
融合深度特征提取和注意力机制的跨域推荐模型
2023-05-31 00:50操凤萍张锐汀
深圳大学学报(理工版) 2023年3期
操凤萍,张锐汀
1)东南大学成贤学院计算机工程学院,江苏南京 210088;2)华泰证券股份有限公司,江苏南京 210019
随着网络信息的爆炸式增长,推荐系统成为用户获取信息的重要工具.在推荐系统的众多算法中,协同过滤(collaborative filtering,CF)被广泛用于推荐系统[1],同时,矩阵分解[2](matrix factorization,MF)在过去十几年中也取得了巨大的成功,但严重的稀疏问题导致推荐性能不尽如人意.跨域推荐(cross-domain recommendation,CDR)可以用来自一个或多个领域的反馈或评分提高推荐的性能[3].迁移学习已被广泛用于缓解跨域推荐过程中的数据稀疏问题,如联合矩阵分解(collective matrix factorization,CMF)模型[4]通过共享相同因子矩阵将两个共维矩阵耦合在一起,但该模型只学习用户评分矩阵,未考虑不同领域潜在特征的异质性.Temporaldomain CF[5]共享一个跨时域的静态组级评级矩阵,跨领域三元分解(cross-domain triadic factorization,CDTF)模型[6]提出利用张量分解来获得用户域的三元关系.但是,这些基于CF 的聚合式迁移方法仍未能很好地解决数据稀疏问题.为进一步缓解数据稀疏问题,近年来许多基于深度学习的模型被提出来以期增强迁移学习中的知识迁移.例如,基于嵌入和映射的跨域推荐(embedding and mapping for cross-domain recommendation,EMCDR)[7]模型通过多层全连接神经网络显式映射来自不同域的用户表示;DCDCSR(deep framework for both cross-domain and cross-system recommendation)[8]进 一 步 扩 展 了EMCDR,通过生成基准因子来解决跨域和跨系统问题;CoNet(collaborative cross networks)模型[9]通过训练一个深度“十字绣”网络,同时增强了两个域的推荐;喜好传播网络图(preference propagation graphNet,PPGN)[10]使用用户-项目交互图来捕获用户交互的过程偏好传播;DARec (deep domain adaptation for cross-domain recommendation via transferring rating pattern)模型[11]配备了对抗性学习过程,用于预测用户项目评分;π-Net[12]为共享账号的跨域顺序推荐而设计;KOREN 等[13]认为邻域模型可有效检测局部关系,而潜在因子模型通常可有效估计整体结构.跨域潜在特征映射(cross-domain latent feature mappingc,CDLFM)模型[14]通过将用户相似度纳入矩阵分解过程,充分利用了两种方法的优点.
近几年,为改善跨域推荐目标域数据稀疏与冷启动问题,有学者从深度融合邻域描述信息和评价信息等辅助信息的角度出发,对基于深度学习的跨域推荐模型荐方法进行了大量研究[15-20].但是,现有的跨域推荐模型往往对用户和项目所携带的大量且易获得的属性特征利用得不够充分[16-17].本研究提出一种融合深度特征提取和注意力机制的跨域推荐模型(cross-domain recommendation model of deep feature extraction and attention mechanism,CRDFEAM),使用类型相似度来获取用户对不同类型项目的偏好,以期增强用户特征的提取.模型迁移时并没有直接进行特征映射,而是减少两个领域特征之间数据分布的差异,使其具有更好的可解释性.在特征调整过程中,通过引入多层感知机(multilayer perceptron,MLP)并使用注意力机制(attention mechanism,AM)调整迁移到目标域的嵌入,缓解了目标域中用户特征信息和项目特征信息不足的问题.
1 研究基础
1.1 潜在因子模型
潜在因子模型[21]假设每个用户和每个项目都有一个因子相关联,用户-项目评分实际上是用户和项目的潜在因子相互作用的结果,可以从用户-项目评分中提取用户对产品类别的偏好信息.潜在空间中用户和项目的因子可以表示为特征向量,通过用户与隐类别的关系、项目与隐类别的关系,可计算出用户与项目的关系.
1.2 域适应
域适应[22]属于基于特征的迁移方法,研究的是如何将从源域学习到的知识迁移至目标域,以辅助解决目标域中的同类问题.

1.3 AM
特征迁移可能使不合适的源域隐语义迁移至目标域上,存在着负迁移的情况,导致跨域推荐的效果不够理想.AM[23]作为一种常用的捕捉不同特征间相关程度的神经网络结构,能很好地提取各输入特征之间的相关性.它将人类视觉的信息获取方式引入到深度学习中,在自然语言处理、模式识别和推荐系统等领域得到了广泛应用.AM 将注意力权重自动地关注在某个重要的局部特征,在解码过程中有效关注各个编码的隐藏状态,改善了模型在解码时遇到的信息缺失问题.
在传统的迁移学习中,迁移完成后,需根据源域的标注信息对目标域中的未标注特征进行标注.推荐系统的迁移则不需要标记,只需源域的特征信息.因此,使用最近邻算法(k-nearest neighbor,kNN)或支持向量机等方法进行后续处理将无法完成本研究任务,而AM可以解决此问题.
2 CRDFEAM模型
CRDFEAM 模型框架如图1.该框架包含增强嵌入(embedding)、嵌入迁移、嵌入调整和跨域推荐4个主要步骤.CRDFEAM算法描述见图2.
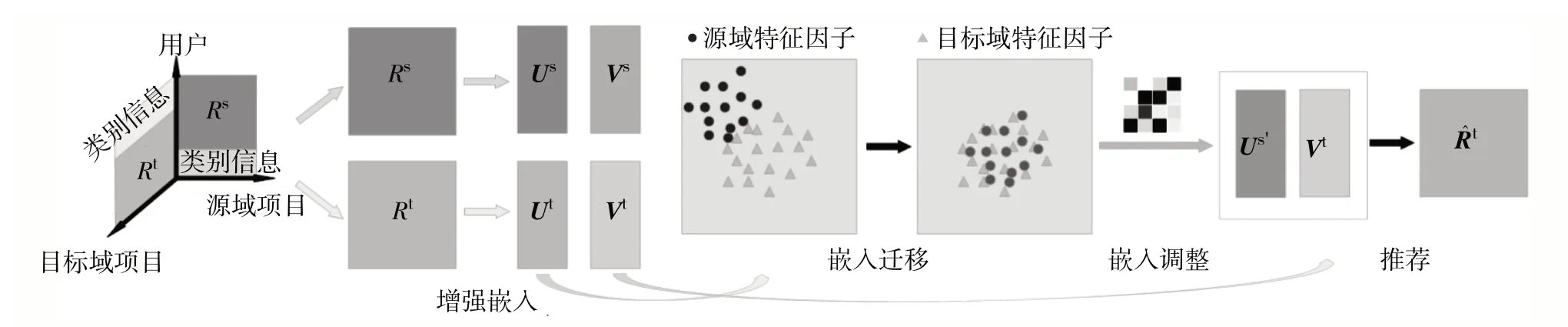
图1 CRDFEAM模型框架Fig.1 Illustration of proposed CRDFEAM model.

图2 CRDFEAM算法描述Fig.2 CRDFEAM algorithm description.
1)通过潜在因子模型挖掘潜在空间中用户-项目的表示,并使用项目类型相似度来增强用户特征提取.从源域Rs和目标域Rt分别学习到源域潜在因子{Us,Vs}和目标域潜在在因子{Ut,Vt}.其中,Us和Ut分别为源域和目标域的用户潜在因子;Vs和Vt分别为源域和目标域的项目潜在因子.
2)使用经典的迁移学习方法对用户和项目之间的跨域关系进行建模.形式上,给定第i个用户的源域特征因子Usi和目标域特征因子Uti,使用相关对齐(correlation alignment,CORAL)方法[24]来缩小源域特征相对于目标域的差异其中,fcoral为传递函数.
3)使用AM 进一步调整迁移特征.每个用户都可以利用注意力权重矩阵W来注意到与自己最相似的用户,并得到他们的特征因子Usi''=Us'·Wi.
4)跨域推荐.借助源域中的潜在因子、CORAL 算法和AM 来获得目标域中相应潜在因子,为目标域中的一个新用户-项目进行推荐.
2.1 矩阵分解和增强嵌入
CRDFEAM模型首先分别在Rs和Rt中学习用户-项目的源域潜在因子{Us,Vs}和目标域潜在因子{Ut,Vt},然后使用类型相似度来增强特征的提取效果,即在特征提取过程使用MF[11]和CDLFM[6]模型,再将评分矩阵分解和类型相似度结合起来进行特征提取.
1)MF 模型.MF 模型将评分矩阵R=(Rij)∈Rm×n分解为两个低维矩阵U=(Uij)∈Rm×k和V=(Vij)∈Rk×n.其中,k为潜在因子维数;m为用户总数;n为项目数;U为用户潜在因子矩阵,Ui为用户i的潜在因子矩阵;V为项目潜在因子矩阵,Vj为项目j的潜在因子矩阵.使用高斯观察噪声,则用户i项目j的用户-项目对的评分Rij被观测到的概率为
其中,N(Rij|UiTVj,σ2)是均值为UiTVj,方差为σ2的高斯分布概率密度函数.
MF 模型使条件分布在观测评分矩阵R上的概率最大化,即形成优化
其中,I为由0 和1 组成的二维矩阵,若用户i对项目j有评分,则元素Iij= 1;否则,Iij= 0;Ui为用户因子矩阵U中第i个用户与各个潜在因子之间的关联度的用户因子组成的向量;Vj为项目因子矩阵V中第j个项目与各个潜在因子关联的项目因子组成的向量;‖ ·‖2F表示Frobenius范数;λ1和λ2分别为预设的正则化参数.
2)增强特征提取.MF模型对评分矩阵进行分解,可将用户与项目嵌入到一个共享的低维隐空间内.然而,用户对不同类别项目的评分对推荐结果也很重要[6],例如,若用户对电影中的恐怖片评分较高,则认为用户偏爱“恐怖”类型.因项目类型信息往往容易获得,因此可在MF 过程中将用户与项目类型的相似性视为损失.项目类型偏好相似的用户的特征信息也相似,反之亦然.用户i对类型t的偏好为
其中,Ii.为被用户i评分的项目的集合;Tjt为项目j与类型t的关系.若项目j属于类型t,则Tjt= 1;否则,Tjt= 0.
给定两个用户p和q(p≠q),根据式(3)分别计算他们对类型t的偏好Ppt和Pqt,则用户p和q在类型t上的相似度为
其中,γ为设定的指数参数;Dpq为衡量用户p和q类型偏好的平方差,Dpq=∑k(Ppt-Pqt)2,Dpq越小意味着相似性越大.因此,可得最小化问题为
其中,L为拉普拉斯矩阵,L=D-S,D为对角矩阵,Dii=∑jSij;λu、λv和λs分别为控制3 个正则化项的参数.对式(5)进行等效转换,可得
其中,tr为求迹函数.
2.2 嵌入迁移
假设源域和目标域的用户-项目特征向量之间存在域偏移,则迁移需要缩小两个域之间的分布差异.以迁移用户的嵌入为例,迁移后的特征需要与目标字段中的特征进行交互,以得到R̂t.因此,特征的迁移必须从源域迁移到目标域,而不能同时迁移到再生核希尔伯特空间(reproducing kernel Hilbert space,RKHS)等外部空间,这限制了传统迁移学习的应用.以CORAL[24]为例描述嵌入的迁移过程,针对迁移后匹配不完全的问题,利用AM重新调整特征的权重,得到包含足够源域信息的迁移特征.对于经过增强嵌入得到的源域嵌入和目标域嵌入,先将它们集中起来以缩小这两个域的一阶统计量,再最小化两个域的二阶统计量(协方差).通过矩阵分解和增强嵌入,得到源域和目标域中的用户和项目的潜在特征因子{Us,Vs,Ut,Vt}.假设Cs和Ct分别为源域和目标域特征向量的协方差矩阵,为线性变换后的源域特征向量的协方差矩阵,Cs=(Us)TUs,Ct=(Ut)TUt.为最小化源特征和目标特征的二阶统计量之间的距离,对原始源特征应用线性变换A并使用Frobenius 范数作为矩阵距离度量,则统计特征对齐的目标函数为

其中,(·)+表示广义逆矩阵.
最后,可得迁移嵌入为
2.3 嵌入调整
由于目标域的特征向量与迁移的源域特征向量对应,因此重新调整源域迁移的特征非常重要.在CRDFEAM 模型中从未出现过的用户,都可以使用注意力权重矩阵来注意到与自己最相似的用户并得到其嵌入.而对于已经出现过的用户,一方面可通过注意力权重矩阵注意到他们的嵌入,另一方面也可通过AM调整项目嵌入来改善稀疏问题.这一步通过目标函数(10)来实现.

其中,[·,·]表示两个矩阵的拼接;ÛsMLP为通过MLP映射得到的嵌入.
2.4 跨域推荐
由Us、Vs、Ut、Vt、A*和W,可计算出评分预测矩阵为
3 实验及结果分析
3.1 实验设置
3.1.1 数据集
实验在3 个真实的电影领域数据集Movielens、Netflix和 Douban上进行,基本统计数据见表1.这3个数据集的用户重叠度低,可形成跨平台的项目共享场景.若选择邻域如图书数据作为源或目标数据集,形成跨域推荐场景,算法同样适用.

表1 数据集信息统计Table 1 Statistic of the datasets
由于数据大小不一且分布不均匀,本研究从每个数据集中随机选择5 000个用户和2 500个项目分别构建一个小规模的Movielens、Netflix 和Douban数据集,数据密度分别为0.021 0、0.006 8 和0.002 9.将3 组数据集作为源域和目标源进行轮换,得到6组跨域推荐.3个数据集的数据稀疏度从高到低依次为Douban > Netflix > Movielens,为验证模型的有效性,设置从稀疏域到密集域的迁移.
3.1.2 评估指标
使 用 均 方 根 误 差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)作为性能指标,计算公式分别为
其中,O为用于参数选择的冷启动用户验证集;ru,i和r̂u,i分别为用户u在项目i上的实际评分和预测评分.
3.1.3 验证模型
实验所用基准模型包括隐语义模型(latent factor model,LFM)、CMF 模 型、EMCDR 模 型 和CDLFM 模型.其中,LFM 模型以对称方式进行跨域推荐,模型中的每个实体都有一个跨域共享的全局潜在因子,每个实体的域相关因子通过将全局因子和特定领域的迁移矩阵相乘生成;CMF模型使用共享用户因子和跨域联合评分矩阵分解.EMCDR模型率先提出3步优化示例,依次在两个领域训练矩阵分解,然后使用线性映射和MLP 映射用户潜在因子.EMCDR-LM和EMCDR-MLP分别表示基于线性映射和基于MLP的EMCDR.CDLFM模型通过融合3个用户相似性作为基于用户评分行为的正则化项来调整矩阵分解.采用考虑相似用户和基于梯度提升树的集成学习方法,使用基于邻域映射的方法代替MLP.
本研究提出的CRDFEAM 模型使用的组件包括增强嵌入、嵌入迁移、嵌入调整和推荐,而CRDFEAM+模型指在AM过程中引入MLP映射嵌入的CRDFEAM模型.
3.1.4 实验流程
本研究将CRDFEAM和CRDFEAM+模型与基准模型进行对比实验,并设置实验分析增强特征提取(enhanced embedding,EE)组件、嵌入迁移过程中CORAL和MLP组件,以及嵌入调整过程中AM组件的作用.
实验在基于Window 10 操作系统,计算机硬件CPU 为Intel(R)Core(TM)i5-8300H CPU @ 2.30 GHz,GPU 为NVDIA GeForce GTX 1050Ti 4 Gbyte,内存为8 Gbyte.实验代码使用Python 3.7.3 编写,使用Tensorflow 1.14.0 作为深度学习框架.
3.2 实验结果分析
3.2.1 跨域推荐效果
表2 和表3 分别展示了跨域推荐模型LFM、CMF、EMCDR-LM[5]、EMCDR-MLP[5]、CDLMF[6]、CRDFEAM 和CRDFEAM+,在Movielens、Netflix 和Douban 组成的6 组数据对上的RMSE 值和MAE 值.其中,“→”表示跨域推荐,其左边为源域,右边为目标域;ΔRMSE和ΔMEA分别为模型的RMSE 值和MEA值较CDLMF模型结果的提升率.

表2 跨域推荐模型RMSE值对比1)Table 2 Comparison of RMSE values of cross-domain recommendation models

表3 跨域推荐模型MAE值对比1)Table 3 Comparison of MAE values of cross-domain recommendation models
由表2 和表3 可见,在所有跨域推荐场景中,CRDFEAM+ 的RMSE 值和MAE 值均明显优于其他基线,显示了CRDFEAM+的跨域推荐方法的优越性.分析表2和表3结果可得到如下结论:
1)与基准模型中表现最优的CDLMF 模型相比,CRDFEAM+的RMSE值平均提升9.88%,MAE值平均提升11.14%.说明CRDFEAM+模型在改善了跨域推荐中目标域数据稀疏与冷启动问题的优越性.
2)早期的LFM 和CMF 模型的效果相对较差.基于线性映射和 MLP的EMCDR方法在一定程度上改善了跨域效果.CDLFM 在用户特征学习方面做了改进,效果良好可以接受.
3)嵌入迁移越多跨域推荐效果越显著,增加MLP 映射的CRDFEAM+模型比CRDFEAM 模型RMSE和MAE平均提高了约2%,RMSE值改进率由7.51%提升到9.88%,MAE 值改进率由9.21%提升到11.14%.
3.2.2 消融分析
1)在模型其他模块相同条件下,对所提基于EE 的模型CRDFEAM+与基于单纯MF 的推荐模型(记为MFACR+)进行对比实验.结果如表4.其中,Δ为较基准模型CDLMF 的提升率.由表4 可见,RMSE的改善率从9.58%提高到9.88%,MAE值提高率从11.09%提高到11.14%.可见,在嵌入提取过程中引入类型相似信息可在一定程度上提高跨域推荐的效果.图3 为从Movielens到Netflix特征迁移前和迁移后的分布情况的t-分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)可视化展现.其中,t-SNE1 和t-SNE2 分别为降准后的2个维度.由图3可见,在嵌入迁移前,两域之间存在一定的距离,而在嵌入迁移后,两个域的分布比较接近,这与本研究设想一致.

表4 类型信息对跨域推荐RMSE值和MAE值的影响1)Table 4 The influence of type information on RMSE value and MAE value of cross-domain recommendation

图3 (a)迁移前和(b)迁移后两域分布距离t-SNE可视化结果(实心圆点是源域特征,空心圆点是目标域特征)Fig.3 Two-domain distribution distance visualization results (a) before and (b) after transfer by t-SNE.(Solid dots are for source domain features, hollow dots are for target domain features.)
2)对EE、CORAL、MLP 和AM 组件进行不同组合,并考察这些组合方法下的RMSE 值和RMSE值(表5),以验证CORAL、MLP 和AM 组件的作用.其中,组合1 为4 种组件都使用;组合2 为使用EE、CORAL 和AM 组件;组合3 为使用EE、MLP 和AM 组件;组 合4 为仅使用EE 和CORAL 组件.比较组合1和组合2可见,引入MLP 映射嵌入模块,RMSE 值从1.010 7 降至0.984 7,MAE 值从0.795 3 降 至0.778 4.比 较 组 合2 和 组 合3,CORAL 的嵌入迁移优于MLP,RMSE 值从1.019 5降至1.010 7,MAE 值从0.803 3 降至0.795 3.比较组合2 和组合4 看到,RMSE 值从1.199 2 降至0.987 0,改善了16%,MAE 值从0.953 9 到0.778 4降至了17%,验证了注意力模块的重要性.

表5 不同组件组合下的RMSE和MAE值1)Table 5 RMSE and MAE values of under different componeut combinations
结 语
CRDFEAM 模型通过使用深度特征提取和分布对齐减少了领域差异,AM 可以很好地提升跨域推荐性能.通过潜在因子模型,将类型相似度合并到矩阵分解过程,以挖掘隐性偏好.实验表明,CRDFEAM 模型能更充分地获取用户特征,分布对齐方式有效减少了两个领域特征之间数据分布的差异,AM 进一步调整用户特征,有效缓解了目标领域数据的稀疏问题.与基准模型相比,CRDFEAM模型的整体评分效果优于基准模型.后续将以CRDFEAM模型为基础进行多域迁移研究.
参考文献 / References:
[1]KOREN Y, BELL R, VOLINSKY C.Matrix factorization techniques for recommender systems [J].Computer, 2009,42(8): 30-37.
[2]SALAKHUTDINOV R, MNIH A.Probabilistic matrix factorization [C]// Proceedings of the 20th International Conference on Neural Information Processing Systems.Red Hook, USA: Curran Associates Inc., 2007: 1257-1264.
[3]KHAN M M, IBRAHIM R, GHANI I.Cross domain recommender systems: a systematic literature review [J].ACM Computing Surveys, 2017, 50(3): 36.
[4]SINGH A P, GORDON G J.Relational learning via collective matrix factorization [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York, USA: Association for Computing Machinery, 2008: 650-658.
[5]FERNÁNDEZ-TOBIÁS I,CANTADOR I.Exploiting social tags in matrix factorization models for cross-domain collaborative fifiltering [C]// Proceedings of the 8th ACM Conference on Recommender systems.New York,USA:Association for Computing Machinery,2014:34-40.
[6]HU Liang,CAO Jian,XU Guandong,et al.Personalized recommendation via cross-domain triadic factorization[C]// Proceedings of the 22nd international conference on World Wide Web.New York,USA:Association for Computing Machinery,2013:595-606.
[7]MAN Tong, SHEN Huawei, JIN Xiaolong, et al.Crossdomain recommendation: an embedding and mapping approach [C]//Proceedings of the 26 International Joint Conference on Artificial Intelligence.California: International Joint Conferences on Artificial Intelligence Organization, 2017: 2464-2470.
[8]ZHU Feng, WANG Yan, CHEN Chaochao, et al.A deep framework for cross-domain and cross-system recommendations [C]// Proceedings of the 27 International Joint Conference on Artificial Intelligence.California: International Joint Conferences on Artificial Intelligence Organization.2018: 3711-3717.
[9]HU Guangneng, ZHANG Yu, YANG Qiang.CoNet:collaborative cross networks for cross-domain recommendation [C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management.New York, USA: Association for Computing Machinery, 2018: 667-676.
[10]ZHAO Cheng, LI Chenliang, FU Cong.Cross-domain recommendation via preference propagation graphNet [C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management.New York,USA: Association for Computing Machinery, 2019: 2165-2168.
[11]YUAN Feng, YAO Lina, BENATALLAH B.DARec: deep domain adaptation for cross-domain recommendation via transferring rating patterns [C]// Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence.California, USA: International Joint Conferences on Artificial Intelligence Organization.2019: 4227-4233.
[12]MA Muyang, REN Pengjie, LIN Yujie, et al.∏-Net: a parallel information-sharing network for shared-account cross-domain sequential recommendations [C]// Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York, USA: Association for Computing Machinery, 2019: 685-694.
[13]KOREN Y.Factorization meets the neighborhood: a multifaceted collaborative filtering model [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York, USA:Association for Computing Machinery.2008: 426-434.
[14]WANG Xinghua, PENG Zhaohui, WANG Senzhang, et al.Cross-domain recommendation for cold-start users via neighborhood based feature mapping [EB/OL].(2018-03-05).[2023-01-01].https://arxiv.org/abs/1803.01617.
[15]方义秋,张震坤,葛君伟.基于自注意力机制和迁移学习的跨领域推荐算法[J].计算机科学,2022,49(8):70-77.FANG Yiqiu, ZHANG Zhenkun, GE Junwei.Crossdomain recommendation algorithm based on self-attention mechanism and transfer learning [J].Computer Science,2022, 49(8): 70-77.(in Chinese)
[16]王禹,吴云.基于评论细粒度观点的跨域推荐模型[J/OL].计算机工程与应用:1-11.[2023-02-21].http://kns.cnki.net/kcms/detail/11.2127.TP.20220304.1425.005.html.WANG Yu, WU Yun.Cross domain recommendation model based on fine-grained comments [J/OL].Computer Engineering and Applications.(2022-03-08) [2023-02-21].http://kns.cnki.net/kcms/detail/11.2127.TP.20220304.1425.005.html.(in Chinese)
[17]陆永倩,生佳根.深度融合辅助信息的跨域推荐算法[J].计算机工程与应用,2022,58(24):90-96.LU Yongqian, SHENG Jiagen.Cross-domain recommendation algorithm based on deep fusion of side information[J].Computer Engineering and Applications, 2022, 58(24): 90-96.(in Chinese)
[18]段乐乐,李博一,丁滋钊,等.目标域特征感知与互补用户迁移的跨域推荐模型[J/OL].小型微型计算机系统:1-10.(2022-11-28)[2023-02-21].https://doi.org/10.20009/j.cnki.21-1106/TP.2022-0373.DUAN Lele, LI Boyi, DING Zizhao, et al.Cross domain recommendation model based on target domain feature perception and complementary user migration [J/OL].Journal of Chinese Computer Systems: 1-10.(2022-11-28) [2023-02-21].https://doi.org/10.20009/j.cnki.21-1106/TP.2022-0373.(in Chinese)
[19]ZHU Yongchun, TANG Zhenwei, LIU Yudan, et al.Personalized transfer of user preferences for cross-domain recommendation [C]// Proceedings of the 15th ACM International Conference on Web Search and Data Mining.New York, USA: Association for Computing Machinery, 2022: 1507-1515.
[20]ZHU Yongchun, XIE Ruobing, ZHUANG Fuzhen, et al.Learning to warm up cold item embeddings for cold-start recommendation with meta scaling and shifting networks[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval.New York, USA: Association for Computing Machinery, 2021: 1167-1176.
[21]VASWANI A, SHAZEER N, PARMAR N, et al.Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook, USA: Curran Associates Inc., 2017: 6000-6010.
[22]BAHDANAU D, CHO K H, BENGIO Y.Neural machine translation by jointly learning to align and translate [C]//The 3rd International Conference on Learning Representations.[S.l.: s.n.], 2015: 1-15.
[23]PAN S J, TSANG I W, KWOK J T, et al.Domain adaptation via transfer component analysis [J].IEEE Transactions on Neural Networks, 2011, 22(2): 199-210.
[24]SUN Baochen, FENG Jiashi, SAENKO K.Return of frustratingly easy domain adaptation [C]// Proceedings of the AAAI Conference on Artificial Intelligence.2016, 30(1):2058-2065.
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
科学家(2021年24期)2021-04-25
计算机技术与发展(2020年11期)2020-12-04
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
电子与信息学报(2015年12期)2015-08-17
