
基于基音周期轨迹的连续汉语语音切分技术研究*
2023-05-12 02:26张二华
计算机与数字工程 2023年1期
高 桥 张二华
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
连续语音切分技术,就是从输入的语音信号流中,自动找出各种段落的始末点位置。连续语音切分技术不仅对连续语音识别有着至关重要的作用,也能够应用于语音分离、音频制作等领域。
语音边界的标注是语音识别的重要环节。一直以来,隐马尔科夫模型(HMM)在语音识别领域有着广泛的应用[1~2]。此类模型通过Viterbi解码或帧同步算法进行解码并得到音素边界[3],是语音识别由孤立词识别发展为连续语音识别的关键里程碑。但HMM 模型没有利用语音帧的上下文,忽略了语音信号的连续性,实际应用的性能较为有限。
随着深度学习的不断发展,端到端语音识别模型抛弃了传统的HMM 框架,旨在一步实现语音信号的输入与解码识别[4]。但端到端语音识别模型需要大量标注的音素进行训练,训练成本较高。如果能够实现准确可靠连续语音切分算法,就可以替代HMM 实现音素边界的界定,从而提升语音识别系统的性能,也可以应用于语音分离等领域。
传统的端点检测技术[5~6]可用于连续语音的初步切分,将语音数据划分为语音段和非语音段,然而端点检测难以实现浊音与非浊音的判别,切分精度达不到连续语音识别系统的需求。相关研究通过分析语音信号的语谱图[7]、共振峰结构[8]、频谱熵[9]、倒谱特征[10]等,实现连续语音切分,但大多存在稳定性差、调参困难等缺点,同时缺少噪声环境下的性能测试,难以满足语音识别系统的应用需求。
为了实现一种低成本、低耗时、高精度,同时具有一定噪声鲁棒性的连续语音切分算法,本文依据汉语的发声原理,以及语音信号的时域、频域、倒谱域特征,实现了连续汉语语音切分算法。听觉实验与数据对比表明,算法具有较好的准确性,以及较好的噪声鲁棒性,能够满足语音识别系统的应用需求。
2 语音信号的特征提取
2.1 语谱图
语音信号具有短时平稳性,任何语音信号的分析都要基于短时的基础,因此需要采用交叠分帧的方法[11],将语音信号划分为多个语音帧,使每一帧语音信号都具有短时平稳的特征。
分帧过程中常用的窗函数有矩形窗、Hanning窗和Hamming窗。矩形窗的频谱侧漏相对较大,因此常用后两种窗函数进行加窗分帧处理。本文使用窗函数为Hamming窗。
分帧后,可以通过短时傅里叶变换(STFT),得到每一帧语音信号的短时谱[12]。将第n 帧语音信号xn代入式(1),可以得到这一帧信号的短时谱Xn(ω)。
其中N 为帧长。通过短时傅里叶变换得到的短时谱,根据式(2)可以转化为振幅谱L。
其中,R为Xn(ω)的实部,I为Xn(ω)的虚部。将振幅谱转化为灰度,振幅越大,灰度值越小,颜色越深(灰度值为0 代表黑色);反之振幅越小,灰度值越大。按照时间顺序绘制每一帧的振幅谱,即可得到语谱图。
图1 为语音数据“那年正月新春”的语谱图(上)和对应的时域波形(下)。黑色线段代表人工标记的音节边界。
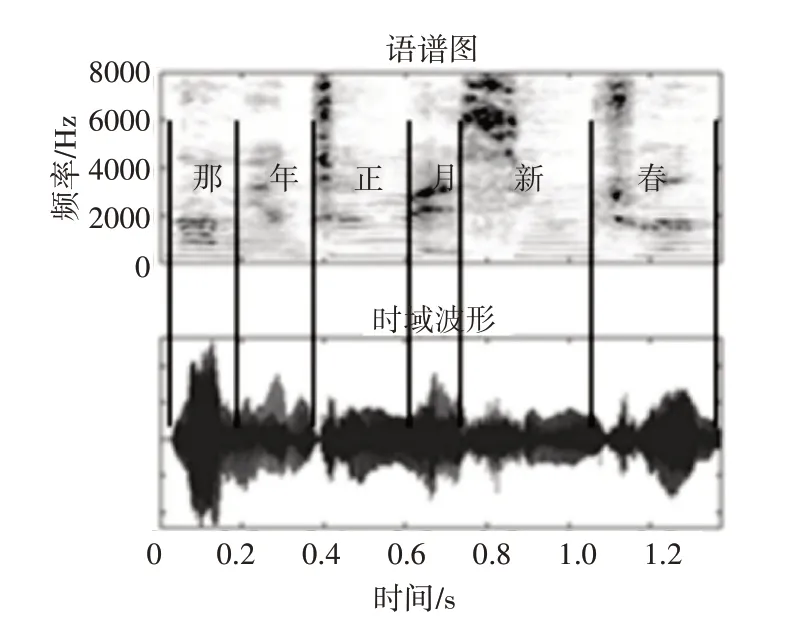
图1 “那年正月新春”语谱图(上)与时域波形(下)
语谱图能够直观展现语音信号的频域特征随时间的变化,不同音节的频域能量分布往往也有明显的区别。
2.2 倒谱与基音周期谱
倒谱的本质是频谱的频谱,能够反映频域中的变化特性,得到每一帧信号的基音周期与基音峰,是语音信号分析的重要特征[13]。将第n 帧语音信号的短时谱Xn(ω)代入式(3),可以得到这一帧信号的倒谱cn。
式中IFFT代表傅里叶逆变换。为了观测基音周期随时间的变化,将每一帧的倒谱幅度转化为灰度,按照时间顺序进行拼接,即可得到基音周期谱,记为T。
图2 为“那年正月新春”语音数据的基音周期谱图与对应的时域波形。

图2 “那年正月新春”基音周期谱图(上)与时域波形(下)
浊音段具有谐波结构特征,谐波分布于基音频率的整数倍附近,使浊音段的频谱具有一定的周期性,倒谱有明显的基音周期峰值。相反,清音段、静音段等非浊音段的倒谱没有基音峰。
因此,可以依据基音周期轨迹检测并切分浊音,在无噪环境下使用端点检测算法检测有声段,去除浊音段即可得到清音。噪声环境下,清音往往会失真,不需要划分为语音段。
3 多级连续语音切分算法
3.1 基音周期轨迹的提取与浊音检测
根据基音轨迹曲线的性质可知,只有浊音段能够形成清晰的连续性强的基音周期轨迹。因此,理论上可以通过提取语音信号的基音周期轨迹曲线,将对应的区间标记为浊音段,实现浊音检测。
为了证实上述猜想,计算基音周期谱图中每帧倒谱的灰度最值。因为灰度大小与倒谱幅度成反比,所以计算时取每帧倒谱的灰度最小值点,从而得到倒谱峰值点轨迹曲线。
“那年正月新春”的倒谱峰值点轨迹曲线如图3(上)所示,图3(下)为对应的基音周期谱图。

图3 “那年正月新春”倒谱峰值点轨迹曲线(上)与基音周期谱图(下)
显然,浊音段倒谱峰值点轨迹曲线相对平稳,并且与基音周期轨迹相符;非浊音段不存在基音周期轨迹,倒谱峰值点轨迹曲线的变化也没有规律。
同时不难发现,音节的起始段、截止段与过渡段,基音峰相对模糊,会引起基音周期轨迹的局部波动。为了尽可能提高切分音节的完整性,本文采用多尺度分析的思想,计算局部灰度最小值,降低基音周期谱图的分辨率,从而平滑基音周期轨迹曲线,提高曲线的连续性,进而提高检测得到的浊音的完整性。
为保证边界区域的准确性,同时保证边缘信息的获取,在进行多尺度分析时,需要按照神经网络的思想,将基音周期谱图的边缘进行填充(pad⁃ding),将填充区域赋值为255(灰度最大值),保证输入输出数据的维度一致[14]。
图4 为“那年正月新春”的多尺度分析基音周期谱图(上)与对应的时域波形(下),上方红色线段代表检测到的浊音段。
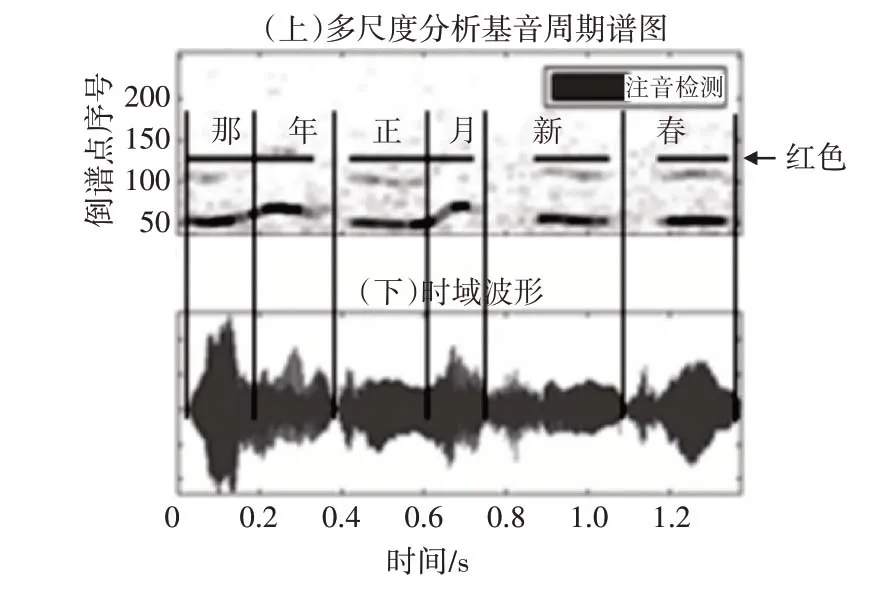
图4 “那年正月新春”多尺度分析基音周期谱图与浊音检测结果
显然,使用多尺度分析的方法能够明显提高基音周期轨迹的连通性,进而提升音节完整性。然而,相邻音节如果间隔较短,可能无法分开,例如“那年”、“正月”。因此,需要浊音检测的基础上,进行更加精确的音节切分。
3.2 基音周期轨迹的断点切分算法
为了尽可能放大浊音段与非浊音段的灰度差别,实现连续语音的单音节切分,可以按照sigmoid函数的思想,将灰度值进行二分类,并利用符号函数将分类结果两极化,从而实现基音周期谱的二值化,寻找相邻音节之间的断点。
为实现灰度的二分类,需要制定灰度阈值。将所有浊音段内每一帧的基音峰(倒谱峰值)对应的灰度进行正序排序(0为黑色),选取前rate%的灰度分类为黑,另外1-rate%的灰度分类为白,排序位于rate%的灰度即为灰度阈值G0。
将基音周期谱T 代入式(4),得到二值化基音周期谱B_T。
其中,bio为二值化函数,根据输入数值的正或负返回1 或0。B_T(i,j)=1 代表第i 帧第j 个倒谱点有明显的峰值,灰度偏黑;反之代表没有明显的峰值,灰度偏白。
将每个浊音段内分类结果为0 的点视为断点,从而将浊音段进行切分。为了保护音节的完整性,同时去除时长过短的浊音段,可以合并相邻间隔较短的浊音段。在合并结束后,根据人的语速特征[15],设定阈值去除时长小于阈值的浊音段。
如果断点切分算法能够寻找到连续基音周期轨迹的断点,就能够将多个音节组成的长浊音段切分为单个浊音。但在实际应用中,部分说话人的语速较快,部分音节之间几乎不存在停顿,断点切分算法难以应对这类语音数据。
3.3 基音周期轨迹的斜率切分算法
为了应对部分说话人语速较快的难点,需要依据更多特征判断音节的边界。汉语音节具有“声韵调”三要素,声调不同的音节,基音周期轨迹曲线的变化也不相同。如果能够捕捉基音周期轨迹的斜率变化,寻找斜率分布的临界点,就能够依据声调的特征实现浊音切分。
例如,“正月”包含的两个音节声调不同,反映出的基音周期轨迹斜率分布有着明显的差异。可以依据这个特征,以贪心算法的思想,选取左右两侧斜率分布差别最大的点作为临界点。如果临界点左右侧的语音段长度都大于一定时长,可以认为临界点左右两侧存在声调不同的两个音节。将这个临界点作为切分点,可以实现基音周期轨迹的斜率切分。
使用多级切分算法对“那年正月新春”进行切分,得到结果如图5 所示。图中红色线段代表浊音检测结果,绿色线段代表多级切分的结果。为了方便观察,将切分结果交错绘制。

图5 “那年正月新春”浊音检测与多级切分结果
从肉眼上能够直观地看出,“那年正月新春”被正确地切分为六个音节,并且与人工标记的区间相符。播放切分结果,也能够证实连续语音切分算法的准确性。
4 切分结果统计与分析
4.1 使用的数据
本文使用的语音数据来源于NJUST603实验室的语音库,内容为作家刘绍棠的《师恩难忘》短文,全篇共593 个汉字。语音采样共计包含男生210人,女生213 人。用于实验的噪声数据来源于NoiseX-92噪声库,采样频率均为16000Hz。
4.2 连续语音切分准确率
随机选取若干具有正常听觉认知能力的被试者,同时随机选取语音库中一位说话人的语音数据,使用连续语音切分算法切分前38 个音节。切分完成后,将切分结果随机打乱顺序,在安静环境下以正常音量播放,相邻音节之间间隔1s,让被试者复述听到的音节,与实际音节进行对比,统计准确率,结果如表1所示。
由表1 数据可知,被试者普遍能够正常识别并复述出正确的音节,证明通过听觉认知实验,能够认为连续语音切分算法得到了正确的切分结果。同时通过数据对比可以发现,多数女性说话人的声音更容易辨识。
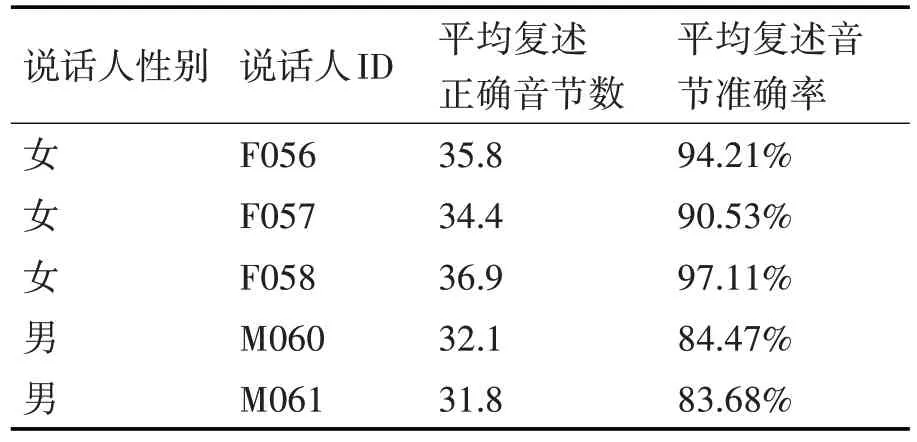
表1 连续语音切分准确率统计结果
4.3 噪声鲁棒性检验
绝大多数语音识别系统都要应用于噪声环境中。因此,需要在噪声环境下进行连续语音切分算法的性能测试,分析不同信噪比的噪声对算法性能的影响。
由于低信噪比的噪声会破坏语音段的共振峰结构,从而导致基音周期轨迹被破坏,使用连续语音切分算法可能会得到不完整的音节和原本不存在的虚假音节。同时,部分音节信息可能会丢失。
选取4.2 节使用的一位说话人的语音段(共38音节),分别加入一定信噪比的白噪声信号,进行连续语音切分,依据听感与数据对比,将切分音节分为四类,分类结果如表2所示。
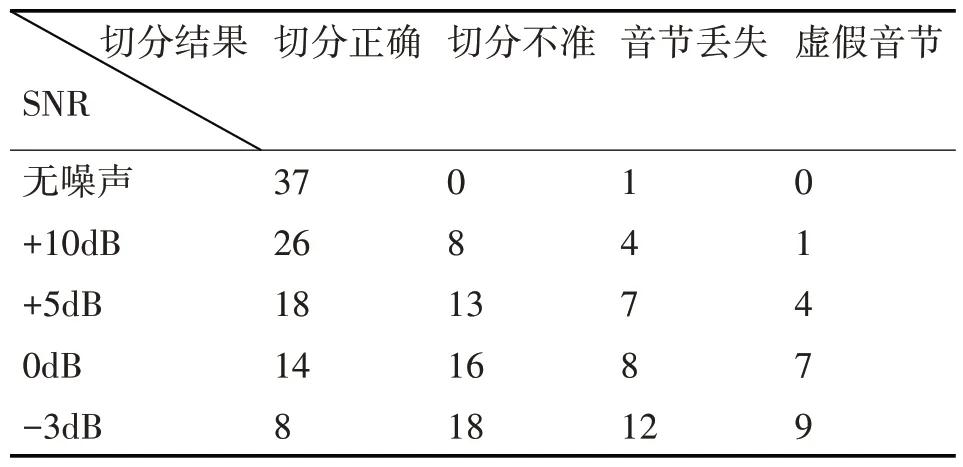
表2 不同信噪比的连续语音信号的切分结果
通过含噪语音切分实验,证实本文提出的连续语音切分算法具有较好的噪声鲁棒性。低信噪比的噪声会破坏基音周期轨迹曲线,因此会对算法性能产生较大影响。高信噪比环境下,算法性能较为稳定,实际应用中产生的偏差可以通过语言模型等方式进行修正。
5 结语
本文提出的连续语音切分方法综合利用了语音信号的时域、频域和倒谱域特征,以及汉语发声原理,通过检测基音周期轨迹区分浊音段与非浊音段,依据基音周期轨迹的断点与斜率进行多级切分。经过大量被试者的测试,证实了算法具有稳定且较好的性能。不仅如此,加噪实验表明算法具有较好的噪声鲁棒性。
连续语音切分算法尚有改进空间。浊音检测与切分算法主要依据基音周期轨迹的特征,噪声环境下一旦基音周期轨迹被破坏,算法的性能也会受到影响。同时,需要依据不同的应用场景,进行一系列的参数调整。例如应用于脱口秀、RAP等快速讲话的字幕生成,需要调整参数,在尽量不破坏完整音节的前提下尽可能提高切分性能。
猜你喜欢
小小说月刊(2019年18期)2019-09-24
成都信息工程大学学报(2019年1期)2019-05-20
青年与社会(2019年4期)2019-03-29
小学生作文(中高年级适用)(2018年4期)2018-05-14
电子技术与软件工程(2017年24期)2018-01-17
——以NHK新闻为中心
小说月刊(2017年14期)2017-12-06
数据采集与处理(2014年2期)2014-07-25
湖南工业大学学报(社会科学版)(2011年6期)2011-12-28
中国火炬(2011年2期)2011-07-25
电子设计工程(2010年1期)2010-09-27
