
先秦汉语词义消歧研究
2023-05-13 13:09于丽丽
文教资料 2023年24期
于丽丽


摘 要:本文调研了现代汉语领域的词义消歧研究现状,分析了目前词义消歧所采用的相关技术,确定出面向古代汉语信息处理的词语义项区分应该遵循的原则和方法。提出在现有的词义消歧理论和技术的基础上,采用机器学习的方法,选择合适的特征,使用广泛应用于信息处理的高效率的CRF分类模型,将统计模型和语言学知识有机结合起来,基于NaiveBayes、KNN、RFR-SUM、CRF、MaxEnt模型对“如”“将”“我”“信”“闻”“之”“能”等古代汉语高频、典型词进行单分类器的词义消歧实验。根据单分类器消歧性能,运用乘法法则、均值法则、最大值法则、投票法则等集成法则进行了分类器集成消歧实验。
关键词:古汉语 词义 集成 分类器
词义消歧一直是自然语言处理中的热点和难点问题,诸多学者已在现代汉语领域展开了一定研究,而在古代汉语领域,却很少有人涉足,本文主要就古代汉语的词义消歧问题进行一些探索。
一、课题的提出
词义研究有着悠久的历史,可以粗略地分为语文学时期、传统语义学时期和现代语义学时期。早在汉代,随着儒家经典的各种注书、辞书的大量涌现,进而逐渐形成了一门以研究词义为出发点和落脚点的具有实用意义的学问,即传统的训诂学。两千多年的传统训诂学对上古汉语的词义解释、词源考证、同义词辨析等方面进行了深入的分析,取得了豐硕的成果,逐渐成为语言学的一个分支——词汇学的重要内容。
在现代语义学时期,汉语词义系统和汉语语义学模式的建立一直是语言学界和信息处理界研究和关注的热点。在信息处理迅猛发展的今天,训诂学的发展应当从训释一词一语的狭小天地中走出来,改变传统以手工为主的研究方式,在研究方法上要有新突破,这都有待于计算机的参与,从而在浩渺的原始文献中实现快速检索和校对、考证研究、文白自动翻译等工作。这是语言研究与计算机科学的结合在信息时代的一个突出要求。中文信息处理技术的先进性必能为传统学科的研究提供更为科学的手段,推动训诂研究的现代化。
古籍的词汇考释等整理工作历来是靠人力手工。20世纪80年代以来,把计算机引入古汉字考释领域,利用计算机技术进行古籍整理工作等受到越来越多研究者的重视,已经研制出一些古籍整理计算机系统,如四川大学的“中文索引编制”、陕西师范大学的“十三经词语索引”、台湾东吴大学的“诸子集成系统”等,这些系统普遍具有阅读、检索、统计、排序、打印等功能。[1]目前古籍数字化的工作还刚刚起步,特别是先秦汉语的信息处理大体还处于字处理阶段,以解决古文字的输入输出、文献逐字索引等问题为主要研究内容。文本词汇级别上的古代汉语信息处理包括分词、词性标注等,有了一些尝试性的探索实践。而在词义标注方面的研究更是相对比较薄弱,仍是自然语言理解系统面临的最大问题。“词义瓶颈”问题还得需要我们从基础入手,为建立一个大规模、高质量的古代汉语词义标注语料库奠定基础,以推动信息处理中词汇级别上的这一最大难题的解决。简言之,语言研究的发展和语言应用的需求,促使了我们本课题的提出。
二、研究内容
词义研究在中国语言学界属于比较薄弱的领域,其原因主要有:① 语义研究本身固有的难度;② 缺乏相应的理论指导;③ 缺乏一套行之有效的可操作的分析方法。[2]随着语言研究的深入以及语言工程实践的推动,词汇语义学成为当今语言学中一个备受关注的研究热点。研究者越来越注重吸收语言学与其他学科领域如句法学、认知语言学、语料库语言学、计算语言学等的相关理论和方法来充实词汇语义研究,也越来越讲究分析过程的可观察性、可操作性及研究成果的客观性和可验证性,尤其强调要在词语的使用环境中观察词义成分的差别,而不是仅仅依赖于内省的直觉判断。从计算的角度来看待汉语词语的多义现象,或许会有一番新的景象。[3]
本文的研究内容主要如下:
(1)通过对《春秋左传》语料的词汇、词频等的统计,结合陈克炯《左传详解词典》 [4]和《汉语大词典》 [5]的义项解释考察,根据相关的词义分类理论,基于上下文特征,重点研究“将”“我”“如”“信”“闻”“之”等义项复杂的词的语义消歧。
(2)在资源建设问题上,以《春秋左传》中的词汇为底本,在考察了该部书的分词、词性标注以及词频统计等工作的基础上,针对词义分布的不同特点,通过抓典型,引入朴素贝叶斯(Naive Bayes,简称NB)、K近邻(KNN)、相对词频比(RFR-SUM)、条件随机场(CRF)及最大熵(MaxEnt)等分类模型进行了消歧实验,并采用多分类器集成的方法,进行了多种集成模式的消歧效果研究。该研究将会使标注者的标注速度、标注正确率和标注一致性得到显著的提高。
三、研究过程
(一)实验过程
我们采用了五个性能各异的单分类器模型,即CRF、KNN、MaxEnt、NB、RFR-SUM,以及四种基于概率的集成法则(用Avg、Max、Pr、Mv分别代表均值法则、最大值法则、乘法法则、简单投票)。为了考察如何能发挥分类器集成的优势,我们采取了一些集成策略,在具体实验时,我们发现NB和KNN的输出概率很多都为0,考虑这会影响乘法集成的效果,所以我们做了归一化处理,即对每个概率加上一个小数0.00001,再求概率。用斜线柱形图表示单分类器第一次利用集成法则形成的结果,网格柱形图表示将集成后的结果再与CRF、KNN进行投票后产生的最终结果。
(1)对五个分类器进行四种集成,然后将所得的预测结果再与最好的两个分类(CRF、KNN)进行投票预测。结果如图1所示。
从图1中的数据可以看出,用斜线表示的四种集成法则后的平均F值都低于CRF的F值,说明不管分类器的差异,把所有单分类器进行集成,效果并没有提高。在进行了二次投票之后,四种法则的F值都有不同程度的提高,尤其是Pr的F值达到了87%以上,Mv的F值提高了1.33%。
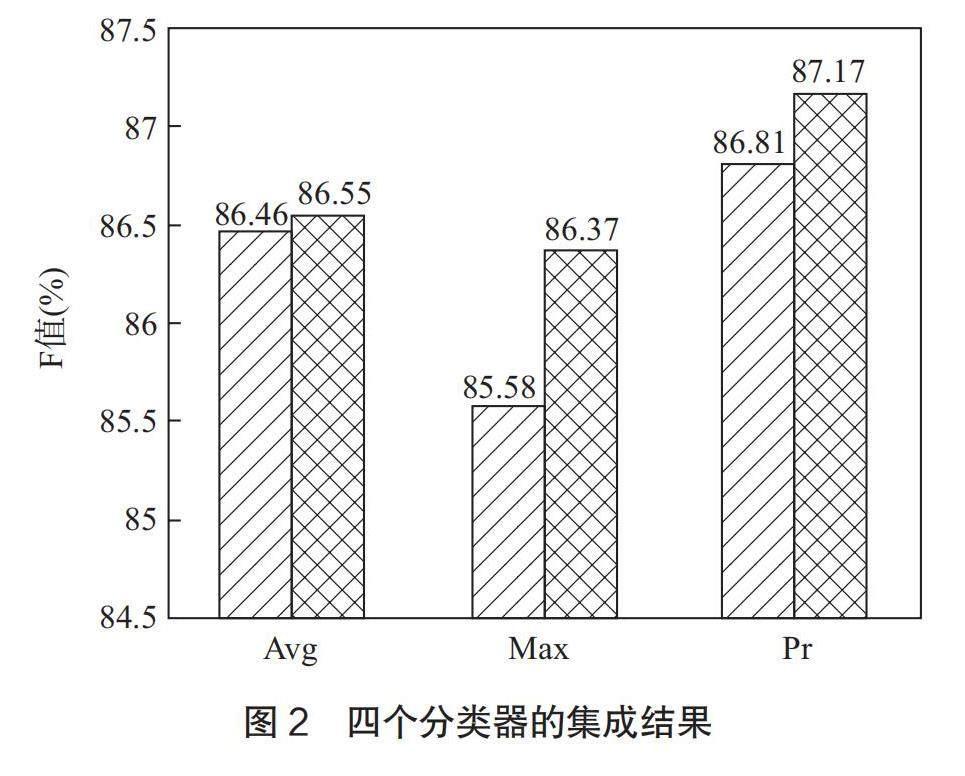
(2)由于RFR-SUM效果相对较低,我们对CRF、KNN、MaxEnt、NB四个分类器按照Avg、Max、Pr法则进行集成,再将所得的预测结果与CRF、KNN进行投票预测。结果如图2所示。
比较图1与图2,可以看出,除了Avg的F值没有提高,Max和Pr的F值都有提高,并且Pr的最终F值达到87.17%。这说明在同样的条件下,加入性能较差的分类器会影响集成的总体效果。Pr在图1和图2中效果均是最好的。
(3)由于CRF和KNN是这五个单分类器中最好的两个,所以分别与MaxEnt、NB、RFR-SUM逐一按照四种法则进行集成,再将结果与CRF、KNN做投票,即两个性能高的分类器和另外三个分类器逐一集成测试。结果分别如图3—图5所示。
比较图3和图4,可以看出,虽然MaxEnt模型对这几个古代汉语高频词的消歧效果高于NB模型,但无论利用哪一种集成法则,MaxEnt模型与CRF、KNN模型的集成结果都不高于NB与CRF、KNN模型的集成结果。在图3和图5中,均是利用Avg得到的集成结果最好。但仍低于图4中的利用Pr得到的集成结果,图3是三个最好的单分类器的集成,但它们的结果均低于87%。这可以从一定程度上说明在进行集成的时候并不是效果最好的分类器放在一起集成效果就一定出色,而往往是互补性最好的再辅之利用合适的集成方法效果才会优。
(4)区别于前一个实验,我们进行CRF、MaxEnt、
NB的集成和CRF、MaxEnt、RFR-SUM的集成,再将所得的预测结果与CRF、KNN做投票预测。结果分别如图6和图7所示。
分别比较图4与图6、图5与图7,可以发现在其他条件不变的情况下,我们替换了一个处于中间性能的单分类器,将性能较好的KNN换成了稍逊的MaxEnt,四种法则下的集成结果都有明显幅度的下降。参与集成的单分类器的效果性能直接影响着最终的集成结果。
(5)尝试效果最差的三个集成模型(NB、MaxEnt、RFR-SUM),再将所得的预测结果与CRF、KNN做投票预测。目的是考察是否可以通过集成,使效果较差的几个单分类器通过集成形成一个较好的分类系统,结果如图8所示。
将三个效果最差的单分类器进行集成实验,目的是考察是否可以达到“三个诸葛亮,顶个臭皮匠”的效果。在我们的实验中,四种法则下都超过了原来的最差的三个单分类器的效果,说明集成方法也是至关重要的,同时Pr达到了最好效果。
在上面八个图中,我们进行了不同分类器组合的四种法则的集成,从结果可以看出Pr法则有五次取得最好效果,Avg法则三次取得最好效果。总的说来,在我们的实验所运用的集成方法中,乘法法则的效果最好,而且参与乘法集成的分类器性能越好,集成效果越佳。比较图2和图3,三个性能最好的单分类器的集成效果却均低于三个最好的再加一个较差的,这是模型所利用的特征等互补性强的缘故。
最后把效果最好的图2的集成结果列在表1中。
通过表1可以反映出:① 被消歧的词对词义的消歧方法十分敏感,甚至不同的词语需要不同的消歧策略方法。对于个别词,如“信”,在KNN单个分类器学习时,相比于另外的分类器较差,单个分类器的差值达10%左右,说明并不适合这种分类器的学习。② 三种集成结果中,“如”“信”“之”的集成后最优结果优于单个分类器,集成性能尤佳,而“将”和“我”消歧的最好结果是由CRF模型得到的。③ 在集成的过程中,不同的集成方法对集成结果影响甚大,平均效果由高到低排列为:乘法法则集成﹥均值法则集成﹥最大值集成﹥投票法则集成。
由表1可见,集成分类器的整体表现均得到不等程度的提升,最终平均结果还是较理想的,保持在86%以上,除了Max的略低于CRF的,其他均高于单个分类器的性能。如“信”,从表1中可见,三种集成的测试结果均高于单个分类模型,其中高于CRF模型4.09%,比KNN模型提高了14.29%,高于MaxEnt模型达8.17%,比NB模型提高了4.09%,比RFR-SUM模型高6.13%。多分类器的集成是能够减少单个分类器的误差,提高预测性能和分类精度的,在我们的实验中这样的优势充分显现了出来。可以尽可能多地充分利用各种有效的特征,如词频、词形、词性及其各种共现等,将这些特征一起运用于单个分类器本很困难,而通过对多个分类器的集成,增加了信息量,更加充分利用目标词的上下文语境,减少单个分类器的误差,提高了消歧的效果。
(二)实验总结
对于实验结果的分析,从语料方面看,① “如”“将”“闻”的强势词义和弱势词义所在的句子数量差别显著,所以对于个别模型这也是消歧效果较好的原因之一。② “我”的义项分布比较均匀,而且意义的判别需要更大的上下文语境,简单的句子字面信息反映不出該词的实际意义。因此即使是我们在人工标注的过程中,也要不断地回到原文中寻找更大的语境来判别标注词义,对这样的词词义消歧困难更大。③ 语料已经过人工分词和词性标注,但仍存在一些标注失误,在一定程度上影响了实验结果。
从数据来看,CRF和KNN模型对于多分类问题表现出来较好的效果和稳定性,主要在于CRF模型具有表达长距离依赖和组合特征的能力,把所有特征进行全局归一化,进而求得最优值;KNN由于其简单的思想,取得令人满意的效果。MaxEnt可以任意地选择特征,由于在其每一节点都要进行归一化而只能得到局部的最优值,同时也带来标记偏差的问题,所以F值略逊于CRF模型。RFR-SUM模型在并未对生语料深加工的情况下,未加入词性等信息,仍取得了较好的效果。此外,现代汉语词义消歧往往需要较大的上下文窗口,需考虑更多词的搭配等信息,而古汉语实验窗口的加大往往会产生更多的噪声,导致正确率的下降,无论是CRF模型还是MaxEnt消歧,窗口选择1或2效果均是最好的。
四、结语
本章主要研究有指导词义消歧集成方法,效果较理想,比单分类器性能有了一定的提高。但同样面临着有指导词义消歧方法的最大缺点——严重的数据稀疏问题。另外,当标注语料和测试语料不属于同一个领域时,消歧性能也有所下降,可移植性差。而且,一些低频义项可能在规模很大的语料中都不出现或者很少出现,从而导致有指导词义消歧方法的失效。总之,面对自然语言问题的复杂性和多变性,现有的语言处理模型和方法,有待于进一步改进和完善,并期待着新的更有效的模型和方法的出现。
基于统计的方法有其必然的缺陷,而基于规则的方法又缺乏一定规模的面向计算机可利用的古代汉语语义资源。至今在整个自然语言处理领域,语义的形式化与计算问题也还尚未建立起一套完整、系统的理论框架体系。我们尝试着使用了一些新的机器学习方法或新的数学模型,这些尝试和实验都带有很强的主观性。而且在技术实现上,许多实验改进也往往局限于对一些边角问题的修修补补,或者只是针对特定条件下一些具体问题的处理,未能从根本上建立一套广泛适用的处理策略。[6]词义消歧工作艰巨而意义重大,期望在一定程度上能促进实现工程化的实用目标。
第一,继续探索语言学知识和统计模型的有机结合,仍是我们今后工作的首要任务。充分把握一些语言学规则对某些类别的多义词或者多义词的某些义项具有很高的识别率这一规律,将统计模型和语言学知识结合的有益尝试推广到自然语言处理的相关领域中。
第二,寻找利用主动学习策略,扩大词义标注语料库规模,以缓解数据稀疏问题,也由此解决由于标注语料和测试语料所属领域不同而导致的消歧准确率下降问题。
参考文献:
[1] 朱小健.古籍整理通用系统及其中字典的编纂[J].语言文字应用,2000(3):99-103.
[2] 朱彦.取得动词释义研究[D].北京:北京大学,2005.
[3] 吴云芳.词义消歧研究:資源、方法与评测[J].当代语言学,2009(2):113-123.
[4] 陈克炯.左传详解词典[M]. 1版.郑州:中州古籍出版社,2004:96.
[5] 罗竹风.汉语大词典[M].上海:汉语大词典出版社,1993:237.
[6] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008:117.
猜你喜欢
潍坊学院学报(2021年4期)2021-11-20
西夏研究(2020年1期)2020-04-01
汉字汉语研究(2018年1期)2018-05-26
新高考(英语进阶)(2018年3期)2018-05-14
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
现代园艺(2016年17期)2016-10-17
语言与翻译(2014年3期)2014-07-12
语言与翻译(2014年1期)2014-07-10
语文知识(2014年3期)2014-02-28
