
基于叶片匹配的作物植株图像分离与计数方法
2023-05-24 02:23张连宽肖德琴岑冠军于永浩
江苏大学学报(自然科学版) 2023年3期
张连宽, 肖德琴, 岑冠军, 于永浩
(1.华南农业大学 数学与信息学院, 广东 广州 510642; 2.广西作物病虫害生物学重点实验室, 广西 南宁 530007)
传统大田农作物信息的采集由人工采样方式进行,其检测与分析方法的工作量大、覆盖面积小、效率较低、成本高、专业性强,不能满足现代农业的自动化和智能化生产要求.随着图像采集与传输技术的发展,大田作物图像信息的采集已越来越多地应用于农业生产与科研领域.从图像信息中自动提取单个植株的生长信息,如株高、植株数量、出苗率、种植密度、行距与株距、叶片形态与颜色等信息,从而分析作物的长势,评估病虫害的影响,对大田作物生产的精准化和智能化管理具有重要价值,是当前农业图像领域研究的重要方向.
目前,从大尺度田间图像中提取作物生长宏观信息的报道较多.文献[1]采用无人机采集油菜遥感影像,并用回归分析方法建立油菜株数与其外接矩形长宽比、像素分布密度以及周长栅格数的线性关系.文献[2]先采用彩色分割法去除背景,然后在提取骨架的基础上检测图像角点,以角点个数作为田间玉米株数.文献[3]用无人机采集玉米视频图像,在彩色空间中采用阈值分割法获得玉米苗数量,与人工计数的相关系数达到0.89.文献[4]用无人机采集小麦图像,采用颜色分割法去除小麦背景图像,并用支持向量机识别前景目标来估计作物密度状况.文献[5]将图像采集装置安装在玉米收获机上,采集玉米收割后的留高茬地块视频,用近圆形识别法识别玉米秸秆断面,从而得到玉米植株总数.文献[6]提出了分段垂直投影的水稻秧苗中心线提取方法,准确率达到了94.50%.
以上相关报道主要从大尺度田间图像中估算作物生长的宏观信息,如植株数量、出苗率、叶面积指数等,但是不能提取单个植株生长的微观信息.从大田作物图像中分割出单个植株,并获取植株生长的微观信息,如叶片与果实的大小、纹理与空间分布以及受病虫害损害的程度等,能够构建出准确的作物生长模型[7-8]、获取详细的作物表型信息[9-10]、准确地识别病虫害[11-15],为精准的田间管理提供关键信息.文中拟构建基于叶片匹配的识别算法,从按行连续移动相机采集的近距离作物图像中,分离出单个植株图像,为植株生长微观信息的图像采集提供算法支撑.
1 材料与方法
1.1 材 料
本试验图像采集于华南农业大学教学与实验基地和广东省良种推广总站基地.试验采集生菜、花椰菜、紫甘蓝、青花菜、甘蓝苗期或生长期的图像,连续两株作物叶片距离在8 cm以上.图像采集采用单反相机Cannon EOS 700D(分辨率为5 184×3 456像素)和Apple 7智能手机(分辨率为4 032×3 024像素).选择微风天气,手持相机在作物上部,距离作物20~60 cm,让镜头朝下,连续沿作物行移动拍摄.动态采集图像时相机不需要精心设置位置,具有较大灵活性,表现在以下几个方面:① 手持相机沿着行行走拍摄时,仅大体让相机沿着行作物拍摄,相机的角度不必刻意保持一致,相邻两张照片采集时相机角度可以在一定角度变化(通常小于30°);② 相机与作物距离20~60 cm,在沿着行移动相机时相对于地面的距离也不刻意保持一致,前后照片相较于地面可以相差数厘米;③ 相机也不需要严格沿着作物行中心线移动,可以偏移中心线,只要目标作物包含在采集照片的上下边界内;④ 由于方案采用了拼接技术,为了保证拼接图像的进行,连续两张照片需要有15%重叠部分,除此之外,沿着行采集图像时,采集图像的距离也不需严格保持一致.
1.2 方 法
作物植株的图像提取算法框架如图1所示.

图1 基于叶片匹配的作物植株图像分割算法
首先对采集的图像去除背景中的土壤和杂草等背景,获得作物叶片图像.然后根据叶片距离将图像中每个作物的叶片从图像中分离出来.对单株作物可能会在不同图幅中重复出现的问题,采用基于图像拼接的方法实现图片匹配,获得各株作物在不同图幅中的位置关系.最后,对每株作物,通过匹配关系提取各株作物图像,统计作物株数.
1.2.1去除背景
文中采用了文献[16]方法,首先,通过颜色分割去除非绿色部分(RGB的绿色通道值大于红色通道与蓝色通道值),再通过光滑度去除杂草和噪声.光滑度的公式如下:

(1)
式中:D为一个9×9区域;p为图像某个像素;ψ为彩色图像灰度值函数.不同作物的光滑度不同,通常杂草的光滑度高于叶片的光滑度.图2中第1行是连续采集的5幅番茄苗图像,对应的第2行图像为去除背景后的结果,经过背景去除,原始图像中每株番茄苗的叶片都被很好地从背景中分离出来.

图2 番茄苗图像的背景去除
1.2.2各作物植株叶片的归类
如图2所示,作物的枝茎光滑度差,经过背景去除后,作物图像不仅去除了土壤等背景,也会将枝茎删除掉,仅剩下叶片图像,且一些叶片处于分离状态.株内作物的叶片之间虽然分离,但距离较小,株间作物的叶片距离较远,根据这一特点,设置距离门限(按作物不同株叶片的图像距离设置).若距离小于门限的叶片被认为属于同一株作物,否则被认为属于不同株作物.为分析整株作物状况,图像中采集到某株作物的部分图像(边界部分含有的作物叶片图像)将会被删除,由于是按行连续拍摄,该植株的完整图像将会在其他图像中出现,并被提取出来.通过基于距离的分类处理与边界消除,图2中原始图像里属于各番茄植株的叶片被正确分类,结果如图3所示,图像中植株自左至右编号,用数字表示.

图3 番茄植株叶片的归类
1.2.3作物植株去重与数量统计
连续采集的图像中,同株作物图像可能会在不同图像中出现,因此需要识别出重复的株图像.在图2连续拍摄的5幅图像中,共有8株番茄苗,但实际上是3株番茄苗呈现于不同的图像中,如图3所示.
从图2和3可以看出,在沿作物行连续拍摄采集的作物图像中,同株作物的图像存在如下特征:① 同株作物在不同图幅中的位置不同.由于摄像头可能存在晃动、拍摄角度变化,同株作物在不同图幅中的位置不同,变化规律也不同;② 同株作物只可能出现在连续相邻的2幅或者多幅图像中.如1号番茄出现在a图和b图两幅图中,c图中没有出现,说明从c图开始摄像头已经离开了1号番茄的采集范围,后面拍摄的图像也不会出现1号番茄.
根据上述两个特征,在相邻图幅中检测是否有同株作物,如果有则去重,进而设计了算法1,实现了作物植株的识别与株数的统计.
算法1
Input:
plants in the first image:img11,img12,
…,img1m1;
plants in the second image:img21,img22,
…,img2m2;
…
plants in the last image:imgn1,imgn2,
…,imgnmn
Output: plant amountNplant
fori=2 tondo
forj=1 tomido
fork=1 tomi-1 do
ifimgijis matched withimgi-1,k
Nplant=Nplant;
else
Nplant=Nplant+1;
endif
endfor
endfor
endfor
算法1按拍摄顺序逐幅扫描图像,首先将第1幅图像的株数作为总株数Nplant的初始值,然后对第n+1幅图像中的每株作物,将其与第n幅图像中的各株作物进行匹配,若与第n幅图像中的一个作物植株匹配成功,则Nplant不变,否则将Nplant加1.如图3中b图2号作物,第1次出现在图中,由于与图3中a图的植株没有匹配成功,看作新株作物,Nplant加1,接着在检测c图时,与b图中的1号作物匹配成功,所以Nplant不变,以此类推.因此同一株作物虽然出现在不同的图像中,但识别与计数只进行一次.
相邻图像中相同作物植株的匹配采用图像拼接技术实现.图像拼接就是将数张有重叠部分的图像拼成一幅无缝的大型图像.将连续两幅作物图像拼接成一个图像,由于同株作物的图像属于重叠区域,所以拼接后,同株作物在前后图中的图像会拼接成一株图像.文中采用Matthew Brown的图像拼接方法[17]实现前后连续图的拼接.以图2中的第2、3两幅图(分别表示为imgA和imgB)为例,简述步骤如下:
1)对连续相邻的两幅图,用Harris角点检测算法检测角点,两图分别检验出1 148和1 188个点,见图4中a、b图.

图4 Harris角点检测结果
2)采用自适应非极大抑制方法在两幅图中各选择不多于500个关键点, 见图4中c、d图.
3)对imgA和imgB进行拼接,需要求出imgA中的点pi(xi,yi)与imgB中对应点pi′(x′i,y′i)的投影关系h,h为一个3×3矩阵,投影变换表示为
(2)
用8对匹配点(pi,pi′)能够获得h.SIFT(scale-invariant feature transform)算法对矩阵变换不敏感,噪点污染和光照强弱的变化不会影响其稳定性[18].因此对imgA和imgB的关键点采用了SIFT向量表示其特征,进行匹配,如图5所示.

图5 前后图的图像匹配
在匹配点中,随机取出8对匹配点,计算两幅图像的投影变换矩阵h.对imgA中其余点,用式(2)计算对应坐标,与SIFT的匹配点坐标进行距离比较,估计h的误差.随机进行2 000次这样的匹配验证,获得误差最小的投影变换矩阵h.
4)通过投影变换关系建立一个全景空白画布.两幅图像朝画布进行投影变换,对两幅图像的交叉区域,按照交叉融合的方法(cyber-physical system,CPS)获得全景图像,如图6a所示.

图6 前后图像拼图及各株叶片图像相应变换
从拼接的过程看,同株作物在前后图幅的图像会朝着同一个地方映射,交叉融合拼接成一个作物植株图像.以图6为例,采用如下算法进行单株图像匹配:① 将前后两幅图像采用Matthew Brown图像拼接方法进行拼接,同时根据两个彩色图像充分多的匹配点获得两幅图像的单应性变换h和交叉融合CPS;② 将前一幅图像中的各植株与空图按单应性变换h和交叉融合CPS获得相应的拼接图,如图6b所示.将后一幅图像中的各植株与空图按h和CPS获得相应的拼接图,如图6c所示;③ 提取前后幅图像中的各作物植株,对其进行投影变换,将变换后的图像基于质心欧氏距离的阈值进行匹配,若欧氏距离小于阈值,则认为同一株匹配图像,否则认为不同株图像.
图6b中的2号作物图像与6c中1号作物是同一株作物.由于只对含有一株作物图像做单应性变换,而交叉融合与空图进行变换,图像的亮度有差异,但变换后图像的形状与位置变化不大.6b中的1号作物图像与6c中1号作物不是同一株作物,单应性变换后的图像形状与位置差异大.为了简化计算,仅采用质心中心欧氏距离的方法判定是否为同株作物图像.将行内连续两株作物正常距离的一半作为阈值.当变换后两个图像的质心距离小于阈值时,认为是同一株作物图像,反之被认为是不同株作物的图像.
通过算法1获得作物图像的匹配关系如表1所示.图3中5幅图像植株数量为8,现匹配5对,所以植株数量为3,与实际相符.
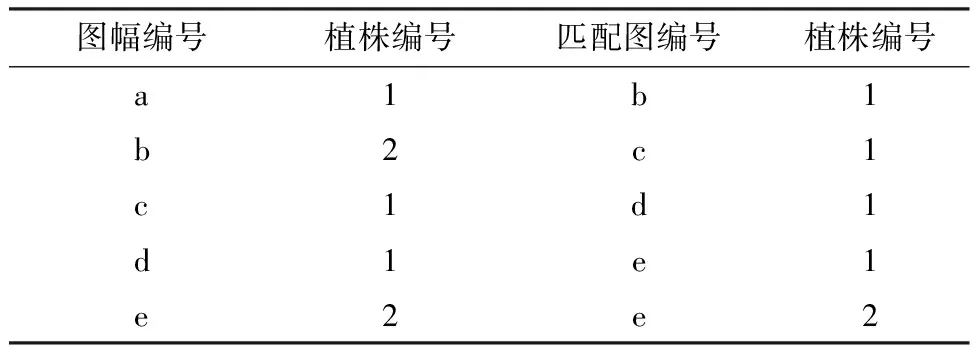
表1 作物叶片图像的匹配表
1.2.4图像中作物植株的提取
A中各株图像之间的匹配表示这些图像采集的同一株作物,显然各株图像的匹配关系满足以下等价性质:① 自反性:任意的x∈A,则x∈A,即x与x匹配;② 对称性:若x与y匹配,即x中的作物与y中作物是采集的同一株作物,则y与x也匹配,即y中的作物与x中作物也是采集的同一株作物;③ 传递性:x与y匹配,y与z匹配,则x与z匹配.
根据相邻两幅图像的匹配关系(如表1所示),将采集的所有植株基于传递性,划分到不同植株的子集.需要将满足等价关系的集合进行划分,获得各植株的划分集合.采用图的传递闭包工具实现.首先将各株作物叶片图像映射为从1开始的数字,如表2所示.
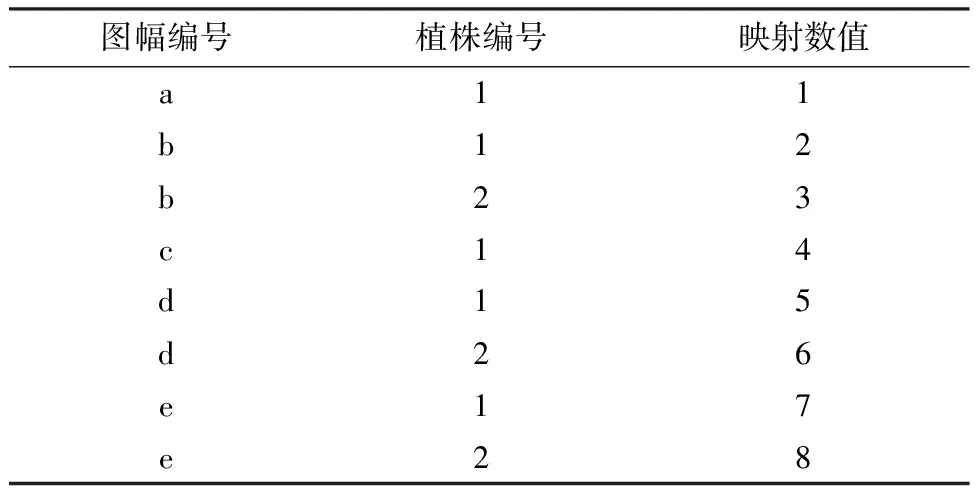
表2 作物叶片图像的映射
则表1的匹配关系用矩阵表示为
(3)
记:M(R2)=M(R)×M(R),M(R3)=M(R2)×
M(R),…,由于M(R2)=M(R4),所有传递闭包关系为
M(t(R))=M(R)∨M(R2)∨M(R3)∨M(R4)∨
(4)
式(4)的传递闭包关系如图7所示,从而得知共有3株作物,第1株标号为1、2;第2株标号为6、8;第3株标号为3、4、5、7.
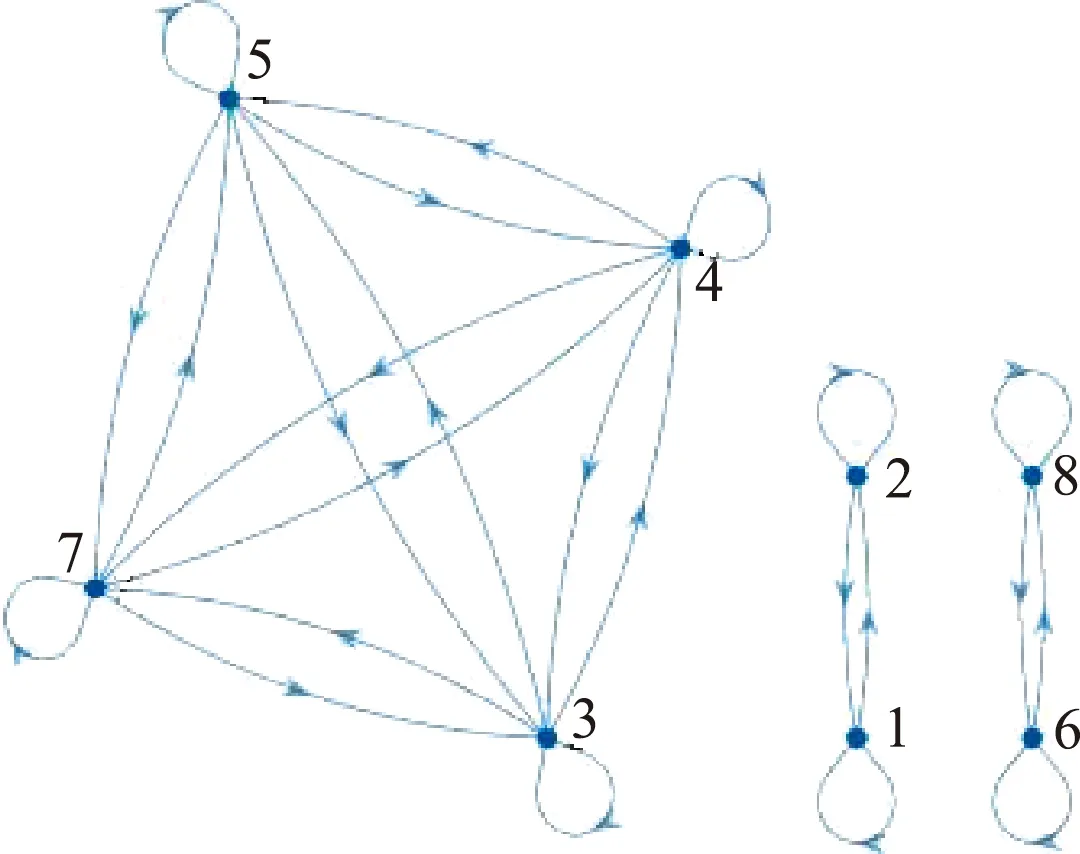
图7 叶片匹配的传递闭包图
在自动对焦采集图像时,当作物植株居于图像中心时,图像质量更清晰,能够识别出更全面的植物信息.因此在获得各株图像序列图的基础上,在每个序列集合中选择最靠近图像中心的图像.计算各子图中作物图像的质心与图幅的中心距离,取距离最小的株图像,并从对应的原始图像中将其区域分割出来(四周加上窄的边界).各株图像的分割结果如图8所示.

图8 各株番茄图像的分割结果
2 结果与分析
大田环境下采集作物图像较为复杂,一方面,机械与人工种植作业受到各种因素的影响,造成植株的相对位置、株间距离存在变化,甚至植株缺失;另一方面,无论用农机携带摄像头、推车携带摄像头还是人工手持摄像头,在复杂田间行走采集作物图像时,不平的地形、机械震动与人的抖动都造成图像采集前后相对位置的变化.因此在试验时,手持相机沿着作物行进行图像采集时不刻意保持相机恒定的高度、采集图像间隔距离等,以反映实际的大田采集状况.
文中基于叶片匹配来分离作物植株图像.颜色分割与光滑度分割后,由于茎、枝光滑度低,分割算法将删除这些部分,使得有些叶片会处于分离状态.因此主要采取叶片距离门限的方法将叶片归为不同株作物中,株间叶片距离较大、株内叶片距离较小时较容易将各株图像分离.株与株之间叶片图像距离较大的分割结果如图9所示,由于株与株之间有明显的距离,算法能够成功地将各株图像分割开来.而图10中,株与株之间有叶片图像重叠,被看作一株作物,产生错误分离结果.

图9 株与株之间叶片图像距离较大的分割结果

图10 株与株之间叶片图像重叠的分割结果
除了株与株粘连或距离过小不适宜本方法,只要株与株有一定的距离,提出的算法具有较强的鲁棒性,分割结果如图11、12所示.虽然图像有较大的角度差,但本算法仍然可以成功分割出5株作物.

图11 角度变化的拼接

图12 角度变化获得的各株作物图像
在株与株叶片存在间距的基础上,对5种作物进行了测试,每种作物连续近距离拍摄了10个种植行.统计了各行作物采集的图像数、图像中总的作物株数,并对各行作物人工统计株数与所提方案的检测株数进行比较,结果如表3所示,株数检测的正确率100%,而且所有行的作物图像提取正确率也达到100%.
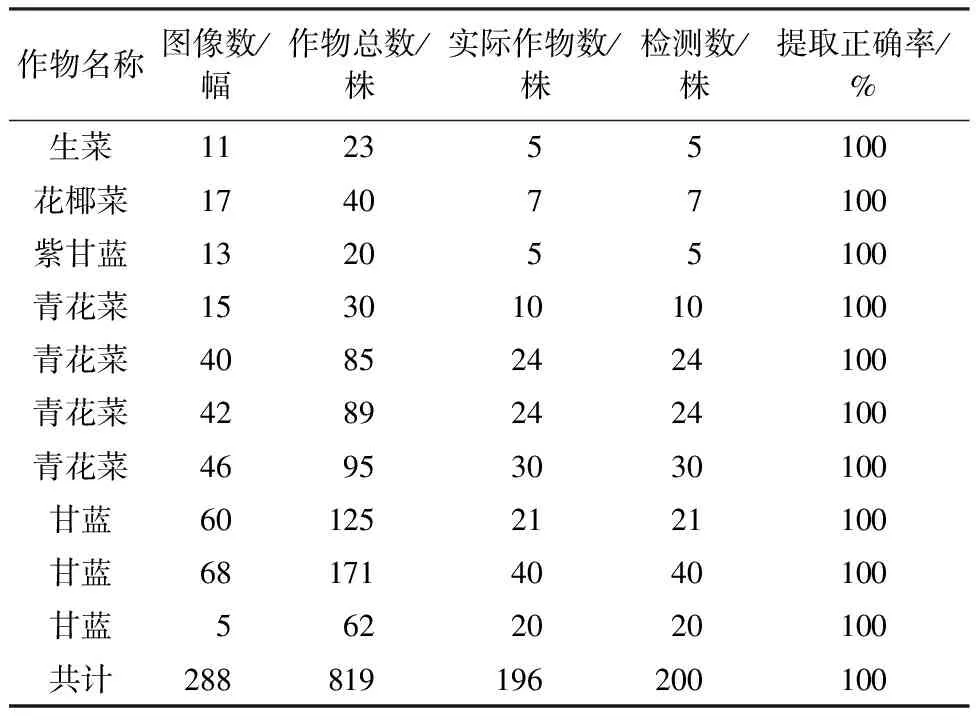
表3 各株作物图像提取正确率
需要指出的是,虽然所提方案主要针对单行进行,但对于多行能够同时覆盖在摄像头内的,只要叶片之间不粘连,所提方案也能够顺利进行.例如表3中第10行,检测结果如图13所示,摄像头一次分别覆盖2行与3行,株数检测与各株图像提取率都达到100%.

图13 图像覆盖多行作物
本算法只需对相邻图像做拼接计算,并不需要将所有图像拼接到一起,因此算法所需的计算资源要求低,运算效率高.以表3第5行为例,其是用相机Cannon采集的一行40幅图像.为了提高效率,先将图像都缩放到原来的20%(分辨率为1 037×692像素).在处理器为Intel Core(TM)i5-6500 CPU内存为8 G的计算机上,40幅图像进行去背景和各株图像分离,用时112.570 0 s,39对相邻图像拼接用时83.663 2 s,采用叶片距离进行相邻匹配计算用时3.748 2 s,生成闭包图并在闭包图中搜索各株作物在图像中的图号与株号用时67.096 5 s,分割各株图像用时1.305 6 s,整个过程约需268 s.
3 结 论
提出了基于叶片图像匹配的方法提取作物植株图像的算法,该算法具有以下特点:① 高正确性.若株与株之间的叶片距离小于株内叶片的空隙距离,所有试验图像的识别正确率都达到了100%,本算法具有较高的正确率.② 低复杂性.提出的算法对计算资源要求较低,株图像匹配采用的拼接算法仅基于前后图像的拼接,不必借助高运算能力的服务器进行整个区域多图长时间拼接计算,仅用普通计算机即可实现.借助于株图像的匹配闭包关系,可以便捷地获得各株图像.
猜你喜欢
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
临床检验杂志(电子版)(2020年1期)2020-04-03
世界农药(2019年4期)2019-12-30
新农民(2019年9期)2019-02-19
上海农业学报(2017年4期)2017-04-10
上海农业学报(2016年2期)2016-10-27
学苑创造·B版(2015年12期)2016-06-23
上海农业学报(2016年5期)2016-02-10
上海农业学报(2016年5期)2016-02-10
