
甲状腺疾病辅助诊断机器学习模型研究
2023-05-30 10:48:04王莹顾大勇
电脑知识与技术 2023年2期
王莹 顾大勇


关键词:甲亢;甲减;机器学习;逻辑回归;医学检验
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2023)02-0007-04
1概述
甲状腺是人体内分泌系统的重要组成部分,通过稳定甲状腺激素,维持人体的新陈代谢。甲状腺功能减退症(甲减)和甲状腺功能亢进症(甲亢)是两种最常见的甲状腺疾病[1]。甲亢的特征是甲状腺激素合成和甲状腺分泌增加,造成机体代谢亢进和交感神经兴奋,引起心悸、出汗、进食和便次增多及体重减少的病症。部分患者同时有突眼、眼睑水肿、视力减退等症状。甲减是指甲状腺激素缺乏症,如果得不到及时治疗,将严重影响健康,甚至导致死亡。甲状腺疾病和代谢异常综合征、糖尿病、高血压和血脂异常的多发性在老年人中很常见[2]。甲状腺疾病的早诊断、早治疗在预防和减少其并发症方面起着重要作用,可以降低相关疾病的发病率和死亡率。
甲状腺疾病的病因复杂,与自身免疫状态、环境、营养、遗传基因等都有着密切的关系。目前,医学实验室检查是临床诊断甲状腺功能障碍的常用方式,主要通过检测总甲状腺素(Total Thyroxine ,TT4)、游离甲状腺素(Free Thyroxine,FT4)、总三碘甲状腺氨酸(Total Triiodothyronine ,TT3)、游离三碘甲状腺氨酸(Free Triiodothyronine,FT3)及促甲状腺激素(ThyroidStimulating Hormone, TSH)五项医学检验项目,从而根据其水平判断甲状腺功能(甲功)是否正常,甲功五项检测结果具有相对较高的临床诊断符合率[3-5]。甲功五项对甲状腺疾病的类型判断、疗效监测、病情评估都具有重要价值,直接影响临床医生的诊断及用药[6]。在临床上, 采用何种检查方式评价甲状腺功能并无统一说法[7],研究发现其他医学实验室检查项目与甲状腺疾病相关,例如尿碘、糖化血红蛋白和血糖等,尿碘与甲状腺疾病的关系日益突出并受到关注,尿碘监测对于防治甲状腺疾病具有重要的现实意义[8-10],糖化血红蛋白与血糖同样与甲状腺疾病相关,患糖尿病人群发生甲状腺功能障碍的概率较非糖尿病人群高出2~3倍[11]。因此有必要全面发掘医学检验项目与甲状腺疾病的相关性。医学检验项目具有数据量大、数据结构复杂和数据维度高等特点,传统的数理统计工具已经无法满足要求,机器学习是用计算机通过算法来学习数据中包含的内在规律和信息,从而获得新的经验和知识,以提高计算机的智能性,使计算机面对问题时能够做出与人类相似的决策[12]。机器学习有助于从海量的医学数据中发现传统数理统计无法发现的问题,为临床诊断提供新的解决问题思路[13]。
为了发掘医学检验项目与甲状腺疾病的相关性,本研究采用机器学习算法对全维度医学检验数据进行挖掘,直观地展示每一项医学检验项目与甲状腺疾病的相关性。
2 资料与方法
2.1 一般资料
本研究共包括65723例甲亢患者、48028例甲减患者和19841例体检人员的1355项医学检验数据。其中甲亢患者、甲减患者和体检人员均以临床诊断结果作为筛选依据。在进行机器学习计算时65723例甲亢患者数据,插入19841例体检人员数据获得85564 例人员数据作为甲亢机器学习数据源。48028例甲减患者数据插入19841例体检人员数据获得67869例人员数据作为甲减机器学习数据源。
2.1.1资料来源
以某医院近5年(2016年10月1日至2021年09 月30日)的全量医学检验数据经过数据治理、开发后形成包含4903891条记录的数据宽表为基础。
2.1.2数据集成
从实验室信息管理系统(Laboratory InformationManagement System, LIS)和医院信息管理系统(Hospi?tal Information System, HIS)中抽取2016 年10 月至2021年9月的全量医学检验数据,字段包括患者的ID、年龄、性别、患者就诊类别(门诊或住院)、检验日期、检验项目编码、检验结果、诊断结果。
2.1.3数据治理、开发
在大数据平台采用结构化查询语言(StructuredQuery Language, SQL)脚本对数据实施行列转置,实现每例患者在同一检验日期的所有检验项目处于同一行,不同患者的同一个检验项目结果处于同一列。获得4903891条记录的数据宽表。对数据宽表进行数据清洗、数据类型转换、数据归一化操作(数据值压缩到[0,1]区间,实现字段间统一量纲)。
2.2 方法
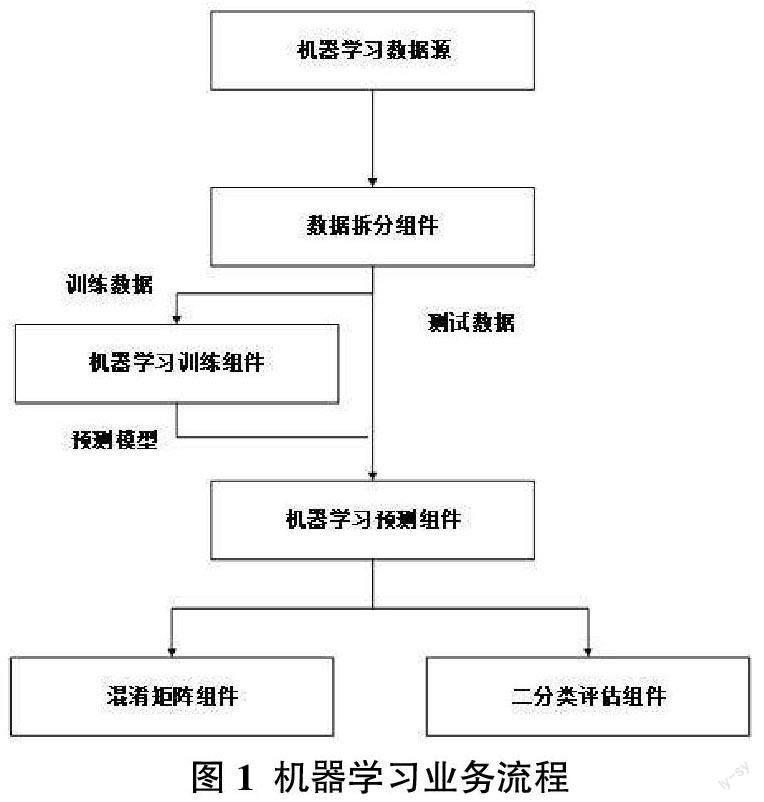
逻辑回归(Logistic Regression,LR)是用于解决二分类问题的经典机器学习算法[14]。LR模型构造简单、结果方便易懂,是数据挖掘方法在医学领域应用的一个典型方法[15]。机器学习数据源首先被读取到机器学习业务流程,数据源通过数据拆分组件按照一定比例随机拆分为两部分数据:一部分训练数据,另一部分为测试数据。训练数据导入机器学习训练组件生成预测模型。测试数据和预测模型分别导入预测组件对测试数据进行预测。预测的结果分别导入混淆矩阵组件和二分类评估组件。对预测模型进行评估,判断预测模型的可用性。业务流程如图1所示。
2.3 工具与评估指标
2.3.1工具
大数据平台Maxcompute用于数据的存储、计算和管理,大数据治理开发平台Dataworks用于数据治理、开发,机器学习平台PAI提供的模块化组件用于模型开发和统计分析。
2.3.2评估指标
模型评估采用混淆矩阵和二分类评估两种方法分别评估。
(1)混淆矩阵
混淆矩阵每一列代表一个类的预测情况,每一行表示一个类的实际样本情况。其中正例樣本数量记为阳性(Positive, P),负例样本数量记为阴性(Nega?tive,N),被正确预测的正例数量记为真阳性(True Pos?itive, TP),负例样本被预测呈正例样本数量记为假阳性(False Positive,FP),正例样本被预测成负例样本数量记为假阴性(False Negative, FN),正确预测到的负例样本数量记为真阴性(True Negative, TN)[17]。如图2所示。
(2)二分类评估
二分类评估通过计算AUC 和F1-Score 两项指标对预测模型进行评估。ROC曲线全称为受试者工作特征曲线(Receiver Operating Characteristic curve,ROC),ROC 的重要特征是曲线下面积(Area Under Curve, AUC),AUC 取值范围是[0,1], AUC 越接近于1识别能力越强。F1 -Score 与混淆矩阵计算公式相同。
3结果
3.1 甲亢机器学习模型及评估
3.1.1模型特征权重排序
LR二分类模型展示了1355项特征列(检验项目)的权重,按照权重降序排列,选择前20 项,如表1 所示。
其中项目编码为检验项目的唯一编码、项目名称为检验项目的中文名称、权重为该检验项目在LR二分类模型中的系数,权重数值越大,该检验项目与目标列对应诊断结果的相关性越大。项目编码:s8604 和s6437;s8603、s8003和s5239;s5516和s8002;s8005 和s6440;s8601和s8001均为来自不同检验设备的同一个检验项目,dep对应的住院或门诊表示患者来源。
3.1.2模型预测结果评估
(1)混淆矩阵评估结果
混淆矩阵对测试数据的预测结果进行统计分析,如表2所示。准确率、精确率、召回率、F1- Score 评估结果均在90%以上(大于50%则具有概率意义上的分辨能力)。
(2)二分类评估结果
二分类评估对测试数据的预测结果进行统计分析,如表3所示,AUC 和F1- Score 的结果均大于0.95,表明模型的预测准确性高,可用性强。
3.2 甲减机器学习模型及评估
3.2.1模型特征权重排序
LR二分类模型展示了1355项特征列(检验项目)的权重,对权重按照降序排列,选择前20项。如表4所示。
其中项目编码为检验项目的唯一编码、项目名称为检验项目的中文名称、权重为该检验项目在LR二分类模型中的系数,权重数值越大,该检验项目与目标列对应诊断结果的相关性越大。项目编码:s8604、s6437和s5240;s8603、s8003和s5239;s8002和s5516;s6440、s5241和s8005均为来自不同检验设备的同一个检验项目,dep对应的住院或门诊表示患者来源。
3.2.2模型预测结果评估
(1)混淆矩阵评估结果
混淆矩阵对测试数据的预测结果进行统计分析,如表5所示。准确率、精确率、召回率、F1-Score 评估结果均在95%以上。
(2)二分类评估结果
4结论
本研究对某医院近5年的全量医学检验数据進行治理、开发形成数据宽表。在此基础上采用机器学习逻辑回归二分类算法构建并验证了甲亢和甲减的预测模型。
对预测模型中部分检验项目与他人研究成果进行比对,在甲亢和甲减的两个模型中FT4的权重均位居第一,表明FT4与诊断结果的强相关关系。多项研究表明FT4 与TSH 是检测甲状腺疾病的优选指标[18-20]。在本研究的甲亢相关权重中,肝功能指标中的谷草转氨酶和间接胆红素也位列其中,证明了甲亢对肝功能的影响。谷草转氨酶与甲状腺激素水平大致呈正相关,说明在一定程度上甲亢合并肝损害程度越重,甲状腺激素水平也越高[21-22]。研究发现甲亢、甲减患者的血糖水平与正常体检者比较差异具有统计学意义(P<0.05),甲状腺功能减退症患者的糖化血红蛋白水平显著高于对照组[23-24]。有研究发现中性粒细胞与甲减发生率密切相关,中性粒细胞联合性别、甲状腺体积等其他检测指标采用逻辑回归算法可以预测甲减发生率(AUC=0.777)[25]。
综合以上国内外研究成果,在对1355项特征列的机器学习构建的预测模型在具有较高辅助诊断能力的基础上,按照权重降序排列的甲亢和甲减的前二十项特征大部分与临床诊断研究结果吻合。说明了预测模型的辅助诊断可用性和可解释性。预测模型中每个权重描述相应预测变量对结果的贡献大小,并不是独立的决定因素。需要包括上述20项在内的1355 项特征列构成的完整LR二分类模型发挥整体作用。考虑到真实数据的分布情况,本研究没有对来自不同检测设备对同一个检验项目的重复数据进行合并处理,这必然会影响到具体的检验项目的真实权重,另一方面,同一个检验项目的权重基本相同也进一步佐证了机器学习发掘的与诊断结果强相关检验项目的可信度。未来可以对同一个检验项目合理去重后进一步研究验证预测模型,从而纠正目前一些数据不规范的影响。由于整个预测模型是将所有检验项目都纳入预测计算的范围,比单项或少数指标更能反映病人的真实情况,减少了医生综合判断时若干项指标矛盾或不符时带来的困惑,在未来人工智能诊断及疗效评估中有着重大的意义和应用前景。二分类评估对测试数据的预测结果进行统计分析,如表6所示,AUC 和F1-Score 的结果均大于0.95,表明模型的预测准确性高,具有较好的可用性。
猜你喜欢
药物与人(2023年5期)2024-01-09 02:44:29
中国典型病例大全(2022年7期)2022-04-22 00:50:34
东方教育(2016年7期)2017-01-17 19:57:33
青年时代(2016年27期)2016-12-08 22:27:25
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
考试周刊(2016年32期)2016-05-28 21:05:04
考试周刊(2016年5期)2016-03-11 09:44:59
