
一种利用网络爬虫技术提高多语种术语库校审效率的方法
2023-05-24 04:51:46刘雯
科技资讯 2023年8期
关键词:网络爬虫
刘雯

摘要:為保障多语种智能翻译系统充分发挥其标准化、快速翻译的作用,必须构建高质量的多语种术语库,不断充实翻译系统的后台词汇。在多语种术语库的构建过程中校审是保证术语库质量的关键环节。然而,与运用数万词条量、甚至体量更为庞大的待校审术语库对比,单纯使用传统的人力校审方式,已经不能满足为智能翻译系统及时扩充术语库的需求。针对上述问题,文章提出了一种网络爬虫技术在多语种术语库校审中的应用方法,并介绍了网络爬虫技术的概念、原理、分类、特点,详细阐述了该技术在多语种术语库校审中的应用实践,最后对网络爬虫技术在翻译和情报专业领域的应用进行了展望。
关键词:网络爬虫 多语种术语库 校审 多语种智能翻译系统
中图分类号:TP393.09 文献标识码:A
A method for Improving the Efficiency of Proofreading Multilingual
Terminology Databases by Using Web Crawler Technology
LIU Wen
(Beijing Institute of Aerospace Information, Beijing, 100854 China)
Abstract: In order to guarantee the multilingual intelligent translation system to give full play to its standardized and fast translation function, it is necessary to build a high-quality multilingual terminology database and continuously enrich the background vocabulary of the translation system. In the process of building the multilingual terminology database, proofreading is the key link to ensure the quality of the terminology database. However, compared with the use of tens of thousands of terms or even a larger volume of the terminology database to be proofread, the simple use of the traditional manual proofreading method can no longer meet the demand for expanding the terminology database in time for the intelligent translation system. In response to the above problems, this paper proposes an application method of web crawler technology in proofreading multilingual terminology databases, introduces the concept, principle, classification and characteristics of web crawler technology, elaborates the application practice of this technology in proofreading multilingual terminology databases, and finally looks forward to the application of web crawler technology in translation and intelligence professional fields.
Key Words: Web crawler; Multilingual terminology database; Proofreading; Multilingual intelligent translation system
在大数据时代,信息采集是一项非常重要的工作,如果单纯靠人力采集信息,不仅效率低,采集成本也很高。为了从海量的网络信息中快速、准确地获取需要的信息,网络爬虫应运而生,其不仅可以抓取网页、提取信息并保存,而且还具有极高的可扩展性[1]。目前,网络爬虫技术已经广泛地应用到众多领域,如金融、医疗、旅游、教育等行业[2]。
1 网络爬虫概述
1.1 网络爬虫的概念
网络爬虫技术是指一种按照一定的规则,自动地抓取互联网信息的程序或是脚本[3]。它作为搜索引擎的信息采集器,是搜索引擎技术的最基础部分,能帮助人们在互联网的海量数据中自动、高效地获取感兴趣的信息[4]。
1.2 网络爬虫的工作原理
网络爬虫通过请求站点上的HTML文档访问某一站点。它爬行Web空间,不断从一个站点移动到另一个站点,自动建立索引,并加入到网页数据库中。当网络爬虫进入某个超级文本时,利用HTML语言的标记结构来搜索信息并获取指向其他超级文本的URL地址,无需用户干预就能实现网络上的自动“爬行”和搜索。
1.3 网络爬虫的分类
网络爬虫按照技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深层网络爬虫等类型[5]。
1.3.1 通用网络爬虫
通用网络爬虫又称为全网爬虫,其爬取的目标资源在全互联网中,主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。其在爬行时采取深度优先、广度优先的策略,适用于某一主题的广泛搜索,一般应用于搜索引擎和大型Web服务商[6]。
1.3.2 聚焦网络爬虫
聚焦网络爬虫根据内容评价、链接结构评价,按照预设的主题,有选择性地爬行[6],可将爬取目标网页定位在与主题相关的页面中,可以节约带宽资源和服务器资源。聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块和链接评价模块能够分别分辨內容和链接的重要性,以确定优先访问哪些页面。聚焦网络爬虫采取的主要策略包括基于内容评价的爬行策略、基于链接评价的爬行策略,基于增强学习的爬行策略和基于语境图的爬行策略。
1.3.3 增量式网络爬虫
增量式网络爬虫在爬行过程中,网页会发生增量式的更新[6]。增量式更新是指在更新的时候只更新改变的地方,未改变的地方不更新。所以,增量式网络爬虫在爬取网页的时候只爬取内容发生变化的网页或新产生的网页,它在一定程度上能够保证所爬取的页面尽可能是新页面。
1.3.4 深层网络爬虫
互联网的网页按照存在方式可以分为表层页面和深层页面。表层页面指的是不需要提交表单、使用静态的链接就能够到达的静态页面;深层页面则隐藏在表单后,不能通过静态链接直接获取,需要提交一定的关键词才能获取得到的页面。在互联网中,深层页面的数量更多,所以我们要想办法爬取深层页面。深层网络爬虫主要由URL列表、LVS列表(填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分构成。深层网络爬虫表单的填写类型分为两种。一种是基于领域知识的表单填写:进行语义分析,获取关键词,提交关键词后,获取Web页面。另一种是基于网络结构分析的表单填写:利用DOM树形式,表示HTML网页。
1.4 网络爬虫的特点
网络爬虫具有高性能、可扩展性、健壮性等特点[7],具体如下。
1.4.1 网络爬虫具有高性能
网络爬虫的高性能是指爬虫的信息抓取速度高。在互联网的海量信息中,爬虫的高性能是保证高效率信息采集的关键因素,通常以爬虫每秒能够下载的网页数量作为性能指标,单位时间能够下载的网页数量越多,爬虫的性能越高。
1.4.2 网络爬虫具有可扩展性
网络爬虫的可扩展性指通过增加抓取服务器和爬虫数量来尽可能缩短抓取周期。单个爬虫的性能虽然很高,但是要将全部网页都下载到本地,仍需要相当长的时间周期,所以网络爬虫的扩展性有利于提高爬虫系统的整体性能。
1.4.3 网络爬虫具有健壮性
爬虫访问的网站服务器类型繁多,所以有时可能会遇到HTML编码不规范、被抓取服务器突然死机等异常情况,为了避免爬虫程序在抓取过程中死掉,或者其所在的服务器宕机,爬虫应该具有一定的健壮性,再次启动爬虫时,能够恢复之前抓取的内容和数据结构,而不是每次都需要把所有工作完全从头做起。
2 多语种术语库的校审问题
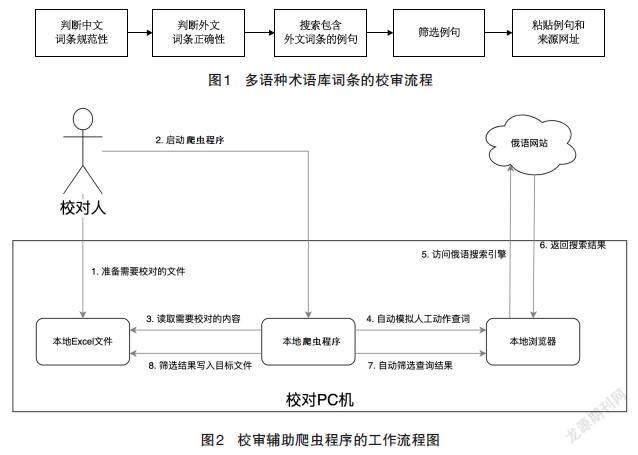
多语种智能翻译系统以术语库和语料库为基础,借助机翻引擎,能够实现快速机器翻译、人机协同翻译等功能,为翻译人员赋能,大幅提高翻译效率。多语种术语库是多语种智能翻译系统的重要组成部分,其为智能翻译系统提供了大规模、强有力的词汇后台支持,是多语种智能翻译系统充分发挥其标准化、快速翻译作用的重要基础。多语种术语库的构建工作包括搜集专业词汇、翻译、校审、入库等环节。为保证多语种术语库的正确性、权威性,术语在入库前必须经过严格的校审程序,这是保证术语库质量的关键环节。术语校审流程如图1。
校审人员在校审术语库时需要在互联网中搜索术语,查找包含术语的文献例句,以验证术语是否正确、地道,并将例句和来源网址粘贴留存,以保证术语验证可溯源。为缩短多语种术语库校审周期,提升多语种术语库建设水平,进一步释放多语种智能翻译系统的效能,必须寻求具有可操作性的实用手段来提高多语种术语词条的校审效率。而网络爬虫就是一个快速得到有效信息的重要手段,我们可以编写辅助术语库校审的网络爬虫程序,实现多语种术语例句和来源网址的自动抓取和汇总。
3 网络爬虫技术在多语种术语库校审中的应用
网络爬虫技术的常规应用场景通常以收集资料为重点,侧重于数量,如搜索引擎场景,可通过深度遍历HTML超链接收集尽可能多的页面。多语种术语库校审场景对术语相关例句的数量要求较低,通常只需要3~5条,但是对术语在例句中的语义准确性和表达地道性要求较高。针对多语种术语库校审工作的特点,下文论述了一种专门的聚焦式爬虫程序——校审辅助爬虫程序。
3.1 校审辅助爬虫程序的应用对象
文章将俄语专业技术术语库作为校审辅助爬虫程序的应用对象。俄语专业技术术语库的全部俄文术语词条已经翻译完毕,进入正式入库前的校审环节,剩余待校审词条量为61 385条。
3.2 校审辅助爬虫程序的数据来源
俄文搜索引擎yandex中的网页信息。
3.3 校审辅助爬虫程序的工作流程
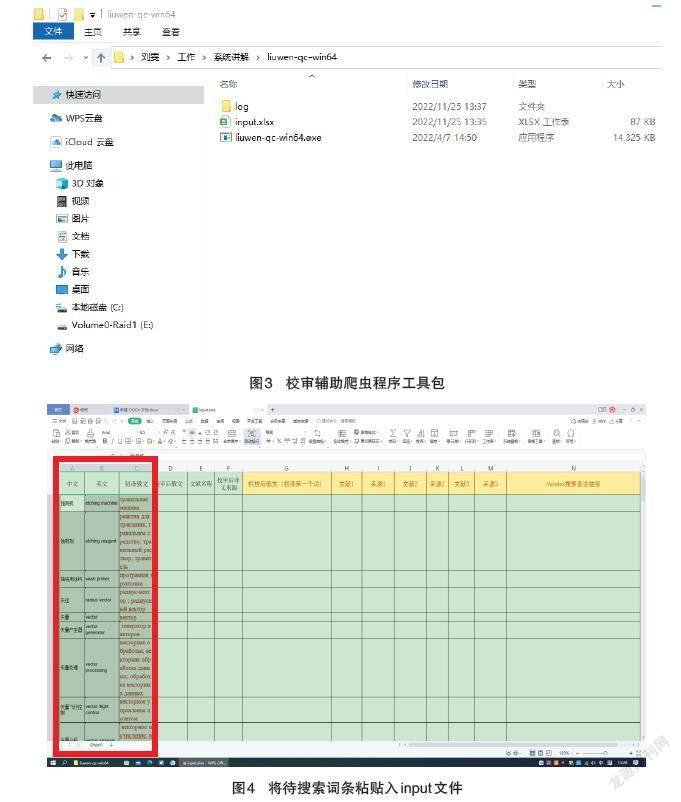
校审辅助爬虫程序使用开发语言go1.17.5,它能够解析校审人员提供的包含待校审术语的Excel文件,从约定的位置提取需要校审的术语词条,然后模拟校审人员的操作习惯,自动打开本地运行的浏览器,使用搜索引擎查询目标术语,将搜索引擎送回的前三条非广告搜索结果采集并录入到校审人员使用的Excel文件中,最终生成包含术语例句和例句来源网址的汇总Excel文件。爬虫程序可以对复制词条、搜索词条、抓取例句、粘贴例句和来源网址等机械性重复劳动进行自动化批量操作,校审人员只需在生成的文件中筛选例句,从而简化校审环节,提高了校审的效率。以俄语专业技术术语库为例的校审辅助爬虫程序的工作流程如图2。
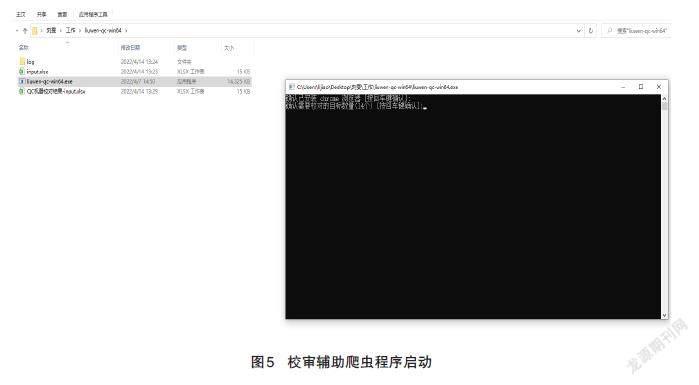
在使用校审辅助爬虫程序时,校审人员需要将待查验的术语词条粘贴进input文件里的相应位置(见图4),一次可以粘贴至少200条术语。
校审辅助爬虫程序的运行流程和关键代码逻辑如下。
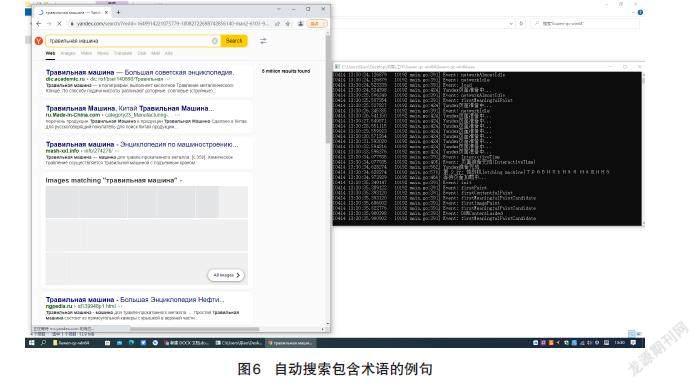
第一,双击启动校审辅助爬虫程序(见图5),程序开始解析包含俄语专业技术术语的Excel文件。
// 準备输入文件解析引擎
parseEngine, err := parser.NewExcelParseEngine(ctx)
if err != nil {
utils.FatalReport(fmt.Errorf("init ExcelParseEngine fail fail: err=%v", err)) os.Exit(-1)
}
俄语专业技术术语词条的解析引擎的接口设计:
type TargetWord struct {
OriginalChinese string //中文原文
CandidatesRussian string //候选的初译俄文:分隔符号支持三种(/;,) QcSelectedRussian string //QC选中的俄语译问:初译俄文的第一个词 QcReferRussianTexts []string //QC获取的参考文献:yandex 搜索结果的摘要 QcReferRussianLinks []string //QC获取的文献链接:yandex 搜索结果的链接 QcReferYandexSearchLink string //QC使用的Yandex搜索地址
}
type ParseEngine interface {
ParseTargetWords(inputFile, sheet string) ([]*TargetWord, error)
}
func NewExcelParseEngine(ctx context.Context) (*ExcelParseEngine, error) {
return &ExcelParseEngine{ctx: ctx}, nil
}
第二,初始化网站。
// 准备术语词条搜索引擎
searchEngine, err := search.NewYandexSearchEngine(ctx)
if err != nil {
utils.FatalReport(fmt.Errorf("NewYandexSearchEngine fail: err=%v", err)) os.Exit(-1)
}
俄语搜索引擎yandex的接口设计:
type SearchEngine interface {
Prepare(resetPageStat func(), isInteractiveTime func() bool) chromedp.Tasks SearchWord(targetWord *parser.TargetWord, abstracts *[]string, absLinksAttr *[]map[string]string,
resetPageStat func(), waitPageFinished func(duration time.Duration)) chromedp.Tasks
}
func NewDefaultSearchEngine(ctx context.Context) (SearchEngine, error) { return NewYandexSearchEngine(ctx)
}
func NewYandexSearchEngine(ctx context.Context) (*YandexSearchEngine, error){
return &YandexSearchEngine{ctx: ctx}, nil
}
第三,爬虫程序执行搜索动作,搜索包含术语的例句(见图6),提取搜索结果,生成包含术语例句和例句来源网址的Excel文件(见图7)。
// 执行 QC 校对任务
go Execute(InputExcelFile, InputExcelSheet, parseEngine, searchEngine, outputFileHandler, signalChan)
// QC校对任务执行
func Execute(fileName, sheetName string, parseEngine parser.ParseEngine, searchEngine search.SearchEngine,
outputFileHandler *excelize.File, signalChan chan os.Signal) {
var err error
var input string
// 设置QC任务执行标记
if err = utils.MarkExecuteStat(outputFileHandler); err != nil {
utils.FatalReport(fmt.Errorf("MarkExecuteStat fail: err=%v", err))
os.Exit(-1)
}
// 程序退出時取消QC任务标记
defer func() {
if err = utils.UnMarkExecuteStat(outputFileHandler); err != nil {
utils.FatalReport(fmt.Errorf("UnMarkExecuteStat fail: err=%v", err))
os.Exit(-1)
}
}()
// 解析输入文件中的目标词汇
targetWords, err := parseEngine.ParseTargetWords(fileName, sheetName)
if err != nil {
utils.FatalReport(fmt.Errorf("ParseTargetWords fail: err=%v", err))
os.Exit(-1)
}
// 初始化浏览器
taskCtx, taskCancel := utils.InitChromeCtx()
defer taskCancel()
fmt.Printf("确认已安装 chrome 浏览器 [按回车键确认]:")
_, _ = fmt.Scanf("%s", &input)
fmt.Printf("确认需要校对的目标数量(%d个) [按回车键确认]:", len(targetWords))
_, _ = fmt.Scanf("%s", &input)
chromedp.ListenTarget(taskCtx, utils.TargetEvent)
glog.Infof("Yandex准备中...")
……(过程代码省略)
//获取搜索结果页地址
chromedp.Location(&targetWord.QcReferYandexSearchLink),
//获取首页结果地址
chromedp.AttributesAll(resultLinkSel, absLinksAttr, chromedp.ByQueryAll, chromedp.AtLeast(0)),
//获取首页结果摘要 chromedp.Evaluate(resultTextSelFunc, abstracts),
}}
3.4 校审辅助爬虫程序的效果和特点
文章选取了200个术语词条,分别计算了纯人工校审所需的时间和使用爬虫程序辅助校审所需的时间。结果显示,在校审环节完成一次“从校审表里复制词条→在互联网中搜索词条→复制词条例句→在校审表中粘贴例句和来源网址”的操作,纯人工平均用时为30 s,应用校审辅助爬虫程序后,批量抓取200条词条需要约15 min,完成一次上述操作仅需要约5 s,搜索术语、摘取例句并粘贴例句和来源网址的时间大幅缩减。而且,爬虫抓取例句的精准度较好,校审人员从抓取结果中基本上能筛选出合适的例句,但在术语翻译错误的情况下可能出现人工重新搜索的情况。可见,校审辅助爬虫程序可以大幅降低校审的操作时间,其例句抓取精准度受术语词条翻译质量的影响,对于翻译正确的术语可以实现准确的例句抓取。此外,校审辅助爬虫程序还有以下特点。
3.4.1 支持多语种术语校审
校审辅助爬虫程序支持英语、法语和俄语术语例句的搜索和抓取,根据不同语种,校审辅助爬虫程序将启动该语种的主流搜索引擎进行搜索。例如:搜索俄语术语时启动俄语的主流搜索引擎yandex(https://ya.ru/),搜索英语术语时启动英语的主流搜索引擎Google(https://www.google.cn/),搜索法语时启动法语的主流搜索引擎Yahoo(http://search.yahoo.com)。此外,校审辅助爬虫程序具有扩展性,可按需要增加其他语种术语的搜索功能。
3.4.2 适应反爬虫机制
针对目前互联网的反爬虫机制,校审辅助爬虫程序设置了随机等待时间,这使爬虫的运行更像人的操作,在一定程度上降低了人工验证非机器人行为的频率,保证了程序运行的流畅性。
3.4.3 自动跳过敏感词
在校审辅助爬虫程序的实践应用过程中,由于正值俄乌冲突局势紧张时期,俄语专业技术术语库中的某些词条成为了敏感词,在俄文搜索引擎中的查询结果为空白页,此种情况出现时,程序运行中斷。鉴于该情况,爬虫程序中增加了自动跳过敏感词的搜索功能,防止出现卡顿现象。
3.4.4 具有一键搜索功能
在生成的例句和网址汇总文件中,设置了搜索直达链接功能。如果校审人员在自动搜索给出的3个例句中没有找到合适的例句,可以点击该链接,自动打开对应的搜索引擎,实现一键搜索术语,节约搜索时间。
4 结语
文章从多语种术语库的校审问题入手,以俄语专业技术术语库为例,详细介绍、分析了网络爬虫技术在多语种术语库校审中的应用方法,展示了网络爬虫技术从海量信息里获取有效信息的能力和优势。作为一种强大的信息搜集工具,爬虫技术在翻译专业和情报专业领域有很大的应用潜力。在翻译专业方面,爬虫技术的应用可以替代人工语料搜集,从广度和精确度上提升语料库的建设水平。在情报专业方面,可以将爬虫技术和AI技术结合,爬取关键情报信息,自动分析并生成情报信息简讯,高效地为情报研究工作提供可参考的信息资料。
参考文献
[1] 郑苗.基于网络爬虫的北京市房价研究[D].荆州:长江大学,2018.
[2] 郑鑫臻,吴韶波.基于网络爬虫技术的时令旅游信息获取[J].物联网技术,2018(5):83-87.
[3] 顾勤.网络爬虫技术原理及其应用研究[J].信息与电脑(理论版),2021(4):174-176.
[4] 缪治.网络爬虫技术的研究与实现[J].中国新通信,2019(6):70.
[5] 傅一平.详解4种类型的爬虫技术[J].计算机与网络,2021(6):37-38.
[6] 李文华.解析网络爬虫技术原理[J].福建电脑,2021(1):95-96.
[7] Kevin.网络爬虫技术原理[J].计算机与网络,2018(10):38-39.
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24 13:09:39
电脑知识与技术(2017年1期)2017-03-24 11:47:34
计算机时代(2017年2期)2017-03-06 20:40:01
中国新技术新产品(2017年4期)2017-03-04 09:04:39
中国新通信(2016年21期)2017-01-06 13:36:11
电脑知识与技术(2016年20期)2016-08-19 19:30:39
电脑知识与技术(2016年17期)2016-07-23 19:00:29
中国市场(2016年23期)2016-07-05 04:35:08
科技经济市场(2016年2期)2016-06-16 15:37:25
电脑知识与技术(2016年7期)2016-05-19 14:02:36
