
水下机器人实时智能裂缝检测算法
2023-06-03 03:40邱昕捷韩凤磊赵望源
哈尔滨工程大学学报 2023年5期
邱昕捷,韩凤磊,赵望源
(哈尔滨工程大学 船舶工程学院,黑龙江 哈尔滨 150001)
我国是拥有水坝最多的国家,随着时间的推移,大坝可能产生一些人为或非人为的损伤而产生裂缝,严重地会带来不可逆的严重后果,因此坝体水下部分的裂缝检测就成为坝体维修与维护的重要工作之一。坝体的裂缝不同于路面上的裂缝,首先由于受到水下环境影响,坝体裂缝图像普遍存在着低对比度、颜色衰减、强噪声等问题,因此现有路面裂缝检测算法无法满足坝体水下裂缝检测的工程需求。其次,水下坝体裂缝可供标注的图像样本比较少,使用传统人力的方法不仅需要检测人员有精湛的专业技术,同时还需要潜水技术和合适的作业时间段和时间长度。近年来,通过水下机器人对大坝复杂环境进行检测成为主流,其搭载的摄像模块能够满足视频交互传输,但仍需人工观测才能获取大坝裂缝相应信息。针对裂缝检测的问题,王军等[1]将多尺度滤波和Hessian矩阵结合在一起,从而获得了裂缝的提取。赵芳等[2]使用的是改进的canny算法,但是无法有效抑制噪声且需要人为调整阈值,同时canny算法只检测了边缘,可能与水下的其他物质所混杂。朱苏雅等[3]使用U-net分割出图像中的裂缝,并且进一步地对图像的裂缝进行测量,但是计算量较大,难以满足实时性要求。毛莺池等[4]为了解决裂缝的多目标、小目标的检测精度不高的问题,对Faster R-CNN[5]进行了改进,但检测速度和精度需要进一步提高。Ji等[6]提出了使用语义分割网络DeepLabv3+的集成方法用于裂缝检测。DeepLabv3+[7]的网络虽然属于较前沿的算法,但是计算效率不高很难达到实时性。因此,此前的算法很难同时满足裂缝检测中的3个要求,即精准性、实时性、可后续研究性。因此需要一种能同时满足这3个要求的检测算法以满足水下作业的工程需求。PSP Net是一种运行速度较快,且能应用于语义分割的网络[8]。因此本文通过应该用水下机器人对真实大坝裂缝进行检测,提出改进的金字塔池化网络(PSP Net)义分割算法以适应大坝在不同水域的水下环境,对不同走向、不同成因的水下裂缝实现高精度实时检测。同时提出激光辅助测量的裂纹面积计算方法,并在真实环境下实现工程应用。
1 语义分割
1.1 网络改进
PSP Net是一种拥有金字塔池化模块用于语义分割的结构,PSP Net的结构如图1所示。PSP Net和Aspp[9]类似,在保留全局平均池化处理的同时,转移了DCNN的位置的,增加了金字塔池化模块从而减少子区域之间上下文信息的损失。从图1看,PSP Net主要可以分为4个部分:输入图片、主干特征提取网络、金字塔池化模块、输出图像。

图1 PSP Net结构Fig.1 PSP Net structure
PSP Net的主要功能体现于特征提取网络、金字塔池化模块。可利用常用的特征提取网络(本文以轻量化卷积神经网络mobilenetv2为例)对输入的裂缝图像进行特征的提取,随后将所提取的裂缝特征结果分为2部分,一部分传入金字塔池化模块,另一部分跳过池化、卷积等流程直接传入后方。金字塔池化模块融合了4种不同尺度下的裂缝特征,对每个子区域进行平均池化操作,得到不同尺寸的裂缝特征图,对不同位置的语义进行聚合,使裂缝预测模型拥有了理解全局的能力。最后将上述采样结果与特征层的裂缝特征提取结果融合经过卷积输出预测的裂缝图像,获取不同尺寸图像的特征信息,以提高分割精准率。
本文将原网络进行改进,着重将输入进来的特征层重新分成1×1、2×2、4×4、8×8的区域(原为1×1、2×2、3×3、6×6),其主要原因就是在这4次卷积中,后者都是前者的整数倍数,可以使所划分的区域得到一定的关联,从而弥补了部分原始区域中无法有效地形成块与块之间的联系的不足。这种做法可以进一步地使得不同区域的上下文信息得到相关联,从而减少区域与区域之间上下文信息的损失、提高获得准确的全局信息,以减小输入图像在语义分割中因未获得足够多、足够准确的全局信息而产生关系不匹配、类别混淆、类别不显著等错误产生的概率。
同时在最初训练时,由于背景的颜色、轮廓、纹理等基础特征相似,可以将主干特征提取网络冻结起来已达到为了增大训练效率的目的。
1.2 超参数优化
合适的超参数对网络的训练速度以及语义分割的准确值有着重要的影响。同样的网络在处理不同的问题的时候有着不同的超参数选择,因此不能一味地使用默认的超参数来训练网络。常见的超参数有:总训练回合、学习率、学习衰减率等,又由于此次实验存在着冻结主干特征提取网络的操作,因此有新的超参数可选择:冻结回合数、解冻回合数等、解冻前后的学习率变化。虽然可供选择的超参数有许多,但是有许多超参数对实验的结果并无太大的影响,同时为了满足超参数之间的独立性,因此,本文只选取以下超参数作为研究:总训练回合,其是深度学习的重要变量,回合不足易导致训练不充分,回合太多可能会发生过拟合现象;冻结回合与解冻回合之比,可以结合总训练回合计算出冻结回合数与解冻回合数,减少变量数;初始学习率、学习衰减率、学习率也是深度学习的重要变量之一。
1.3 评价指标
评价指标是检验水下裂缝检测是否精确的重要依据,本文使用损失值和MIoU(mean intersection over union,平均交并比)值来作为评价指标。损失值所采用的是交叉熵损失与dice损失[10]之和;MIoU值选取第1、25、50、75和最终回合(其中最终的MIoU值为第95~100回合的最小损失值的回合的MIoU值)进行记录,以反应训练趋势与最优的训练结果。
2 面积计算
在预测出裂缝以后,可以运用预测以后的裂缝进行一定的工程应用,比如计算裂缝面积从而确定修补方式和用料数量等信息。
2.1 图像预处理(光斑识别)
图像预处理的目的就是为确定光斑间的距离,以便图中距离与实际距离的换算,其流程如图2所示,计算机逐帧获取摄像头所捕获的画面,将图像转换为灰度图。

图2 图像预处理流程Fig.2 Image preprocessing process
Gray=B×0.114+G×0.587+R×0.299
(1)
式中:B、G、R分别为蓝色、绿色、红色三通道的像素值。Gray为处理后得到的单通道像素值。
对灰度图进行平滑处理以减少高频噪声。平滑处理的方式有许多,这里主要使用高斯滤波进行处理。
(2)
式中:x、y表示相对坐标值;σ表示高斯核标准偏差。
对平滑后的图像应用阈值化方法,以显示出光斑的区域,将所有像素值大于200的所有像素点筛选出来并将其设置为255(白色),反之则设置为0(黑色)。
(3)
若此时依旧无法检测出有效光斑,则对阈值图进行腐蚀膨胀操作。
A⊕B={z∣(B)z∩A≠Φ}
(4)
AΘB={z∣(B)z⊂A}
(5)
式中:A表示图像;B表示结构元素;A⊕B表示对A进行以B为结构元素的腐蚀操作,AΘB表示对A进行以B为结构元素的膨胀操作[11]。
随后根据其像素大小进行合适的阈值筛选,重复多次后即可获得所需要的光斑,最后标记光斑位置并计算光斑间距离。
2.2 计算方法
首先需要将图中距离与实际距离进行换算,即计算图中距离与实际距离比例尺:
(6)
式中:L为比例尺,pixel/m;x0为激光光斑之间的图中距离,由计算机对预处理的图像进行计算而得,通常为以像素为单位,且可以存在小数;d为激光光斑之间的实际距离,也为激光光点水平安装的距离,在水下机器人下水前可进行调节,通常为已知量,且以米为单位。
其次根据所得的比例尺就可以直接求得裂缝通过语义分割所预测到的面积:
(7)
式中:S表示需要测得的实际面积,m;S0为图中面积,由计算机对语义分割后的图像对某一颜色遍历而来(本例中裂缝的颜色为红色),通常以像素为单位。这里需要注意的是,此式的左右的单位并不统一,其主要因为在图像数字化中,像素可以同时被作为长度和面积单位进行计算。
但是,这种计算方法也同样存在着许多限制,如:大坝面与光源发射点间的直线不平行就容易产生误差。
3 实验结果
3.1 图像数据集
实验从水下机器人所拍摄的视频流中,提取了四川某大坝的水下裂缝约500张,同时为了防止样本的数量不足与特征单一性,选取了其中180张进行旋转。并使用从GitHub获得的开源标签工具labelme(主要可应用于语义分割与实例分割)在所预处理的图像中进行手动标注,并将其表存为.json文件,其中.json文件主要记录了图像内所标注的类别以及对应的类别所对应的标注点,可进一步地将.json文件转化为所需要的二值图。图3表示出了手动标记的图像,依次表示了原图、标注情况、二值图(其中黑色属于背景类,红色属于裂缝类)。

图3 手动标注图像过程Fig.3 The process of manually labeling images
3.2 配置与参数
实验在基于GTX1080的笔记本电脑上进行。在最初训练时,设置冻结时的训练轮次为默认值50轮,学习率为默认值0.000 1,训练的批次大小为4。在模型解冻以后,为了防止训练过程中数据震动,学习率为原来的1/10,同时由于解冻以后占用了更高的显存,由此设置训练的批次大小为2。同时为了使网络轻量化,所有的特征提取网络均使用mobilenetv2[12]
3.3 检测结果
此次实验以25回合为步长,分别选取了回合数等于1、25、50、75、100的图片与原图对比。
在图4 (b)中,可以明显发现,刚开始训练时对背景与水下裂缝的划分明显不够精准;在图4(c)中逐渐满足要求,但与预期结果还相差甚远;图4 (d)中可以看到效果进一步明显地改善;图4 (e)中,达到收敛,此时也十分符合要求;图4 (f)中,由于训练已经达到了收敛,因此和图4 (e)的差别不大。

图4 实验结果Fig.4 Experimental results
为了进一步测试语义分割的结果,本文选取了不同新图像对结果测试。结果表明经过改进以后的PSP Net网络可以对不同种类的裂缝进行较好地识别,可以识别的类型包括:竖裂缝、横裂缝细裂缝、粗裂缝、抖动拍摄裂缝、分叉状裂缝、复杂状裂缝、多条裂缝。
图5(a)~(c)所示,这几种形态的裂缝具有常见的纹理及其走向,并且也在水下机器人对大坝面的采集中十分常见,因此使得预测的结果十分精准;图5(d)所表现的是那种粗大状的裂缝,其主要特征就是内部的纹理十分复杂,因此加大了预测的难度;如图5(e) 所示,此类裂缝在现实生活中不会出现,通常出现于摄像头捕获的视频的某几帧中,其主要是因为水下机器人在横摇或者旋转的过程中摄像头的瞬时速度过大,导致捕捉的画面模糊。根据结果不难发现,改进以后的PSP Net网络对此类图片的预测也有不错的结果;图5(f)~(h)所示的就是相对于之前较复杂的裂缝及其裂缝组,其粗细分布不均匀,走向不规则因此相对来说较难预测,从结果来看,有些较细的裂缝无法被成功预测,比如图5 (g)上侧分叉处的左端和图5 (h)左侧裂缝的下端,但是这些较细的裂缝的工程价值不大,同时也不影响后续的面积计算,因此可以忽略不计。
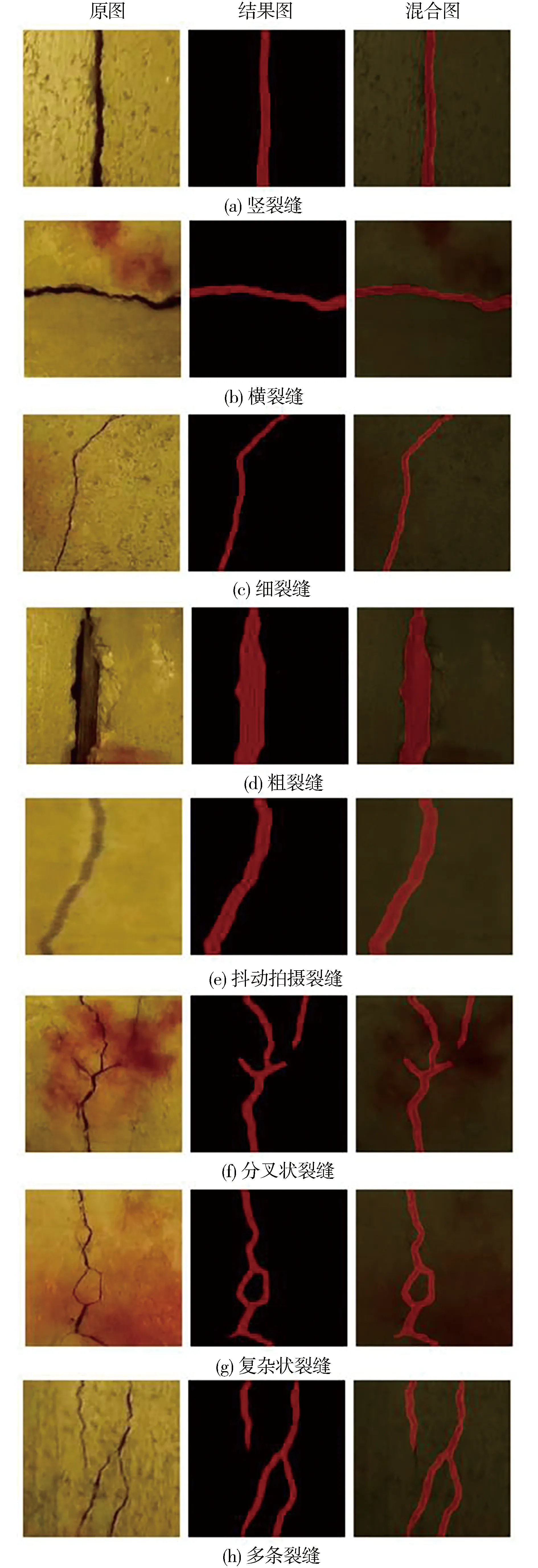
图5 不同种类的裂缝及其对应的预测图Fig.5 Different types of cracks and their corresponding prediction maps
3.4 对比结果
为了进一步验证改进后的PSP Net(即特征层划分成1×1、2×2、4×4、8×8的PSP Net,以下简称“1248 PSP Net”)的可靠性,本研究选取了其他的网络进行对比。主要包括:未改进的PSP Net(即1236 PSP Net),1234 PSP Net,Segnet[13],U-net[14-15]。
3.4.1 PSP Net网络间对比
由于其MIoU值相差不大,无法从几张图片说明1248 PSP Net的优于其他2种,因此就从损失值和MIoU值来分析。从图6(a)的损失值来看,三者的差距不大,但是表1所描述的最小损失值来看,说明其本文方法还是优于其他2种结构。从最终所收敛的MIoU值来说,本文方法的MIoU值均大于其他2种。因此不论从损失值还是MIoU值分析,1248 PSP Net的性能都略优于1236 PSP Net和1234 PSP Net。

表1 不同PSP Net第95~100回合时的最小损失值记录表Table 1 The minimum loss value record table for different PSP Net the 95th~100th epoch

图6 不同PSP Net记录图Fig.6 Different PSP Net records
3.4.2 不同网络间对比
如图7对比发现,经过改进后的PSP Net无论从实际效果来看,还是从MIoU来看,其效果都是优于Segnet。但是对比U-net 的MIoU值得发现,但是无论PSP Net经过何种改进,其预测的正确率都远低于U-net预测的正确率,但是U-net有个致命的缺陷,就是其无论是在训练时,还是使用时都需要较大的算力。在训练阶段时,U-net的批尺寸(batch size)的大小超过了4就已经显示显存不足,而PSP Net的批尺寸的大小可高达至64;在训练完成时,U-net产生了约9GB的权重文件,而PSP Net仅仅占了其1/10;在导入摄像头时,U-net的帧率从未超过10,而PSP Net的平均帧率约26,已经超过了家用电视要求的24帧。综上,U-net无法满足水下机器人在裂缝检测时的实时性的要求,因此即使U-net的精度远超于PSP Net,也无法将U-net应用于对大坝裂缝的实时性检测。

图7 不同网络结构MIoU值对比图Fig.7 Comparison of MIoU between different network structures
3.5 超参数选择结果
为了研究不同的超参数对PSP Net网络训练结果的影响,本研究分别找到了以下可以调整的参数并对其进行研究:初始学习率、学习率衰减率、总共的训练回合、冻结回合与解冻回合之比。在这些超参数中,默认值为:初始学习率lr=0.000 1,学习率衰减率γ=0.95,总共的训练回合epoch=100,冻结回合与解冻回合epoch rate=1∶1。对这些超参数的数值在合理的范围内进行适当的变化,比较不同超参数值与默认值分别对PSP Net网络训练结果的不同。
1)总训练回合。本文分别选取总训练回合epoch=50,epoch=100(默认值),epoch=200,epoch=300进行研究,得到其如图8 (a)的损失值结果。当epoch=50时,其损失值仍处于下降状态,因此当epoch=50,由于其训练回合不足,并非符合要求的训练参数;当epoch=100,200,300时,其损失值最终趋向于平衡,且都收敛于0.275。综上当epoch≥100时,其最终的效果区别不大。同时,训练100回合的时间远小于训练200、300回合的时间,因此epoch=100是总共的训练回合的较优解。

图8 不同超参数损失值记录图Fig.8 Recording chart of loss value of different hyperparameters
2)冻结回合与解冻回合之比。本文分别选取了冻结回合与解冻回合epoch rate=1∶4,epoch rate=2∶3,epoch rate=1∶1(默认值),epoch rate=3∶2,epoch rate=4∶1进行研究,计算其损失值和MIoU值,并且得到了如图8 (b)、图9(a)、表2(a)所示的结果。显然,5种比例所对应的损失值分别在超过20、40、50、60、80回合后发生明显下降,这也恰恰符合了冻结特征提取网络后的特性。当epoch rate=4∶1,epoch=100时,损失值仍处于下降状态而并未得到收敛,其原理也显而易见,解冻特征提取网络的时间太长,没有足够的回合来进行对裂缝特征的提取,以至于没有完全发挥PSP net中特征提取网络的优势,因此epoch rate=4∶1无法满足PSP net的要求;当epoch rate=1∶1,epoch rate=4∶1时,在特征提取网络解冻时的回合(分别为第20回合与40回合)所对应的损失值并未趋于收敛,因此epoch rate=1∶1,epoch rate=4∶1也不是较好地适应此类裂缝检测的问题的超参数。从最终的损失值来看,当epoch rate=1∶4,epoch rate=2∶3,epoch rate=1∶1,epoch rate=3∶2时,其损失值都收敛于约0.275。图9(a)、表2(a)说明了其MIoU的变化情况以及收敛状态,其中,当epoch rate=1∶4和2∶3的时候,MIoU均为73.67%,均大于其他几种情况,因此可以结合对损失值的分析,当epoch rate=2∶3,1∶4时可以为较优解。值得注意的是,当epoch rate=1∶4,epoch=75时,出现了此次实验的最高MIoU值——高达74%,但是经研究与分析以后,这是由于波动过大与测试集合标注共同影响造成的结果,其理由如下:①在此次情况下损失值达0.28,略大于收敛值0.275;②测得epoch=74,76时的MIoU值分别为73.5%和73.68%,与74%相差较远。可以得出当epoch rate=1∶4时存在过拟合的情况,同时特征提取网络解冻的越早所消耗的算力也会越大,因此epoch rate=2∶3比epoch rate=1∶4更适合作为PSP net的超参数。

表2 不同变量第95~100回合时的最小损失值记录表Table 2 Record table of the minimum loss value in the 95th~100th epoch of different variables
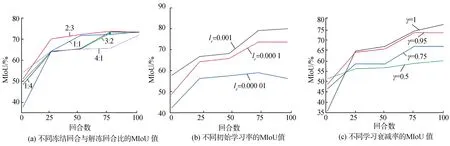
图9 不同超参数MIoU值记录图Fig.9 Records of MIoU values of different hyperparameters
3)初始学习率。本文分别选取lr=0.001,lr=0.000 1(默认值),lr=0.000 1的记录每一回合的损失值和每25回合的损失值MIoU值,得到如图8(c)、图9(b)、表2(b)结果。显然无论从损失值的数值和收敛情况来看,还是MIoU值的递增情况和最值来看,lr=0.001都是适合PSP net的超参数之一。其原因是学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但是学习率也不能过大,因为太大易受异常数据的影响,从而容易发散。
4)学习衰减率。分别选取γ=1,γ=0.95(默认值),γ=0.75,γ=0.5的记录每一回合的损失值和每25回合的损失值MIoU值,得到如图8 (d)、图9(c)、表2(c)结果。从损失值来看,学习率越低收敛的速度越快:在实验中,γ=0.5时,损失值约于54回合达到收敛;γ=0.75时,损失值约于62回合达到收敛;γ=0.95时,损失值约于77回合达到收敛;γ=1,损失值约于92回合达到收敛。但是学习率越低收敛值反之越高:在实验中,γ=0.5时,损失值约收敛于0.57;γ=0.75时,损失值约收敛于0.44;γ=0.95时,损失值约收敛于0.275;γ=1时,损失值约收敛于0.23。综上所述,在训练回合足够的基础上,学习率越大所得到的最终损失值也越小。本次水下裂缝检测的实验中,基础训练回合为100回合时,γ=1是一个相对较好的超参数选择。从MIoU值来看,也显然印证了上述的结论——在本次实验中,γ=1是一个相对较好的超参数选择。
综上,相对较合适的超参数为epoch=100,epoch rate=2∶3,lr=0.001,γ=1。找出较适合的超参数以后,再对改进后的PSP net进行训练并且进行MIoU值的计算,最终MIoU值高达80.35%,与之前相比有了质的变化。
3.6 面积计算结果
3.6.1 激光光斑检测
实验表明,光斑提取在一般的环境下均可被进行排他性提取,如图10(b)所示是对图10 (a)的灰度化处理,图10 (c)进行进一步的模糊与平滑,方便进行进一步后续的提取,经腐蚀以后得到图10 (d),此时图中的2个白点的位置就是如图10 (a)中光斑的真实位置,由图10 (e)在原图中进行标识,以便进行后续裂缝面积的计算。
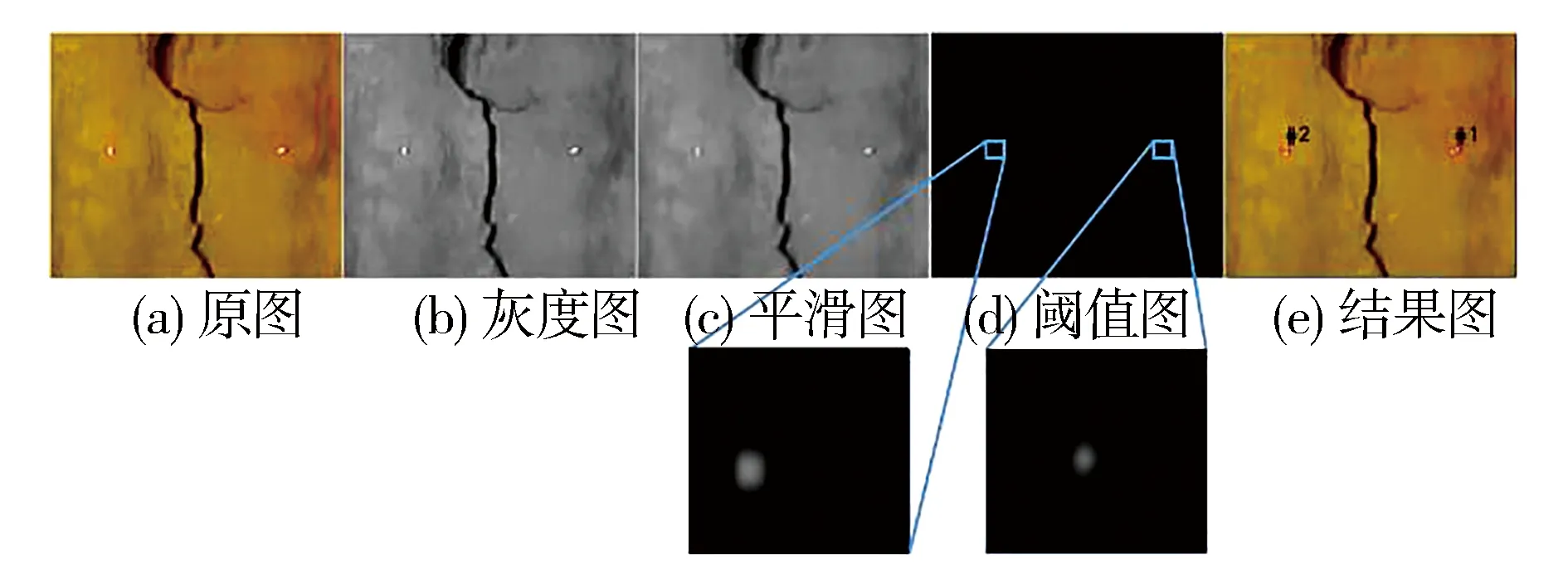
图10 一般环境下的光斑提取Fig.10 Spot extraction under general environment
在复杂的环境下进行实验,实验表明,只要调整好后合适的阈值,就可以在较为复杂的环境下对光斑进行排他性的提取。如图11(a)所示,由于坝体颜色特征的缘故,使得平滑图11(c)在经过阈值化、腐蚀以后,仍有4块区域被误认为所需要的激光光斑,再根据激光点的实际尺寸,设定合适的像素大小阈值进行逐一筛选(本例中筛选设定的为100~300个像素)。

图11 复杂环境下的光斑提取Fig.11 Spot extraction in complex environment
3.6.2 面积测量
找到识别到光斑以后再结合语义分割的结果可以按照式(6) 、(7)的距离测量方法对裂缝面积进行测量。
图12表示了不同环境下的语义分割检测与激光点检测结果。

图12 不同环境下的语义分割检测与激光点检测Fig.12 Semantic segmentation detection and laser spot detection in different environments
由于水下裂缝的无法像路面裂缝那样直接测量,因此只能使用辛普森二式对图片进行面积估算作为实际面积。抽取几张图片进行计算,并且设置d=0.3 m进行试验。
通过表3的实验数据表明,面积计算的结果的误差率能控制在可接受的范围内,因此具有较好的参考意义可用于实际的工程应用。

表3 面积计算结果记录表Table 3 Record table of area calculation results
4 结论
1)将PSP Net在金字塔池化模块方面进行了特征层尺度的改变,改进后可以更好地用于大坝的裂缝检测,相对于原PSP Net和其他改进方法的PSP Net由更高的精确性;相对于U-net拥有更好的实时性;相对于Segnet拥有更高的精确性。
2)在改进网络的同时还选取了相对较好的超参数,即总共的训练回合为100回合,冻结回合与解冻回合之比为2∶3,初始学习率为0.001,学习衰减率为1,以便能更高效率地达到理想的预测结果。
3)经过图像的预测以后,可以使用激光光斑检测算法确定比例尺,并将预测的裂缝和原图像进行一并处理与关联,进一步地提供有关数据、进行相应的工程实践,从而实现了水下机器人观察甚至作业的智能化。
猜你喜欢
诗歌月刊(2023年1期)2023-03-22
数学小灵通·3-4年级(2021年5期)2021-07-16
阅读(高年级)(2019年9期)2019-11-15
阅读与作文(小学高年级版)(2019年8期)2019-10-16
今日农业(2019年15期)2019-01-03
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
中国医疗美容(2015年1期)2015-07-12
读者·校园版(2015年19期)2015-05-14
