
结合指导学习和特征擦除的东北虎重识别研究
2023-05-16 03:06翟冰戴天虹
野生动物学报 2023年2期
翟冰,戴天虹
(东北林业大学机电工程学院,哈尔滨,150040)
传统的动物监测方法,如标记和现场调查等,不仅昂贵,而且很难提供实时和准确的信息[1],因此,研究人员开始逐渐把重识别(re-identification)技术[2]应用于保护稀有野生动物和追踪动物个体领域,这对动物行为和生态学研究及保护濒危物种具有重要意义。近年来,随着计算机视觉技术的发展以及无人机和相机陷阱等技术的逐渐成熟[3−5],人们收集了一些野生动物图像数据并在这些数据上进行了重识别研究,其中包括但不限于针对灵长类(Primates)动物[6−7]、非洲森林象(Loxodonta cyclotis)[8]和北大西洋露脊鲸(Eubalaena glacialis)[9]等的重识别,这些重识别算法利用动物的身体部位提取判别特征,然后根据提取的特征来区分不同个体,然而以上野生动物重识别研究存在数据量较小和在非自然环境中捕获等限制。从长远角度看,如何设计重识别模型使其在自然环境下的较大规模野生动物数据集上具有更高的准确性和更好的泛化性,是野生动物重识别研究领域中一个具有挑战性的问题。
由于深度神经网络最初应用于图像分类[10],因此早期的行人重识别研究是对整张图像进行全局特征学习[11]。东北虎(Panthera tigris altaica)重识别任务与行人重识别任务虽然同属于检索任务,但东北虎靠四肢运动,姿态变化比行人更大,并且光照条件不受约束,杂乱的背景、更随机的遮挡和东北虎条纹的高度相似性,使东北虎重识别任务难度更大,但虎条纹图案具有丰富的信息,可以作为判别虎身份的主要标志[12]。Li等[13]构建了野外东北虎重识别(Amur tiger re-identification in the wild,ATRW)数据集并提出几个基线方法。Liu等[14]设计了一个姿态指导的补偿特征学习(pose-guided complementary features learning,PGCFL)的双流网络,利用虎头朝左或朝右来辅助特征学习。Liu等[15]提出一个部分姿态引导网络(part-pose guided network,PPGNet),该网络包括1 个全局流(global stream)和2 个局部流(lo⁃cal stream),其中2 个局部流用来指导全局流对局部特征的学习,虽然测试时仅使用全局流即可,但在训练时非常消耗资源和时间。
针对东北虎重识别,本研究设计一种结合指导学习和特征擦除的方法:一方面,设计包括全局流和局部流的双流网络,融合局部流输出特征与全局流输出特征来指导全局流对细粒度特征的学习;另一方面,基于判别感知机制(discrimination-aware mechanism,DAM)[16]对融合后的特征向量和全局流输出的特征向量进行特征擦除,以擦除后的特征训练网络,增强特征向量中更多元素的辨别能力,使模型获得更全面、更具有鲁棒性的东北虎特征表示,提高东北虎重识别的准确率。
1 结合指导学习和特征擦除网络模型的构建
研究框架如图1 所示,模型包括1 个全局流和 1个局部流,全局流与局部流之间的网络权重参数不共享,主干网络均为ResNet-50[17],同时将最后一个残差块的步长设置为1,以获得包含更多细粒度信息的高分辨率的特征图。通过特征融合与损失计算实现局部流对全局流的指导学习,通过DAM 指导特征擦除来提高模型的鲁棒性。
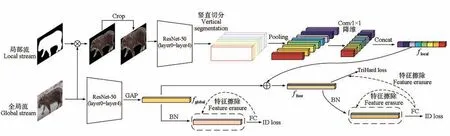
图1 东北虎重识别的整体框架Fig.1 The overall framework of Amur tiger recognition
1.1 双流网络模型
1.1.1 局部流模型
在局部流中,首先利用分割掩码(mask)与原图相乘运算得到东北虎前景图,以减轻杂乱背景产生的影响,使网络更关注东北虎本身,其中掩码获取属于数据预处理部分,分割方法采用Mask R-CNN[18],同时对前景图进行边缘裁剪(crop)以减轻后面划分操作中因错位产生的影响,再将裁剪后的前景图送入ResNet-50 前5 层中,得到输出特征图。目前的东北虎重识别方法主要基于身体条纹,为减轻对条纹竖直结构的破坏,采用PCB[19]中的划分方法将特征图在竖直方向上切分,再对每个分块进行平均池化和降维操作,得到ƒlocal,i∈ℝ256(i=1,2,···,8)。最后将提取到的细粒度特征在通道维度上进行级联,得到特征向量ƒlocal∈ℝ2048。
1.1.2 全局流模型
在全局流中,首先将原图送入ResNet-50 前5 层中,通过全局平均池化操作得到全局特征向量ƒglobal∈ℝ2048,对ƒglobal进行批次标准化(batch normalization,BN)后再以全连接层(fully connected layer,FC)权重为指导进行特征擦除操作。在最后的融合阶段中,将ƒglobal与ƒlocal相加融合得到ƒfuse∈ℝ2048,分别对ƒfuse和BN 层之后的融合特征进行特征擦除。特征擦除只在训练阶段使用,在测试阶段仅使用全局流中经过BN层后的特征进行识别。
1.2 基于DAM的特征擦除
为了使类间的特征元素尽可能不同,在训练过程中,每次迭代将每个特征向量元素都分成低判别性特征元素和高判别性特征元素。对具有低判别性特征元素的集合迭代优化,擦除具有高判别性的特征元素。利用DAM 获得新的特征向量,以进一步优化模型参数。DAM 利用类之间差异的绝对值来确定应该擦除的特征元素。具体地说,当使用交叉熵损失(ID loss)来监督分类任务时,使用最后一个全连接层的权重w∈ℝC×D为指导,将类内特征距离尽可能拉近,类间距离尽可能拉远,其中C是类别数目,D是一个特征向量的维度。特征的类别是由特征向量fi投影到权重向量[w1,⋅⋅⋅,wC]中来决定的,其中wl(l=1,2,···,C)是一个D维向量。通过训练使fi在wyi上的投影更长(yi是fi的真实类别)。特征的每个维度的值和类权重越相似,则投影越长。因此,类别权重可以表示类内样本的平均特征,类权重之间的差异可以表示类间样本之间的差异。类别ci和类别cj之间差异的绝对值定义如下:
式中:Wi,j是一个D维向量,它表示ci和cj之间每个元素的差异性,其值越高,则对应该位置的特征元素在两类之间的判别性越强。通过两个类别之间的差异来决定哪些特征元素需要进一步优化,当差异性较小时,意味着该特征元素在两类之间的判别性较弱。为了选择需要优化的特征元素,采用一种门控机制对具有高判别性的特征元素进行筛选与擦除。具体地说,采用不同类别权重之间差异绝对值的平均值来衡量特征元素的有效性,为了增加门控机制的灵活性,设置一个可调的参数λ,门控权重Ti,j定义如下:
为了进一步优化特征fi中与其他所有类别之间具有低判别性的特征元素,采用ci与其他类别之间的平均差异为指导进行擦除,平均差异Wi,all定义如下:
通过采用相同的门控机制获得门控权重Ti,all,然后得到fi相比于其他类别具有低判别性的新的门控特征Fi,all,其定义如下:
1.3 损失函数
为了提高整体特征表示的鲁棒性,采用新的门控特征计算引入标签平滑[20]后的交叉熵损失,公式如下:
式中:N为一个批次中的图像数目;C为类别个数;Fi,all表示第i个样本的新的门控特征;yi表示第i个样本对应的真实标签;qi是一个C维向量,每一维的值的定义如式(8)所示;ε是一个很小的常数,为0.1;wj和wl分别表示第j个类别和第l个类别对应的权重向量,当l=yi时,wl表示第i个样本对应的真实类别的权重向量。
为了使网络能够学到更丰富的特征信息从而提高泛化能力,采用新的门控特征来计算锚样本与负样本之间的欧氏距离,使其优化难度进一步提升从而提高特征表示的鲁棒性,公式如下:
式中:[·]+=max(·,0);α是一个预定义的值,设置为0.1;d(·)表示欧氏距离;fa和fp表示锚样本与正样本对应的特征向量;Fa,n表示锚样本相对于负样本生成的新的门控特征向量;Fn,a表示负样本相对于锚样本生成的新的门控特征向量。
综上所述,总体损失如下:
式中:LS_global为全局流的交叉熵损失;LS_fuse为融合特征的交叉熵损失;LTriH_fuse为融合特征的难三元组损失;θ和β分别是融合特征的交叉熵损失的权重和难三元组损失的权重。
2 试验与性能分析
2.1 数据集
采用Li等[13]构建的野外东北虎重识别数据集作为试验数据集,该数据集规模相对较大且大多图像是在自然环境下采集,由92 只东北虎的182 个实例组成,并且还包含3 649 个边界框注释,其中50 个实例由交叉摄像机捕获,其余实例则在单摄像机下捕获。60%单摄像机下的实例和40%交叉摄像机下的实例构成了训练集,训练集共1 887 张图像,包含75 只东北虎的107 个实例。测试集共1 762 张图像,包含58 只东北虎的75 个实例。测试集中的每个图像都将对整个测试集查询1 次,因此测试集既是库集也是查询集。
2.2 试验参数设置
操作系统为Windows 10专业版,中央处理器为In⁃tel Xeon Gold 6142,显卡为2 块NVIDIA GeForce RTX3090,每块显存为25.4 GB,深度学习框架采用Py⁃torch 1.10。输入网络的图像均调整为256像素×512像素,批处理大小设置为16,使用Adam优化器训练270个周期,初始学习率设置为0.000 3,前30个周期学习率从0.000 03线性增长到0.000 3,后期每40个周期学习率缩减至之前的1/3。λ为1.5,θ和β分别为1.5和2.0。
2.3 数据增强
东北虎的身体两侧可以看作不同的实例[19],因此通过水平翻转可以进一步扩大数据集,得到新实例,最终数据集规模是原来数据集的2倍。采用3种类型的数据增强方法,分别是随机旋转(随机选择旋转角度-10°~10°,图2A)。随机改变图像属性(亮度、对比度和饱和度,改变范围均为0.8~1.2,图2B)和随机添加噪声(图2C)。

图2 东北虎图像的数据增强样例Fig.2 Sample of data enhancement of Amur tiger image
2.4 方法对比
在ATRW数据集上与CE[13]、Triplet Loss[13]、Aligned-reID[13]、PPbM-a[13]、PPbM-b[13]、PGCFL[14]和PPGNet[15]进行比较,试验结果(表1)显示,本研究提出的方法在所有指标上均优于后者。在ATRW 数据集上使用单摄像机的情况下,本研究方法在mAP、Rank-1 和Rank-5 上的准确率分别达到92.1%、98.8%和99.6%,相比于最先进的PPGNet,分别提高了1.5%、1.1%和0.5%;在使用交叉摄像机的情况下,本研究方法在mAP、Rank-1 和Rank-5 上的准确率分别达到72.9%、94.1%和97.0%,相较于PPG⁃Net分别提高了0.3%、0.5%和0.3%。

表1 不同方法在ATRW数据集上的mAP、Rank-1和Rank-5的精度Tab.1 Accuracy of mAP,Rank-1,Rank-5 of different methods on ATRW dataset %
2.5 消融试验
2.5.1 试验1
为测试算法中各模块对模型性能的贡献,设计了消融试验。将未引入DAM 和局部流,但引入了难三元组损失和带标签平滑的交叉熵损失的全局流模型作为基准模型(baseline),比较了加入局部流、掩码(未加入掩码时,局部流输入与全局流输入相同,即为原图)、边缘裁剪和DAM 后的试验数据,以验证各模块的效果,结果如表2 所示,每个模块均对性能提升做出了贡献。引入局部流后,模型在单摄像机和交叉摄像机下的mAP 指标均有显著提升,表明局部流的指导学习效果显著,可以让模型学习到更多的细粒度特征。局部流的输入为分割前景图时,模型在单摄像机下的各项指标具有小幅提升,在交叉摄像机下的mAP 指标有大幅提升,提升5.7%,这是因为通过背景抑制的方法让局部流更关注前景,即东北虎本身,有效减轻了背景变换造成的影响。引入裁剪操作后,各项指标具有小幅度提升,这表明裁剪操作可在一定程度上减轻姿态错位对后续PCB分块的影响,能更好地指导全局流对细粒度特征的学习。引入DAM 后,模型性能进一步得到提升,在交叉摄像机下的mAP 指标提升最大(提升2.6%),指导性的特征擦除使模型学习到的特征向量更具判别性,对背景的变换更具鲁棒性。

表2 在ATRW数据集上以ResNet-50为主干网络的消融试验Tab.2 Ablation study with ResNet-50 as the backbone on ATRW dataset %
2.5.2 试验2
针对局部流中PCB分块操作对模型性能的影响进行对比分析,在不改变其他条件的情况下,分别测试将特征图分为1、2、4、8、16 块的模型性能,如表3所示,N是竖直方向切分的块数,可以发现当N为8时,模型性能最优,因此在试验中将本研究中的模型特征图等分为8块。

表3 PCB分块的结果Tab.3 PCB blocking results %
2.5.3 试验3
通过多次试验分析DAM中λ取值不同对最终结果的影响,这里仅对mAP 和Rank-1 两项指标进行测试,将λ分别取值0.5、1.0、1.5、2.0 和2.5,结果如图3 所示。当λ值为1.5 时,在单摄像机下和交叉摄像机下的mAP 和Rank-1 准确率最高。这是因为当λ值较小时,擦除的特征维度较多,导致不能充分表示图像的语义信息,致使优化不充分;当λ值较大时,擦除的特征维度较少,出现冗余,同样不能较好的优化。

图3 不同λ值下的模型性能Fig.3 Model performance at different λs
2.5.4 试验4
为验证DAM 的有效性,在其他条件相同的情况下,将其与Dropout[21]和DropBlock[22]进行比较,试验结果如表4 所示。综合来看,无论是哪种特征擦除方法,单摄像机下的mAP 均不低于90.7%,交叉摄像机下的mAP均不低于71.6%,但DAM 相比于其他特征擦除方法表现更好,尤其在交叉摄像机下的mAP 指标具有明显提升,由此可见指导性擦除更具有针对性,可以有效提高特征向量的判别能力。
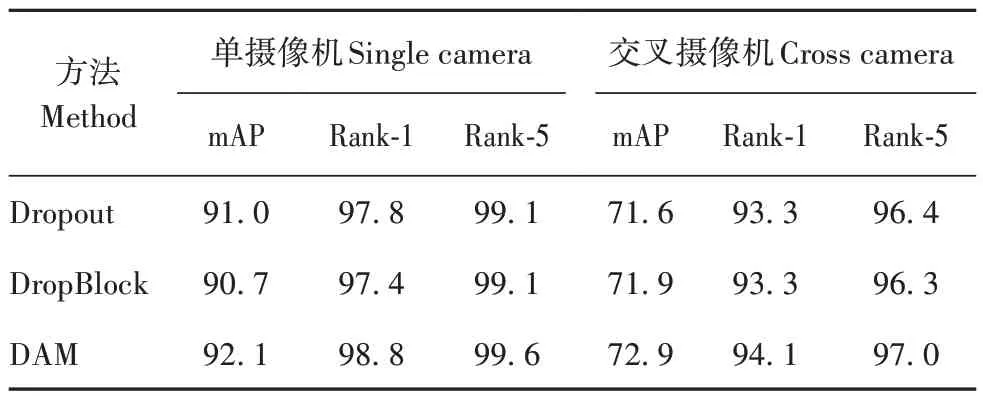
表4 DAM与其他特征擦除方法的差异Tab.4 Difference between DAM and other feature erasure methods %
2.6 试验结果可视化
为清晰直观地表现本研究的识别效果,对ATRW 数据集下某些查询图像的前5 个排序结果进行展示(图4),绿线边框表示正确的查询结果,红线边框表示错误的查询结果。第1 组待检索东北虎姿态变化较大,基准模型在第5 序位出错,本研究方法检索结果全部正确;第2 组待检索东北虎受光照影响较大,基准模型在第4 序位出错,本研究方法检索结果全部正确;第3 组基准模型在第5 序位出错,主要因为被错误检索的东北虎的条纹与待检索东北虎的条纹相似度较高,而本研究方法检索结果全部正确;第4 组待检测东北虎存在遮挡,基准模型在第4序位出错,本研究方法仍然全部检索正确。总体来看,相较于基准模型,本研究结合指导学习与特征擦除的方法可以使东北虎特征表示更具鲁棒性,实现更高的重识别准确率。

图4 ATRW数据集部分图像查询排序结果样例Fig.4 Sample sorting results of partial image queries in ATRW dataset
3 结论
本研究针对东北虎重识别问题提出了一种结合指导学习和特征擦除的方法,该方法设计了一种双流网络,包括局部流和全局流,局部流采用分割后的前景图作为输入,并对全局流进行指导学习,使全局流获得关于前景的更多的细粒度信息,同时,在全局流和特征融合中引入DAM 对原始特征进行特征擦除得到新的门控特征,利用新的门控特征进行损失函数的计算,使得模型优化更加困难,但是也让模型泛化能力进一步提高。在ATRW 数据集上的试验结果验证了本研究方法的有效性,消融试验对比了各模块及超参数对于模型性能的影响。此外,无论是何种方法,单摄像机条件下的各评估指标都明显优于交叉摄像机条件下的指标。这是因为在单摄像机条件下,采集的图像是某只东北虎在某个摄像机下的连续图像,这些图像的背景、光照、遮挡和姿态等方面的变化不是很大。但在交叉摄像机条件下,采集的图像是某只东北虎被2 个或2 个以上摄像机共同捕获的图像,即不同摄像机拍摄到同一只东北虎,因此不同摄像机采集到的东北虎图像在时间、色调、拍摄角度和背景环境等诸多方面都存在着比较明显的差异。在实际应用中,提升模型在交叉摄像机条件下的识别准确率具有十分重要的现实意义。整体而言,模型结构挖掘判别特征信息的能力还有提升空间,如何进一步优化结构和提高特征元素的判别能力以及将模型算法扩展到其他野生动物重识别应用上是下一步要研究的内容。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
汽车与运动(2022年8期)2022-09-16
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
保定学院学报(2022年2期)2022-04-07
小哥白尼(野生动物)(2020年1期)2020-06-12
金桥(2018年4期)2018-09-26
许昌学院学报(2018年4期)2018-05-02
今古传奇·故事版(2017年23期)2018-01-12
