
基于相关向量机的网络舆情反转预测研究
2023-05-14 20:48:00艾敬怡耿亮安彧胡孜睿
计算机时代 2023年5期
艾敬怡 耿亮 安彧 胡孜睿

摘 要: 根据前人研究成果对网络舆情影响因素进行分析,构建出基于相关向量机的网络舆情反转预测模型。通过对46个舆情事件的训练和预测,发现相关向量机的预测精度和预测时间均优于支持向量机。由此可知,相关向量机具有良好的应用前景,对于及时发现反转舆情,规避舆情反转风险具有现实意义。
關键词: 网络舆情; 舆情反转; 相关向量机; 支持向量机
中图分类号:G206.3 文献标识码:A 文章编号:1006-8228(2023)05-113-05
Research on the prediction of network public opinion reversal
based on relevance vector machine
Ai Jingyi, Geng Liang, An Yu, Hu Zirui
(School of Science, Hubei University of Technology, Wuhan, Hubei 430068, China)
Abstract: In this paper, we analyze the influencing factors of network public opinion, and construct a prediction model of network public opinion reversal based on RVM. Through the training and prediction of 46 public opinion events, it is found that the prediction accuracy and prediction time of RVM are better than those of SVM. It can be seen that RVM has good application prospects, which is of practical significance for timely detection and avoidance of the risk of public opinion reversal.
Key words: network public opinion; public opinion reversal; relevance vector machine (RVM); support vector machine (SVM)
0 引言
据第49次《中国互联网络发展状况统计报告》显示,截至2021年12月,我国网民规模达10.32亿,网民人均每周上网时长为28.5小时[1]。网络舆情事件逐渐呈现出频率高、规模大、传播门槛低、影响广等特点,这增加了大众甄别、判断虚假舆情的难度[2,3]。网络舆情反转在传播过程中,网民的态度情绪前后互逆,当更多的事件细节不断出现,真相慢慢浮出水面时,该事件的热度可能会再一次猛然上升,使得舆情事件爆发频次增加,讨论时间延长,舆情的发展环境呈现出与普通舆情不同的状态,增加了政府或相关监管部门治理网络舆情的难度,有些舆情反转事件甚至会引发社会不稳定情绪和社会矛盾[4]。面对网络舆情反转带来的一系列影响,本文探究了网络舆情反转的影响因素,基于相关向量机(RVM)的方法构建了网络舆情反转预测模型,预测网络舆情事件是否会反转,并与传统的支持向量机模型进行对比分析,最终获得更为准确的预测结果,期望能为政府治理网络舆情反转提供参考依据,构建清朗的网络环境。
1 研究现状
1.1 网络舆情的定义与特征
对于网络舆情的定义,不同的学者对其有着不同的见解与认识。姜胜洪认为网络舆情是指媒体工作者或公民借助互联网,对某一社会问题或热点事件等的集中反映,这些意见或言论一般具有一定的影响力,同时带有倾向性[5];刘毅认为网络舆情就是指在网络空间内,公众对自己比较关心的或者与自身利益紧密相关的事务所拥有的多种情绪、意见和态度的综合[6]。
1.2 网络舆情反转相关研究
目前针对舆情反转的研究主要分为定性研究和定量研究两种方法。定性研究主要集中在网络舆情反转的内涵[7]、成因[8]、影响因素[9]和应对策略[10]等方面。袁野等从事件性质、报道倾向、报道形式、首发平台和网民相关度五个角度识别网络舆情反转的影响因素[9]。少数学者针对网络舆情反转做了定量研究,主要预测舆情反转事件的类别和预测舆情事件是否会发生反转。王楠等提出了改进KE-SMOTE算法,可以将不均衡的舆情事件样本进行处理,构建以神经网络为基础的集成学习预测模型[11]。
上述学者的研究成果为本文奠定了良好的理论基础,但是依旧存在只针对一个具体舆情反转事件进行分析和舆情事件数量较少的问题。相关向量机(RVM)是一种常用的监督学习算法,由于其优越的学习能力,已在医学影像处理,故障智能诊断和高光谱图像分类等方面取得了较好的应用效果,但是尚未出现运用相关向量机预测网络舆情反转的研究。基于此,本文随机抽取了46个网络舆情事件,选取了合理的舆情特征指标,构建了基于相关向量机方法的反转舆情预测模型,并与传统的支持向量机模型进行对比分析,从而为治理网络舆情提供参考支持。
2 相关向量机
2.1 相关向量机简介
相关向量机(Relevance Vector Machine,简称RVM)是一种与支持向量机(SVM)类似的稀疏概率模型,能较好地应用于回归问题和分类问题。RVM除了具有SVM的典型优点以外,还克服了SVM固有的一些局限,如与SVM相比,RVM更稀疏,从而测试时间更短,效率更高;RVM的核函数[K(x,xi)]不受Mercer条件的限制,其应用范围更广等。
2.2 RVM分类模型
对于二分类问题,假设训练样本集合为[X=xn,tnNn=1],[xn∈Rd],[tn∈0,1]为类别标签,则RVM的分类函数如式⑴所示:
[yx,w=n=1NwnKx,xn+w0] ⑴
其中,[w=w0,w1,…,wNT],[K(x,xn)]为核函数。
通过logistic sigmoid连接函数[σy=1/1+e-y]将[yx]转换为线性模型,则数据集的似然估计概率如式⑵所示:
[pt|w=n=1Nσyxn,wtn1-σyxn,w1-tn] ⑵
为了确保模型的稀疏性,RVM为每个权参数[wi]都引入了一个单独的超参数[αi],并定义其服从零均值高斯先验概率分布:
[pw|σ=i=0NNwi|o,α-1i] ⑶
假设给定新的待测试样本[x*],则相应的目标值[t*]的预测分布如式⑷所示:
[pt*|t=pt*|w,αpw,α|tdwdα] ⑷
3 网络舆情反转预测模型
3.1 网络舆情反转指标构建
根据信息传播机理和网络舆情的有关理论,网络舆情事件的组成要素包括主体、客体、本体和媒体四部分。本文以网络舆情的四个组成要素和相关学者的研究成果为依据构建网络舆情反转的指标体系,如表1所示。
⑴ 舆情事件类型(T)
《2020年中国互联网舆情报告》显示2015-2019年舆情事件类型主要集中在社会矛盾、公共安全和公共管理。本文令舆情事件类型[N∈0,1],将极易发生反转的社会公德与伦理、行政执法、民生生活和文化教育归为一类,赋值1,将不属于这几个类型的事件赋值为0。
⑵ 舆情首发主体权威度(A)
首发主体就是舆情突发事件的首次发布人或机构。权威媒体的新闻制作方式较严谨,而非权威媒体的新闻制作方式不受报道规则的拘束。因此首发主体是否为官方媒体,也是影响舆情是否会反转的关键因素。本文令舆情首发主体[N∈0,1],如该事件首发主体为信任度较高的官方媒体渠道则赋值为1,反之赋值为0。
⑶ 权威媒体参与度(PT)
对于网络事件来说,进行相关报道的权威媒体越多,说明事件的清晰度越高,可信程度越高,发生反转的可能性也就越低。因此,报道舆情事件的权威媒体数量也是衡量舆情是否反转的重要指标之一。本文根据国家信息中心发布的《2021中国网络媒体发展报告》确定了20家权威网络媒体,其中,中央媒体10家,商业媒体10家。令权威媒体参与度为[N∈-1,0,1],若有0-6家媒体报道此事件,说明参与度较低,赋值为-1;若有7-13家媒体报道则说明参与度中等,赋值为0;若有14-20家媒体报道则说明参与度较高,赋值为1。
⑷ 舆情热度(H)
舆情热度指的是舆情事件受关注的程度。舆情热度通常是由原创微博发布数(O)、转发数(B)、评论数(C)和点赞数(D)来体现。
① 本文借鉴文献[12]的方法建立舆情热度评价指标体系,所有数据以天为时间单位进行统计,其对应关系如下所示。
第[i]天的原创微博发布数、转发数、评论数、点赞数分别为:
[Oi=n,Bi=j=1nbi,j,Ci=j=1nci,j,Di=j=1ndi,j] ⑸
因此第[i]天的舆情热度[Hi]表达式为:
[Hi=w1×Oi+w2×Bi+w3×Ci+w4×Di] ⑹
② 本文利用信息熵[13]計算各项指标的权重。
本文采用效益性指标,为了消除指标类型不同和量纲不一致的问题所带来的影响,使用极值法对该指标进行无量纲化处理,得到第[j]项指标的熵权值为:
[wj=1-ejj=1n1-ej=1-ejn-j=1nej0≤wj≤1且j=1nwj=1] ⑺
⑸ 视听化程度(E)
视听化程度用以衡量网络舆情事件的传播方式,分为纯文本类、图片加文本类和视频加文本类。一般认为视听化比例越高的事件,其内容直观性更强,所包含的信息量也就越多,越难以造假。其计算方式参考舆情热度。
因此,第[i]天的舆情视听化程度[Ei]为:
[Ei=w5×PVi+w6×PPi] ⑻
[PVi]为第[i]天的视频微博数占博文总数比例,[PPi]为第[i]天的图片微博数占博文总数比例。
⑹ 网民情感倾向(ET)
网民情感倾向是指公众对此次舆情事件的所表现出的主观态度,可分为正向、负面和中立三种状态。原创微博最能体现网民的观点态度,本文借鉴文献[4]的方法计算网民情感倾向。
第[i]天网民负向情感的占比率为[Pi,-],正向情感的占比率为[Pi,+],中立情感的占比率为[Pi,0]:
[Pi,-=Ni,-NAi,Pi,+=Ni,+NAi,Pi,0=Ni,0NAi] ⑼
其中,[Ni,-]、[Ni,+]、[Ni,0]分别表示第[i]天网民负向、正向、中立情感的原创微博数,[NAi]表示第[i]天原创博文总数量。
⑺ 事件-网民相关度(RE)
事件-网民相关度是指网络舆情事件与网民的利益相关程度。本文令网民相关度为[N∈0,1,2],一般社会现象定义为弱关联,赋值为0;涉及公共利益的公共服务、基础等事件属于中关联,赋值1;涉及公众财产和生命安全的事件则属于强关联,则赋值2[9]。
3.2 构建基于RVM的网络舆情反转模型
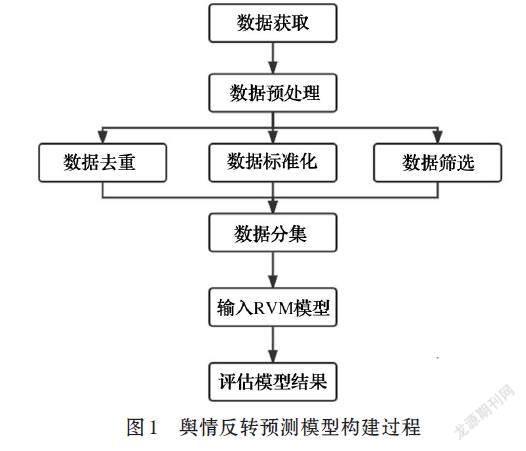
基于RVM的网络舆情反转预测模型实现过程如图1所示。
⑴ 数据获取。从搜狐网、新华网等主流网站和清博大数据等平台获得舆情事件的一些具体信息并进行分析。运用GooSeker软件爬取微博平台舆情事件的相关数据,如评论数、转发数、首发平台和权威媒体参与数等。
⑵ 数据预处理。对原始指标的数据进行归一化处理。根据指标构建过程可知输入数据为:[x=T,A,PT,Hi,Ei,Pi,-,Pi,+,Pi,0,RE],同时输出数据的类别标签为是否发生反转,令[y∈0,1],其中0表示事件不发生反转,1表示事件发生反转。
⑶ 将获得的数据分成两类,训练样本和测试样本,以标准化处理过的训练数据进行RVM预测模型的训练,选取合适的核函数和核函数参数,得到符合此数据指标精度要求的RVM预测模型。
⑷ 将标准化处理过的测试集输入到RVM模型中进行性能测试并分析结果。
4 模型运用与评估
4.1 模型应用实例
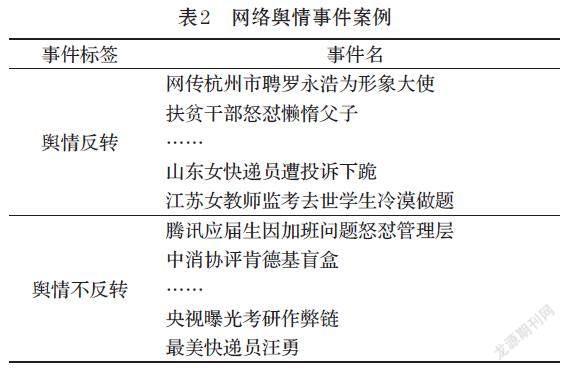
本文随机抽取了46个2016~2021年发生的网络舆情热点事件,其中舆情反转事件和舆情不反转事件各23个,选取30个事件作为训练样本集,剩余16个事件作为测试样本集。事件的相关信息如表2所示。
通过GooSeker等平台软件爬取舆情事件相关信息。首先确定舆情事件的关键词,爬取一定时间下有关此关键词的所有原创博文信息。本文选择了事件发生后24小时内的相关信息进行分析。
将已得到的指标值与标签输入matlab软件分别进行RVM和SVM模型的构建与训练,并进行接下來的测试,得到测试样本的预测结果如表3所示。
4.2 模型的评估与验证
在模型的评估过程中,通常会使用准确率、精确率、召回率和特异度四个指标,其具体含义如表4所示。
在本文中正类为舆情反转事件,负类为舆情不反转事件。由此可得到RVM模型和SVM模型的总体评估结果和验证结果如表5、表 6所示。
根据实验结果可以看出,RVM算法在舆情反转事件中的预测效果较好,总体准确率较高,其值为0.875,而SVM模型的总体准确率为0.625。相对RVM模型来说,SVM模型在反转事件的预测上表现出了较差的效果,八个舆情反转事件中只正确识别出了二个事件,其余事件全部错分为舆情不反转事件,RVM模型在舆情反转和不反转事件中都只错分了一个事件。
因为两种模型都是在matlab软件中实现的,所以可以比较两种模型对样本的训练时间和预测时间如表7所示。由此可知,相关向量机的训练时间较长但是预测时间较短,在进行大规模舆情时间的预测时,数据量较大,使用RVM模型能够大幅缩短预测时间,具有时效性。
本文的目的是要根据舆情事件的初期指标值,正确预测舆情事件的反转与否,从而为营造清朗的网络空间提供参考和帮助。从预测准确度上看,RVM模型比SVM模型的预测精度更高,能较好地识别出舆情反转事件;从预测时间角度看,RVM模型的预测时间较SVM模型的短,在大规模预测舆情事件时具有更实际的应用前景。
5 结束语
本文借鉴了网络舆情及其反转的相关理论和研究成果,对影响舆情事件反转与否的因素指标进行了分析并将其量化处理为模型指标,构建了基于相关向量机的网络舆情反转预测模型。通过对爬取到的46个样本数据进行训练和预测来评估RVM模型,并将其与常用的SVM模型进行对比、分析,得到了RVM模型比SVM模型更具有预测优势的结论。
同时本文也还存在一些问题。如模型输出结果只有反转与不反转两类标签,在后续的研究中可以将预测准确度进行细化;此外,可以增加模型的指标,如网民年龄分布和地域分布或者事件扩散程度等,达到得到更为准确的预测结果。
参考文献(References):
[1] 中国互联网络中心.第49次中国互联网络发展状况统计报告[R/OL].(2022-02-25)[2022-06-24].http://www.cnnic.net.cn/n4/2022/0401/c88-1131.html
[2] 张明新.国内网络舆情建模与仿真研究综述[J].系统仿真学报,2019,31(10):1983-1994
[3] 田世海,孙美琪,张家毓.基于贝叶斯网络的自媒体舆情反转预测[J].情报理论与实践,2019,42(2):127-133
[4] 江长斌,邹悦琦,王虎,等.基于SVM的自媒体舆情反转预测研究[J].情报科学,2021,39(4):47-53,61
[5] 姜胜洪.网络舆情的内涵及主要特点[J].理论界,2010(3):151-152
[6] 刘毅.网络舆情与政府治理范式的转变[J].前沿,2006(10):140-143
[7] 夏一雪,兰月新,刘茉,等.大数据环境下网络舆情反转机理与预测研究[J].情报杂志,2018,37(8):92-96,207
[8] 孙好.后真相时代舆情反转的成因探析[J].青年记者,2018(23):18-19
[9] 袁野,兰月新,张鹏,等.基于系统聚类的反转网络舆情分类及预测研究[J].情报科学,2017,35(9):54-60
[10] 刘琪,肖人彬.观点动力学视角下基于意见领袖的网络舆情反转研究[J].复杂系统与复杂性科学,2019,16(1):1-13
[11] 王楠,李海荣,谭舒孺.基于舆情事件演化分析及改进KE-SMOTE算法的舆情反转预测研究[J].数据分析与知识发现,2022,6(2):396-407
[12] 杨树仁,沈洪远.基于相关向量机的机器学习算法研究与应用[J].计算技术与自动化,2010,29(1):43-47
[13] 魏志惠,何跃.基于信息熵和未确知测度模型的微博意见
领袖识别——以“甘肃庆阳校车突发事件”为例[J].情报科学,2014,32(10):38-43
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
遵义(2018年20期)2018-10-19 07:15:06
中国公路(2017年9期)2017-07-25 13:26:38
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
中国民政(2016年24期)2016-02-11 03:34:38
新高考·高二数学(2015年11期)2015-12-23 18:17:44
传媒国际评论(2014年1期)2014-02-27 07:12:12
