
基于分布式的农业信息检索系统的设计与实现
2017-03-24 13:09靳晟李永可李悦陈燕红
电脑知识与技术 2017年1期
关键词:网络爬虫
靳晟+李永可+李悦+陈燕红


摘要:垂直信息检索是针对某一行业的专业检索技术,为用户提供高相关度信息检索服务。本文通过对分布式系统hadoop、搜索引擎、分布式数据库、倒排索引等技术的研究,开发设计了分布式农业信息检索系统,为用户提供专业的农业信息检索服务。系统主要包括分布式平台模块,分布式网络采集器模块,分布式检索系统等模块。
关键词:分布式平台;网络爬虫;分布式检索
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)01-0237-02
随着信息技术的飞速发展,互联网数据资源呈爆炸式增长,互联网数据的快速增长虽然满足了我们日益增长的信息需求,但对信息检索技术也提出了挑战,如何在大规模的数据集中快速检索出用户需要的有价值信息成为当前研究的热点。全文检索针对范围广,返回检索结果往往涉及各个方面知识,而用户真正关心领域的知识可能不多或者排在了检索结果后面,这给用户从检索结果中挑选自己需要的结果带来了一定的困难,而垂直检索只是针对某一领域的专业检索,检索范围只针对该领域,返回结果不多,但都是用户关心领域的结果,和传统全文搜索引擎相比,垂直搜索引擎更能满足用户信息检索需求。
1 系统总体设计及结构
分布式农业搜索引擎首先要解决单机环境下数据采集效率低、存储难以扩充等问题,分步式系统是解决这些问题的完美方案,本系统采用Hadoop的HDFS作为分布式搜索引擎底层文件系统,解决了分布式存储和检索问题,使用nutch作为数据采集器,负责网络数据的采集,使用Solr作为检索器,本系统主要包括信息采集模块、倒排索引模块、信息检索模块、HDFS系统等四大部分组成,系统结构图如图1。
2 分布式农业信息采集子系统
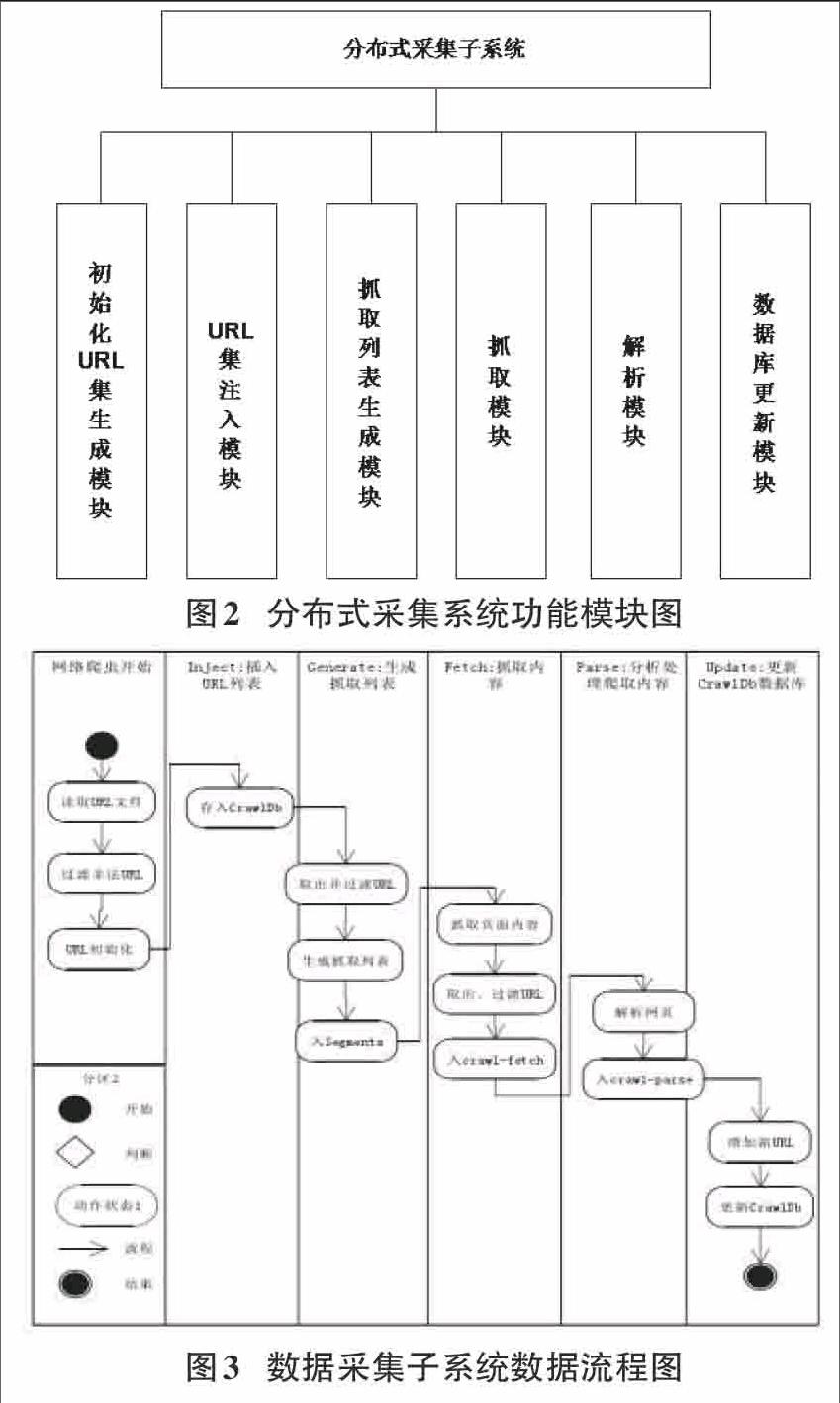
分布式农业信息采集子系统主要负责从互联网抓取指定站点的农业信息,该模块维护有一张农业种子网站列表,目前在该列表中有3000个农业网站,该模块采用分布式采集技术,底层分布式系统采用Hadoop2.4版本,网络爬虫使用nutch2.3,分布式数据库使用HBase0.94,采用分布式架构不但大大提高了数据采集效率,而且使系统具有高伸缩性,当数据采集节点不够时可方便向集群中添加新的采集节点。数据采集模块是搜索引擎设计的基础,该模块为搜索引擎提供源源不断的数据源,分布式数据采集系统功能模块图如图2所示。
网络爬虫从种子列表开始,逐级解析网页中出现的url链接,本系统采取广度优先算法进行网页抓取,直到网络爬虫采集到系统设定级数时才停止采集,数据采集采用增量更新原则,确保采集过的网页没有发生变化时不再重新采集,提高采集效率降低磁盘冗余。数据采集流程如图3所示。
采集模块从URL种子列表开始,首先读取完整的的url地址信息,检验url有效性,删除无效url地址,将有效url地址注入CrawDb库中,注入CrawDb库后,Generate模块从该库中提取出所有url并按指定规则进行过滤,之后生成FetchList待采集列表,并将此列表写进Segments目录中;根据Fetchlist列表,Fetch模块按广度优先算法依次抓取网页信息并保存在本地的crawl-fetch目录下;根据采集到的网页数据,Parse模块对数据进行解析并将解析后的完整数据保存至crawl-parse目录下;根据Fetch模块和Parse模块采集到的数据Updata模块对已采集到的数据进行增量更新。
3 分布式索引子系统
分布式索引模块将分布式采集模块采集到的数据建立倒排索引,为分布式检索系统提供检索服务支撑,分布式索引系统使用lucene4.1设计实现,分布式检索系统结构如图4所示。
索引模块将对采集模块采集到的数据进行文档解析、语义分析、词法分析、分词、相关度评分等操作,经这些处理后最终建立倒排索引文件。任务调度器JobTracher会协调各Slave节点采用MapReduce算法建立倒排索引文件,并在本地HDFS服务器进行存储,为检索系统提供分布式检索支撑。
4 分布式检索模块
分布式检索模块为用户提供分布式检索服务,分布式检索模块依据MapReduce算法设计,对Lucene4.10和solr4.10进行二次开发设计用户检索接口,为用户提供检索界面和检索服务,分布检索模块系统结构如图5所示。
分布式检索服务器根据IPC(Inter-Process Communication)通信规则向分布式系统中各子节点分发检索请求,各检索子节点根据检索请求从本地索引中检索并将检索结果反馈给检索服务器,检索服务器将反馈会的结果进行处理后反馈给用户,分布式检索对检索语句进行词法分析、语法分析、分词、去停用词等处理,然后从倒排索引中进行关键词检索,然后对检索结果进行相關性排序并将关键词进行高亮显示,最后将排序后的结果反馈给检索用户。
5 总结
通过对分布式系统、搜索引擎技术、倒排索引技术、MapReduce技术的深入研究,开发设计了基于分布式平台的农业垂直搜索引擎,系统具有高扩展性和稳定性,为用户提供了高相关度的信息检索服务,满足了用户的基本信息检索需求,后期系统将进行数据清洗技术的研究,对采集到的数据进行相识度分析,过滤重复页面,为用户提供更加友好、高质量的信息检索服务。
参考文献:
[1] 崔杰,李陶深,兰红星. 基于Hadoop的海量数据存储平台设计与开发[J]. 计算机研究与发展,2012,49(s1):12-18.
[2] 许丞,刘洪,谭良. Hadoop云平台的一种新的任务调度和监控机制[J]. 计算机科学,2013,40(1):112-117.
[3] 朱珠. 基于Hadoop的海量数据处理模型研究和应用[M].北京:北京邮电大学,2008.
[4] 郑晓薇,项明. 基于节点能力的Hadoop集群任务自适应调度方法[J]. 计算机研究与发展,2014(3):618-626.
[5] 詹恒飞,杨岳湘. Nutch分布式网络爬虫研究与优化[J]. 计算机科学与探索,2011,5(1):68-74.
