
基于深度学习的杂草识别方法研究进展*
2023-06-05 01:32付豪赵学观翟长远郑康郑申玉王秀
中国农机化学报 2023年5期
付豪,赵学观,翟长远,郑康,郑申玉,王秀
(1. 广西大学机械工程学院,南宁市,530004; 2. 北京市农林科学院智能装备技术研究中心,北京市,100097)
0 引言
随着人口的增长,粮食需求量越来越大,但粮食的生产却面临巨大挑战,作为影响粮食质量和产量的生物因素之一,杂草和作物生长于同一空间,与作物争夺生长空间、阳光、养分,同时大田中的杂草也会为害虫提供生长繁殖的环境[1],增加了杀灭害虫的难度。
目前清除杂草的方式主要有4种:预防除草,通过消除田间杂草种子以及优化耕作模式,减少杂草生长;生物除草,在田间引入杂草天敌;化学除草,通过喷施化学药剂除草;机械除草,采用割除或翻耕覆盖的方式清除杂草[2]。上述除草方式作用对象是大田整体区域,当对无杂草区域进行操作时,浪费劳动力和增加生产成本,对靶除草技术只针对杂草生长区域进行工作,能有效减少杂草清除过程中无杂草区域对劳动量和生产成本的浪费。
对靶除草已经成为精准农业领域中的研究热点[3]。对靶除草技术主要包括杂草识别与杂草清除两个过程,其中杂草识别是进行对靶除草的首要任务,传统的杂草识别方法根据杂草的颜色特征、形状特征、纹理特征、空间特征等对杂草进行识别[4],但作物与杂草具有一定的相识性,这导致传统的杂草识别方法精度较低。近年来深度学习方法被广泛应用于田间杂草识别,深度学习通过数据输入,自动提取杂草特征,识别出目标杂草,识别精度远高于传统的杂草识别方法。基于深度学习的杂草识别方法已经取得较多研究成果,但其在技术层面上仍然存在两大难题:(1)田间环境复杂,深度学习对样本的数量具有较大的依赖性。(2)深度学习计算量大,杂草实时识别对硬件要求较高。本文通过综述深度学习硬件和软件实现以及深度学习在杂草识别中的应用,分析存在的问题,并对未来的研究方向进行展望。
1 深度学习技术与系统
深度学习是机器学习的一个分支,其本质是通过非线性映射进行特征提取学习的一个过程,采用大量数据信息训练模型,得到有利于分类的特征提取参数,通过多层非线性映射堆叠,将低级特征抽象组合成高级特征,把目标抽象化表达,进而对目标进行分类[5-7]。深度学习相较于传统的机器学习,最大的优势在于自动提取特征[8],有足够的数据去训练模型,深度学习能够更好地解决较复杂的问题[6]。在杂草识别时大量采用深度学习的方法,深度学习实现流程如图1所示。

图1 深度学习实现流程图
主要包括数据采集以及数据集制作、模型的搭建、模型训练、模型评估和模型部署,这其中涉及到深度学习方法的硬件以及软件实现,以下对整个过程进行详细叙述。
1.1 深度学习硬件需求
深度学习需要处理大量的数据,对硬件算力要求较高,在模型推理阶段,需要将训练好的模型移植到嵌入式设备上运行,这给嵌入式设备的计算能力以及功耗提出了巨大的挑战[9]。硬件的性能直接影响深度学习模型识别效果,选择合适的硬件能使基于深度学习的杂草识别达到更理想的效果。目前常用的深度学习硬件有CPU(Central Processing Unit)、GPU(Graphics Processing Unit)、FPGA(Field Programmable Gate ARRAY)、ASIC(Application Specific Integrated Circuit)[10]。不同类型的硬件各有其优缺点,以下对4种类型硬件的优缺点以及适用范围进行综述。
CPU是最为常见的芯片,主要由计算单元、控制单元和存储单元组成,遵循冯诺依曼架构,其中控制单元和存储单元占了大量的空间,相比之下计算单元部分较少,这导致CPU处理大量数据的计算能力不强。但是现在主流的CPU主频较高,在小规模数据计算方面要优于GPU,相较于GPU,CPU不适合用于较为复杂的神经网络模型的训练阶段,可以用于一些参数较少模型的推理阶段。
GPU是专为图像处理而设计的处理器,与CPU不同,其架构由大量运算单元组成,适合并行运算,与包含大量加法、乘法并行运算的深度学习模型相匹配,同时GPU有较大的内存,能存储深度学习模型大量的参数,GPU成为目前深度学习领域应用最广泛的硬件[11]。王璨等[12]使用CPU运行杂草识别模型识别玉米杂草,单张图片平均耗时1.68 s,使用GPU硬件运行后,单张图片识别速度缩短为0.72 s。彭明霞等[13]采用深度学习方法识别棉田杂草,模型在CPU上运行时,单张图片平均耗时1.51 s,采用GPU加速后,单张图片平均耗时缩短到0.09 s。姜红花等[14]采用NVIDIA GTX 1080Ti GPU代替CPU进行运算,单幅图像平均耗时0.44 s。刘庆飞等[15]在GPU上运行深度学习模型对杂草及作物进行识别,对3通道图像识别速度达到20 fps。深度学习模型在GPU上运行速度远远高于CPU,但GPU功耗较大,这使其在小型移动式设备上部署存在较大的限制,更适用于深度学习模型训练阶段。但随着NVIDIA公司推出了NVIDIA Jetson系列基于GPU的嵌入式系统,该系统具有体积小、算力强、兼容众多深度学习框架的特点,使得GPU在小型移动式设备上完成深度学习的推理阶段成为了可能。
FPGA又叫做现场可编程门阵列,是一种半定制电路,用户可根据任务要求进行编程达到想要的逻辑操作[16],与CPU、GPU相比,具有性能高、功耗低、可硬件编程的特点。但为了保证编程的灵活性,电路设计上有大量冗余,导致工作频率不高,同时FPGA的编程需要编程人员对硬件知识有一定的掌握,这提高了FPGA的使用门槛。
ASIC是针对某一类深度学习任务定制的硬件,其针对特定任务性能较好,能耗较低,但是与FPGA相比,ASIC硬件制作完成后不能更改,这导致使用灵活性较差,同时硬件的设计、制作需要花费较长的周期,导致成本较高。目前针对深度学习而设计的专用ASIC芯片较多,例如NVIDIA公司推出的NVIDIA Tesla P100显卡,其性能是同期NVIDIA公司推出的GPU显卡性能的12倍。谷歌公司针对张量计算设计了TPU芯片,2016年中国科学院计算机研究所发布了名为寒武纪的全球首个支持深度学习的神经网络处理芯片。
综上所述,不同的硬件有各自的优缺点[17],如表1所示,CPU与GPU相比性能较差,不适合用于模型的训练;GPU性能好,但是功耗高,体积大,适用于模型的训练阶段,但在小型移动设备上完成模型推理阶段具有一定挑战;FPGA性能好,能耗低,但其编程较难,入门门槛高;ASCI性能好,但成本高。

表1 深度学习硬件开发情况对比Tab. 1 Comparison of deep learning hardware development
1.2 深度学习软件实现
深度学习软件实现主要包括以下过程,图像采集、数据集制作、深度学习框架选择、搭建深度学习模型、模型训练、模型评估以及模型部署。
1.2.1 图像采集及数据集制作
深度学习模型需要大量数据进行训练,从而提高模型的识别准确率。在杂草识别中大量的杂草及作物图片数据可通过不同的设备进行采集,采集后可使用labelme、labelimg等标注工具对采集图片进行标注,并将数据集按照一定比例分为训练集、测试集、验证集,用于模型的训练、性能评估和参数优化。
在图片数据的采集过程中工业相机、手机等是较为常用的图像采集设备,工业像机、手机一般手持或者被固定安装于移动装置上,并与目标作物以及杂草保持一定的距离进行拍摄。如Olsen等[18]采用手持高清摄像机在不同光照条件下采集了17 509张杂草及作物图片。Suh等[19]将摄像头安装于1 m高的移动平台上,相机光轴垂直地面,移动平台以0.5 m/s的速度运行,拍摄大豆与杂草图像。刘亚田[20]使用手机对不同生长时期的玉米进行拍摄,共采集1 600张玉米杂草图片。
无人机也常被用于图像数据采集,张茹飞[21]使用大疆无人机并设置飞行高度为2 m,采集小麦以及杂草图像。Alessandro等[22]使用无人机采集大面积的大豆图像,该图像可用于制作杂草地图。
除了在研究时通过电子设备采集图像并制作数据集,也可使用网上公开数据集获取数据进行研究。Sudars等[23]公开了一个由6种作物和8种杂草共1 118 张RGB图片组成的数据集。Olsen等[18]制作了一个澳大利亚北部地区8种主要杂草数据集,该数据集总共包含17 509张图片。其他一些网上公开数据集有Plant Village、Plant Seedlings Clasification[6]等。
1.2.2 深度学习框架
深度学习模型需要在深度学习框架上训练,常用的深度学习框架及其接口语言如表2所示。
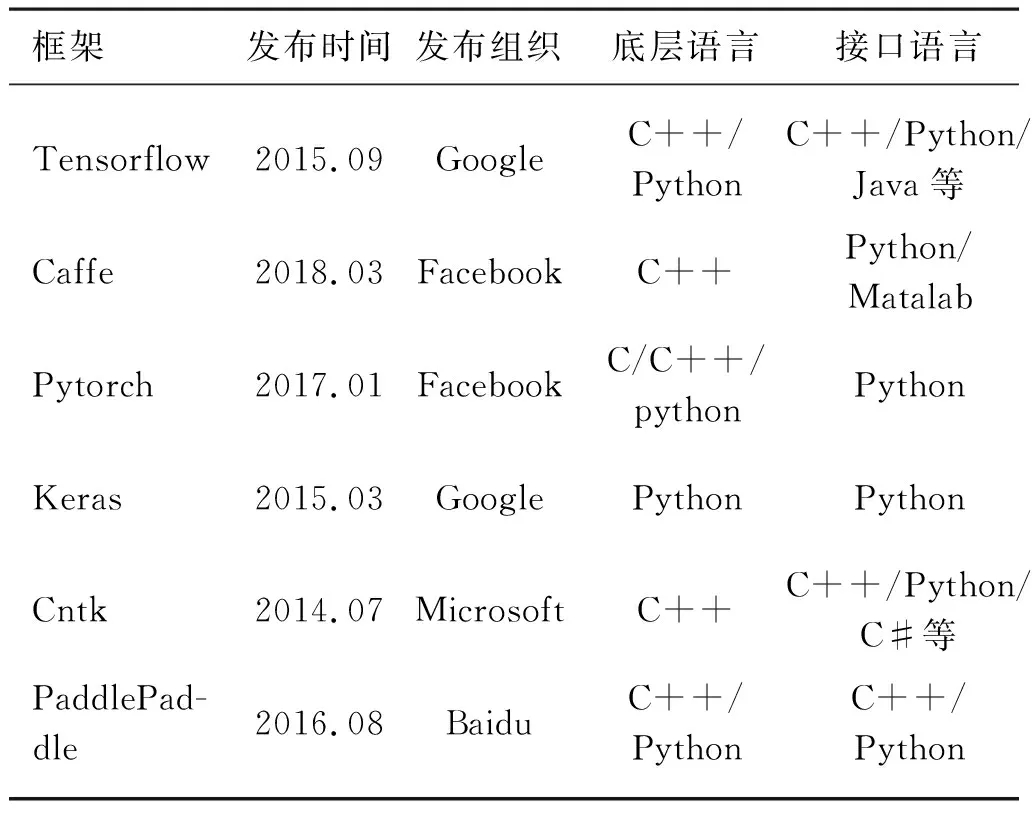
表2 常用深度学习框架Tab. 2 Common deep learning frameworks
其中较为常用的框架为Tensorflow和Pytorch等,Tensorflow是Goolge于2015年发布的深度学习框架,使用的接口语言为C++/Python/Java等,可使用语言种类较多,同时其可以部署于一个或多个CPU、GPU服务器中;Pytorch是Facebook于2017年发布的深度学习框架,其优点在于能实现强大的GPU加速,还支持动态神经网络。目前Pytorch更多应用于学术研究,而Tensorflow多应用于工业生产。
1.2.3 深度学习模型
以常用于图像分类识别的卷积神经网络(Convolutional neural networks,CNN)为例对深度学习模型进行说明。CNN是由输入层、卷积层、池化层、全连接层以及输出层组成的一类前馈神经网络[24],如图2所示。输入层是整个卷积神经网络的输入,在图像分类任务当中,输入层输入的是图像的像素矩阵;卷积层是卷积神经网络的核心部分,其作用是利用卷积核检测输入的图片或特征图中不同位置的局部特征,并输出到下一层[25],卷积层的计算过程如图3所示,卷积核扫描输入的像素矩阵,对应位置的数值相乘,其和作为下一层特征图的一个像素值,卷积核扫描完一张图片后,即可得到一张对应的特征图,该特征图作为池化层的输入;池化层计算过程如图4所示,采用一个选择框,框选特征图元素,并对其进行计算(取框内数据均值或者最大值),得到的结果作为下一层特征图的像素值;全连接层主要是将提取到的特征图转换成列向量并映射到对应的样本空间[26];输出层即输出图像分类结果。

图2 卷积神经网络结构示意图

图3 卷积运算示意图

图4 池化运算示意图
目前已经出现了较多成功的深度学习模型,例如VGG Net[27]、Google Net[28]、ResNet[29]等,现阶段用于杂草识别的深度学习模型,大部分是在已有模型的基础上进行优化设计。
训练神经网络模型就是求取模型中各个参数最优值,是一个监督学习的过程。在深度学习模型训练阶段,需要设置损失函数和优化器,损失函数用于计算经过一次训练后,模型输出的预测值与真实值的偏差,优化器的作用是进行反向传播运算,改变神经网络参数,使损失函数的值下降,最后收敛。当损失函数收敛后,此时模型的参数较优。在训练时神经网络模型的各参数的初始值可以设置为随机值,也可以用迁移学习的方法设置初始值,即使用已训练好的模型参数值为所训练模型的参数值初始值。该方法可以减少模型训练的时间,同时能缓解样本数据少导致训练出的模型精度不高的问题。Abdalla等[30]使用迁移学习的方法,用IMGNET数据集训练的VGG16模型参数作为杂草识别模型参数的初始值,迭代25次后,损失函数收敛,而采用参数随机初始化的方法,迭代50次后,损失函数收敛。同时在小规模数据集上采用迁移学习的方式进行训练,可以得到较好的训练结果,邓向武等基于深度学习和迁移学习相结合的方法,使用650张图片训练了稻田杂草识别模型,该模型在测试集上的准确率达到了96.4%。
1.2.4 模型评价指标
根据不同的杂草识别任务目标,深度学习模型有不同的性能评价指标,对于分类任务,常用的模型评价指标有准确率(Accuracy)、精准率(Precision)和召回率(Recall)。准确率表示所有样本都正确分类的概率,既包括正样本也包括负样本,样本较多时准确率不能全面评价分类模型性能;精准率表示预测为正样本的目标中预测正确的比例,精准率能表示一个类别的正确率;召回率表示所有正样本中被检测出来的比例;在多分类任务中,可分别计算每个类的精确率和召回率。准确率、精准率、召回率的计算如式(1)~式(3)所示。
(1)
(2)
(3)
式中:TP——正样本预测成正样本的数量;
FP——负样本预测成正样本的数量;
TN——正样本预测成负样本的数量;
FN——负样本预测成负样本的数量。
在目标检测和语义分割任务中,常采用交并比(Intersection over Union,IoU)评价模型的性能。交并比如图5所示,为候选框(candidate bound)与原标记框(ground truth bound)交集与并集的比值,交并比越大,模型性能越好,交并比计算公式如式(4)所示。
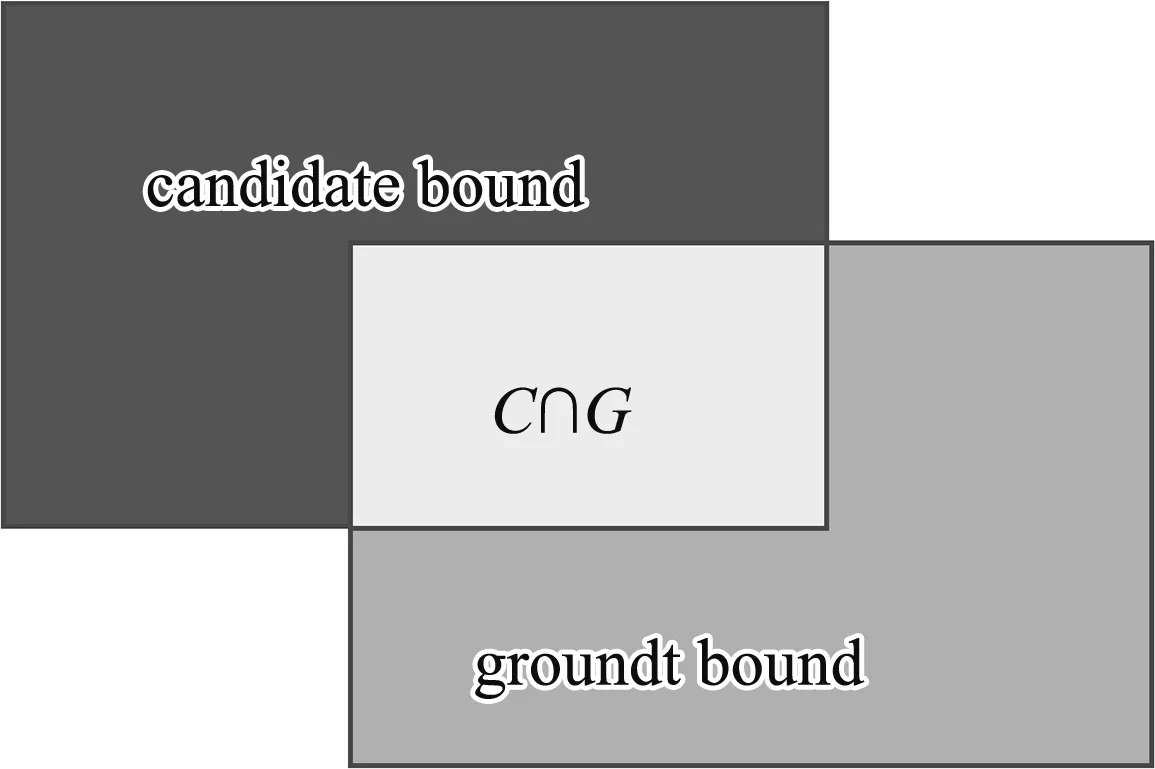
图5 交并比示意图
(4)
1.2.5 模型部署
深度学习应用的最后一步为模型部署,根据杂草识别的工作要求,将训练好的模型部署于嵌入式设备上进行推断。本文以在NVIDIA Jeston Xavier NX上部署使用Pytorch框架训练的杂草识别模型为例,叙述深度学习模型的部署过程。在NVIDIA Jeston Xavier NX上部署使用Pytorch框架训练的模型有两种方法,第一直接使用Pytorch框架进行部署,在NVIDIA Jeston Xavier NX上配置Pytorch环境,并将训练好的模型拷贝到NVIDIA Jeston Xavier NX上运行即可,这种部署方式要求嵌入式设备支持使用的神经网络框架;第二种部署方式,采用NVIDIA Jeston Xavier NX的TensorRT模块进行部署,采用TensorRT模块部署时,首先将Pytorch模型转成ONNX模型,同时使用TensortRT模块内置函数将ONNX模型转化成TensorRT模型,即可应用于TensorRT框架进行前向传播推理。TensortRT模型将模型权重参数量化为INT8类型,同时将神经网络层与张量进行融合,进而能提高模型的推理速度。
嵌入式设备算力较低,在部署深度学习模型前,可以对模型进行加速优化,以提高在嵌入式设备上的推理性能。常用的模型优化方法有网络剪枝与稀疏化、张量分解、知识迁移。网络剪枝与稀疏化是将神经网络中输出值趋近于0的神经元删除;张量分解的主要思想是将卷积网络中的张量分解为若干低秩张量,减少卷积操作的运算量,降低对嵌入式设备的算力要求;知识迁移是基于迁移学习的思想产生的,将复杂的教师模型的知识迁移到学生模型上,完成对网络结构的简化[31]。
2 深度学习在杂草识别中的应用
2.1 在作物与杂草识别定位中的应用
在基于深度学习的作物与杂草识别方法中,主要采用的是目标检测模型、语义分割模型和实例分割模型。目标检测模型用于估计特定类型目标出现在图像中的具体位置[32],杂草识别中常用的目标检测模型有Faster R-CNN[33]、SSD[34]、YOLO[35]等。孟庆宽等[36]将SSD网络中提取到的图像浅层细节特征与深层语义特征相融合增强目标特征信息,融合后的特征图作为杂草分类识别依据,并用深度可分离卷积代替传统卷积轻量化网络,采用优化后的SSD网络模型对幼苗期玉米及其伴生杂草进行识别,平均识别准确率mAP(mean Average Precision)达到了88.27%,与标准SSD模型相比,精度提高了2.66%,同时检测速度由24.10 f/s提高到了32.26 f/s。樊湘鹏等[37]测试了VGG16、VGG19、ResNet50和ResNet101四种特征提取网络的性能,综合考虑了特征网络的检测精度、检测速度,确定使用VGG16为特征提取网络构建优化的Faster R-CNN模型对自然条件下棉花幼苗及其7类常见杂草进行识别,mAP为94.21%,优于标准SSD(87.23%)和YOLO(84.97%),但0.385 s的单张图片处理时间高于SSD(0.297 s)和YOLO(0.314 s)。薛金利等[38]改进YOLO_V3模型用于识别棉花及杂草,mAP达到94.06%,检测速度为51 f/s。彭明霞等[13]设计了融合特征金字塔网络的Faster R-CNN模型识别自然光照下的棉花与杂草,mAP达95.5%,比传统的YOLO_V3高30%,但识别一帧图像需要1.51 s,高于YOLO_V3(1.35 s)。李春明等[39]提出一种融合生成对抗网络的Faster R-CNN模型,对正常拍摄的图片进行识别,mAP达到97.05%高于传统Faster R-CNN(92.72%),同时单张图片处理时间0.21 s高于传统Faster R-CNN(0.14 s)。
在目标检测的方法中以YOLO和SSD为代表的一阶段检测模型在检测速度上相比二阶段检测的Faster R-CNN具有一定的优势,但检测精度方面略低;同时,采用目标检测的方法识别作物和杂草,能获取杂草和作物的位置信息以及杂草的类别信息,但无法提取杂草形状特征,判断作物及杂草的生长阶段,该方法可用于不考虑杂草大小以及生长阶段的除草方式。
语义分割模型的功能是为图像中的每一个像素点打上标签[40],在杂草识别中,即为表示作物与杂草的像素点打上标签进行分割。Asad等[41]结合极大似然估计法对杂草作物数据集进行标注,采用该数据集训练模型,平均交并比MIoU(Mean Intersection over Union)为82.88%。孙俊等[42]提出一种深度可分离卷积的卷积神经网络模型用于甜菜与杂草图像分割识别,MIoU为87.58%,图片识别帧频为42.064 f/s。You等[43]提出一种融合注意力机制及金字塔卷积的模型,用于识别甜菜和杂草,MIoU达到89.01%。Potena等[44]设计了深层神经网络用于识别蔬菜和杂草,mAP最高为91.3%,单张图片处理时间最低为0.98 s。王璨等[12]提出一种基于卷积神经网络的玉米杂草识别方法,mAP为98.92%,单幅图像平均耗时1.68 s。语义分割的方法能对作物和杂草进行分类,并提取出杂草以及作物的外形特征,但不能对同种杂草的不同个体进行判断区分,无法针对单个杂草个体进行定向除草。
实例分割是将整个图像分成单个像素组,然后对其进行标记和分类,达到识别和分割图像中每一个实例的深度学习模型。在杂草识别中常用Mask R-CNN[45]及其改进模型做实例分割。权龙哲等[46]提出一种改进的Mask R-CNN模型,对复杂田间环境下的杂草和玉米进行识别,MIoU为67.5%。姜红花等[47]提出一种基于Mask R-CNN的杂草检测方法,在复杂背景下对玉米、杂草图像进行测试,mAP为78.5%高于SharpMask(68.4%)和DeepMask(46.2%),但是其单张图片处理时间为0.285 s高于SharpMask(0.260 s)和DeepMask(0.252 s)。实例分割是语义分割与目标检测的结合,能有效获取杂草种类、位置、轮廓等特征信息,但该方法一般算法较为复杂以及前期数据集制作较为麻烦,所以该方法在杂草识别中使用较少。针对不同的除草任务要求,可选择相应的杂草识别方法。
2.2 在杂草分类识别中的应用
杂草分类识别就是输入一张杂草图片(图片中最多只能包含一类杂草),输出图片中的杂草类别。深度学习方法是目前主流的图像分类方法,在对杂草分类识别中也较为常用。赵轶等[48]基于VGG16卷积神经网络对田芥、猪殃殃、鹅肠草等12种杂草进行分类识别,准确率达95.47%,高于SVM(89.64%)和Random Forest(90.03%)。王术波等[49]基于CNN模型对小麦、花生、玉米以及3种伴生杂草(藜草、葎草、苍耳)分类识别,准确率达到95.6%。Andrea等[50]基于优化CNN网络对玉米及杂草进行分类,准确率最高为97.26%。Hu等[51]采用图神经网络(Graph Neural Network,GNN)识别马樱丹、银胶菊、多刺洋槐等8种杂草,准确率为98.1%。徐艳蕾等[52]基于轻量卷积网络识别自然条件下玉米幼苗及8类杂草,准确率为98.63%,单张图片检测平均耗时0.683 s。Ahmad等[53]采用VGG16识别玉米和大豆田中4种杂草(苍耳、狗尾草、反枝苋和豚草),准确率达到98.90%。Jiang等[54]设计了一种基于CNN的图神经网络在玉米杂草数据集、莴苣杂草数据集和萝卜杂草数据集上,准确率分别为97.8%,99.37%,98.93%,均高于传统CNN模型。王生生等[55]基于轻量和积网络对大豆苗、禾本科杂草以及阔叶型杂草进行分类,准确率达到99.5%。
杂草分类局限于图片中只有一种杂草,分类对象为整张图片,该模型一般为杂草定位识别模型的研究基础,或用于杂草分类识别系统的研制。
2.3 深度学习在杂草识别中应用的优势
采用深度学习的方法识别杂草,识别精度高。本文杂草识别与定位部分引用的论文当中,平均识别准确率最低的是88.27%,其中李春明等[39]设计的深度学习模型杂草识别准确率达到97.5%,在杂草分类识别部分,识别准确率均高于95%。
深度学习方法可以自动提取大量特征。传统图像处理采用手工提取特征的方式,且特征提取数量较少,这可能导致提取的特征无法全面表征作物或杂草,同时手工提取特征需要较多的经验,提取特征难度较高,甚至一些目标无法手动提取特征,然而深度学习方法能自动提取大量特征。
2.4 深度学习在杂草识别中应用的不足
采用深度学习的方法进行杂草识别虽然有自身优势,但也存在较多的不足之处。主要体现在以下几个方面。
1) 目前大部分学者采用监督学习的方式进行训练深度学习模型,该方法需要大量作物和杂草数据,同时需要对这些图片进行标注,整个过程较为繁琐。未来可采用无监督学习或半监督学习的方法来解决此问题,大大减少数据集采集与标注中所消耗的劳动量。无监督学习或半监督学习使用未标记数据集或少部分标记数据集训练模型,目前对于多分类识别任务,计算机无法自动将分类好的目标打上标签,这是无监督学习的缺点与研究难点。同时随着生成对抗网络的发展,使用生成对抗网络生成新的图像数据,进而扩充数据集,这将会成为以后研究热点。
2) 深度学习方法进行杂草识别能获得较高的识别精度,但是深度学习模型层数较深,通过大量的卷积运算提取图像特征,在进行前向推理过程中进行大量的并行计算,当模型部署于功率小、算力低的嵌入式设备上时,杂草识别模型的图像处理时间较长,难以达到实时检测的目的。模型轻量化研究和研究模型剪枝技术、模型蒸馏等方法对模型进行加速优化,使模型能部署于计算能力较低的设备上是一种趋势。
3) 模型设计复杂,无法从数学角度对模型的性能进行分析,在进行杂草识别模型设计时,需要进行大量的试错,模型设计时间长,且需要占用大量的计算资源[56]。
3 存在问题
3.1 数据需求量大,无通用数据集
基于深度学习的杂草识别模型较高识别准确率是基于数量多、信息全的杂草图像数据集训练得到的。在非结构化的农田环境中,要获得全面的杂草数据集,需要采集不同光照、不同生长周期、不同种类的杂草图像,该过程需要花费大量的时间和劳动力。目前,研究人员在构建数据集时,一般只针对某个区域生长的几种类型杂草,其他科研人员采用该数据集训练杂草识别模型,一般会遇到数据集中杂草种类不同或缺少的问题,无法使用该数据集,进而需要重新采集,造成大量的重复工作。
3.2 遮挡影响靶标识别准确性
在作物的生长过程中,杂草与作物相互遮挡是较为常见的情况,对于遮挡部分,目标不完整、不易分辨,无法准确提取到杂草/作物靶标特征[57]。遮挡分为完全遮挡和部分遮挡两种情况,杂草被完全遮挡,目前无有效方法解决,部分遮挡又可分为非目标造成的遮挡和需要检测的目标造成的遮挡,对于非目标物造成的遮挡,目前的解决办法是采用更多的数据和更丰富的特征信息进行模型训练,对于目标物产生的遮挡,可借鉴图卷积神经网络、胶囊网络和目标检测中的推理关系网络来提高部分遮挡情况下识别准确率[58]。
3.3 识别精度受运动模糊影响
相机的成像质量与其曝光时间有关,在运动状态下曝光时间过长容易引起运动模糊,丢失目标区域部分特征信息,不能准确地获取杂草纹理特征和轮廓特征,影响靶标的准确识别。
3.4 识别精度受光线影响
在强光直射、光线不均条件下,易引起杂草表面整体或局部反光严重。成像时靶标整体或局部纹理特征、轮廓特征变模糊,采集到的靶标特征量变少,造成深度学习模型在分类识别时难以精确区分。
4 展望
1) 农作物和杂草植物有许多相似之处,融合光谱数据信息可以提高深度学习性能。然而,缺乏关于作物和杂草的大型数据集。有必要通过从不同的地理位置、天气和环境中采集各种作物/杂草建造一个大型的数据集,适应作物和杂草的不同生长阶段。
2) 杂草分类识别后,建立杂草作物生长模型,对杂草作物长势进行预测,判断最佳除草时间。目前大部分基于深度学习的杂草识别方法主要针对某一个生长阶段的杂草进行分类识别研究,没有建立相关模型对杂草生长周期进行预测,而在进行施药除草时,不同的杂草喷洒除草剂效果最佳阶段不同,在杂草识别之后根据相关信息,建立杂草生长模型,对未来杂草长势进行预测,选择最佳的喷洒除草剂的时间是很有必要的。
3) 杂草识别模型模块化发展,目前研究的杂草识别方法大多数只针对一种作物和与其伴生的几种杂草,识别范围有限,未来发展时可考虑模块化设计,即通过更换其中某个模块的某些参数,即可对其他作物与杂草进行识别,扩大部署杂草识别模型的设备使用范围。
4) 2020年中国工程院发布《全球工程技术前沿2020》,农业机器人作业对象识别与定位作为在农业领域公布的11个工程研究前沿之一,与生态无人农场理念的众多关键技术密切相关,是农业领域未来发展的重要方向。杂草识别是作业对象识别与定位的重要方面,如何将识别模型部署于无人机、田间移动平台,仍是后续研究需要解决的问题。
猜你喜欢
科教新报(2022年22期)2022-07-02
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
现代农业(2015年5期)2015-02-28
电视技术(2014年19期)2014-03-11
