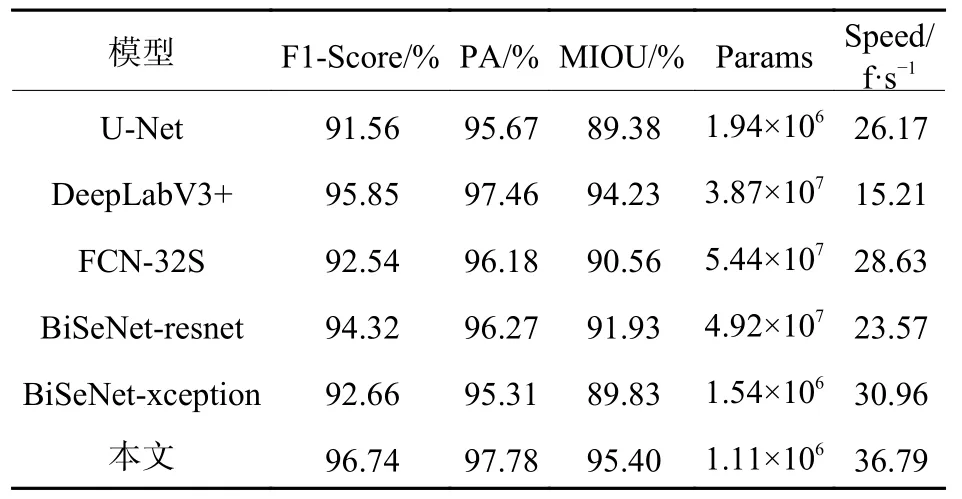
表3 不同网络模型性能对比Table 3 Performance comparison of different network models
由表3 可知,在准确性方面,本文模型的F1-Score 为96.74%,分别比U-Net、DeepLabV3+、FCN-32S、BiSeNet-resnet、BiSeNet-xception 高 5.18%、1.89%、6.2%、5.42%、8.08%;在实时性方面,本文模型使用轻量级mobilenetv3 作为上下文路径的特征提取网络,在空间路径使用深度可分离卷积,网络实时性得到很大提升,对比BiSeNet-xception 检测速度提升18.83%,分别是U-Net、DeepLabV3+、FCN-32S 模型检测速度的1.41 倍、2.42 倍、1.29 倍;在参数量方面,本文模型参数量仅有1.11×106,低于其他模型。通过与改进前模型以及当前主流分割模型的性能对比综合分析可知,本文模型兼顾实时性和准确性,具有良好的分割性能。
选用BiSeNet 及效果较好的DeepLabV3+与本文模型在不同场景下进行预测效果对比,对比结果如图10 所示。可以看到,DeeplabV3+对道路边界把控不理想,在噪声、动态模糊等情况的影响下,会出现部分错误分割,如图10(c)矩形框部分所示;BiSeNet 模型对阴影、道路转弯部分分割效果不佳,光照、噪声、动态模糊均会影响其分割效果,容易出现细节丢失的情况,如图10(d)矩形框部分所示;而本文模型可以较为准确、完整地对非结构化道路进行分割,避免了上述问题,具有较强的鲁棒性,预测效果最接近标签图像。
4 结论
本文提出了一种基于改进BiSeNet 网络的非结构化道路场景的语义分割算法,在空间路径引入深度可分离卷积,上下文路径使用MobileNetv3替换原BiSeNet 的主干网络,并在最后的特征融合部分引入注意力机制,极大地降低了模型参数量,提升了实时性的同时保证了分割精度,获得了较好的分割效果。本文算法的准确性对比其他网络都有不同程度的提高,对比原BiSeVet 检测速度提升18.83%,分别是U-Net、DeepLabV3+、FCN-32S模型检测速度的1.41 倍、2.42 倍、1.29 倍。本文模型参数量仅为1.11×106,低于其他对比模型。实验结果表明,本文改进的模型实现了速度与精度的平衡,具有良好的性能。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
开放教育研究(2020年2期)2020-03-31 01:54:14
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
现代语文(2016年21期)2016-05-25 13:13:44
CHIP新电脑(2016年3期)2016-03-10 14:22:03
计算机工程(2015年8期)2015-07-03 12:20:35
大连民族大学学报(2015年2期)2015-02-27 08:28:11
