
基于XGBoost-LightGBM的保险理赔预测研究
2023-05-14 21:49:59丁海博张睿崔丽玲
计算机时代 2023年5期
丁海博 张睿 崔丽玲

摘 要: 为提高保险公司对保险理赔的预测精度,提出一种基于多模型融合的XGBoost-LightGBM预测方法。构建XGBoost模型与LightGBM模型,使用Optuna框架对模型参数进行优化,结合MAPE-RW(Mean Absolute Error-reciprocalweight)算法确定融合权重,将两个模型的预测结果加权结合作为最终组合模型的预测结果。以Allstate公司的数据为例,对该组合模型进行验证,结果表明:与随机森林、Lasso回归、SVM及单个XGBoost模型、LightGBM模型相比较,XGBoost-LightGBM组合模型有最低的平均绝对误差(MAE)值,预测精度最高。
关键词: XGBoost; LightGBM; 多模型融合; 保险理赔预测
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2023)05-61-04
Research on insurance claims prediction based on XGBoost-LightGBM
Ding Haibo, Zhang Rui, Cui Liling
(Hunan University of Technology, Zhuzhou, Hunan 412007, China)
Abstract: In order to improve the prediction accuracy of insurance claims by insurance companies, an XGBoost-LightGBM prediction method based on multi-model fusion is proposed. The XGBoost model and LightGBM model are constructed, the model parameters are optimized using the Optuna framework, the fusion weights are determined by combining the mean absolute percentage error-reciprocal weight (MAPE-RW) algorithm, and the prediction results of the two models are weighted and combined as the final combined model prediction results. Taking the data of Allstate company as an example to verify the combined model, the results show that compared with the random forest, Lasso, SVM, single XGBoost model and LightGBM model, the XGBoost-LightGBM combined model has the lowest mean absolute error (MAE) value and the highest prediction accuracy.
Key words: XGBoost; LightGBM; multi-model fusion; insurance claim forecast
0 引言
保险理赔预测是指运用理赔的历史经验,对投保人提出的理赔要求进行分析和预测,判断其存在保险欺诈的可能性,预测的精度至关重要[1]。
保险理赔预测问题是典型的回归问题。目前,机器学习算法被广泛用于解决各种回归问题上,如支持向量机(SVM)[2]、随机森林[3]、神经网络[4]等。使用单一模型继续提高预测精度已变得十分困难,因为单一模型在处理某个问题时容易遇到模型泛化瓶颈。模型融合通过科学的方法对多个模型进行融合,综合各个模型的优点从而提高模型的泛化能力。多模型融合方法被广泛应用于各种精度预测问题上。文献[5]使用自适应权重的组合模型对发电量进行预测;文献[6]提出一种基于多特征融合和XGBoost-LightGBM-ConvLSTM的组合模型对短期光伏发电量进行预测;文献[7]构建基于Stacking的集成学习模型,融合多种机器学习算法对数据资源价格进行预测。上述研究都使用了较为复杂的模型进行融合,取得了比较简单、单一模型更高的预测精度。目前被广泛使用的集成学习、深度学习等模型的参数较多并且复杂性较大,使用传统的网格搜索调整参数计算量大,而随机搜索不能保证给出最好的参数组合,模型的參数优化十分依赖个人经验。
为进一步提高保险理赔预测的精度,本文提出一种XGBoost-LightGBM组合模型,构建单个XGBoost模型和LightGBM模型,针对网格搜索和随机搜索在参数寻优时遇到的问题,使用Optuna[8]框架对模型进行参数优化,结果表明参数优化后的模型在预测精度上有较大的提升。分别使用优化后的XGBoost模型和LightGBM模型对测试样本进行预测,根据模型在验证集上的表现,通过平均绝对百分误差倒数权重(MAPE-RW)[9]确定模型融合权重并得到最终的XGBoost-LightGBM组合模型。本文使用美国Allstate公司的数据对组合模型的预测精度进行验证,结果表明,相较于随机森林、Lasso回归、SVM以及单个XGBoost、LightGBM模型,XGBoost-LightGBM组合模型有更高的预测精度。
1 相关理论
1.1 XGBoost模型
集成學习通过组合多个学习器来完成学习任务,XGBoost(extreme Gradient Boosting)是一种基于Boosting树模型的集成学习算法,由陈天奇等人于2016年提出[10]。XGBoost高效地实现了GBDT算法并进行了算法和工程上的许多改进,被工业界广泛应用[11,12]。
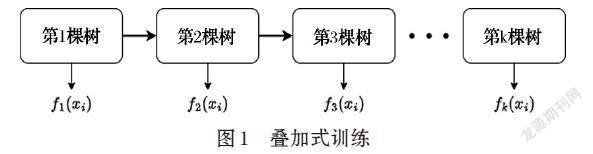
XGBoost是由[k]个基模型组成的一个加法模型:
[yi=k=1Kfkxi] ⑴
其中,[k]表示树的个数。[yi]为对第[i]个样本的预测值,[fk]为第[k]个树对样本[xi]的预测值。如图1所示。
构建目标函数:
[obj=i=1nlyi,yi+k=1KΩfk] ⑵
其中,[Ω(f)=γT+12λω2]为XGBoost中的正则项,[T]为叶节点个数,[ω]为每个叶子节点所对应的分数。传统的GBDT为了控制树的复杂度只会对树的叶子个数加正则项来控制,这是XGBoost相较于GBDT在算法层面的一个改进。
假设[y(0)i=0],则
[y1i=f1xi+y0i=f1xi+0] ⑶
[y2i=f2xi+y1i=f2xi+f1xi] ⑷
[yki=f1xi+f2xi+…+fkxi=yk-1i+fkxi] ⑸
即[y(k)i=y(k-1)i+fk(xi)],假设共有[k]棵树,则对样本[xi]的预测结果[yi=y(k)i],目标函数可改写为:
[obj=i=1nlyi,yk-1i+fkxi+j=1K-1Ωfj+ΩfK] ⑹
XGBoost相较于GBDT在算法层面的另一个改进就是引入二阶泰勒展开,将目标函数简化为如下的形式:
[minimize:i=1ngi?fkxi+12hi?f2kxi+ΩfK] ⑺
其中,[gi=?y(k-1)il(yi,yk-1i)],[hi=?2yk-1il(yi,y(k-1)i)]分别为损失函数关于[yk-1i]的一阶导和二阶导,因此在训练第[k]棵树时,[hi,gi]是已知的。
将遍历对象从样本改为叶子结点,样本[xi]落在叶结点[q(xi)]上,[Wq(xi)]为该叶节点的值,[Ij]为该叶节点的样本的集合。目标函数可化为:
[i=1ngi?Wqxi+12hi?W2qxi+γT+12λt=1Twt2]
[=j=1Ti∈Ijgi?wj+12i∈Ijhi+λ?wj2+λT] ⑻
令
[Hj=i∈Ijhi] ⑼
当树的结构固定时,可求得叶节点最佳的权重[w*j]以及最佳目标函数分别为:
[w*j=-GtHt+λ] ⑽
[obj=-12j=1TG2jHj+λ+γT] ⑾
确定目标函数后,对于每个特征,训练样本按特征值进行排序并选择分裂点,分列前的目标函数记作:
[obj1=-12GL+GR2HL+HR+λ+γ] ⑿
分裂后的目标函数为:
[obj2=-12G2LHL+λ+G2RHR+λ+2γ] ⒀
计算分裂的收益为:
[Gain=12G2LHL+λ+G2RHR+λ-GL+GR2HL+HR+λ-γ] ⒁
选择收益最大的分裂特征和分裂点。
1.2 LightGBM
轻量级梯度提升机LightGBM是一个实现GBDT算法的框架,由微软提出[13]。LightGBM被用于排序、分类、回归等多种机器学习的任务,支持高效率的并行训练[14]。LightGBM主要有一下改进:
⑴ 使用单边梯度采样算法,在计算信息增益时,只使用具有高梯度的数据,减少了时间开销。
⑵ 使用互斥特征捆绑可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
⑶ LightGBM算法在寻找最佳分裂点的时候,使用直方图算法,使得时间复杂度从O((特征值个数-1)*特征数)降到O((每个特征分箱个数-1)*特征数)。
⑷ 带深度限制的Leaf-wise的叶子生长策略,只对信息增益最大的点进行分裂,避免过拟合。
2 XGBoost-LightGBM组合模型
基于多模型融合的XGBoost-LightGBM组合模型构建流程如图2所示。
Optuna是一个自动超参数调整框架,可以与Pytorch、TensorFlow、Sklearn等其他框架一起使用。Optuna可使用网格搜索、随机搜索、贝叶斯搜索等采样器自动调整超参数。
使用Optuna框架对XGBoost和LightGBM模型进行参数优化后分别输出在验证集上的MAE值。为了提高组合后预测的精度,我们希望预测精度更高的模型所占权重越高,所以,结合MAE-RW算法对组合模型的权重进行计算。模型[i]在验证集上的测试结果为[MAEi],则权重[Wi]和最终的预测值[f]为:
[Wi=MAEjMAEi+MAEj] ⒂
[f=WXGBoost?fXGBoost+WLightGBM?fLightGBM] ⒃
其中[fXGBoost]、[fLightGBM]分别为XGBoost和LightGBM的预测值。
3 数据预处理
3.1 数据描述
本文数据来自美国保险巨头Allstate公司,该数据集包含188318个样本,每个样本包含116个类别属性(cat1~cat116)和14个连续属性(cont1~cont14),loss为保险赔偿的真实值。
3.2 数据预处理
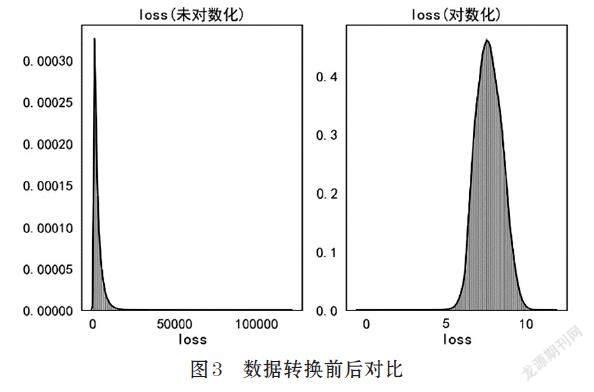
该数据集没有缺失数据,因此无需填充缺失值。将离散特征cat1~cat116转化为category特征,并重新编码。数据转换前后对比如图3所示。
偏度是统计数据分布偏斜方向和程度的度量,可以反应分布的不对称性。
[SkewX=EX-μσ3=k3σ3=k3k322] ⒄
公式⒄中,[k2],[k3]分别表示二阶和三阶中心矩。计算loss的偏度值为3.794,偏度值大于1,说明数据是倾斜的。为了更有利于后续建模,对loss值进行对数化后偏度值变为0.092,转换前后的数据如图3所示,使用转换后的loss值进行训练。
3.3 数据划分
按9:1的方式将数据集划分为训练集和测试集,训练集与测试集样本数如表1所示。
4 实验结果及分析
4.1 实验环境
本次实验在Windows11系统上进行,CPU为Inteli7-10700 @ 2.90GHz,16G内存,Python版本为3.7.13,开发环境为VS Code+ Anaconda3,使用了Numpy、Pandas、XGBoost、LightGBM等第三方库。
4.2 评价指标
本文使用平均绝对误差MAE作为模型的评价指标。
[MAE=1Ni=1Nyi-yi] ⒅
其中,[N]为预测样本数,[yi]和[yi]分别为模型对第[i]个样本的预测值和该样本的真实值。
4.3 模型构建与结果分析
使用Optuna框架分别对XGBoost和LightGBM进行参数寻优。使用测试集分别对优化前后的XGBoost模型和LightGBM模型进行测试,结果如表2所示。
从表2可以看出,使用Optuna框架优化后XGBoost和LightGBM相较于优化前平均绝对误差分别下降了6.297%、2.134%。优化后XGBoost和LightGBM的参数分别如表3、表4所示。
使用测试集对组合模型进行测试,将优化后的XGBoost模型和LightGBM模型并联起来通过MAE-RW算法得出最终的预测结果。同时,为了验证XGBoost-LightGBM组合模型相较于其他模型的泛化性能,本次实验给出了随机森林(RF)、Lasso回归、支持向量机(SVM)在测试集上的MAE值,实验结果如表5所示。
由表5可以看出,XGBoost-LightGBM组合模型相较于XGBoost模型和LightGBM模型预测误差均有下降,说明融合策略提高了预测精度。与RF、Lasso回归、SVM相比,XGBoost-LightGBM组合模型的MAE值分别降低了7.050%、11.426%、9.034%,实现了更高精度的预测。
5 结论
为提高保险理赔预测精度,本文提出一种基于多模型融合的XGBoost-LightGBM预测方法。使用并行的XGBoost、LightGBM模型,分别对测试样本进行预测并对结果进行融合,通过平均MAPE-RW算法确定模型融合权重。针对XGBoost、LightGBM模型参数较多,调参复杂的问题,本文使用Optuna框架分别对XGBoost、LightGBM模型进行参数寻优,提高了单一模型的预测精度。
实验结果表明,与RF、Lasso回归、SVM以及单一XGBoost、LightGBM模型相比,该组合模型在测试集上表现出了更高的预测精度。
参考文献(References):
[1] 张健,冯建华.数据预处理在保险理赔预测中的应用[J].计算机工程与设计,2005(9):2537-2539,2564
[2] 陈荣.基于支持向量回归的旅游短期客流量预测模型研究[D].博士,合肥工业大学,2014
[3] 夏晓圣,陈菁菁,王佳佳,等.基于随机森林模型的中国PM_(2.5)浓度影响因素分析[J].环境科学,2020,41(5):2057-2065
[4] 焦李成,杨淑媛,刘芳,等.神经网络七十年:回顾与展望[J].计算机学报,2016,39(8):1697-1716
[5] 贾睿,杨国华,郑豪丰,等.基于自适应权重的CNN-LSTM&GRU组合风电功率预测方法[J].中国电力,2022,55(5):47-56,110
[6] 王俊杰,毕利,张凯,等.基于多特征融合和XGBoost-LightGBM-ConvLSTM的短期光伏发电量预测[J].太阳能學报,2021:1-7
[7] 沈俊鑫,赵雪杉.基于Stacking多算法融合模型的数据资源定价方法研究[J].情报理论与实践,2022:1-12
[8] Akiba T, Sano S, Yanase T, et al. Optuna: A next-generation hyperparameter optimization framework[C]//Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining,2019:2623-2631
[9] 庄家懿,杨国华,郑豪丰,等.基于多模型融合的CNN-LSTM-XGBoost短期电力负荷预测方法[J].中国电力,2021,54(5):46-55
[10] Chen T, Guestrin C. Xgboost: A scalable tree boostingsystem[C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining,2016:785-794
[11] Ogunleye A, Wang Q G. XGBoost model for chronickidney disease diagnosis[J]. IEEE/ACM transactions on computational biology and bioinformatics,2019,17(6):2131-2140
[12] Dhaliwal S S, Nahid A A, Abbas R. Effective intrusiondetection system using XGBoost[J]. Information,2018,9(7):149
[13] Ke G, Meng Q, Finley T, et al. Lightgbm: A highlyefficient gradient boosting decision tree[J]. Advances in neural information processing systems,2017,30
[14] 马晓君,沙靖岚,牛雪琪. 基于LightGBM算法的P2P项目信用评级模型的设计及应用[J]. 数量经济技术经济研究,2018,35(5):144-160
