
抽取-生成式自动文本摘要技术研究综述
2023-05-19 07:54:32奚雪峰崔志明盛胜利
计算机技术与发展 2023年5期
刘 迪,奚雪峰,崔志明,盛胜利
(1.苏州科技大学 电子信息与工程学院,江苏 苏州 215000;2.苏州市虚拟现实智能交互及应用重点实验室,江苏 苏州 215000;3.苏州智慧城市研究院,江苏 苏州 215000;4.德州理工大学,得克萨斯州 拉伯克市 79401)
0 引 言
随着互联网的快速发展,信息俨然成为最具有活力的资源,信息的产量也在成倍增长,如何为用户从大量的信息数据中提取出有用的数据成为亟待解决的问题,自动文本摘要技术的出现填补了这一空白。自动文本摘要技术是一种利用计算机及相应规则、算法和模型完成的信息压缩技术。旨从给定的文本中快速地提炼出一段简明、连贯、全面反映文献核心内容且篇幅少于原文的短文本。早期文本摘要主要依靠人工操作完成,但随着近年来非结构化文本的变多,利用人工处理此类非结构化文本的工作变得异常繁琐,而使用自动文本摘要技术可以有效地弥补人工处理的不足,因此,自动文本摘要技术成了自然语言处理研究中的热点。
1 相关工作
按照摘要生成方式的不同,自动文本摘要可分为抽取式、生成式和抽取-生成式三类。抽取式文本摘要技术利用计算机技术并按照一定的规则计算出词语或句子的重要程度,直接从原文中抽取原词或原句组成摘要,常用于数据规模较小的数据集。该方法技术实现简单、摘要贴合主题、方法适应性广,能尽量地保留文章原有的单元,并且语法上没有特别明显的错误。其不足之处在于灵活性较差、冗余信息过多、缺少语义理解、无法保障生成语句的连贯性和文本语义信息的完整性。
生成式文本摘要技术要求计算机模仿人类的思维方式理解文本信息,对输入原文进行概括、转述并总结成摘要。此方法生成文本理解能力强、灵活性高且语义较为完整。虽然相较于抽取式在生成摘要质量上有了明显的提高,但其依然存在目标语句表达的主旨不明确、摘要与主题偏离、生成过程缺乏关键信息控制与指导、信息编码不充分等问题。综合现有的研究成果,针对上述问题,许多研究者将传统的抽取式文本摘要方法与基于深度学习的生成式摘要方法相结合,提出了基于抽取-生成式的摘要技术。抽取-生成式技术是将摘要生成任务分为两部分:
(1)利用抽取式摘要技术进行关键词或关键句的定位与提取。
(2)采用生成式摘要技术将前一部分定位与提取到的内容改写生成摘要。
2 数据集
抽取-生成式摘要常用数据集如表1所示。
2.1 中文数据集
2.1.1 清华新闻(THUCNews)
清华新闻(THUCNews)数据集[1]是由清华大学自然语言处理实验室根据新浪新闻RSS订阅频道2005至2011年间的历史数据整理而成。包含80多万篇新闻文档,格式均为UTF-8纯文本。作者在原有新浪新闻分类体系的基础上,将其重新划分为14个类别:彩票、财经、房地产、股票、家具、教育、科技、社会、时尚、时事政治、体育运动、星座预测、游戏、娱乐。
2.1.2 NLPCC-2017
NLPCC-2017摘要数据集[2]是2017年由CCF中文信息技术专委会组织的中文计算会议的比赛发布的Task3任务中使用的数据集。该数据集包含标准摘要和不标准摘要数据集两类,共有5万条样本。常被用于语义关系分类、情感对话生成、文本摘要等任务中。
2.1.3 LCSTS
LCSTS数据集[3]是哈尔滨工业大学整理,基于中国微博网站新浪微博构建而成的一个大型中文短文本摘要数据集。该数据集由200多万篇真实的中文短文本组成,每篇文本作者都给出了简短的摘要。作者还手动标记了10 666条简短摘要与其相对应短文本的相关性。
2.1.4 Sogou-News
Sogou News Dataset是由SogouCA和 SogouCS新闻语料库构成的数据集[4],其拥有5个类别共计2 909 551篇文章,每个类别均包含90 000个训练样本和12 000个测试样本,并且这些样本均以转换为拼音。
2.1.5 搜狐新闻数据集
搜狐新闻数据集来自2012年6-7月间搜狐新闻网上国际、体育、社会、娱乐等18个频道的新闻数据。按照不同的文本处理方式,该数据集可分别用于文本分类、事件检测、跟踪、新词发现、命名实体识别、自动文本摘要等任务。该数据集包含140万条新闻正文和新闻标题。
2.2 英文数据集
2.2.1 DUC2004
DUC2004数据集[5]是只用于测试摘要文档的数据集,由500篇新闻文章组成,每篇文章都配有4篇人工概要。其中包含的500篇新闻文章主要来自纽约时报新闻网(1998-2000)、AP newswire(1998-2000)、新华社(英文版,1996-2000)。该数据集多用于多文档摘要与抽取式文本摘要任务中。
2.2.2 Gigaword
Gigaword是一个由英文新闻文章组成的数据集,最早在2003年由Graff等人[6]提出,数据来源纽约时报(New York Times)等多个新闻源,其中包括近950万条数据。后经过Rush等人[7]整理,得到了380万个训练样本、19万个验证样本和2 000个测试样本。
2.2.3 NYTAC
NYTAC数据集[8]是由《纽约时报》新闻室、《纽约时报索引服务》和nytime.com的在线制作人员提供,包含从1987年1月1日至2007年6月19日《纽约时报》撰写和发表的180多万篇文章。其中超过150万篇文章由专业人员手工标注,标注索引词包括人员、组织、位置和主题等内容,并且超过27.5万篇带有算法标签的文章被nytime.com在线工作人员验证。该数据集被用于自动文摘与文本分类工作,用于自动文摘时,常将其作为抽取式文摘工作的数据集。
2.2.4 CNN/Daily Mail
CNN/Daily Mail数据集[9-10]简称CNN/DM,其数据主要来源于美国有限电视新闻网(CNN)和每日邮报网(Daily Mail)合计大约100万条新闻报道数据。该数据集是一个单文本摘要语料库,在语料库中含有大量的摘要篇章,每个篇章中又包含了若干个摘要句子,随后对其进行了简单的修改,形成了一个用于文本摘要技术的语料库。将报道每一个重要新闻事件的新闻要点都按在原文材料中所出现时间的时间先后顺序来概括写成这几句的摘要。在此数据集中训练集大小为286 817条,验证集大小则为13 368条,测试集大小则为11 487条并且训练集中平均摘要句子数3.72个。目前此数据集经常被用于自然语言处理的机器阅读理解以及文本自动摘要任务中。
3 自动文本摘要的评价方法
3.1 ROUGE
文本摘要通常使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation)作为评估手段,由Lin和Hovy[11]提出。ROUGE是以文摘中n元词的共现信息为基础,对文摘进行评估,是一种面向n元词召回率的评价方法。ROUGE准则包含一系列的评价方法,如ROUGE-1、ROUGE-2、ROUGE-L等,这里1代表基于1元词,2代表基于2元词,L是最长公共子序列的意思。在自动文本摘要研究中,通常会针对特定的研究需求,选取适当的N元语法ROUGE方法。ROUGE-N与ROUGE-L计算公式如下:
其中,gramn代表n元词,{Ref}代表之前已经获得的标准摘要(参考摘要),系统摘要和标准摘要中同时出现n元词的个数,可用Countmatch(gramn) 表示[12]。
3.2 BLEU
BLEU(Bilingual Evaluation Understudy)指标[13]是在2002年由IBM公司提出的一种以准确度为基础的相似度量方法。BLEU的取值范围为0~1,分数越接近1,说明生成文本的质量越高。BLEU指标不但可以用来对候选译文和参考译文中n元组共现程度进行分析,而且可以通过计算生成文本和参考摘要中共同的n-gram用于评价生成摘要的优缺点。由于BLEU仅考虑到生成文本与实际真实文本的契合度,因此,对于具有较高语义质量和较大开放性的摘要任务,采用BLEU并不是一个好的选择。
3.3 CIDEr
Vedantm等人提出了专门针对图像摘要问题的评价指标CIDEr(Consensus-based Image Description Evaluation)[14],采用BLEU和向量空间模型的方法,通过计算TF-IDF向量的余弦夹角得到候选句子和参考句子的相似度,从而实现对候选语句的评价。
4 技术原理
21世纪,随着互联网的全面普及,自动文摘技术的应用日益广泛,受到了越来越多的研究学者重视。目前,实现自动文本摘要任务的方法主要分为抽取式方法、生成式方法与抽取-生成式方法。经过多年来发展,抽取式和生成式方法已趋近于成熟,而相较于前两者抽取-生成式方法的出现时间晚了许多。在技术路线研究方面,抽取-生成式主要用于弥补前两者摘要技术的缺点,如摘要冗余性过高、语法自然性较差等。
目前主流的抽取-生成式摘要技术方法的对比见表2。
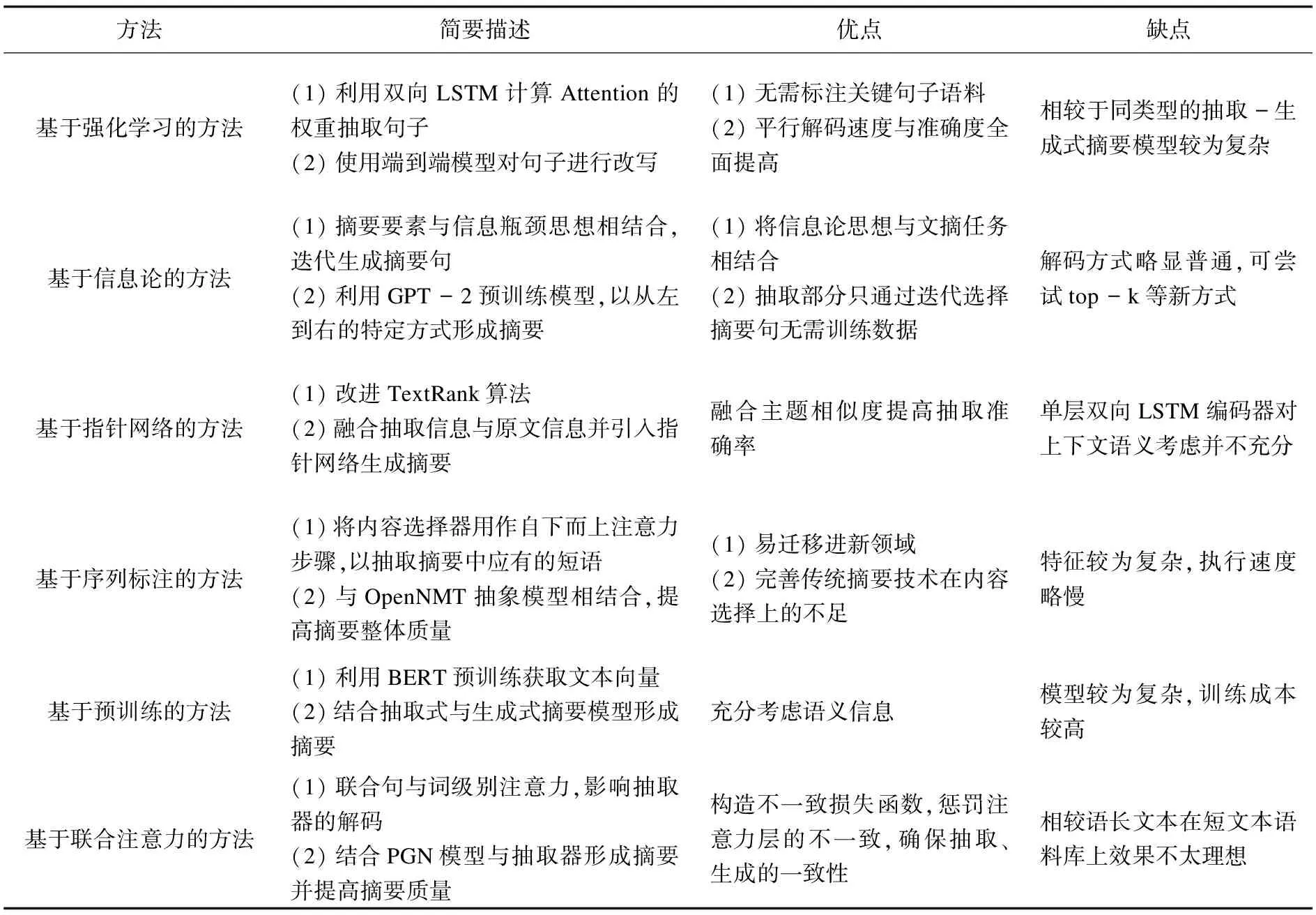
表2 抽取-生成式文摘主流技术方法
4.1 基于强化学习的方法
在抽取-生成式文本摘要中,摘要任务常被解耦为两个部分,该方法虽能集中重写过程中的主要信息,但却使得端到端无法直接训练。因此,一个很自然的想法就是利用强化学习在两部分训练间搭起桥梁。
受分步总结长文本方法的启发,Yen-Chun Chen与Mohit Bansa[15]提出基于强化学习的摘要方法。首先,通过计算Attention定位突出的句子,然后,抽象地重写被选出的句子(即压缩和转述),最后,由粗到细地生成简洁的整体摘要。在其优化模型过程中还加入句子级策略梯度方法,致使能在确保生成摘要流畅度的同时,以分层方式桥接抽取器与生成器这两个神经网络。

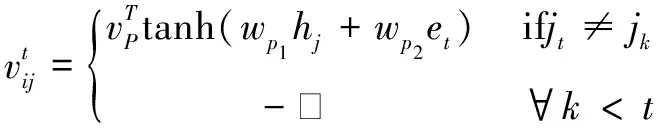
生成模块只采用了最简单的Seq2Seq模型,因为摘要的质量主要取决于抽取模型中得到的关键句的准确率,所以Seq2Seq模型可以满足生成模块的要求。
在训练阶段,通过句子级策略梯度方法合并形成可训练的端到端的计算图,解决抽取模块和生成模块存在的图融合问题。首先,用ML(机器学习)方法单独训练各子模块,然后,用RL(强化学习)训练整个模型。值得注意的是,在抽取模块训练中,可将模型看成分类任务,关键句子即为正类,因为抽取式模型训练没有标注语料,因此该方法中采用了简单的相似度方法来获取标签,之后利用最小化交叉熵损失函数来训练。最后为了减小生成摘要的冗余度,利用重排机制来消除跨句的重复问题,将解码获得的k个句子按照重复的N-gram的数量进行重排,数量越小,结果越好。
综合来说,将抽取与生成相结合,巧妙地引入了强化学习,从而建立了一个与单一通道系统相区别的端到端模型。一定程度上,加速了训练与测试解码速度并提高了摘要的质量,在CNN/Daily Mail数据上取得了当年最先进的结果。
4.2 基于信息论的方法
信息论是对所有事物的信息量进行描述的一种学说,而摘要则是以尽可能少的信息量来表示原始信息。所以,把信息论引入到摘要任务中是非常恰当的。2019年,West P等人[16]提出基于信息论的方法使信息瓶颈与文摘任务相结合,利用信息瓶颈(Information Bottleneck)[17]能关注信息压缩率与压缩后相关信息保留率的特性,将其作为整个摘要任务的准则。
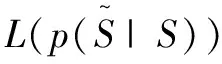
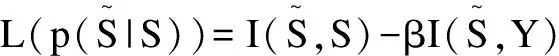
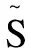
Algorithm 1:BottleSumExmethod
Require:sentencesand contextsnext
C←{s} ▷ set of summary candidates
forlin length(s) …1 do
Cl←{s'∈C|len(s')=l}
sortCldescending byp(snext|s')
fors'inCl[1:k] do
l'←length(s')
forjin 1…mdo
foriin 1…(l'-j) do
s''←s'[1:i-1]∘s'[i+j:l']
ifp(s'')>p(s') then
C←C+{s''}
Return argmaxp(snext|s'')
s'∈C
在重写摘要阶段,采用GPT-2[18]作为预训练模型,以抽取阶段生成的摘要句为target,从左到右生成摘要。相比较第一阶段的抽取摘要,重写阶段产生的摘要更加贴近自然语言的摘要,并在一定程度上更加满足摘要的相关性和冗余度要求。
整体而言,基于信息论的摘要方法是将无监督与自监督相结合。虽然结果较传统的监督式略低,但其优势在于无需训练数据并融入信息论的思想,使得模型整体变得简单、直观。
4.3 基于指针网络的方法
在传统的摘要任务中,生成式产生的摘要主要源于对原文语义的理解。但由于自然语言的复杂度较高,单纯的理解和生成是无法满足用户需求的。而在抽取式中,因其擅长对有效特征的挖掘、重要句子的抽取恰好能弥补生成式摘要技术的不足。因此,利用抽取式来改进生成式成为了研究热点。2021年,陈伟等人[19]提出基于指针网络的方法成功改进了基于Seq2Seq模型[20]的生成式方法,巧妙地融入TextRank算法实现了摘要生成任务。
传统TextRank算法[21]是将文本分割为若干个以句子或单词为基础单元的状态,将其作为一个个节点并通过计算节点间的相似度确定边和权重值。节点的权重迭代计算公式如下:
接着,进一步结合节点的自身权重,将所有节点的权重值赋为1并计算每个节点的权重收敛值与每个句子的得分。最后,利用该语句的得分对其进行排序,选出其中最有价值的语句作为候选文摘,并依照相关的要求,将所收集的句子从集合中提取出来,形成文摘。收敛公式如下:
Bi=SMn×n·Bi-1
相较于传统TextRank算法,改进后算法利用文献的标题、真实人工摘要往往都涵盖了丰富的主题信息的特点,将参考摘要信息引进到算法中,在计算句子间相似度的基础上添加参考摘要与句子相似度计算。通过计算参考摘要与句子间相似度得出的结果获取向量Tn×1并以此调整上式为:
Bi+1=TMn×1·Bi
同时,在改进过的算法中还考虑了单词层面的共同包含的特征词项,规定当参考摘要中包含特征值时,相应的词的权值增大,反之,保持原状态不变,计算公式如下:
最终计算出权重调整值,根据其对句子排序并抽取排名靠前的句子形成候选摘要集。
在生成模型部分,基本架构为Seq2Seq模型,编码器与解码器分别为单层双向LSTM与单向LSTM。编码内容包含上述提到的抽取语义和原文语义,利用两者间语义向量拼接使得信息融合,融合后的向量经过模型训练完成摘要任务。在此基础上,引进指针网络解决模型中出现的OOV(out of vocabulary)问题,进一步提升摘要质量。
4.4 基于序列标注的方法
基于神经网络的生成式摘要能够获得较好的输出结果,但在文本内容选取上,其效果并不理想。为解决此问题,Gehrmann等人[22]提出了Bottom-Up模型,模型将文摘任务分为两个阶段,第一阶段采用抽取技术进行序列标注,通过内容选择器将原文本中应包含在摘要中的一部分短语抽取出来,第二阶段使用此技术结合OpenNMT抽象模型[23]完成摘要任务。
在整体框架中,模型做了一个假设,将其视为序列标记问题。令t1,…,tn为每个源字符的二进制标记,如果在目标序列中复制了一个词,则为1,反之为0。通过使用标准的双向LSTM模型对序列标注问题进行最大似然训练。将每个字符wi映射到预训练单词嵌入的静态通道和预训练语言模型的上下文嵌入通道中,通过微调上下文嵌入获得特定于任务的上下文嵌入。接着将两个嵌入连接为一个向量作为双向LSTM的输入,计算出字符wi的表示hi,并使用训练参数计算该词被选中的概率。但由于神经复制模型具有复制句子过长问题,因此,该模型充分利用了在全文中的标准编码器聚合效果良好的优点,将自底向上的步骤限制为注意力掩码。即,通过在上述所定义的内容选择器和全部数据资料集合中训练,从而获得指针生成网络。在推理过程中,以生成掩码为目标,利用内容选择器对原文本中每个标记的选择概率进行计算。通过选择概率来修正复制注意力分布,使其仅包括选择器标识的标记。为了确保联合分布概率的准确性,需将字符的注意力与归一化相乘重新进行归一化,此处获得的归一化分布可用于替换新的复制概率。
总而言之,基于序列标注的方法通过将内容选择器用于自下而上的注意,充分限制了OpenNMT抽象摘要器从原文本复制词的能力。在抽象模型不失流畅度的基础上,提高了摘要的整体质量。
4.5 基于预训练的方法
自2018年,谷歌推出无监督预训练模型BERT[24]之后,其就成了完成各类NLP任务的有力工具。特别在文本摘要任务中的应用,通过对大量无标记数据集的训练得出深度模型,大幅度提高了摘要生成质量。
2020年,吕瑞等人[25]提出了基于预训练的混合式文本摘要模型TSPT,该模型采用抽取式与生成式相结合的方式,并根据sigmoid函数和预训练原文本所得的双向上下文信息词向量,计算出句子得分抽取关键句。之后,将所选出的关键句当作完形填空任务进行改写并形成摘要。
•抽取阶段,首先将输入序列进行标记嵌入、分段嵌入和定位嵌入,得到预训练句向量。在此基础上,采用BERT模型预训练层所得到的嵌入句向量,作为单层LSTM抽取模型输入。最后在输出层通过sigmoid激活函数计算抽取句子的预测得分并依照分数由低到高排序,丢弃分数最低的三个句子,将剩余句子作为候选摘要句集合。
•因受BERT模型中完形填空任务的启发,摘要生成阶段类似于一个完形填空任务。采用BERT预训练编码器对抽取的关键语句进行处理,得到编码器的输出向量,将每个关键语句中的词逐个掩盖,然后将其输入到BERT模型中,产生上下文向量,并由2层的Transformer解码器对最后的摘要进行预测。
相较于吕瑞提出的TSPT模型,2021年谭金源等人[26]提出的BERT-SUMOPN模型充分考虑了语义信息对摘要质量提高的重要性。
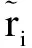
•在重写阶段,利用指针生成网络模型作为生成式模型,将指针网络与基于注意力机制的序列到序列模型结合起来,使得指针可以直接地指向所产生的单词。在此基础上,把从真实标签列表选择出来的重要语句作为重写模型的输入,并利用这些重要语句中单词对应的BERT预训练语言模型向量化结果w注入到指针生成网络之中,同时也通过coverage机制克服指针网络生成重复词的问题。特别是在BERT-SUMOPN模型中,引入了EAC损失函数,以最小化EAC损失函数为目标,对抽取模型和重写模型进行端到端训练。
综合比较基于预训练的两种模型的相同点与不同点。从待解决问题方面看,TSPT模型与BERT-SUMOPN模型都通过BERT预训练解决传统摘要模型中摘要语法错乱、自然性差的问题。从模型整体结构看,TSPT模型基于BERT进行三阶段训练,而BERT-SUMOPN模型的两阶段训练分别由BERT与指针网络组成,比较而言BERT-SUMOPN模型相对简单、易于训练。从语义丰富程度看,TSPT模型预训练仅获取词向量,而BERT-SUMOPN模型同时获取词向量和句子向量语义程度更加丰富。
4.6 基于联合注意力的方法
2018年,Hsu等人[28]提出了基于联合注意力的方法,该模型由信息的提取器与摘要的生成器两部分组成。通过获取句子的概率输出调制单词级别注意力的方式,减少产生较少注意句子中的单词可能性,从而提高摘要的质量。
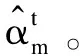

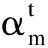
信息提取器筛选出原文中具有高信息性的句子,并以重要程度准则打分得出句子的概率分布。提取器的整体结构包含一个提取句子表征的分层双向GRU和一个预测句子级别特征的分类层。首先,计算出原始文本中各语句与参考摘要之间的ROUGE-L得分,并对每一句话的信息量进行判定。然后,按照信息性由高到低的顺序选择句子,依次添加使已选句子整体信息性更高的新句子。最后,通过获取的ground-truth label最小化抽取器的损失函数得出ground-truth sentences,损失函数公式如下:
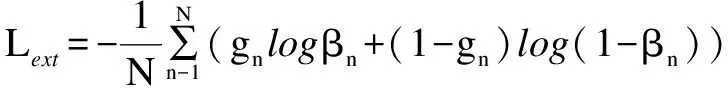
在摘要生成器中,采用See等人提出的PGN模型并联合信息抽取器。PGN模型包含一个双向LSTM作为编码器和一个单项LSTM作为解码器。将ground-truth label作为生成器的输入,利用句注意力机制调节词级别的注意力权值,然后采用指针生成网络逐词生成摘要。
5 抽取-生成式摘要技术面临的挑战与发展趋势
目前,国内学术界对抽取-生成式自动文本摘要技术研究的时间较短、重视程度不够,普遍缺乏融合前沿技术的深入研究。在未来的工作中,对抽取-生成式摘要技术的改进可从以下几个方面着手:
(1)寻找更科学、更可行的评价指标。目前常使用ROUGE或BLEU作为评价指标,这类指标的缺点是无法考虑到语义层次上的匹配,导致输出的文本摘要过于生硬,并且ROUGE、BLEU评价指标较适用于英文摘要任务,在中文任务中效果不太理想。
(2)构建高质量的数据集。因为目前质量高且信息量大的数据集非常少,中文长文本的数据集更少,无法从根本上解决问题,这样会使得整个摘要的研究过程变得十分困难。
(3)提出简单的模型架构。目前的抽取-生成式模型多由抽取式和生成式两部分组成,模型复杂度较高,不易于训练。因此,提出一个能将抽取与生成任务并行运行的模型十分关键,这样有利于降低模型的复杂度,减少模型的训练成本。
在未来的发展中,因抽取-生成式摘要技术拥有高精度、低冗余等特点,将会在以下几个应用场景中发挥重要作用:
(1)舆情管控;因互联网的快速发展,短视频APP层出不穷,对各类负面信息的管控也变得尤为重要。通过抽取-生成式摘要技术能够快速的过滤垃圾文本,减少人工处理的时间成本,在满足用户掌握网络舆情动态的前提下,正确引导舆情。
(2)网页分类;通过对网页内容的摘要,将网页分成多种类型,如:电器类网页、汽车类网页等。不同于普通的文本摘要,用于网页分类的摘要需能充分反映网页的内容,精确捕捉关键的句子,抽取-生成式摘要技术高精度的特点能够满足此类要求。
(3)电商产品说明书摘要;在经济全球化的大环境中,电商行业变得异常火热,商家要想在竞争中取得优势,产品说明书的简洁易懂不可忽视。使用抽取-生成式摘要技术能够有效地提炼产品卖点,帮助客户了解产品的详细特征,促进商家产品的曝光率和销量。
6 结束语
自20世纪50年代末起,人们对自动文本摘要技术进行了近60年的研究。从开始的抽取式摘要技术到后来的生成式摘要技术在文摘任务中都取得了不错的成绩。近年来,由于抽取-生成式摘要技术的兴起,使得以往的摘要技术得到了进一步的发展。该文对当前自动文本摘要中的抽取-生成式摘要技术进行了综述,分析、梳理完成该技术所有方法的基本思想、优缺点,并对与之相关的数据集和评价指标进行了详细阐述,最后对抽取-生成式摘要技术的挑战和未来的发展趋势做了预测和展望。
猜你喜欢
童话王国·奇妙逻辑推理(2024年5期)2024-06-19 16:03:38
中学生数理化·七年级数学人教版(2020年10期)2020-11-26 08:24:50
数学物理学报(2020年2期)2020-06-02 11:29:24
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
意林原创版(2016年10期)2016-11-25 10:28:30
光学精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小学教学参考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
