
国内基于社会化标签的信息推荐研究进展:架构与应用*
2023-05-12 02:25孙雨生
计算机与数字工程 2023年1期
孙雨生 徐 鑫
(1.湖北工业大学经济与管理学院 武汉 430068)(2.湖北工业大学职业技术师范学院 武汉 430068)(3.湖北工业大学湖北农村社会管理创新研究中心 武汉 430068)
1 引言
伴随Web2.0、Web3.0 时代到来、社会化媒体发展[1~3],用户不再满足机器挖掘信息,而更多通过参与网络信息构建(产生、组织、分享、发布[4])彰显个性,实现用户共建、共治、共享的开放网络平台,致使用户生成内容、社会化标注资源日益增多[5],信息过载、知识迷航、信息品质低下、搜索负荷过重等问题日益严重。在此形势下,如何优化传统信息推荐机制以更好基于用户信息需求、兴趣、行为、情境模式[2~3,5~7]等主动推荐符合其需求的信息成为亟待解决问题。作为维护成本低、自带语义性[8]的用户生成元数据,社会化标签有组织、共享、检索和发现作用[9],可从语义角度挖掘用户信息[5],从用户角度表达其兴趣及认知偏好、揭示信息资源特征[10]及与用户间关系[1,3~4,6~8,11~12],可优化用户兴趣、信息资源建模[8]从而提高推荐精度、奇异发现能力及用户体验,因此研究基于社会化标签的信息推荐问题有重要意义。
本文先以知网、万方的学位论文库、期刊论文库及维普的期刊论文库为信息源,以“社会化标签”和“推荐”为关键词组合在题名中检索(截至2023年1月27日),共得期刊论文38篇、硕博论文25篇;再用同样方法排列组合标签类关键词(社会化标注、社会标注、社会标签、大众标签、大众标注)与推荐类关键词(推荐、推送)进行相关主题检索以获取相关文献,经剔重整合共得期刊论文63 篇、硕博论文46 篇。然后详读全部109 篇文献归纳基于社会化标签的信息推荐内涵、研究框架,分析该主题的架构体系、应用及评价研究进展并根据提及频次、内容质量详细标注,本着最大限度揭示该主题研究进展重要文献、覆盖全部内容、优中选优原则,剔除标注次数少、与其他标注文献内容重复文献后选出44 篇参考文献,最后从架构体系、应用与实践、效果评价三方面阐述国内基于社会化标签的信息推荐研究进展。
2 基于社会化标签的信息推荐简介
2.1 定义与内涵
基于社会化标签的信息推荐挖掘网络信息资源内容、用户标注历史、显隐式关系[13]来精准描述、组织信息资源、用户特征[12]及两者关系[7,10],并基于标签(反映用户对信息资源内容理解、兴趣[1,3~4,6~8,11~12,14~15])频率、时间、共现、权重[16]等构建用户兴趣模型[17](多为加权标签向量)以量化、预测用户兴趣[17],用基于聚类、矩阵、图结构、数据挖掘、本体等技术[1,5,12,16]个性化推荐标签[11,14]、资源[11,17]、相似用户[11],最终实现信息、产品和服务的时空、方式及内容个性化[7,10],与传统信息推荐对比见表1。此外,孙智超[18]认为基于受控词表的标签推荐用受控词表的分类关联标签、用户、资源(用户选择偏好类并据此构建标签与主题词映射关系聚类标签集,以形成该类下的标签推荐列表)。

表1 基于社会化标签的信息推荐与传统信息推荐对比

推荐机制信息资源管理基于协同过滤基于内容混合推荐数据采集数据挖掘数据存储用标签信息发现相似用户和资源并由协同过滤得到的标签对目标资源进行推荐;解决兴趣模型单一问题,缩小评分矩阵规模,提高计算效率,挖掘用户潜在兴趣以针对性推荐根据用户标签评价资源相似度,对比用户兴趣和资源相似度进行推荐将各算法输出转为表明用户、资源和标签标注可能性的四元组形式并以评分立方形式组织和存储,通过统一框架同时推荐资源、标签和用户显性采集,隐性挖掘,显隐式混合基于分类、聚类、关联规则、时间序列分析及Web挖掘在线存储,数据仓库分析用户历史评分,基于用户和资源相似性个性化推荐;常评分矩阵稀疏,冷启动,易受攻击,用户兴趣模型单一分析用户以往感兴趣资源与待推荐资源相似性进而推荐;常挖掘信息不全、推荐内容有限综合各推荐算法优势进行推荐,分整体式、并行式、流水线式三种基于网络爬虫、显式采集基于聚类、分类、贝叶斯网络数据库,本体库项目 基于社会化标签的信息推荐 传统信息推荐
2.2 研究框架
纵观现有文献,国内相关研究成果最早是田莹颖2010 年发表的《基于社会化标签系统的个性化信息推荐探讨》,目前国内研究整体处起步阶段[5,16]但发展迅速[7],学术研究集中于架构体系[1,5,8,10~12,19]、用户兴趣建模[8,10,12]、推荐机制[4~5,8,10,12,15,19]、效果评价[4]等方面[2~3,7,16],应用研究集中于图书[4~5]及书签[16]、电 影[4~5,12,16,19]、图 片[12,16]、音乐[5]、链 接[4]、网页、E-mail、新闻等领域[1,7]。基于社会化标签的信息推荐研究框架见图1。
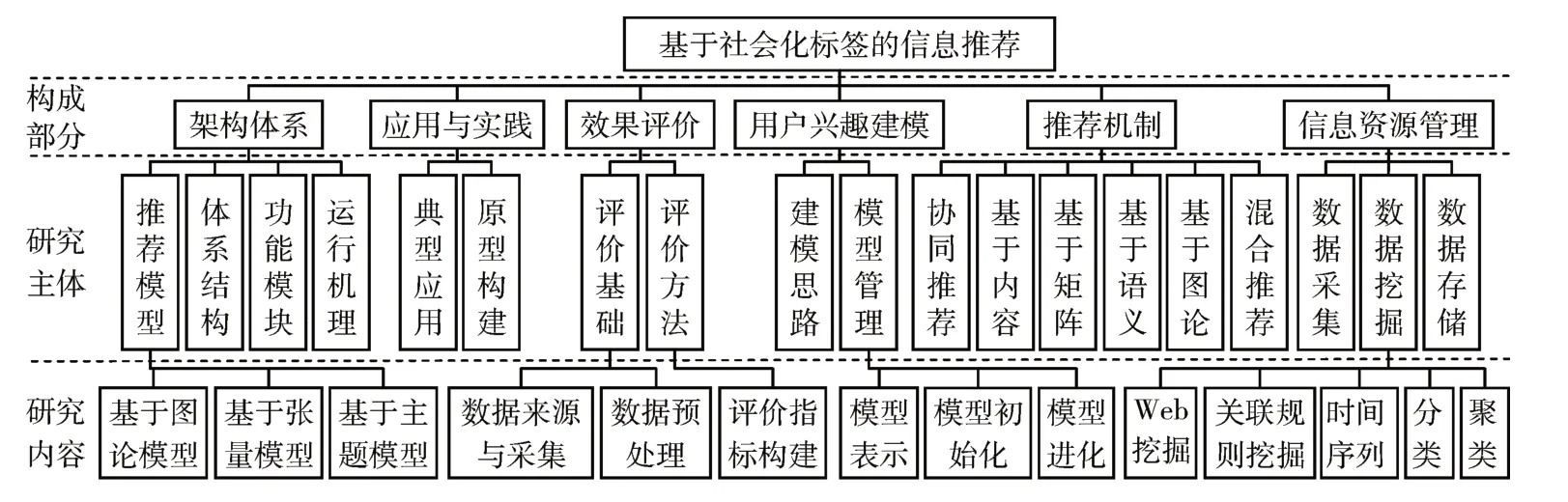
图1 基于社会化标签的信息推荐研究框架
3 基于社会化标签的信息推荐架构体系
国内基于社会化标签的信息推荐遵循系统化、体系化原则并以推荐模型为驱动、体系结构为支撑、功能模块为内生动力、运行机理为主线从整体出发构建架构体系。
3.1 推荐模型
按社会化标签系统中用户、资源、标签组织方式分为基于图论、基于张量和基于主题三类。基于图论和基于张量模型描述用户、资源和标签间关系很大程度解决推荐系统冷启动和数据稀疏问题,基于主题模型从语义角度深层次挖掘标签涵义使推荐内容更符合用户需求,三者各有优缺点。
3.1.1 基于图论模型
从复杂网络角度用二维向量表示用户、资源、标签两两间关系并从整体出发基于超图揭示标签系统中网络结构以提高推荐效率[5]。武慧娟[5]根据系统动力学理论提出基于社会化标签的信息推荐系统构成要素涉及核心要素(用户)、动力要素(知识共享、用户信任机制)、基础要素(资源、标签)、自复制要素(超循环、耗散机制)、传输要素(用户关系网络)、转换要素(发现、推荐机制);提出静态推荐模型以核心要素和基础要素为主体,在动力要素作用下随知识共享和用户信任机制提高标注资源效率,通过自复制要素形成用户关系网络,挖掘用户关系网络将所发现群内和群际个性化信息推荐给用户实现信息转换;基于推荐过程构建动态模型,分为一层动态模型(以用户、资源、标签为核心构建标注系统,用社会化网络分析理论动态聚合知识形成用户关系网络,通过知识发现动态产生个性化信息进行群内、群际推荐)和二层动态模型(包括基于社会网络分析动态聚合知识、发现个性化信息、个性化推荐模块)。蕲延安[9]采用隐含话题模型提取标签空间隐含话题,基于标签共现关系、话题分布构建话题标签超图进而推荐;陈平华[20]结合用户LBS、用户标签和社会关系网络构建融合标签网络、社会关系网络的双层网络推荐模型;安志伟[14]针对传统三部图分解推荐算法缺陷提出基于张量模型的新三部图分解算法,用低阶张量分解高阶稀疏数据进而推荐;史云飞[21]基于推荐系统中对象及对象间关系构建图结构模型进而推荐;周欢[22]根据二部图关联网络生成用户、电影、标签完全三部图,基于此构建图神经网络获取标签可重叠社区(某些标签隶属多个标签社区)进而提高推荐效果。
3.1.2 基于张量模型
基于加权标签向量,引入张量构建统一框架模型描述用户、资源和标签关系,生成3 阶张量并基于Tucker(塔克)、CP(平行因子)、HOSVD(高阶奇异值)等[5]算法降维分解,常用贝叶斯算法最优排序标签、资源并推荐[5]。孙玲芳[23]基于K-Means 聚类相似标签特征,用高阶奇异值分解构建多维张量模型,以部分解决稀疏性问题进而个性化推荐资源;张浩[24]加权系统中元素权值、用户评分等级并作为张量元素构建新加权张量模型进而推荐;丛维强[17]构建基于数据仓库多维数据集技术的社会化标签推荐模型以充分利用用户、资源和标签间关系,构建基于加权元组潜在语义分析的三维张量模型(引入社会网络分析法量化加权相关元组构建加权三维张量结构模型,并通过元组潜在语义分析得到体现用户兴趣度的加权元组集)并据此推荐;王晓芳[25]构建基于四元语义分析的Flickr 组推荐模型,采用四阶张量分解算法挖掘用户、标签、图片和资源群组间潜在语义关系为用户推荐图片组。
3.1.3 基于主题模型
从标签系统语义出发,深度挖掘标签所含语义信息以提高推荐针对性(在标签与用户或资源关系中引入主题因素降高维数据到低维主题以推荐资源、标签[26]),常引入概率潜在语义分析模型(PLSA)统一标签系统中用户-资源和资源-标签共现以提高推荐效率[5],其发展历经向量空间模型、潜在语义分析模型(LSA)、基于概率潜在语义分析、潜在狄利克雷分配模型(LDA)等阶段[4,27]。常引入LDA 主题模型构建社会化标签推荐系统,张彬彬[28]构建基于主题模型的社会化标签推荐模型LTR,综合考虑用户、标签、资源语义信息,从话题语义层挖掘内在联系,推导模型联合概率和转移概率分布,最后根据模型输出概率参数推荐标签;王晓耘[29]融合社会关系构建用户加权LDA 标签主题模型,涉及用户社会关系建模(链接互联的用户加入“用户-标签”二元模型)、“用户-标签”关系矩阵构建(基于用户标注行为分解)、LDA 建模分析;窦燕[30]基于LDA 主题模型改进基于内容、相似资源和相似用户的标签推荐,构建标签混合推荐模型;李培植[31]引入LDA 主题模型和信任机制构建多源混合标签推荐模型挖掘资源潜在语义信息提高推荐结果全面准确性。
此外,张引[32]构建基于异构对象融合的标签推荐模型(扩展LDA 主题模型构建用户、标签、资源间关系及其与额外类型对象间关系生成的模型,用主题关联性(概率)揭示异构对象间关系),建模标签、用户及资源间关系并融入用户对资源兴趣、标签使用习惯等自主意识以构建面向用户自主意识的标签推荐模型;丁玲[33]改进LDA 模型挖掘潜在标签主题,结合“先优化后服务”思想提出集成主题优化的协同推荐方法:线下基于标签主题优化对象构建用户多兴趣主题推荐模型,线上基于目标用户兴趣主题和用户兴趣主题模型匹配计算并生成推荐列表;孙甲申[34]针对社会化标签自由性特点,引入标签粒度和噪声构建新主题模型,为未标注文档推荐标签;丛维强[17]构建基于加权元组潜在语义分析的标签推荐模型,使数据仓库更好体现用户、资源和标签间语义关系。
3.2 体系结构
基于社会化标签的信息推荐系统常分功能应用层(支持用户注册/登录,浏览、聚合、标注、发布资源)、数据分析层(支持资源及其标签发现与分析,相同资源、标签归纳与推荐)、资源管理层(添加资源标签及其他信息)[1,11];基于社会化标签的信息推荐框架遵循客观、全面、系统、多层次原则确定标签、资源、用户间关系[5]。李欣[19]提出B/S模式基于社会化标签的推荐引擎系统结构(用MVC 模式降低耦合度),改进推荐体系结构为应用层、推荐层、网络层和数据层;白雪[1]整合社会化标注网站中基于标签的资源管理与推荐机制、E-learning 平台构建基于标签的教育资源(含学习伙伴)管理与推荐体系,分为功能应用、可视化表示、数据分析、资源管理四层。
此外,易明[15]提出社会化标签系统中基于混合策略的个性化知识推荐系统体系结构;苏巧[7]提出基于标签的分布式、可扩展、可插拔混合(资源、标签、用户)个性化推荐框架,统一数据适配器分别为基于图论、张量和主题推荐算法输入数据,新增算法只需分布式实现,混合推荐算法提供常用修改器将算法输出整入评分立方,索引构建器只需在首次推荐或评分立方更新时(推荐算法周期运行、算法权重更新、推荐算法增删)访问评分立方并构建索引,后续推荐直接运行索引,分在线(数据适配、推荐算法并行计算、修改器插值)、离线部分(索引构建、推荐生成);姚陶钧[35]提出基于社会化标签、概率化矩阵分解推荐算法(Tag-PMF)的推荐系统框架,线上(数据采集和预处理)、线下(结果推荐)混合,分析老年人对项目(资讯、视频等)历史评分,结合项目标签,考虑项目隐含因子和标签相似项目预测用户需求并推荐。
3.3 功能模块
基于社会化标签的信息推荐系统常包含人机交互(用户与标签、项目交互,推荐结果显示)、业务(含用户兴趣建模、推荐(分协调控制(用户操作分析,按情况触发功能事件,用户自选推荐算法)、推荐算法模块))和系统数据库(含用户标签数据库、用户兴趣模型库、项目评分库)三模块[12]。
此外,刘珊珊[2]提出音乐推荐系统包含用户接口(支持分类导航、检索、列表推荐、歌曲关联可视化、评分等)、推荐算法和资源模块(含歌曲数据库、特征数据库、用户信息及其他Web 资源);赵艳[8]提出基于社会化标签的P2P 个性化推荐系统包含普通节点(涉及用户兴趣管理、个性化推荐、本地资源管理、资源标注模块)和社区管理节点(增加社区节点信息管理模块);姚陶钧[35]提出基于Tag-PMF 的推荐系统包含线上模块(包含人机交互、数据预处理和推荐增量更新模块)、线下模块(包含结果推荐、算法训练及测试、数据存储、相似项目集采集模块);王战平[36]提出基于社会化标签挖掘的微博内容个性化推荐包含微博用户标签扩充模块(以微博内容为数据源,基于TextRank 和Word2vec 扩充用户标签)、标签语义计算模块(将标签映射到HowNet知识库计算语义相关性以构建标签语义相似度矩阵,进而提高用户标签相似度计算准确性)、社会化标签挖掘模块(挖掘社会化标签获取深层次用户偏好,为构建用户兴趣偏好表示模型提供语义知识)、微博内容个性化推荐模块(根据用户兴趣偏好表示模型构造排序函数以个性化推荐微博内容);贾伟[37]融合用户智能标签与社会化标签设计图书推荐系统模型,包含数据采集模块(获取图书标签书和用户数据)、数据预处理模块(去噪并基于标签主题建模深层次挖掘语义信息)、推荐模块。
3.4 运行机理
基于社会化标签的信息推荐通过描述资源特征构建资源模型,采集用户标注标签及反馈获取其特征构建并进化用户兴趣模型,用推荐技术匹配用户兴趣模型、资源特征模型以按相似度排序后推荐[8,10]。张灵菡[38]提出基于用户兴趣模型的个性化推荐流程为近邻用户发现、资源集确定与特征表示、个性化推荐生成;田莹颖[10]提出基于社会化标签的个性化推荐流程为采集并向量表示用户兴趣得出相似用户集,形成并向量表示内部资源集,比较用户兴趣、资源向量以按相似度进行Top-N 推荐;熊回香[39]提出基于社会化标注系统的个性化推荐流程为数据采集及预处理、资源-标签-用户聚类、推荐模型构建和个性化推荐;李烨朋[16]提出通过K-Means聚类在离线状态下初步聚类数据,再对用户-标签-项目数据组构建空间向量模型,经高阶奇异值分解运算向量并个性化推荐。
此外,姚谊[40]提出基于社会化标签音乐推荐流程为采集用户数据集,通过用户日志和显式反馈分析其听歌习惯,按用户兴趣模型选择、排名歌曲并推荐靠前歌曲;刘珊珊[2]提出结合音频特征、社会标签的音乐推荐流程为音乐特征采集处理、特征降维及推荐结果可视化;李海英[27]提出基于标签主题特征扩展的图书馆书目推荐流程:数据采集及预处理、图书标签主题建模、书目特征选择与扩展、书目相似度计算、推荐结果生成;赵艳[8]提出P2P 环境下基于社会化标签的个性化推荐流程为本地节点计算、用户标签偏好向量更新并提交至社区节点以共享、发现社区内用户近邻并获取其所收藏资源,过滤本地用户已标注资源并计算剩余资源与用户兴趣相似度、排序后为其进行Top-N 推荐;陈俊鹏[41]经数据采集、数据预处理、联合加权矩阵分解(将社会化标签系统与图书馆馆藏资源语义融合)为非图书馆用户推荐馆藏资源以提升其利用率;潘淑如[42]将本体引入社会化标签系统构建基于本体的个性化信息推荐模型,首先基于本体描述标签语义,然后基于标签构建用户兴趣本体(基于领域本体的用户模型),最后基于本体提供的语义和个性化标签集推荐符合用户兴趣的信息。
4 基于社会化标签的信息推荐应用与实践
4.1 典型应用
基于社会化标签的信息推荐应用领域伴随推荐技术成熟逐步拓展,涉及图书[4~5]及书签[16]、电影[4~5,12,17,19]、图片[12,16]、音乐[5]、网页、链接[4]、E-mail、新闻等[1,7],典型应用见表2。

表2 基于社会化标签的信息推荐应用
4.2 原型构建
白雪[1]基于社会化网络、E-learning 平台实现基于标签、任务学习的跨平台海量资源管理,学习资源及学习伙伴推荐,知识点可视化导航;孙智超[18]以《中国分类主题词表》医学类主题词表、豆丁网资源、标签为数据源,实现基于受控词表的医学资源社会化标签推荐系统,结合标签与资源、用户与类目构建标签与受控词表映射关系并聚类标签扩展标签集,以优化标签推荐和层次浏览机制;姚陶钧[35]构建基于智能终端、云端技术、中西医健康体征采集设备、动态监控,由健康服务总线、健康数据中心和健康服务库构成的老人健康个性化服务平台,整合相关产业数据和服务、管理老年人相关服务和数据以关联老人与政府、企业、社区、机构、亲人和社会工作者,提供资讯阅读(基于用户兴趣和反馈定制或推荐栏目、频道、展示风格等)、视频资源、健康应用(基于用户健康状况按疾病类型展示药品名称、成分、适应症、用量、用药指南、注意事项等,基于用户评价、位置等推荐药店、医院)、生活服务(基于用户需求、反馈个性化推荐、分类展示健康活动)等个性化定制、推荐服务并接受用户评分、标注反馈等;刘珊珊[2]构建含用户接口、推荐算法和资源模块的音乐推荐系统;郭雪梅[43]依托数字图书馆信息资源构建面向社会公众的医学健康知识服务平台,基于标签使用频率描述用户偏好,结合标签使用时间因素动态更新用户偏好,为其提供健康知识推荐服务。
5 基于社会化标签的信息推荐效果评价
5.1 评价基础
5.1.1 数据来源与采集
现有研究常根据评测问题在社会化标签系统中选择数据集验证推荐算法效果、系统性能,常用网页解析工具和网站自带API采集Delicious[4,6,11~12,16]、Bibsonomy[12]、CiteULike[38]、Amazon[3]、MovieLens[3~4,12]、Netflix[3]、Flickr[4,7]、Last.fm[40]及博客标签数据集等。
5.1.2 数据预处理
为满足应用对数据准确性、完整性、一致性、时效性、可信性及可解释性要求,常只考虑数据集中用户、标签、资源间关系(忽略时间标签)并预处理(涉及数据清洗、集成、变换、规约和离散化[28],删除异常标签及乱码)后存入数据库:赵艳[8]、田莹颖[9]、孔祥迎[4]剔除无意义标签、合并相似标签、删除标签数较少的资源及用户。此外,李岩[3]从每个数据集(涉及用户、标签、资源数据)中取10%数据,用十层验证法将用户集分为10 份并依次单独作为测试集,剩余数据作为训练集,随机去除测试集中用户标记过的一项资源后进行评价;张彬彬[28]过滤词项剔除停用词,再用TF-IDF法删减数据集,筛选排名前8000 词语作为后续实验词库并存储,最后据此提取文献特征以便评价;窦燕[30]用中科院分词系统NLPIR 对图书内容简介及不规范标签进行分词,并基于停用词表删除特殊符号和无用词。
5.2 评价方法
5.2.1 评价指标构建
推荐算法评价常用指标有准确度、多样性和新奇性[4,7],内涵详见表3;推荐系统评价标准主要分统计精度(常用平均绝对偏差MAE,计算目标用户预测和实际评分间偏差,值越小越好)和决策支持精度(常用受试者操作特性曲线(ROC)分析法)两类[3]。李岩[3]、孔祥迎[4]、李烁朋[16]、李欣[19]、李海英[27]等用MAE、推荐命中率(HR,推荐项目中命中项目所占比例)和命中排序(ARHR,评估命中项目在推荐排序集中位置)[12]、平均均方误差(RMSE)[4,16,35]等指标评价预测评分准确度;同时部分学者改良MAE 法提出平均绝对误差法(NMAE,规范化MAE 以消除评分范围影响)、平均绝对用户误差法(MAUE,消除MAE评估时用户差异性)。

表3 推荐算法评价指标
此外,丛维强[17]用支持度(标签被多少资源使用过)、概率(同时被特定标签和推荐标签标注过的概率)、调整概率(即置信度,综合标签支持度及在标签数据集中出现次数算出,揭示标签在标签集中获得推荐的概率)等指标评价所推荐标签质量;刘志丽[44]用平均准确率、多级制相关性评价法(计算推荐结果与待标注文档相关度)等多维评价标签推荐效果;史云飞[21]用相似度和网络密度指标评价标签、资源及用户推荐有效性;赵艳[8]用推荐准确率评价资源推荐准确度(对目标用户的推荐正确数与推荐总数之比);孔祥迎[4]、姚谊[40]用覆盖率表示算法为所服务用户推荐商品占所有商品比例(越低推荐给用户商品数越少,反之亦然)。
5.2.2 评价过程
分为统计精度度量法和决策支持精度度量法两类[3],常将数据集分为训练集(用于用户兴趣建模)、测试集(推荐精确度和效率计算、支持推荐与评价),推荐系统按给定的用户-资源对返回推荐标签集并在候选集中评价[13],对比改进后和现有推荐方法以衡量推荐系统性能、算法效率。此外,苏巧[7]从Flicker选择测试数据集进行多维评价:以系统为中心评价推荐算法预测准确率,以网络为中心评价项目或用户网络拓扑结构相似性,以用户为中心评价推荐用户接受度和可用性;王海雷[6]分析正规化参数、学习率、用户-资源矩阵、资源-标签矩阵因子等变量敏感度以评价协同矩阵分解有效性;王晓耘[29]设计用户兴趣模型及模型更新方法验证、个性化推荐算法验证(与传统标签推荐算法对比取算术平均值为最终评价结果)两部分实验评价推荐有效性。
6 结语
综上,本文阐述了基于社会化标签的信息推荐内涵及研究框架,并从架构体系、应用与实践、效果评价三方面阐述了国内基于社会化标签的信息推荐研究进展:架构体系包括推荐模型、体系结构、功能模块及运行机理;应用集中于图书及书签、电影、图片、音乐、网页等领域,实践集中于教育、医疗、健康等领域;效果评价研究评价基础、方法,前者涉及数据来源及采集、数据预处理,后者包括评价指标构建和评价过程。
下一步,笔者将从用户兴趣建模、推荐机制、信息资源管理三方面分析国内基于社会化标签的信息推荐核心内容研究进展,供相关研究参考。
猜你喜欢
少先队活动(2021年5期)2021-07-22
开放教育研究(2020年2期)2020-03-31
中国非营利评论(2019年1期)2019-06-18
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
现代语文(2016年21期)2016-05-25
公民与法治(2016年10期)2016-05-17
体育科技(2016年2期)2016-02-28
学习月刊(2015年7期)2015-07-09
计算机工程(2015年8期)2015-07-03
