
海关大数据分析教学研究
2023-05-30 10:48郑鹏飞李菁菁
计算机应用文摘 2023年1期
郑鹏飞 李菁菁

关键词:海关大数据;GTA;R语言教学
1引言
对贸易数据进行统计和分析,是我国海关的传统重要职能之一。2021年,我国货物进出口总额突破39万亿元,比上年增长21 .4%。其中,出口21.7万亿元,增长21.2%;进口17.4万亿元,增长21. 5%。进出口贸易规模飞速增长,对海关统计分析人员的数据处理能力提出了更高的要求。然而,依据我国的海關统计制度,海关贸易数据的采集依赖各海关日常业务中产生的海量报关单,汇总以后具有来源广、字段多、跨度大、体量大等特征,原始数据经常会到达数百万行甚至上亿行,面对如此规模的数据,传统的Excel,Tableau等办公软件基本很难使用或者无法使用,需要使用新的工具才能实现“快、广、深”的目标[1]。
作为一种综合分析、科学预测的技术手段,大数据技术为构建统筹全局、系统集成、协同高效的海关数据分析体系提供了可能[2]。欧美发达国家海关的实践已经表明,大数据技术可以成为海关数据分析的“效率倍增器”。例如,美国海关开发的“全球自动布控系统”能够迅速将旅客、舱单等信息与其他数据库进行综合比对,大幅提升了对“高风险旅客”的筛查效率。
鉴于此,《“十四五”海关发展规划》将“科技兴关动力强劲,创新应用能力大幅提升”作为主要目标之一,强调要“以大数据驱动风险防控、通关监管、税收征管、检验检疫等海关主要业务运行,形成大数据智能应用生态,提升大数据辅助治理能力。”
2统计软件R语言特征
为使人才培养符合大数据处理的需求,目前很多高校都开设了诸多统计软件课程[3],如Python,R,Stata,SAS,SPSS,MATLAB等。其中,R语言是一种功能强大、被诸多高校所青睐的课程,它具有以下几个基本特征。
(1)R是开源软件[4]。可以在它的网站及其镜像中下载任何有关的安装程序、源代码、程序包及其源代码、文档资料。标准的安装文件自身就带有许多模块和内嵌统计函数,安装好后可以直接实现许多常用的统计功能。
(2)R是一种可编程的语言。作为一个开放的统计编程环境,语法通俗易懂,很容易学会和掌握语言的语法。而且学会之后,我们可以编制自己的函数来扩展现有的语言。这也就是为什么它的更新速度比一般统计软件(如SPSS,SAS等)快得多。大多数最新的统计方法和技术都可以在R中直接得到。
(3)所有R的函数和数据集是保存在程序包里面的[5]。只有当一个包被载人时,它的内容才可以被访问。一些常用、基本的程序包已经被收入标准安装文件中,随着新的统计分析方法的出现,标准安装文件中所包含的程序包也随着版本的更新而不断变化。在另外版安装文件中,已经包含的程序包有:base-R的基础模块、mle-极大似然估计模块、ts-时间序列分析模块、mva-多元统计分析模块、survival-生存分析模块等。
(4)R具有很强的互动性[6]。如图1所示,除了图形输出是在另外的窗口处,它的输入输出窗口都是在同一个窗口进行的,输入语法中如果出现错误会马上在窗口中得到提示,对以前输入过的命令有记忆功能,可以随时再现、编辑修改,以满足用户的需要。输出的图形可以直接保存为JPG,BMP,PNG等图片格式,还可以直接保存为PDF文件。另外,和其他编程语言与数据库之间有很好的接口。
综上所述.R语言是一门适合大数据分析的强大工具。然而,凡事都有其两面性,与图形界面丰富的传统统计软件相比,R语言具有一定的学习门槛,初学者往往需要输入至少一万行代码才能入门[7],而且很多程序包的学习甚至比R语言本身还要复杂(如ggplot2软件包)。
3教学难点
在当前的R语言类课程教学中,主要存在两个难点。
(1)教学时长偏短。在大多数高校的人才培养方案中,R语言类课程的教学时长都是16周、32学时,教学内容多聚焦于数据结构、基本语法,难以使学生快速掌握大数据分析能力[8]。
(2)难以获取数据来源。海关高度重视数据保密工作,海关采集并保有的很多数据都涉及国家机密。虽然海关统计部门也通过其数据公布平台定期发布海关数据(如图2所示),但其体量与“大数据”的特征存在较大的差距[9]。
除海关数据外,很多其他来源的大数据都涉及商业机密,既难以供学生在课堂上操作实践,也可能与海关数据分析的主题相去甚远。
4基于GTA数据的教学案例
GTA是全球关贸数据库(Global Trade Atlas)的简称,它将全球200多个国家和地区海关所提供的进出口统计信息整合成一个全面的、双边的商品贸易数据库,使全球贸易分析人员按需搜索并下载所需数据成为可能。该数据库同时提供逐笔的贸易信息,数据来源广、体量大、跨度久,是用来进行海关大数据分析教学的绝佳数据。
4.1分析目标
验证“十三五”期间我国优势出口产业是否发生了明显地向其他国家转移。
4.2解决思路
第一阶段:基于GTA数据库,将我国2015年的全部出口报关单按6位数HS编码进行分组并汇总金额,按倒序排列,取出前200位HS编码(TOP 200商品)作为我国2015年优势产业代码。
第二阶段:计算2015年,全世界各个国家和地区的TOP 200商品出口金额,计算包括我国在内的各个国家和地区这200种商品的出口份额(Share2015)。
第三阶段:基于GTA数据库,查找2019年全世界各个国家和地区TOP 200商品的出口金额,计算包括我国在内的各个国家和地区这200种商品的出口份额(Share2019)。
也可以绘制成图形,更清晰直观地展示5年内我国在TOP 200商品出口份额的变化情况,如图3所示。
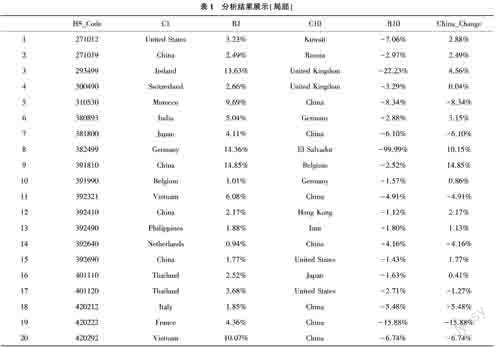
计算结果如表1所列(局部),不仅能得到在目标5年内TOP 200商品中国的市场份额变化情况,还能得到该商品市场份额增加的前5名国家和减少的后5名国家(因篇幅限制,此处仅显示前1和后1),即回答了“我们的份额是从谁那抢来的”或者“我们的份额被谁抢走了”的现实问题。
总体来看,在TOP 200商品中,我国出口份额增加的商品有95种,减少的有105种,基本保持稳定,即2015~2019年间,我国并未发生明显的产业链流失。
5结束语
在大数据人才培养过程中,统计软件R语言等可编程开源软件是较为普遍的选择。然而,由于海关数据的特殊性和难以获取性,贴近海关数据分析实际的实践教学相对困难。本文以GTA数据为例,利用难度不高的代码对海关统计分析领域的一个常见问题进行了较为清晰的解答,为海关大数据分析教学提供了新的思路。
