
基于混合上下文熵模型的点云几何编码算法
2023-05-31 03:23:10黄昕郑明魁黄施平刘文强
福州大学学报(自然科学版) 2023年3期
黄昕,郑明魁,黄施平,刘文强
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
近年来,点云编码技术受到广泛的关注.为了统一点云的编码方式,动态图像专家组(moving picture experts group,MPEG)发布了对点云压缩技术的提案征集[1](call for proposals,CFP),并随后确定基于表面点云压缩(surface-based point cloud compression,S-PCC)、基于视频点云压缩(video-vased point cloud compression,V-PCC)和激光雷达点云压缩(lidar-based point cloud compression,L-PCC)等3种测试模型[2].
点云编码技术常见的是基于树结构的方法,八叉树结构在2006年就被应用在点云编码上[3].该方法将点云不断划分为8个子立方体.利用块间的相关性构建熵模型进行算术编码.MPEG推出几何点云压缩(geometry-based point cloud compression,G-PCC)标准[4],借鉴Mekuria等[5]基于块的思想在八叉树编码的基础上做了改进.基于体素的点云几何压缩算法[6-7]使用体素来表示三维空间中的点,然后通过卷积提取全局特征,对体素直接编码,得到比八叉树编码更好的压缩效果,但对点云密度较为敏感.YAN等[8]提出一个通用的基于自动编码器的有损几何点云压缩方法.训练过程中使用点到点距离作为损失函数[9],并对解压后的损失作为目标函数进行网络优化.该方法通过池化对称函数对输入的点云坐标值进行重新的排序,通过解决点云无序性的问题来提高网络的压缩性能.基于体素结构的算法能够对空间中点云的局部特征做出很好的表达,却难以处理分布不均匀的稀疏点云;基于八叉树结构的算法虽然消除了点云结构中的大部分空白,却忽略了点之间的强依赖性.目前没有看到其他的方法能很好地结合体素和八叉树结构的优势,建立相应的熵模型做出优化.为解决此问题,本研究通过深度学习的方法对点云的数据分布进行调整并且在熵编码中对上下文信息进行修改,以达到改善编码效果的目的.
本研究提出一种新颖的点云几何编码方案,对不同结构下获得的上下文信息进行更新融合,并根据给定体素的条件分布建立熵模型获得更准确的概率预测,从而提升编码效率.同时,通过对点云数据的划分,除掉组间体素的依赖性,实现神经网络的并行化处理,以节约编解码时间.
1 基于混合上下文熵模型的点云几何编码方案
为提供更精细的点云上下文模型,本研究提出一种基于混合上下文熵模型的点云几何编码框架(见图1).主要包括混合结构化点云模块,基于不同层次划分的上下文信息提取模块、上下文融合模块、概率估计模块和最终的二进制算术编码.首先对点云进行结构划分,通过不同的网络结构提取上下文信息,使用上下文融合模块对同一尺寸体素块的上下文信息都进行更新和混合,将得到的上下文信息送入神经网络进行条件概率估计.最后,将当前编码块和概率送入二进制算术编码模块进行编码得到码流.
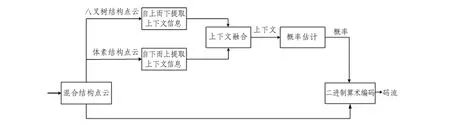
图1 点云编码方案框图Fig.1 Block diagram of point cloud coding scheme
1.1 上下文信息提取
1.1.1混合结构化点云
利用八叉树结构可将一个点云在2n×2n×2n的网格上划分成一个n个层级,在结构化的过程中首先使用八叉树结构将点云划分到n~6层级,之后使用大小为26×26×26的非空二进制块来体素化点云.即混合结构化点云由一个n~6级的八叉树和一些尺寸为64(d=64)的非空二进制块体素组成.其中位于体素域的点云将其送入后面编码模块中进行编码,而高级八叉树,以及每一个块的深度,都变转换为字节,被作为边信息发送给解码器.
1.1.2自上而下的上下文信息提取
上下文信息包括当前节点在父节点中的索引、节点的空间位置、父节点的子节点占用情况等.当算术编码器用来编码块中每一个节点时,上下文信息都会被反馈回神经网络中生成概率,预测下一个节点的占用情况.尺寸较大的块因其稀疏性返回较少的上下文信息.本方法在自上而下的上下文信息提取过程中,若子块的总码流小于父块的码流大小,则进一步分区尺寸更小的块.本文设置八叉树划分到立方体的尺寸为 8 时,停止划分,同时为每一个尺寸大小为8的立方体块中的节点提取一个独立的上下文嵌入xi,然后将块所对应的的父节点信息ci执行渐进聚合,输入的上下文信息包括节点的位置信息、级别和父节点的占用信息.以上下文特征ci为输入,通过多层感知器(multilayer perceptron,MLP)[10]为每一个节点提取一个独立的深度特征,即

(1)
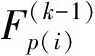
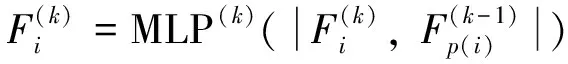
(2)
1.1.3自下而上的上下文信息提取
由于在体素化结构中没有分层概念,无法考虑到来自父节点的上下文信息.所以在自下而上的上下文信息提取模块中,需把局部体素信息Vi用作强先验信息.同时,为了得到当前体素的高阶上下文,将体素结构的上下文与对应八叉树结构的上下文信息结合起来;然后对得到的尺寸为M=64大小的块通过最大池化操作[11]进行下采样,并从尺寸最小的块开始送入残差网络当中提取上下文信息.在自下而上的上下文信息提取过程中,尺寸大的块将从小尺寸块的上下文中获取信息.小尺寸的块由大尺寸的块通过最大池化操作获得.在预测过程中,首先从低分辨率中预测出第一块尺寸为8的体素块,接着第二块将从第一块以相同的尺寸预测得来,在后面的过程中前面所有已编码的块则都可以用来预测生成下一个块,直到最终生成尺寸大小为64的块.
1.2 上下文融合
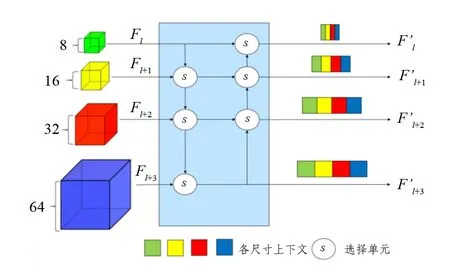
图2 上下文融合网络Fig.2 Context fusion network
在自上而下的上下文信息提取中,更多地注意到点云的局部上层信息,而在自下而上的上下文信息提取中,则是更多考虑到同一层级的全局特征.为了使当前编码块使用更丰富的上下文,在使用两种方式提取多尺度上下文信息后,将对其上下文进行融合.这表示每一尺寸的块的上下文信息是被更新和混合的,能够使用到双向的上下文信息,包括自上向下的来自父节点的信息和自下向上的子节点的信息.图2中显示了融合上下文的框架结构.
将不同尺寸的体素块的上下文信息和其对应层级的八叉树节点的上下文信息一同输入到上下文融合网络中,使用选择单元S对各尺寸的上下文进行处理[12].在选择之前,每一层的特征只包括自己的信息,通过选择单元后,每一层的特征不仅包含了自己的信息还包含了相邻更高一层级的信息.通过这样的双向融合,可以得到了一个特征金字塔.在这个金字塔中,多尺度的上下文信息被充分的混合在一起.
图3中显示了选择单元内部具体操作.设Fl和Fl+1分别代表低尺寸的上下文信息和高尺寸的上下文信息.首先,使用C(·)函数将其连接起来,得到Fc,即
Fc=C(Fl,Fl+1)
(3)

图3 选择单元S的结构示意图Fig.3 Select the structure diagram of unit S
其次,通过平均池化M(·)将Fc压缩到Zc中,用于描述全局特征,即
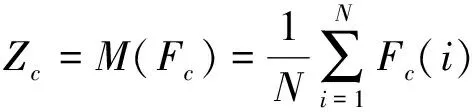
(4)
其中:N代表的是体素.然后使用两层瓶颈结构的多层感知机将Zc转换成注意r,即
r=MLP(Zc)=σ(W2δ(W1Zc))
(5)
式中:σ为Sigmoid函数;δ为ReLU函数;W1∈RC×(C/t),W2∈R(C/t)×C,t为调整模型复杂度的参数.最后,利用所生成的r对输入Fc进行选择,并由1×1的卷积层进行混合.在选择过后,使用残差策略,以防止过度进行特征选择,即

(6)
1.3 基于神经网络概率估计
本方案使用基于上下文的自适应算术编码[22]对体素化的点云进行无损编码.具体来说,估计的是体素块占用情况的概率模型P(V).假设体素块的概率分布是体素的联合概率分布p(v1,v2,…,vn),由于高维很难建模,一个体素的值仅取决于它之前的体素的值,联合概率近似为条件概率的乘积.将块联合概率p(v)分解成一系列体素的条件概率的乘积,即
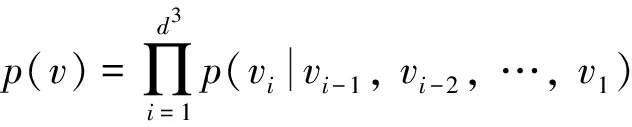
(7)
每一项p(vi|vi-1,vi-2,…,v1)是当前体素编码之前所有体素被占用的概率,即当前体素编码的要用到的上下文信息.
通过使用一个自回归神经网络[13]估计p(vi|vi-1,vi-2,…,v1),并将其称为基于混合结构上下文的神经网络(hybrid voxel context and octree context neural network,HVOCNN).为更好地学习已编码体素的概率占用分布,使用交叉熵损失函数[15]来训练神经网络.图4中显示用于估计概率的HVOCNN网络结构.由于条件概率分布依赖于先前解码的体素,可以利用三维卷积掩膜[14]来确保网络在预测输出体素vi时不会看到输入体素.其中,从中心开始权重为0是A型掩膜,而将卷积核的中心设置为1则是B型掩膜.给定d×d×d输入块的融合上下文,神经网络输出所有输入体素的预测占用概率.在输入层,即第一个三维卷积层使用了带有A型掩膜的7×7×7的卷积核,B型掩膜则在后面的层中使用.在输入层使用A型掩膜卷积来限制未编码体素信息和当前体素信息对预测编码的影响,而在之后用B型掩膜卷积,则允许了当前编码体素到自身的连接,放松了掩膜A的限制.在网络中,为了避免梯度消失和加快收敛速度,使用带有5×5×5卷积核的两个三维卷积层实现残差连接,并且除了在最后一层使用softmax激活函数外,其他的卷积层其后都跟随ReLU激活函数.
1.4 体素并行多尺度自回归概率估计
HVOCNN网络的算法瓶颈在于每一个新的体素都需要应用网络进行编解码.从二维图像并行生成工作[16]中获得启发,通过并行计算多个上下文部分并行化该过程,将计算时间除于一个常数因子,这样的并行网络称为并行混合结构上下文的神经网络(parallel hybrid voxel context and octree context neural network,PHVOCNN).本方法并行预测多个体素块以达到减少网络复杂度和计算时间的目的,而这需要放松体素块之间的空间依赖关系.首先将体素分为T组,并使用vt来表示T组中的所有体素,t=1,2,…,T.将联合概率p(v)分解近似为T的条件概率分布,即
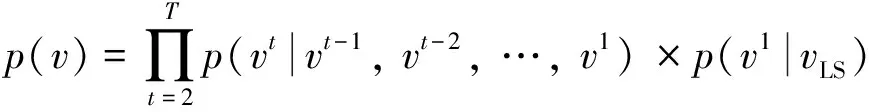
(8)
式中:p(vt|vt-1,vt-2,…,v1)表示当前编码组之前的所有组中已占用体素的联合概率;vLS表示较低尺寸的条件独立体素.
此方法在去除掉组间体素依赖性的基础上,可以同时预测组中的所有体素.此外,除了给定的第一组,所有其他组都可以进行自回归预测而得到.如图5所示,2×2块的角构成了给定比例的4个体素组,箭头表示相邻的依赖关系,已占用的体素组都可以用来预测当前组的体素且块间的体素组仍然是有依赖的,这些附加依赖能帮助处理捕捉局部纹理和组间边界.因为每组中的体素值是互相独立的,所以可以并行计算并且前一组的体素值可用于生成后面的体素值.

图5 4×4的二维体素体素分组Fig.5 Two dimensional voxel grouping of 4×4
2 实验仿真与结果分析
2.1 实验数据和实验环境
所用的试验数据来自ModelNet数据集[17]和Microsoft[18],MPEG CAT[19]和 MPEG 8i[20]3个较小的数据集.其中ModelNet数据集包括40个不同的类别,需要首先对其进行处理,每个数据从网格表面统一采样,然后体素化点云到 9位精度.而其他数据集同样选取10位精度的数据,并且为了大小数据的公平性,选择在小数据集中选取用于测试的点云,数据集示例如图6所示.

图6 数据集示例Fig.6 Dataset example
所有实验都是在Ubuntu 16.04系统,CPU配置为Intel Xeon E5 1620v4@ 3.5 GHz,GPU配置为NVIDIA GeForce GTX 1080 Ti ,CUDA版本10.0的设备上完成的.在并行分组估计体素概率的情况下,将输入的点云,分成8组,每组有3个不同的缩放尺寸,一共24个模型对应处理不同体素组输入不同尺寸的体素块.实验使用 Adam优化器[21]对模型进行优化,学习速率为10-5,迭代20次.
2.2 实验结果与分析
本节评估基于混合上下文模型的方法与其并行方法在MPEG和Microsoft数据集上稠密点云的性能.实验根据每个被占用体素的编码平均比数和编码所花费的时间来评估网络的编码性能,平均比特数通过输出文件总比特数除以被占用的体素数计算得出.实验比较了本文算法及其并行算法和G-PCC的平均比特率,见表1.表2为HVOCNN与PHVOCNN相对于G-PCC的比特率提高百分比的对比.
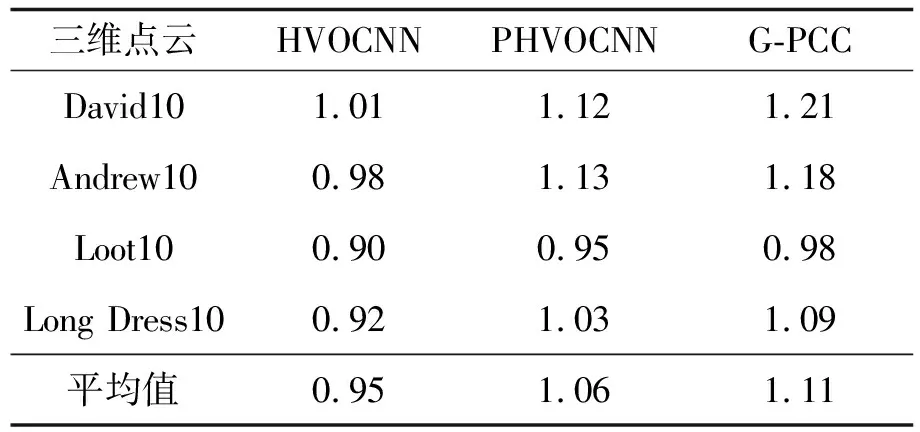
表1 平均比特率对比
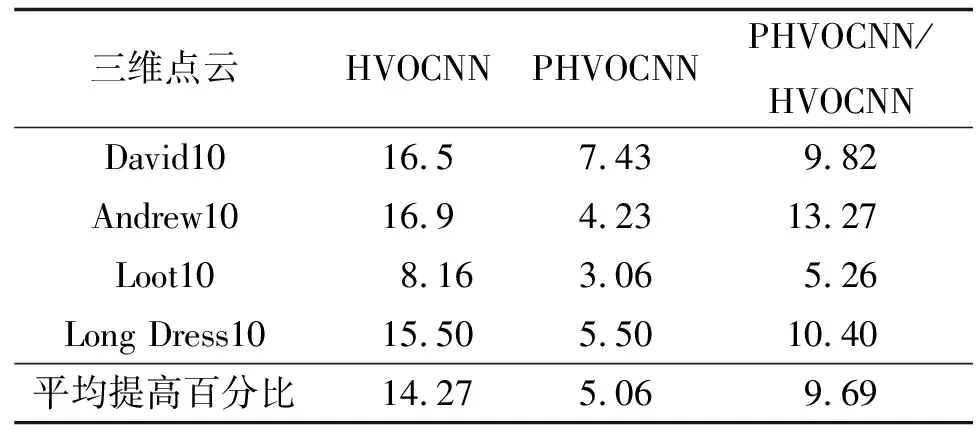
表2 平均比特率增益对比
从表1可看出HVOCNN、PHVOCNN和G-PCC编码标准在不同测试数据下的平均比特率,可以观察到HVOCNN在所有的测试点云上都优于G-PCC,每个体素所占的比特位都明显小于G-PCC.从表2可看出,HVOCNN方法相比于G-PCC的比特率提高百分比最高可以达到16.9%,平均比特率则是提高了14.27%.
而与HVOCNN网络相比,并行网络 PHVOCNN 比G-PCC的压缩效果则没有那么明显,其中最高比特率提高了7.43%,平均比特率则提高了5.06%,这是因为并行的算法打破了体素之间的一些依赖关系,并行建模估计体素概率导致的.在所有的实验中,高级八叉树都是直接转换为字节而并不进行任何压缩,这一部分的数据只占不到1%的码流.

表3 不同测试数据下的编码时间
实验通过测试本研究方法在不同测试数据集下的编解码时间来比较不同方法的复杂度,如表3所示.虽然都慢于G-PCC,但数据通过并行化后的网络编码时间比通过基于HVOCNN网络的时间要快的多,在Microsoft数据集上,编码时间快58倍,在MPEG数据集上,则加快了53倍的速度.这是因为并行估计编码概率的方法降低了上下文的建模难度,而是分成多组并同时进行,虽然压缩效果降低,却大大加速了编解码时间,并且理论上该并行算法可以泛化到其他基于体素的编码器上,从而使算法适用于不同需求的场景.以上结果表明,在体素上下文中结合八叉树上下文将有助于模型为当前体素建立更加准确的上下文模型,从而提供更准确的概率估计,达到降低比特率的效果.
3 结语
本研究提出了一种基于体素结构和八叉树结构的上下文信息融合神经网络点云压缩框架.为了对当前节点建立更精细的上下文模型,利用选择单元对上下文信息进行双向的融合,在概率估计中使用掩膜卷积,以此来避免未编码节点和当前节点的信息对预测的干扰.提出了并行多尺度自回归估计概率的方法,通过对三维点云体素化结构进行分组,缩短了编解码时间,使得算法可以适应不同环境的要求.本文方法明显优于目前主流的G-PCC 算法,然而使用不同的网络提取上下文耗费了过多的资源和功耗,难以满足实际的场景需求.本研究下一目标是使用一个网络对数据进行数据特征的提取,并且减少参数的需求,加快编码时间.
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05 11:40:44
导航定位学报(2022年5期)2022-10-13 08:35:28
中国体视学与图像分析(2021年3期)2021-11-24 02:20:44
计算机集成制造系统(2020年4期)2020-05-08 02:41:16
中国惯性技术学报(2019年1期)2019-05-21 00:58:46
制造技术与机床(2017年10期)2017-11-28 05:20:18
计算机应用与软件(2017年8期)2017-08-12 12:22:06
信息安全与通信保密(2016年2期)2016-09-08 10:32:03
科技资讯(2016年21期)2016-05-30 18:49:07
郑州大学学报(工学版)(2013年1期)2013-09-13 07:57:54
