
基于二进制蜉蝣优化的特征选择及文本聚类算法
2023-05-21 04:02:44高新成周中雨王莉利邵国铭
吉林大学学报(理学版) 2023年3期
高新成,周中雨,王莉利,邵国铭,张 强
(1.东北石油大学 现代教育技术中心,黑龙江 大庆 163318; 2.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
文本聚类是将给定对象的集合划分为不同子集的过程,目标是使每个子集内部的元素尽量相似,不同子集间的元素尽量迥异,其在文本挖掘中应用广泛.空间矢量模型VSM(vector space model)是文本数据挖掘的常用模型,其通过把词条变成一维空间向量便于进行空间向量计算.因此,聚类效果主要受特征维度[1]大小和冗余特征的影响,文本特征中存在冗余特征,无监督特征选择是选取非冗余特征,使聚类效果得到明显提升.
传统的特征选择方式有文档频率DF、互信息MI、卡方检验CHI和信息增益,这些方式均存在局限性且特征选择后的精度较低问题.目前特征选择的目标有两个: 一是基于特征选择后聚类效果得到提升; 二是如何获得最多有用的文本特征[2-3].因此,本文设计一种基于二进制蜉蝣算法优化的特征选择及文本聚类算法,首先对文本特征进行选择,选择出最优子集并把特征选择的最优解作为K-means++算法的输入,得到最优的聚类效果.
目前已有的特征选择方法主要有3种: 过滤法、嵌入法和封装法.过滤法是一种基于数学的统计方法,其特征选择方法与后面的模型训练分开,聚类效果较差; 嵌入法是将学习器训练过程与特征选择过程融为一体,二者在同一优化过程中完成,在学习器训练过程中自动进行特征选择[4],但参数设置需要较深的背景知识,不利于实际推广; 封装法利用搜索策略寻找优质特征子集,并基于学习算法得到优质特征子集,是直接面向算法优化,不需要太多的知识,也是最常用的特征选择方法.
元启发式算法已广泛应用于最优化问题求解中,且已被应用到文本挖掘领域中特征选择的求解问题[5-6],主要包括一些智能优化算法,如蚁群算法、遗传算法、粒子群优化算法、野草算法等.这类问题通过迭代的方式不断去搜索最优解.刘占峰等[7]提出了一种基于粒子群优化的模糊粗糙集和实例联合选择算法,算法用于特征和实例联合选择任务中识别高质量的模糊粗糙双约简集,通过ε-双约简的适应度函数评估约简集的质量,并把粒子群算法用于搜索过程中,实现特征的约减与精准分类; Chen等[8]用混沌蚁狮算法与特征选择模型结合并对文本特征进行筛选,在11个基准函数上利用3个文本数据集和其他4种分类算法比较,该方法能减少文本特征,具有较好的分类效果; 张阳等[9]提出了一种基于Word2Vec词嵌入和高维生物基因选择遗传算法的文本特征选择方法,对高维词向量模拟基因表达方式进行迭代进化,用Word2vec把文本转换成基因的词向量,最后基于遗传算法搜索策略,在特征缩减率和文本聚类精度方面性能良好; Mahdieh等[10]提出了一种多目标相对判别准则(MORDC),平衡了最小冗余特征及与目标最大相关的特征,并采用多目标进化框架,通过解空间进行搜索文本特征,该方法具有较好的分类性能; 王琛等[11]把灰狼寻找食物的过程模拟成特征选择的过程,对特征子集合并然后交叉,选出最优的子集,最后得到特征子集与多目标的K-means算法进行融合,经多方面评估性能良好.因此,元启发式算法在缩减特征数量与优质特征选择上效果较好,但以上早期的智能群体算法寻优能力不强,且收敛速度较慢,与过滤的方法相结合效果也不明显.而蜉蝣算法(mayfly algorithm,MA)是一种结合粒子群优化算法(particle swarm optimization,PSO)[12]、遗传算法(genetic algorithm,GA)[13]、萤火虫算法(firefly algorithm,FA)[14]等优点的群体智能优化算法,具有极强的寻优能力,但受限于解决连续型问题.因此,本文将传统蜉蝣算法改进为解决离散型问题的蜉蝣优化算法,即二进制蜉蝣优化算法(MOMA).该算法对传统二进制位置更新公式进行改进,克服了局部寻优能力弱的缺点,并提出新的交配与变异操作,提高了全局寻优能力.
1 算法设计
为更好实现聚类效果,本文首先利用二进制蜉蝣优化算法对文本特征进行选择,获得去除冗余特征的最优子集,然后在最优特征子集上进行聚类分析.算法过程分3个阶段: 第一阶段构建向量空间模型,其中涉及必要的文本预处理步骤; 第二阶段用二进制蜉蝣优化算法对特征进行选择,得到初始的信息化特征子集; 第三阶段在最优特征子集的基础上[15],利用文本聚类算法K-means++进行聚类,得到文档最终聚类效果.
1.1 构建空间向量模型
构建空间向量模型主要分4步: 1) 分词,根据空格和标点符号把文本和文档分割成词语和词条,并移除空格; 2) 去除停用词,去除小权重、高频率词语,如果这些词语存在于文档中将会影响聚类的结果; 3) 提取词干,去除词汇的前缀和后缀,转换为相同词根,并将相同词定义为一个特征,该步骤可进行提词器操作; 4) 计算文本词条权重,当词条在不同文档中的频率较高时,可利用该词区分文档内容,且词条应被赋予更高的权重值.目前,应用的主要词条权重计算方法为统计分析算法中的逆文档频率指数TF-IDF方法,计算公式为

(1)
其中wi,j为文档i中词条j的权重,TF(i,j)为文档i中词条j的频率,IDF(i,j)为倒数文档频率,n为文档数量,DF(j)为包括特征j的文档数量.构造空间向量模型VSM如下:

(2)
1.2 基于二进制蜉蝣优化算法的特征选择策略
1.2.1 特征选择模型
特征选择的目标是选出具有明显区分性的样本特征,而文本特征选择就是选出代表文档主要含义的特征词.假设给定文本特征集合为F,表示为Fi={fi,1,fi,2,…,fi,j,…,fi,t},其中t表示预处理后唯一文本特征数量,i为文档数量.FS经过特征选择算法选择后选出新的特征子集FSi={fsi,1,fsi,2,fsi,j,…,fsi,m},其中m为选择后的特征长度,fsi,j∈{1,0},j=1,2,…,m.若fsi,j=1,则表明文档中所选特征j为优质特征; 若fsi,j=0,则表明文档中所选特征j为无用特征.
1.2.2 解表示
在用二进制蜉蝣算法对文本特征进行选择过程中,每个雄雌蜉蝣的位置代表一个特征文档的子集,如表1所示.蜉蝣种群包括蜉蝣的位置集合,其中位置集合由二进制0或1表示,每个蜉蝣的位置表示文档是否选择其特征.蜉蝣第j个位置表示文档第j个特征的位置.

表1 特征选择的解表示
该算法从随机解开始搜索,不断地选择高质量的特征并改进蜉蝣种群总体以获得全局最优解,最优蜉蝣的位置表示最优解和新文档的子集.在给定的数据集中,每个特征都被视为一个搜索空间.表1中假设蜉蝣位置值为1,则表示该位置的特征为信息特征; 蜉蝣位置值是0,则表示特征j会被选择为非信息特征.
1.2.3 适应度函数
适应度函数用于评价算法的候选解,每一代都要计算候选解的适应度值.若解的适应度值较大,则该解用于替换当前较小适应度值的解.平方误差(MAD)是特征选择领域常用的度量方式,本文使用MAD作为特征选择的适应度函数,并作为评判蜉蝣位置的目标函数.MAD可由均值与Xi,j的中值之差表示:

(3)

(4)

1.3 二进制蜉蝣优化算法
受蜉蝣生物活动启发,Zervoudakis等[16]提出了蜉蝣算法,每只蜉蝣在搜索空间中的位置表示问题的解.算法工作原理: 随机产生两组蜉蝣种群,其中分别表示雄性和雌性蜉蝣种群.每只蜉蝣被随机放置在问题空间中,作为由d维向量表示的候选解x=(x1,x2,…,xd),并结合目标函数f(x)对其性能进行评估.蜉蝣的速度v=(v1,v2,…,vd)定义为其位置的变化,每只蜉蝣的飞行方向是个体和社会飞行经验的动态交互作用.每只蜉蝣都会调整自己的轨迹,使其向个人最佳位置(pbest)以及整个过程中蜉蝣所获得的最佳位置(gbest)飞行.算法伪代码如下:
算法1蜉蝣优化算法特征选择算法MA.
Initializing the male mayfly populationxi(i=1,2,…,N) and speedvmi//初始化雄蜉蝣种群位置及速度
Initializing the female mayfly populationyi(i=1,2,…,M) and speedvFi//初始化雌蜉蝣种群位置及速度
Evaluate the fitness values of each mayfly//评估每只蜉蝣的适应度
Find the global optimal solutiongbest//发现全局最好的蜉蝣位置
Do While the termination criteria are not met//为满足终止规则
Update male and female mayfly speed reconciliation//更新雄性和雌性蜉蝣的速度和位置
Evaluation of solution//评估解
Mayflies sorting//蜉蝣排序
Mayflies mate//蜉蝣交配
Evaluation of offspring//评估子代
Randomly divide the offspring into male and female//随机将子代分为雄性与雌性
Updatepbestandgbest//更新全局最优解与蜉蝣历史位置最优解
End while.
每只蜉蝣位置表示的候选解通过式(3)定义的适应度函数进行评估.在MA算法中,解包含单个实体(特征),且算法不断对蜉蝣位置进行评估.蜉蝣当前的位置按适应度函数进行评估,全局最好的蜉蝣由自身速度更新位置,其余雄蜉蝣按全局最好位置和历史最佳位置更新位置,而雌蜉蝣由雄蜉蝣位置更新速度与方向.直到取得表示问题最优解的蜉蝣位置.
二进制蜉蝣个体更新策略如下: 雄蜉蝣位置更新公式为

(5)
雄蜉蝣移动速率更新公式为

(6)
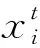
实际上,为繁衍雌蜉蝣会一直向雄蜉蝣运动,吸引过程取决于解的质量,雌蜉蝣的位置更新公式为

(7)
速度更新公式为
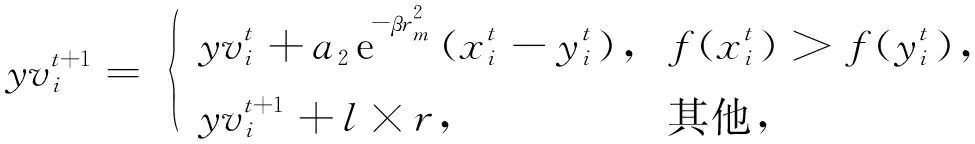
(8)
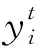
针对传统蜉蝣算法仅解决连续性问题,不适用于特征选择的离散性问题,本文借鉴刘建华等[18]提出的基于改进二进制粒子群算法的优化思路,在保持速度公式不变的前提下,对雄雌蜉蝣的速度概率映射函数进行重新定义,表示为

(9)

图1 映射概率函数值Fig.1 Mapping probability function values


(10)


(11)

由于最初雄蜉蝣位置的舞蹈系数d很大,导致映射的概率很大,因此位置改变概率也会变大,这种情况下,最优雄蜉蝣位置容易变化,可增强算法全局的搜索能力.随着迭代次数的增加,最优的雄蜉蝣速度逐渐变小,位置变化概率也会变小,此时全局搜索能力变弱,局部探测能力变强.对于非最优雄蜉蝣,速度的更新是由最优位置和历史最优位置决定的.当速度为0时,最优蜉蝣和历史最优位置相等,位置一般不需要改变.当速度为负时,利用式(10)进行位置更新,此时最优雄蜉蝣位置和历史最优位置很可能为0,雄蜉蝣的位置很可能为1,因此位置需大概率变为0.当速度为正时,利用式(11)对位置进行更新,此时最优雄蜉蝣位置可能为1,而雄蜉蝣的位置很可能是0,所以位置需要最大概率变为1.对于雌蜉蝣,其位置由雄蜉蝣的位置确定.当优于对应的雄蜉蝣位置时,雌蜉蝣根据自身的速度进行变化,随着迭代次数的增加,雌蜉蝣速度趋于0,位置改变概率也逐渐变小,这种情况下雌蜉蝣位置小概率会改变.当劣于对应的雄蜉蝣位置时,雌蜉蝣的位置由雄蜉蝣的位置更新,当雌蜉蝣速度为负时,对应的雄蜉蝣位置很大可能为0,而雌蜉蝣位置很大可能是1,此时雌蜉蝣的位置可能为0.当雌蜉蝣速度为正时,对应的雄蜉蝣位置很可能为1,而雌蜉蝣位置很可能为0,所以雌蜉蝣的位置可能变为1.
1.4 进化策略
1.4.1 交配操作
蜉蝣交配根据解的质量将同等级的雄雌蜉蝣进行交配,产生两个后代.为解决原始蜉蝣算法只能求解连续值的问题,现对蜉蝣的交叉策略进行改变.本文采用多点交叉的方式,随机生成初始交叉点和交叉结束点,如图2所示,[1,0,0,1,1]为雄蜉蝣位置,[0,0,1,0,0]为雌蜉蝣位置,[0]和[1]为雄、雌蜉蝣随机生成的初始交叉点,[1]和[0]为雄、雌蜉蝣随机生成的交叉结束点,雄、雌蜉蝣通过交换选中区间完成交叉,最终生成两个子代.

图2 交配操作示意图Fig.2 Schematic diagram of mating operation
1.4.2 变异操作
原始的蜉蝣算法变异是高斯近似变异,应用于连续值问题的求解,并不适用于二进制变异策略.本文采用基本位变异方法,该方法随机生成一个(0,1)的随机数,当随机数小于变异概率时进行变异,为增加种群的多样性,采用多点变异的方式,如图3所示.由图3可见,蜉蝣位置第一个随机选[0]为变异初始点,第二个[0]为变异结束点,变异操作即对变异区间的数取反.原始蜉蝣位置由[1,0,1,1,0,1]变为[1,1,0,0,1,1].

图3 变异操作示意图Fig.3 Schematic diagram of mutation operation
1.5 基于K-means++算法聚类分析
K-means算法[19]是目前常用的聚类算法之一,已在许多领域中得到成功应用,实用性良好,但传统的K-means算法存在聚类中心参数难以确定且聚类结果不稳定的问题.本文利用提出的二进制蜉蝣优化算法对K-means++算法进行聚类优化.K-means++算法采用一定策略选择质心,其中轮盘赌算法是最简单有效的策略.在轮盘赌算法中,第m个质心的选取取决于选取数据点距离第(m-1)个质心的距离,度量距离越大则越有可能被选取.假设K-means++算法的输入样本集为D={x1,x2,…,xm},聚类的簇数为k,则经过N次迭代后算法停止.K-means++算法的运行步骤如下.
1) 找出k个聚类中心点: 从文本数据集D中随机选出一个样本作为初始的质心向量c1,计算每只样本与最近的质心向量距离和Sum(D(x)),取一个能位于Sum(D(x))中的随机值Random,并令Random-=D(x),直到其值≤0,此时的点便可作为下一个质心点.重复上述步骤,直到k个聚类中心被选出来,k个聚类中心可记作{c1,c2,…,ck}.
2) 利用这k个初始聚类中心运行K-means算法,对于n=1,2,…,N进行如下操作:
① 将簇划分Ci,初始化为Ci={ci}(i=1,2,…,k);
② 对i=1,2,…,m分别计算样本xi和各质心向量cj(j=1,2,…,k)的距离ci,j,其中ci,j=‖xi-cj‖,将最小的xi标记为di,j所对应的类别j,然后更新C=Cj∪{xi};
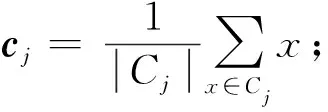
④ 如果k个质心的位置都未发生变化,则终止算法,转步骤3).
3) 输出结果簇划分C={C1,C2,…,Ck}.
2 实验对比及分析
本文用Python编写二进制蜉蝣优化算法,用该算法进行文本特征选择[20],寻求拥有更多有用特征的最优子集,利用K-means++算法对选择的特征进行文本聚类,并通过实验验证基于二进制蜉蝣算法特征选择后的聚类效果.
2.1 测试文本数据集
为验证算法的稳定性和适应性,本文采用智能实验室LABIC(http://sites.labic.icme.usp.br/text_collections/)提供的5种基准数据集进行测试,测试文档数据集信息列于表2.

表2 测试文档数据集信息
2.2 算法评估指标
准确率(Accuracy)、查准率(Precision)、查全率(Recall)和F度量(F-measure)是文本聚类常用的指标,为验证二进制蜉蝣优化算法的效果,引入特征选择的数量和适应度值与迭代次数的关系.
1) 准确率.准确率用于计算真实样本被分为正确类别的比例,计算公式为
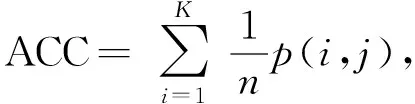
(13)
其中K表示总聚类数量,p(i,j)表示聚类j中分类i的精确值.
2) 查准率.查准率P表示相关文档占所有聚类中i文档总量的比例,计算公式为

(14)
3) 查全率.查全率R表示相关文档实际数量占所有文档的比例,计算公式为

(15)
其中R(i,j)表示聚类j中分类i的召回值,ni表示分类i中的实际样本数量.
4)F度量.F度量根据查准率P和查全率R计算,其中F是0~1的小数,其值越接近1效果越好,聚类j中分类i的F度量计算公式为

(16)
所有聚类的F-measure可表示为

(17)
5) 特征数量.该指标表示基于元启发式算法对特征选择后得到的特征个数,特征数量的选择影响文本聚类效率与准确性.
6) 收敛性能.该指标用于衡量算法的寻优能力,本文通过计算进行特征选择的适应度函数值评估算法的性能,算法收敛值即通过若干次迭代后的最优适应度值.
7) 收敛时间.收敛时间是指进行特征选择和文本聚类所用的总时间(s),该指标用于衡量算法的收敛速度.
2.3 实验结果分析
2.3.1 文本特征缩减率对比
在5个测试文本数据集上,用传统元启发式算法和本文提出的二进制蜉蝣优化算法得到的特征选择情况对比结果如图4所示.由图4可见: 在特征缩减方面,遗传算法特征缩减率约为50%,表现较差; 二进制粒子群优化算法特征缩减率为50%~70%,表现一般; 二进制蜉蝣算法的特征缩减率达到75%~80%,相比于前两种算法,二进制蜉蝣算法对特征缩减率的效果更好,表明二进制蜉蝣算法和特征选择模型的结合,可降低冗余性特征,并降低维度空间.此外,二进制蜉蝣算法在5种数据集中保持稳定且领先的特征缩减率,也说明其具有良好的普适性和广泛性.
2.3.2 算法收敛性对比
MOMA,GA和PSO三种算法的复杂度对比列于表3.由表3可见,当种群个数和迭代次数为N时,3种启发式算法的时间复杂度理论上均为O(n2),但在实际运行过程中,PSO和MOMA算法寻优具有方向性,因此这两种算法运行中所用的时间比GA算法低.而MOMA算法与PSO算法相比,前者的寻优能力较强,其迭代次数通常比N小,因此MOMA算法在实际运行过程中时间小于GA算法与PSO算法.在空间复杂度上,由于GA算法是无记忆性算法,只需要得到种群中最大的适应度值,因此其空间复杂度是O(1),而PSO和MOMA算法要记录个体的当前位置与种群的最佳位置,且所占空间和种群大小有关,因此其空间复杂度为O(n).由于种群个数通常较小,所以3种算法分配的内存空间差距较小.

表3 不同算法的复杂度对比
5个数据集基于3种元启发式算法在特征选择方面的算法收敛性实验结果如图5所示.通过计算适应度函数值评价算法的收敛性能,算法收敛即通过若干次迭代得到最优适应度的值.由图5可见,二进制蜉蝣算法约在300代收敛,而其他两种算法约在500代收敛,因此二进制蜉蝣算法收敛性能较好.在文本特征选择中,二进制蜉蝣算法得到的特征结果也具有较高的适应度,表明其寻优能力较好,再次证明了二进制蜉蝣算法的有效性.

图5 不同算法在5个数据集上的收敛性对比Fig.5 Comparison of convergence of different algorithms on 5 datasets
2.3.3 算法精度对比
3种算法在5个公共数据集上得到的类准确率、查准率、查全率和F度量值的指标对比结果列于表4.由表4可见:K-means++的聚类评估指标较其他算法差,因为K-means++算法未经过特征选择机制,文本中存在大量的非信息化特征; 经过元启发式算法进行选择后,聚类精度得到一定提升; 二进制蜉蝣算法在5个指标上明显优于其他两种传统算法.因为二进制蜉蝣算法是在萤火虫、遗传和粒子群优化算法基础上改进而来的,其寻优能力强,能选取表示文档意义的适应度值,所以精度显著提高.
2.3.4 算法收敛时间对比
不同算法在进行文本特征选择时的收敛时间对比结果如图6所示.时间越短说明算法运行的速度越快,3种算法在5个数据集上进行测试的结果表明,在进行特征选择过程中,相比其他传统的遗传和粒子群优化算法,二进制蜉蝣算法运行时间短,运行速度较快.此外,在特征选择时,算法的运行时间长短与文本的特征数目和文档数量有关,文档数目越多,特征越多,进行特征选择的时间越长.

表4 不同算法精度的对比

图6 不同算法收敛时间的对比Fig.6 Comparison of convergence time of different algorithms
综上所述,针对文本冗余特征导致聚类精度较低的问题,本文提出了一种基于二进制蜉蝣优化的特征选择算法(MOMA).首先对文本进行分词、去停用词以及计算文本权重构造向量空间模型; 然后改进蜉蝣位置更新和交叉变异策略,并结合特征模型选出优质特征,将其输入到K-means++算法中; 最后利用5个公开数据集进行实验.实验结果表明,本文提出的二进制蜉蝣优化的特征选择算法能有效选取信息化特征,大幅度缩减特征维度,聚类效率较好.
猜你喜欢
青年文学家(2022年33期)2022-02-13 22:31:13
中等数学(2021年8期)2021-11-22 07:53:38
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
小雪花·小学生快乐作文(2017年7期)2017-09-07 13:35:31
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
合肥工业大学学报(自然科学版)(2011年2期)2011-03-15 14:30:26
