
联合软阈值去噪和视频数据融合的低质量3维人脸识别
2023-05-20 07:36桑高丽肖述笛赵启军
中国图象图形学报 2023年5期
桑高丽,肖述笛,赵启军*
1.嘉兴学院信息科学与工程学院,嘉兴 314001;2.四川大学计算机学院,成都 610065
0 引 言
近年来,受益于便携式3 维传感技术的发展,基于低质量3 维人脸的识别研究受到越来越多的关注。区别于传统高质量3 维人脸数据(徐成华 等,2004),基于便携式3 维传感器采集的3 维人脸数据存在严重的质量差、噪声大和精度低等问题。图1展示了传统高质量和低质量3 维人脸数据对比图。可以看出,低质量3 维人脸数据表面存在大量毛刺,数据采集精度较低,给基于低质量3 维人脸识别的研究带来很大困难。目前基于低质量3 维人脸的识别精度很难令人满意(He 等,2016;Mu 等,2019;Liu等,2019;龚勋和周炀,2021),基于低质量3 维人脸识别方法的研究非常有限且面临诸多挑战。

图1 低质量和高质量3维人脸数据对比图Fig.1 Low-quality and high-quality 3D face data comparison diagram ((a)high-quality 3D faces;(b)low-quality 3D faces)
现有基于低质量3 维人脸识别方法主要围绕低质量3 维数据质量提升、有效特征提取等方面开展研究,存在以下困难:1)在低质量3 维人脸数据提升方面,现有方法大都基于单张深度数据优化或基于单张深度数据的重建进行低质量3 维人脸识别研究。基于单张深度数据所能获取形状信息有限,如何利用现有多帧视频数据之间的互补信息进行低质量3 维数据质量提升亟待解决。2)在有效特征提取方面,低质量3 维人脸受噪声影响较大,导致其形状信息存在较大误差,增加了有效特征提取难度。
针对上述存在问题,本文主要贡献如下:1)针对低质量3 维人脸中存在的噪声影响,本文提出了一个即插即用的软阈值去噪模块。不同于传统的阈值去噪方法严重依赖于大量经验,本文结合深度学习方法,利用神经网络模型自动学习软阈值,在网络提取特征的过程中对特征进行去噪处理。2)为了实现低质量3 维人脸多帧视频数据的融合,提出基于门控循环单元的低质量3 维人脸视频数据融合模块,自动提取低质量3 维人脸视频帧数据间的依赖关系,实现视频帧数据间互补信息的有效融合。3)在有效特征提取方面,结合softmax 和Arcface(additive angular margin loss for deep face recognition)提出了联合渐变损失函数,使网络提取更具有判别性特征,进一步提高了低质量3维人脸识别准确率。
1 相关工作
对低质量3 维人脸的研究始于2010 年以后,随着便携式3维采集设备Kinect v1的出现,3维人脸数据的获取变得更方便,也更能满足实际应用的需求。由于这些3 维人脸数据质量较差,早期关于低质量3 维人脸识别的研究主要是基于传统人脸识别方法,通常将这些低质量3 维数据与2 维RGB 图像结合来进行人脸识别,以减轻RGB 图像在识别中遇到的姿态、遮挡和光照等因素影响。例如,Li 等人(2013)提出一套首先利用深度数据同时将RGB 图像和深度图像归一化到正面姿态的预处理方法,然后通过稀疏表示分别对纹理和深度图进行相似度计算,再对相似度简单融合进行识别。在数据规模为52 人的CurtinFace 低质量3 维人脸数据库(Li 等,2013)中的不同姿态、表情、光照和遮挡等图像上都取得了较好效果。Hsu 等人(2014)为了应对姿态变化,同时针对低质量3 维人脸数据噪声大的问题,提出3D 表面重建技术,利用特征点对人脸对齐,然后提取图像的局部二值模式(local binary patterns,LBP)特征,并使用稀疏表示分类进行识别。
随着Kinect v2 和RealSense 等更多便携式3 维采集设备的相继出现和大型低质量3 维人脸数据集Lock3DFace(low-cost kinect 3D faces)(Zhang 等,2016)和Extended-Multi-Dim (Hu 等,2019)的发布,一方面,使用这些设备获取的低质量3 维人脸数据质量相比之前有了一定程度的改善;另一方面,由于低质量3 维人脸数据库规模的扩大,逐渐出现了一些基于深度学习的方法来解决低质量3 维人脸识别问题。Cui 等人(2018)提出了第1 个基于深度学习的低质量3 维人脸模型,证明了利用深度学习方法对低质量3 维人脸识别的可能性。在低质量3 维人脸数据提升方面,为了减轻噪声、遮挡、姿态和表情等因素的影响,Hu等人(2019)提出了基于深度图像归一化为正面姿态和中性表情的低质量3 维人脸识别算法。Mu 等人(2019)提出了一个轻量化的深度学习模型和数据预处理方法。数据处理流程包括点云恢复、表面细化和数据增强等,轻量化的深度学习模型则由5 层卷积神经网络结构块组成,并在其中使用4个跳跃连接来结合不同语义层面的信息,以生成更具有鉴别性的特征。为了减弱低质量3 维人脸识别中噪声的影响,Zhang等人(2021)认为采集低质量3维人脸数据噪声服从一种分布,从而导致相应特征存在扰动,因此受扰动的特征也服从一种潜在分布(即给定3维人脸的后验分布),并提出基于低质量3维人脸识别的分布表示方法,在Lock3DFace数据集上取得了很好的识别结果,但该算法网络结构复杂且参数量较大,时间复杂度较高,训练难度大。
在特征提取方面,区别于早期的传统方法,Hu等人(2019)提出以高质量3 维人脸数据为引导,提出3 种使用高质量3 维人脸引导低质量3 维人脸识别模型训练的策略,减轻了低质量3 维人脸特征提取难度。然而该算法需要同时使用高质量和低质量数据进行训练,数据获取难度较大,且目前缺少其他包含高低质量3 维人脸的数据集。龚勋和周炀(2021)针对低质量3 维人脸难以提取有效特征的问题,提出了基于dropout 的空间注意力机制和类间正则化损失,有效提高了低质量3维人脸识别准确率。
2 网络模型介绍
2.1 网络结构
图2 为本文提出的低质量3 维人脸识别模型的整体结构。首先,将视频帧数据X=(x1,x2,…,xn) ∈Rn×128×128经 过 预 处 理(Yang 等,2015)得到3D 人脸的法线贴图输入到软阈值(soft thresholding,STD)-Led3D网络,在STD-Led3D网络的特征提取过程中,插入软阈值去噪模块(soft threshold denoising module,STDM)对数据噪声进行过滤,得到视频帧的特征表示Y=(y1,y2,…,yn) ∈Rn×960,然后将这些特征输入门控循环单元融合模块对特征向量进行融合,得到视频级特征表示rv∈Rn×960。图2 中,MSFF(multi-scale-feature fusion)为多尺度特征融合模块,SAV(spatial attention ectorization)为空间注意矢量化模块。

图2 联合软阈值去噪和视频数据融合的低质量3维人脸识别模型示意图Fig.2 Diagram of soft threshold denoising and video data fusion-relevant low-quality 3D face recognition
2.2 软阈值去噪模块
传统阈值化方法通常利用人工设计的滤波器将有用信息转化为积极或消极的特征,并将噪声信息转化为接近零的特征。然而,设计这样的过滤器需要大量的经验。而深度学习中的梯度下降算法可以自动对滤波器的阈值进行学习,避免了阈值设定的开销。本文设计了一个即插即用软阈值去噪模块(STDM)以减轻噪声对网络提取特征的影响,提高模型对噪声的鲁棒性,其结构如图2所示。
软阈值去噪模块的输入为c×h×w大小的特征图X,其中c为通道数,h和w分别为特征图的高度和宽度。输入特征图X首先通过由3 × 3 卷积层、批归一化层、ReLU 激活层和3 × 3 卷积层组成的连通结构进行特征变换,得到特征图Y。然后对变换后的特征图Y取绝对值和全局池化来获取软阈值模块的初始阈值S。为了使S不会过大,将S通过一层全连接层和sigmoid 层,得到范围为0~1 的缩放向量M。将M作用于向量S得到每个通道最终阈值S^,最后利用该阈值对特征图Y中的噪声进行过滤得到软阈值去噪模块输出O。
考虑到软阈值去噪模块主要作用是在网络提取特征的过程中进行特征去噪,而随着网络层靠后,噪声特征和有用特征将会混合到一起。因此,为了保证更好的去噪效果,本文将软阈值去噪模块插入到Led3D(Mu 等,2019)网络中的第1 个结构块后。Led3D 网络是第1 个专门设计用来提高低质量3 维人识别准确性和效率的卷积神经网络。
2.3 联合渐变损失函数
损失函数是特征提取的关键部分,特征提取过程也是使损失函数最小化的过程。损失函数越小,说明网络对当前训练数据的拟合能力越好,特征判别性越高。由于低质量3 维人脸识别是细粒度识别问题,人脸之间相似性很强,如何设计损失函数来优化网络,使同类特征靠近、不同类特征尽量远离变得尤为重要。过去一段时间,低质量3 维人脸识别领域的研究大多使用softmax 损失来优化模型。但softmax 仅保证类别是可分的,并不要求同类特征紧凑、异类特征分离,使得最后识别准确率较低。而Arcface(Deng 等,2019)损失函数可以使类内特征更加紧凑,同时类间特征产生明显的距离。
为了利用两个损失函数的优点,进一步提高网络的特征提取能力,使网络提取的特征同类更近、不同类更远,本文将softmax损失函数与Arcface损失函数相结合,提出了一种联合渐变损失函数,计算为
式中,λ为权重参数,i表示迭代次数,Ls和La分别为softmax 和Arcface 损失函数。λ的值会随着训练次数不同而改变。具体来说,在训练的最初始阶段,λ为1,损失函数完全由softmax 决定。随着迭代次数增加,当迭代次数达到T(根据网络的实际收敛情况,本文选用T为1 500)时,λ变为0,损失函数完全由Arcface决定。
直观上,本文提出的联合渐变损失函数会首先利用softmax 优化网络,使网络迅速收敛。在训练过程中,逐渐增加Arcface 的权重,慢慢提升模型训练难度,逐渐使同类特征距离更近、不同类间特征距离更远,从而使模型收敛到一个更好的特征空间。
2.4 门控循环单元数据融合模块
门控循环单元(gated recurrent unit,GRU)(Dey和Salem,2017)能够很好地对序列数据之间的相关信息进行建模,并已广泛用于各类时序任务中。本文使用门控循环单元来建模低质量3 维人脸视频数据之间的相关性,提出基于门控循环单元数据融合模块对每帧低质量3 维人脸视频数据进行融合,通过对每帧视频的所有特征表示来预测每个特征表示中每个维度的向量权值,然后加权和得到整个视频序列融合后的低质量3维人脸特征表示。
GRU 的具体结构如图2所示。设当前节点输入为xt,上一节点传送的包含先前节点相关信息的隐藏状态为ht-1,利用两者,GRU 会得到当前时间步的隐状态输出ht,并将其传递到下一时间步,其过程可表示为
式中,σ表示sigmoid函数,τ表示tanh函数,⊕表示向量拼接,⊙表示向量元素相乘,Wz,Uz,Wr,Ur,Wh,Uh分别表示可学习的权重矩阵。
GRU首先利用当前时间步输入xt和上一时间步输出的隐藏状态ht-1来获取更新门控信息zt和重置门控信息rt。值得注意的是,在获取zt和rt前会将对应数据通过sigmoid 函数,该函数会将数据范围变换为[0,1],转换之后的值越接近于1,代表记忆下来的信息越多,而越接近于0 代表遗忘的信息越多。求得门控信息之后,GRU 首先会使用rt对输入的隐状态信息ht-1进行重置,并与xt进行拼接,再利用tanh 激活函数功能将数据范围缩放为[-1,1],由此得到中间状态信息h~t。最后GRU 使用更新门zt来完成对记忆的遗忘和选择,(1 -zt) ⊙ht-1表示对上一时间步隐藏状态中不重要的信息进行遗忘,zt⊙h~t表示选择性记忆当前时间步h~t中的信息,通过两者可以得到当前时间步的输出ht。
本文提出的门控循环单元数据融合模块由一个双向门控循环单元、一个全连接层和一个softmax 归一化层构成,如图2 所示。STD-Led3D 网络输出的视频帧特征表示Y会首先输入双向门控循环单元完成视频帧之间的依赖关系建模,即双向门控循环单元会对视频帧特征表示分别进行正方向和反方向的处理,得到每帧数据与其前后视频帧之间的关系表示Hb∈Rn×960和Ha∈Rn×960,这两个特征向量随后被拼接为H∈Rn×960,H被送入全连接层预测视频帧特征的初始权值Q∈Rn×960。在特征融合前,利用softmax 操作对所有特征表示在同一维度进行归一化。具体来说,给定初始权重集合Q={q1,q2,…,qn},第t个视频帧特征向量的第j个成分归一化计算过程为
式中,qij表示第i个视频的第j个分量。在获得每帧数据每个维度的权重之后,即可将其与STD-Led3D输出特征加权求和,获得最终视频级特征表示,计算为
式中,n表示视频帧数量,⊙表示向量元素相乘。
3 实验结果与分析
3.1 数据库及评价协议
3.1.1 数据库情况
为了评估本文方法的有效性,在Lock3DFace(Zhang 等,2016)和Extended-Multi-Dim(Hu 等,2019)两个低质量3维人脸数据集上进行验证。
Lock3DFace数据集采集自Kinect v2,包含509人的5 711个视频样本,并伴随有表情、姿态、遮挡和时间流逝等方面的变化。数据集包括两个独立的部分,两部分采集时间间隔最长达7 个月。所有的509 人参加了第1 阶段的数据采集,169 人参加了第2 阶段的数据采集。Lock3DFace 数据集样例如图3所示。
Extended-Multi-Dim 是第1 个包含高、低质量的3 维人脸数据集,其中低质量深度图和彩色图像使用RealSense 设备采集,高质量3 维人脸使用SCU(Sichuan University)高精3 维扫描仪采集。该数据集共包含902 个不同样本,是最大的多模态人脸数据集。每个采集样本伴随3 种表情、水平方向[+90°,-90°]和俯仰角方向[+15°,-15°]连续姿态变化的数据。Extended-Multi-Dim 数据集样例如图4所示。

图4 Extended-Multi-Dim数据集样例Fig.4 The samples of Extended-Multi-Dim dataset
3.1.2 评估协议
1)Lock3DFace 闭集评估协议。本文采用与Mu等人(2019)相同的实验设置进行训练和测试。具体地说,将每个身份的第1 个自然表情视频数据作为训练数据,剩余视频划分为表情、遮挡、姿态和时间4 个测试子集。其中,时间子集只使用自然和表情数据。由于Lock3DFace 数据集中每个视频内数据相似性过大,因此所有视频都以相等的间隔选出6帧作为代表。最后生成6 617个训练样本,1 283个表情子集测试样本,1 004 个遮挡子集测试样本,1 010 个姿态子集测试样本,676 个时间子集测试样本。与Mu 等人(2019)方法一致,在Lock3DFace 数据集上训练的模型都使用高质量3 维人脸数据集FRGC v2 和Bosphorus(Savran 等,2008)合并之后的数据集进行预训练,预训练学习率为0.005,其他与正式训练保持一致。
2)Lock3DFac 开集协议。随机从509 个身份中选取300 个身份的所有视频数据作为训练数据,剩余209 个身份的视频数据作为测试集。并对训练视频数据中每个人的第1 个自然表情视频数据进行数据增强,其余使用原始数据,共生成3 272 个训练样本。测试集中每个人的第1 个自然无表情视频作为图库样本,剩余视频作为测试样本,共包含自然、表情、遮挡、姿态和时间5 个测试子集,分别包括205,520,407,417,256 个样本。与Lock3DFace 闭集协议一致,所有视频都以相等的间隔选出6帧作为代表。
3)Extended-Multi-Dim 开集评估协议。采用与Hu等人(2019)相同的实验设置进行训练和测试,训练集包括430 人,约5 082 组训练样本。测试时,以每个身份的第1 个自然无表情视频中的第1 个样本作为图库数据,其余视频中所有样本作为测试数据,共包含自然(中性表情)、表情(张嘴、皱鼻、闭眼等)、姿态1(水平旋转头部)和姿态2(顺时针旋转头部)4 个子集,分别包括2 184,1 356,857,870 个样本。与Lock3DFace 协议一致,所有视频都以相等的间隔选出6帧作为代表。
3.2 消融实验
本文所有消融实验均采用Lock3DFace 闭集评估协议,并以Led3D网络为基准网络模型。
为了验证本文提出的软阈值去噪模块、渐变损失函数模块和门控循环单元模块的有效性,分别在基准模型上应用相应的模块以及同时叠加所有模块进行消融实验。
首先,为了验证软阈值去噪模块的有效性,在基准模型的不同位置添加软阈值去噪模块(STDM),结果如表1 所示。模型1 表示在基准模型中的第1 个卷积神经网络(convolutional neural networks,CNN)模块前加入STDM;模型2 表示在第1 个CNN 模块后添加STDM;模型3 表示在第2 个CNN 模块后添加STDM;模型4 表示在第3 个CNN 模块后添加STDM。所有模型都使用softmax损失函数进行训练。
从表1 可以看出,与基准模型相比,随着在基准模型中加入STDM 的位置逐渐靠后,Rank-1 识别准确率先上升后下降。其中,模型2 的Rank-1 识别准确率最高,相比基准模型高了2.49%,而模型4 的准确率最低,相比基准模型低了约2.27%。由于网络利用不同层进行特征变换,随着层次深入,有效特征和噪声特征会逐渐混合到一起难以分离,因此插入位置越深,效果越差。根据表1 的结果,本文使用模型在第1个CNN模块后添加软阈值去噪模块。

表1 不同位置添加软阈值去噪模块的Rank-1识别率Table 1 Rank-1 recognition rate of adding soft threshold denoising module in different locations/%
为了直观展示软阈值去噪模块在特征提取过程中的有效性,选取1 幅高质量3 维人脸数据,向其添加不同强度的高斯噪声,然后将经过软阈值去噪模块前后的特征可视化,观察模块的去噪效果。如图5所示,第1列为加入高斯噪声,第2~7列为经过软阈值去噪模块前的特征,第8~13 列为经过软阈值去噪模块后的特征。不难看出,随着噪声强度的增加,输出特征图中噪声响应越多,人脸判别性区域特征越来越不明显。而经过软阈值去噪模块后的特征包含噪声响应较少,有效特征也更加明显。尽管在此添加的是高斯噪声,不难得出,本文提出的软阈值去噪模块不仅在直观上确实减弱了特征中的噪声,在性能上也提高了低质量3 维人脸识别准确率(表1)。

图5 软阈值去噪模块前后特征可视化Fig.5 Feature visualization begore and after the soft threshold denoising module
其次,为了验证联合渐变损失函数的有效性,分别使用softmax、Arcface 和联合渐变损失3 种损失函数对基准模型进行训练。其中,Arcface 和联合渐变损失函数中的超参s和m使用了4 组不同的设置。如表2所示,在不同超参设置下,使用softmax损失函数的模型结果远不如使用Arcface 和联合渐变损失的模型结果,Rank-1 准确率最多相差12.06%。另外,随着角边距惩罚项m逐渐增大,使用Arcface 损失函数训练的模型平均准确率先是增大后又减小,这是由于随着角边距惩罚项的增大,同类特征距离更紧凑,不同类特征距离变大,特征判别性高,识别效果好。而当角边距惩罚项超过一定值之后,其准确率下降。这是由于角边距惩罚项过大导致模型学习难度增加,而无法学习到一个很好的特征空间,因此识别结果大幅下降。与此相反的是,使用联合渐变损失函数的模型不仅在同样角边距惩罚项设置下比使用Arcface 损失函数的模型取得的Rank-1 识别准确率都高,同时,两者准确率差距随着角边距惩罚项的增大先是逐渐减小后又逐渐增大,在m= 0.7时达到了约10.20%的差距。以上结果说明,本文提出的联合渐变损失函数在不同参数设置下都有助于基准模型收敛到一个更好的特征空间,提升了模型识别准确率。

表2 不同损失函数的Rank-1识别率Table 2 Rank-1 recognition rate of different loss functions/%
为了进一步直观展示联合渐变损失函数的有效性,分析各参数对方法性能的影响,将联合渐变损失函数(以s= 32,m= 0.7 为例)的训练损失曲线图可视化。作为对比,softmax和Arcface损失函数也一并可视化,如图6所示。可以看出,softmax 损失函数的损失值起始值比较低,且很快收敛至0 附近;Arcface损失函数的起始值很高,收敛至15 附近就趋于平缓;而联合渐变损失函数的起始值与softmax 一致,训练中经历了先降低后增加再降低的过程,这是由于联合渐变损失函数中Arcface 所占权重逐渐增大的缘故。结合表2 的结果,说明联合渐变损失函数能在加快模型训练收敛速度的同时,使模型学习到一个更好的特征空间,从而提高低质量3 维人脸识别准确率。

图6 损失函数对比Fig.6 Comparison of different loss functions
再次,为了验证本文提出的门控循环单元数据融合模块的有效性,设计了以下3 种基准数据融合模型。1)投票法(Vote)。该方法在获取每个视频帧的身份之后,采用投票的方式确定整个视频的身份;2)最大池化法(Maxpool)。该方法对所有视频帧使用最大池化获取同一维中的最大响应值构成视频特征表示;3)单向门控循环单元(单向GRU)。该方法使用一层单向GRU 网络对输入视频帧特征进行融合,由于最后一个节点的输出包含前面所有帧的相关信息,因此直接将其作为整个视频的特征表示。本文提出的视频数据融合模型则是在软阈值去噪和联合渐变损失函数的基础上,添加双向门控循环单元模块,结果如表3所示。
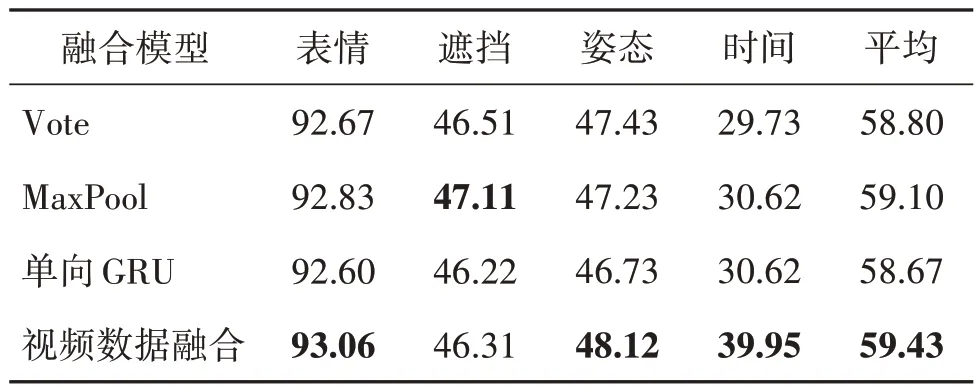
表3 不同融合模型的Rank-1识别结果Table 3 Rank-1 recognition rate of different fusion models/%
从表3 可以看出,投票法Vote 和最大池化法MaxPool没有对视频帧之间的互补特征进行学习,所以Rank-1识别率较差。此外,由于前置CNN 网络已经提供了可识别特征,而单向GRU 融合模型中最后一个节点输出的特征进行加权的表示可能会与原始CNN 输出特征有较大不同,在数据量有限的情况下,进行新的特征学习可能会导致过拟合,所以单向GRU识别性能比视频数据融合方法差。本文提出的视频数据融合模型在大部分测试子集中都实现了最高的识别准确率,在最后平均识别率上都高于其他方法,表明了本文提出的视频数据融合方法的有效性。
最后,为了验证本文提出软阈值去噪模块、联合渐变损失函数和门控循环单元模块叠加之后的有效性,在表1取得最优软阈值去噪模块位置的模型2上分别叠加联合渐变损失函数和门控循环单元模块,结果如表4 所示。从表4 可以看出,相比基准模型,本文提出的任一模块都对最终的识别准确率有益,且叠加之后的模型取得了最佳识别性能。

表4 叠加模块在Lock3DFace闭集协议上的对比结果Table 4 Comparison results of superposition of modules on Lock3DFace close-set protocol/%
3.3 与现有方法比较
3.3.1 Lock3DFac闭集协议实验结果
为验证本文方法的性能,与现有的低质量3 维人脸识别方法VGG16(Visual Geometry Group network)(Simonyan 和Zisserman,2014)、ResNet34(residual network)(He 等,2016)、Inception-V2(Ioffe和Szegedy,2015)、MobilNet-V2(Sandler 等,2018)、Led3D(lightweight and efficient deep approach for 3D faces)(Mu 等,2019)、SAD(龚勋和周炀,2021)、NAN(neural aggregation network)(Yang 等,2017)和MAA(meta attention-based aggregation)(Liu 等,2019)方法进行对比。
表5展示了上述方法在Lock3DFace闭集上的实验结果。可以看出,本文方法实现了最好的性能,相比其他最好的结果,准确率提升了3.13%。相比其他方法,本文方法的识别结果总体上有所提升,这是由于本文方法提出的软阈值去噪模块在特征提取过程中对噪声进行过滤,减轻了噪声的影响;而本文提出的联合渐变损失函数有效利用了softmax 和Arcface 损失函数各自的优点,有效降低了模型的训练难度,使网络收敛到一个判别性更好的特征空间;另外,本文提出的视频数据融合模块可以融合视频帧之间的互补特征,其对视频帧之间序列进行建模,因此效果最好。

表5 不同算法在Lock3DFace闭集协议上的对比结果Table 5 Comparison results of different algorithms on Lock3DFace close-set protocol/%
3.3.2 Lock3DFace开集协议实验结果
表6展示了不同方法在Lock3DFace开集上的实验结果。可以看出,本文方法在平均识别率上依然高于其他所有对比模型,再次说明了本文提出方法的有效性。同时,可以发现本文方法在姿态子集中的结果远高于其他对比模型,说明本文方法由于学习了视频帧之间的互补特征,从而提高了识别准确率。另外,与表5 相比,表6 中相同测试子集的识别结果更好,这是因为在开集上本文使用了多种类型的训练数据进行训练,使模型泛化能力得到了增强。

表6 不同算法在Lock3DFace开集协议上的对比结果Table 6 Comparison results of different algorithms on Lock3DFace open-set protocol/%
3.3.3 Extended-Multi-Dim开集协议实验结果
表7 展示了不同方法在Extended-Multi-Dim 开集上的实验结果。可以看出,本文方法实现了最好的性能,相比其他最好的MAA方法平均有1.03%的准确率提升。在姿态1和姿态2测试子集中,本文方法的识别结果比MAA 方法分别高出了0.58%和2.87%。Extended-Multi-Dim 中的视频数据相比Lock3DFace 数据集中的视频数据,人脸在姿态子集中有较大的姿态变化,因此未考虑视频帧相关性的其他方法在两个姿态测试子集中的效果较差。而本文方法使用门控循环单元获取不同帧之间的互补信息,通过互补信息预测特征表示每个维度的权重,然后对特征表示加权求和获取最后的视频级特征表示,有效提高了低质量3 维人脸识别准确率。同时,也说明了本文方法在应对较大姿态变化时具有良好性能。

表7 不同算法在Extended-Multi-Dim开集协议上的对比结果Table 7 Comparison results of different algorithms on Extended-Multi-Dim open-set protocol/%
4 结 论
本文围绕低质量3 维人脸数据噪声大、依赖单幅有限深度数据提取有效特征困难的问题,提出了一种联合软阈值去噪和视频数据融合的低质量3 维人脸识别方法。本文提出的软阈值去噪模块,将去噪过程直接融入深度学习网络模型,避免了传统阈值设置严重依赖人工经验的缺陷;在有效特征提取方面,本文结合softmax和Arcface提出的联合渐变损失函数使网络提取更具有判别性特征;另外,本文提出的视频数据融合模块,利用门控循环单元对低质量3 维人脸视频帧特征数据间的依赖关系建模,实现视频帧数据间互补信息的有效融合,进一步提高了低质量3 维人脸识别准确率。大量的对比实验证明了本文网络模型的有效性。
猜你喜欢
美文(2023年5期)2023-03-26
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年31期)2020-06-01
动漫星空(2018年9期)2018-10-26
妇女生活(2017年5期)2017-05-16
幼儿教育·教育科学版(2016年5期)2016-09-29
计算机工程(2015年8期)2015-07-03
浙江大学学报(工学版)(2015年1期)2015-03-01
发明与创新(2015年33期)2015-02-27
