
基于声呐图像的类别增量学习方法研究
2023-05-12 12:40陈鑫哲梁红徐微雨
西北工业大学学报 2023年2期
陈鑫哲, 梁红, 徐微雨
(西北工业大学 航海学院, 陕西 西安 710072)
随着水下勘探技术的不断发展与水下环境的逐渐开发,更多未经训练过的水下目标信息会被获取,水下目标识别系统的需求也随之增加。目前,大部分用于水下目标声呐图像的分类识别网络采用的都是一次性输入所有类别样本的训练方法,这样训练好的分类识别网络只能对学习过的类别样本进行分类识别,当有新的类别样本需要学习时,就只能将目前的所有类别样本重新进行训练,需要耗费大量的时间与算力。
类别增量学习(class-incremental learning,C-IL)[1]要求分类识别网络能不断地从新获取的任务类别样本中学习到新知识,同时保留历史学习过的任务目标类别知识。但是,类别增量学习网络在学习了新任务类别样本后,通常会对历史学习过的任务类别样本出现灾难性遗忘问题[2],导致所有任务目标的分类识别准确率严重降低。
为了缓解灾难性遗忘问题,研究人员提出了各种增量学习方法,依据方法原理的不同,可以将目前的增量学习方法分为以下2类:基于正则化(regularization)和基于重放(replay)。基于正则化的代表方法有:Li等[3]提出的不忘学习(learning without forgetting,LWF),DeepMind团队提出的弹性权重巩固(elastic weight consolidation,EWC)[4]。基于重放的代表方法是Shin等[5]提出的生成重放(generated replay,GR),基于生成重放的增量学习方法对类别增量学习总体表现更好,它对于光学图像取得了较高的类别增量识别准确率,并且在一定程度上缓解了灾难性遗忘问题。
相比数以百万计的高质量光学图像数据,由于获取难度高、水下环境噪声干扰大和观测角度有限,声呐图像存在样本数少、分辨率低和边缘不连续的问题[6],直接将光学领域的识别方法应用于声呐图像,通常表现较差[7]。因此,GR增量网络对声呐图像类别增量学习的可行性还待进一步研究。
本文研究GR增量网络对于声呐图像类别增量学习的可行性,提出一种适用于声呐图像类别增量学习的改进GR增量网络,缓解灾难性遗忘问题,提高声呐图像所有任务目标类别的平均识别准确率。
1 数据集的建立
本文建立的数据集包含前视声呐和侧扫声呐等多种声呐成像设备得到的声呐图像,依据图像的目标类别将其整理划分为6类,分别是飞机、沉船、瓶子、轮胎、石块和水下机器人。采用双线性插值法对声呐图像进行尺寸统一,规范后的图像尺寸为(112,112),每个目标类别的数据按照4∶1的比例随机分为训练集和测试集,数据集分布如表1所示。
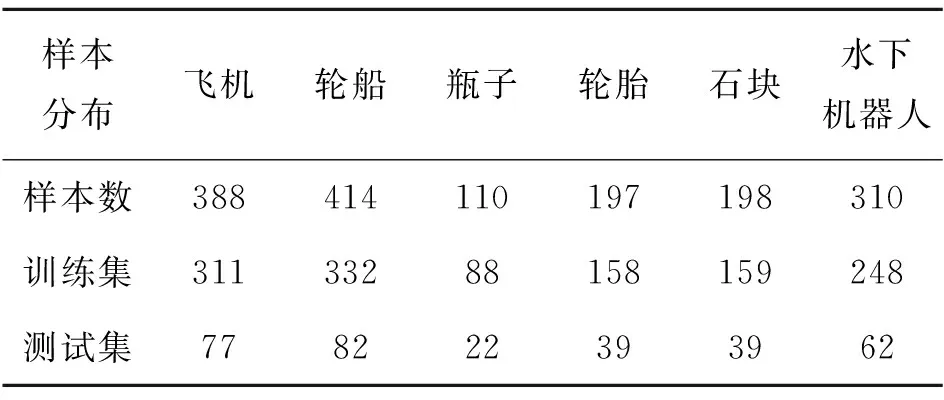
表1 数据集分布
本文将数据集划分为如图1所示的3个任务目标,依次输入到类别增量学习网络中,作为新的类别知识对网络进行训练。

图1 任务目标
2 GR增量网络
2.1 GR增量网络结构
GR增量网络是由重构模型和识别网络组成的合作双模型架构。利用这种模型架构,网络可使用重构的历史数据和真实当前数据的集合进行联合训练,缓解灾难性遗忘问题,GR增量网络学习流程如图2所示。
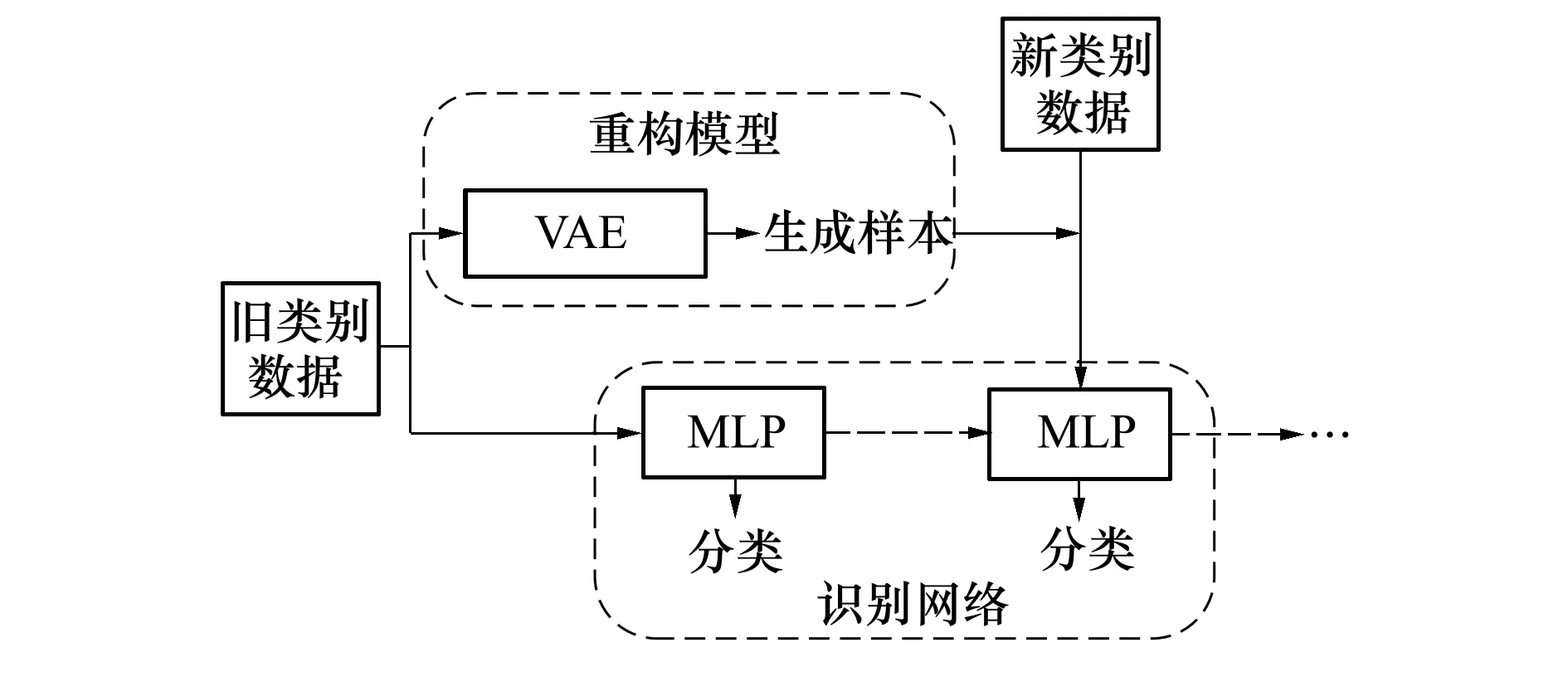
图2 GR增量网络学习流程
GR增量网络在类别增量学习过程中,对历史类别数据进行重构的模型是变分自编码器(variational autoencoder,VAE)[8],由编码器、采样模块和解码器组成。编码器将图像数据分布的高维特征映射到低维特征上,这一部分主要是均值和方差的计算;图像数据经过编码后,采样模块从正态分布中采样数据,并与编码器得到的均值和方差联合计算,从而得出采样变量;获得采样变量后,将其作为解码器的输入,利用解码器进行图像还原,输出生成图像。对图像进行训练的识别网络采用多层感知机(multilayer perceptron,MLP)[9]这一浅层全连接网络。
2.2 GR增量网络实验分析
本文实验平台为AMD 5900X CPU、Nvidia RTX 3080 GPU和32G内存的工作站,Pytorch版本为1.9,操作系统为Windows10。针对本文建立的声呐图像数据集,采用GR增量网络进行训练。随着任务目标的不断增加,网络对新任务目标和旧任务目标的识别率变化如图3所示。
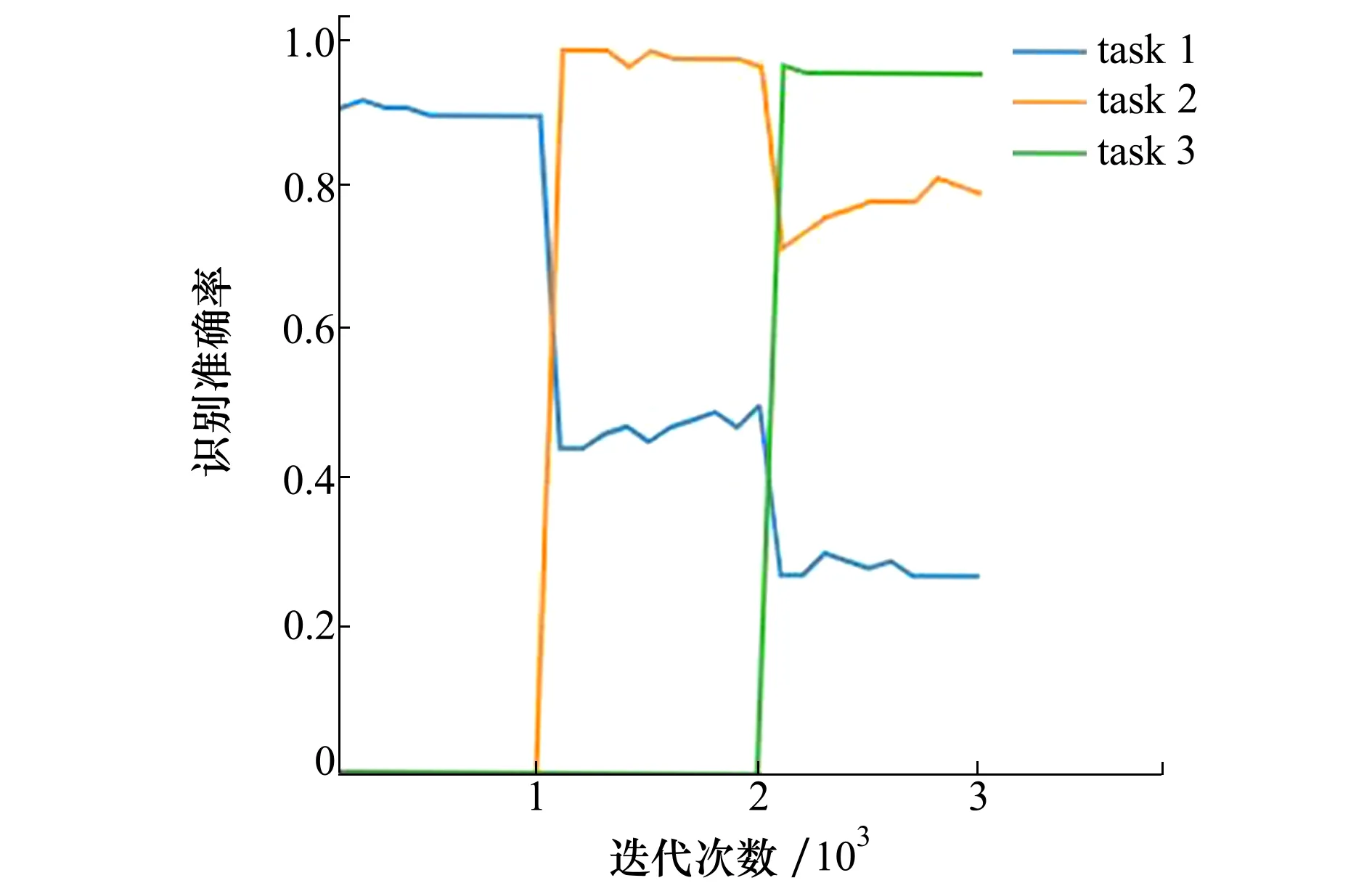
图3 GR增量网络的识别率
当第一个任务进入增量网络训练完成后,网络对所有目标类别的识别准确率为89.9%。当第二个任务作为新类别数据进入增量网络训练完成后,网络对所有目标类别的平均识别率为73.6%,对历史学习的第一个任务的识别率从89.9%降为50.5%。当第三个任务作为新类别数据进入增量网络训练完成后,网络对所有目标类别的平均识别率为67.6%,对历史学习的旧任务目标的识别率明显下降,其中,对第一个任务的识别准确率降到了27.3%,对第二个任务的识别准确率降到了79.6%。结果表明,GR增量网络的平均识别率较低,对历史任务目标产生了较严重的灾难性遗忘。
3 改进的GR增量网络
3.1 网络结构改进原理
由2.2节可知,GR增量网络对于声呐图像的类别增量学习效果较差,本文对GR增量网络的重构模型和识别网络进行改进,以期望获得更好的类别增量学习性能。
GR增量网络的重构模型VAE虽然可以通过编码与解码重构图像,但是这种方式下生成的图像较为模糊[10]。深层卷积生成对抗网络(deep convolutional generative adversarial network,DCGAN)[11]由生成器和判别器两部分组成,二者结构近似于卷积神经网络,但是使用带步长的反卷积层或卷积层代替池化层,DCGAN通过生成器与判别器的生成对抗来重构图像。本文随机选取飞机和沉船的重构图像进行对比,VAE和DCGAN重构的声呐图像分别如图4a)和图4b)所示。两图的上半部为原始声呐图像,下半部为重构的图像。VAE重构的图像中,当飞机较小时,图像无法清晰分辨目标,并且所有沉船的重构图像均严重失真。相比而言,DCGAN重构的飞机与沉船图像轮廓更明显、细节更丰富,大部分重构图像可较为清晰地分辨目标。

图4 VAE和DCGAN重构的声呐图像
GR增量网络的识别网络MLP是由多个神经元层组成的全连接网络模型,它早期在手写数字识别和行人检测中获得了不错的效果[12]。但是,在进行声呐图像类别增量学习训练时,MLP这种全连接网络模型的参数量是十分巨大的,过大的参数量会导致网络训练过拟合,而且在图像的特征提取过程中,MLP会将所有图像转换成一维向量,导致其失去空间特征,影响图像的分类识别准确率。卷积神经网络(convolutional neural network,CNN)[13]利用卷积层和池化层实现了网络结构的局部连接、权值共享和空间下采样,在提取出图像局部空间特征的同时,有效降低了网络模型训练的参数量,避免训练过拟合,对图像的准确识别起到积极作用。
本文基于水下目标声呐图像的特点,设计搭建新的DCGAN和CNN,并将设计搭建好的DCGAN和CNN分别替换GR增量网络的VAE和MLP,作为网络新的重构模型和识别网络,得到改进的GR增量网络。改进的GR增量网络结构如图5所示。
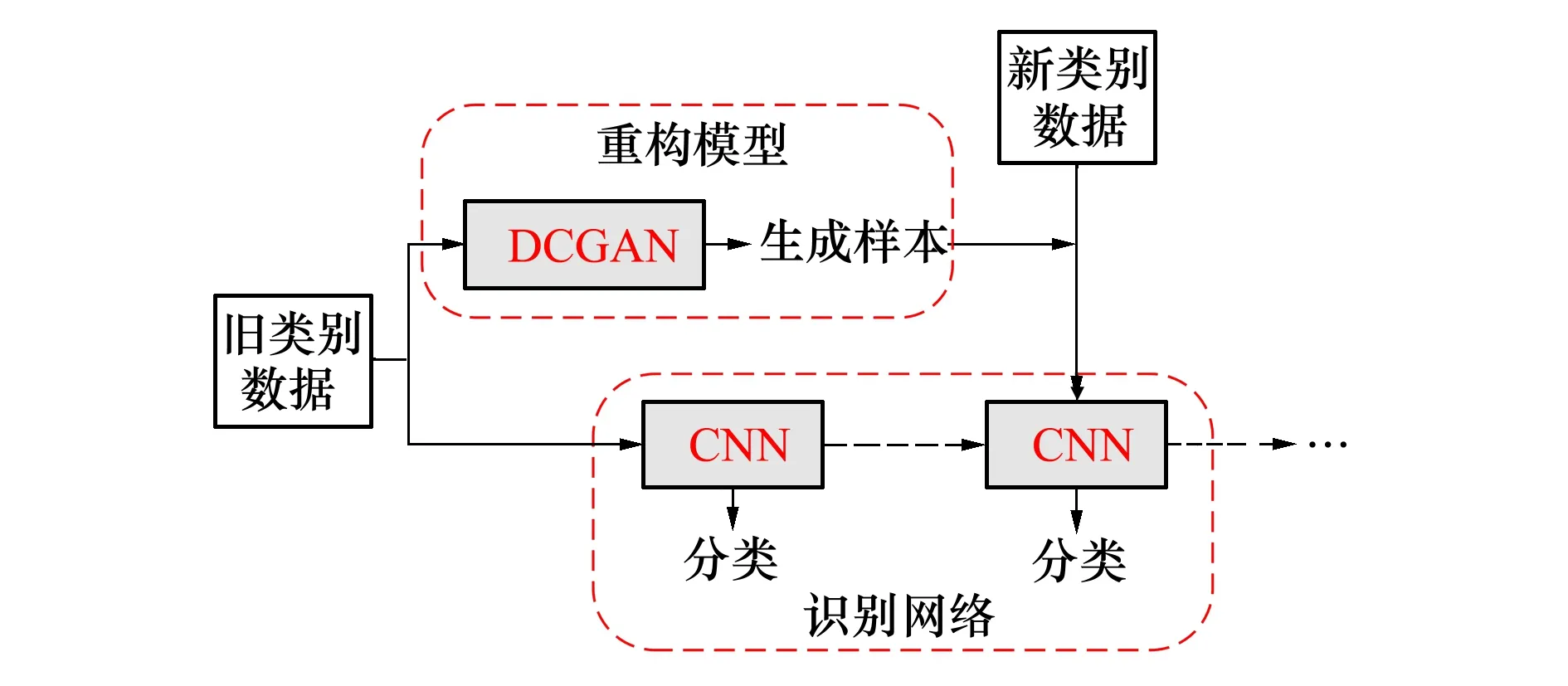
图5 改进的GR增量网络结构
3.2 网络模型搭建
3.2.1 DCGAN模型搭建
基于生成对抗网络理论与水下目标声呐图像特点,设计搭建DCGAN需考虑以下几点:
1) 生成器与判别器模型的设置。生成器与判别器要求模型对称,即生成器的反卷积层与判别器的卷积层数目相等,这样才能达到网络可微的目的,从而使网络的损失函数在训练过程中向着一个方向稳定收敛。
2) 反卷积层和卷积层数目的设置。由于声呐图像样本数少,应使用较少的层数进行模型搭建,避免因参数过多而导致网络训练出现过拟合。
3) 卷积层参数的设计,包括卷积核大小、步长、边界填充数目。声呐图像经过裁剪等预处理操作后,图像的尺寸相较原始图像减小了很多,为了避免网络模型在声呐图像的特征提取过程中丢失大量的有用特征,应使用较小的卷积核,如3×3卷积核。设置步长可以压缩卷积层的运算量,加快网络训练的拟合速度,但是步长不宜设置过大,过大的步长会使卷积层提取不到充足的声呐图像特征。边界填充是为了避免带步长的卷积运算错过声呐图像的边缘信息,边界填充的数目需根据输入图像、步长与卷积核来设置,不能超过卷积核的大小,以避免无效运算。
4) 网络参数优化算法和激活函数的选取。Adam算法能基于训练数据迭代更新网络参数,具有计算高效和所需内存少等优势。ReLU、Leaky ReLU激活函数在图像处理的卷积神经网络中使用较多,它们能够保持梯度不衰减,从而缓解梯度消失问题。
综合考虑以上几点设计要求,本文设计搭建的DCGAN的生成器与判决器模型分别如表2~3所示。

表2 生成器模型
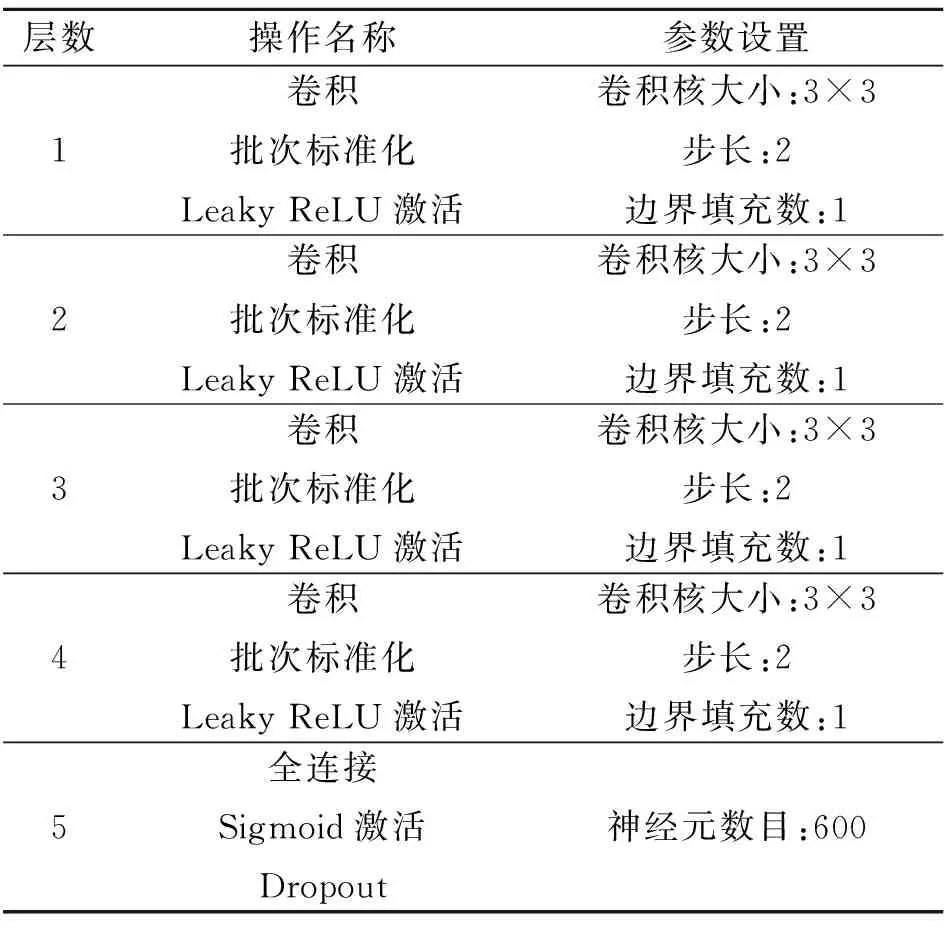
表3 判别器模型
生成器首先产生随机噪声输入到网络第一层——全连接层,通过全连接层进行尺寸变换,转化为7×7×128的特征矩阵,然后该特征矩阵通过4层反卷积核大小为3×3,步长s=2的反卷积层,同时,对反卷积层进行p=1的边界填充。其中,在每个反卷积层进行反卷积操作前,都使用批次标准化BatchNorm和激活函数Leaky ReLU,将特征归一化与非线性整合,以加速网络训练和提升训练的稳定性。最终,经过4个反卷积层后,网络输出得到与历史图像尺寸(112,112)相同的生成图像。
判别器与生成器形成模型对称,同样设置4层卷积核大小为3×3,步长s=2的卷积层,并进行p=1的边界填充,经过每一层卷积操作完成特征提取后,对得到的特征进行BatchNorm批次标准化以及Leaky ReLU激活函数的非线性整合。然后,判别器网络中加入了Dropout,可在一定程度上避免网络过拟合。最后,将提取到的特征图经过全连接层输出映射为一个值,并将这个值经过sigmoid激活函数后,输出该判别器网络对输入图像数据类别的概率值。
3.2.2 CNN模型搭建
CNN与DCGAN的判别器模型设计搭建原理大体相似,不同的是本文的CNN采用ReLU激活函数,并且比DCGAN的判别器多了池化层的设计,池化层通常位于卷积层之后,用于降低卷积层的尺寸,从而降低网络训练复杂度,但是,池化层在降低网络复杂度的同时会丢失掉图像的许多特征。由于声呐图像分辨率低,应用于声呐图像识别的CNN应使用较少的池化层,池化方法可以选取最大池化。本文设计搭建的CNN模型如表4所示。
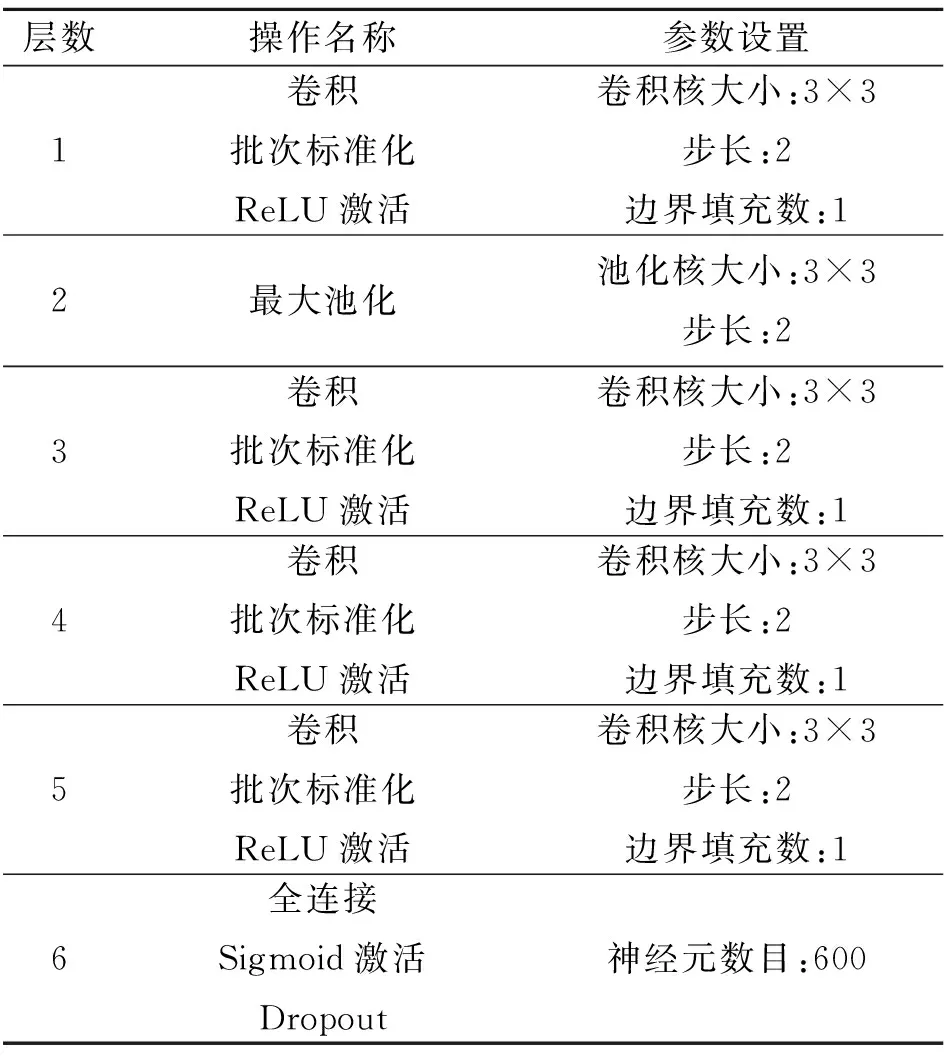
表4 CNN模型
3.3 改进的GR增量网络实验分析
为验证本文提出的改进的GR增量网络的类别增量学习性能,使用该网络对水下目标声呐图像数据集进行类别增量学习训练,每一个任务目标训练完成后,都用当前学习过的所有类别数据进行测试,得到网络对新任务目标和旧任务目标的识别率变化如图6所示。
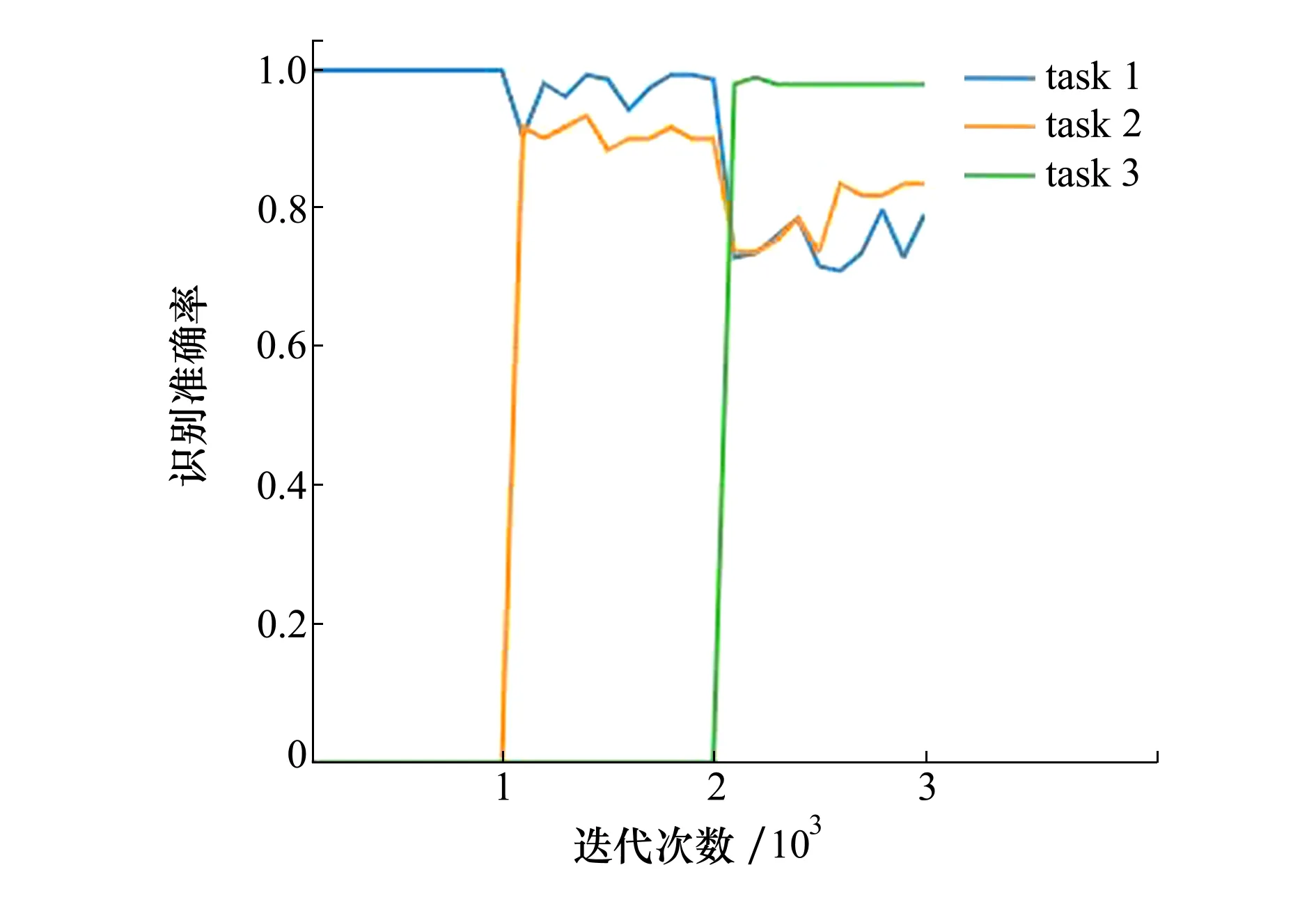
图6 改进的GR增量网络的识别率
将GR增量网络与改进的GR增量网络的平均识别准确率进行对比,网络改进前后的类别增量识别率结果如表5所示。
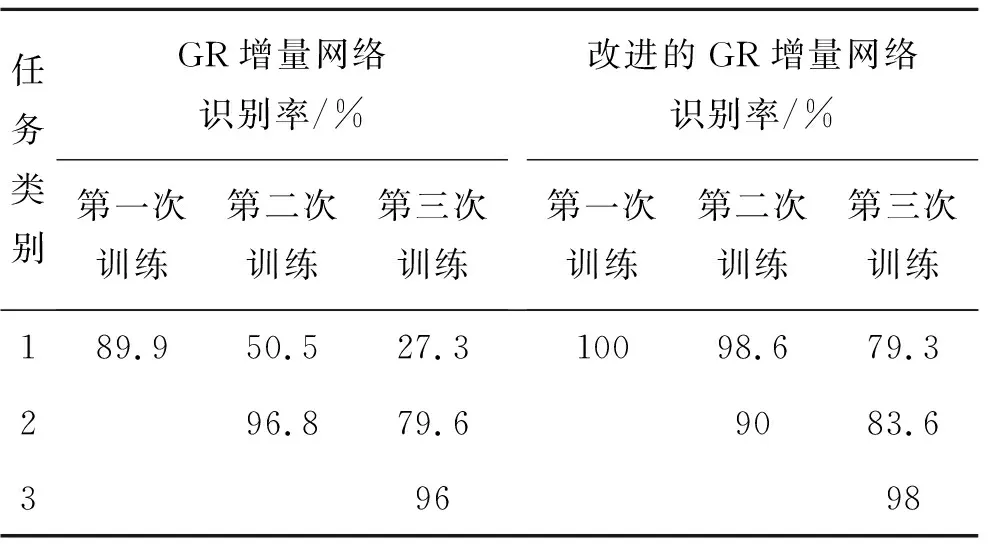
表5 增量网络改进前后的类别增量识别率
采用改进的GR增量网络,第一个任务进入增量网络训练完成后,网络对所有目标类别的平均识别率为100%。当第二个任务作为新类别数据进入增量网络训练完成后,网络对所有目标类别的平均识别率为94.3%,对历史学习的第一个任务的识别率从100%降至98.6%,对第二个任务的识别率为90%。当第三个任务作为新类别数据进入增量网络训练完成后,对当前所有目标类别的平均识别率为87%,对历史学习的第一个任务的识别率从98.6%降到了79.3%,对历史学习的第二个任务的识别率从90%降到了83.6%,对第三个任务的识别率为98%。改进的GR增量网络对当前所有任务目标的平均识别准确率始终高于GR增量网络,平均识别率相比提高了19.4%。改进的GR增量网络对于历史任务目标的平均识别率相比GR增量网络提升了34.7%。
为验证本文提出改进的重构模型和识别网络分别对于声呐图像类别增量学习的作用,将重构模型VAE和DCGAN与识别网络MLP和CNN分别进行组合,重构模型和识别网络分别改进前后的平均识别率和参数量如表6所示。
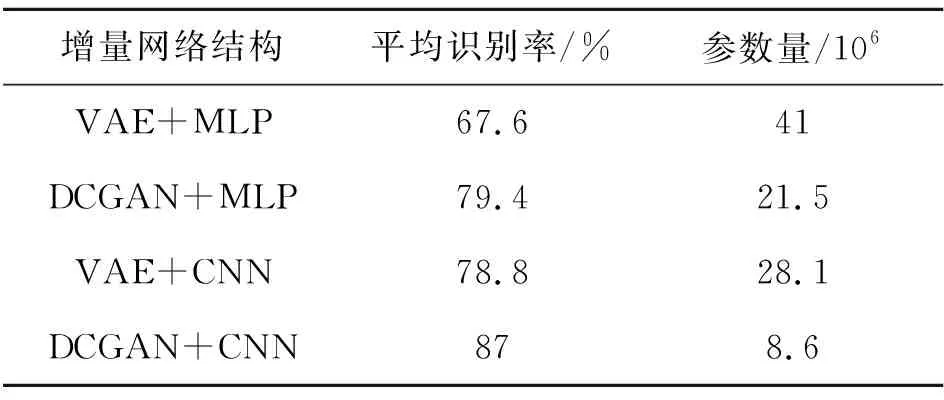
表6 增量网络改进前后的平均识别率和参数量
由表6可得,相比VAE+MLP,DCGAN+MLP的平均识别率提高了11.8%,参数量降低了47.5%;VAE+CNN的平均识别率提升了11.2%,参数量降低了31.5%;DCGAN+CNN的平均识别率提高了19.4%,参数量降低了79%。相比单独改进识别网络,单独改进重构模型对GR增量网络平均识别率的提高和参数量的降低更加明显,而DCGAN+CNN是最佳的GR增量网络结构。
4 实验验证与分析
4.1 实验数据集的建立
为验证本文提出的改进GR增量网络对水下目标声呐图像类别增量学习的泛化性,通过外场试验建立水下目标声呐图像数据集如表7所示,将实验数据集随机划分为图7所示的3个任务目标。
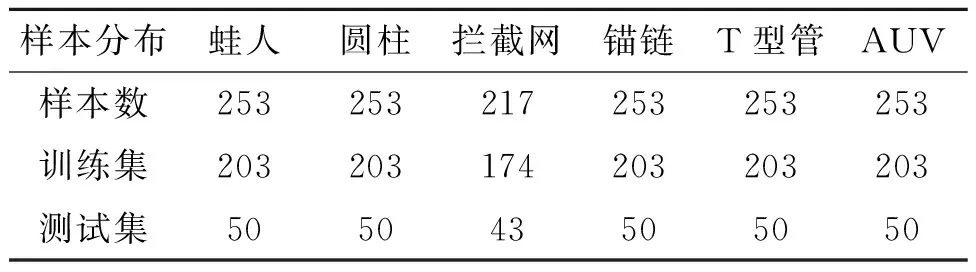
表7 实验数据集

图7 任务目标
4.2 增量网络泛化性实验
分别采用GR增量网络和改进的GR增量网络对实验数据集进行类别增量学习训练,得到改进前后的GR增量网络对所有任务目标的识别率如表8所示。
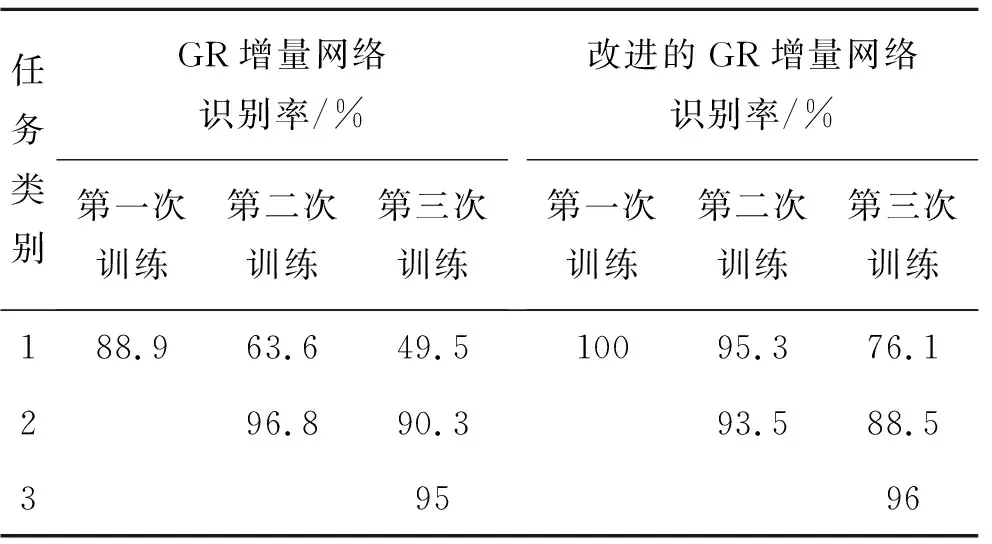
表8 增量网络改进前后的类别增量识别率
本文提出的改进的GR增量网络相比GR增量网络,第一次训练后的平均识别率提高了11.1%。第二次训练后的平均识别率提高了14.2%。第三次训练后,对所有任务目标的平均识别率提升了8.6%。对历史任务目标的平均识别率提升了18.8%。
对于本文建立的实验数据集,采用经典增量学习方法与本文提出的改进GR增量网络进行对比,各种增量学习方法的识别率结果如表9所示。
由表9可得,基于正则化的EWC和LWF方法对于声呐图像类别增量学习表现较差,当网络训练完成后,对所有任务目标平均识别率均低于45%。相比而言,GR增量网络总体表现更好,尤其是本文提出的改进GR增量网络,对所有任务目标的平均识别率达到86.9%。
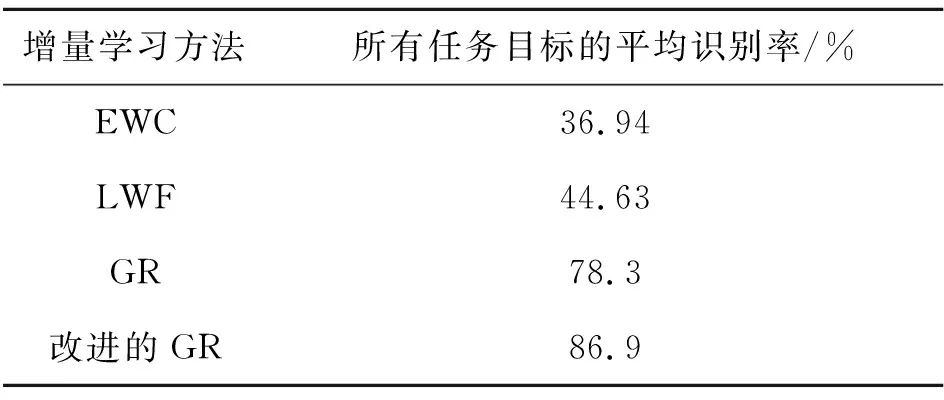
表9 各种增量学习方法的识别率
5 结 论
本文基于深层卷积生成对抗网络与卷积神经网络理论,对GR增量网络的重构模型与识别网络进行改进,提出了一种改进的GR增量网络,对所有声呐图像任务目标的平均识别率提升了19.4%,对历史任务目标的平均识别率提升了34.7%。采用外场实验获得的水下目标声呐图像实验数据集进行了网络泛化性实验,改进的GR增量网络对所有任务目标的平均识别率提升了8.6%,对历史任务目标的平均识别率提升了18.8%。上述结果表明,本文提出的改进GR增量网络对于声呐图像具有良好的类别增量学习性能,较好地缓解了对历史任务目标的灾难性遗忘问题。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
当代陕西(2022年6期)2022-04-19
海洋信息技术与应用(2020年3期)2020-08-24
计算机工程(2020年3期)2020-03-19
中学生数理化·中考版(2019年9期)2019-11-25
小学科学(学生版)(2019年10期)2019-11-16
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
电信科学(2016年9期)2016-06-15
中国交通信息化(2016年2期)2016-06-06
