
基于Bi-LSTM 的在线物联网设备识别方法
2023-05-17 06:31:34郝秦霞谢林江杭菲璐
西安科技大学学报 2023年2期
郝秦霞,荣 政,谢林江,杭菲璐
(1.西安科技大学 通信与信息工程学院,陕西 西安 710054;2.云南电网有限责任公司 信息中心,云南 昆明 650000)
0 引 言
物联网技术的高速发展,方便智能设备的数据收集和交换。医疗、教育、交通、工业生产等领域部署大量的物联网设备[1-4],预计到2025年,将有超过750亿物联网设备投入使用[5]。大规模应用的同时,也带来诸多问题[6-8],许多物联网设备都是以低成本设计原则生产的,这些物联网设备具有开放式设计[9],易受到网络攻击,如DDoS攻击[10]、SQL注入攻击[11]和高级可持续威胁攻击[12]等。典型的案例Mirai僵尸网络[13]使用大规模的DDoS攻击美国域名解析服务提供商Dyn,使其DNS服务器大面积瘫痪。Mirai僵尸网络在最初的20个小时内感染近65 000台物联网设备,然后达到30万数量的峰值,这其中包括DVR,IP摄像头、路由器和打印机。新型的Hajime僵尸网络[14]使用点对点(P2P)的方式进行传播,与Mirai相比,Hajime支持更广泛的访问方法,且更具有弹性。网络病毒会对某个厂商的某个型号的物联网设备进行攻击[15]。为防止这些病毒恶意传播,要正确识别出物联网设备的型号信息,对该型号的物联网设备进行补丁升级等防护措施。从安全防护的角度来看,发现并识别网络空间的物联网设备具体型号是防止它们被破坏和利用的先决条件。
国内外学者针对流量指纹识别物联网设备,开展了大量的研究工作。IoT SENTINEL是最早使用流量特征来识别物联网设备的方法,每个数据包选取23个流量特征,共接收N个数据包。每个设备生成N*23的特征矩阵,运用机器学习训练模型并进行预测[16]。MEIDAN等收集9个不同物联网设备的流量数据特征,利用监督学习训练多阶段多分类模型,整体分类模型精度为99.2%,此方法只能识别到物联网设备类型,而无法精确到设备的具体型号,分类精度低,给下一阶段的安全防护增加困难[17]。KOSTAS等提出的IoTDevID通过分析并计算网络数据包中每个特征的权重值,用遗传算法选取特征池中52个特征子集构建特征向量,运用机器学习算法训练模型,在不同测试集上均提高准确率[18]。HASAN等在开源数据集Kaggle使用分布式智能空间编排系统(DS2OS)创建一个虚拟物联网环境,用于生成合成数据,并通过对比不同机器学习模型的效果,得出随机森林模型识别的准确性最好,为99.4%[19]。NGUYEN等提出的DÏoT通过将网络数据包转化为语言符号,用于检测异常的物联网设备,是第1个将联合学习方法用于基于异常检测的入侵检测的系统。通过评估30多个物联网设备,证明在检测被Mirai恶意软件破坏的物联网识别设备方面是非常有效的,检测率为95.6%,并将其部署到真实的智能家居中[20]。YANG等根据应用层不同协议返回的数据文本,按单词出现频率排序,选取前30 000个单词,搭配网络层和传输层的流量特征,作为神经网络的输入训练模型,在测试集结果为94%的准确率和95%的召回率[21]。
上述方法都需要依靠先验知识进行特征工程,即提取、选择和调整特征,部分特征需要领域专家决策。流量传输受网络时延和偏移误差累计影响较大,且识别粒度较低,无法识别出设备的型号,识别范围局限于少数厂商。结合主动探测的特点及流量指纹识别存在的缺陷,提出基于Bi-LSTM的在线物联网设备的识别方法,改进了指纹提取方式,向目标地址的7种常用协议端口进行探测,将返回的报文经过TF-IDF算法特征降维得到应用层报文指纹,带入到厂商识别模块得到设备厂商。运用爬虫技术建立型号知识库,通过正则表达式技术过滤出报文中可能是型号的字段,结合Jaro-Winkler文本匹配算法[22]得出设备型号和设备类型。
1 二阶段在线物联网设备识别框架
二阶段在线物联网设备识别框架如图1所示,由预处理模块、基于Bi-LSTM神经网络的物联网设备厂商识别模块、基于Jaro-Winkler算法的设备型号识别模块组成。
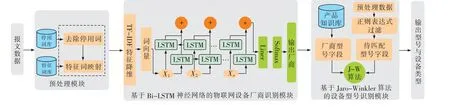
图1 二阶段在线物联网设备识别框架Fig.1 Two-stage identification framework of online IoT device
1)预处理模块。对于HTTP协议提取HTML页面源码;对于非HTTP协议提取banner信息。提取的信息均以文本型保存,利用特征词库实现文本型向数值型转换的特征词映射。解析协议源码后删除视频、音频文件,去除停用词。
2)基于Bi-LSTM神经网络的物联网设备厂商识别模块。为过滤无用词,减少样本的特征维度,提高模型的训练速度和识别精度,采用TF-IDF文本挖掘算法,将输入样本经特征降维后转化为词向量。鉴于Bi-LSTM神经网络能够捕获长远上下文信息,在文本分类任务上表现出色,将词向量通过Bi-LSTM神经网络进行训练,输出结果为设备厂商。
3)基于Jaro-Winkler算法的设备型号识别模块。通过爬虫构建三元组<厂商-型号-设备类型>产品知识库。筛选已明确的厂商型号字段构建案例库,将待匹配的物联网设备的型号字段通过Jaro-Winkler算法与案例知识进行相似度计算,比较得出该物联网设备的型号、设备类型。
2 数据预处理
在HTTP协议中,在线物联网设备应用层返回的响应数据通常包含与厂商高度相关的内容,如<TITLE>TL-MR30XX</TITLE>,<meta name=“description”content=“WVC54GXX”>,标签含有厂商和设备型号信息,组成应用层指纹,且唯一标识设备。
解析不同厂商设备登录页面的DOM树结构,统计标签特征和标签数量,如图2所示。
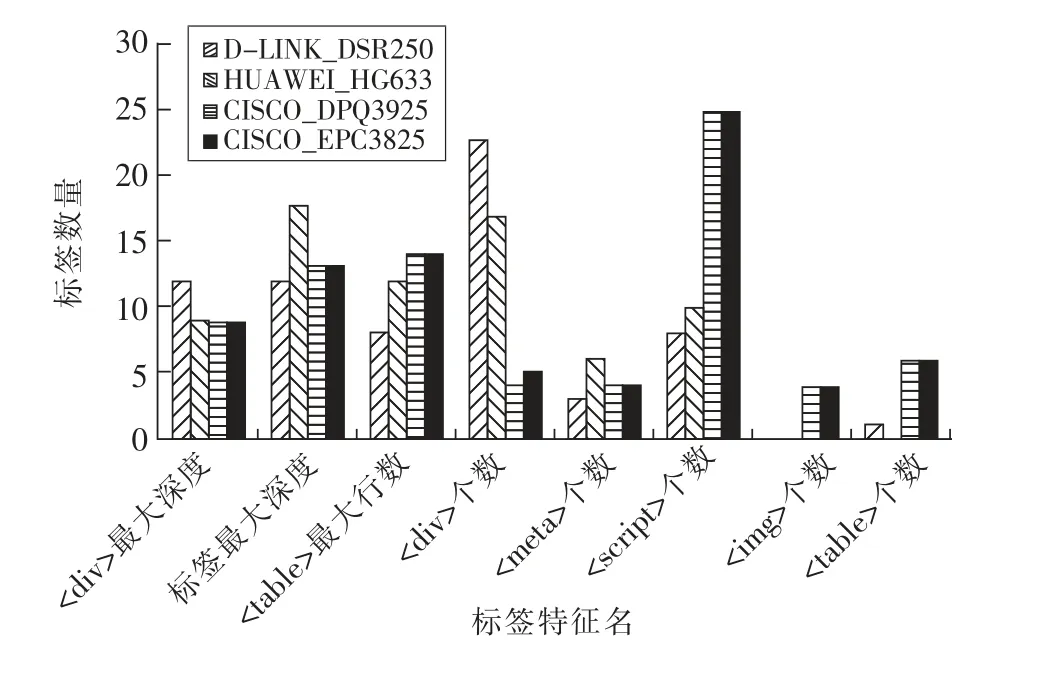
图2 不同型号设备页面标签特征统计Fig.2 Page label feature statistics of different models of devices
从图2可以看出,厂商D-LINK、HUAWEI和CISCO在标签特征<div>个数、<meta>个数、<script>个数、<img>个数、<table>个数上存在明显差异,而同为CISCO的设备仅在<div>标签数量上不同,其他标签特征完全一致,表明相同厂商设备管理页面的布局具有相似性,而不同厂商设备管理页面的布局有较大差异,这些差异可以作为识别物联网设备的依据。
一些设备存在不同端口使用不同协议,因而将同一IP不同端口返回的报文数据分配相同标签,增加数据集的多样性。文本样式以全英文小写,预处理公式,见式(1)。
式中 Tl为分词后的样本;Te为文本T以英文空格为间隔转化为字符串集合,Te={t1,t2,t3,…,tn},其中n为分词个数。S={s1,s2,s3,…,sn}为停用词集合,包括标点符号、“is”、“the”这些没有冗余的单词、自定义去除的单词。
分析7种应用层协议返回信息,7种协议和常用端口见表1。
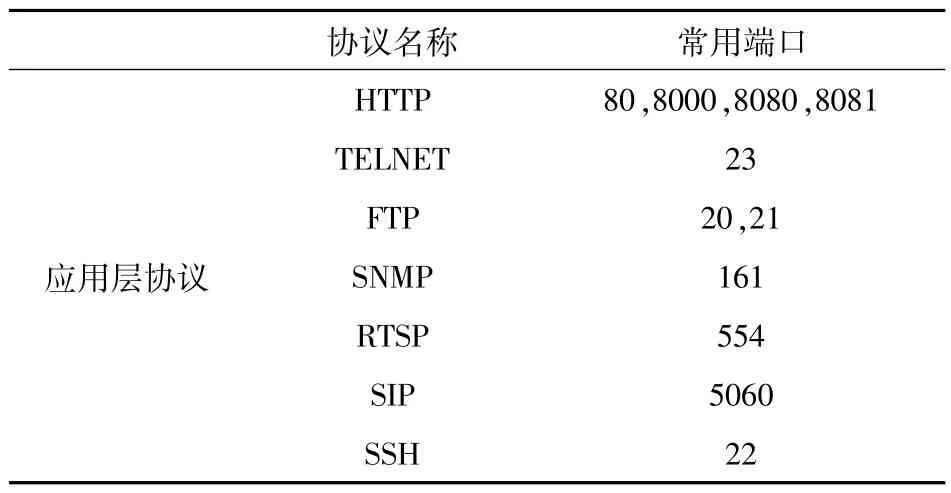
表1 常用协议及对应端口Table 1 Common protocols and corresponding ports
从表1可以看出,HTTP协议常用的端口数量最多,这是由于厂商为了方便用户设备管理和权限登录,使用HTTP协议开放管理页面。限篇幅原因文中只对HTTP协议数据处理过程进行分析。
3 在线物联网设备识别
3.1 厂商识别
预处理后的样本经TF-IDF算法降维后转为数值型词向量,作为模型输入。利用Bi-LSTM神经网络构建厂商识别模块,输出结果为设备厂商。
3.1.1 TF-IDF算法降维
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法,用于评估单词对于样本或样本集合的重要程度。TF-IDF主要由TF和IDF两部分组成。设样本集合为T,ti为集合T中第i个样本。词cij的词频公式,见式(2)。
式中 nij为单词j在样本i中出现的次数;∑ni为ti的单词总数。逆向文本频率公式,见式(3)。
式中 |T|为样本集合中的样本总数,|{i:cj∈ti}|为包含词语j的样本数。最终单词的TF-IDF权重,见式(4)。
式中 wij越大,表示单词在样本集中越重要。
当在线物联网设备返回的报文数据量较大,预处理后仍存在冗余字符串,且这些字符串的权重小、贡献度低,增加特征向量的维度,导致出现过拟合现象,模型性能下降。将TF-IDF算法加入词向量转化过程中,计算单词在数据集中的权重值,过滤掉低于阈值θ的无用词,减少样本的特征维度,提高模型的训练速度和识别精度。完整的流程如算法1所示。
算法1 基于TF-IDF的词向量转换
输入:样本集合T;样本总数N;阈值θ;词向量维度k;词向量个数m;特征词列表H_List。
输出:样集合本的词向量Tword
1:INIT H_List←Ø
2:for each sample from T do
3: for each word from sample do
4: ws,w←tfsmaple,word*idfword
5: if ws,w>θthen
6: H_List.add(word)
7: else
8: continue
9: end for
10:end for
11:H_List去重,然后按入库先后顺序为每个单词增加索
引,转换为字典类型D_List
12:H_List.add(0:”unk”)
13:H_List.add(1:”pad”)
14:for each sample from T do
15: sample.word←D_List[word]
16:end for
17:如果样本的单词数量超过m,取前m个单词;如果单词数量少于m,用1填充到m。将每个数字转化为随机生成的k维的向量。
18:return Tword
算法1得到的Tword为大小为n×m×k,其中n为样本数量,m为一个样本的分词数量,k为词向量的长度。将Tword作为厂商识别模块的输入,用于训练模型。
HTTP协议文本数据样本处理前后对如图3所示,基于HTTP协议得到“CISCOEPC3825”设备报文的内容,将分词处理后的样本经TF-IDF降维,得到最终样本。

图3 HTTP协议文本数据处理前后对比Fig.3 Comparison of HTTP protocol text data before and after processing
3.1.2 基于Bi-LSTM神经网络的厂商识别模块
转换后的词向量作为厂商识别模块的输入样本,LSTM[23]为RNN[24]的改进结构解决了处理较长时间序列时梯度消失问题,但只能学习单方向的特征。Bi-LSTM通过将前向特征和后向特征反馈到输出层,同时学习过去和未来时刻元素对当前时刻元素的关系,在文本分类任务上表现出色。
厂商识别模块由Bi-LSTM神经网络结合3层全连接层构成。Bi-LSTM神经网络公式,见式(5)~式(7)。
式中 hf为正向隐藏层状态;hb为反向隐藏层状态;y为hf和hb拼接后的最后输出。
全连接层之间使用Tanh激活函数作非线性变换,模型收敛速度更快,函数公式,见式(8)。
输入向量经Tanh函数计算后,映射至(0,1),最后1层全连接层接Softmax函数输出设备厂商的类别,函数公式,见式(9)。
式中 zi为第i个类的输出值;C为类的数量。完整的模型架构如图4所示。

图4 厂商识别模块网络结构Fig.4 Network structure of manufacturer identification module
3.2 型号识别
为防止不法分子针对具体型号设备进行攻击,还需进一步识别设备型号,以便与漏洞做更精准的关联分析,在漏洞爆发时及时制定相应的防护措施。
Jaro-Winkler算法是Jaro度量标准的改进。对于2个给定的字符串s1和s2,Jaro距离dj计算公式,见式(10)。
式中 m为s1,s1匹配的字符数量;|si|为字符串si的长度;t为字符需要转化的次数。匹配窗口公式,见式(11)。
当2个字符相同且它们之间的距离小于ω时,认为这2个字符是匹配的。Jaro-Winkler距离dw定义,见式(12)。
式中 l为前缀部分匹配的长度;p为范围因子常量,用来调整l的权重,默认值为0.1。当Jaro距离陷入停滞时,Jaro-Winkler算法可以对Jaro距离进行调整。它的取值范围为[0,1],越接近1,表示两段字符串相似度越高。
利用爬虫技术获取厂商官网产品介绍构建物联网设备知识库,详细信息见表2,其中厂商、设备型号和设备类型均为字符串类型。

表2 型号知识库及属性值Table 2 Model knowledge base and attribute values
使用Jaro-Winkler算法计算型号待匹配字段与案例的相似度,确定物联网设备的型号,设备类型也随之确定。设备型号字段通常由数字或字母加数字的组合形式,例如Cisco 1841,Axis Q7424-R,运用正则表达式技术(^[a-z]+\d{1,5}|\d{1,4}$|^\d+[a-z])抓取样本页面中可能是型号的字段进行相似度匹配,流程如算法2所示。
算法2设备型号匹配
输入:待确定的型号词列表M_List;产品知识库Dm,厂商m;阈值δ
输出:样本的设备型号model_true
1:INIT model_List←Ø,item_List←Ø
2:for each item from M_List do
3: for each model from Dmdo
4: jw←Jaro-Winkler(item,model)
5: model_List.add([jw,model])
6: end for
7: item_List.add(max(model_list))
8:end for
9:temp←max(item_List)
10:if temp[jw]>δthen
11: model_true←temp[model]
12:else
13: model_true←Ø
14:return model_true
输出结果得到的model_true为匹配到的该设备的型号信息,model_true为空表示匹配失败。
4 试验与评估
4.1 数据来源
数据集来源于Zmap[25]扫描工具探测IPv4地址空间,对于存活的IP地址,向7种协议的常用端口发送请求数据包,共解析了10 400条报文数据并打上标签。数据集中包含10种设备类型,15个厂商的800种型号设备。其中80%的数据集作为训练集,20%的数据集作为测试集。
4.2 运行环境
硬件环境为Windows 10操作系统,内存16GB,Intel Core i5-1135G7@2.40 GHz,软件环境为Pycharm 2021版本,Pytorch框架。
4.3 评价指标
从准确率(Accuracy)、精确率(Precision)、召回率(Recall)、和F1-score来评价模型的性能。各指标公式,见式(13)~式(16)。
式中 TP为正类判定为正类;FP为负类判定为正类;FN为正类判定为负类;TN为负类判定为负类。精确率表示正确预测为正的占全部预测为正的比例,越高越好。召回率表示正确预测为正的占全部实际为正的比例,越高越好。F1-score是衡量分类性能的一种综合指标。
4.4 试验结果分析
4.4.1 厂商识别结果分析
设置训练集与测试集数量比为4∶1,训练次数为400次,模型每训练4次测试1次。取词向量维度k=10,30,60,100进行训练和测试[26],结果如图5所示。
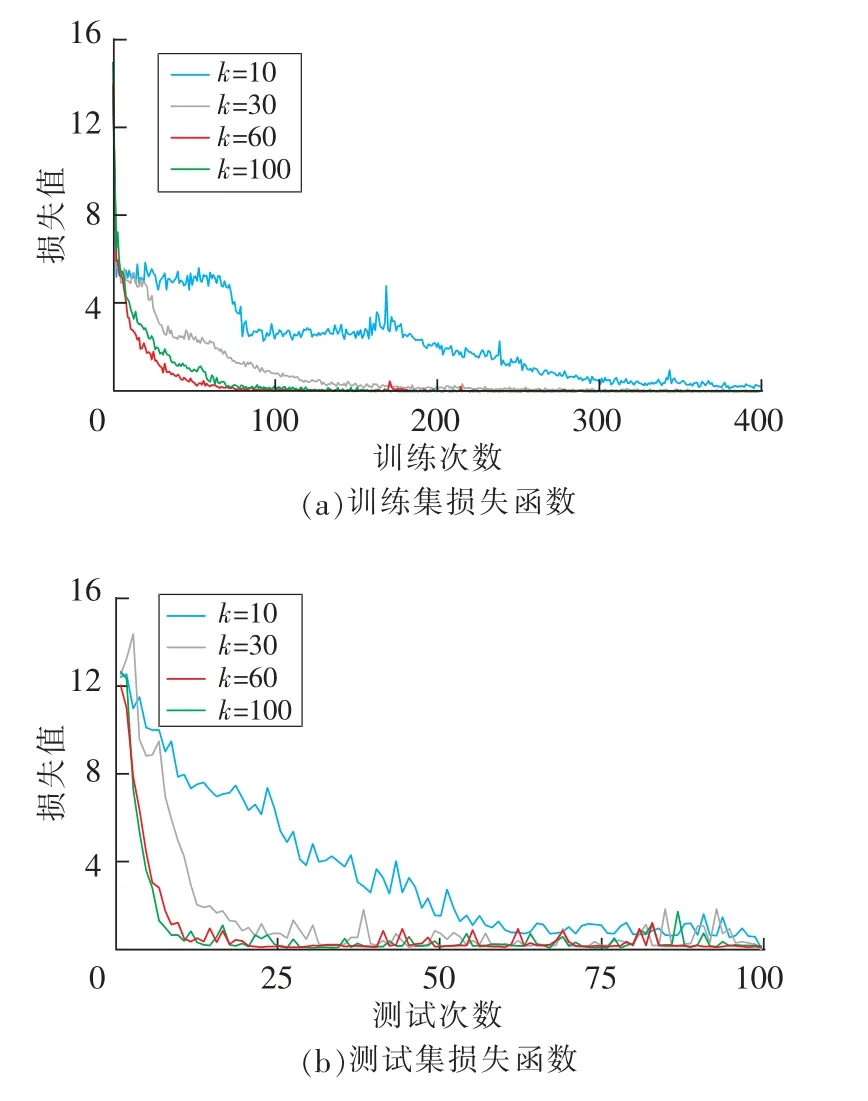
图5 训练集与测试集损失函数Fig.5 Loss function between training set and test set
从图5可以看出,k=10时,训练集损失函数收敛速度最慢,在训练次数为400次左右达到收敛,在测试集上损失函数最大,这是因为词向量维度太小,导致样本之间差异性较弱,机器需要学习更多的次数;k=30时损失函数在训练次数为200次左右达到收敛,测试集损失函数波动较为明显;k=60时,在训练集和测试集上均最先达到收敛;k=100时,损失函数收敛速度降低,这是因为词向量维度过高导致模型复杂度增加,但损失函数曲线波动最小,模型更加稳定。
4.4.2 Bi-LSTM神经网络参数调优
设置与4.4.1一致,结果如图6所示,通过结果分析参数k与训练次数的选取。

图6 k取值大小与分类性能关系Fig.6 Relationship between the value of k and the classification performance
从图6可以看出,随着训练次数的增加,所有参数的模型精确率、召回率不断提高,然后逐渐趋于收敛。k=10时,在训练400次左右曲线达到收敛,此时精确率达到最高为92.3%,召回率为90.5%,F1-score值为0.91;k=30时,曲线在训练280次达到收敛,此时精确率为96.4%,召回率为95.2%,F1-score值为0.95;k=60时,曲线在训练120次达到收敛,在4条曲线中最先达到收敛,此时精确率为98.9%,召回率为98.6%,F1-score值为0.99;k=100时,在训练140次时达到收敛,精确率为99.3%,召回率为97.3%,F1-score值为0.98,曲线波动范围最小。词向量维度越小在向量空间中越密集,需要更多的训练次数来达到收敛;随着词向量维度增加,模型的稳定性增强;词向量维度过大时将导致计算量指数级上升,训练时间也随之增加。
综合考虑,取k=60,训练次数为150来训练厂商识别模型,此时训练次数和模型性能最均衡。
4.4.3 型号识别结果分析
在型号匹配模块中,匹配阈值δ决定模型的匹配精度。当匹配结果的可信值大于阈值时,视为匹配成功;否则,视为无法匹配。δ取值过小时,会得到非型号字段的干扰词,模型的准确率降低;当δ取值过大时,匹配失败的样例会增加,模型整体的性能降低。因此,需要找到阈值最佳的平衡点。δ取值和模型性能的关系如图7所示。
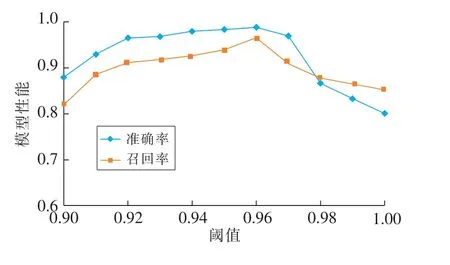
图7 阈值大小与模型性能关系Fig.7 Relationship between threshold and model performance
从图7可以看出,随着阈值δ从0.9增加到0.96,模型的准确率和召回率不断增加,在δ=0.96时达到最大值,此时准确率为98.8%,召回率为96.5%。之后随着阈值的增加,准确率和召回率逐渐减小。当δ=1时,模型的性能表现最差,这是因为阈值设置过高时,型号匹配的要求更加严格,导致包含正确型号字段被过滤掉,使得模型整体性能变差。综合考虑取δ值为0.96,此时准确率和召回率达到峰值,模型的整体性能最佳。
4.4.4 方法对比
将提出的方法与IoT SENTINEL[16]、IoTDevID聚合和IoTDevID混合模式[18]从平均准确率、识别粒度、识别范围和时间开销4个方面进行对比。IoT SENTINEL从每个设备的前12个数据包中提取的23个流量特征,作为设备的唯一指纹。IoTDevID通过使用遗传算法从52个候选流量特征中挑选性能更高的特征子集来降低模型的计算开销。比较结果见表3。

表3 不同方法性能对比Table 3 Performance comparison of different methods
从表3可以看出,在平均准确率方面文章提出的方法表现最好,平均准确率为98.8%;IoTDevID在2种模式下通过重新组合流量指纹,得到最优特征子集,提高了算法的准确率,分别为94.3%和94.1%;IoT SENTINEL由于存在地址冲突问题,性能与其他方法差距较大,仅为81.5%。在识别粒度方面,提出的二阶段识别框架识别细粒度最高,知识库800个设备型号中,识别出型号的占778个,约占97%;IoT SENTINEL和IoTDevID采用流量指纹的方式,前者在27种流量中只能识别出4种设备型号,后者只能识别到厂商粒度。时间开销方面,IoT SENTINEL没有进行额外的预处理,算法整体开销最小,约为0.15 s;IoTDevID由于加入了遗传算法增加了时间开销,约为0.5 s;文章构建型号知识库扩大识别范围到800个物联网设备,分别比其他方法多773个和769个,识别型号时需要额外开销,但识别细粒度得到有效提升。
5 结 论
1)改进指纹提取方法,提取应用层报文特征生成设备指纹以识别在线物联网设备。试验证明该方法准确率为98.8%,召回率为96.5%,与其他方法相比平均识别准确率提升4.7%。
2)提出的二阶段在线物联网设备识别框架细化了设备识别粒度,利用Bi-LSTM 神经网络加Jaro-Winkler算法,在有效识别设备厂商后进一步判别设备型号和设备类型。试验证明该方法在数据集中正确识别出97%的设备型号。
3)构建物联网设备型号知识库,用于存储设备型号、设备类型等物联网设备信息。知识库可扩展性强,通过将新设备信息添加入到库中,有效解决识别范围受限问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
机械工业标准化与质量(2021年10期)2021-11-19 09:17:44
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中外玩具制造(2021年2期)2021-02-07 08:49:12
航天工业管理(2020年9期)2020-12-28 00:37:44
汽车观察(2018年10期)2018-11-06 07:05:32
铁道通信信号(2016年8期)2016-06-01 12:10:21
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
声屏世界(2015年2期)2015-03-11 18:31:32
