
基于DA-SSD的有轨电车轨道小目标障碍物检测算法
2023-05-09 05:29王运明彭国都周奕昂李卫东
大连交通大学学报 2023年2期
王运明,彭国都,周奕昂,李卫东
(1.大连交通大学 自动化与电气工程学院,辽宁 大连 116028;2.中车长春轨道客车股份有限公司 国家工程技术中心,吉林 长春 130000)
城市有轨电车是一种能提供高质量公共交通服务、降低交通拥堵、改善空气环境的低成本高效率的交通工具,未来将成为公共交通系统的新生力量。城市有轨电车主要采用人工驾驶的方式行驶在城市骨干道路中,与汽车、行人共同占用道路空间。然而,驾驶员受视觉盲区、精力不集中、突发情况等因素影响,难以准确观察电车轨道前方的障碍物,尤其是行人、动物等小目标障碍物,容易引发交通事故,影响城市有轨电车行车安全。近年来,深度学习技术的快速发展,在计算机视觉领域得到广泛应用,大大提升了目标检测的精度,可为有轨电车前方小目标障碍物检测提供新的技术手段,对提高城市有轨电车行车安全具有重要意义。目前,基于深度学习的目标检测算法主要分为两类。一类是以R-CNN[1]、Fast R-CNN[2]、Faster R-CNN[3]为主的基于区域的双阶段目标检测算法,该类算法具备检测精度高的优点,但检测速度较慢。文献[4]在Faster R-CNN算法的基础上,设计全局平均池化层替换全连接层,增加先验框数量,提高目标建议区域的精确性,提升了铁路侵限障碍物的识别能力,但实时性较差。另一类是以YOLO[5]、SSD[6]为主的单阶段目标检测算法,该类算法不需要提前生成真实的先验框,直接将目标边界框定位问题转换为回归问题,具有检测速度快的优点。文献[7]在YOLO-V3的基础上,采用k-means算法聚类分析缺陷先验框的尺寸,提高轨道扣件缺陷的检测准确性和效率;刘力等[8]针对YOLO-V4网络的先验框,采用欧式距离度量改进k-means算法的聚类中心选取方法,获得更加吻合实际检测对象大小的先验框尺寸,提升铁路侵限障碍物的检测精度。YOLO改进算法的检测精度仍低于SSD算法。张云佐等[9]改进了SSD网络结构的网络宽度和网络深度,提升了铁路隧道漏缆卡具的检测精度;李兆洋等[10]采用ResNet101替换SSD的VGG16网络,利用膨胀卷积扩大网络的感受野,提高高铁轨道扣件的检测精度;王焕民等[11]提出了一种基于MobileNet-SSD的铁路信号灯检测算法,提升了铁路信号灯的检测精度和速度。上述SSD改进算法提取低层特征层的语义信息能力有限,致使铁路小目标障碍物的检测精度不高。
为提高有轨电车轨道小障碍物的检测精度和效率,在SSD算法的基础上,本文提出了一种基于DA-SSD的有轨电车轨道小目标障碍物检测算法。
1 DA-SSD网络结构
城市有轨电车运行在与汽车、行人等共用的复杂城市主干道路上,前方经常出现各类障碍物,尤其是小目标障碍物,严重影响有轨电车的行车安全和行车效率。为提高有轨电车检测前方障碍物的智能化水平,本文在SSD目标检测算法的基础上,设计双段反卷积模块,增加自适应注意力机制模块,建立了DA-SSD网络结构模型,提升轨道小目标障碍物的检测能力。DA-SSD网络结构模型见图1,图中De表示对特征层进行反卷积,C表示通道级联融合,A表示自注意力机制模块。

图1 DA-SSD网络结构模型
DA-SSD网络结构模型以VGG16主干网络为基础进行设计。首先,设计双段反卷积模块(Two stage deconvolution module),替换VGG16网络中用于检测小目标障碍物的conv4_3、fc7两层低层特征层,生成融合特征层fu_conv4_3、fu_fc7;其次,增加自适应注意力机制模块(Adaptive attention mechanism module),生成具有更强语义信息和更精确位置信息的new_conv4_3、new_fc7;最后,修正先验框生成方式,增强电车检测轨道小目标障碍物的适应性,提升小目标障碍物的检测精度。
1.1 低层双段反卷积模块
深度卷积网络的低层特征层包含丰富的特征信息,SSD目标检测算法主要通过低层特征层检测小目标。SSD算法在低层特征层的卷积次数较少,产生较少的语义信息,影响电车轨道小目标障碍物的检测效果。为增强SSD算法在低层特征层的特征表达能力,本文设计了低层双段反卷积模块,对conv6_2、fc7两层特征层分别进行反卷积操作[12],按照通道级联方式与前一层特征层进行融合。低层双段反卷积模块结构见图2。
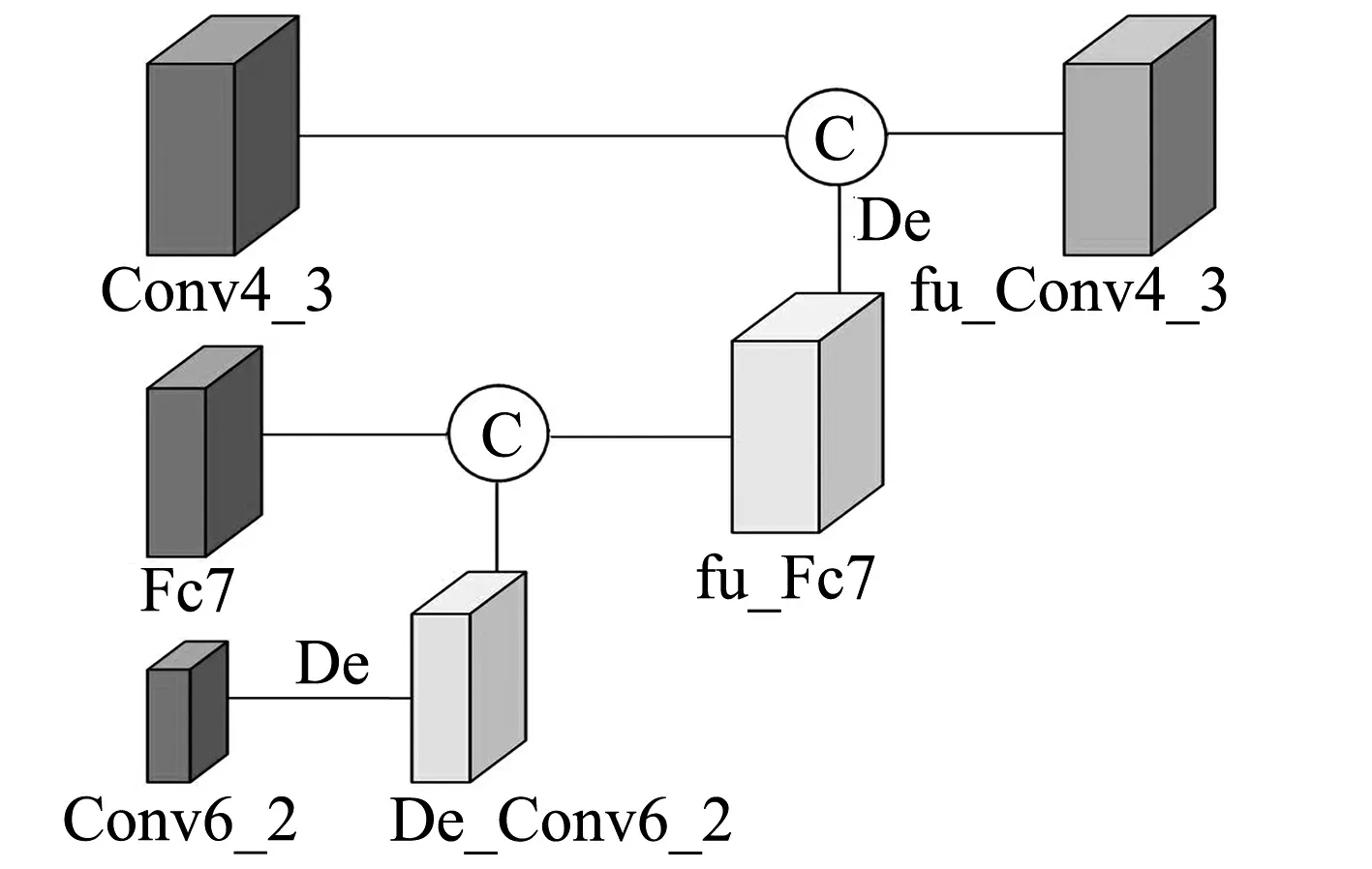
图2 低层双段反卷积模块结构
低层双段反卷积模块首先对conv6_2进行反卷积,得到与fc7大小、通道数均相同的De_conv6_2,然后按照通道级联方式与Fc7进行融合,得到fu_fc7;同理,对新生成的fu_Fc7进行反卷积,得到与Conv4_3大小、通道数均相同的De_fu_fc7,再按照通道级联方式与Conv4_3进行融合,得到fu_conv4_3。
1.2 自适应注意力机制模块
VGG16网络的各个输入特征层包含许多不同大小的向量,且向量之间存在一定的相关性。然而,在实际训练中,通常无法充分利用这些输入特征之间的相关性;同时,由于多尺度特征图的感受野大小不同,导致各个特征图包含的特征信息存在差异,造成生成的特征图无法充分反映不同尺度下空间特征的重要性。上述问题将导致模型预测结果出现偏移,影响训练效果,降低预测精度。因此,在低层双段反卷积模块新生成的fu_conv4_3、fu_Fc7之后,增加CBAM自适应注意力机制模块,自适应地调整融合特征层中的参数,更加关注对当前任务有意义的关键信息,生成New_Conv4_3、New_fc7,提升新的小目标预测层中通道间的相关性和目标间的空间依赖关系。
CBAM自适应注意机制包含通道注意力模块和空间注意力模块,见图3。

(a)通道注意力模块
通道注意力模块,以通道为单位,对低层双段反卷积模块中融合生成的特征图Fi∈RH×W×C分别做全局最大池化和全局平均池化,生成Fi1、Fi2,Fi1、Fi2∈R1×1×C,该过程可分别表示为:
Fi1=Max Pool (Fi)
(1)
Fi2=Avg Pool (Fi)
(2)
Fi1、Fi2传递到一个共享的全连接层。全连接层共包含两层,第一层全连接层神经元个数较少,第二层全连接层神经元个数和输入特征图通道数相同。对全连接层输出的两个长度为C的特征长条进行相加处理,并取sigmoid,使其值固定在0~1,得到Channelattention(Fi),简称CA(Fi),CA(Fi)∈R1×1×C,该过程可表示为:
CA(Fi)=S[FR(Fi1)+FR(Fi2)]
(3)
最后,将CA(Fi)乘以输入特征图。
空间注意力模块以每个通道对应的点为单位,对CA(Fi)分别做全局最大池化和全局平均池化,生成CA(Fi1)、CA(Fi2)和CA(Fi1)、CA(Fi2)∈RH×W×1,CA(Fi1)和CA(Fi2)堆叠得到CA(Fi3)。
再对CA(Fi3)特征图取卷积,卷积核的通道数为1,生成一个大小为H×W×1的特征长条,特征长条取sigmoid,使值固定在0~1,得到Spatial attention(Fi),简称SA(Fi),该过程可表示为:
SA(Fi)=S{C[CA(Fi3)]}
(4)
最后,将该值分别乘以输入CA(Fi),得到新的特征预测层。
1.3 低层双段反卷积模块
SSD算法采用默认先验框的方式,处理不同层的特征图,回归位置信息。算法以不同尺寸缩放每层特征层的先验框,即:
Sk=0.2+0.17(k-1),k∈[1,m]
(5)
式中:Sk表示第k+1层先验框的大小相对于输入图片的比例;m设置为5。
第一层特征层生成的先验框相对于输入图片的比例为0.1,其他5层特征层生成的先验框相对于输入图片的比例分别为0.1、0.2、0.37、0.54、0.71、0.88,若输入图片大小为300×300,则每层特征层生成长宽比为1的先验框大小为30、60、111、162、213、264。



图4 自制数据集尺寸分布
由图4可以看出,自制数据集中真实框的尺寸分布在0~40,均为小目标障碍物,应根据真实框的变化范围设置先验框的尺寸。SSD算法中原始先验框的生成方法在训练时易产生较大的回归偏差。
因此,本文将第一层特征层先验框相对图片的比例调整为0.05;同时对先验框的生成公式进行修改,修改之后的公式为:
Sk=0.1+0.05(k-1),k∈[1,m]
(6)
则各层特征层生成的先验框相对于输入图片的比例分别为:0.05、0.10、0.15、0.20、0.25、0.30,每层特征层生成长宽比为1的先验框大小分别为:15、30、45、60、75、90。
SSD模型生成的先验框中负样本的数量远大于正样本数量,会导致模型收敛速度变慢、漏检率偏高。DA-SSD模型仍通过计算先验框和真实框的iou区分正负样本,iou大于阈值为正样本,否则为负样本。模型按照正、负样本1∶3的比例删除负样本中置信度低的先验框,保证训练过程中正负样本数量的均衡性。
2 试验数据与试验结果分析
2.1 试验设置
试验采用分段衰减的方式调整学习率,初始学习率设置为5×10-4,每训练1 000次学习率下降为前一阶段的1/10,当迭代次数达到10 000次后,学习率大小保持不变。选用VGG16网络在VOC2007数据集上的训练权值作为本试验的预训练参数,设置训练集和测试集的比例为4∶1,input_shape为325×500,classes为3,batch_size为8。本试验在Python 3.8.3环境下的tensorflow深度学习框架开展训练和测试。
2.2 自制数据集和评测指标
试验采用实地拍摄的电车轨道障碍物图片制作数据集。拍摄图片数量为2 000张,障碍物分为人、动物两类小目标,每类障碍物包含1 000张图片,预处理过程将图片大小调整为325×500;通过对每张图片进行镜像操作达到数据集增广的目的,增广后的障碍物图片见图5。

图5 数据镜像增广样本
最终数据集共4 000张图片,包含两类6 328个小目标障碍物。通过tensorflow中Labelimg标注工具,标注数据集中障碍物目标区域及其所属类别,生成相应的xml文件,图片和对应标注文件的存储格式与VOC2007数据集相同。
为了更直观地衡量DA-SSD算法检测有轨电车前方小目标障碍的能力,采用平均精度均值MAP(Mean Average Precision)和每秒传输帧数FPS(Frame Per Second,即每秒处理图片数量)作为评价指标。平均精度均值MAP是所有类别平均精度AP的平均值,平均精度AP是综合数据样本中某个类别的精确率(Precision, P)和召回率(Recall, R)的评价指标。
精确率指被正确检测的数量占全部检出数量的百分比,召回率指被正确检测的数量占全部标注数量的百分比。根据检测结果绘制纵轴为精确率,横轴为召回率的P-R曲线,P-R曲线的面积为平均精度值,计算公式如下:

(7)
2.3 试验结果与分析
为验证本文所提出的双段反卷积模块和自适应注意力机制模块对有轨电车小目标障碍物的检测效果,通过特征图可视化,对比SSD在conv4_3和DA-SSD算法在New_conv4_3输出的特征图,结果见图6。

图6 两种算法在conv4_3层输出的特征图
由图6可以看出,SSD算法在conv4_3特征层输出的可视化特征图中狗的空间特征较为模糊,说明SSD算法经过多层卷积后空间信息丢失明显,导致狗的特征逐渐抽象化;DA-SSD算法在New_conv4_3特征层输出的特征图中狗的空间特征更为清晰,说明采用双段反卷积模块和自适应注意力机制模块能够丰富低层特征图的语义信息和空间信息,有利于提高小目标障碍物的检测精度。
同时,为验证本文针对小目标障碍物检测提出的先验框生成方式,在VOC2007训练集中分别对SSD算法和执行先验框改进操作的SSD算法(Improve-SSD)进行训练,训练过程中损失函数Loss变化曲线见图7。

图7 Loss曲线对比图
由图7可知,迭代约8 000次后,SSD算法与Improve-SSD算法达到收敛状态,SSD算法的收敛值约为0.7,Improve-SSD算法的收敛值约为0.65。说明修正先验框生成方式,提升了算法的性能,更适用于检测小目标障碍物。
为评估DA-SSD算法对城市有轨电车轨道小目标障碍物的检测性能,利用SSD算法和DA-SSD算法在自制数据集上进行训练和测试,Riou设置为0.6,测试集中Precision、Recall、AP三个指标的测试结果见表1。
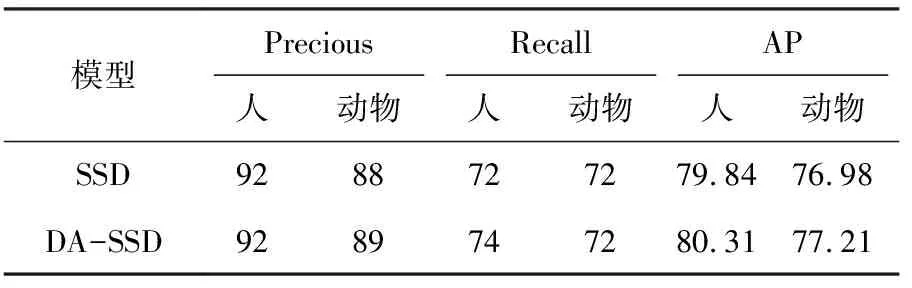
表1 两种算法的AP测试结果
由表1可知,DA-SSD算法的各项测试指标均高于SSD算法,检测人和动物两类小目标障碍物的Precious值均大于89%,AP值均大于77%,DA-SSD算法提高了电车轨道小目标障碍物的检测精度。
为进一步验证本文所提出算法的优越性,将DA-SSD算法与Faster RCNN、YOLO-V3、SSD、FSSD 4种先进的目标检测算法进行对比。其中,FSSD算法是对SSD的经典改进算法,提出了一种特征融合的方式,将VGG16产生的不同尺度的特征图,利用双线性插值法变换为与conv4_3大小、通道数相同的的特征图,再按照通道级联的方式将多个特征图进行特征融合。所有用于对比的目标检测算法均在自制的城市轨道电车障碍物数据集上进行训练和测试。不同算法的Loss曲线见图8,性能对比见表2。

图8 各种目标检测算法的Loss曲线对比图

表2 不同算法的性能对比
由图8可知,由于DA-SSD网络模型更为复杂,在训练的初始阶段,DA-SSD算法的损失值高于SSD、Faster-RCNN、YOLO-V3 3种算法,但低于FSSD算法。在迭代约7 000次后,DA-SSD算法达到收敛状态,收敛速度快于SSD算法和FSSD算法,这是因为DA-SSD算法增加了自适应注意力机制模块,能够自适应地分配权重,快速排除干扰,提升训练收敛速度;DA-SSD算法的收敛值约为1.5,低于其余4种算法。
由表2可知,DA-SSD算法检测人、动物两类小目标障碍物的AP值均高于其他4种算法,提升了小目标障碍物的检测精度。在测试集下,相比于Faster RCNN、YOLO-V3、SSD、FSSD 4种目标检测算法,MAP分别提升了0.12%、0.5%、0.28%、0.21%。从检测速度上看,DA-SSD算法的FPS在测试集上达到23.4 f/s,检测速度与SSD、FSSD基本保持一致,能够满足城市有轨电车对障碍物检测速度的要求。
为避免试验过程中由于Riou取值的不同,使试验结果产生偶然性,在测试集上设置Riou分别为0.5、0.7。DA-SSD算法与其他算法的检测精度随迭代次数的变化情况见图9,其中图9(a)为Riou=0.5时的测试结果,图9(b)为Riou=0.7时的测试结果。

(a) Riou=0.5
由图9可以看出,当Riou取不同值时,经过约4 000次迭代后,DA-SSD算法的MAP值逐渐超过Faster RCNN、YOLO-V3、SSD、FSSD 4种算法。经过约6 000次迭代后,DA-SSD算法的MAP曲线进入稳定的收敛状态,且MAP值大于其余4种算法,表明无论Riou取任何值,DA-SSD算法对有轨电车小目标障碍物的检测效果均优于Faster RCNN、YOLO-V3、SSD、FSSD 4种主流的目标检测算法。
最后,采用自制数据集中的测试集对训练后的SSD模型和DA-SSD模型进行小目标障碍物的检测测试,见图10。图10(a)为SSD算法检测动物和人的结果,图10(b)为DA-SSD算法检测动物和人的结果。

(a) SSD算法
由图10可以看出,相比于SSD算法,DA-SSD算法提升了预测框的位置精度和置信度,提高了有轨电车轨道小目标障碍物的检测精度。DA-SSD算法通过引入低层双段反卷积模块和自注意力机制模块,丰富了低层特征层的语义信息,通过修正先验框生成方式,增强了电车检测轨道小目标障碍物的适应性,提升了小目标障碍物的检测精度。
3 结论
本文为提高SSD算法检测有轨电车轨道小目标障碍物的精度,提出了一种基于DA-SSD的有轨电车轨道小目标障碍物检测算法。该算法利用反卷积和通道融合,设计双段反卷积模块,丰富低层特征层语义信息;增加自注意力机制模块,生成新的具有更强语义信息和精确位置信息的特征预测层;结合实际应用场景,缩小SSD算法先验框大小,增强轨道小目标障碍物检测的适应性。在自制的有轨电车轨道障碍物数据集上进行训练与测试,结果表明:该算法保持检测速度的基础上,提高了轨道小目标障碍物的检测精度,为有轨电车安全行驶提供保障。
猜你喜欢
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
成都信息工程大学学报(2019年3期)2019-09-25
报刊荟萃(上)(2018年3期)2018-04-24
自动化学报(2017年5期)2017-05-14
益寿宝典(2017年34期)2017-02-26
探测与控制学报(2015年4期)2015-12-15
建筑工程技术与设计(2015年12期)2015-10-21
东南法学(2015年2期)2015-06-05
城市道桥与防洪(2014年5期)2014-02-27
