
基于EfficientNet对地震受灾建筑物破坏评估
2023-05-16 05:11丁子林姚新强李雅静
自然灾害学报 2023年2期
丁子林,姚新强,李雅静,张 勇
(1. 天津市地震局,天津 300201; 2. 云南省地震局,云南 昆明 650041)
0 引言
破坏性地震发生后,快速地获取灾区信息,对于救援指挥、救援物资运输的意义重大。由于大部分人员伤亡是由于建筑物的破坏而引起的,所以建筑物的受损信息,对于应急救援非常重要。传统的灾情获取方式包含现场调查[1]、基于GIS数据的评估技术[2]和遥感技术[3],其中,现场调查和评估技术,需要投入大量人力、物力,往往不能及时、准确地了解地震现场情况。另外,遥感技术仅能从受损的建筑物上方进行观测,还受限于天气等客观因素,同时,通过遥感技术获取的数据,还需要相关的技术人员进行分析,这一般需要数小时的时间,造成这种技术往往难以满足救灾的需要。
近些年,智能手机和社交媒体软件的广泛使用,为实时的灾情数据获取提供了良好的环境,智能移动设备不仅可以采集和发送文字、声音、图像,还可以同时获得智能移动设备的地理坐标数据,这为灾后快速地收集灾情提供了基础条件[4]。针对社交媒体灾情数据,有学者以多种自然灾情现场的识别为主题,进行数据采集分析[5]。也有采用爬虫方式对文本数据进行采集挖掘,进行主题识别[6],或者对灾民的情绪判别[7]。有些学者针对某一类灾情的数据进行收集分类,例如地震[8]、洪水[9]、飓风[10]。虽然也有学者对蕴含其中的空间位置信息进行提取[11],但可以看出,大部分学者的研究集中在社交媒体中的文字、图像数据。由于图像比文字蕴含更多的信息[12],并且更加客观、真实,所以针对社交媒体的图像获取、分析的研究越来越多。
以大数据的视角[13],对社交媒体中图像数据进行分析处理,是绝大部分学者的选择。有学者采用支持向量机对火灾进行识别分类[14],但更多的学者采用深度学习的方法,对图像进行分类、检测,例如,使用VGG[15]、ResNeT[16]、InceptionNet[17]等网络模型进行分析。针对建筑物破坏,有学者采取结合ResNet和YOLO网络,对钢筋混凝土建筑物破损进行分析[18]。由于灾害图像数据在数量上有限,大部分学者采用了迁移学习的技术,以提高精度,有学者尝试使用深度卷积生成对抗网络,增加图像数量,以提高数据集的数量和最终的训练效果[19]。在上述研究中,由于灾情信息的特殊性,相对于人脸识别、自动驾驶等领域,其数据量远少于社会环境、自然环境处于正常状态下采集的数据量,进而影响到2个方面,一是这些研究中,存在对灾情识别、分类的粒度较大,例如,有对多个灾种进行识别的研究,仅简单地识别出火灾、洪水、地震房屋倒塌,没有进一步地分析,这影响到其进一步的应用价值;二是影响到了算法精度的提高,例如,有些数据集分类中,其数据量仅仅几百张图片。因此,有必要在扩大数据集和算法优化上继续努力。
文中主要工作聚焦于地震后建筑物受损的灾情图片数据,并广泛地收集,对图像数据进行预处理后进行分类,建立了一个大型的地震受损建筑物灾情的数据集,采用深度学习的方法分析处理,对建筑物破坏类型识别分类,训练得到建筑物识别模型,然后基于QGIS平台制作灾情图。文中编写的程序模块应用于天津市地震局灾情收集系统的灾情数据后台处理,并针对青海玛多7.4级地震的受损建筑物图片数据进行了分析。
1 研究方法
1.1 技术路线
文中提出的地震后受损建筑物灾情分析方法,包括3个部分:1)收集国内外历史破坏性地震后的受损建筑物图片数据,并进行预处理和数据增强;2)分别使用收集的数据集,对EfficientNet模型进行训练,同时用检测数据集进行检测最后评估模型的效果;3)将模型分析的结果,结合空间数据,制作灾情分布图。
1.2 神经网络模型EfficientNet介绍
EfficientNet是2019年谷歌大脑团队提出的系列神经网络模型[20],包含B0~B7共8个模型,不同的模型分别对应不同的图片分辨率。这些模型分别在网络的宽度、深度和分辨率3个维度上,基于复合模型进行缩放,既实现了高效率,又节省了计算资源,如式(1)、式(2)所示:
(1)
(2)
式中:d、ω、γ分别为模型的深度、广度和分辨率;φ是资源控制系数,根据式中的约束条件,对3个维度上对应的系数α、β和γ进行调节,在参数量和运算量不变的情况下,对网络模型的深度、宽度和分辨率调节,达到最优的精度。EfficientNet模型的基础模块是MBConv,其结构如图1所示。MBConv先用1×1的卷积增加维度,然后连接3×3或5×5卷积,再增加一个关于SE通道的注意力机制,最后用1×1的卷积降维,再添加一个残差。通过对EfficientNet B0~B7共8个模型的实验,发现EfficientNet B1模型更适合本数据集,为简便起见,文中仅描述使用EfficientNet B1的实验过程。
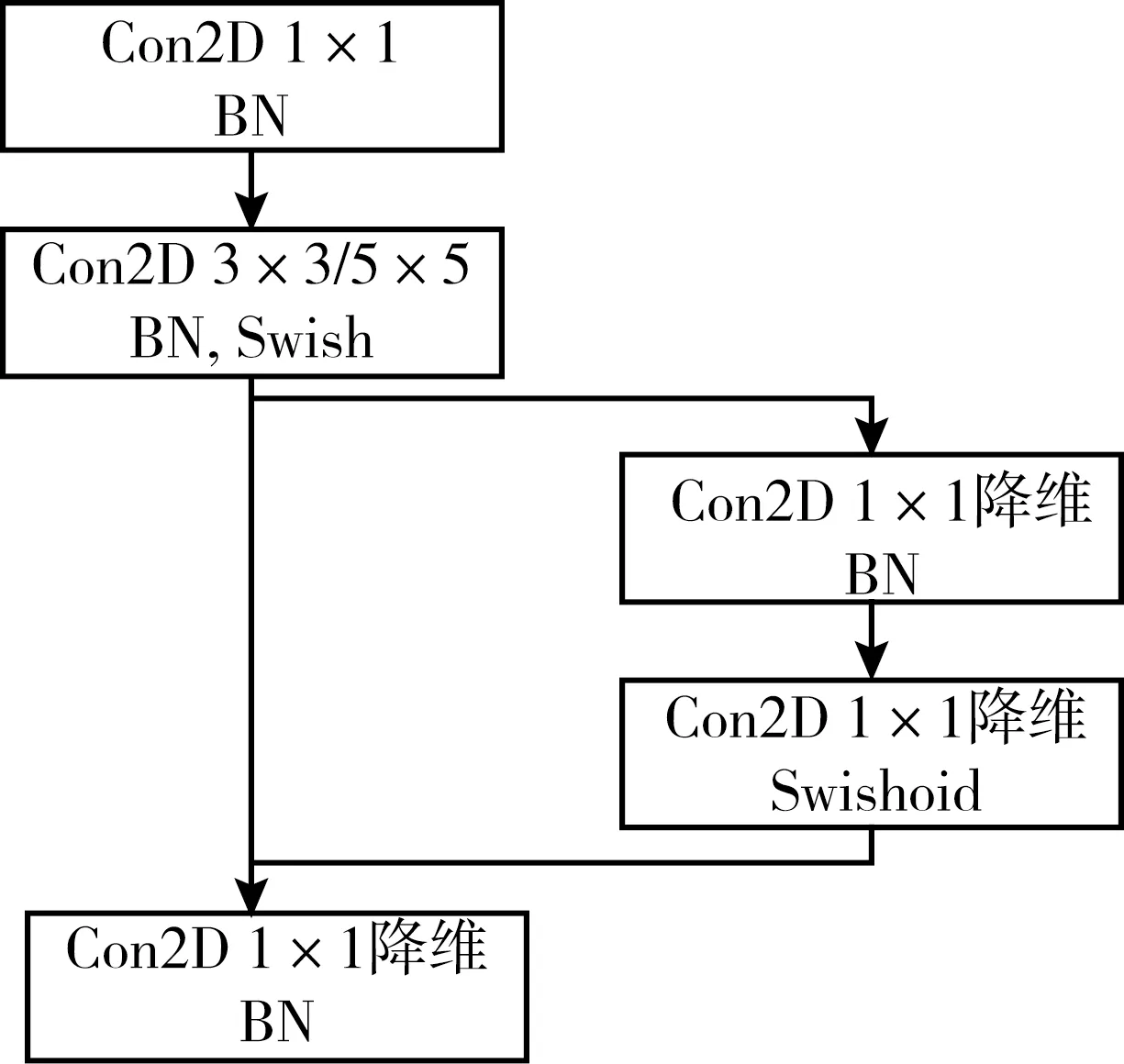
图1 MBConv模块结构Fig. 1 MBConv model constructure
1.3 模型训练
模型在训练的时候,由于数据量有限,为了避免造成过拟合,文中在EfficientNet B1模型中添加了Dropout算法。Dropout算法在训练的时候,按照一定的概率对神经网络中的某些神经元进行丢弃,这样使模型不依赖局部特征,范化能力更强。
2 震后受灾建筑物图像数据
2.1 数据来源
文中所使用的震后受灾建筑物图像数据,主要来源于近些年国内的一些较大破坏性地震的震后科考数据,包括汶川地震、玉树地震、九寨沟地震等20余个地震,这其中包含中国地震局工程力学研究所提供的工程震害数据。同时包括来自PHI(PEER Hub ImageNet Challenge,PHI)的开放数据[8,21],这个开放数据集包含8个数据集,文中主要使用了第1个场景识别数据集,并重新对这个数据集中的数据进行了分类。另外,也在网络上收集了国外一些地震后的灾情图片。
2.2 建筑物震害类型划分
我国有2个关于建筑物的震害类型划分的标准,分别是用于地震现场调查的GB/T 24335—2009《建(构)筑物地震破坏等级划分》[22]和用于遥感数据的建筑物破坏评估的DB/T 75—2018《地震灾害遥感评估建筑物破坏》[23]。现场灾害调查的标准规定,建(构)筑物综合的破坏等级划分是综合考察建筑物的类型、是否承重构件和其破坏程度等多个因素,其依据的数据更加详细,而社交媒体上的受损建筑物的图像往往反映不出这些信息。而遥感数据评估震害的标准,由于其从高空中的视角查看建筑物,遥感数据展示的受损建筑物细节较少,其分类按照倒塌的程度来分,所以其分类标准也不适用于社交媒体上震害图片的研究。因此,文中参考上述2个标准和以往的研究[8,21],根据地震对建筑物的破坏程度,结合震害在建筑物受损部位图像的视觉特征,即线性特征、面状特征和包含现状和面状破坏特征的综合严重体破坏,将震害建筑物类型分为4类:没有破坏、建筑物裂纹、部分墙皮或少量墙体脱落、墙体倒塌或整个建筑物倒塌。数据样例如图2所示。

图2 建筑物受损类型示例Fig. 2 Examples of building destroyed types
2.3 数据预处理和数据增强
数据预处理包括图像文件格式统一,图像的大小统一为(240,240,3)和数据增强。数据集按照8∶1∶1的比例,分为训练数据、验证数据和测试数据。
由于建筑物类型多样,以及图像拍摄采集环境多变,造成了建筑物震害在图像的颜色、大小、形状等方面表现多样,为此,训练集中的数据不能完全涵盖今后实际地震受损的情况。文中采取数据增强的技术,以减少神经网络模型的过拟合现象,主要采用了几何变换、亮度、对比度调整增强数据集。其中,几何变换包括水平翻转和在一定范围内随机旋转角度。
3 实验结果与分析
3.1 实验平台和模型训练
在模型训练阶段中使用的实验环境为Google Colaboratory,GPU型号为Tesla T4,深度学习平台采用Tensorflow 2.5,在此环境中进行了受损建筑物分类识别模型的训练、评估。
基础模型采用Tensorflow Hub中的EfficientNet B1模型,其预训练数据集为ILSVRC-2012-CLS。
3.2 模型训练
经过预训练的EfficientNet B1,在震害建筑物数据集进行迁移训练,采用优化器RMSprop对模型进行参数优化,其学习率设置为0.005,平滑常数设置为0.95。图3是此模型在训练时,模型的正确率和损失值在训练集和验证集上与迭代次数的关系。从图3可以看到,从第7轮训练之后,模型的检测精度就不再增加了,最高达到87.45%。
3.3 模型性能评价
为了评估文中使用的模型对建筑物破坏程度识别的效果,使用精确率和混淆矩阵对其进行性能的评价。其中,精确率表示识别的建筑物受损类别是否正确,如式(3)所示:
(3)
式中:Tp表示识别为某种受损建筑物类型的样本个数;Fp表示错误判定为某种受损建筑物类型的样本个数。
测试数据中包含5 922张图像,其中全部完好的建筑物的图片1 415张,含有建筑物裂缝的图像1 507张,含有建筑物部分墙皮或少量墙体脱落的图像1 500张,含有建筑物墙体严重破坏整体倒塌的图片1 500张。根据测试数据的识别结果,在图4中可以得到标准化混淆矩阵。可以看出模型的识别精确率为87.45%,Kappa系数为0.832 7,说明模型的识别效果与人眼识别是基本一致的,并且正确率较高。
3.4 青海玛多地震灾情数据分析
应用文中所训练的模型,识别2021年5月22日青海玛多县发生的7.4级地震的建筑物震害图片,如图5所示。收集到图片共14张,其中5张包含坐标数据。正确识别的有12张,2张图片识别错误,错误为将建筑物裂缝识别为部分墙皮或少量墙体脱落。识别的正确率为85.71%。

图5 玛多7.4级地震建筑物受损示例图Fig. 5 Example of damaged buildings in Maduo Ms7.4 earthquake
实验中,使用EfficientNet B1模型识别14张图片,并将其中包含坐标的图片制作成灾情分布图,整个过程用时2 s。
4 结语
文中为实现对地震后受损的建筑物进行自动识别,首先收集了大量的海内外相关机构的震害调查图像和震后各个社交网络上的相关图片,结合国家相关标准和前人的研究,探讨了针对这些图片的分类原则,建立了一个大型专题数据集。然后建立了一个基于EfficentNet B1的建筑物受损情况识别网络模型,使用文中建立的数据集进行训练,得到比较优秀的识别模型,并进行了震后受灾建筑物受损程度的评估实验,最后将成果应用于2021年5月22日的玛多7.4级地震的建筑物震害数据。实验结果表明:
1)EfficientNet B1网络模型在地震受损建筑物受损程度评估识别效果明显,实验中的训练精度为87.45%,Kappa系数为0.832 7。模型对于完好的和严重破坏的建筑物类型识别正确率更高,对于包含裂缝、部分墙皮或少量墙体脱落的建筑物识别正确率低些。因为部分墙皮或少量墙体脱落的图片中,一般也包含裂缝,很容易造成误判。这也是地震灾害判别的一个特点,即破坏严重的类别中,会包含轻微破坏的图像特征。
2)将此模型应用于2021年5月22日的青海玛多7.4级地震的震害图片识别。正确识别率为85.71%,与训练时的识别正确率相当。灾情图片识别和制作灾情分布图的实时完成,相对于其他方法的灾情处理,具有数据易采集,可以对数据实时处理的优势,并且其灾情在空间描述和灾情准确度上更加精准,有为地震后的抗震救灾指挥提供信息支持的潜力。
3)基于对国内外地震受损建筑物数据的收集,建立了一个大型专题数据集,并建立了一个针对社交媒体的相关图片数据的分类方法。
4)文中所采用的技术路线,具有智能化、自动化特征,因而可以有效应对地震的突发性的潜力,可以大幅的缩短从灾情数据收集,到最终制作建筑物受损分布图的时间。
5)本模型在识别部分墙皮或少量墙体脱落时的识别精度相对差一些,说明模型在不同尺度特征提取方面,还需要进一步提高,需要后续的进一步研究。另外,在将来的研究中,除了继续扩大数据数量,还应该研究适合小数据量的算法模型。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
东方剑·消防救援(2022年7期)2022-07-16
东方剑·消防救援(2022年1期)2022-01-17
中国石油石化(2021年16期)2021-10-14
铁道建筑技术(2021年4期)2021-07-21
作文小学中年级(2020年6期)2020-07-24
小学生学习指导(低年级)(2019年9期)2019-09-25
公民与法治(2016年17期)2016-05-17
小天使·二年级语数英综合(2015年12期)2015-12-04
河南科技(2014年24期)2014-02-27
