
基于半监督学习的三维Mesh建筑物立面提取与语义分割方法
2023-05-16 04:24成浩维资文杰
郑州大学学报(理学版) 2023年4期
成浩维, 资文杰, 彭 双, 陈 浩,2
(1.国防科技大学 电子科学与技术学院 湖南 长沙 410073; 2.自然资源部 南方丘陵区自然资源监测监管重点实验室 湖南 长沙 410114)
0 引言
物联网、云计算、大数据、空间地理信息集成等新一代信息技术,促进了城市规划、建设、管理和服务智慧化的新理念和新模式。随着遥感技术的发展,来自天基、空基,乃至无人机平台的三维倾斜摄影数据日益丰富。与点云数据相比,三角面片(Mesh)数据具有轻便高效的特点,在智慧城市建模与分析、数字孪生城市应用、城市规划建设等领域的应用日益广泛。
利用Mesh三维数据,可以方便地构建大规模数字城市三维场景。但基于Mesh数据的三维场景通常以“场”的形式存在,不具备任何语义,难以支撑如数字孪生城市、智慧城市建设等需要语义分析结果的应用。如何高效合理地面向三维Mesh数据完成建筑物立面语义分割是大规模城市三维场景数据分析的基础。近年来,随着深度学习的兴起,深度学习方法在图像分类[1]、目标检测[2]、语义分割[3]等计算机视觉领域都取得了巨大的成功。深度神经网络的成功部分归因于训练数据的人工标注质量。深度网络通常通过监督学习来实现其强大的性能,而监督学习需要一个带标签的数据集。因此,使用更大的数据集带来的性能收益可能会付出大量的人力物力,而高质量的Mesh三维场景人工标注数据集昂贵且稀缺。为了应对这个挑战,我们希望考虑一种更加轻量的数据集标注方法,利用图像的附加信息,例如空间信息(相邻像素属于同一类)或特征关系表示(相似的特征表示可能属于同一类)来用于建筑物立面分析。可以将这类稀疏标注分为点级、涂鸦[4]、图像级标签[5]。Bearman等[6]首次尝试将点级的注释用于语义分割,每个实例仅用一个点标注,此方法基于人类指向对象的过程,且引入客观先验,取得了较好的分割效果。Wu等[7]提出从涂鸦中学习航拍建筑物的分割模型,使用简单的线形涂鸦数据,训练过程中加入迭代生成的伪标签以及标签阈值过滤自训练,该方法有效地提高了精确度和鲁棒性。Hua等[8]提出应用多边形级的涂鸦作为标注,应用特征和空间关系正则化(feature and spatial relational regularization,FESTA)的方法,以在空间和特征方面的邻域结构补充监督任务与非监督学习信号,进一步提升了半监督训练的精度。
本文探索并提出一种建筑物立面的提取与语义分割方法:基于mean-teacher结构的特征空间关系正则化方法(mean-teacher structure of feature and spatial relational regularization,MT-FESTA),采用弱监督的方式进行模型训练;同时引入mean-teacher模型以获取伪标签来深度挖掘图像表征信息。由于公开的建筑物立面数据集尚未见报道,为验证提出方法的有效性和可用性,我们基于长沙市区三维Mesh数据构建并标注了一个建筑物立面数据集,通过实验对比,所提出的模型与之前主流的方法相比,在平均交并比、F1分数、整体精度(OA)上取得了更好的性能。
1 相关工作
2006年深度学习方法的提出,立即在学术圈引起了巨大的反响。2012年,Hinton领导的小组采用深度学习模型AlexNet[9]在著名的ImageNet图像识别大赛中一举夺冠,促进了深度学习的火热。
1.1 基于深度学习的分割方法
深度学习算法成为计算机视觉领域的主流研究方向并在各种相关任务中取得了显著的成果。与仅能提取有限表达能力的中低层特征的传统机器学习相比,深度卷积神经网络可以端到端自动地提取更具有辨识度的高层特征。因此,深度卷积神经网络具有更强的特征表达能力和更好的性能。
文献[10]提出在AlexNet 中移除FC6和FC7层不仅减少了参数,得到的结果甚至更好,由此证明神经网络的优势来自卷积层,并提出全卷积神经网络(fully connected network,FCN)。FCN只包括卷积层,这使得它能够拍摄任意大小的图像并产生相同大小的分割图。通过用全卷积层取代所有全连通层来管理非固定大小的输入和输出。因此,该模型输出的是空间分割图,而不是分类分数。这项工作被认为是图像分割的一个里程碑,展示了深度网络可以被训练成端到端的方式,并在可变大小的图像上进行语义分割。然而,传统的FCN模型虽然具有普及性和有效性,但也存在实时推理速度不够快、没有有效地考虑全局上下文信息、不容易转换为3D图像等局限性。
另一类流行的深度图像分割模型是基于卷积编解码器架构的。大多数基于深度学习的分割工作都使用某种编解码器模型。例如文献[11-12]利用新的编码-解码网络架构,重用空间分辨率较高的浅层特征来增强在空间细节上的深层特征。
1.2 弱监督学习
机器学习在各种任务中取得了巨大成功,特别是在分类和回归等监督学习任务中。深度学习的成功部分归因于他们的可扩展性,在更大的数据集上训练他们会产生更好的性能。但数据通常需要人为进行标记,数据标记过程的成本极高。因此,研究者希望减轻对标记数据的要求,以获得能够在弱监督前提下工作的机器学习技巧。
通常来说,弱监督可以分为三类[13]:第一类是不完全监督(incomplete supervision),即只有训练集的一个子集是有标签的,其他数据则没有标签;第二类是不确切监督(inexact supervision),即图像只有粗粒度的标签;第三种是不准确的监督(inaccurate supervision),模型给出的标签不总是真值。
本文关注不准确监督,其中像素级别的空间信息是主要关注的问题。不准确监督关注监督信息不总是真值的场景,也就是说,有部分信息会出现错误。比较典型的是在有标签噪声的情况下进行学习。在实践中,基本的思想是识别潜在的误分类样本,然后尝试进行修正。例如,我们用数据编辑的方法去构建一个关系相邻表,然后判断一个点是否为可疑点,判断这个点和相邻的点是否一样。如果一样,那这个点就不是可疑的,将保持原样。如果这个点和相邻的点不一样,那么这个点是可疑的,将被删除或者被重新标记。对图像分割不准确监督使图像分割从细致的对象边界轮廓中解放出来,但是牺牲了部分性能。
近年来,大量工作利用了各种形式的监督信号,例如点级、线级稀疏标记、多边形涂鸦等来完成不准确监督任务。这些工作能很好地提升分割的性能,但往往对标记的位置(如在图像中心附近)、是否有清晰的边界和合理的大小有严格的限制。采用FESTA能够使模型自适应地聚合像素点周围的特征信息,同时能够检测确切的边缘信息并进行判断,能较好地消除标记点对位置的要求。同时为了更进一步挖掘图像信息,我们加入mean-teacher结构。通过数据增广生成伪标签进行自训练,使模型能更好地关注类内的同一性和类间的差异性。
2 建筑物立面提取方法
由于公开的建筑物立面数据集尚未见报道,为了验证本文提出算法的有效性和可用性,我们基于长沙市区的三维Mesh数据,构建了数据集CHANG_SHA_2022进行实验。为获取初始立面数据集,我们利用2020年在长沙市区拍摄的一组分辨率为0.15 m的倾斜摄影数据集,探索一套完整的建筑物立面提取流程,如图1所示。
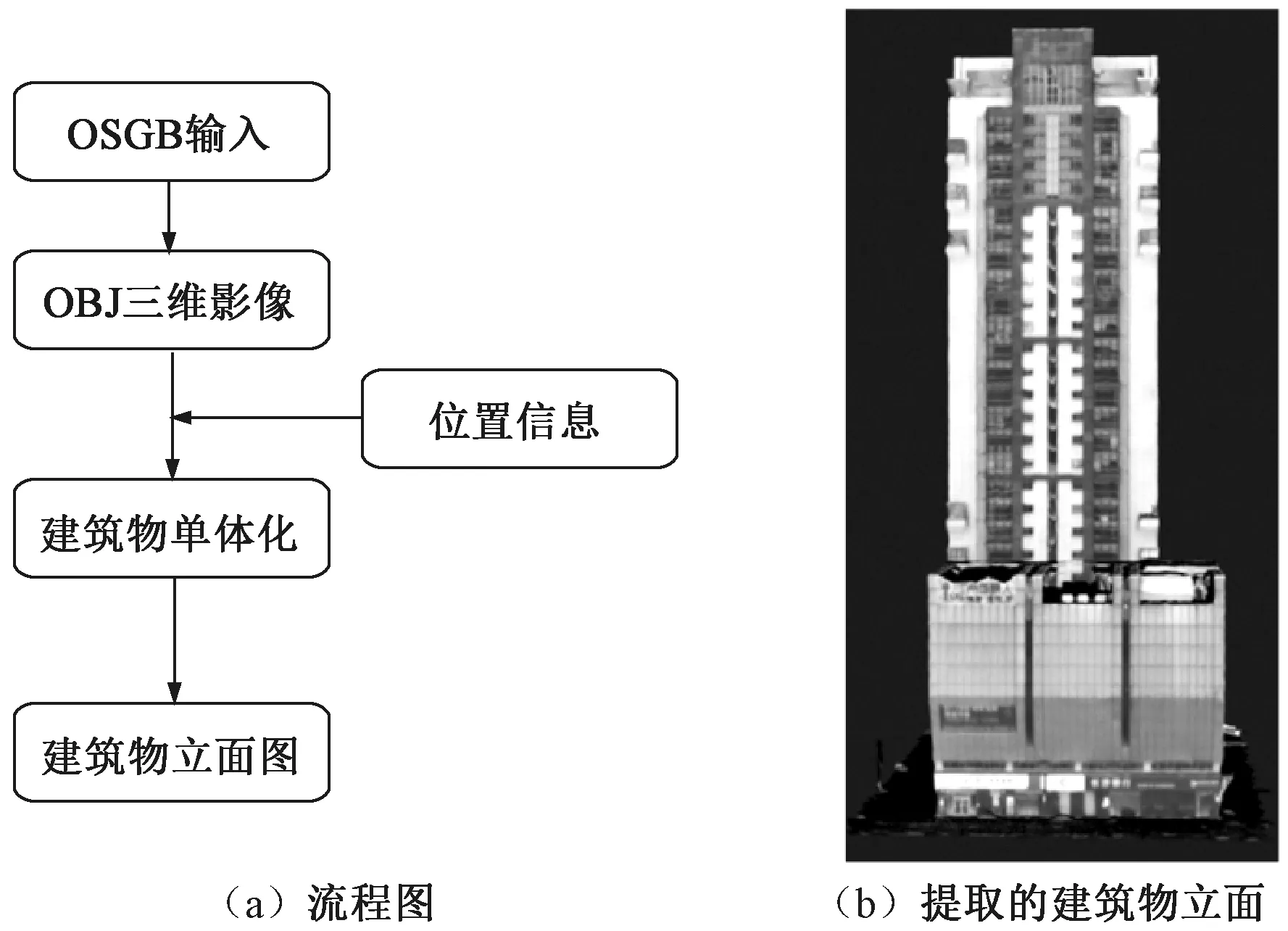
图1 提取建筑物立面的完整流程。Figure 1 The complete flow chart of extracting building facade
仅依靠OSGB倾斜摄影数据难以获取直观的建筑物立面图像,因此首先需要对数据进行一定的处理,得到易于用户读取的开源数据格式。根据OSGB倾斜摄影数据的性质,可以对其进行三维重构得到三维影像。我们考虑将OSGB数据的格式转换为OBJ文件。OBJ文件是一种标准的3D模型文件格式,很适合用于3D软件模型之间的互导,且能够支持三个点以上的面,可以有效地防止模型三角化,这对模型进行再加工有很大的好处。OBJ文件包含每个面片的顶点索引和对应的纹理信息,在数据转换时能够很好地使用倾斜影像图像所附带纹理信息。
使用大规模OSGB倾斜摄影三维重构的OBJ文件通常是一个完整区域的三维图像,为了方便建筑物立面提取,需要对图像进行切割来得到单栋建筑物数据。为了实现定点切割,我们希望能够根据给定的坐标点计算包含该点的建筑物,对建筑物所在的面片进行提取,保存为一个单独的建筑物OBJ文件。获取单栋建筑物的OBJ文件之后,可以调用Blender等开源软件进行三维建模,得到三维建筑物模型后通过不同角度进行拍摄,构建多方位的建筑物立面数据集。
3 基于mean-teacher结构的特征空间关系正则化方法
3.1 模型整体框架
首先通过现有的OSGB[14]格式的倾斜影像提取相应的建筑物立面图,构建我们所需要的数据集,定义标签数据集Xl={xl,yl},其中xl为立面图像,yl为对应的稀疏点标记。为了适应这项任务,我们引入了FESTA[8]方法,以在空间和特征方面的邻域结构补充监督任务与非监督学习信号。同时使用mean-teacher训练方案。如图2所示,模型采用U-Net网络作为基础构架,基于mean-teacher结构搭建。在每个训练周期中,强增广图像经过教师网络生成伪标签,“”表示伪标签信息。原始图像输入学生网络,由网络倒数第二层输出提取的特征图(输入输出对应蓝色长箭头),“△”表示提取特征信息,“◇”表示原始图像由学生网络输出的结果信息。所有输出信息根据像素点的空间位置和特征相似度进行匹配,并加入弱增广图像输出与点标记数据指导模型训练。
定义教师网络参数为fξ,学生网络fθ的权重为θ,损失函数训练公式为

(1)

图2 MT-FESTA模型整体概览Figure 2 An overview of the MT-FESTA model
3.2 FESTA
在图像处理方面,全监督的训练方式依赖于海量的数据集和像素级的标注,因此,使用更大的数据集带来的性能收益可能会付出巨大的代价,因为标记数据通常需要人力,这一成本可能非常高昂。相较于稠密标记的全监督模型数据,稀疏标记的数据能够更加轻量地表示图像中的每个语义类别,不需要完全注释或进行复杂的边缘标记,显著降低了对数据标签的要求。因此在实验中,我们采用稀疏的点级标记注释,引用FESTA所提出的弱监督方法进行训练。
FESTA提出一种基于无监督的假设:邻近的实体通常属于同一类[15],如图3所示。基于这种假设,FESTA提出对特征域和空间域中像素之间的关系进行编码和正则化,使无标记的数据能够学习到有标记数据特征所包含的更多信息。具体来说,假定一个样本(即从图像中的位置i提取的CNN特征向量)xi,特征空间中与其相似度最低的样本被判定为远离类xiff,同理,相似度最高的记为邻近类xinf。根据上文提出的假设可知,xiff有很高的可能性为xi的不同类,应该鼓励这两者在特征空间中的距离尽量远离;而xinf应该被鼓励在特征空间上与xi尽量接近。同时考虑了xi的8个空间邻居区域,并选择了特征空间中最相似的一个作为空间邻近区域,定义为xins。此操作旨在防止xi与属于对象边界的空间邻居配对。

图3 FESTA对于样本学习的示意图。Figure 3 Schematic diagram of FESTA for sample learning
根据上文提出的假设,定义损失函数为
(2)
λins∑C(xi,xins),
(3)
3.3 伪标签学习
弱监督实验采用的数据集标签为手动标注的稀疏点注记,采用弱监督的方法得到的空间特征信息比较有限。为了进一步挖掘图像信息,我们希望追加一个伪标签损失函数,借助mean-teacher[16]网络,将学生网络作为训练对象,用其参数更新教师模型。如图4所示。

图4 基于mean-teacher结构更新模型Figure 4 Updated model based on mean-teacher structure
1) Mean-teacher。为了适应训练任务,我们采用mean-teacher训练方案。仅采用损失函数对学生网络的权重θ进行训练,训练好的学生网络参数将通过一个衰减率τ∈[0,1]更新教师网络fξ。在每个训练周期中,教师网络的权重参数ξ更新公式为
ξ=τξ+(1-τ)θ。
(4)


(5)
(6)
(7)
(8)
4 实验结果和分析
4.1 数据集和评估准则
数据集CHANG_SHA_2022中包含30个训练数据和10个测试数据,训练数据对应稀疏点标记作为标签,如图5所示。测试数据采用稠密标记作为标签。根据我们所关注的重点,数据集的标记主要分为墙面、窗户和杂质三类。数据集由空间分辨率为9 cm的倾斜摄影影像构建OBJ格式的三维影像,再进行单体化切割后拍摄制成。该数据集中的原始OSGB来自长沙的多个不同区域,涵盖多种建筑物风格,包括小区居民住宅、高层公寓、大型商场等各类建筑。每张影像大小为810 pixel×540 pixel。采用点级标签对数据集进行标注,图像标注的比例约为图像整体的20%~30%。我们将图像裁剪为96 pixel×96 pixel的像素块放入模型进行训练。
在实验中,我们采用的评估指标包括F1分数,整体精度(OA)和平均交并比(Mean_IOU)。定义TP、TN、FP、FN分别表示正样本判定为正、负样本判定为负、正样本判定为负、负样本判定为正。定义准确率为P,召回率为R,计算如下:
P=(TP)/(TP+FP),
(9)
R=TP/(TP+FN),
(10)
OA=(TP+TN)/(TP+TN+FP+FN),
(11)
F1=(2×P×R)/(P+R),
(12)
Mean_IOU=TP/(TP+FP+FN)。
(13)
4.2 实验设置

表1 数据增强Table 1 Data augmentation
弱增广同时对原始图像和标签数据进行随机翻转(水平翻转,垂直翻转,水平垂直翻转),能够较好地保留标签区域。强增广数据仅对原始图像进行亮度、对比度和加噪处理,此举旨在使模型学习更深层次的语义信息。
在实验中我们将数据标签分为墙面、窗户、杂质和背景四类,其中背景在训练过程中不进行标注,计算损失时定义权重为0。在训练过程中,我们采用SGD优化函数,初始学习率设置为2e-04,并在每个周期以0.9为指数进行衰减。在网络的训练中,设置λfesta为0.1,λpseudo为0.1,λinf、λiff、λins分别设置为0.5,1和1.5;Mean-teacher模型中初始权重ξ=θ,教师网络的更新参数τ在训练过程中由0.995逐渐增加为1。根据服务器的性能,设置batch-size为5,将图像裁剪为96 pixel×96 pixel大小,进行500批次的训练。
4.3 实验结果及评估
为了验证本文提出方法的有效性,我们引入K-means聚类分割[19]、FCN[10]、FESTA(FCN)[8]、U-Net[11]、FESTA(U-Net)(将FESTA中的FCN替换为U-Net)模型作为基线比较算法,实验结果如表2、图6所示。图中绿色表示表面,蓝色表示窗户,红色表示杂质。在图6中,从(a)到(h)依次为原始图像、稠密标签数据、K-means预测结果、FCN预测结果、FESTA(FCN)预测结果、U-Net预测结果、U-Net+FESTA预测结果、MT_FESTA的预测结果。然后,我们对本文中模型所附加的两个模块(即FESTA和伪标签学习)进行探讨。

表2 不同模型的结果Table 2 Results of different models

图6 建筑物立面分割结果Figure 6 The result of the building façade segmentation
表2展示了在相同数据集、不同模型上的分割性能。实验结果显示,与之前存在的模型相比,我们的模型取得了更好的结果。对于不同的数据分割,我们的方法取得了最高的评分(表中加黑数据为最优数据),且在平均交并比、F1分数和整体精度上分别取得2%~15%的性能提高。实验是在稀疏的点标记下进行,证明了本文方法在弱监督学习的适用性。图6更加直观地展示了不同模型的分割效果。由实验结果可以看出,我们的模型在墙面、杂质的识别上有明显的改善,且对于建筑物立面的整体结构把握更加精准,出现掺杂的现象更少。
采用传统的聚类分割方法能够在部分简单图像上取得不错的分割效果。但能明显观察到,这种分割方法仅依靠浅层的颜色信息对不同物体进行判断,而不能获得深层次的语义信息,如物体的位置、形状和大小等。此外传统的聚类方法不能通过人为干预进行分割的监督和判断,仅依靠机器识别的方法,只能在颜色特征不明显的图像上进行分割,会出现很多错误,并且性能欠佳。
深度学习算法(FCN,U-Net)相较于传统的分割算法,不仅关注颜色等浅层信息,同时更好地关注图像的语义信息和人为信息的监督,对每一类的特征把握更加准确,在复杂的图像上不会出现大规模的误分现象。和FCN相比,U-Net整合多尺度上下文信息,显著提升了分割性能。
在上述的深度学习的语义分割模型基础上,加入FESTA模型能够更好地利用卷积模型提取特征信息,将特征信息相似的归于同一类,能够更好地聚合在图像空间离散的同类物体上。FESTA可以增强网络对图像中的小目标(即窗户)的识别能力。与FESTA模型相比,伪标签自训练的方法在改善点级涂鸦网络的训练结果方面发挥了重要作用。通过强增广数据生成的伪标签自训练,能使模型更好地关注每一类物体的自身特征。基于此,可以得到分割类的内部紧凑性和类间可分性。加入伪标签的方法在FESTA模型的基础上能够更进一步挖掘未标记数据的自身信息。
5 结论
在本文中,我们提出了一套探索建筑物立面材质分析的完整流程,从OSGB格式的倾斜摄影提取建筑物立面,并构建了相应的数据集。同时为了减轻数据标注带来的负担,我们采用FESTA弱监督的方法,仅对数据集进行稀疏点标记。同时希望模型从未标记的图像中更多地挖掘自身信息,我们加入伪标签生成模型来进一步提升模型的性能。实验结果表明,我们的模型能够更好地利用图像信息,取得了优异的性能。实验在窗户类的细微物体上分辨率不高,一方面受限于数据集的清晰度,另一方面特征提取模型方法存在一定不足。同时我们发现基于U-Net结构,结合多尺度上下文信息模型能够很大程度上提升细微物体的识别能力,基于此类模型结构,探索更深层次半监督和弱监督图像信息提取方法是我们下一步研究的方向。
猜你喜欢
铁道建筑技术(2021年4期)2021-07-21
人大建设(2020年4期)2020-09-21
小学生学习指导(低年级)(2019年9期)2019-09-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
人大建设(2017年2期)2017-07-21
人大建设(2017年9期)2017-02-03
公民与法治(2016年10期)2016-05-17
小天使·二年级语数英综合(2015年12期)2015-12-04
计算机工程(2015年8期)2015-07-03
