
基于Span方法和多叉解码树的实体关系抽取
2023-05-19 07:51:10冼广铭梅灏洋周岑钰刘赢方
计算机技术与发展 2023年5期
张 鑫,冼广铭,梅灏洋,周岑钰,刘赢方
(华南师范大学 软件学院,广东 佛山 528225)
0 引 言
作为自然语言处理领域的一个重要任务,实体关系抽取受到了广泛的关注和研究。早期,基于规则[1]或本体[2]的实体关系抽取方法过度依赖行业专家进行的大规模的模式匹配规则,在跨领域中可移植性差,极大耗费了人力物力。后来,随着传统机器学习的发展,以统计学为基础的机器学习方法显著提高了实体关系抽取的召回率和跨领域能力。
近些年,随着深度学习的发展,实体关系抽取的性能得到了极大的提升[3-5]。自从Hinton G等[6]提出深度学习方法以来,研究人员将深度学习应用到实体关系抽取任务中,取得了相当优异的效果。2012年,Socher R等[7]运用循环神经网络[8](Recurrent Neural Networks,RNN)进行实体关系抽取,并在该任务中融入了句子特征,然其忽略了位置信息的重要性;Zhang等[9]使用循环神经网络时虽然引入了位置信息,但循环神经网络存在远距离依赖问题;Zeng等[10]首次使用卷积神经网络(Convolutional Neural Networks,CNN)进行关系抽取,提取出更加丰富的特征,但是由于受到卷积核大小的影响,无法很好地提取出语义特征;李青青等[11]设计一种Attention机制的多任务模型,通过共享信息编码提升实体关系抽取的性能;李卫疆等[12]使用Bi-RNN解决词与词之间的依赖关系,并融入位置、语法、句法和语义信息进行实体关系抽取;Zheng等[13]将BiRNN和CNN模型融合成为联合抽取模型,通过共享BiLSTM的编码层,运用LSTM与CNN进行解码,解决了信息冗余问题,然而都无法很好地解决复杂实体中的实体重叠问题。并且以上所有方法由于使用单解码模型,都受到单解码强行执行某种顺序而带来的局限性。
随着预训练模型的兴起,以往的循环神经网络和卷积神经网络等逐渐淡去,新的神经网络Transf-ormer[14]逐渐受到广大研究者的青睐。对于Transfo-rmer等预训练模型,由Tang等[15]实验结果表明,相较循环、卷积等模型,Transformer在综合特征提取能力和语义表征能力上有较高提升。而近期,基于Transformer的模型BERT(Bidirectional Encoder Representation from Transformers)[16]凭借其合理的设计,在自然语言处理领域取得了重大突破,同时也备受实体关系抽取研究人员的青睐。其中Wei等[17]和Fan等[18]利用BERT预训练模型在关系抽取领域取得不错的效果。
针对实体关系抽取中的依赖信息不足、重叠实体获取效果低下、解码顺序问题进行研究,主要贡献为:一是使用GCN融入语句的句法特征,增强相关实体与关系之间的依赖性;二是使用基于span的方法,筛选出对应的实体信息;三是利用深度多叉解码树进行解码操作,最终得到相应的关系三元组。
1 模型框架
该文提出的基于Span[19]和DMFDT的实体关系抽取模型主要由四个部分组成,即使用预训练模型BERT编码层、基于GCN[20]的句子依赖性增强、基于Span的实体获取、深度多叉解码树抽取关系三元组。模型的实现流程如图1所示。
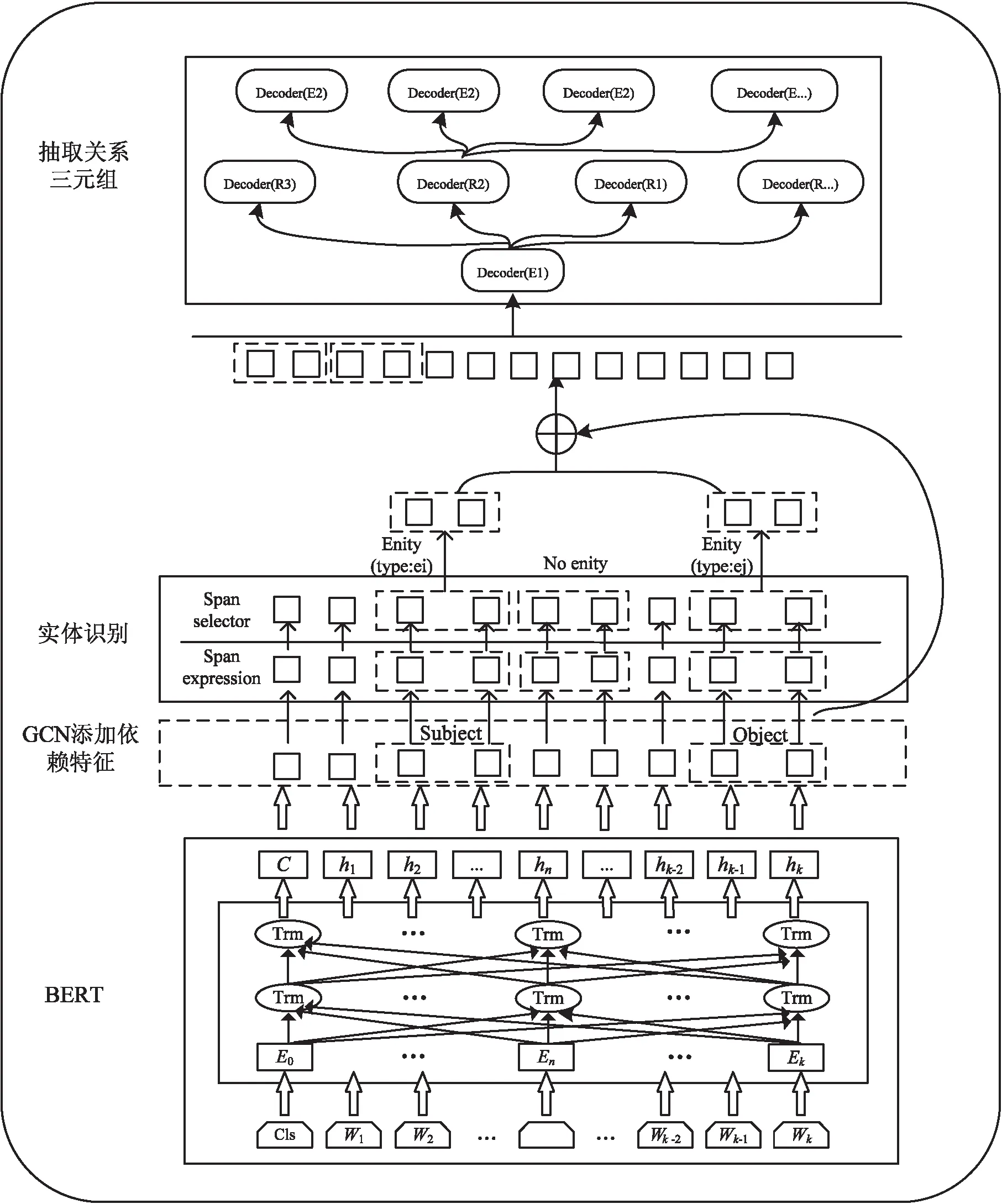
图1 基于Span和深度多叉解码树的实体关系抽取模型框架
1.1 BERT编码层
BERT预训练模型主要包含输入层和多层编码层,其中输入层由位置编码(PosEmbedding)和词编码(Token Embedding)等组成,并为其添加[CLS]和[SEP]标志位,也正因如此使得BERT具有较强的综合特征提取能力和语义表征能力。该文使用BERT编码器提取句子特征,为下游任务提供后续的H(隐藏层向量)。公式如下:
H=BERT(W)
(1)
其中,W={w1,w2,…,wn}为输入的句子;H=[h1,h2,…,hn]为相应位置词对应输出的隐藏层向量。
1.2 基于GCN的句子依赖性增强
对于BERT模型输出的隐藏层向量H,通过融合句法特征可以很好地利用词与词之间的依赖信息,然而在过往的实体关系抽取模型中往往忽略实体与关系本身在句法上的联系。该文综合前人的研究成果,将可以有效利用句法依赖信息的图神经网络(GCN)融入其中,以提高模型的抽取性能。对于给定的句子,使用Stanford CoreNLP工具生成相应的句法依存树[21],然后使用GCN运行依赖关系图,将相应的依赖信息融合到编码中。
1.2.1 使用GCN标记图
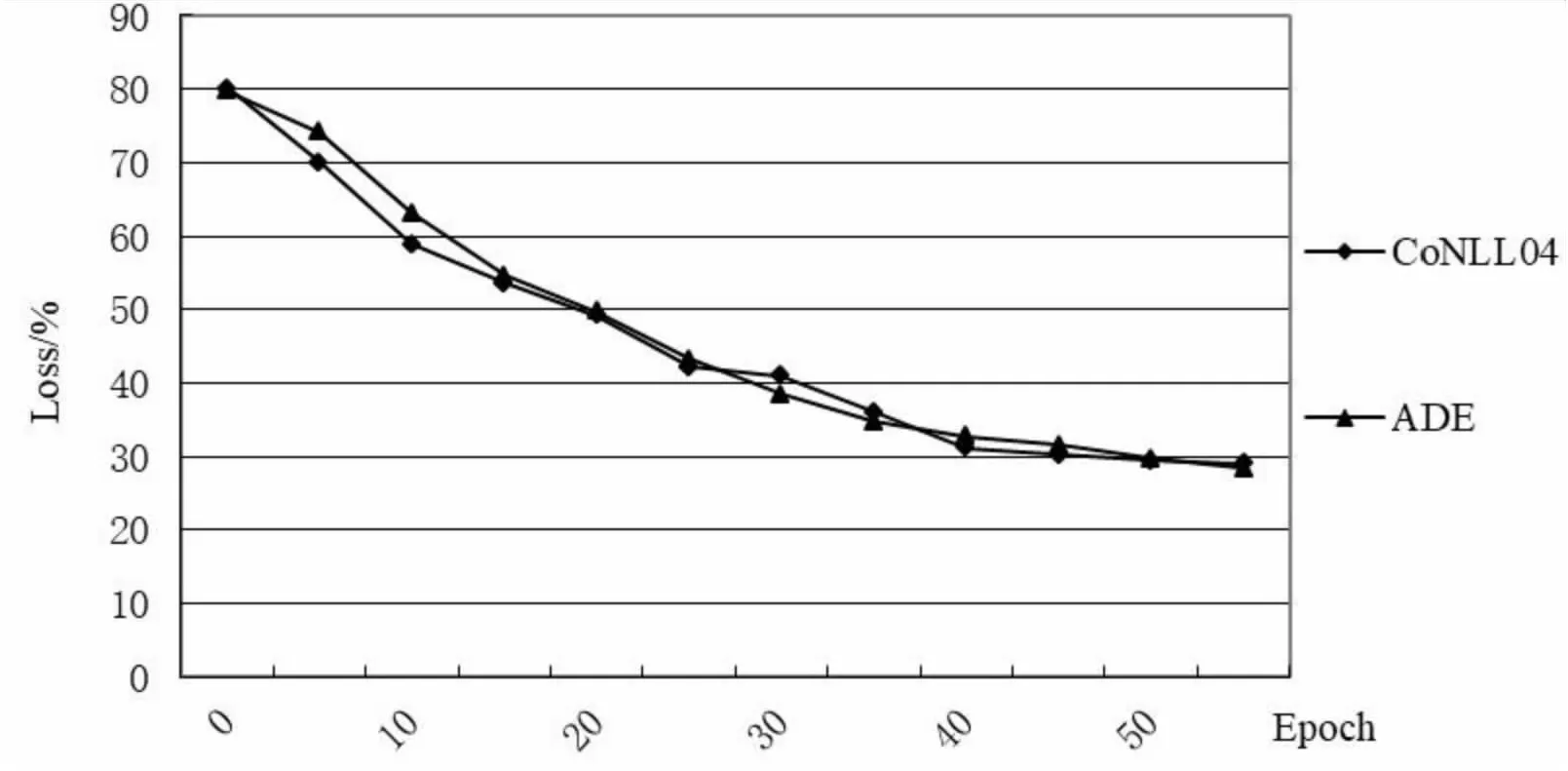
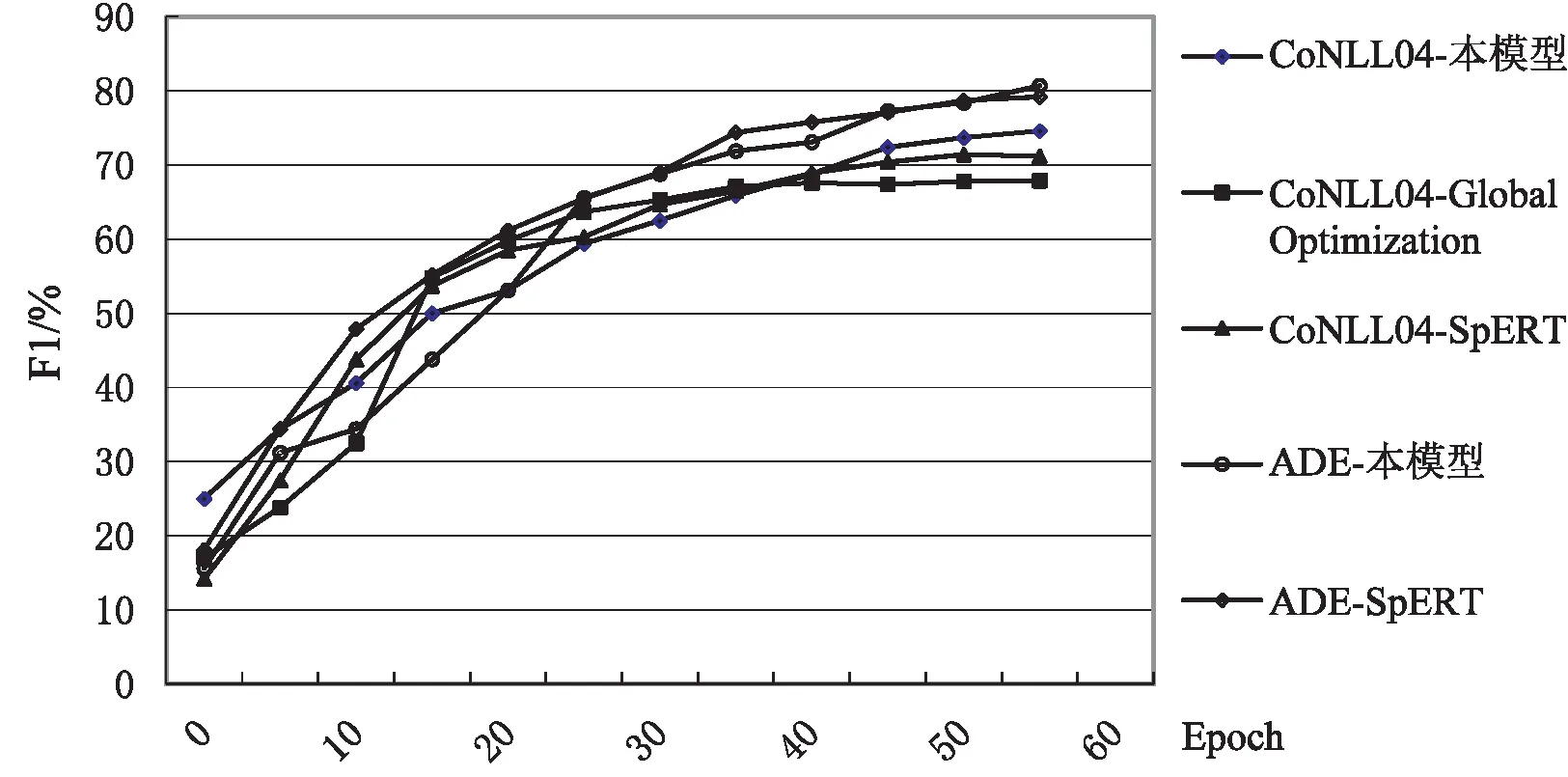
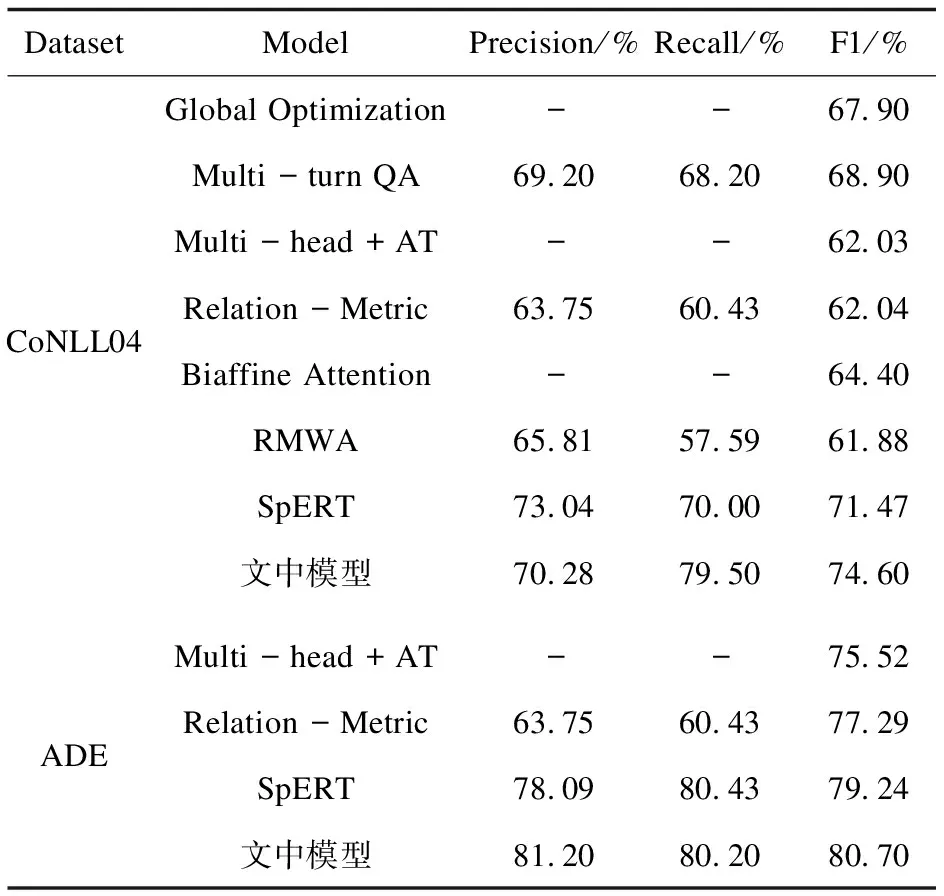
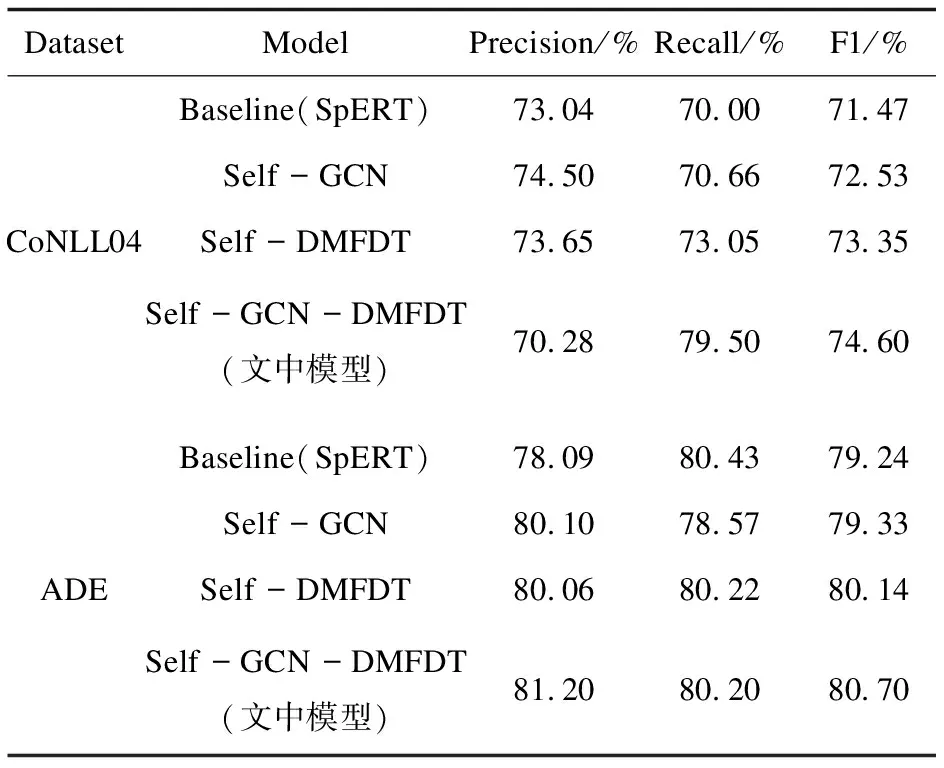
对于依赖关系图,G=(N,Ed),其中N和Ed表示节点(Node)和它们之间边(Edges)的集合。将任意的隐藏向量hi(1 (2) 其中,wLuv为权重,bLuv为偏置,F为非线性激活函数。 1.2.2 边处理 在生成的图中,可能会存在错误的边需要丢弃。因此,需要对生成的每一条边进行打分。通过打分,高分的边得到保留,低分的边被丢弃。用于计算最终边(hu,hv,Luv)取舍的公式为: Tuv=Score(huwLuv+bLuv) (3) 通过保留有效边,得到含有句法信息的隐藏v节点表示hv_side: (4) (5) (6) 将所有的边信息和BERT输出连接生成新的序列表达hGcn_s。 随着基于Span的实体关系抽取方法被提出,极大提升了过往基于BIO/BILOU标签方法[22]对重叠实体提取的效果。如在“food poisoning”中识别出“food”。基于Span的方法:任意标记的子序列(Span)都作为潜在的实体,例如:“Jones was diagnosed with food poisoning”中{“Jones”,“Joneswas”,…,“food”,“food poisoning”}等均可以作为潜在实体。通过Span selector得出相应的实体。基于Span的实体获取流程如图2所示。 图2 基于Span实体获取流程 1.3.1 Span表示 使用融合函数g生成候选Span表达式。且在已有研究上发现最大池化的效果最好。 (7) 根据前人研究,连接标记C(cls,表达上下文语义信息)对实体类型表达具有强有力的作用。因此,融入标记C。表达式如下: Xs=E(s)°C (8) 其中,Xs作为Span的最终表达,°表示连接符号。 1.3.2 Span分类器 将得到的Span表达输入到softmax分类器中,得到相应的实体类型。 ECs=softmax(Xs) (9) 其中,ECs表示实体类型得分。 将构成实体的Spans连接,表达相应的实体集合: (10) 然后将增强依赖性的上下文语句信息与实体信息进行连接,作为解码部分的输入。 hconcat=[X;hGcn_s] (11) 深度多叉解码树一改以往单解码的方式,运用多解码的方式更好地解决了单解码带来的模型容易记忆和过度拟合训练集中频繁出现的三元组顺序的问题。通过并行解码三元组(Triad),很好地解决了三元组执行顺序问题。例如:“Qian Xuesen was born in Shang hai,and graduated from Massachusetts nstitute of Technology andCalifornia Institute of Technology.”。如果解码时三元组的执行顺序为{Triad1,Triad2,Triad3}(单解码执行顺序如图3所示)。但是{Triad2,Triad1,Triad3}{Triad2,Triad3,Triad1}也是正确的。然而对于单解码情况下只能执行其中一种顺序。并且对于单解码情况,若出现如{Triad2,Triad3}这种顺序的数据,由于训练出来的模型将会高度拟合{Triad1,Triad2,Triad3}这种顺序,从而直接由Triad3结束,进而忽略了Triad1,在后期的应用中出现无法拟合三元组1的现象。因而,放弃以往的单解码的方式,使用多叉解码树的方式,解码关系三元组顺序如图4所示。 图3 单解码关系强制顺序执行 图4 多叉解码树关系执行顺序 e1=sig(Max(hconcatwe1+be1)) (12) 其中,we1为权重,be1为偏置,sig为sigmoid函数。 Possiblere=Sig(hconcatwr+br) (13) Possiblers=Sig(hconcatwr+br) (14) 其中,wr为权重,br为偏置。 对于实体2解码层与实体1类似,在整个序列上预测实体1和关系R对应的实体2,最终得到构成的三元组。 e2=Sig(Max(hconcatwe2+be2)) (15) 其中,we2为权重,be2为偏置。 损失函数作为评价模型输出值(预测值)与真实目标的相似程度。因此,选择合适的损失函数对模型的性能来说至关重要,不同的模型损失函数一般也不一样。通过对比多个损失函数的,该模型最终使用Hinge损失函数,它的标准形式如下所示: L(y,f(x))=max(0,1-yf(x)) (16) 其中,f(x)是预测值,Hinge损失函数的特点:使用Hinge损失函数如果被分类正确,损失为0,否则损失为1-yf(x);f(x)在-1到1之间,使得分类器并不过度打分,让某个正确分类的样本距离分割线超过1并不会有任何奖励,从而使得分类器更加专注于整体的误差,y是目标值(-1或1);具有较高的健壮性。 该模型使用的Hinge损失函数为MultiMarginLoss,公式如下: Loss(x,y)= (17) 其中,x为神经网络的输出,y是真实的类别标签,w为每一类可传入相应的权值,margin默认为1。 为了测试该模型的性能,使用实体关系抽取领域公开数据集CoNLL04、ADE进行实验。CoNLL04数据集包含了从新闻中提取出来的带有注释的命名实体和关系的句子。其包含LOC、ORG、PER、OTHERS四种实体类型和Located in、Work for、Organization based in、Live in、Kill五种关系。ADE数据集包含了从医学报告中提取出的4 272个句子和6 281个关系。它包含了一种单一的关系Adverse Effect和两种实体类型Adverse Effect、Drug。 实验采用Pytorch框架,使用谷歌云盘和谷歌Colab作为实验环境,使用Python编程语言。 在模型训练过程中,将batch_size设置为32;根据数据集合理设置语句的长度(max_length);根据日常训练过程中损失函数的收敛情况,设置失活率(drop out)和学习率(learning rate)分别为0.1、1e-4;设置hidden_size为768。使用Multi-MarginLoss损失函数和Adam(Adaptive Moment Estimation)算法优化模型参数。 将所提模型与目前该领域主流基线模型进行比较。其中用于比较的模型如下: (1)Global Optimization[23]:将双向 LSTM和全局优化结合在一起,命名实体识别和关系抽取同时进行。 (2)Multi-turn QA[24]:将实体关系抽取任务转换为多问答任务,即将实体和关系的提取转换为从上下文识别答案跨度的任务。 (3)Multi-head+AT[25]:将对抗训练应用到联合实体关系抽取模型当中。 (4)Relation-Metric[26]:结合CNN(卷积神经网络)和metric learning(度量学习)的思想应用到端到端的关系抽取任务中。 (5)Biaffine Attention[27]:提出了一种端到端神经网络的抽取模型。其采用BiLSTM-CRF体系结构进行实体识别,使用双注意力机制的关系分类。 (6)Replicating Multihead with AT[28]:使用CRF将实体识别和关系抽取任务建模为多头选择任务。 (7)SpERT[29]:一种基于预训练模型BERT和Spaner的实体关系联合抽取模型,是一种和文中同样使用BERT和Span方法的关系抽取模型,但相对于文中模型未使用依赖增强和多叉解码方法。 其中Multi-head+AT、Biaffine Attention、RMWA模型使用不同的RNN-CRF方法进行关系抽取;SpERT使用基于BERT和Span的方法进行关系抽取;模型Global Optimization、Multi-turn QA、RelationMetric使用关系抽取的其他方法进行关系抽取。 为了评估文中模型的优劣性,实验结果主要采用准确率P(precision)、召回率R(recall)以及F1进行评估。其中计算准确率、召回率、F1值之前,首先要得到TP(预测为真且实际正确的样本数)、FN(预测为假且实际正确的样本数)、FP(预测为真且实际为假的样本数)、TN(预测为假且实际为假的样本数)。然后进行如下计算: (18) (19) (20) 为了更好地展现文中模型的效果,在数据集CoNLL04、ADE上进行了对比实验和消融实验。 2.4.1 模型对比实验分析 文中模型以BERT模型作为词编码层,基于Span的方式获取实体信息,并通过GCN增强词与词之间的依赖性,最后运用深度为多叉解码树对实体关系三元组进行解码,得到实体与对应的关系。损失函数值与训练次数如图5所示,可以直观地看到,随着训练次数的增加,模型的loss逐渐减少,当loss值分别为0.3、0.28左右时,模型在CoNLL04、ADE数据集上趋于收敛。 图5 损失函数值与训练次数变化 图6展示的为文中模型、Global Optimization模型、SpERT模型在数据集CoNLL04与ADE上F1值随着训练次数增加的变化曲线。可以看到,在CoNLL04数据集上Global Optimization模型的最优F1值明显小于文中模型和SpERT,由此说明了基于预训练模型和Span方法的优越性。在数据集CoNLL04、ADE上,对于SpERT模型,虽然也取得了不错的效果,但相比文中模型F1值分别低了3.13百分点、1.54百分点,由此可见文中模型使用依赖增强和多叉解码树的优越性。 图6 文中模型、Global Optimization、SpERT 模型的F1与迭代次数变化 由表1中的实验结果对比可知,在Co-NLL04数据集上,文中模型相比Multi-head+AT、Biaffine Attention、RMWA等RNN-CRF类型网络模型的F1值分别高出12.57百分点、10.2百分点、12.72百分点,说明使用预训练模型和Span方法要明显优于使用RNN-CRF方法的模型。通过文中模型与Global Optimization、Multi-turn QA、RelationMetric等其他关系抽取方法对比结果可知,文中模型在CoN-LL04数据集上效果要比以上三种模型分别高出6.7百分点、5.7百分点、12.56百分点,在数据集ADE上文中模型也要比Multi-turn QA、Rel-ationMetric模型分别高出5.18百分点和3.14百分点,由此也说明了即使在一些优化方法的作用下,文中模型依然具有相当大的优势。根据文中模型与SpERT模型的实验结果对比可以看出,文中模型使用GCN增强依赖性下的多叉解码树方法的提取效果在CoNLL04、ADE数据集上要比SpERT模型高出3.14百分点、1.46百分点(GCN、多叉解码树各自优势见消融实验)。由此可见,文中模型具有极好的优越性。 表1 实体关系抽取对比实验结果 文中模型性能较优主要因为使用实体提取能力更强的Span方法和更具优越性的多叉解码方法,以及使用了综合特征能力提取更强的预训练模型和GCN进行词与词之间依赖增强。 2.4.2 消融实验与分析 为了验证提出的多叉解码树和使用GCN融入依赖特征的效果,做了以下消融实验: (1)Baseline(SpERT):不使用多叉解码树和GCN,使用单解码的方式也即模型SpERT的效果。 (2)Self-GCN:文中模型只进行依赖增强但仍使用单解码的方式。 (3)Self-DMFDT:不融入依赖增强信息,将单解码换为多叉解码树进行解码。 (4)Self-GCN-DMFDT(文中模型):将2中的单解码的方式换为多叉解码树的方式。 从表2可见,在CoNLL04、ADE数据集上,Self-GCN相比于Baseline (SpERT)模型分别提升1.06百分点和0.09百分点,由此证明了通过GCN进行词与词之间的依赖增强,模型的性能可以得到一定的提升。而Self-DMFDT相比于Baseline(SpERT)模型的实验结果证明,通过使用多叉解码树进行并行解码在两种数据集上可以使模型性能提升1.88百分点、0.9百分点,由此也证明了多叉解码树的优越性。对于融合了两种方法的模型也即文中模型相比Baseline (SpERT)在两种数据集上达到了3.13%和1.54%。由此证明使用依赖增强和多叉解码方法对模型的效果有一个不错的提升。 表2 消融实验结果 该文提出一种基于Span方法和深度多叉解码树的实体关系抽取模型。该模型通过利用句法依赖信息提升下游实体识别和关系抽取的效果。下游任务中基于Span方法更好地获取重叠实体的同时,使用多叉解码树成功地避免了单解码的执行顺序问题。实验结果表明,该方法在CoNLL04、ADE数据集上明显比先前方法优越。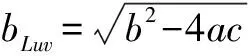


1.3 基于Span的实体获取
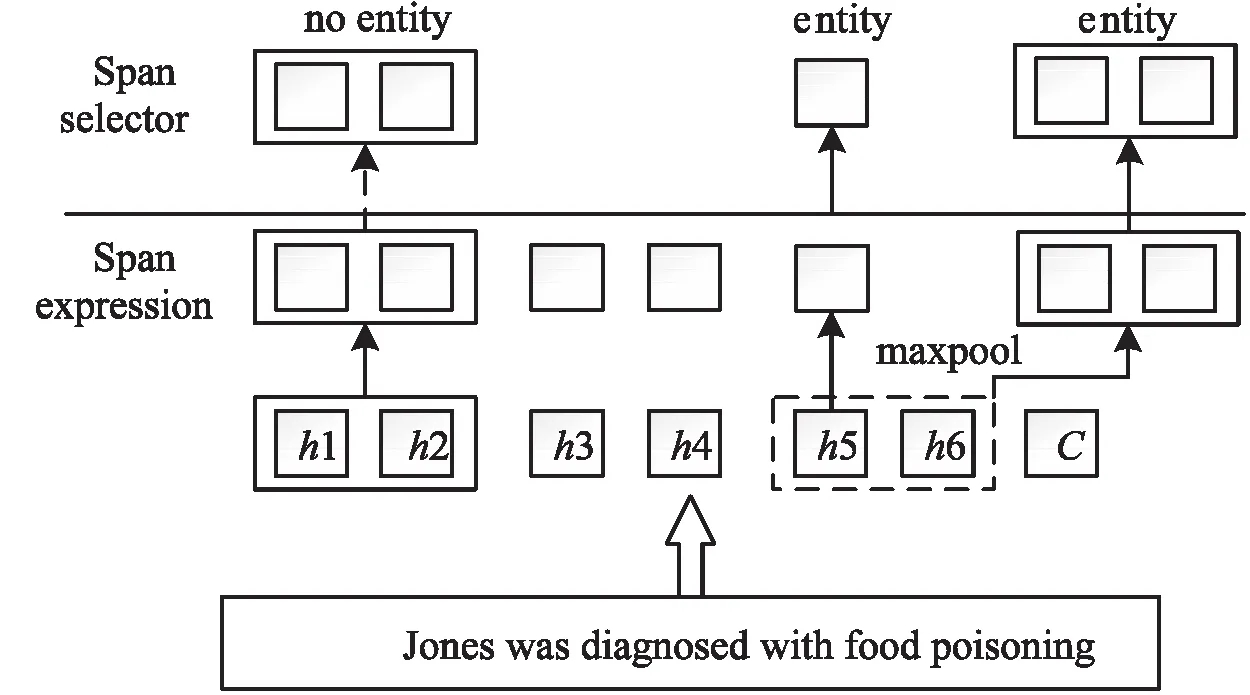

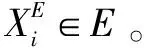
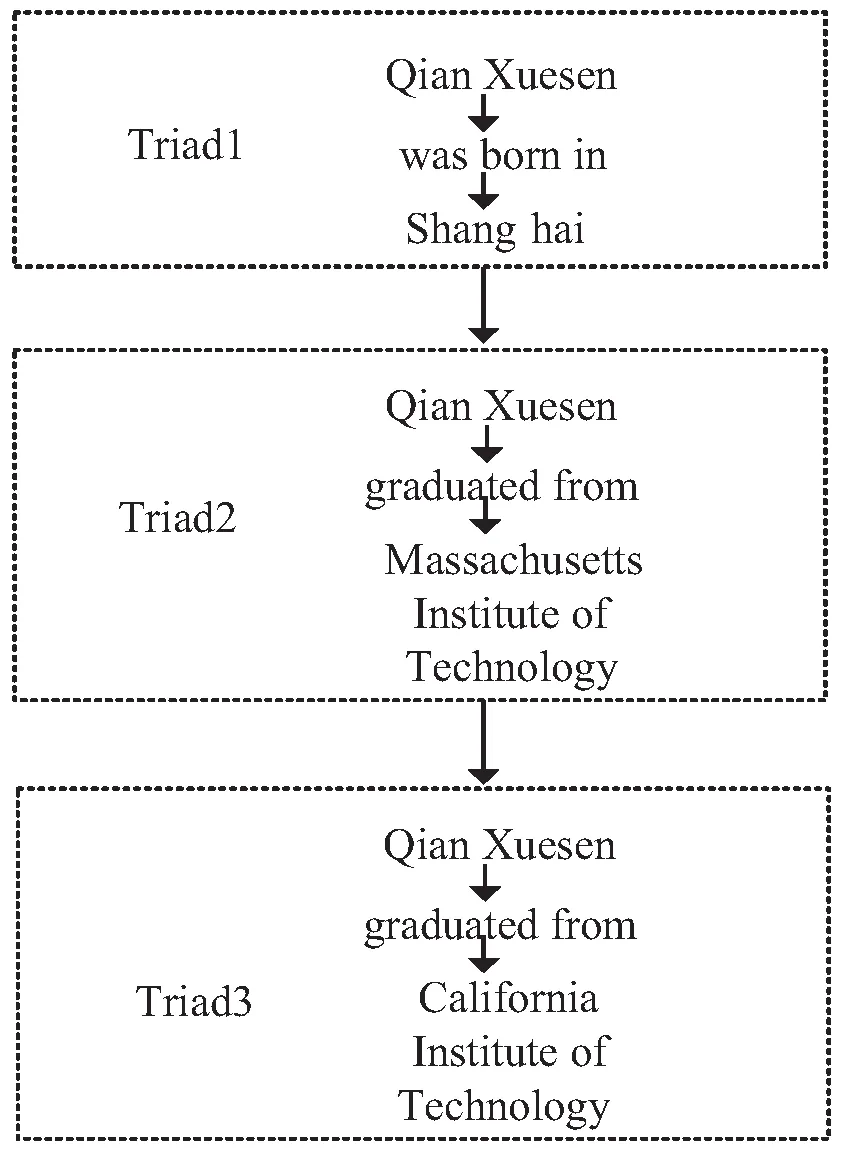
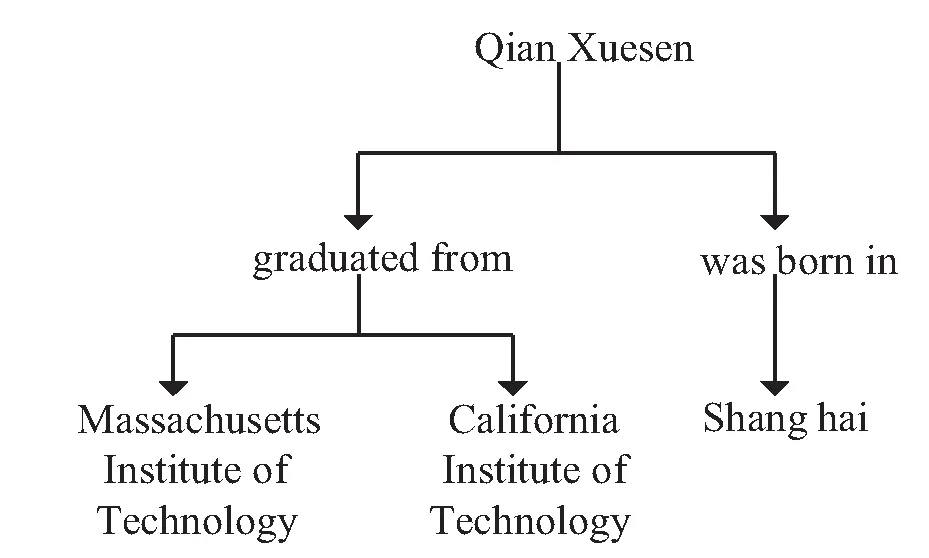
1.4 深度多叉解码树抽取关系三元组
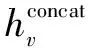
1.5 损失函数
2 实 验
2.1 数据集
2.2 实验环境与参数设置
2.3 基线模型与评价指标
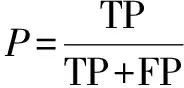
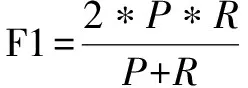
2.4 实验结果与分析
3 结束语
猜你喜欢
软件工程(2024年12期)2024-12-28 00:00:00
计算机与数字工程(2023年5期)2023-08-31 08:40:44
中国石油石化(2022年12期)2022-07-16 08:28:28
中国外汇(2019年19期)2019-11-26 00:57:32
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
