
边界跨越对科学论文引文量的影响:基于因果推断的分析
2023-05-20 01:30郑碧丽侯剑华
图书情报知识 2023年2期
郑碧丽 侯剑华
(中山大学信息管理学院,广州,510006)
1 引言
创新,是体现科学知识产出重要性和颠覆性的要素之一,在推动科学研究与技术研发过程中起着至关重要的作用。在科学学与知识管理的视角下,创新主要分为直接创造和结合已有知识再创造两种路径[1-2]。正如牛顿所说,“如果我看得更远,那是因为我站在巨人的肩膀上”。在科学活动中,过去的研究为后续科学发展提供了理论框架、方法与算法、实证数据、支撑性的结论,因此,新的研究发现往往是基于现有知识基础和实践证据,重构研究框架、重塑理论、优化方法与算法、进一步验证实验结果[2]。1955年贝尔纳在《科学研究的战略》一文中指出:“科学中的总的发展模式还是相当清楚的:这种模式与其说像树,不如说像网。与课题或应用直接相关的科学工作的内容,可以比做网的网眼。各条线的交叉点是经验和思想集合的地方,是中心点,是一些新发现,从这里产生各种各样的应用技术和科学学科”[3]。在正式交流体系中,科学的发展往往表现为科学文献网络中知识的演化与发展。科学文献引证不同理论、不同领域、不同学科的参考文献,形成复杂的科学引文网络,文献引证关系表征继承与创新、基础与前沿的关系[4]。在引文网络中,来自不同学科、不同研究主题的知识融合、关联、分化[5],从而激发来自不同科学领域的学者合作,力求发挥各学科的优势。这些来自不同领域的知识的结合可以看作是知识跨越边界(boundary-spanning)的融合、重组和再创造的过程。目前,在科学学、科学计量学等领域,已有不少研究表明边界跨越对论文质量、引文量有积极的影响[2,6-8]。引文量是反映论文在学术共同体传播、扩散效果的重要指标,除了边界跨越之外,还有文章相关、作者相关、参考文献相关、引文相关的指标。目前,有相当数量的研究从定量的实证或质性的内容分析两个角度探讨引文及其影响因素的相关关系[9-11]。
现有研究虽然解析了与引文量相关的影响因素,也反映出边界跨域对引文数量的积极影响,但是仍然存在进一步研究的空间:(1)边界跨越测度方法大多数是基于期刊耦合、学科耦合的方法测度论文的边界跨越效应,难以从知识内容的角度,以细粒度分析的方法,反映知识的重组、融合、流动;(2)引文量及其影响因素的相关性并不能完全揭示知识扩散的机理,相关性并不意味着因果关系。一方面,相关性系数是对称的,而因果关系则不然。例如,研究表明知识跨学科领域的融合与引文数量正相关,则引文数量与边界跨越程度也呈正相关的关系,但是我们并不能得出引文数量是知识跨边界重组的原因。另一方面,因果关系并不是相关性的唯一解释。例如,关键词的数量与引文数量呈现正相关的关系,但关键词数量是否可以作为解释引文量的原因,还需要考虑其他因素,如是否被数据库收录、期刊影响因子、文章长度等。因此,基于已有研究成果,本文主要围绕两个研究问题分析边界跨越对引文量的影响:
(1)如何测度论文的边界跨越程度?
(2)论文边界跨越程度与引文量之间是否存在因果关系?
为了解决上述两个问题,本文首先界定边界跨越论文的概念及测度方法,通过文献调研,选择影响引文量的潜在影响因素,采用倾向值匹配的方法讨论边界跨越对引文量的影响,以加深学界对引文扩散机制和成因的理解。
2 文献综述
为了解析边界跨越论文对其被引量的影响,本部分首先阐释边界跨越论文的内涵。其次,概述引文影响因素,为后续因果推断的实验提供必要的分析依据。最后,介绍目前关于边界跨越效应对引文量影响的研究,总结现有研究的局限性。
2.1 边界跨越论文的概念
许多网络呈现出高度组织化的结构[12]。在一个网络中,可以通过不同的聚类算法(如谱聚类、K均值聚类、基于密度的聚类算法、模糊C均值聚类算法)将网络中具有相同属性的节点划分为不同的社区或模块,每个社区将网络拆解成了相互不重叠的节点组合[6]。在网络中,节点往往是有意义的实体,网络中的连接则是节点与节点之间的链接或边。节点所承载的信息因网络而异,例如,合著网络中的作者、共被引网络中的参考文献、共现网络中的关键词等。在合著网络、参考文献共被引网络、关键词共现网络等各种网络中,参考文献共被引网络包含更为具体、广泛的信息。在合著网络或者期刊共被引网络中,同一作者或同一期刊的文献可能会被纳入到同一节点当中[6],导致部分文献信息在节点归并的过程中丢失。然而,参考文献共被引网络能够更好地反映知识发展的足迹。以往的研究为后续的研究提供概念基础、研究框架,被阅读、被借鉴、被引用,在科学交流系统这一抽象的知识空间中凝固成足迹[13-14]。通过共被引网络,我们可以窥见知识、研究主题甚至是学科的稳定与变动、融合与演化。因此,大多数的研究是以参考文献共被引网络为基准网络,识别颠覆性、重要性论文,探讨引文结构、学科发展[15-17]。
鉴于参考文献共被引网络(Co-citation Network of References,CNR)的特征,我们以该网络作为基准网络探讨边界跨越文献或知识的内涵与测度方法。在基准网络中,如果一篇文献在不同主题间建立新的链接,则将该文献定义为边界跨越文献,承载着边界跨越的知识[6]。即,在一个由多个主题聚类的参考文献共被引网络中,一篇论文进入到该网络时,所添加的链接可能在某主题聚类内,也可能跨越若干个主题聚类(如图1 所示)。本文将连接两个不同主题聚类的文献称为边界跨越论文(如图1 中的文献1),将连接同一主题聚类的文献称为非边界跨越论文(如图1 中的文献2)。
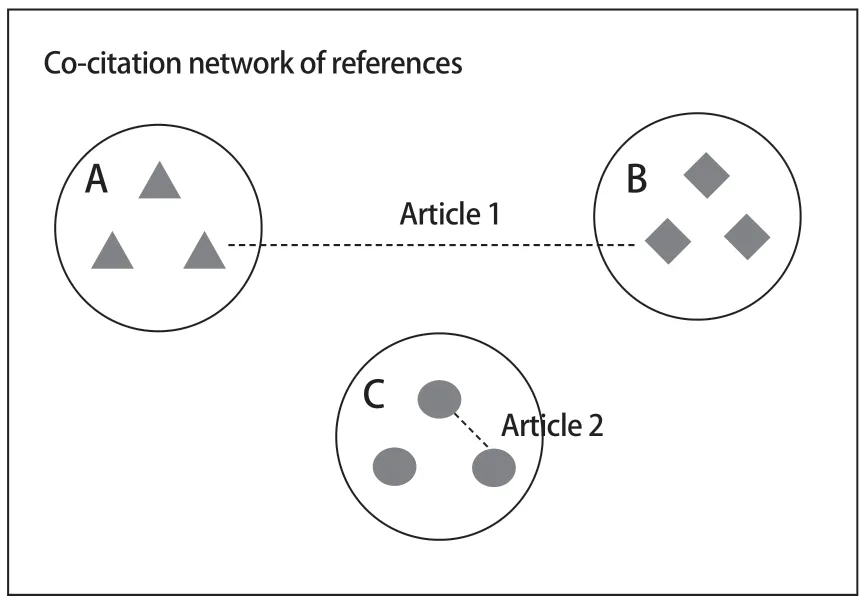
图1 边界跨越论文示意图Fig.1 The Illustration of Boundary-spanning Paper
2.2 边界跨越对引文量的影响
关于边界跨越论文,多数研究将其视为论文“不常见”的组合(atypical combinations)或者是“新组合”(novel combinations)。例如,Uzzi[2]等将知识的重组操作化为论文参考文献在期刊层面的不常见组合,这种组合通常也被称为文献的新颖性。而跨学科的学者认为,边界跨越的论文是涵盖两个及以上学科的论文[18-20]。从边界跨越的理论上看,无论是期刊层面还是学科层面的知识重组都是知识跨越边界重组、传播、扩散的现象。然而,由于期刊和学科都承载大量的研究领域和主题,这两个层面对知识组合的分析均难以深入解析知识边界跨越的细粒度特征。
目前学术界关于边界跨越是否对引用量产生影响仍然存在分歧[1,21]。一些学者认为,来自不同领域的学者合作,可以促进思维碰撞,弥合不同的知识体系,充分发挥各学科的优势,其成果可能获得更高的引用量[22-24]。例如,Steele和Stier[25]利用布里渊多样性指数量化作者、研究主题和引文文献的学科交叉性,基于引文分析和OLS的方法,揭示跨学科的研究对引文量有积极的作用。然而,其他研究表明,边界跨越的文献对其引用没有影响,甚至对某些学科产生负面的影响[26-27]。新的知识组合会激发新想法,形成高创新性的成果,但也导致了较高的不确定性,并且需要较长的时间才能在学术共同体中得到认可[28-29]。
2.3 影响引文量的相关因素
除了边界跨越之外,引文量还受到其他因素的影响。Tahamtan[30]等将28个因素分为三大类:论文相关、期刊相关、作者相关。Xie[11]等认为,累积引文量还受到文献早期被引情况的影响,并结合WoS、CNKI、ORCID的数据,将66个要素分为论文相关、作者相关、参考文献相关、引文相关四个方面。
2.3.1 论文相关的因素
大量的研究表明,篇幅较长的论文(具体以文献的页数进行计算)会有更高的引用量[31-33]。此外,结构化摘要、图表与公式、开放存取、数据库收录情况、关键词数量、摘要长度与引文量呈现正相关的关系[34-35]。然而,标题的长度对引用量没有影响甚至是负面的影响[35-36]。除了论文文本属性之外,文章的质量、创新度、关注度、研究主题等都是影响引文量的重要因素,文献越有吸引力、质量越高,其获得引用的次数越多[37-39]。
2.3.2 作者相关的因素
一篇论文的影响力与合作关系、合作国际化程度、作者声誉等要素相关。在交叉学科领域,一篇论文的作者越多,作者多样性越高,其被引用的可能性就越大[40-41]。作者学历、学术生涯、作者h指数、教育背景等与引用量呈正相关关系[11]。另外,作者的性别、生产力、头衔、隶属机构等也与引文量有关[41-43]。
2.3.3 参考文献相关的因素
参考文献的数量、影响力和多样性是影响引用量的重要因素[44-45]。参考文献平均“年龄”较低的文献比引用“旧文献”的论文更容易被引用[46]。此外,会议论文、参考文献易获取性、学位论文与文献的被引量相关性较弱,而外文参考文献的占比与引文量呈正相关的关系,但相关性系数较低[11]。
2.3.4 引文相关的因素
论文自发表后获得的初始引用量反映学术界对论文的早期反馈,这对论文的累积引文量有重要的影响[47]。因此,论文在初期获得的引用量可以预测其未来的科学影响力[45,48]。对于“睡美人文献”,论文价值难以通过初期引用量表征,但大多数的研究还是基于论文发表后第一年、第二年以及第五年的累积引文量作为其早期学术表现的评估指标[49]。
综上,目前关于边界跨越对引文量的影响主要存在几点不足。(1)从期刊、学科等知识单元的角度,难以深入挖掘论文的边界跨越程度对引文扩散的影响。(2)大量的研究从文献、期刊、参考文献等角度分析各个要素与引文的关系。然而,鲜有文献从论文研究主题的边界跨越角度探讨其对引文量的影响,并且论文的边界跨越程度越高,是否意味着更高的引文量仍有待进一步的探索。(3)以往研究主要通过相关性的分析或者回归方法探讨边界跨越特征与引文数量的关系。这些方法揭示边界跨越对引文量的正向或负向的影响,但无法揭示导致引文数量的成因及机理。
有鉴于此,本研究利用倾向值得分匹配(PSM)的方法,基于参考文献共被引网络,以论文边界跨越程度为视角,阐释边界跨越特征与引文量的因果关系。本文提出假设:论文的边界跨越特征对其引文量有积极的作用,且边界跨越程度越大,被引量越高。
3 数据、变量与方法
3.1 数据来源
本研究我们选取科学计量学、信息计量学领域的五本期刊[50],包括Scientometrics、Journal of Informetrics、Journal of the Association for Information Science and Technology(2014-2015)、Journal of Information Science、Information Processingand Management作为数据来源。为了使每篇论文有至少五年引文窗口,本文选取2011-2015年期间共2,860篇论文作为目标文献集(dataset S)。本文从Scopus中下载目标文件集所有论文的文献记录,包括如标题、摘要、作者、关键词、论文长度、来源期刊、来源期刊的影响因子、文献的总被引量。其次,我们从Dimensions数据库中爬取目标文献的参考文献和施引文献的记录,包括DOI、标题、关键词、摘要等信息。本文将参考文献集命名为数据集R(dataset R)和数据集C(dataset C)(表1)。

表1 研究数据基本信息Table 1 Basic Information of Research Data
3.2 变量的操作化
3.2.1 自变量:论文的边界跨越程度
陈超美教授[6]提出引文网络结构变换(Structural VariationAnalysis,SVA)的方法,通过对目标文献进行分析,测度其对现有知识空间的边界跨越连接。SVA基于现有科学知识结构与新发表论文中新思想之间相互作用的过程,通过测度论文改变现有知识结构的能力,评价论文的影响力。SVA基于三个网络指标:模块度变化率(modularitychangerate,ΔM)、聚类连接(clusterlink)、中心性散度(centralitydivergence)识别文献改变知识网络结构的能力。其中,网络的模块度是衡量网络整体结构的指标,数值范围在[-1,1]之间。模块度变化率是测度目标文献在参考文献的基准网络中引起的相对网络结构变化。目标文献可能在聚类之间或聚类内部添加新的连接,导致网络模块度增加或减少。例如,一篇文献综述或一篇具有“不常见”知识组合的文献往往涉及多个聚类,在基准网络中添加边界跨越连接,导致知识空间的显著变化。聚类连接反映随着目标文献进入,聚类间产生新的连接,使基准网络的整体结构发生改变。中心性散度是根据目标文献进入知识空间后,网络中节点中介中心性分布的分散程度来评估文献改变网络的能力。后两个指标直接反映了知识网络的节点属性变化。
本文选择ΔM指标来测度论文的边界跨越程度,原因有二。(1)本研究的目的并不是为了识别哪些是边界跨越的论文,以及这些边界跨越论文如何改变节点的中心性,我们关注的是具有边界跨越特征的论文在既定网络中引起网络结构变化的程度。也就是说,本研究的目的在于明确一篇具有边界跨越特征的文献是如何改变知识网络的,而不仅是关注它是否为边界跨越论文。(2)此外,在笔者前期的研究工作中[51],通过模块度变化率(MCR)测度LIS领域中具有边界跨越特征的作者,揭示了MCR与高被引论文、高影响力作者具有较强的相关性,反映MCR在预测被引量方面有一定的适用性,为这篇论文关于边界跨越论文与被引量的关系研究提供实证依据。
具体计算步骤如下[52]:(a)根据Dataset S,通过CiteSpace信息可视化软件系统逐年绘制参考文献共被引网络;(b)通过Threshold Interpolation(c,cc,ccv)①Threshold Interpolation 是阈值插值,其中c 是被引频次,cc 是两篇文献的共被引频次,ccv 是两篇文献的共被引系数的方法,按照(2,2,20)、(4,3,20)、(3,3,20)筛选共被引网络中的参考文献节点;(c)采用LLR②LLR 是Likelihoodratiotest(对数极大似然率),是CiteSpace 中主题聚类分析方法的一种。的算法,根据聚类内的文献题名、摘要、关键词析出聚类名;(d)计算每篇论文的ΔM值,并以此作为因果推断的自变量。样本中ΔM呈幂律分布的特征(图2),ΔM数值在(0.5]之间的论文约占所有样本的98.6%。考虑到样本中ΔM差异较大,若直接按照其分布特征进行实验组与控制组的划分,在后续的倾向值匹配过程中容易导致实验组中的样本因没有相同或相近倾向值而匹配失败及样本丢失。因此,为了使实验组、控制组均有足量的样本进行高质量的匹配,本研究根据样本均值(均值为0.45),将ΔM大于均值的样本划分为实验组,反之为控制组,进而探讨边界跨越程度大于均值的论文较之小于均值的论文,在被引量方面的净效应。
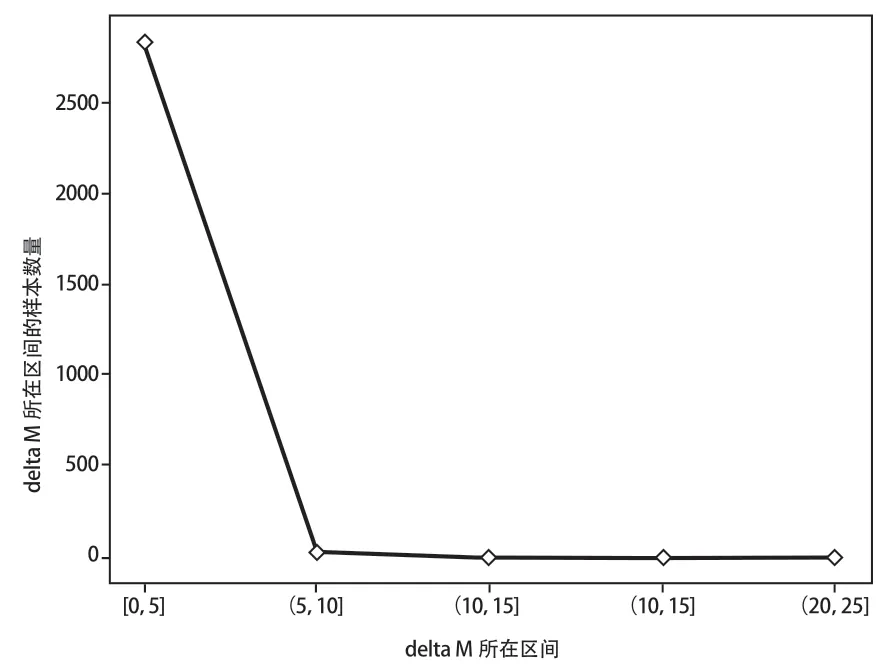
图2 ΔM 分布情况Fig.2 The Distribution of ΔM
3.2.2 因变量:论文的引用量
近年来,虽然以引文数量作为评估指标存在较大的争议[53],但论文的引用量仍然是评估学术界对文献价值、研究水平、学者评价的重要参考来源[13]。因此,大量的研究依旧以引文数量作为学术影响力的数据基础[54-56]。基于此,本文以目标文献自发表后至2020年12月31日在Dimensions数据库中获得的被引量作为因果推断的因变量。
3.2.3 控制变量
为了提高因果推断过程的有效性,本文基于文献综述部分提及的可能影响引文数量的要素作为控制变量。由于诸多数据需要手动预处理,考虑到数据的易获取性,本文根据以下思路选择控制变量:(a)现有研究已验证与引文数量的相关性;(b)在Scopus与Dimensions数据库可获取。本研究选取与文献、作者相关的10个变量(表2)作为控制变量。
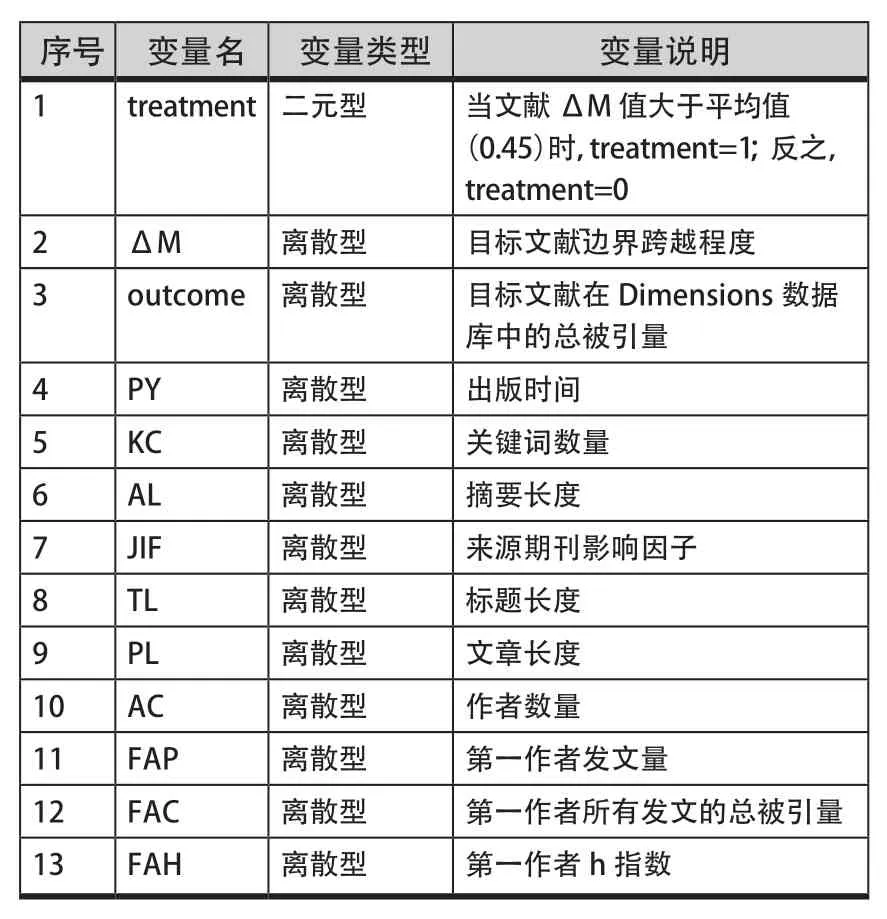
表2 因果推断变量说明Table 2 Description of Causal Inferential Variables
3.3 方法:样本选择偏误与倾向值匹配
在社会科学的研究中,混淆变量③混淆变量(confoundingvariable)是指与自变量与因变量均相关的变量,可能会使自变量和因变量之间产生虚假的相关关系。和选择性偏误④选择性偏误(selectionbias),是指在研究过程中因样本选择的非随机性而导致得到的结论存在偏差。会对因果推断结果带来影响。一方面,在实际研究过程中,自变量在研究对象之间是非随机分配的,这可能导致自变量对于因变量的净效应难以获得。另一方面,多元线性回归的回归系数由于受到混淆变量的影响,往往会产生“选择性偏误”的问题。倾向值匹配作为一种相对新兴、可靠的因果推断方法,被广泛应用在社会科学研究中[57,58]。倾向值计算将多维混淆变量整合为一个降维后的分数(即倾向值),从而均衡实验组与对照组之间混淆变量的分布。将非随机化实验中的混淆变量进行类似随机化的均衡处理,在一定程度上可以降低选择性偏误,保证因果推断的可靠性。倾向值匹配的逻辑是从对照组中选出与实验组某一个或多个倾向值相同或相近的样本进行配对,常用匹配方法是近邻匹配、卡尺匹配等。以本研究中边界跨越程度对被引量的影响为例,倾向值匹配就是在考虑多个混淆变量之后,将高边界跨越论文与低边界跨越论文进行配对,并确保他们的倾向值相同或相近。在控制多个混淆变量的情况下,高边界跨越论文组和低边界跨越论文组的被引量差异只能归因于其边界跨越的程度,由此降低了选择性偏误。具体地,本研究通过倾向值匹配的方法,计算目标文献的倾向值,估计目标文献接受干预的概率,将ΔM值大于0.45的目标文献设为实验组(treatment=1),将小于0.45的目标文献设为控制组(treatment=0),在此基础上考虑边界跨越程度对引文量的影响,得出边界跨越对引文量的净效应。本研究涉及的干预变量为边界跨越的程度(二分变量),结果变量为引文量(离散型变量),将出版时间、关键词数量、摘要长度、来源期刊影响因子、标题长度、文章长度、作者数量、第一作者发文量、第一作者被引量、第一作者h指数作为控制变量。
4 结果与讨论
4.1 平衡性与共同区间检验
为了确保匹配结果在实验组和控制组之间是平衡的,即用于匹配的所有变量在两组之间没有显著差异,本研究测试一对一近邻匹配、一对四近邻匹配、一对四卡尺匹配、一对四半径匹配、核匹配、局部线性匹配六种方法的平衡性及共同区间。匹配后,大多数观测值均在共同取值范围内(on support),因此在进行倾向得分匹配时仅损失少量样本。
图3、表3显示所有变量的标准化偏差在匹配后缩小,并且所有变量的标准化偏差绝对值小于10%,对比匹配前的结果,所有变量的标准化偏差均大幅缩小。除了一对四半径匹配之外,其他匹配结果也有相似的平衡性检验结果。根据六种方法匹配后,实验组与控制组文献的10个混淆变量值分布均衡,说明这六种匹配方法在很大程度上改善了样本数据的内生性问题。
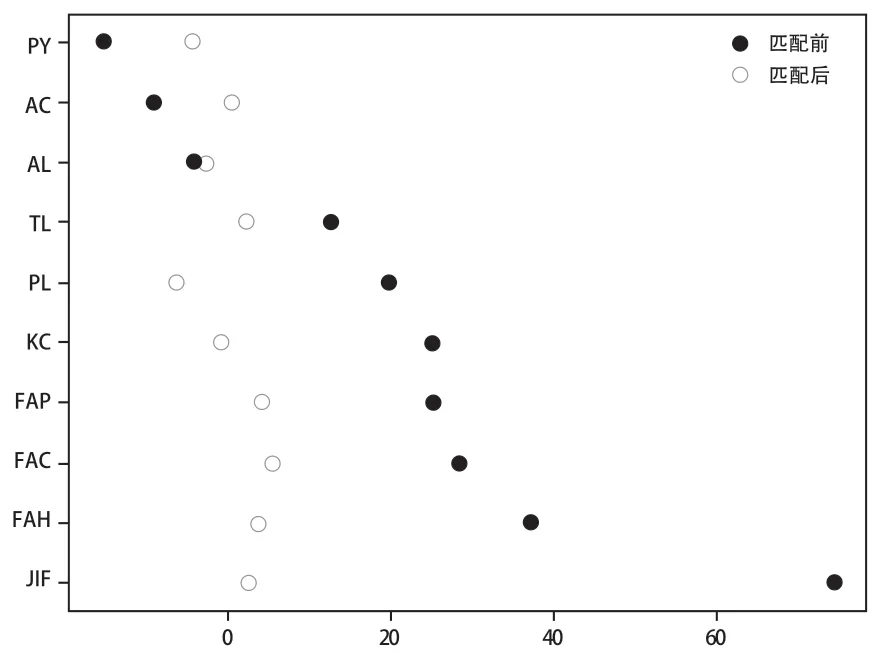
图3 各变量标准化偏差图Fig.3 Standardized Deviation for Each Variable

表3 一对四半径匹配平衡性检验Table 3 One to Four Radius Matching Balance Check
4.2 边界跨越影响的分析结果与讨论
本研究通过近邻匹配、卡尺匹配、半径匹配、核匹配、局部线性匹配的方法对所有目标文献进行匹配。其中,在卡尺匹配中,倾向得分的标准差为0.15,然后乘0.25,可知0.25σ=0.037≈0.04。为了使匹配对象得分更为相近,本文将卡尺范围定为0.03,这意味着对倾向得分相差3%的观测值进行一对四匹配。
表4为基于倾向值匹配法所得到的实验组平均处理效应(ATT)以及使用Bootstrap方法计算的标准误。六种匹配方法所得实验组的平均处理效应基本相近,ATT值介于9-12之间,并通过了置信度为99%的显著性水平检验。ATT是文献在干预状态下的平均干预效应,也就是在控制其他匹配变量不变的情况下,文献在控制组和实验组内因变量的变化。结果表明,对于边界跨越程度高的文献来说,其获得的引文数量比程度低的文献普遍提高约9次。也就是说,在其他匹配变量一致的情况下,控制组(边界跨越程度低于平均值)与实验组(边界跨越程度高于平均值)的文献所引起的引文量差异为9次左右。这也证实了我们的研究假设:论文的边界跨越特征对其引文量有积极的作用,且边界跨越程度越大,被引量越高。
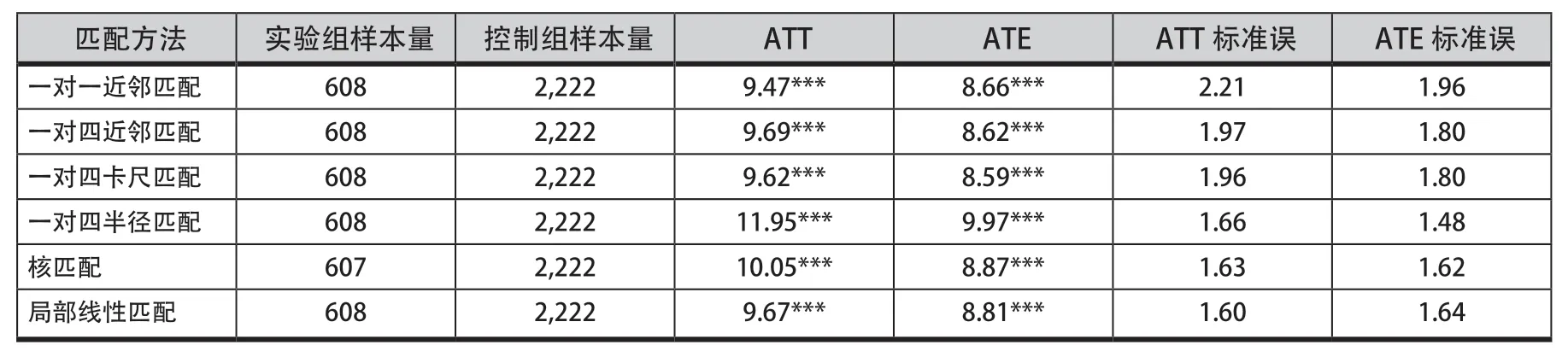
表4 边界跨越程度对引文量的处理效应Table 4 Treatment Effects of the Degree of Boundary-spanning on Citation Counts
对于边界跨越程度对引文量的作用,本研究做了进一步的分析。首先,从文献类型来看,边界跨越程度高的文献包括综述性文献。综述类触及多个学科主题,融合当下研究热点和难点,对科学发展起到导航的作用,因此这类文献不仅边界跨越程度高,被引量也相对较高。例如,边界跨越程度最高的文献The diffusion of H-related literature,分析了h指数产生、方法研究的分化以及在各领域的应用等方面,涉及到信息计量学与科学计量学和研究评估领域、信息计量学领域中的h指数相关问题及应用、h指数方法的应用和h指数理论研究四个方面。
其次,从文献内容来看,边界跨越程度高的文献也包括理论与方法创新、方法完善类的文献。这类文献基于现有的理论与方法,提供更完善的研究框架或方法。例如,A further step forward in measuring journals'scientific prestige: The SJR2 indicator提出一种新的期刊评价指标——SJR2,不仅考虑了施引期刊的声誉,还通过两个期刊共引分布向量之间的余弦判断两本期刊的主题相近度。
4.3 敏感性分析
倾向值匹配方法如果存在遗漏变量,可能会带来“隐藏偏差”的问题。为了解决这一问题,使用Rosenbaum Bounds方法检验PSM对隐藏偏差的敏感性。Γ系数越接近1,研究结果对隐藏偏差越敏感。Γ系数越大(通常为2),研究结果对隐藏偏差越不敏感。在表5中,紧邻匹配、半径匹配、核匹配、卡尺匹配、局部线性匹配方法的Γ系数在大于2时,才在5%的置信水平上显著。因此,本研究根据已有的混淆变量进行的因果推断结果是稳健的。

表5 Rosenbaum Bounds 敏感性分析Table 5 Sensitivity Analysis by Rosenbaum Bounds
5 结论
知识的重组与再创造是对现有知识结构改变的过程,是知识分化、跨越原有学科主题重新融合的过程,也是跨学科激发创新、促进合作的重要体现。本研究基于边界跨越的理论与倾向值匹配方法,从实证的角度分析边界跨越论文对引文量的影响。研究表明,边界跨越的程度带来引文量的差异化结果。第一,论文是否呈现边界跨越特征,影响其在学术共同体的扩散效果;第二,高度跨越边界的论文比程度低的论文,更能吸引后续研究的引用。
上述研究结论对跨学科知识演化及科学合作有一定的参考价值。一方面,知识的边界跨越促进知识的扩散。边界跨越的知识由于涉及多个知识单元、研究主题,往往越容易给后续的研究提供参考。另外,由于“新组合”的知识具有一定的创新度,因此“新组合”的知识在一定程度上可以变革知识结构,促进知识、学科的演化与发展[58]。另一方面,对科研人员来说,随着学科发展逐渐细化,一个学者难以同时掌握多个领域的知识体系,通过合作的方式促进学科之间的知识流动与交融[59-61],既能充分发挥学科优势,又能提高成果的影响力。
本文的研究还存在变量获取与分析方法的局限性。首先,受限于数据的易获取性,本文只考虑论文相关及作者相关的混淆变量。因此在后续的研究中,需要补充其它变量,如参考文献、初期引文量相关的变量。其次,倾向值匹配方法亦存在其局限性。PSM通过匹配的方式减少对多元线性回归等函数形式的依赖,并未从根本上解决由选择偏差或遗漏变量所导致的内生性问题,并且需要比较大的样本容量才能得到高质量的匹配结果[62]。
作者贡献说明
郑碧丽:设计研究方案,数据收集与分析,论文撰写与修改;
侯剑华:确定选题,提出研究思路,修改论文。
支撑数据
支撑数据由作者自存储,E-mail:zhengbli@mail2.sysu.edu.cn。
1. 郑碧丽. 2011-2015data.rar.论文题录数据.
2. 郑碧丽. finaldata.csv. 变量数据.
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
国际比较文学(中英文)(2019年1期)2019-11-12
证券法律评论(2018年0期)2018-08-31
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
东方教育(2016年4期)2016-12-14
电子设计工程(2015年6期)2015-02-27
中国校外教育(下旬)(2014年10期)2014-11-20
外语学刊(2014年6期)2014-04-18
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
