
面向养殖网箱巡检任务的强化学习训练系统*
2023-05-12 02:25林远山
计算机与数字工程 2023年1期
王 昊 林远山 李 然 于 红 王 芳
(1.大连海洋大学信息工程学院 大连 116023)(2.辽宁省海洋信息技术重点实验室 大连 116023)(3.设施渔业教育部重点实验室(大连海洋大学) 大连 116023)
1 引言
我国是海洋大国,海洋渔业是我国粮食安全保障体系的重要组成部分。多年来,我国以海水养殖为重点的海洋渔业迅猛发展,网箱养殖是我国海洋渔业生产重要组成部分[1]。随着水产养殖行业向集约化、自动化、信息化、智能化的方向发展,水下机器人作为重要的渔业设施装备,因其灵活性在其中也发挥越来越重要的作用[2~7]。
网箱定期巡检是网箱养殖过程中的必要环节。随着网箱养殖规模的扩大、网箱离岸距离的增加,传统人工网箱巡检的难度亦随之增加,对网箱巡检提出了新的要求,其中利用机器人实现网箱的自主巡检是未来的重要发展趋势之一,其研究具有重要的现实意义和价值。
水下机器人巡检方法种类繁多[8~13],其中基于强化学习的巡检方法近年来受到广泛关注[14~19]。强化学习方法与环境交互,并利用交互得到的数据进行模型学习。相较于其它巡检方法,强化学习方法在水下机器人应用中的优势在于:无需预先准备标注数据,无需事先了解水下机器人动力学知识,可对全部或部分非线性动力模型进行学习。因此,对诸如水下环境这样未知、复杂环境中的自主巡检问题,强化学习方法尤其适用[20~22]。
相较于地面和空中机器人,水下机器人的仿真平台数量较少,更无针对养殖场景的专门仿真。目前,针对水产养殖机器人的研究多是采用真实机器人在真实水下环境进行[23~25]。然而在真实水下环境中开展强化学习算法训练、测试和评估存在以下问题:
一是在强化学习训练中,需要通过大量随机探索来采样数据,在真实水下环境下进行实验成本高、效率低、危险性大。真实机器人本体成本相对较高;真实环境搭建成本巨大;离岸真实场景实验需要母船支持,成本高;实验过程机器人易受碰撞损坏和丢失;同时实验的开展还受到地点、气温、季节等因素的制约;数据采样效率低、质量低下。
二是缺乏一个通用的水下标准环境公平横向地对比不同的强化学习算法。在真实水下环境中,机器人本体、环境、任务不同,状态定义、回报函数定义、动作定义皆有区别,难以公平地横向对比多个算法之间的性能。
三是缺乏一个统一的简化环境规则。水下环境复杂,涉及因素众多,受风、浪、水压等复杂因素的严重干扰。刻画过细则模型训练难度大大提升,不利于模型的大规模应用。如何对实际水下环境、AUV 及其之间的交互关系进行抽象和简化,需对具体业务和强化学习算法有较为深刻的理解和研究。
为此,本文基于UUV Simulator[26]、ROS[27]、和OpenAI Gym[28],搭建了一个面向养殖网箱巡检任务的强化学习训练系统。首先在UUV Simulator 中实现了养殖网箱巡检场景的仿真。该场景中包含网箱、巡检机器人、各类传感器、水体环境,以及部分水体动力,如浮力、海流等。然后基于ROS 和OpenAI Gym 对仿真环境进行封装,标准化了强化学习算法与网箱巡检仿真环境的交互。依据传感器类别、网箱数量等的不同,预设了五种网箱养殖Gym环境,适用于不同强化学习算法的开发。用户也可在该系统中自定义、扩展环境。该系统可用于强化学习训练与性能评估,也可用于控制算法测试。最后,利用近端策略优化强化学习算法算法(Proximal Policy Optimization,PPO)[29]对系统进行测试。测试结果验证了系统的有效性、可用性和方便性。
2 系统总体结构
仿真系统由UUV Simulator、ROS、OpenAI Gym三部分构成,系统结构如图1 所示。UUV Simulator是一个水下环境仿真平台,该平台通过一套插件来模拟水下力学效应、致动器、传感器和外部干扰,且能够灵活地模块化配置新的水下场景和机器人。同时该仿真器提供了和ROS 的集成接口。OpenAI Gym是一个用于强化学习算法训练、测试和比较的工具包,它不依赖强化学习算法结构。其一方面内置了一批已定义好的经典环境集合,可供强化学习算法直接使用;另一方面它还提供了一套标准化环境定义接口,使用户可自定义、封装环境。OpenAI Gym使强化学习算法与环境的交互得以标准化,使用户专注算法本身,提升了算法的开发效率。ROS是运行在Linux 上的次级操作系统,是用来开发机器人的中间件。它制定了机器人开发的统一接口标准,提供了操作系统应用的各种服务,如:硬件抽象、底层设备控制、常用函数实现、进程间消息传递、软件包管理等。目前在机器人领域,ROS 是最广泛接受的机器人开发平台。
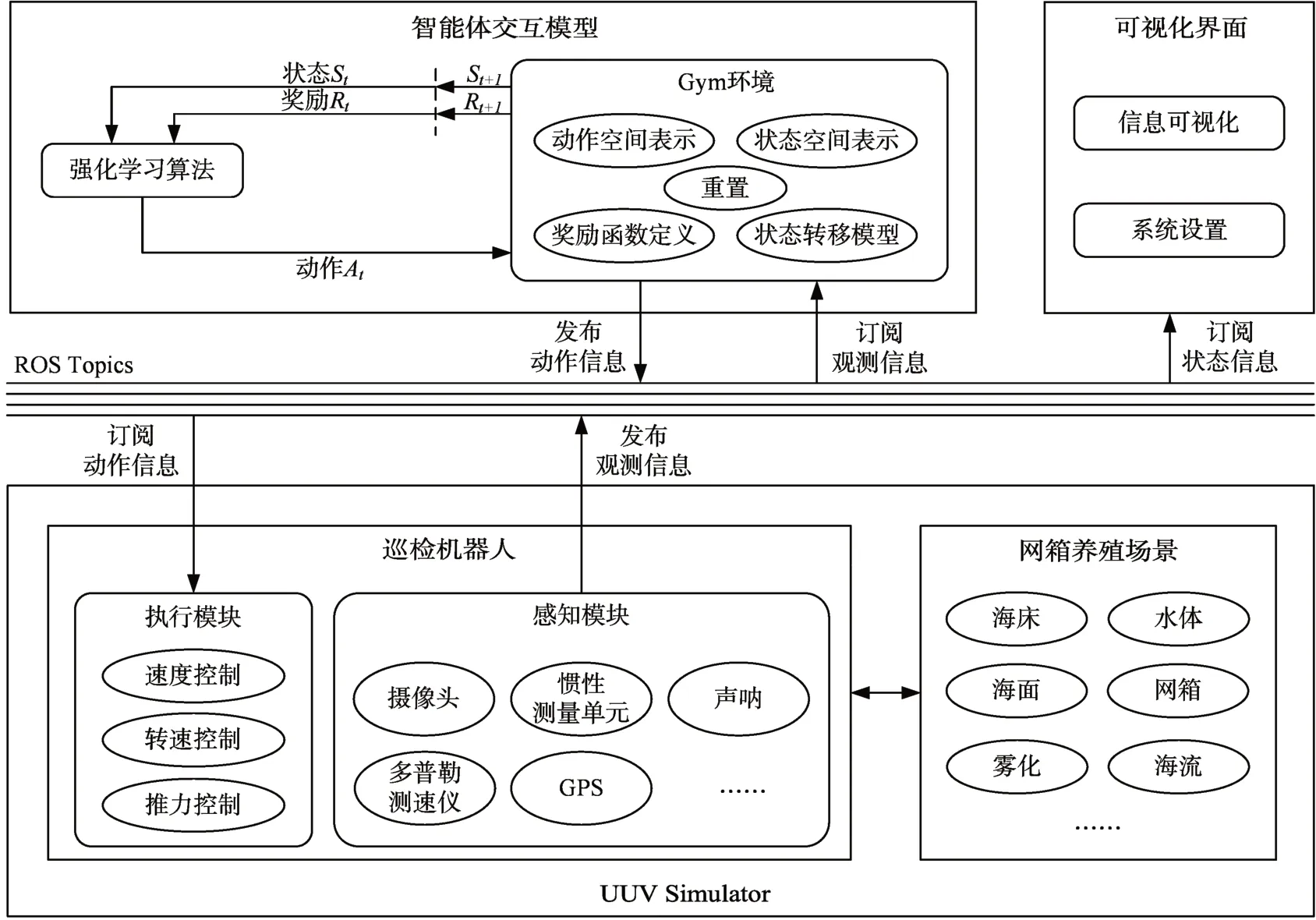
图1 系统架构
整个系统架构包含四大部分:网箱养殖巡检场景仿真、通信机制、智能体与环境交互和可视化界面。各部分描述如下:
1)网箱养殖巡检场景仿真。该部分包含两部分,一是对机器人工作环境,即网箱养殖场景的仿真,一是对执行巡检任务的机器人的仿真。该部分在UUV Simulator中实现。
(1)网箱养殖场景仿真:该部分实现对网箱养殖场景的仿真,即模拟巡检机器人的工作环境。网箱养殖场景实现了对海洋环境的仿真、网箱本体的仿真和水体动力学的仿真。巡检机器人通过搭载的传感器感知该场景中的环境数据,进而根据数据执行相应的动作。
(2)巡检机器人仿真:该部分实现对机器人本体,即机器人机械结构、外观的仿真;对传感器,例如摄像头、惯性测量单元、声呐等的仿真;对推进器的仿真,可实现前进、后退、上浮、下沉、悬停、任意角度转向等动作的模拟。
2)ROS Topics通信:系统中各个部分与仿真环境之间的通信,本文利用ROS的话题通信机制实现。
3)智能体与环境交互:该部分包含强化学习算法,及其训练环境。其中,训练环境即对网箱养殖场景仿真封装得到。封装基于OpenAI Gym 提供的标准接口和框架实现,包括对感知状态、机器人动作、奖励函数等的定义。
4)可视化界面:该部分包含数据信息可视化和系统设置两个部分。数据信息可视化部分实现了对机器人搭载的传感器获取的信息的可视化,以及机器人本身状态信息的可视化,包括线速度、角速度、姿态和运动轨迹等。系统设置部分实现ROS话题的订阅、日志路径设置等,方便开发人员对感知信息、对训练过程进行观察和评估。
3 网箱养殖场景仿真
网箱养殖场景在UUV Simulator 中构建。该场景包含三部分:海洋环境的仿真、养殖网箱的仿真和水体物理特性仿真。
3.1 海洋环境仿真
海洋环境的仿真,采用名为海洋盒(ocean_box)的世界模型实现,它包含海床、水体和海面三个实体模型。每个实体模型以模型目录形式存在。该目录中SDF(Simulator Description File,SDF)文件定义实体的视觉属性、惯性属性等。
3.1.1 海床仿真
海床仿真的具体做法是:首先通过3D 建模软件构建具有高低起伏的海床网格模型,然后在海床SDF 文件中对visual 标签下的material 参数进行配置,实现对海床网格模型的贴图,例如对其贴沙石图片,以获得海床的逼真视觉效果。
3.1.2 海面仿真
与海床仿真相同,海面仿真首先通过3D 建模软件构建海面表面网格模型,然后在海面SDF文件中对visual标签下的material参数进行配置,实现对海面网格模型的贴图,例如海浪纹理图形贴图,以获得逼真的海浪视觉效果。
3.1.3 水体仿真
水体具有一定的体积,浮力,水流流速和方向,此外由于海水中光衰现象,水体还具有雾化效果。水体体积范围由海面、海底和四条垂直线所构成的六面体所界定,通过在水体SDF 文件中对visual 标签下的pose 参数进行配置实现。雾化效果通过对world 文件中对scene 标签下fog 参数进行配置实现。水的密度、水流速度和方向通过对world 文件中相应参数进行配置实现仿真。
3.2 养殖网箱仿真
养殖所使用的网箱形状各异,较为常用的是圆柱形重力式网箱[30]。基于此,本文仿真实现了圆形重力式网箱。与海床、水体和海面实体模型相同,网箱实体作为一个独立实体模块存在。由3D建模软件构建圆柱形重力式网箱网格模型,通过对SDF文件进行参数配置实现网箱大小、位置、数量的设置。
3.3 海流仿真
海流生成以及作用到海底实体的过程为:由3.1.3 节中水体仿真可知,首先在world 文件中设置密度、水流速度和方向等数据;然后海流插件读取设置的数据,并通过相应的ROS话题发布数据。受海流作用的水下实体,例如机器人等在它的SDF文件中添加一个名为水下物体的插件,并订阅相应的ROS话题接受海流相关数据,接受海流的作用。如图2所示。

图2 海流插件实现
4 巡检机器人仿真
巡检机器人仿真可分为本体、感知器和执行器三个部分的仿真。
本体仿真实现对机器人外观、结构、静力学和动力学的仿真。机器人感知模块本质是一个传感器系统,其仿真包括各类传感器参数、布局等,以及实现传感器感知能力,即获取机器人自身状态信息和环境信息的仿真。执行模块的仿真,包括执行机构的参数、布局等仿真,以及实现接收控制指令,并通过驱动器等动力元件使机器人执行动作的仿真。
三个部分的仿真皆通过编写机器人描述文件(Unified Robot Description Format,URDF)来实现。
4.1 机器人本体仿真
UUV Simulator 中提供了以SF 30k 为原型的RexROV2,ECA A9 AUV 和LAUV 等几种水下机器人模型。本文选择实验室已有的开源水下机器人BlueROV2 为原型进行仿真。BlueROV2 性价比较高,是目前最受欢迎的开源水下机器人之一。
BlueROV2 长45.7cm,宽33.8cm,高25.4cm,最大额定深度为100m,拥有6 个推进器,其中包括四个水平推进器和两个垂直推进器,可实现5 自由度(DoF)的控制。
机器人本体的仿真主要包含视觉模型、碰撞模型、结构、静力学和动力学。模拟器渲染引擎使用的视觉几何模型为COLLADA 格式,碰撞模型为STL 格式,通常碰撞模型相较于视觉模型更加精简,以此提高碰撞计算的速度。在base.xacro 文件中配置了机器人的静力学参数,如质量、重心、惯量,以及视觉几何模型和碰撞几何模型。gazebo.xacro 中配置了机器人水动力学模型,如机器人的尺寸、浮心和福森运动方程。在虚拟环境中仿真的BlueROV2如图3所示。

图3 BlueROV2仿真
4.2 感知模块仿真
巡检机器人实现自主控制需搭载传感设备以获取其工作环境信息和其自身状态信息。工作环境信息,如环境的视觉信息、距离信息等;机器人自身状态信息,如机器人位姿信息、加速度信息、位移信息等;UUV Simulator 提供了多种虚拟传感器供选择和配置,包括摄像头(含广角摄像头)、惯性测量单元、侧扫声纳、多普勒计程仪、压力计、虚拟里程计等。这些虚拟传感器皆可通过插件实现。具体实现是在机器人描述文件sensors.xacro中加载配置各种传感器插件和位置参数,实现对传感器的仿真。
每个传感器的功能被封装为一个ROS节点,被称之为ROS 传感器节点。ROS 传感器节点将原始感知数据发布到指定ROS 话题上,强化学习算法、可视化界面等通过订阅指定ROS 话题获取传感器数据。
某些情况下,需要对原始感知数据进行一定预处理,这时可新建ROS 节点以扩展功能,我们称之为扩展节点。该节点订阅原始感知数据信息,完成预处理后再封装、发布处理后的数据。例如,在基于视觉的巡检任务中,可创建一个新的节点,用于对摄像头所获取的图像信息进行二值化、边缘检测等操作,然后将处理后提取的信息采用自定义消息类型重新封装并发布到自定义的话题上,供强化学习算法、可视化界面等订阅获取。扩展节点、传感器与强化学习算法、可视化界面的交互如图4 所示。

图4 感知模块流程图
4.3 执行模块仿真
运动控制是机器人巡检的关键。机器人接收控制指令,根据控制指令部署推进器执行相应的动作。在此系统中执行模块包含控制器、推进器管理器和六个推进器单元。具体实现方式是,在snip⁃pets.xacro 和actuators.xacro 中配置几何模型文件、推进器参数和位置。为生成推进器驱动机器人的控制力,需要计算推进器分配矩阵以将控制器输出的总控制力转化为对每个推进器的指令,这是由推进器管理器完成的。在.yaml 文件中配置推进器模型和话题,推进器管理器生成机器人机身框架和推进器框架之间的转换矩阵,即TAM(thruster alloca⁃tion matrix)文件,另外推进器管理器还根据TAM和配置参数生成指定数量的推进器模型和对应话题。控制器则是由相应的控制算法实现的控制器节点。
共存在三种可利用的运动控制方式:基于速度的运动控制、基于推力的运动控制和基于转速的运动控制。在基于速度的运动控制方式中,速度控制器被封装成ROS节点,称之为速度控制器节点。强化学习算法通过指定话题发布目标速度信息,速度控制器节点订阅该话题获取目标速度信息。在速度控制器节点内,目标速度首先被转换为总目标推力,然后根据分配矩阵将总目标推力分配给每个推进器,即每个推进器获取推力,最后每个推进器推力转换为转速,从而实现对机器人的运动控制,如图5所示。
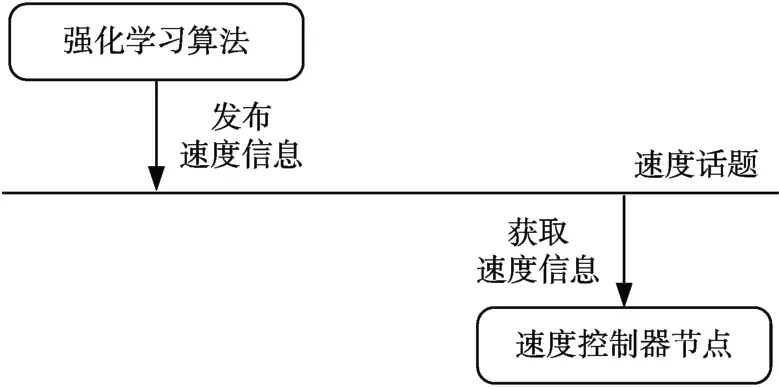
图5 基于速度控制方式中信息传递示意图
在基于推力的运动控制方式中,推动器管理器被封装成ROS节点,称之为推进器管理器节点。强化学习算法通过指定话题发布总目标推力信息,推进器管理器节点订阅该话题获取总目标推力信息。在推进器管理器节点内,根据分配矩阵将总目标推力分配给每个推进器,即每个推进器的推力,最后每个推进器推力转换为转速,从而实现对机器人的运动控制,如图6所示。

图6 基于推力控制方式中的信息传递示意图
在基于转速的运动控制方式中,推进器被封装成ROS节点,称之为推进器节点。控制指令为对每个推进器单元的单独推力,强化学习算法通过指定的话题发布所有推进器的推力信息,推进器模型订阅该话题获取对应推进器的推力信息,从而实现对机器人的运动控制。如图7所示。

图7 基于转速控制方式中的信息传递示意图
5 基于Open AI的仿真环境封装
系统基于OpenAI Gym 提供的标准化环境接口,将网箱养殖仿真场景封装成一套自定义的环境集合,用于面向网箱巡检任务的强化学习算法的开发。
环境接口的实现基于网箱养殖仿真系统中机器人的感知模块和执行模块,利用ROS的话题通信机制实现机器人感知状态信息的获取,以及机器人动作的执行。封装的环境作为中间件充当代理的角色在算法和仿真机器人之间传递动作和观测,如图8所示。
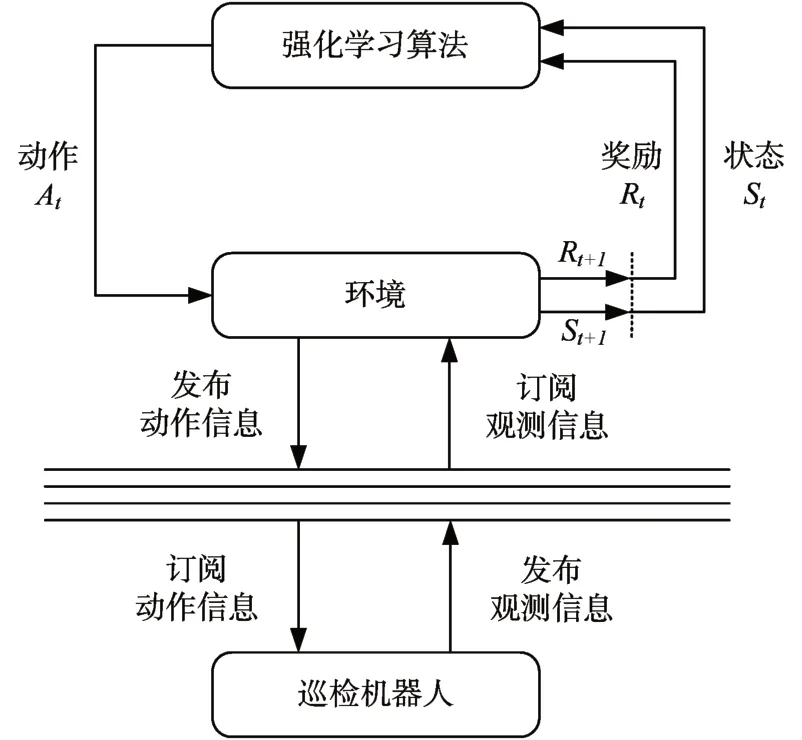
图8 强化学习与巡检机器人的交互
为降低Gym版本变化对本文仿真环境的影响,本文将Gym作为工具库,充分利用其所提供的功能和接口,但不依赖Gym 所提供的特定文件结构格式。具体地,通过以下三个核心方法来扩展本文环境接口。强化学习算法在训练过程中调用这些核心方法以实现与环境的交互,核心方法如下:
init():构造方法,用于初始化环境。包含对当前环境的参数设置,如状态空间表示、动作空间表示、订阅节点、订阅服务、启动仿真环境以及相关的ROS节点。
step():执行一个动作,动作执行后返回状态观测、即时奖励、是否重置环境的标志和用于调试的诊断信息。该方法中的action 参数为强化学习算法通过采样得到的动作。
reset():该方法用于将水下机器人重置到初始位置。
由于不同环境共享大量代码,本文在环境包内提供了一批工具API,以提高代码复用率,实现低耦合、模块化。这些工具API 可划分为以下四大类:
1)环境创建API:该类API 主要用于创建env,包含一系列与env创建有关的方法。
2)仿真器连接API:该类API 用于env 与仿真器的连接,实现训练过程中所必需的开始、暂停和重置模拟的功能。
3)env 父类API:该API 作为所有env 的通用父类。父类中包含了所有env 公有方法,如init()、step()、reset()等方法。
4)奖励函数API:该类API用于解析奖励函数,用户根据具体情况设计奖励函数并写入指定配置文件,奖励函数API读取解析奖励配置并生成奖励函数。
根据传感器、网箱数量等的不同,本文共自定义创建了以下五种网箱巡检环境,供强化学习算法训练、测试和对比。
1)UUVCircleCAM-v0
该环境中网箱底部带有一个环形轨道,机器人搭载两个摄像头,分别位于机器人侧面和底部,可获取轨道图像和网箱图像,如图9所示。

图9 UUVCircleCAM-v0环境
状态:摄像头所获取的实时轨道图像。
动作:动作类型或为速度,或为推力,或为转速,分别对应速度、推力、转速三种控制方式。动作类型通过参数设置。
2)UUVSonar-v0
该环境包含一个网箱,机器人搭载一个侧扫声呐,如图10所示。

图10 UUVSonar-v0环境
状态:状态为测扫声纳数据。
动作:动作类型或为速度,或为推力,或为转速,分别对应速度、推力、转速三种控制方式。动作类型通过参数设置。
3)UUVSonarIMU-v0
该环境中包含一个网箱,机器人搭载了一个测扫声呐和一个IMU。
状态:状态为测扫声纳数据和IMU测量数据。
动作:动作类型或为速度,或为推力,或为转速,分别对应速度、推力、转速三种控制方式。动作类型通过参数设置。
4)UUVDVLIMU-v0
该环境中包含一个网箱,机器人搭载了一个多普勒测速仪(Doppler Velocity Log,DVL)和一个IMU的机器人,如图11所示。

图11 UUVDVLIMU-v0环境
状态:状态为DVL和IMU测量数据。
动作:动作类型或为速度,或为推力,或为转速,分别对应速度、推力、转速三种控制方式。动作类型通过参数设置。
5)UUVSonarDVLIMUMulti-v0
该环境中包含一个多网箱组成的阵列,机器人搭载一个测扫声呐、一个IMU 和一个DVL,如图12所示。

图12 UUVSonarDVLIMUMulti-v0环境
状态:状态为声呐、DVL和IMU测量数据。
动作:动作类型或为速度,或为推力,或为转速,分别对应速度、推力、转速三种控制方式。动作类型通过参数设置。
6 系统测试
为验证本文所搭建系统的有效性,以自定义环境UUVCircleCAM-v0 为例,采用OpenAI 的默认强化学习算法PPO(Proximal Policy Optimization,PPO)进行测试。这里使用Stable Baselines3强化学习库实现。
6.1 训练
训练可通过命令行部署,运行以下命令:
roslaunch uuv_train start_train.launch tb_dir:=
可视化界面中标签栏三个选项依次分别是3D可视化模块、训练状态和观测信息可视化模块、评估数据可视化模块和系统设置模块。左栏中两个仪表盘是对于机器人线速度和角速度的可视化,中间栏为机器人摄像头的观测图像,右上栏是当前存在的ROS 话题列表。菜单栏上部显示了机器人的连接状态即与ROS Mater 的连接状态,下部为对训练的部署和监测。“数据/指标”如图13 所示。训练过程中截图如图14所示。

图13 训练数据可视化
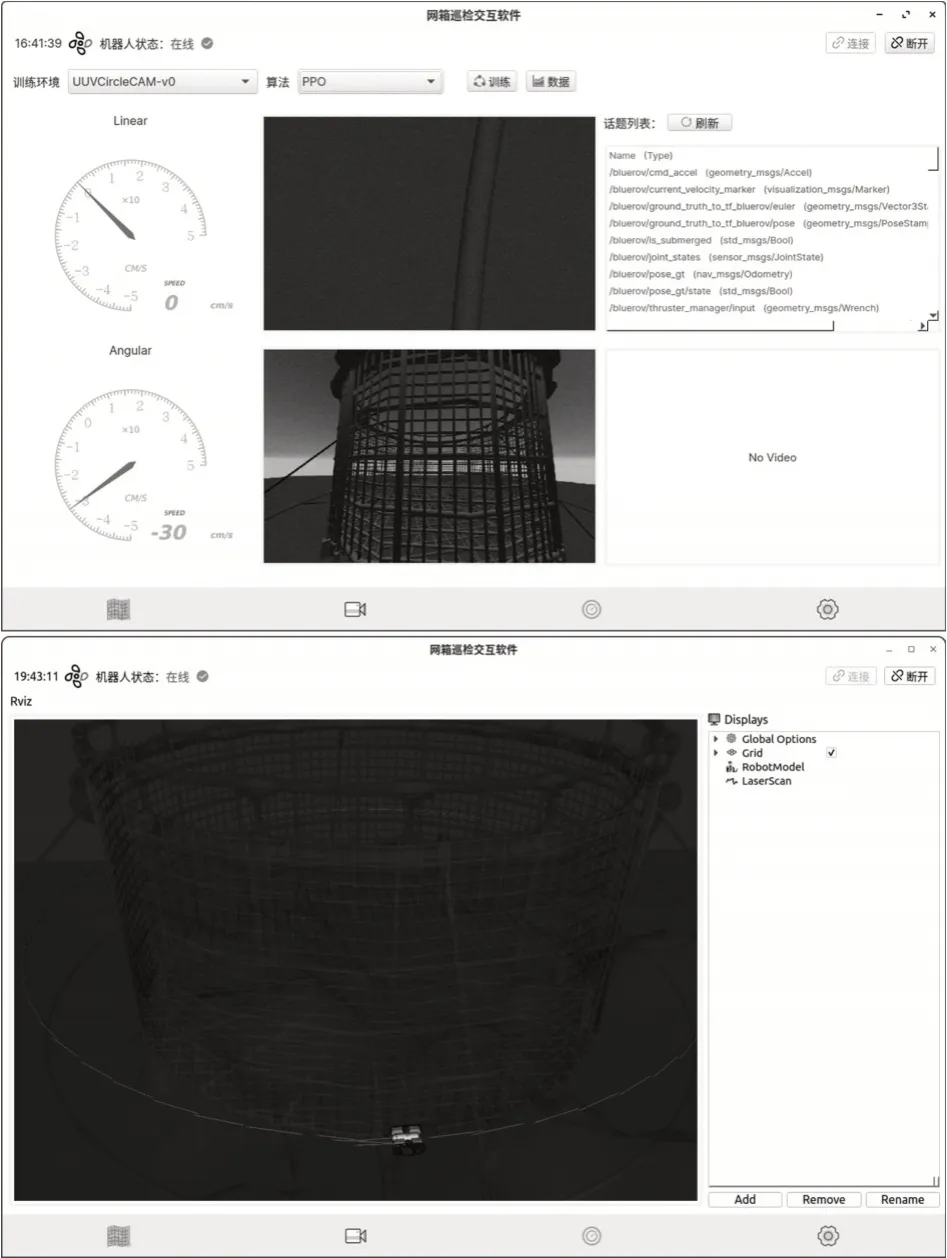
图14 训练过程可视化
6.2 策略评估
对于已训练完成的强化学习控制策略或其他控制策略可利用本系统进行测试、性能评估。图15为对训练好后的PPO算法的评估可视化视图。

图15 控制策略评估可视化
7 结语
本文基于UUV Simulator、ROS、OpenAI Gym 搭建了一个面向养殖网箱巡检任务的强化学习训练系统。该系统具有一定的可扩展性,用户可在该系统中自定义、扩展环境。该系统可用于强化学习训练与性能评估,也可用于控制算法测试。试验案例表明了本文系统的有效性、可用性和操作简便性。该系统对难以在真实水下环境进行试验的情况下,具有一定的现实意义,有助于提升网箱巡检控制算法的研发效率和安全性,进一步推动网箱养殖的智能化发展。未来工作将进一步考虑更多的海洋环境因素,如各种干扰,迭代完善该系统。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
舰船科学技术(2021年12期)2021-03-29
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
当代陕西(2018年12期)2018-08-04
电子制作(2017年24期)2017-02-02
渔业致富指南(2016年12期)2016-11-11
湖南农业(2016年3期)2016-06-05
学习月刊(2015年10期)2015-07-09
