
基于YOLOv5s的车辆实时检测与跟踪研究
2023-05-19 02:35阜远远王建平张太盛周晋伟方祥建王嘉鑫王天阳
安徽工程大学学报 2023年1期
阜远远,王建平*,张太盛,周晋伟,方祥建,王嘉鑫,王天阳
(1.安徽工程大学 机械工程学院,安徽 芜湖 241000;2.中车浦镇阿尔斯通运输系统有限公司 工程部,安徽 芜湖 241000)
在深度学习之前,物体检测主要依赖于具有特征提取和分类器两个阶段的传统方法,其操作实质是用滑动窗遍历整张图片,提取窗内的图像特征,然后再进行分类器检测[1-3]。但是传统方法的特征与分类器之间的联系比较弱,深度学习的发展改变了这种状况,使得二者的联系更加紧密,卷积神经网络本身就具有特征提取的能力,同时也具备分类能力。因此深度学习很好地将特征与分类器整合到一起使其发挥出更大的价值。
随着人工智能的快速崛起,机器视觉、机器学习不断推进,物体检测的需求越来越强烈。计算机技术的发展使得物体检测、目标跟踪等人工智能技术不断迭代更新[4-6],也越来越贴近人们的实际生活。基于深度学习的物体检测算法可以分为两类,一类是Two-stage,代表算法有Fast Rcnn、Faster Rcnn、Mask Rcnn等,这种方式将检测问题划分为两个阶段,首先产生候选区,然后对候选区进行分类,这类算法误识别率和漏识别率低,但是识别速度较慢,很难满足实时检测的场景;另一类检测算法被称为One-stage检测算法,代表算法有SSD、YOLO 算法等,这类算法直接产生物体的类别概率和位置坐标值,经过一次检测就可以得到最终的检测结果。与其他的算法相比,YOL Ov5最快每秒可检测140帧,速度更快,更适合于视频流的物体实时检测。
文中基于YOLOv5s开展道路前方车辆实时检测与跟踪研究,通过对YOLOv5s检测层的改进[7-8],把车辆行驶视频输入检测网络,车辆检测的准确率有明显的提升。此外,通过增加目标跟踪模块,进一步扩展了该算法在车辆环境感知方面的应用。
1 YOLOv5算法
1.1 YOLOv5算法特点
机器视觉主要解决图像分类、目标检测、图像分割三类问题。对于目标检测来说,已经涌现了很多不同的算法,并且算法逐渐完善。YOL O 算法与Faster RCNN、Res Net等算法相比,将候选区和对象识别这两个阶段融合为一个阶段,将图片划分成网格(Grid),每一个网格可以检测网格中的目标,并且将全部格子含有的目标边界框、定位的置信度以及全部类别的概率向量一次性预测出来,这样就粗略地覆盖了图片的整个区域。YOLOv5是YOLO 系列物体识别中最先进的对象检测技术,并且推理速度更快,YOLOv5按模型大小分为4个模型YOLOv5s、YOLOv5 m、YOLOv5l、YOLOv5x。YOLOv5s在YOLOv5的系列中不但深度最小而且特征图的宽度也最小,因此其识别检测的速度相对较快。后面的3种通过不断加深、不断加宽特征层来提高图像识别的准确率。在YOLOv5中有多种因素能影响图像识别准确率,损失函数对最终结果的影响不可忽略。
1.2 YOLOv5s的损失函数
损失函数的作用为度量神经网络预测信息与期望信息(标签)的距离,预测信息越接近期望信息,损失函数值越小。YOLOv5s包含了3种损失函数[9-10]:(1)分类损失(Classification Loss)。在YOLOv5s中考虑到一个目标可能同时属于多个类别,如“行人”“儿童”两个结果,此时概率之和可能大于1,故采用二元交叉熵损失作为其分类失:
式中,N表示类别总个数;xi为当前类别预测值;yi为经过激活函数后得到的当前类别的概率;y*i为当前类别的真实值(0或1);Lclass为分类损失。
(2)定位损失(Localization Loss)。目标检测想要框出检测到的目标,就需要通过对边界框所在的位置数据进行预测,YOLOv5s采用GIo U 作为定位损失:橙色2部分(包括蓝色1和绿色3)即为最小方框C。C的面积减去预测框与真实框的面积,再比上C的面积,即可反映出真实框与预测框距离。
GIo U 损失计算公式如下:

图1 损失函数示意图
在GIo U 中,真实框与预测框距离越远时,C的值也越大,C减去预测框与真实框面积的值也越大,最后趋近于1。那么真实框与预测框当越远时,损失也越接近2。
文中把原模型的GIo U 改为CIo U 作为Y OL Ov5s的损失函数,即在Io U 损失后面添加预测框和目标框的惩罚项与一个影响因子,这个影响因子把预测框长宽比拟合目标框的长宽比考虑进去。
CIo U 具体的损失函数定义为:
式中,v是预测框和真实框长宽比例差值的归一化:
α是权重系数:
CIo U 在考虑中心点距离和重叠面积的基础上进一步考虑了长宽比,使得预测框更加符合真实框。
为了体现CIo U 对本文研究的影响,采用EIo U 作为损失函数与CIo U 作对比。EIo U 的损失函数为:
EIo U 在CIo U 的基础上将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,优化了边界框回归任务中的样本不平衡问题,减少了与目标框重叠较少的大量锚框对边界框回归的优化贡献,使回归过程专注于高质量锚框。
(3)置信度损失(Confidence Loss)。每个预测框的置信度表示这个框的可信度,置信度越大,表示预测框越靠谱,反之,则预测框越不接近真实框。用Sig moid函数代替Soft max来计算概率分布,损失函数采用BCEl oss。
1.3 注意力机制
YOLOv5s注意力机制是模仿人在观察事物时,会将注意力集中在感兴趣的区域,目前应用的比较多的是CBA M、SE、CA、ECA,本文把位置注意力(Coordinate Attention,CA)引入到YOLOv5s网络中。位置注意力将通道注意力分解为两个一维特征编码过程,分别沿2个空间方向聚合特征。这样可以沿一个空间方向保留精确的位置信息。将生成的特征图分别编码为一对方向感知和位置敏感的注意力特征图,将其互补地应用于输入特征图,以增强关注对象的表示。
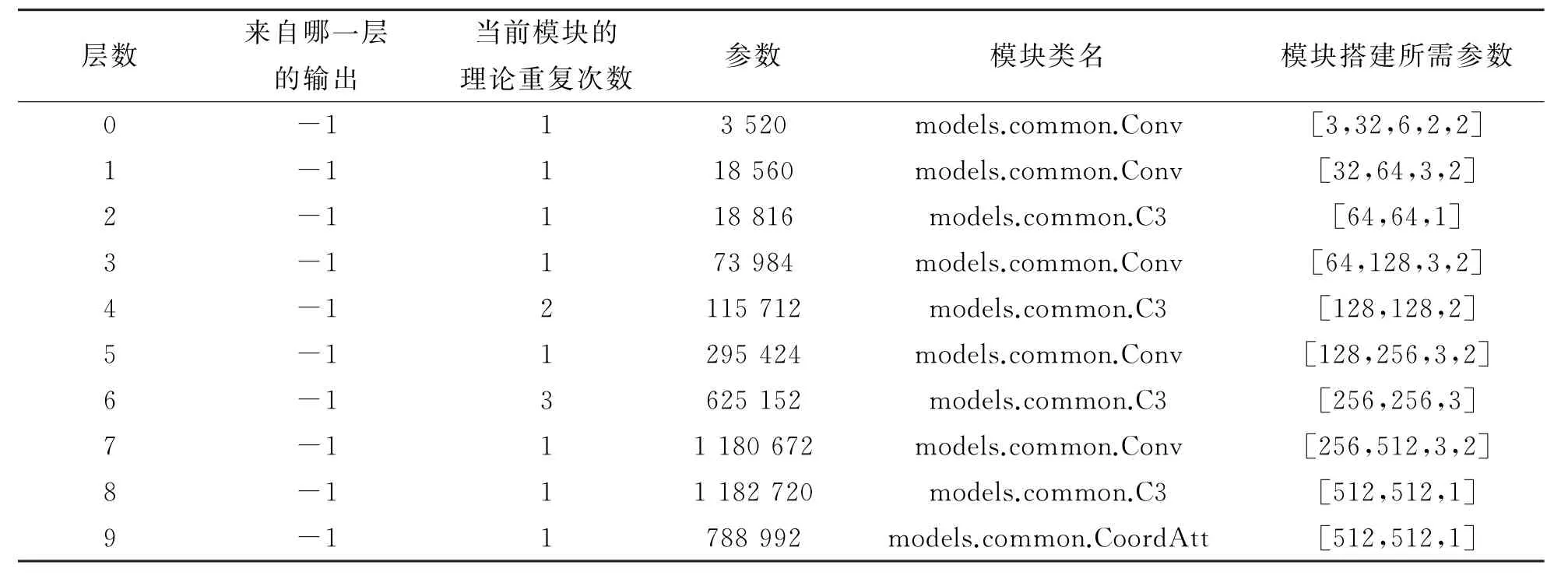
表1 引入注意力机制的部分网络结构层
2 数据集建立及模型训练
2.1 数据集建立
本次实验主要是检测路面上的车辆,YOLOv5s原模型用的是Coco数据集,其中车辆目标并不多,训练出来的权重参数在车辆检测的准确性方面不高,针对这种问题,研究建立新的数据集。对生活中常见的车辆拍照获取原始数据集2 025张,如今生活中常见的车辆大小和样式越来越多,大致可以分为出行代步的小型车(Tinycar)、短途载人车辆(Midcar)、中长途载人车辆(Bigcar)、小型运输车辆(Smalltr uck)、大型运输车辆(Bigtr uck)、油罐车(Oiltr uck)和一些社会中的特殊车辆(Specialcar),将车辆分为这7类可以在实际车辆检测跟踪过程中对不同车型在不同的距离设置不同的提示语,如果前方是社会中的特殊车辆(如警车、救护车),驾驶系统持续向驾驶员预警保持车距,注意避让,给驾驶员更加舒适更加文明的驾驶体验。
采用makesense在线标注工具对原始数据集中的图片进行框选标注,接着导出yol o格式的文件。在YOLOv5s项目中新建数据集Mydata,划分训练集、验证集以及测试集,在YOLOv5s框架内复制Coco.yaml文件并且修改其中的类别个数以及具体的类别,保存为Mydata.ya ml,数据集建立完成后开始对模型进行训练。
2.2 模型训练
本次的模型训练机器选用的CPU 为Intel(R)Core(T M)i5-7300 HQ CPU@2.50 GHz,4 GB显存,512 GB固态硬盘。使用Windows版本的Pytorch框架,将基于Pytorch深度学习框架的YOLOv5s模型嵌入到文中的项目中,由于设备配置无法用GPU 完成训练,故采用CPU 对模型进行训练。
在模型训练前要进行超参数优化,良好的初始参数值能得到更好的最终结果,YOLOv5利用遗传算法进行超参数的优化,文中的超参数设置如表2所示。

表2 超参数设置
对原模型YOLOv5s训练300 轮,损失函数为EIo U 和损失函数为CIo U 且引入注意力机制的YOLOv5s训练300轮分别得到图3和图4的PR 曲线,P表示精度(Precision),R 表示召回率(Recall),PR 曲线与坐标轴围成的面积越大,表示该模型对该数据集效果越好。图4与图3相比,PR 曲线结果更好,说明YOLOv5损失函数CIo U 与EIo U 均优于GIo U。由图4可见,当损失函数为CIo U 时,训练的结果稍微优于EIo U。

图2 数据集车辆类别
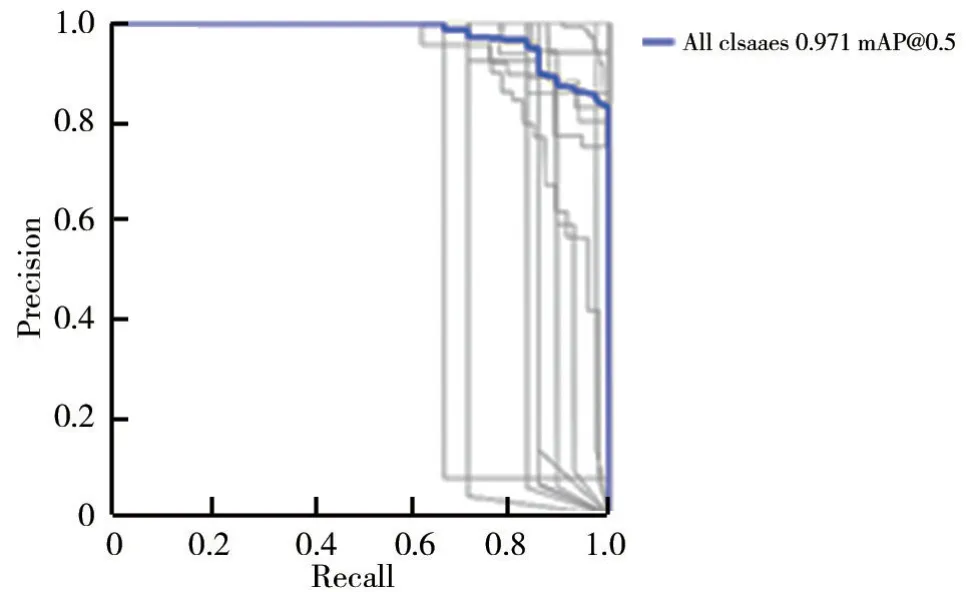
图3 GIo U 作为损失函数的PR 曲线
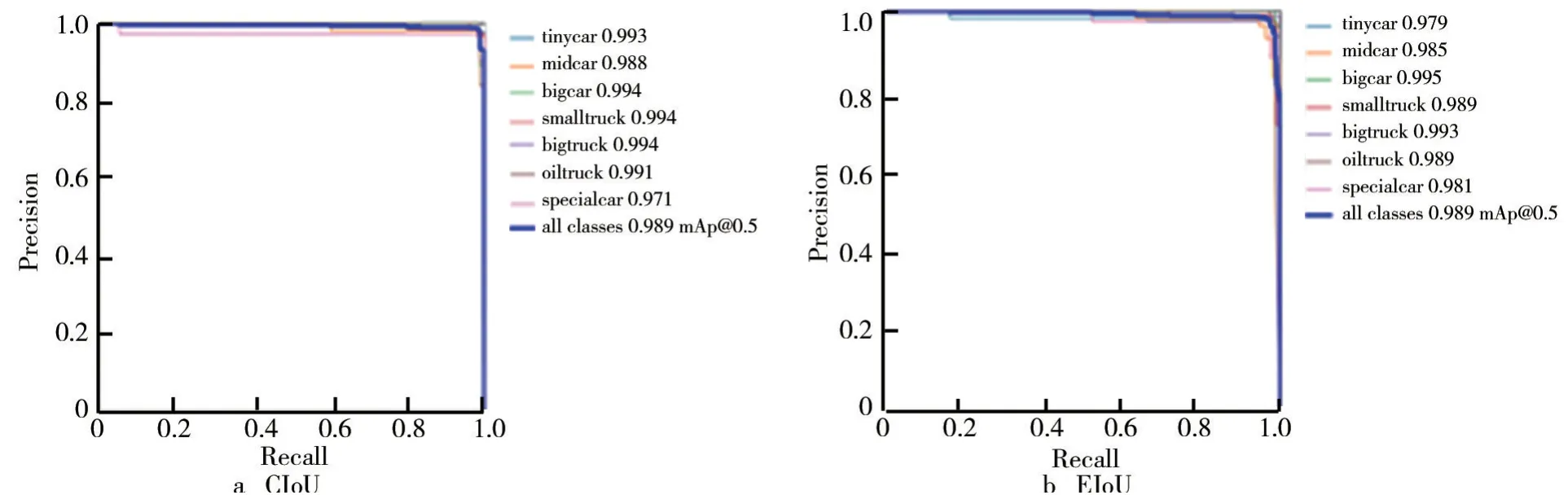
图4 CIo U 与EIo U 作为损失函数的PR 曲线
由图4及表3、4可以看出,YOLOv5s使用CIo U 作为边界框损失函数,训练300轮后损失已经降低到0.01以下,精度可以达到0.98,召回率可以达到0.98。当Io U 阈值为0.5 时mAP值为0.99,当Io U 阈值为0.95 时mAP也能达到0.87。训练结果与原模型相比得到了较大提升,可以将其用于车辆的检测与跟踪。
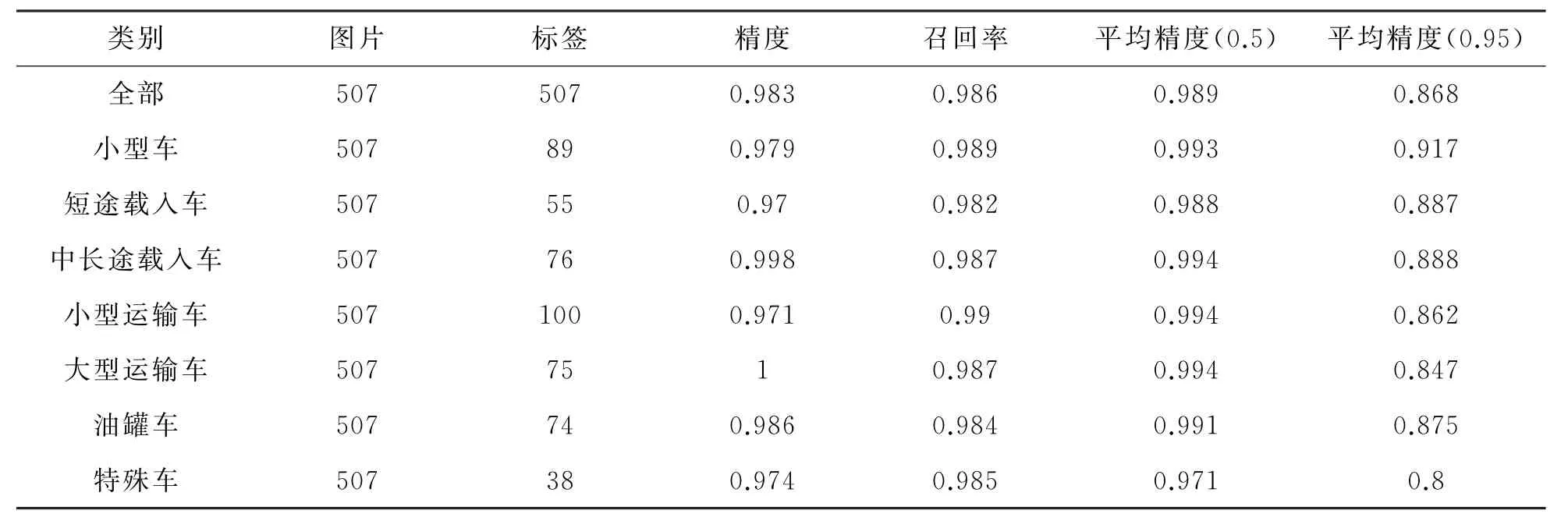
表3 CIo U 作为损失函数的训练结果对比
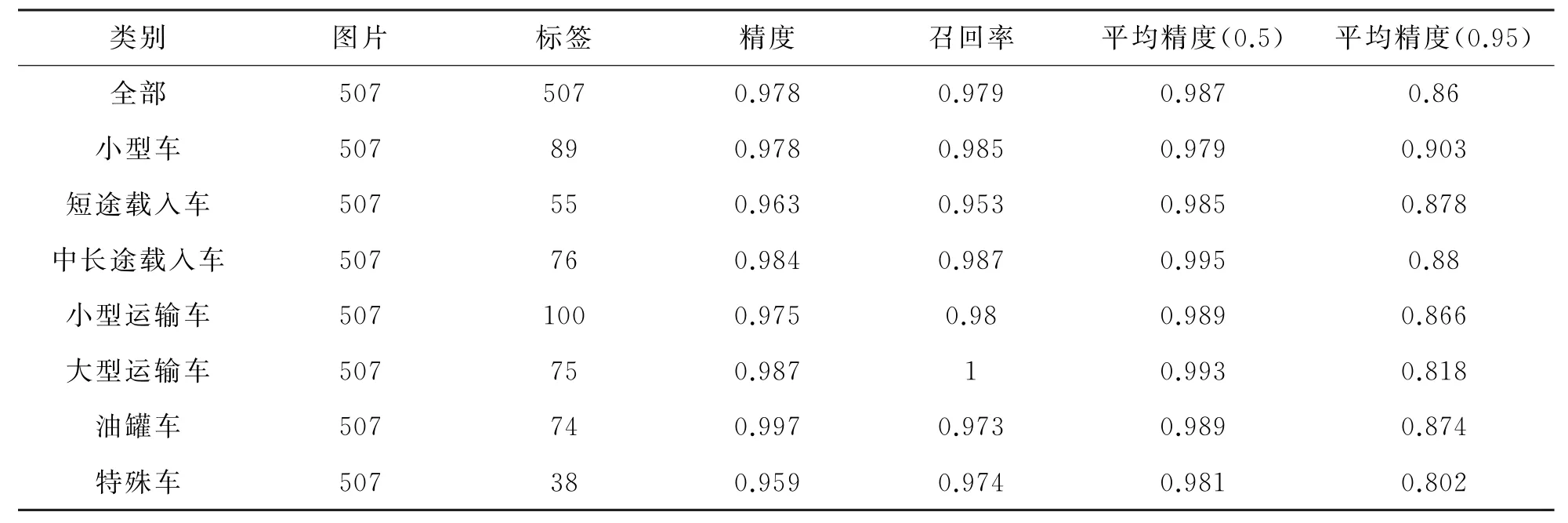
表4 EIo U 作为损失函数的训练结果对比
2.3 目标跟踪
文中基于训练完成的YOLOv5s 检测模型,开展了目标跟踪研究。在视频检测的过程中,增加帧数计数功能,将前一帧图片上的物体打上标注,得到物体的中心点坐标,然后比较当前帧图像与上一帧图像中物体的坐标。当前后两帧的同一目标的中心点移动距离小于规定值,认为是同一物体,对其进行追踪[11]。遍历当前帧与前一帧物体的中心点坐标,计算距离。如果距离小于20像素,认为是同一目标,记录当前目标的索引以及当前帧中物体的中心目标。在后续的比较当中,比较当前帧物体的中心点与被追踪目标物体的中心点之间的距离。如果当前帧中,上一帧跟踪的对象不存在了,则删除该对象的标记,如果当前帧中出现新的目标,则给新出现的目标打上标记,然后遍历每一帧需要跟踪的目标,在跟踪目标的中心点画圈,并且显示出该目标的id。本文的目标跟踪流程如图5所示。
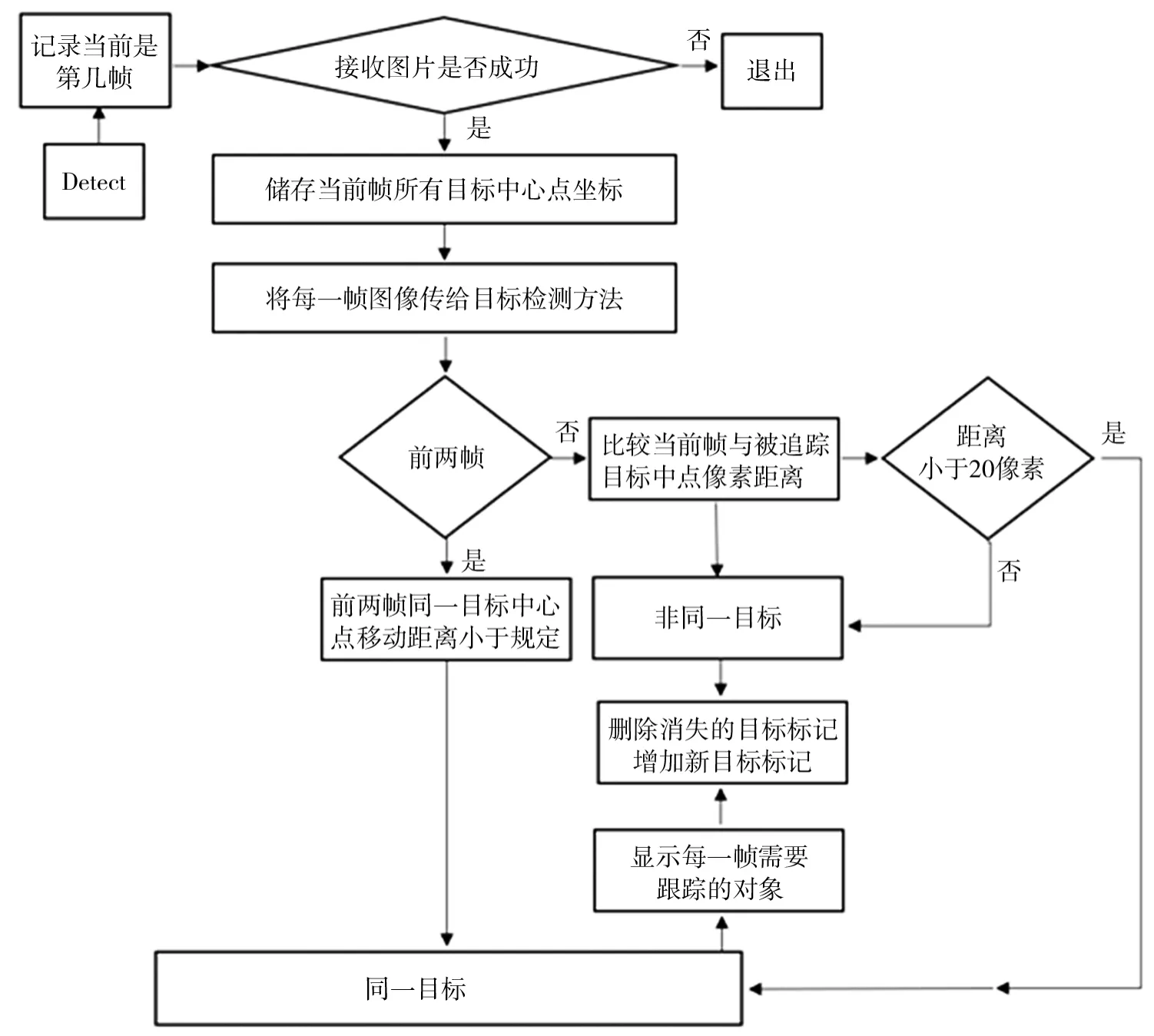
图5 目标跟踪流程图
将车载摄像头安装在车辆前部,将车辆检测视频输入网络,在经过非极大值抑制之后,得到车辆预测框,在输出图像对预测框中心画圈计数,存储当前帧预测框像素中心点和预测框大小,若下一帧图片中同一目标的车辆预测框变大且超过某一阈值,在输出端输出“靠近前车,注意安全!”的警示语,提醒驾驶员及时调整车辆行驶速度,保证行车安全。
2.4 实验结果比较
(1)速度比较。YOLOv5s改进前后检测速度对比如表5所示。由表5可知,在实际检测时,同一设备上改进检测模型前与改进模型后的检测速度没有区别,改进之前213层,改进(损失函数,引入注意力机制)之后270层,每秒10亿次的浮点运算数数均为15.9 GFLOPs。所以本文对YOLOv5s模型的改进对车辆检测速度没有影响,即保证了车辆的检测速度。

表5 YOLOv5s改进前后检测速度对比
(2)精度比较。对于视频流的物体检测识别是将视频中的图片逐帧检测,由于YOLOv5s检测算法速度较快,在输出端仍然能以视频的方式输出。把训练好的最优模型权重参数应用于detect部分,把一段车辆行驶视频输入到YOLOv5 检测端,视频中某一帧如图6 所示。由图6 可见,改进损失函数后的YOLOv5检测精度有所提高。前方车辆1、2、3均已不在实验车辆的视野中,已经删除了它们的标记,保留仍然存在车辆的标记id。在当前帧图片发现距离前方车辆较近,此时系统向驾驶员发出预警。

图6 实验检测结果对比图
3 结论
文中基于YOLOv5s检测算法开展了目标车辆检测和实时跟踪的研究,研究结果表明:
(1)改进损失函数,对模型训练得到最优权重参数,对比损失函数EIo U 与CIo U 对检测模型的影响,发现本文应用CIo U 作为YOLOv5s在检测车辆模型的损失函数更好,在实际检测车辆时,所得到的检测结果比在原有模型下得到的结果更好,在保证检测速度的前提下,检测的准确率有所提高。
(2)目标跟踪模块可以对前方车辆目标打上数字标签,记录车辆在像素中的实时坐标,一旦两帧之间车辆的像素坐标发生较大变化,驾驶员可以通过对预测框的变化判断前方车辆的行驶情况,及时调整车辆的跟踪行为。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·高一版(2020年1期)2020-02-20
今日农业(2019年15期)2019-01-03
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
汽车文摘(2015年11期)2015-12-02
读者·校园版(2015年19期)2015-05-14
科普童话·百科探秘(2015年4期)2015-05-14
