
基于萤火虫算法改进BP神经网络的电力用能行为预测方法
2023-05-26 14:06吴明兴谷昊霖杨塞特
沈阳工业大学学报 2023年3期
吴明兴, 谷昊霖, 别 佩, 陈 青, 杨塞特
(1. 华中科技大学 电气与电子工程学院, 武汉 430074; 2. 广东电力交易中心有限责任公司 发展研究部, 广州 510030; 3. 北京清能互联科技有限公司 战略咨询部, 北京 100084)
电力用能数据中蕴藏着用户的用能行为,对这类数据进行分析及挖掘可以更好地梳理用户特征[1-2].将电力用能行为类似的用户进行聚合,有利于电力公司提供更为合理的套餐服务、收取不同的税费以及调整电网的输电效率等[3].精准的负荷预测对于电力管理系统的在线调度至关重要,便于系统进行统一规划、营销及调度,从而提高经济与社会效益[4-5].
当前,时间序列[6]以及人工智能[7]的预测方法被广泛应用于电力负荷预测,这类方法令模型的预测精度和鲁棒性均得到大幅提升.李晨熙[8]采用小波去噪法改进了传统时间序列ARIMA模型,虽有效解决了电力负荷波动较大的问题,但改进模型仍无法对非线性数据进行准确拟合;朱健安等[9]通过傅里叶变换对预测误差进行修正,提高了预测精度,但该方法的整体计算量较大;程超[10]则提出应用遗传算法(genetic algorithm,GA)对BP神经网络的权重及偏置进行优化,有效抑制其较易陷入局部最优的问题,但却并未考虑工作日与非工作日的影响.针对上述问题,本文首先分析了用户的电力用能数据,并从中提取了时间序列特征,然后采用K-means聚类算法对用户的电力用能行为进行类别划分,且分析了每个类别用户的电力用能模式及特点,进而对各类别的用户进行负荷预测,再利用萤火虫算法(firefly algorithm,FA)优化BP神经网络的初始化权重和偏置,最终提升了模型的预测精度及收敛速度.
1 电力用能数据特征
电力用能数据属于典型的时间序列数据,其具有趋势性、周期性、随机性与综合性等特点,因此特征提取是时间序列预测准确性的关键[11].本文提取了时间特征、均值特征、布尔特征、滑动窗口作为电力用能行为分类的依据以及负荷预测模型的输入.
1) 时间特征.电力用能数据在时间上具有显著的规律性.用户每日的负荷表现为峰、平、谷的差异分布,每年的负荷则呈现出丰、平、枯的差异分布,因此,可提取年、月、日、时等时间特征来作为分类依据.
2) 均值特征.由于用户在不同时间维度的电力用能行为有所不同,故负荷的波动性较大.而提取某个时间维度的均值特征能够有效降低负荷波动性,并可反映该时间维度的负荷水平.
3) 布尔特征.通常而言,用户在节假日与工作日的电力用能行为区别较大,负荷的分布差距也较为明显.针对此种情况,本文提取了是否为节假日的布尔特征.
4) 滑动窗口.当前时刻的负荷受到前N个时刻的负荷影响,因此每个时刻前N个时刻负荷也可作为特征.滑动窗口示意图如图1所示,若已知前9个时刻的负荷,需预测第10个时刻的负荷,则可假设N=2,将第1~2时刻的负荷作为特征,第3时刻作为预测标签,依次向后滑动1个时刻,从而形成8个样本数据,并将其中1~7个样本作为训练集建立预测模型,样本8则为预测样本,进而预测出第10个时刻的负荷.
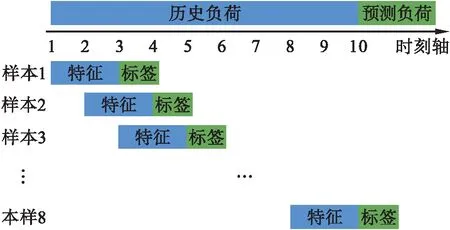
图1 滑动窗口示意图
2 电力用能行为聚类分析
通过分析用户电力用能数据的时间特征、均值特征、布尔特征、滑动窗口等特征,并将用电行为类似的用户进行聚类,电力公司便可根据每类用户的电力用能行为提供不同的策略及服务,从而更加科学、合理地实现智能用电.本次采用K-means算法对用户的电力用能行为进行聚类分析.
2.1 K-means聚类
K-means聚类的本质就是簇的划分,簇是对象的集合,且其中每个对象到该簇的距离比到其他簇的距离更近或更为相似.距离的度量通常包括:欧式距离、曼哈顿距离和余弦距离等,因电力用能数据是连续型数据,故采用欧式距离进行度量,即
(1)
式中:c为簇的中心,即簇中所有样本点的平均值,也称为质心;x为簇中的样本点;k为簇的个数.K-means算法流程如下:首先随机选择k个初始质心,计算每个样本点到质心的欧式距离并将其分派到最近的质心中,被分派到同一个质心的样本点集合为一个簇;然后根据每个簇的样本点重新计算均值且更新每个簇的质心;重复分派和更新的步骤,直至簇内不再发生变化或达到最大迭代次数为止.
2.2 评估指标
K-means聚类的核心在于k取值,而k的取值取决于对聚类效果的评估.通常簇内稠密程度越小,簇间的离散程度便越大,聚类效果也相对越优,因此可采用轮廓系数作为K-means聚类效果的评价指标.轮廓系数计算表达式为
(2)
式中:a为样本点与同一簇中其他样本点的平均距离,即簇内相似度;b为样本点与距离最近簇中所有样本点的平均距离,即簇外相似度.轮廓系数的取值范围为[-1,1],该值越接近1表示样本点的簇内相似度越高,且簇外相似度越低,即簇的划分更为合理;越接近-1则表示样本点与簇外样本点的相似度更高,此时k的取值不合理;而当其为0时,代表样本点在两个簇的相似度是一致的,即这两个簇为同一个簇.
3 电力用能行为预测方法
3.1 BP神经网络
BP神经网络是一种信号前向传播、误差反向传播的多层前馈神经网络,其能够有效识别特征之间的非线性关系,因此被广泛应用于电力用能行为的预测中[12].BP神经网络的结构如图2所示.其中输入层为提取的时间序列特征,在第一阶段前向传播时,经过隐含层到达输出层,输出层即为电力负荷预测值;第二阶段误差(真实值与预测值的偏差)反向传播时,传播路径从输出层到隐含层最后到达输入层.在此过程中,权重和偏置的优化顺序为:先优化隐含层到输出层参数,再优化输入层到隐含层参数.依次迭代,直至误差小于某个阈值或达到最大迭代次数停止.
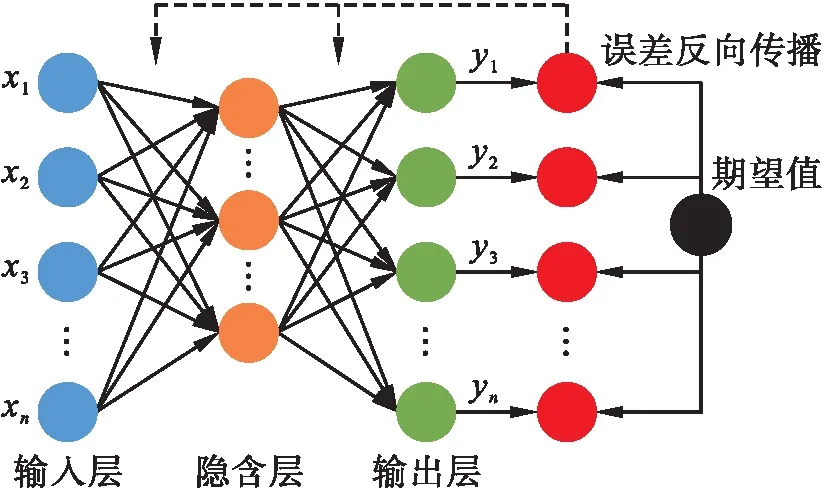
图2 BP神经网络结构图
3.2 基于萤火虫算法的改进网络
BP神经网络的初始化权重和偏置是随机获取的,在迭代过程中易存在局部最优或误差较大的问题.而萤火虫算法[13]作为一种启发式算法,能够有效地对权重和偏置的初始化取值进行优化.该算法的原理是:萤火虫通过闪光吸引其他个体,且吸引力与闪光的亮度(荧光素)成正比.其中亮度低的个体会被亮度高的个体吸引并向其移动,但亮度会随着距离的增加而减小.而萤火虫相互吸引与移动位置的行为,即是在一定范围内搜索最优解的过程.

(3)
式中:ρ为t-1时刻荧光素的比重,取值为(0,1);γ为荧光素的更新率,一般为常数.萤火虫位置更新表达式为
(4)
式中:β为移动步长;dij为萤火虫i和j的欧氏距离.位置的更新受种群中荧光素值高的萤火虫吸引力影响,对于距离较远的个体,其受到的吸引力可能较小,由此便会导致整个空间解缺乏多样性,从而陷入局部最优.文中利用融合粒子群算法(particle swarm optimization,PSO)中的上一次迭代最优位置这一概念,改进萤火虫位置的更新方式,具体表达式为
(5)
式中:Xbest为在上一次迭代中荧光素值最大的个体位置;ξ为上一次迭代最优位置对萤火虫的吸引力占比.式(5)表明上一次迭代中荧光素值最大的个体位置对本次迭代的种群仍具有吸引力,从而进一步平衡了萤火虫的全局与局部寻优能力.位置更新后,决策半径会根据相邻萤火虫的数量进行更新,即
(6)
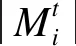
4 实验验证
本文实验数据来源于某地216户2015年7月1日0时0分~8月1日0时0分的电力用能情况,每15 min采集一次,共收集了646 981条数据.由于数据量较大,因此仅展示第一天的数据,如图4所示.实验利用了Anaconda的Python 3.7.3,并结合Jupyter notebook进行分析.

图4 用户电力用能数据
该数据集时间颗粒度为15 min,时间范围为月,因此时间特征设置为日、时数据;均值特征设置为每日及每个小时的平均用电量;布尔特征代表是否为工作日;滑动窗口则采用皮尔森相关系数计算用电量平移1~16个单位时间(每个单位15 min)的相关性,具体如图5所示,数字0表示当前单位时间,1~16分别表示用电量平移1~16个单位时间.皮尔森相关系数大于0.4 表示呈中等程度及以上相关,因此滑动窗口提取了1~8个单位时间.
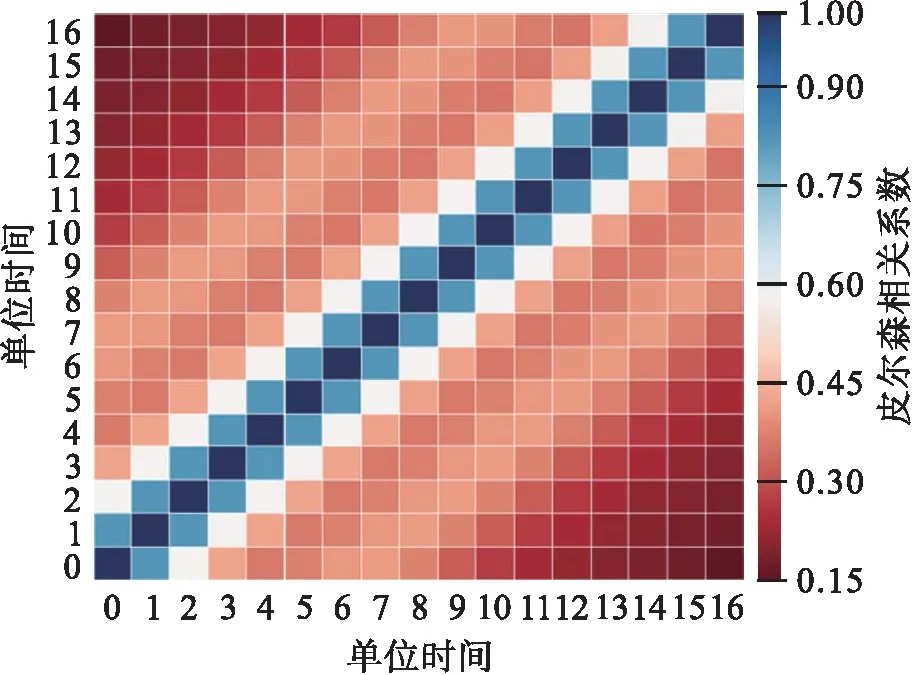
图5 用电量平移1~16个单位时间热力图
根据提取的时间序列特征,采用K-means算法进行聚类,k取值范围为[3,12],计算不同取值的平均轮廓系数,如图6所示.从图6中可看出,当k=3时,轮廓系数最大,因此聚类数量为3组.
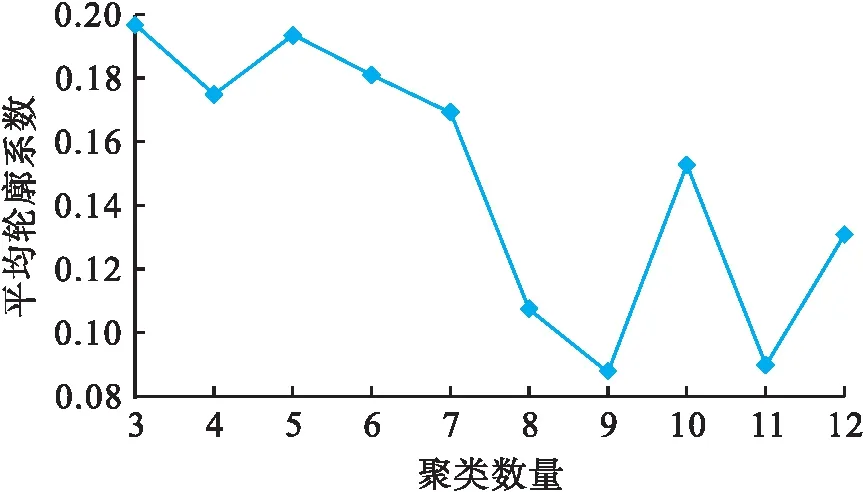
图6 不同聚类数量的平均轮廓系数
按照聚类结果,绘制每类用户的平均电力用能行为曲线,如图7所示.由图7可知:第一类用户的用电量始终维持在较高位置,且峰值电力负荷达到了4.5 kW,最低时段也有约1.5 kW,因此该类用户有可能是小生产商或手工业者,故针对该类用电需求显著的用户,可以提供更为合理的用电服务,以便满足其用电需求;第二类用户的用电量则比第一类用户显著降低,但在夜晚用电量出现明显升高,峰值电力负荷接近2.5 kW,因此可能是普通家庭用电;而第三类用户的用电量始终处于较低的位置,电力负荷维持在0.5~1 kW的范围内,可能是由于仅有普通照明灯需求的场所或已装修的闲置二手房.
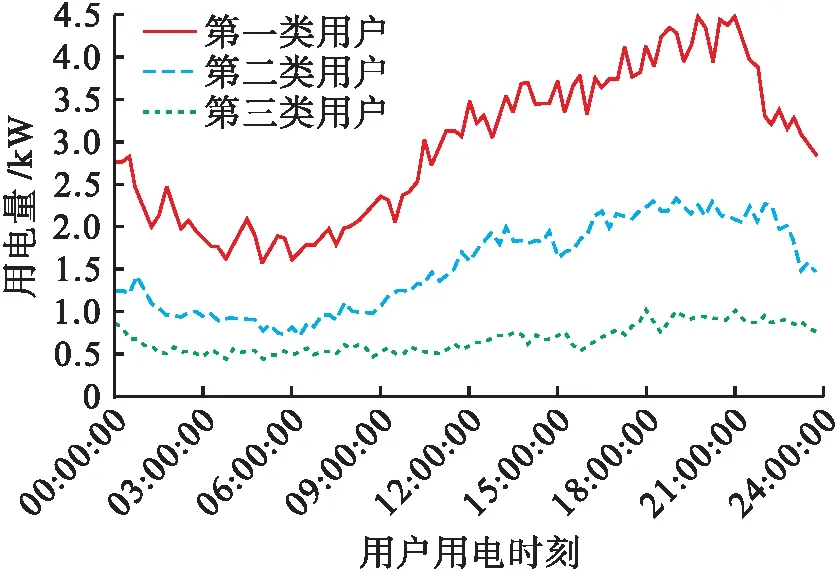
图7 聚类用户平均电力用能行为曲线
此外,还建立了基于萤火虫算法改进BP神经网络的预测模型对每类用户的电力负荷进行预测.因为19∶00~20∶45的电力负荷波动较大,故预测此时间段的8个单位时间负荷值.首先确定萤火虫种群规模,BP神经网络的输入层神经元个数对应时间序列特征为13个,输出层神经元个数对应预测负荷为8个,对应匹配隐含层神经元个数为10个,需要优化的参数个数则为228个,即萤火虫的种群规模为228个.由于萤火虫算法仍处于初级研究阶段,并未具备完整的数学理论基础,因此参数的选择根据经验,并结合网格搜索法进行设定.网格搜索法是指定参数值的一种穷举搜索方法,将估计函数的参数通过交叉验证的方法得到最优参数组合.其中,收敛精度和最大迭代次数可以人为设定,为了避免计算量过大,每次调试两个参数,参数取值具体如表1所示.
将真实值、BP神经网络与萤火虫改进BP神经网络的预测值进行对比,结果如图8所示.两种方法的均方根误差(RMSE)与平均绝对误差百分比(MAPE)结果如表2所示.由图8和表2可以看出,与BP神经网络算法相比,本算法对三类用户用电负荷的预测精度均得到了提升,且根据RMSE与MAPE指标可以看出:第一类用户数值分别下降了0.200 5、1.78%;第二类用户数值降低了0.079 8、1.43%;而第三类用户数值则下降了0.018 5、0.78%.

表2 两种算法的RMSE与MAPE对比

图8 预测结果对比
5 结 论
电力用能行为分析与预测是电网规划中的重要环节,通过对用户用能数据的深度挖掘,可发现用户的电力用能规律,进而提升电力负荷预测的精准性.本文深入分析了用户的电力用能数据,并提取了具有代表性的时间序列特征;同时通过探索不同用户之间特征的相似性,对用户的电力用能行为进行聚合;再针对目前电力用能行为预测模型存在的问题,提出了一种基于萤火虫改进BP神经网络的预测方法.实验结果表明,该预测方法相较于BP神经网络,RMSE与MAPE平均下降了0.099 6和1.33%.然而文中仅将该方法应用于短期电力负荷预测,故具有一定的局限性.在后续研究中,会将所提方法应用于中长期的电力负荷预测,进而不断提升该方法的预测精度及普适性.
猜你喜欢
电子制作(2019年19期)2019-11-23
小天使·一年级语数英综合(2018年7期)2018-09-12
电子测试(2017年15期)2017-12-18
小天使·一年级语数英综合(2017年6期)2017-06-07
雷达学报(2017年6期)2017-03-26
重型机械(2016年1期)2016-03-01
为了孩子(孕0~3岁)(2016年1期)2016-01-16
大连工业大学学报(2015年4期)2015-12-11
小天使·一年级语数英综合(2015年8期)2015-07-06
海军航空大学学报(2015年4期)2015-02-27
