
一款人工智能芯片上FCOS模型的应用研究
2023-05-19 07:50:58林广栋黄光红陆俊峰
计算机技术与发展 2023年5期
林广栋,黄光红,陆俊峰
(中国电子科技集团公司第三十八研究所,安徽 合肥 230094)
0 引 言
近年来,深度学习模型在计算机视觉、语音处理等人工智能领域得到了越来越广泛的应用,很多应用领域要求快速且低功耗地完成深度学习模型的推理。例如,在自动驾驶领域,要求深度学习模型在限定的时间内完成图像传感器拍摄的图像中的目标识别任务;在手机等端侧设备中,要求进行图像识别、目标检测的深度学习模型的能耗尽可能小;在大型数据中心,能耗已经成为其成本的重要组成部分,降低深度学习模型在数据中心推理和训练的能耗成为降低数据中心成本的重要因素。然而,深度学习模型的参数量和计算量巨大,在传统的CPU/DSP上难以完成高性能且低功耗的推理。因此,专门用于深度学习模型推理的人工智能芯片成为目前研究的热点,且已经有成熟的产品出现[1-2]。中国电子科技集团公司第三十八所研制了一款人工智能芯片,该芯片是一个异构的SOC(System On Chip)芯片,由支持通用软件的中央处理核心(Central Processing Unit,CPU)和神经网络加速核(Neural Network Accelerator,NNA)构成。其中CPU负责一般的软件(如Linux或嵌入式操作系统)的运行,而NNA负责在CPU的调度下完成数值计算密集的神经网络推理任务,两者配合高效地完成深度学习模型的推理。FCOS模型是目前比较先进的一种单阶段无锚框的目标检测深度学习模型[3],该模型首次提出了对目标框内的所有特征点输出目标的位置并进行训练的机制。这种机制在后续很多新的目标检测深度学习模型中得到应用。该文研究了FCOS模型在该人工智能芯片上的硬件加速技术,介绍了深度学习模型在该人工智能芯片上部署的一般流程,并研究了人工智能芯片的关键配置如算力、DDR带宽、数据类型对推理性能、最终效果的影响。
1 FCOS模型介绍
FCOS是一个一阶段的不基于锚框的目标检测深度学习模型。与其他的一阶段深度学习模型类似,它不需要提取候选区域然后在候选区域上执行图像分类操作。与yolo系列基于锚框的目标检测模型相反,它不需要预先设计和定义锚框。它针对输出特征图的每个位置,输出这个位置上的目标的左上角、右下角顶点相对于该位置的偏移。FCOS模型由骨干(backbone)网络、颈(neck)网络、头(head)网络组成,其中骨干网络负责提取图像不同层次的特征,颈网络负责把不同层次的特征融合,而头网络负责根据不同尺度的特征得到最终的输出。它同样采用了特征金字塔格式的输出,输出层共5个分支,分别代表不同尺度下目标的检测信息。FCOS目标检测模型的骨干网络和颈网络的结构如图1所示。
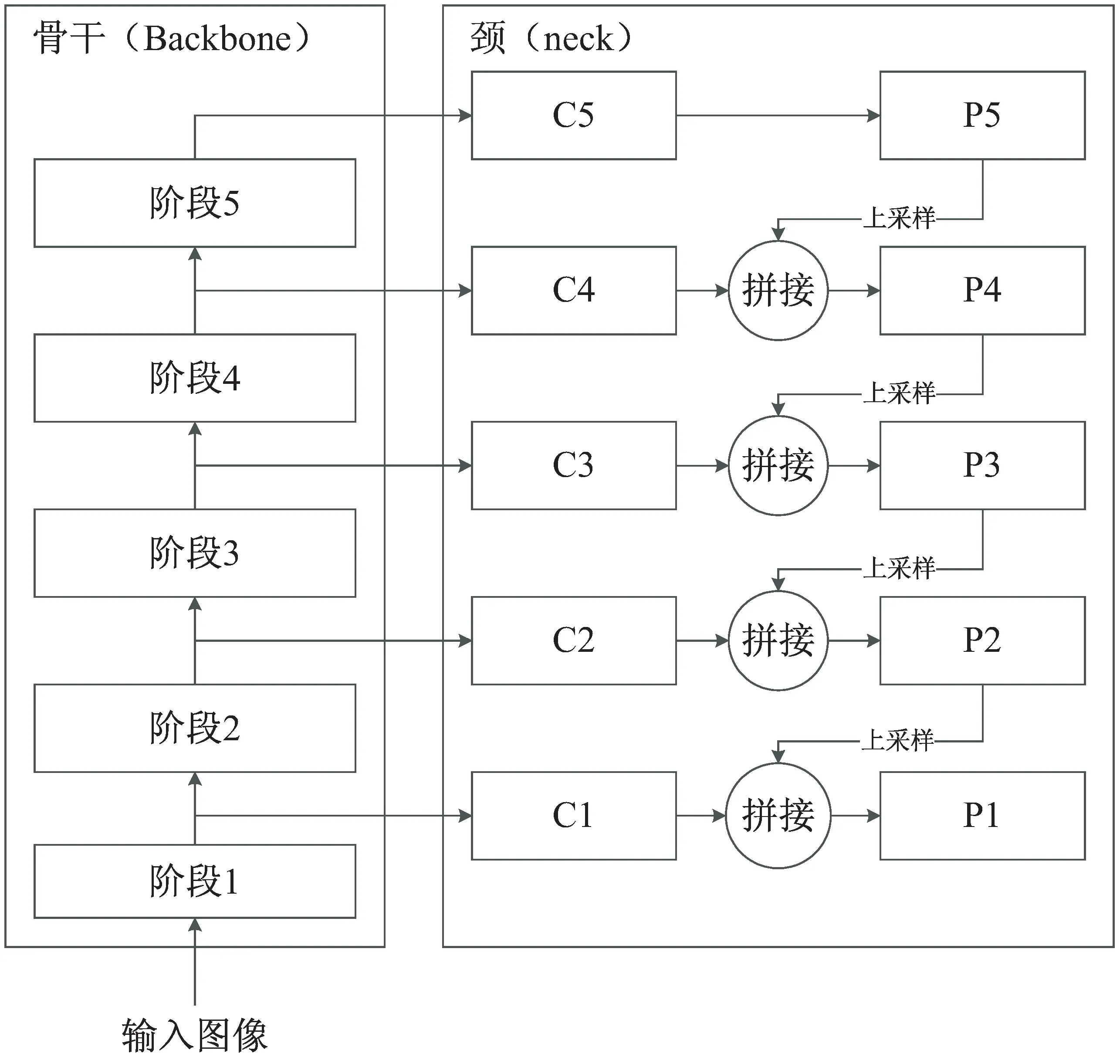
图1 FCOS深度学习模型骨干及颈网络示意图
其头部网络的结构如图2所示。该图仅仅是输出的五个分支的一个分支示意图,像这样的输出结构在五个分支中都存在。该头部由三类小分支组成,分别是以softmax方式处理后代表该位置目标属于各类别的概率的分支,代表该位置处于目标的中心位置的程度的centerness分支,代表目标左上角、右下角位置的偏移的分支。若目标有N个类别,这三个小分支的通道数分别为:N、1、4。整个模型共5*(N+1+4)个输出通道。
FCOS目标检测深度学习模型提出了一种新的从图像中提取更多训练数据的方法,即位置在真实目标框里的点都可以输出目标的位置,都会进行训练。其于FCOS模型的思想,很多新的模型被提出,如FCOS-3D[4]、TTFNet[5]等等。相比于yolo系列目标检测深度学习模型,FCOS模型不需要设置锚框,更便于训练,未来将在工业界得到更广泛的应用。

图2 FCOS深度学习模型头部网络示意图
2 一款人工智能芯片架构介绍
中国电子科技集团公司第三十八研究所研制了一款人工智能推理芯片,其深度学习推理核心的理论峰值性能达到16TOPS(INT8),支持int8、uint8、int16、float16、bfloat16等数据类型。该芯片的核心SOC架构如图3所示。

图3 一款人工智能芯片硬件架构
该芯片是一个由深度学习推理加速核NNA与通用处理器CPU构成的异构计算系统,两者通过片上总线进行交互。CPU通过AHB总线配置NNA的寄存器,而NNA通过AXI总线访问片上存储器与片外的DDR,CPU和DDR通过片上存储器与片外的DDR共享数据。NNA内部由4个同构的计算核构成,每核理论峰值算力为4 TOPS(INT8),4个核可以一起工作完成同一个任务,也可以分别执行不同的任务。该芯片的高速外设主要包括用于网络通信的以太网接口(Gigabit Media Access Control,GMAC)和用于PCIE协议通信的PCIE接口。该芯片工作时,首先由CPU配置NNA,使其获取到待执行的神经网络模型的信息,如神经网络模型的结构、权重信息。由CPU控制GMAC或PCIE接口从片外设备(如传感器芯片)获取待处理的输入数据,存储在DDR上。之后CPU控制NNA读取输入数据,执行神经网络模型的推理过程,并把神经网络模型的输出结果写到DDR上。之后CPU再控制GMAC或PCIE把计算结果传输到片外设备,进行下一步处理。该芯片配置了一块片上存储器(On Chip Memory,OCM),该存储器相比DDR的访问带宽更高。神经网络推理过程中产生的需要反复使用的中间数据,如中间特征图的值,优先存放在OCM上,以提高推理效率。
3 FCOS模型部署步骤
该人工智能芯片提供了完善的软件工具链来支持深度学习模型的部署,包括如下步骤:
①导入:将各种深度学习软件框架生成的模型文件解析为该人工智能芯片内部的模型表示方式,以便后续处理。
②量化:深度学习软件框架中一般用浮点数表示深度学习模型,而如果量化为低位宽的定点数在芯片上进行实时推理,将可提高推理速度[6-7]。对深度学习模型的量化有两种方式:量化敏感的训练[8](Quantization-Aware Training,QAT)、训练后量化[9](Post-Training Quantization,PTQ)。前者在量化完成之后再使用训练数据对量化后的模型进行精调。后者在训练完成之后根据一些测量数据对激活度的范围进行测量后直接量化。该人工智能芯片配套工具链使用的是训练后量化方法。量化时,需要提供少量测试数据,软件工具链会对这些输入数据执行推理过程,以得到深度学习模型各层特征图的取值范围,再进行量化,以使量化后的定点数最大程度地覆盖原始模型的浮点数的取值范围。深度学习模型的量化分为不同的层次,包括逐层量化[10]、分组量化[11]、逐通道量化[12]等等。该人工智能芯片的软件工具链的量化算法均使用逐层量化的方式。深度学习模型在芯片中的量化推理方式按量化参数是否动态变化又可分为两类:动态量化[13]、静态量化[14]。前者的量化参数会在运行时根据实际激活度的变化范围进行调整;而后者的量化参数在推理前确定,并在运行时保持不变。该人工智能芯片的软件工具链的量化方式是静态量化方式。
③优化:该人工智能芯片的软件工具链内部以计算图的方式表示深度学习模型,基于计算图,可以执行如算子合并、冗余计算删除等计算图优化操作,在不降低精度的基础上提高性能。
④导出:把经过量化、优化后的深度学习模型保存下来,输出为模型文件。该人工智能芯片的模型文件同时包含模型的结构与量化后的权重。
⑤推理:芯片上的驱动在应用程序的调用下,加载并解析模型文件,根据具体的硬件配置对计算图执行进一步的优化,并执行实时的模型推理任务。
4 量化方式
由于深度学习模型中的权重存在一定冗余性,因此把权重及激活度量化为低位宽的数据,可以在不明显降低模型精度的前提下减少模型的计算量、减小模型的大小,进而减少模型推理时对于片外数据传输带宽的需求,最终提高模型推理的效率。量化算法主要分为两类:对称量化[15]和非对称量化[16]。当以对称量化算法量化为8位时,数据类型称为int8;当以非对称量化算法量化为8位时,数据类型称为uint8;当以对称量化算法量化为16位时,数据类型称为int16。
4.1 INT8
量化为INT8方式时,由浮点数转换为定点数的计算方式为:
首先计算中间值:
data=round(fdata*2fl)
然后计算最终量化值:
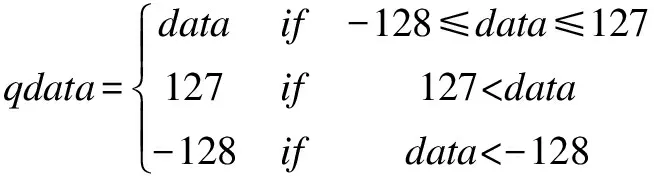
而由量化后的INT8值计算原始浮点值的方式如下:
fdata=qdata*2-fl
其中,fl是进行INT8量化后的常数,每一层的权重与每一层的激活度在量化后有不同的fl值,分别根据该层权重与激活度的分布计算得到。其中权重的fl的计算方法如下:
fl=7-「log2(max(abs(w)))⎤
其中,max(abs(w))代表一层的权重的绝对值的最大值。激活度的fl按类似的方法根据激活度的分布计算得到。
4.2 UINT8
UINT8型量化将权重和激活度都量化为无符号的8位数,量化后的数值范围在0~255之间。由浮点数计算UINT8量化数的计算方式如下:
首先计算中间值:
data=round(fdata/scale+zeropoint)
然后计算最终量化值:
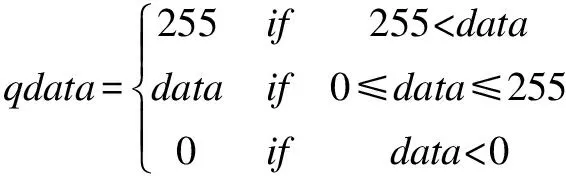
而由量化后的UINT8型数据转换为浮点数据的计算方式为:
fdata=(qdata-zeropoint)*scale
其中,scale和zeropoint为根据特定算法计算得到的缩放因子与零点。以计算某一层的权重的scale和zeropoint为例,记神经网络某层的权重的最大值为max(w),最小值为min(w),则该层的权重量化为UINT8时的scale和zeropoint的计算方式如下:
scale=


4.3 INT16
量化为INT16方式时,由浮点数转换为定点数的计算方式为:
首先计算中间值:
data=round(fdata*2fl)
然后计算最终量化值:
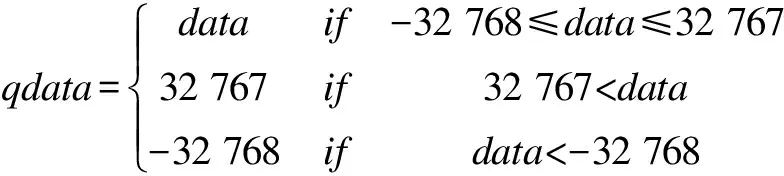
而由量化后的INT8值计算原始浮点值的方式如下:
fdata=qdata*2-fl
其中,fl是进行INT8量化后的常数,每一层的权重与每一层的激活度在量化后有不同的fl值,分别根据该层权重与激活度的分布计算得到。其中权重的fl的计算方法如下:
fl=15-「log2(max(abs(w)))⎤
其中,max(abs(w))代表一层的权重的绝对值的最大值。激活度的fl按类似的方法根据激活度的分布计算得到。
4.4 FLOAT16
FLOAT16是IEEE规定的标准数据格式,共16位,各位的含义如表1所示。

表1 FLOAT16数据类型
4.5 BFLOAT16
在深度学习领域,由于网络模型中存在大量参数,这些参数具有大量的冗余性,精确地表示这些参数的重要性降低。在深度学习模型推理领域,人们开始使用bfloat16数据类型,这种数据类型相对于常规的float16数据类型降低了尾数的位宽,增加了指数的位宽,其效果是增加了其表示的数值的范围,减少了表示的精度。这种数据类型能在与float16相同的数据位宽下以较低的精度表示更大的数据范围,比较适合深度学习领域。这种数据类型各位的含义如表2所示。

表2 BFLOAT16数据类型
5 实 验
以下实验基于中国电子科技集团公司开发的针对该人工智能芯片的演示板卡完成,该演示板卡实物图如图4所示。

图4 一款人工智能芯片演示板卡实物图
以下实验中,FCOS模型的输入图像宽度为1 216,高度为800,总卷积计算量约为138 GOPS。
5.1 片上存储器的影响
该人工智能芯片内部设置了4 MB大小的片上存储器。片上存储器的访问延迟比片外的DDR小得多,并且其带宽可以达到片上总线传输带宽的上限。将FOCS模型量化为精度比较高的INT16数据类型,分别控制使用不同大小的片上存储器,对性能的影响如表3所示。

表3 片上存储器大小对FCOS模型推理时间的影响
由表3可以看出,使用芯片内部的片上存储器可以提高深度学习模型的推理速度。当然,片上存储器会增加芯片的面积与功耗,其容量不可能设置太大,需要在推理性能与芯片的面积和功耗之间进行平衡。
5.2 DDR带宽的影响
深度学习模型推理时,其中间层的通道数量很大,使得中间层特征图无法在片上存储器全部存储,需要在片外容量更大的DDR中暂存。这就导致深度学习模型推理时需要进行大量片上数据与片外数据的传输,因此,DDR的带宽对模型推理的性能影响很大。将FCOS模型量化为INT16数据类型,然后分别配置DDR控制器的频率为不同的数值,在不同的DDR带宽下进行推理,模型推理的性能如表4所示。该芯片使用DDR控制器数据位宽为64位,理论峰值带宽(bandwidth)与频率(frequency)的关系为:
bandwidth=frequency*64
其中,频率的单位为MHz,而带宽的单位为Mbit/s。
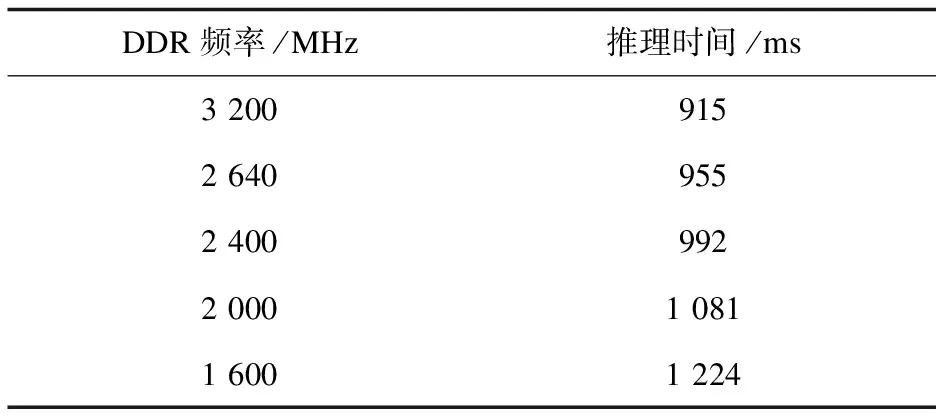
表4 DDR带宽对FCOS模型推理时间的影响
可见,随着DDR频率的降低,推理性能也呈现明显的降低。显然,DDR带宽对推理性能有着重要的影响。
5.3 DDR配置的影响
DDR有很多配置选项,包括配置各AXI端口的优先级、带宽限制、是否使能bank group、写命令重排、命令队列选择等等。对DDR控制器的不同属性进行配置的寄存器数量多达三百多个。同DDR的带宽配置一样,DDR的各项配置也会对推理性能产生影响。该文无法穷尽所有的DDR配置,仅就是否使能bank group、是否打开写重排功能、是否打开命令选择功能三个选项进行实验,检验这些配置对推理性能的影响。表5为几种典型的DDR配置及不同的DDR带宽下FCOS模型的推理性能,该表中的数据均是在模型量化为INT16数据类型、使用4核推理、片上存储器容量为4 MB时统计出来的。
其中bank group是DDR4设备专用的概念,它把区分bank group的第[0]地址放到区分DRR颗粒“列”的地址位中,使DDR控制器同时维护两个bank group的状态,可以以更高的效率支持连续的burst读写。在本芯片的DDR配置中,支持bank group时,bank group的第[0]位位于软件视角的地址的第[6]位。当DDR收到的burst请求大于64 byte时,使能bank group的效果更好。但实验表明,使能bank group这个功能(bg_rotate_en)反而会降低性能,这是因为NNA发出的burst请求大小一般为64个byte或更小,而很少发出更大burst请求,这是由NNA的核心架构决定的。因此,NNA无法利用bank group的优势。
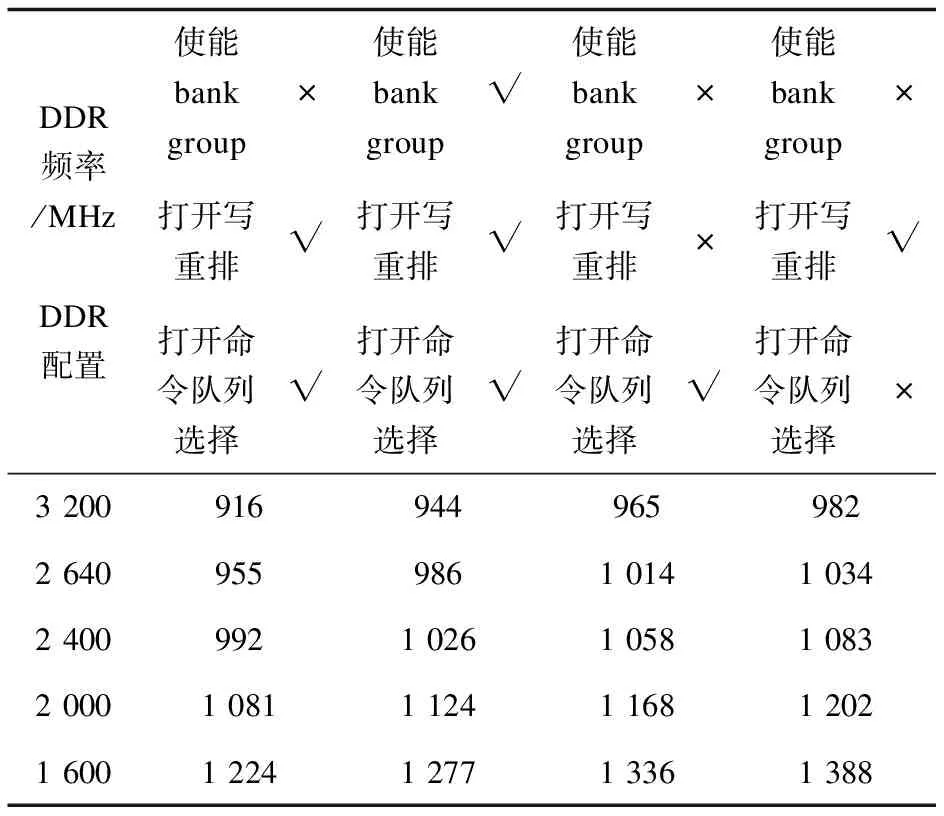
表5 不同DDR配置下FCOS模型推理时间 ms
DDR控制器维护了一个命令队列,按照一定的逻辑把来自不同总线端口的访问请求放入队列中,并支持按一定的逻辑从队列头部的4个命令中选择最适当的命令发送给DDR颗粒。DDR控制器一般根据bank是否冲突、地址是否冲突等规则决定从命令队列前4个命令中取出命令的顺序。若关闭命令队列选择(in_order_accept)功能,则DDR控制器总是选择队列头部的命令发送给颗粒。实验表明,打开命令队列选择的推理性能更好,这是因为DDR控制器会在队列头部的命令因为颗粒未准备好等原因而无法执行时,选择队列头部前4个命令中的其他命令执行,从而提高了效率。
DDR控制器对来自不同端口的写命令有三种策略(wr_order_req):(1)不论是否是来自相同的总线端口的写请求,也不论命令ID是否相同,都可以改变写的顺序;(2)来自相同总线端口的带有相同写命令ID的请求不会被重排,其他的写命令可以被重排;(3)只要是来自相同总线端口的写请求,都会按发送到DDR控制器的顺序执行,不会被重排;来自不同总线端口的写请求会被重排。显然,根据DDR颗粒的状态及时改变写命令的执行顺序,将可以提高写命令的执行效率。实验表明,写重排功能打开时的推理性能要优于写重排关闭时的推理性能。
5.4 算力的影响
该人工智能芯片中,深度学习推理加速核内部由4个结构相同的核构成,每个核的理论峰值算力为4 TOPS(int8),这4个核可以组合配置为不同的算力。作为深度学习推理的核心部件,算力的配置显然也对推理性能产生影响。表6统计出不同算力配置下FCOS模型的推理性能,此表中的数据均是模型量化为INT16数据类型、片上存储器容量设为4 MB时统计出的。

表6 算力配置对FCOS模型推理时间的影响
显然,算力配置越高,推理性能越强。但推理性能与算力之间并不是线性关系。例如,四核配置下的推理时间并不是单核配置下推理时间的1/4,主要原因有两点:(1)算力提高,计算需要的数据量线性增长,对带宽的要求也相应提高,但芯片的整体带宽不变,因此推理性能不能线性增长;(2)核数量增加,需要额外的操作进行特征图的切分与计算结果的合并、核之间计算的同步,带来额外的负担。因此,推理性能并不能随着算力配置的增加而线性增加。
5.5 数据类型的影响
部分硬件电路可复用为支持不同的数据类型。例如,一个计算INT16乘法的电路可以复用为4个INT8乘法的电路。同样,该电路也可复用于计算浮点数据类型尾数的乘法。理论上,本芯片计算INT8数据类型的算力是计算INT16数据类型时算力的4倍。由于芯片带宽、片上存储器容量等其他因素限制,实际执行推理运算时,INT8与INT16数据类型的表现并不完全是4倍的关系。在CPU运行在1 200 MHz、NNA运行在660 MHz、DDR运行在2 400 MHz频率下,片上存储器容量固定为4 MB时,量化为各种数据类型的FCOS模型的运行速度如表7所示。

表7 数据类型对FCOS模型推理时间的影响
从推理性能上看,int8和uint8数据类型的推理性能几乎相同,int16和float16的推理性能约是int8和uint8的3~4倍。Bfloat16由于需要在推理前和推理后执行向常规数据类型的转换,性能最差。
使用不同数据类型对FCOS模型进行量化后进行目标检测的实际效果如表8所示。

表8 FCOS模型量化为不同数据类型后的实际目标检测效果
从以上结果可以看出,量化为BFLOAT和INT16数量类型的FCOS模型可以检测出最左侧一列中从网球到网球拍、人三种不同尺度的物体,表现最好。最终推理的结果精度上看,效果从好到差依次为:bfloat16=int16>float16>uint8>int8。其中int16数据类型等效于对同一层的特征图,使用统一的指数来表示,由于其尾数位数大于float16数据类型的尾数位数(10位),因此,其最终的效果比float16更高。
6 结束语
该文介绍了FCOS目标检测模型的基本网络结构。同时介绍了一款人工智能芯片的基本硬件结构。研究了把FCOS深度学习模型应用到该人工智能芯片的方法,并研究了片上存储器大小、DDR带宽、DDR配置、算力、不同的量化算法等因素对推理效果的影响。研究表明,从对推理精度的影响来看,int16量化方法和bfloat16数据类型的精度最高,float16、uint8数据类型的精度依次降低,int8最差。从对推理时间的影响来看,bfloat16数据类型的效果最差,int16和float16的性能次之,int8和uint8的推理时间最短。研究结果证实,片上存储器容量越大、DDR带宽都对推理时间产生重要的影响,片上存储器容量越大、DDR带宽越大,推理时间越短;反之则越长。另外,研究还表明,DDR的配置,如是否使能bank group、是否使能命令队列选择功能、是否支持写重排,也会对推理时间产生影响,但影响的程度不如DDR带宽的影响。研究成果将为人工智能芯片、深度学习模型推理算法的研究者提供参考。
猜你喜欢
新华月报(2024年7期)2024-04-08 02:10:56
都市人(2023年11期)2024-01-12 05:55:06
卫星应用(2023年1期)2023-02-21 06:51:50
现代经济信息(2022年22期)2022-11-13 18:32:00
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
数码世界(2020年5期)2020-06-23 00:14:36
环球时报(2014-06-18)2014-06-18 16:40:11
电子设计工程(2014年23期)2014-02-27 12:02:22
空间控制技术与应用(2009年3期)2009-01-20 13:47:23
