
基于CA-BIFPN的交通标志检测模型
2023-05-31 00:51郎斌柯吕斌吴建清吴瑞年
深圳大学学报(理工版) 2023年3期
郎斌柯,吕斌,吴建清,吴瑞年
1)兰州交通大学交通运输学院,甘肃 兰州 730070;2)山东大学齐鲁交通学院,山东 济南 250002;3)兰州市大数据管理局,甘肃 兰州 730070
交通标志是用汉字或符号传达导向、控制、警戒或指挥等信号的道路设施,能够熟练解读标志含义是每个驾驶员的基本要求,对于自动驾驶也是如此.交通标志检测是自动驾驶及辅助驾驶系统的重要研究方向,正确识别道路交通标志关系着智能驾驶任务的成败.
交通标志检测优化模型包括基于人力的交通标志检测优化模型和基于深度神经网络的交通标志检测优化模型[1-2].基于深度神经网络的交通标志检测优化模型包括1 阶段目标检测模型和2 阶段目标检测模型.2阶段目标检测模型需从图片中产生候选区(运行后续模型的子区域),再从候选区域中生成最终的物体检测边框[3].与2 阶段目标检测模型相比,1阶段目标检测模型直接得到目标物体的分类概率和方位坐标值,并通过此环节直接获得最后的检测结果.1 阶段目标检测模型包括SSD(single shot multibox detector)[8]与YOLO(you only look once)[9-11]系列等.
2 阶段目标检测模型的精度一般高于1 阶段检测模型,但2 阶段目标检测模型的计算速率较慢,无法满足实际应用中实时性的需要.1阶段目标检测模型同时确保了精度和处理速度,因而其应用范围更广泛[12].但是由于交通标志目标通常为小目标(物体相对图像占比小于0.58%[13])物体,所以,上述检模型的精度均不能满足实际需求.
注意力机制可以根据图像中不同位置的重要程度提取图像信息,从而使神经网络专注于图像中更重要的部分[14].因此,在检测模型中引入注意力机制有助于提高模型对于小目标物体的检测精度.基于此,考虑检测实时性和精度的要求,本研究选择YOLOv5(you only look once version 5)为基础检测模型,并以此为骨干网络,在骨干网络中添加协调注意力(coordinate attention,CA)机制,聚焦于小目标交通标志检测.同时在模型特征融合部分引入加权双向特征金字塔网络,增强不同尺度特征图融合效果,进一步提升模型检测精度.
1 CA-BIFPN交通标志检测模型
在保证实时检测精度的前提下,为提高YOLOv5 网络模型对交通标志的识别精度,本研究提出基于协调注意力-双向特征金字塔网络(coordinate attention - bidirectional feature pyramid network,CA-BIFPN)的交通标志检测模型,其网络结构如图1.可见,基于CA-BIFPN的检测模型网络结构主要由输入、骨干网络、Neck 特征融合网络及预测网络构成.其中,CBS(convolution,batch normalization,SiLU)为卷积-批标准化-SiLU 激活函数组合模块;CSP(cross stage partial)为跨阶段分区网络,分为CSP1-x和CSP2-y,x和y分别为残差模块数量和CBS 数量;SPPF(spatial pyramid pooling - fast)为快速空间金字塔池化.采用YOLOv5 6.0 版本神经网络为基础网络,在其骨干网络中加入CA 机制,实现在添加少量训练参数的同时增加网络特征提取能力.相关注意力对比实验[15]表明,虽然通道注意力能够显著提高模型性能,但其容易忽视与空间选择性注意力产生密切相关的位置信息,在CA 机制中将位置信息放入通道注意力中,则能够较好规避这个问题.YOLOv5 与注意机制的结合方式为[16]:①将注意力机制与Neck 特征网络融合,替换骨干网络中所有跨阶段局部网络(cross stage partial networks,CSPN)模块;② 在骨干网络后单独加入注意力机制.本研究采用后种方法,即将CA 机制加入至空间金字塔前,随后导入Neck 特征融合网络,在特征融合网络中混合不一样的特征图.选用加权双向特征金字塔网络,可以将交通标志图像的各个特征合理融合,有效解决各尺度特征信息不一致以及其他特征金字塔计算量大的问题.以下分别说明检测模型各优化模块的组成.

图1 CA-BIFPN模型网络结构Fig.1 (Color online) Network structure of CA-BIFPN model.
1.1 CA-BIFPN注意力机制
注意力机制的本质是寻找特定的数据信号,操纵无用信息,结果一般以几率图和概率特征空间向量的形式表达,有利于增强神经网络对于小目标物体的检测精度.注意力机制模型可分为空间注意力、通道注意力及混合注意力模型[17].
空间注意力模型偏向全部通道,在二维平面图中训练尺寸为H×W的特征图权重值矩阵,并为全部图像单元获得1个权重值.该权重表示某个空间位置信息的重要程度,将空间注意力矩阵附着到原始特征图像上,以增加可用特征,减少无效特征,进而达到特征筛选与增强的目的.
与空间注意力不同,通道注意力类似于在各个通道的特征图中都给出1个权重值,表明方式和重要信息之间的关联性,该权重值与相关性呈正相关关系[18].在深度神经网络中,层面越高,特征度的尺寸越小,但通道数量更多.通道还体现全部图形的特点信息,信息过多时神经元网络难以挑选出有效信息,此时利用通道注意力就可以使网络判断出最重要信息,这也是利用通道注意力进行目标检测时效果更优的原因[19].CA 机制为混合注意力,其包含了通道注意力和空间注意力,也继承了二者的优点,使CA 在获得跨通道信息的同时,获得方向感知和位置感知信息,因此,检测模型可以对目标进行更为精准地定位与识别.CA 机制模型如图2.其中,C为通道数;r为缩减因子.CA 应用精确的部位信息对通道关联信息和长期性依靠信息展开编码,编码过程包括坐标(coordinate)信息嵌入和CA生成[20].

图2 CA机制示意Fig.2 Schematic diagram of CA mechanism.
在坐标信息嵌入过程中,全局池化方法通常用作对空间内容的整体编码,但由于该方式将去全局空间信息内容压缩在通道描述中,无法表达信息的位置内容.为使控制模块可以更好捕获具备精确部位信息的远程空间交互,利用式(1)计算全局池划分,并将其变换为一维特征编码.
其中,zc是变量通道c的输出;特征图的高度和宽度分别为H和W;通道c的坐标值为xc(i,j).使用长和宽为(H,1)和(1,W)的池化核在水平和竖直坐标方位对每个通道进行编码,相对高度为h的输出zhc(h)可表述为
与通道注意力中转化成单独特征空间向量的控制模块方式不同,式(1)和式(2)的转换方式各自在2 个空间上开展特征融合,获得1 对空间方位上感知的特征图.这两种转换方式能够使实体模型捕获与另一个空间方位的相互联系,并维持从另一个空间方位的精准位置信息,进而根据网络寻找合适的总体目标[21-22],可以取得比全局编码更准确的信息.
将式(1)和式(2)两种输出结果应用到另一种转换,完成CA 生成.CA 设计准则包括:① 新的转化全过程应尽量简单;② 注意力机制应能灵活运用捕获的信息,使感兴趣的区域信息能够被精确捕捉;③ 设计还需合理捕捉信息通道间的关联.特征信息转换完成后进行Concatenate函数变换,随后根据1 × 1卷积神经网络变换F1函数进行变换,为
其中,F1为卷积变换函数;[,]为Concatenate 函数变换;σ为空间信息在水平和竖直方位编码的中间特征投射,可用来操纵CA的控制模块尺寸减缩率.
1.2 CA-BIFPN的特征金字塔网络
通常尺度较大的特征图更适于检测小目标物体,尺度较小的特征图更适于检测大目标物体,而将两者结合的特征金字塔则能更好兼具大小目标的检测.最早的特征金字塔网络(feature pyramid network,FPN)[23]是一个自上而下的单项特征融合金字塔结构,如图3.运算过程中,FPN的p6—p3输出层先将上一次特征图像的上采样结果进行特征融合,再经过与p7相同的运算流程,最终形成5个不同尺寸的特征图像,供后续网络检测.

图3 FPN结构示意Fig.3 (Color online) FPN structure.
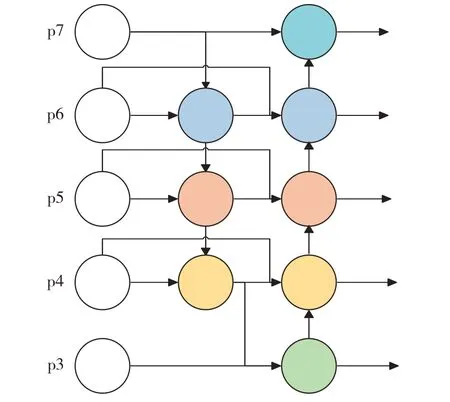
图4 BIFPN结构示意Fig.4 (Color online) BIFPN structure.
FPN可通过由顶向下的传递路径来获得语义更加丰富的特征,并将特征与更准确的位置信息结合.但针对由大目标产生的掩码,空间信息可能要传递数百层,导致传递路径过于冗长,使网络高层信息与低层信息无法有效结合,出现信息丢失.
路径聚合网络(path aggregation network,PANet)是一种改进的FPN,该网络通过使用由底层至顶层的横向连线来缩短传输路径,引入另一种由底向上的传输途径[24].PANet相对于FPN具有更好的网络精度,但其网络规模较大、参数量多,计算效率较低.TAN 等[25]提出的双向特征金字塔网络(bidirectional feature pyramid network,BIFPN)引入了跳跃连接,即在相同尺度的输入节点到输出节点中间再增加1个跳跃连接,因为运算处于相同层,该方法可在参数较少的情况下结合更多特征.BIFPN将每1 条双向路径视作1 个特征网络层,并对同一层参数进行多次计算,以实现更多的特征融合.
由于不同输入特征具有不同分辨率,因此,特征对于网络的影响也不同.针对无界融合、Softmax基础融合以及快速归一化融合方法的比较结果表明,无界融合训练不稳定,需要使用权重归一化进行约束;Softmax 基础融合能表示出每个输入的重要程度,但会导致计算量增加;快速归一化融合与Softmax 基础融合类似,但没有将Softmax 函数应用到参数中,因此,其运算准确度与Softmax 基础融合类似,而计算速度较Softmax 基础融合更快[25].本研究选择快速归一化融合方法作为BIFPN的融合算法.
2 实验和结果
2.1 实验数据集
本研究采用由腾讯公司与清华大学联合制定的数据集TT100K,该数据集包含9 176幅道路与交通标志牌图片.其中,6 105幅为训练集;3 071幅为测试集.每幅图片都包括道路交通标志的一些案例,其中,训练集包括16 527个案例;测试集包括8 190 个案例.涉及的道路交通标志牌类型有221种.由于TT100K 中221 种交通标志分布不均衡,部分交通标志如山体滑坡等相对罕见,为提高训练效果,本研究将所有数据进行清洗,去除无标签和出现频次较少的交通标志种类,筛选出7 972 幅超过100幅图像的45种交通标志.对清洗图像采用随机旋转和拓展数据,包含放缩和增加高斯噪声[26],处理后的最终数据集共包括23 916 幅图像,其中,训练集15 873幅;测试集8 043幅.
为测试模型在有雾环境下的检测效果,对最终数据集随机使用红绿蓝(red green blue,RGB)通道合成雾、中心点合成雾及随机合成雾3种算法进行图像加雾处理,制成雾天数据集进行辅助实验.
2.2 实验环境和评价指标
本实验操作系统为Windows10,训练使用的显卡为NVIDIA RTX2070,显存为8 Gbyte,深度学习框 架 为Python 3.7、TensorFlow 2.0 和Pytorch 1.8.1.为保证对比结果的客观性,实验对不同网络进行测试时应用相同的超参数,如表1.

表1 超参数设置Table 1 Hyperparameter setting
采用平均精度均值mAP(mean average precision)作为模型评价指标.mAP 通过统计模型成功检测数量与目标总数比值来评价模型优劣,mAP值越高,表明目标检测模型在给定数据集上的检测效果越好.通过选择不同的交并比(预测框与真实框重叠面积与总面积之比)阈值来统计不同标准下模型的精度均值,常用的有mAP 0.50(交并比阈值为0.50)和mAP 0.50∶0.95(交并比阈值从0.50 到0.95,步长为0.05).mAP的计算过程为
其中,PrecesionCn表示图像n中,模型对于类别为C的目标检测准确度;N(TruePositives)Cn为图像n中,类别为C正确检测的目标数量;N(TotalObjects)Cn为图像n中,类别为C的目标数量;APC为模型对类别为C的平均检测准确度;N(TotalImages)C表示存在类别为C的目标的图像数量,如总共20 幅图像中,有10 幅图像有类别为C的目标,则N(TotalImages)C= 10;N(Classes)为类别数量.
2.3 实验结果分析
分别使用SSD、YOLOv5、YOLOv5+CA 模块、YOLOv5+BIFPN 模块及CA-BIFPN 模型的mAP 作为实验评价指标值,进行检测模型性能对比,结果见表2.可见,在相同参数训练条件下,分别加入CA和BIFPN 模块的YOLOv5 模型的mAP 0.50 上升0.5%和0.3%;CA-BIFPN 模型的mAP 0.50 相比SSD和YOLOv5分别提升4.5%和1.3%.CA-BIFPN模型的mAP 0.50∶0.95 与SSD 和YOLOv5 相比分别提升4.1%和1.2%.在模拟雾天环境下,CA-BIFPN模型精度为80.5%,高于原模型的80.3%,CABIFPN 的mAP 0.50∶0.95 与 原 模 型 相 比 提 升 了0.6%.
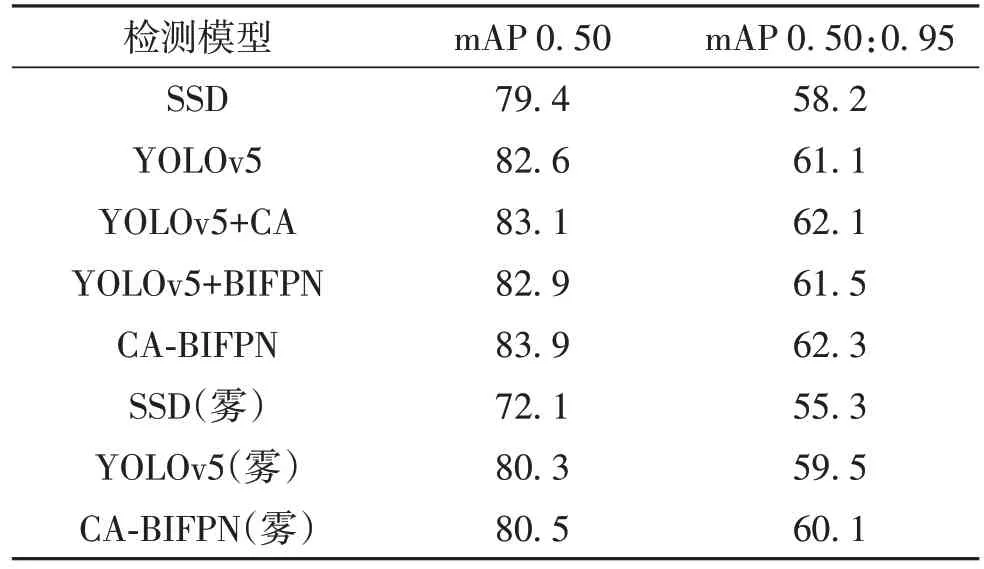
表2 检测模型性能结果Table 2 Model performance results %
在YOLOv5 模型中引入BIFPN 模块并加入注意力机制后,研究模型对数据集中小目标物体的检测精准度,从45类交通标志中分别选取mAP 0.50最高和最低的2 类进行对比,结果见表3.由表3 可见,与YOLOv5 相比,CA-BIFPN 模型的各类小目标交通标志精准度均有所提高,表3 中4 种交通标志的mAP 0.50 分别提高2.2%、2.5%、0.3%及0.5%.
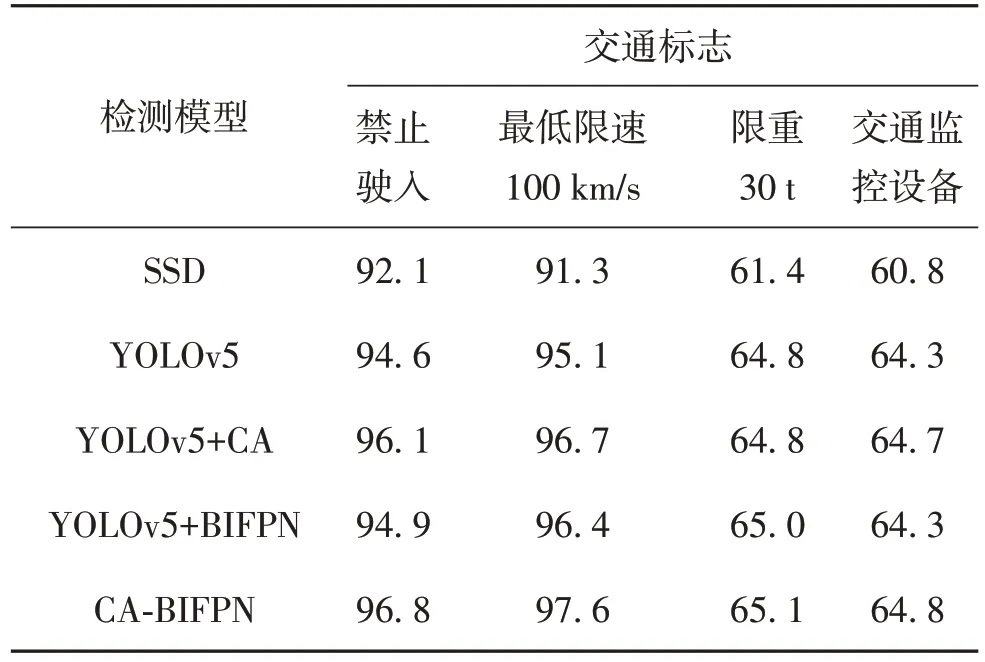
表3 TT100K中mAP 0.50最高和最低的4类交通标志Table 3 Value of mAP 0.50 for the highest and lowest 4 types of traffic signs in TT100K %
为进一步验证CA-BIFPN 模型的可靠性,从某市和某高速公路随机选取5幅交通标志图像进行检测,结果如图5,图中检测框上侧的字母和数字分别表示目标分类类型和概率.其中,图5(a)和(b)分别为CA-BIFPN 模型城市道路中远、近目标检测结果;图5(c)、(e)及(g)为CA-BIFPN、YOLOv5及SSD 模型高架道路中多目标远距离检测结果;图5(d)、(f)及(h)为CA-BIFPN、YOLOv5 及SSD 模型高速公路中多目标近距离检测结果;图5(i)、(j)及(k)为CA-BIFPN、YOLOv5 及SSD 模型雾天交通标志检测检测结果.图5(a)和(b)表明,交通标志位于较远处时仍能被正确检测出;图5(d)、(f)及(h)表明,SSD 模型发生了1 处误检,CA-BIFPN 与YOLOv5 模型在近距离检测中无较大差距;图5(c)、(e)和(g)表明,仅CA-BIFPN 模型实现了对小目标的检测,YOLOv5 和SSD 均出现不同程度漏检;图5(i)、(j)和(k)表明,本模型在部分雾天环境下也能实现对交通标志的有效检测.

图5 不同道路环境下CA-BIFPN、YOLOv5及SSD模型的交通标志检测结果 (a)CA-BIFPN模型城市交通标志远距离检测;(b)CA-BIFPN模型城市交通标志近距离检测;(c)CA-BIFPN模型高架交通标志远距离多目标检测;(d)CA-BIFPN模型高架交通标志近距离多目标检测;(e)YOLOv5模型高架交通标志远距离多目标检测;(f)YOLOv5模型高架交通标志近距离多目标检测;(g)SSD模型高架交通标志远距离多目标检测;(h)SSD模型高架交通标志近距离多目标检测;(i)CA-BIFPN模型雾天交通标志检测;(j)YOLOv5模型雾天交通标志检测;(k)SSD模型雾天交通标志检测Fig.5 (Color online) CA-BIFPN, YOLOv5 and SSD traffic sign detection results in different road environments.(a) CA-BIFPN long-range detection of urban traffic signs, (b) CA-BIFPN proximity detection of urban traffic signs, (c) CA-BIFPN long-range multi-target detection of traffic signs on elevated roads, (d) CA-BIFPN proximity multi-target detection of traffic signs on elevated roads,(e) YOLOv5 long-range multi-target detection of traffic signs on elevated roads, (f) YOLOv5 proximity multi-target detection of traffic signs on elevated roads, (g) SSD long-range multi-target detection of traffic signs on elevated roads, (h) SSD proximity multi-target detection of traffic signs on elevated roads, (i) CA-BIFPN detection of traffic signs in foggy, (j) YOLOv5 detection of traffic signs in foggy, and (k) SSD detection of traffic signs in foggy.
结 语
交通标志检测对于智能交通的意义重大,本研究提出CA-BIFPN 交通标志检测模型,以YOLOv5为骨干网络,引入CA 机制聚焦小目标物体,在Neck 网络中使用BIFPN 加权双向特征金字塔,进一步提高了网络融合效果.基于TT100K 数据集,将本模型与SSD 和YOLOv5 等经典目标检测模型进行比较检测实验,结果显示本模型的平均检测精度mAP 0.50 和mAP 0.50∶0.95 分 别 为83.9% 和62.3%,相比YOLOv5 网络提高了1.3%和1.2%,在交通标志检测中更可靠,在除极端雨雪气候及光照变化影响外的场景中均有较好的检测效果.本模型虽然提高了交通标志检测精度,但CA 机制的引用以及BIFPN增加了模型的训练参数,降低了模型的运行速率,同时本模型缺少对于极端天气情况下的特殊检测优化,因此,后续研究中仍需要针对以上问题进一步改进,以提高模型检测效率.
参考文献 / References:
[1]李铭兴,徐成,李学伟.交通标志识别研究综述[C]//中国计算机用户协会网络应用分会第二十五届网络新技术与应用年会论文集.北京:中国计算机用户协会网络应用分会,2021:196-199.LI Mingxing, XU Cheng, LI Xuewei.Summary of research on traffic sign recognition in urban traffic scenes [C]// Proceedings of the 25th Annual Conference on New Network Technologies and Applications, Network Application Branch of China Computer Users Association.Beijing:Network Application Branch of China Computer Users Association, 2021: 196-199.(in Chinese)
[2]陈飞,刘云鹏,李思远.复杂环境下的交通标志检测与识别方法综述[J].计算机工程与应用,2021,57(16):65-73.CHEN Fei, LIU Yunpeng, LI Siyuan.Survey of traffic sign detection and recognition methods in complex environment [J].Computer Engineering and Applications,2021, 57(16): 65-73.(in Chinese)
[3]杨晓玲,江伟欣,袁浩然.基于yolov5的交通标志识别检测[J].信息技术与信息化,2021(4):28-30.YANG Xiaoling, JIANG Weixin, YUAN Haoran.Recognition and detection of traffic signs based on yolov5 [J].Information Technology and Informatization, 2021 (4): 28-30.(in Chinese)
[4]GIRSHICK R, DONAHUE J, DARRELL T, et al.Rich feature hierarchies for accurate object detection and semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, USA:IEEE, 2014: 580-587.
[5]GIRSHICK R.Fast R-CNN [C]// IEEE International Conference on Computer Vision (ICCV).Piscataway, USA:IEEE, 2015: 1440-1448.
[6]REN Shaoqing, HE Kaiming, GIRSHICK R, et al.Faster R-CNN: towards real-time object detection with region proposal networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[7]CAI Zhaowei, VASCONCELOS N.Cascade R-CNN:delving into high quality object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway, USA: IEEE, 2018: 6154-6162.
[8]LIU Wei, ANGUELOV D, ERHAN D, et al.SSD: single shot MultiBox detector [C]//The 14th European Conference Computer Vision - ECCV 2016.Amsterdam: Springer,2016: 21-37.
[9]REDMON J, DIVVALA S, GIRSHICK R, et al.You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, USA: IEEE, 2016: 779-788.
[10]REDMON J, FARHADI A.YOLO9000: better, faster,stronger [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway, USA: IEEE,2017: 6517-6525.
[11]REDMON J, FARHADI A.YOLOv3: an incremental improvement [EB/OL].(2018-04-08) [2022-05-10].https://doi.org/10.48550/arxiv.1804.02767.
[12]寇大磊,权冀川,张仲伟.基于深度学习的目标检测框架进展研究[J].计算机工程与应用,2019,55(11):25-34.KOU Dalei, QUAN Jichuan, ZHANG Zhongwei.Research on progress of object detection framework based on deep learning [J].Computer Engineering and Applications,2019, 55(11): 25-34.(in Chinese)
[13]CHEN Chenyi, LIU Mingyu, TUZEL O, et al.R-CNN for small object detection [C]// Asian Conference on Computer Vision - ACCV 2016.Taipei, China: Springer, 2017:214-230.
[14]张宸嘉,朱磊,俞璐.卷积神经网络中的注意力机制综述[J].计算机工程与应用,2021,57(20):64-72.ZHANG Chenjia, ZHU Lei, YU Lu.A review of attention mechanisms in convolutional neural networks [J].Computer Engineering and Applications, 2021, 57(20): 64-72.(in Chinese)
[15]鞠默然,罗江宁,王仲博,等.融合注意力机制的多尺度目标检测算法[J].光学学报,2020,40(13):126-134.JU Moran, LUO Jiangning, WANG Zhongbo, et al.Multiscale target detection algorithm based on attention mechanism [J].Acta Optica Sinica, 2020, 40(13): 126-134.(in Chinese)
[16]徐诚极,王晓峰,杨亚东.Attention-YOLO:引入注意力机制的YOLO 检测算法[J].计算机工程与应用,2019,55(6):13-23.XU Chengji, WANG Xiaofeng, YANG Yadong.Attention-YOLO: YOLO detection algorithm that introduces attention mechanism [J].Computer Engineering and Applications, 2019, 55(6): 13-23.(in Chinese)
[17]任欢,王旭光.注意力机制综述[J].计算机应用,2021,41(增刊1):1-6.REN Huan, WANG Xuguang.Review of attention mechanism [J].Journal of Computer Applications, 2021, 41(Suppl.1): 1-6.(in Chinese)
[18]刘玉红,陈满银,刘晓燕.基于通道注意力的多尺度全卷积压缩感知重构[J/OL].计算机工程:1-8 [2022-04-29].DOI:10.19678/j.issn.1000-3428.0063546.LIU Yuhong, CHEN Manyin, LIU Xiaoyan.Multi-scale full convolution compressed perceptual reconstruction based on channel attention [J/OL].Computer Engineering:1-8[2022-04-29].DOI: 10.19678/j.issn.1000-3428.0063546.(in Chinese)
[19]许德刚,王露,李凡.深度学习的典型目标检测算法研究综述[J].计算机工程与应用,2021,57(8):10-25.XU Degang, WANG Lu, LI Fan.Review of typical object detection algorithms for deep learning [J].Computer Engineering and Applications, 2021, 57(8): 10-25.(in Chinese)
[20]HOU Qibin, ZHOU Daquan, FENG Jiashi.Coordinate attention for efficient mobile network design [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway, USA: IEEE, 2021: 13708-13717.
[21]HU Jie, SHEN Li, SUN Gang.Squeeze-and-excitation networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway, USA: IEEE,2018: 7132-7141.
[22]刘学平,李玙乾,刘励,等.嵌入SENet 结构的改进YOLOV3 目标识别算法[J].计算机工程,2019,45(11):243-248.LIU Xueping, LI Yuqian, LIU Li, et al.Improved YOLOV3 target recognition algorithm with embedded SENet structure [J].Computer Engineering, 2019, 45(11):243-248.(in Chinese)
[23]KIM S W, KOOK H K, SUN J Y, et al.Parallel feature pyramid network for object detection [C]// European Conference on Computer Vision - ECCV 2018.Munich,Germany: Springer, 2018: 239-256.
[24]LIU Shu, QI Lu, QIN Haifang, et al.Path aggregation network for instance segmentation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway, USA: IEEE, 2018: 8759-8768.
[25]TAN Mingxing, PANG Ruoming, LE Q V.EfficientDet:scalable and efficient object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, USA: IEEE, 2020: 10778-10787.
[26]杨真真,匡楠,范露,等.基于卷积神经网络的图像分类算法综述[J].信号处理,2018,34(12):1474-1489.YANG Zhenzhen, KUANG Nan, FAN Lu, et al.Review of image classification algorithms based on convolutional neural networks [J].Journal of Signal Processing, 2018, 34(12): 1474-1489.(in Chinese)
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
河南科技(2014年23期)2014-02-27
