
基于弱随机相机位姿图像的三维场景恢复
2023-05-19 07:51:12荆树旭
计算机技术与发展 2023年5期
荆树旭,赵 娇
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
当前人们通过手机、相机等可以很容易地获取真实世界的高分辨率图像并以数据的形式永久地保存下来。随着人工智能的高速发展,从多幅图像中恢复场景的三维几何信息成为研究热点,主要途径是通过多视立体几何(Multi-View Stereo,MVS)、深度学习等计算机视觉理论和方法恢复真实场景的三维几何信息。
目前三维场景的表示形式有深度图、点云、网格、体素等。根据所使用的图像数据源的不同,恢复场景三维信息的方法[1]主要分为主动视觉和被动视觉两种类型,主动视觉通过设备主动发射可被测量的激光、红外等信号直接获取场景的三维点云信息,其可靠性高,主要应用于实时任务,但存在设备成本高、环境条件限制大以及点云数据精度不足等问题。被动视觉通过提取和学习图像数据中的视觉特征恢复场景的三维几何信息,具有方便快捷、成本低、应用范围广的特点。被动视觉根据目标场景的多幅不同视角图像,利用三角测量法、立体视觉法、视差法、深度学习等方法恢复场景三维几何信息。图像获取相比基于激光、红外传感器的深度信息获取更经济,是时间不敏感任务的更好选择。
基于MVS和深度学习的三维场景恢复需要获取目标场景具有一定空间重合度的多视角图像,多视角图像相机位姿分布的规范度、重合度对三维恢复的效果有很大的影响,基于深度学习的训练数据集在场景图像相机位姿分布的规范度和重合度方面良好。在具体应用中,用户拍摄的目标场景多视角图像具有较大的随机性,难以保证获取到和训练数据集质量等同或接近的场景图像数据,从而影响恢复效果。为了缓解这一问题,该文提出了基于弱随机相机位姿图像的三维场景恢复方法,通过给用户提供目标场景拍摄建议,降低所获取目标场景图像相机位姿分布的随机性,提高场景的三维恢复效果。
1 相关工作
基于被动视觉的三维场景恢复一般分为传统多视几何MVS和深度学习两种方法。MVS方法将获取的场景图像通过相机模型、对极几何约束、特征匹配等几何原理进行解析,从而得到图像中物体的三维几何模型。卷积神经网络CNN (Convolutional Neural Networks)的出现,为三维恢复算法改进以及性能优化提供了新思路,伴随深度学习的发展,通过机器学习模仿动物视觉进行场景三维恢复,将深度学习算法和传统MVS三维恢复算法进行融合实现优势互补。
基于MVS的三维场景恢复通过多视角图像来获取场景三维信息。2018年Yao等人[2]提出了基于可微分的单应性变换立体匹配算法,然后结合深度学习提出MVSNet方法进行三维恢复。继而一些研究者在MVSNet方法的基础上做了许多改进:R-MVSNet[3]把3D卷积换成门控循环单元GRU (Gated Recurrent Unit),把损失函数改为多分类交叉熵损失,内存减小,精度也有所下降。Point-MVSNet[4]通过预测图像深度信息并结合图像构成三维点云,再用3D点云算法优化深度信息,提高了点云精度。P-MVSNet[5]将假想面上的特征匹配置信聚合变为一个向量,以此提高立体匹配的精度。CVP-MVSNet[6]提出成本体积金字塔模型,应用在深度网络中,可处理高分辨率图像并获取高质量场景深度图,缩小了匹配代价的搜索范围。Fast-MVSNet[7]提出由稀疏到稠密、由粗糙到精细的框架进行场景深度估计,并增加高斯-牛顿层优化深度提高恢复速度。上述方法都需要获取真实场景的三维数据,而三维场景训练数据获取比较困难,MVS2[8]提出了无监督的多视图深度学习方法,在深度图中引入了跨视图一致性约束,并提出了一种损失函数来度量跨视图一致性。Khot T等人[9]提出了稳健的光度损失函数以提高无监督学习的性能。PatchmatchNet[10]提出了一种新颖的、可学习的、用于高分辨率多视图立体视觉的级联公式,可以处理更高分辨率的图像。Xu H等人[11]提出了一个基于语义共分词和数据增强指导的可靠监督的框架,并设计了一种有效的数据增强机制,从而保证三维场景恢复的鲁棒性。
MVSNet、P-MVSNet、R-MVS、MVS2等把DTU datasets、Blended MVS或Tanks and Temples作为训练和评估网络的数据集。DTU数据集[12]是针对室内场景和对象使用工业机械臂专门拍摄并处理的图像,摄像机轨迹和视角都经过严格规划和控制。Blended MVS数据集[13]是通过规范相机位姿的虚拟摄像机获取的用于MVS训练的合成数据集,包括106个训练场景和7个验证场景。Tanks and Temples数据集[14]针对更为复杂的室内和室外场景,主要用于验证深度学习网络是否对光照变化大、存在动态目标的场景仍具备较为精确的重建能力。总之,上述介绍的训练数据集在获取时通过搭建规范的拍摄场景,对相机以及相机拍摄的视角都有严格的控制。普通用户在拍摄目标场景时多视角图像的相机位姿具有较大的随机性,难以保证获取到和训练数据集质量等同或接近的场景图像数据。
在三维场景恢复应用方面,余生吉等[15]使用双结构光相机直接获取三维信息对莫高窟第45窟彩塑进行三维重建,在获取高精度几何信息的同时,达到了色彩、纹理、细节等高度还原效果。杨会君等[16]提出了交互式选择和滤波器相结合的果实表型离群点去除方法,完成了基于普通图像复杂背景下的作物果实三维表型重建。郑亦然等[17]通过尺度不变特征变换匹配SIFT(Scale Invariant Feature Transform)算法以及PCL(Point Cloud Library)泊松曲面重构算法实现了实验室复杂设备的结构重建。张琼月等[18]设计了三维环物摄影装置,从原始图像质量和建模软件选择两个方面,优化模型精度,完成岩矿标本精细化三维重建及虚拟仿真平台搭建。周祖鹏等人[19]提出一种基于多图像拼接三维重建算法,利用无人机操作的灵活性、视角可控制性等优点进行目标场景的三维重建。张香玉等[20]构建VR环境,借助VR生成的多视图三维数据实现了场景稠密重建。Lin Z H等人[21]、Jonathan T. Barron[22]、Kara-Ali Aliev[23]提出一系列新颖的视图合成算法,在基于单目视频的三维重建的应用上具有更高的性能和速度;唐嘉宁等[24]提出一种深度网络和边缘检测融合的单目视觉建图方法,能够实现无人机实施构建三维地图的要求;吴长嵩等[25]对无人机航拍图像的三维重建技术进行综述,提出已经取得的突破和即将面临的挑战。以上高精度三维重建应用中使用结构光相机、三维环物装置、无人机等设备对重建场景进行拍摄,并对相机的拍摄位姿有更严格的规范性和重合度要求,均未考虑弱随机相机位姿的三维重建效果评价。
2 文中方法
三维场景恢复一般步骤是用户首先拍摄目标场景的多个不同视角的图像,再对图像进行特征提取和特征匹配并计算出各幅图像对应的初始相机位姿,同时重建出稀疏的三维点云,最后,以多视角图像和对应初始相机位姿作为深度网络输入,进行深度图计算和相机位姿优化继而生成三维稠密点云,点云的颜色依据多视角图像在该点的相似RGB决定。
近些年,研究者更多关注于优化网络以提高三维场景的恢复效果,而对于三维恢复应用中的用户拍摄影响因素关注不足,通过实验发现用户在拍摄目标场景图像时的规范性会直接影响三维场景恢复的效果。对于一般消费级的用户在没有相机滑轨、机械臂等辅助装置和缺乏3D视觉专业知识的条件下,如何在目标场景图像的获取环节更好利用相机获取目标图像,从而提高三维恢复效果是一个有益的尝试。例如,一般用户在没有拍摄建议的条件下拍摄的图像,相比于规范的训练数据集,前者的三维效果明显较差,图1(a)是DTU数据集的相机位姿分布,图1(b)是一般用户拍摄的相机位姿分布。通过对比可以发现,二者在相机位姿整齐度、图像重合度及数量等方面有较大区别,这些区别会直接影响三维恢复效果。

图1 DUT数据集和一般用户相机位姿分布对比
2.1 实验设置
该文通过一般用户对目标场景实例进行图像拍摄和三维恢复实验,了解普通用户的拍摄习惯,通过实验研究提供一套系统的场景拍摄建议指导用户拍摄,从而提高三维场景恢复效果。实验邀请30个参与者,在没有拍摄建议指导下,每个参与者拍摄30个场景的多视角图像。对每个场景分别拍摄10张、20张、30张多视角图像,分别称为一个图像集合,理论上,如果拍摄规范每个图像集合都可以完成目标场景的三维恢复。把一个参与者拍摄的一个场景的图像组称为一组,实验图像组的总数量为b,本实验一共有900组图像。对900组图像进行多视角相机位姿可视化以及三维恢复结果分析,一共有4种情况,如表1所示。第一种情况是一组图像的10张、20张、30张的多视角图像集合都能恢复出三维点云,第二种情况是一组图像中仅有30张的图像集合不能恢复出三维点云,第三种情况是一组图像中仅有10张的图像集合可以恢复出三维点云,第四种情况是一组图像的10张、20张、30张的图像集合都不能恢复出三维点云。第一、二、三、四种情况出现的数量分别记为a1、a2、a3、a4。

表1 900组多视角相机位姿图像的恢复情况
该文把可以恢复出三维场景的多视图图像称为拍摄成功,在表1中使用‘√’符号标注,符号‘×’代表拍摄失败的多视角图像。在没有拍摄建议指导的情况下,拍摄的多视角图像集合的三维场景恢复的成功率如公式(1)(三维恢复的成功率Z=可成功恢复出三维点云的多视角图像集合A/所有进行实验的多视角图像集B)仅有(121×3+127×2+164)/(900×3)=28.93%。很明显,大部分参与者第一次拍摄多视角图像达不到三维恢复要求,仅有少数参与者的拍摄图像相机位姿分布较为规范,可以恢复三维场景。
(1)
根据实验结果,影响三维恢复的因素有图像集合的图像数量、图像集合的拍摄相机位姿分布等,实验表明相机位姿分布是最主要的影响因素。接下来,就实验中计算相机位姿出现的具体问题进行分析,并通过给参与者提供拍摄建议尝试解决这些问题。
2.2 拍摄存在问题一
图2所示是目标场景拍摄时相机视角间隔过大或过小导致的问题,图2左是拍照视角间隔过大导致图像间场景空间重合度不足,在特征匹配时无法在图像间匹配到相同目标特征的问题;图2右是拍照视角间隔过小导致图像间在小范围内空间过度重合,而在更大的目标围内重合度又不足的问题。

图2 无拍摄建议时的拍摄视角间隔问题
图3是比较规范的相机位姿拍摄视角分布,图3左表明相机分布比较规则,每个视角的间隔比较接近且不重合,图3右表明每个相机位置和主体场景的距离都约相等并呈弧线分布。由后期实验可知,规则的相机位姿分布明显提高了三维场景恢复的成功率。
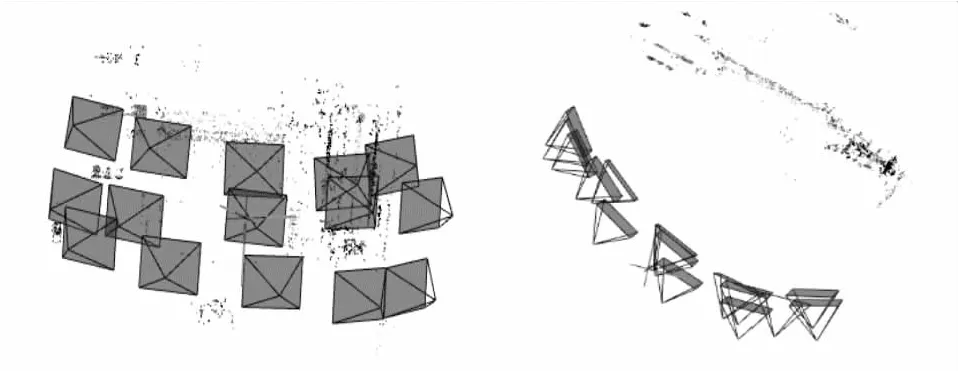
图3 规则的相机拍摄位姿分布
2.3 拍摄存在问题二
图4左右分别是在无拍摄建议下多视角图像成功恢复稀疏点云的效果,30张多视角图像集合的相机位姿只有28个视角有效,由于图片数量和能够恢复的相机位姿数量不同,导致在输入到MVS网络中进行稠密重建时直接出错。

图4 无拍摄建议时的部分相机位姿无效问题
规划拍摄的轨迹。实验参与者在拍摄时,提前规划好每一个拍摄视角,按照蛇形轨迹从左到右,从上到下进行拍摄可以有效提高拍摄图像相机位姿的有效性。
2.4 拍摄存在问题三
实验参与者拍摄的场景有室内和户外两种。户外场景优点是拍摄相机运动自由、光线充足等,拍摄时的相机位姿相对室内更整齐,完整性更高。弊端是目标场景过大导致拍摄的相机位姿轨迹比较单一,例如目标场景上方视角图像难以获取,第二个弊端是目标背景复杂,主体和背景距离较近,在稠密重建时导致的目标对象不突出、噪点多等问题。
为了验证是否由于现实场景的背景影响主体场景的三维恢复效果,实验使用Adobe Photoshop 2021手动剔除了24张多视角图像的背景,再进行三维恢复。图5是其中一幅图像的剔除背景前后对比图,对背景剔除的多视角图像进行三维场景恢复,图6左是未剔除背景的多视角图像恢复的三维点云,图6右是剔除背景后的多视角图像恢复的三维点云。可看出,剔除背景的三维恢复效果有明显改进,未剔除背景图片的重建结果看不出主体场景要表现的内容,由此实验可证明复杂背景的干扰会影响主体场景的三维恢复效果。

图5 剔除多视图背景的对比

图6 剔除背景前后的三维重建效果对比
虽然对图片背景做剔除处理在一定程度上解决了户外场景三维重建的问题,但其工作量比较大,需要将所有拍摄的照片进行背景剔除操作,浪费人力和时间。故可以借助相机的自动对焦或者模糊背景的功能,在拍摄户外场景时凸显主体场景,弱化背景影响。
2.5 拍摄建议
用户采集数据还应该注意以下问题:在采集过程中控制快门速度,避免模糊。围绕目标对象物体或环境采集尽量多的图像;在场景选择方面,应选择如图7(a)相近的光线充足、光照条件变化不剧烈的环境,如果是(如图7(d))光线较暗的环境,可以利用补光灯辅助补光。同时尽量避免选择的物体(图7(b))纹理单一;在重建物体的选择上,需要避免拍摄透明或半透明等强反光材料环境(如图7(c)),总之,图7(a)是弱反光、纹理复杂的材料,环境光线充足,是个良好的场景图像示例。


图7 目标场景的其他影响因素示例
总之,在图像采集任务中,相机、场景的选择是第一步,更重要的是拍摄时的相机位姿规划布设建议指导。首先,估计目标物体的中心点,如图8(a)使用一个虚拟球把目标对象包裹在虚拟包围球中,相机始终保持在接近虚拟包围球表面进行运动拍摄,并且相机光轴始终接近正对虚拟球的球心,具体位姿分布以图1左为参考。采用如图8(b)分布的蛇形拍摄轨迹获取更多的目标场景图像,户外拍摄可以使用自拍杆或无人机等设备布设更多条拍摄轨迹。

图8 拍摄建议
实验发现通过给用户提供目标场景拍摄建议,可降低所获取目标场景图像相机位姿分布的随机性,提高场景的三维恢复效果。
3 实验验证分析
3.1 实验配置
实验运行的PC平台配置如下:Windows10操作系统,Intel(R)Core(TM)i7-8700,NVIDIA TeslaK 40c,Intel(R) UHD Graphics 630。训练环境:python 3.7,Tensorboard2.6.0,Torchvision0.5.0,pytorch1.4.0,Opencv-python4.5.3.5。
硬件:手机:根据拍摄意见拍摄场景的多视角图像,注意拍摄视角和轨迹;补光灯:拍摄光线弱的场景时进行补光,减少光照对三维恢复效果的影响;软件:COLMAP-3.6-windows-no-cuda:计算并可视化多视角图像的相机位姿和稀疏三维点云,计算结果为相机、图像和位姿信息,可作为MVS网络的输入信息,相机位姿可视化方便用户观察拍摄图像的位姿并及时加以调整;Python:训练数据集并进行三维场景稠密重建;Meshlab:可视化三维点云。过程:拍摄图像数据,数据预处理,稀疏稠密三维恢复,优化三维模型,渲染重现。运用手机+Colmap+MVS+Meshlab的方式,实现了弱随机相机位姿图像的场景三维恢复。
3.2 三维恢复步骤
基于平面扫描的多视图立体视觉深度学习三维恢复的实现步骤如图9所示。
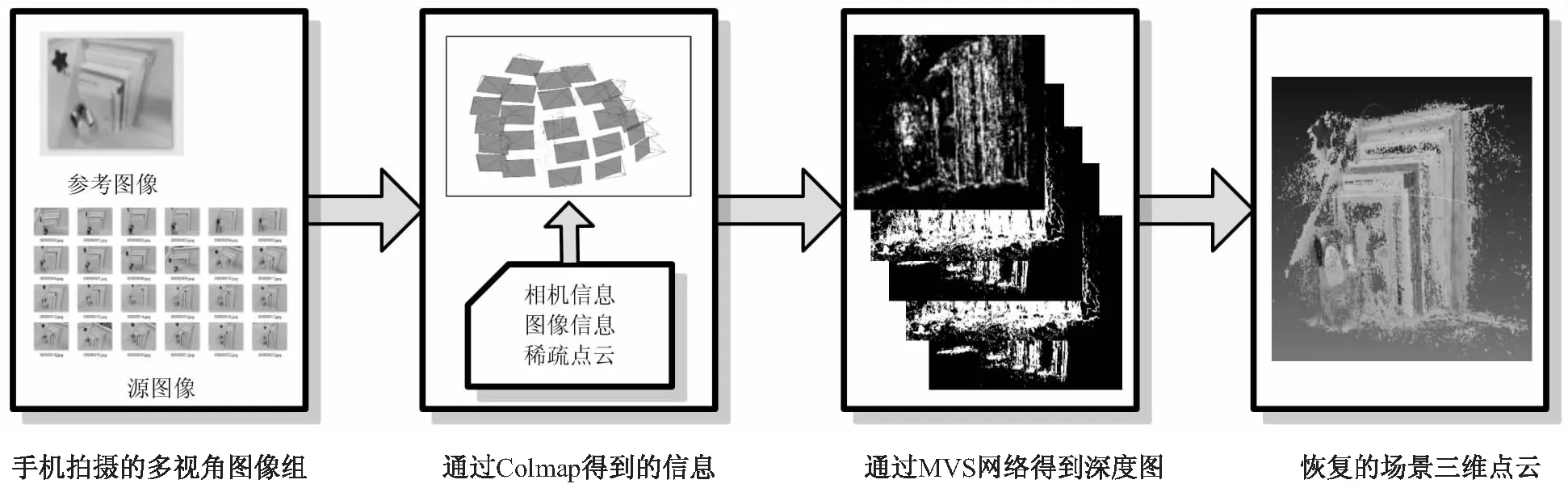
图9 三维场景恢复的完整流程
步骤一:用户根据指导建议使用手机或单反相机采集同一场景不同视角的多视角图像,图9左侧为手机拍摄的书桌场景的图像组示例。
步骤二:把用户拍摄的多视角图像输入到Colmap软件中,Colmap首先由SIFT算法进行特征提取,构建不同尺度空间进而获得更稳定的特征点,如公式(2)、公式(3),图像的尺度空间L(x,y,σ),由高斯核G(x,y,σ)与图像I(x,y)卷积获得,其中σ是尺度参数,是模糊处理规模的大小,σ值越大,图像越模糊。
L(x,y,σ)=G(x,y,σ)⊗I(x,y)
(2)
(3)
然后进行多尺度SIFT特征点匹配,最后利用对极几何关系去除错误匹配的特征点对。一组多视角图像分为一个参考图像和其他多个源图像,以参考图像的图像坐标系作为相机位姿的参考坐标系。假设某个源图像坐标系为P,某一点p的坐标为X1;参考图像为目标坐标系P',点p对应匹配点坐标为X2,已知参考图像的相机内参K1,外参(R1,t1),源图像的相机内参Ki,外参(Ri,ti),法向量n,n为目标平面法向量且朝向P,投影平面到对象平面的深度为d。通过求解P到P'的基础矩阵F(fundamental)、单应矩阵H(homography)和本质矩阵E(essential)获得源图像的外参,核心求解公式为公式(4)~公式(6)。具体的计算过程见文献[26]。

(4)
E=KTFK
(5)
(6)
步骤三:寻找一对初始的匹配图像对,结合步骤二方法通过奇异值分解SVD (Single Value Decomposi-tion)获得参考图像和源图像位姿,然后三角化生成三维点。通过每次增加一张新源图像方式进行增量重建,具体的计算过程见文献[21]。
步骤四:根据上述步骤,得到图9中第二个黑框中相机信息、图像信息、稀疏点云信息和相机位姿可视化结果;图10左上和左下是拍摄的两个场景的多视角图像,图10右上和右下是对应场景的相机位姿及稀疏点云可视化结果,其中右侧两幅图中的黑框内是稀疏点云的三维坐标系,是由步骤二中提及的参考图像坐标系转换而来,也是后期进行稠密重建的参考坐标系。

图10 多视角图像及对应的相机位姿
步骤五:根据图像拍摄时刻的摄像机位置姿态和稀疏三维点云,利用多视角立体匹配算法获取稠密三维点云;根据MVS网络[10]生成深度图和相应的置信度,进行滤波融合和稠密重建。根据一系列具有各自校准相机参数的图像,进行稠密点云恢复,恢复结果为图9最右侧的深度图和三维点云图。
计算深度图,即平面扫描立体。原理是通过多视角机位姿对同一物体进行拍摄,首先大致估计出物体的深度范围(即最小深度dmin和最大深度dmax),然后把深度范围划分为多个平行平面,判断图像上每个像素点在每个平行范围的匹配代价,最后选出最小代价,即为该像素点的深度值。
3.3 经过拍摄指导后的场景三维恢复效果展示
为验证数据采集指导建议对三维场景恢复的有效性,给予10位参与者拍摄建议,各拍摄30组多视角图像,实验发现,300组图像仅有57组不能恢复出三维场景,故在指导下拍摄出的多视角图像的三维场景恢复的成功率可达到(300-57)/300=81%。

图11 拍摄指导前后的三维点云对比
图11是在拍摄多视角图像时,进行拍摄指导前后的三维场景恢复对比图,左列是未经过指导拍摄的多视角图像的三维恢复效果,右侧是进行拍摄指导后的三维恢复效果。可以发现,图11第一行的左图中矩形框相较于右图矩形框中的三维点云缺失比较严重,点云完整性和三维恢复效果都稍差。图11第二行同理可观察到,在进行指导后的右图,用户拍摄的多视角图像在恢复出三维点云的视觉效果和点云精度方面都有较明显的提高。
图12是在建议指导下拍摄的多视角图像的三维场景恢复效果与真实场景对比展示,图12左列是拍摄的真实场景图像,图12右列是对应的三维场景恢复点云展示。可以发现,恢复的三维场景在点云精度、主体场景完整性方面和整体视觉效果上与目标场景十分接近。

图12 拍摄指导下的三维恢复效果展示
基于深度和颜色数据的三维重建是目前三维恢复的一个途径,需要通过深度相机获取场景的深度数据,相较于单纯基于图像数据的三维恢复其代价较高同时方便性也有所降低。该文在多视角图像获取方面研究也有助于融合深度数据源的三维场景恢复。
4 结束语
通过研究基于MVS深度网络的弱随机相机位姿图像的三维场景恢复,提出一系列拍摄建议,降低拍摄相机位姿分布的随机性,提升了三维恢复的效果。实验结果表明,普通用户经过指导能将自己拍摄的多视图二维图像转化为较高精度的三维模型。该文的文字指导容易存在歧义并且在实际操作时实现程度不高,故后期可以增加简易便携式辅助设备或辅助软件指导用户拍摄。比如规划轨迹和拍摄视角,也可在相机中加入基于AR的实时引导功能等。
总之,基于多视角的被动视觉三维重建依旧面临较大的困难。如透明或半透明,无纹理或重复纹理等都是三维恢复面临的挑战,在该方面的研究也需要尽快从研究转化到应用层面,使更多的普通消费级用户能够分享三维恢复重建带来的便利从而产生实际的应用价值。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
软件(2020年3期)2020-04-20 00:56:34
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
光学精密工程(2016年6期)2016-11-07 09:07:56
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
腹腔镜外科杂志(2016年12期)2016-06-01 12:10:09
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
