
一种时序边界注意力循环暴力行为检测神经网络
2023-04-29 15:26:33刘邦义周激流张卫华
四川大学学报(自然科学版) 2023年2期
刘邦义 周激流 张卫华

暴力行为检测是行为识别的一个重要研究方向,在网络信息审查和智能安全领域具有广阔的应用前景.针对目前的时序模型在复杂背景下不能有效提取人体运动特征和常规循环神经网络无法联系输入上下文的问题,本文提出一种时序边界注意力循环神经网络TEAR-Net.首先,以本文提出的一种全新的运动特征提取模块MOE为基础,在保留输入视频段序列背景信息的前提下加强运动边界区域.运动边界对于动作识别的作用要远大于图像其他区域,因此运动边界加强能够有效提高动作特征的提取效率,从而提升后续网络的识别精度.其次,引入了一种全新的结合上下文语境和注意力机制的循环卷积门单元(CSA-ConvGRU),提取连续帧之间的流特征以及不同帧的独立特征,并关注关键帧,能够极大提升动作识别的效率,以少量参数和较低计算量的代价掌握视频流的全局信息,从而有效提高识别准确率.本文提出的模型在目前最新的公开数据集RWF-2000和RLVS上进行了多种实验.实验结果表明,本文提出的网络在模型规模和检测精度上均优于目前主流的暴力行为识别算法.
暴力行为; 时序信息; 运动边界; 注意力机制; 上下文
TP391A2023.023003
收稿日期: 2022-01-17
基金项目: 四川省科技计划(2022YFQ0047)
作者简介: 刘邦义(1998-), 男, 硕士研究生, 主要研究方向为计算机视觉、模式识别等. E-mail: 228980603@qq.com
通讯作者: 张卫华. E-mail: zhangweihua@scu.edu.cn
Temporal edge attention recurrent neural networkfor violence detection
LIU Bang-Yi1, ZHOU Ji-Liu1, ZHANG Wei-Hua2
(1. College of Electronic Information Engineering, Sichuan University, Chengdu 610065, China;
2. College of Computer Science, Sichuan University, Chengdu 610065, China)
Violence detection is one of the most important research topic in behavior recognition,which has great potential applications in network information review and intelligent security.The published works cannot keep their performance in the complexity environments, because they cannot effectively extract movement features and contact consecutive frames. Hence, a novel method is proposed in this paper, which is referred to as temporal edge attention recurrent neural network (TEAR-Net). First, we propose a novel motion object enhancement (MOE) module, which enhances the motion edge while keeping the background information of the video sequences. Because the motion edge has a much greater effect on motion recognition than other areas of the image, the enhancement of motion edge can effectively improve the extraction efficiency of action features, and thus the recognition accuracy is improved. Then we introduce a novel recurrent convolutional gate unit CSA-ConvGRU, which combines context and attention mechanism. It can extract the stream features among consecutive frames and the independent features of each frame. Attention mechanism can help to focus on key frames, which greatly improve the efficiency of action recognition, capture the global information of the video stream with a lower cost, and thus effectively improve recognition accuracy. The proposed model has been tested on the currently lastest public datasets RWF-2000 and RLVS. The experimental results show that the proposed model outperforms the state-of-the-art violence detection algorithms in terms of computational cost and detection accuracy.
Violence; Temporal information; Motion edge; Attention mechanism; Context
1 引 言伴随着城镇化的规模不断扩大和人口的聚集,群众对公共区域安全的监管需求日益提升,各种监控设备被广泛部署.如今大部分的公共安全监管仍然采取基于人工观察的方式,因此尽管底层感知设备布置较为完善,但是仍然具有较高的漏检率和错检率.这导致有时不能及时处理应急事件.因此一种基于计算机图像技术的异常行为检测算法是急需的,由于图像技术的快速、准确、轻量化、高拓展性且易于维护等特点,这类方法具有较大的社会价值和应用前景[1].
视频作为安防监控的载体,由连续的图像构成,具有高度的时空相关性[2].相较于图片,视频往往具有更为丰富的信息,例如帧间的时间语义信息和空间语义信息.然而,视频具有输入维度高,时空信息难以解耦提取等难题.因此,如何提出一种针对视频的实时准确轻量化的异常行为检测算法是十分困难的,具有较高的研究价值.
近年来,行为识别的研究热度不断提高,许多算法相继被提出,根据特征提取方法的不同,可以被分为基于传统图像处理和基于深度学习的方法.Wang等[3]提出密集轨迹提取的相关算法(Dense Trajectories, DT ),通过将三种特征描述子方向梯度直方图融合编码后进行分类,最终取得了较好的效果.传统方法具有不需要训练以及对硬件设备要求低等优点,但是它们在面对背景复杂等情况下往往难以维持较好的表现,因为其提取的特征泛化能力不足.
神经网络近年来得到飞速发展,卷积神经网络(Convolutional Neural Network, CNN)作为神经网络的代表算法在诸多重要图像任务如分类[4]和分割[5]上均取得了瞩目的成绩.深度学习能够获得样本深层特征表示,故基于深度学习的方法往往具有较强的鲁棒性和较高的识别精度.行为识别算法可被分为多流卷积神经网络(Multi Stream CNN,MSCNN)的模型、时空序列模型和时间序列模型[6].Simonyan等[7]提出双流CNN模型,该模型分别从单帧RGB图像和多帧稠密光流图中提取视频的时空信息,最后将特征融合进行分类,取得较好的效果.尽管多流CNN模型在提取动作信息特征有一定优势,但是光流信息的提取需要大量算力,增大了计算开销,难以在边缘设备部署.
时空模型采用三维卷积提取时空特征.Tran等[8]在三维卷积的基础提出3D卷积模型(Convolutional 3D,C3D),C3D为三维卷积和池化的线性组合,故模型简单训练速度较快.为了缓解C3D参数量大的问题,Qiu等[9]提出了伪3D(Pseudo-3D, P3D)模型,Tran等[10]提出了 R(2+1)D模型.两种模型的都采用将时空域分离进行灵活组合的思路,从而在保证模型参数量小的同时,能够提升所提取特征的鉴别性和鲁棒性.
时序模型采用CNN与递归神经网络级联的方式提取时序特征.Hochreiter和Schmidhuber[11]提出长短期记忆单元(Long Short Term Memory, LSTM),被认为是时序模型最有代表性的方法之一.此后,Donahue等[12]提出了长期循环卷积网络(Long-term Recurrent Convolution Network, LRCN),LRCN将CNN和由LSTM单元组成的递归神经网络级联,分别提取输入的空间信息和时间信息.Melis等[13]在自然语言处理领域中发现随着模型的复杂程度的加深,LSTM单元中的输入与隐藏层之间的相关性会逐渐消失,进而提出了形变LSTM.Cho等[14]提出循环门单元(Gated Recurrent Units, GRU),GRU相较于LSTM具有参数量更少,训练速度更快等优点.Shi等[15]提出了ConvLSTM,ConvLSTM通过将LSTM中的全连接层替换为卷积层,使该结构不仅可以建立时序关系还可以像CNN一样提取局部空间特征.Lin等[16]在ConvLSTM中增加基于记忆单元的自注意力模块(Memory-based Self-Attention Module, SAM)预测记录全局时空特征,以此来提取输入中具有代表性的时空特征.
尽管时序模型取得了较好的识别效果,但该类方法在复杂背景下不能有效提取人体运动特征.相较于其他任务的视频数据而言,安防监控视频需对大范围场景进行监控,因此安防监控视频中的运动主体并不突出,目标往往较小,同时背景非常复杂.而时序模型针对具有突出主体的视频数据具有较好的识别效果,而当背景复杂并且运动目标较小时,该类方法难以保持其良好的识别性能.其主要原因是冗杂信息占据视频的主导地位,直接使用原始视频训练如LRCN为代表的时序模型时难以取得良好的识别效果.而这些算法为缓解这个问题往往使用帧差法消除背景信息的干扰,但与此同时运动区域的动作信息也会被一并删除.
时序模型的根基是以ConvLSTM为代表的递归神经网络.该网络深度和视频长度相关,视频越长网络越深.而递归神经网络中层级之间缺乏联系,在深度增加的同时网络会倾向关注近期输入的信息,而忽视早期信息随着深度的增加逐渐被忽视.因此,这类模型难以对上下文信息建立有效联系.
为了缓解上述的问题,有效提取出视频主体运动的时空特征,减少复杂背景对模型的影响以提高识别准确率同时克服以往模型中上下文相关性不足的问题,本文提出了一种时序边界注意力循环神经网络(Temporal Edge Attention Recurrent Neural Network, TEAR-Net).本文主要贡献可以总结如下:
(1) 本文提出一种全新的视频帧处理模块(Motion Object Enhancement, MOE),MOE可以基于帧间图像差异提取出运动边界,减少背景等因素的干扰,从而有效提高识别精度.
(2) 本文提出一种基于语境化的自注意力机制循环单元(Contextualization and Self-Attention ConvGRU, CSA-ConvGRU)对时序信息进行提取.相较于其他结构,CSA-ConvGRU在参数大小、显存占用和训练速度上更占优势.此外相比于ConvGRU,CSA-ConvGRU对长时中的短时时序特征拥有更强的敏感性,相较于其他方法,本文提出方法在公共数据集上取得了令人满意的效果.
2 网络结构
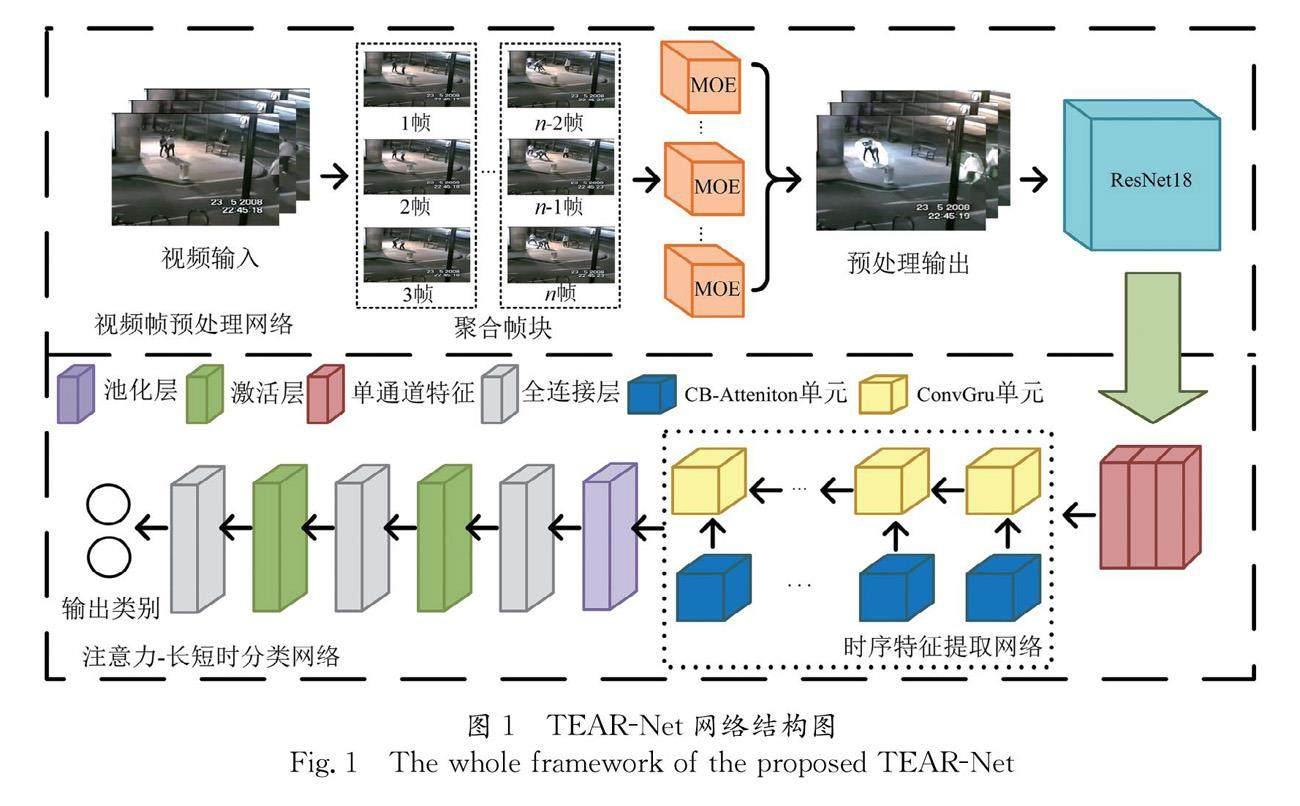
为缓解识别率低,参数量大等问题,本文提出TEAR-Net,整体框架图如图1所示,由三个主要部分组成分别为视频帧预处理模块,卷积特征提取网络和注意力-长短时特征提取网络.MOE为视频帧预处理模块的主要成分,MOE对聚合帧块做一系列的操作提取运动目标,在有效剔除可能造成干扰背景信息的同时保留主要运动目标.卷积特征提取网络使用残差网络 (Residual Network, ResNet)[17]来提取帧图像中的运动特征.在注意力-长短时特征提取网络中,本文提出CSA-ConvGRU,能够有效获取时间序列中的关键特征,使之能够提取更具有鉴别性的时空信息.
为了避免歧义,本文将对一些基本内容进行数学定义.其中,输入为视频V,其中V的维度是V∈RN×T×C×H×W,N,T,C,H和W分别代表批尺寸,帧序列长度,图像通道数以及帧图像的长宽.V由帧图像组成,其中帧图像维度可以被表示为Vt∈RN×C×H×W, t表示视频中的第t帧.δ代表sigmod激活函数,pool代表平均池化层.
2.1 运动目标检测模块
在行为识别中,背景信息往往不是重要特征并且通常会对结果造成极大的干扰.因此,为了去除背景信息加强运动区域,本文提出一种全新的视频帧处理模块(Motion Object Enhancement, MOE)对运动区域进行加强.不同于多流的方法,该方法不需计算额外的光流信息,即可对运动目标进行强化,具有快速,运算算力和硬件设施要求低等优点.
MOE的整体框架图如图2所示,共分为4步.首先,计算聚合帧块中相邻图像间不同通道维度的一阶导数的均方根(Root Mean Square, RMS),第t帧图像的RMS可以被表示为vt,其中vt∈RN×H×W,具体计算过程由式(1)表示.
vt=∑t+1i=t-1∑Cj=1(Vji+1-Vji)22(1)
由式(1)求得图像的RMS后,利用全局平均池化层和激活层对空间信息bt进行进一步提取,其中bt∈RN×1×H×W,计算过程如式(2)所示.通过这种方式,使MOE不仅可以有效提取运动边界,同时还能对提取的运动边界进行平滑与膨胀.
bt=ReLU(pool(vt))(2)
其次,对得到的bt进行归一化处理,并将处理的归一化数据进行掩码提取,从而得到边界清晰的运动区域mt.本文采用的归一化方式是实例归一化(Instance Normalization, IN)[18],IN可以进一步剔除图像的全局信息进而凸显个体差异.具体计算方法如式(3)~(5)所示.
μti=1HW∑Wl=1∑Hm=1xti,lm(3)
σ2ti=1HW∑Wl=1∑Hm=1xti,lm-μti2(4)
yti,jk=xii,jk-μtiσ2ti+ε(5)
然而在式(2)中提取的运动边界仍然存在些许瑕疵,即图像中包含了非主要运动目标的噪声区域.除此之外,运动目标的特征值往往较大,在之后进行处理的过程中会出现亮度失常的情况.因此需要对归一化后的bt的取值范围进行约束,去除不必要噪声并且避免亮度爆炸的问题,这些问题使得在之后对图像特征进行提取的时候,特征质量急剧下降从而导致较低的识别准确率.因此,为了解决上述问题,本文在归一化操作之后引入阈值化操作,得到运动目标掩码图像mt∈RN×1×H×W,i∈RH×W,具体的阈值化过程如式(6)所示.
mti=0, bti<0
0.8, bti≥0(6)
得到掩码mt后,将mt与Vt点乘并与Vt求和组成残差结构得到最后的运动目标强化输出Y(t).MOE中之所以采用残差方式来进行连接,是因为该方式不仅增强动态变化区域,还保留了视频中的场景信息,这使得网络被迫发现和获取差异化信息的时间特征.具体过程如式(7)所示.
Yt=Vt+1+mt⊙Vt+1(7)
其中⊙代表了张量之间的哈玛达积.
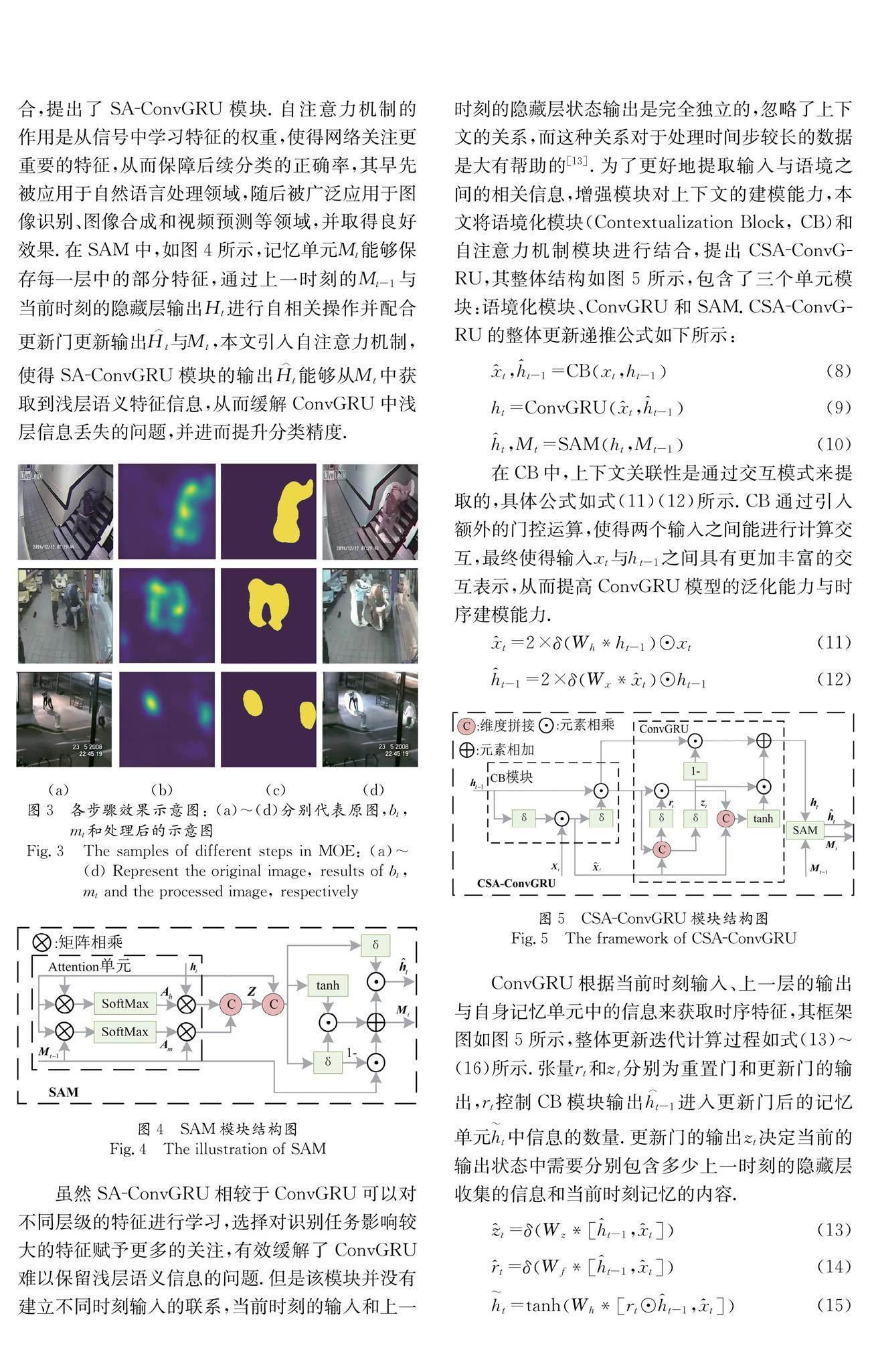
如图3所示,模块输出Y(t)∈RN×3×H×W将应该被予以关注的运动物体对应的图像区域进行凸显.
2.2 时序特征提取网络
ConvGRU在保持参数量较少的同时,可以对时序信息进行有效提取,被广泛用于动作识别任务.然而,随着网络深度的增加,浅层ConvGRU模块通过帧图像提取的隐藏层特征会随着级联层数的增加而逐渐被更新,在此过程中大部分浅层特征信息会丢失,但在动作识别领域中,浅层语义信息往往包含重要的信息,因此仅使用ConvGRU的识别网络无法达到令人满意的效果[16].为了缓解这个问题,本文将自注意力机制与ConvGRU相结合,提出了SA-ConvGRU模块.自注意力机制的作用是从信号中学习特征的权重,使得网络关注更重要的特征,从而保障后续分类的正确率,其早先被应用于自然语言处理领域,随后被广泛应用于图像识别、图像合成和视频预测等领域,并取得良好效果.在SAM中,如图4所示,记忆单元Mt能够保存每一层中的部分特征,通过上一时刻的Mt-1与当前时刻的隐藏层输出Ht进行自相关操作并配合更新门更新输出H︿t与Mt,本文引入自注意力机制,使得SA-ConvGRU模块的输出H︿t能够从Mt中获取到浅层语义特征信息,从而缓解ConvGRU中浅层信息丢失的问题,并进而提升分类精度.
虽然SA-ConvGRU相较于ConvGRU可以对不同层级的特征进行学习,选择对识别任务影响较大的特征赋予更多的关注,有效缓解了ConvGRU难以保留浅层语义信息的问题.但是该模块并没有建立不同时刻输入的联系,当前时刻的输入和上一时刻的隐藏层状态输出是完全独立的,忽略了上下文的关系,而这种关系对于处理时间步较长的数据是大有帮助的[13].为了更好地提取输入与语境之间的相关信息,增强模块对上下文的建模能力,本文将语境化模块(Contextualization Block, CB)和自注意力机制模块进行结合,提出CSA-ConvGRU,其整体结构如图5所示,包含了三个单元模块:语境化模块、ConvGRU和SAM.CSA-ConvGRU的整体更新递推公式如下所示:
x^t,h^t-1=CBxt,ht-1(8)
ht=ConvGRUx^t,h^t-1(9)
h^t,Mt=SAMht,Mt-1(10)
在CB中,上下文关联性是通过交互模式来提取的,具体公式如式(11)(12)所示.CB通过引入额外的门控运算,使得两个输入之间能进行计算交互,最终使得输入xt与ht-1之间具有更加丰富的交互表示,从而提高ConvGRU模型的泛化能力与时序建模能力.
x^t=2×δWh*ht-1⊙xt(11)
h^t-1=2×δWx*x^t⊙ht-1(12)
ConvGRU根据当前时刻输入、上一层的输出与自身记忆单元中的信息来获取时序特征,其框架图如图5所示,整体更新迭代计算过程如式(13)~(16)所示.张量rt和zt分别为重置门和更新门的输出,rt控制CB模块输出h︿t-1进入更新门后的记忆单元ht中信息的数量.更新门的输出zt决定当前的输出状态中需要分别包含多少上一时刻的隐藏层收集的信息和当前时刻记忆的内容.
z^t=δWz*h^t-1,x^t(13)
r^t=δWf*h^t-1,x^t(14)
h~t=tanhWh*rt⊙h^t-1,x^t(15)
ht=1-zt⊙h^t-1+zt⊙h~t(16)
SAM通过引入Attention单元,使得输出的当前时刻的隐藏状态h︿t包含了当前的全局时空信息.整个单元的结构图如图4所示,相关公式如式(17)~(23)所示.使用两个注意力模块将两个输入分别提取出其中的重要特征后进行拼接得到聚合特征Z.使用门控机制求得更新门门值it与更新值gt,通过这两个值即能自适应的更新记忆单元Mt与最后的输出h︿t.
Ah=SoftMaxhTtWThqWThkht(17)
Am=SoftMaxMTt-1WThqWTmkMt-1(18)
Z=Wz*Whv*htAh,Wmv*Mt-1Am(19)
it=δWmi*Z,ht(20)
gt=tanhWmg*Z,ht(21)
Mt=1-it⊙Mt-1+it⊙gt(22)
h^t=δWmo*Z,ht⊙Mt(23)
3 实验结果与分析
为了验证本文提出的暴力检测框架的有效性,本文使用两个最新的数据集RWF-2000[19]和Real Life Violence Situations(RLVS)[20]进行多次实验.实验环境如下所示:Intel Xeon E3-1231 v3 CPU,Nvidia Geforce GTX1080 GPU,Ubuntu 20.04,PyTorch 1.9.0架构.
3.1 实验数据集
RWF-2000数据集包含从YouTube收集的2000个经过剪辑的监控视频.训练集包括1600个视频,测试集包括400个视频.该数据集中的视频片段全部由实际场景中的安防摄像头获取,所以视频具有场景丰富、人数众多和光照复杂等特点,是目前最具挑战性的暴力行为识别的数据集之一.
RLVS数据集由YouTube收集的监控视频和人为拍摄的共计2000个视频经过剪辑组成.训练集包括1600个视频,测试集包括400个视频.其中的暴力行为视频是在监狱、街道和学校等环境中拍摄的,而非暴力行为视频是在运动场和竞技场等环境中拍摄的,包括游泳、射箭及打篮球等项目.
3.2 相关参数设置
预处理:首先将数据集中的视频样本进行逐帧切割,每一个视频段中包含38帧寸为224×224的帧图像.对于训练数据而言,首先将输入的视频帧的尺寸扩展到256×256像素大小,随后按照50%的概率对图像进行随机翻转,然后在图像4个顶角和中心的5个位置上随机剪裁224×224的像素格.最后使用ImageNet数据集中的均值与归一化系数进行标准化操作.
相关参数设置:从预处理完后的视频段以等差间隔的方式抽取30个视频帧作为网络输入.在训练过程中使用在ImageNet数据集上预训练的ResNet18模型提取视频帧图像特征,使用Adam优化器和交叉熵损失函数对网络进行优化,优化器中参数设置为:第一次估计的指数衰减率β1=0.5;第二次估计的指数衰次减率β2=0.99、权重衰减L2=5×e-4.初始学习率被设置为1×10-4,学习率衰减使用余弦退火衰减方法,其中余弦函数周期Tmax设置为64,总共迭代轮次被设置为150.
3.3 CNN主干网络探索实验
在RWF-2000数据集上,保证网络另外两个模块不变的情况下使用三种主流神经网络模型进行测试,分别为AlexNet[21],VGG[22]和ResNet.实验结果如表1所示.
通过实验结果不难发现,尽管在视频帧预处理网络中采用了MOE对运动边界进行了增强,但是通过分析数据集视频不难得知真实场景下的暴力冲突图像场景往往十分复杂.由于AlexNet深度过浅并不能有效地提取出其中的特征信息,导致识别准确度不高.而Vgg网络虽然有着足够的深度能够提取出深层抽象特征,但是Vgg16的模型大小已经增加到25.45 M,并且模型训练时间较长收敛缓慢.考虑到模型大小和识别精度,本文采用ResNet18来提取帧图像中的运动特征信息.残差结构可以有效避免梯度消失,同时在保证模型参数轻量的情况下拥有足够的网络深度提取出单帧图像运动特征
3.4 消融实验
为了验证本文提出的MOE和CSA-ConvGRU 结构在暴力行为检测中的有效性和泛化性,在相同的实验条件下,我们在RWF-2000数据集上对这两个模块的所有组合进行了消融实验.从显存占用情况、模型大小和识别准确率三个方面进行对比,其中显存占用大小是在batch size为1的条件下检测,实验结果如表2所示,组合模型的训练和测试准确度的变化情况如图6a~6c所示.
一方面,由于MOE使用了连续三帧的信息并进行了一系列的归一化和阈值化操作,所以相较于将两帧之差作为运动特征的帧差法能够包含更精确和丰富的人体运动信息,从而在不引入额外参数的情况下有效地提高识别精度.从表2中可以发现MOE相比于简单的帧差法在模型大小和显存占用上并没有明显的增加,但是识别准确上升了2.25%.这也说明本文所提出的MOE能在不增加模型大小以及运算复杂度的基础上显著的提升识别精度.从图6a和图6c中可以看出添加了MOE的网络在训练过程中收敛速度更快.这也从侧面说明了MOE能够有效地提取出人体运动边界从而加快训练速度.
另一方面,添加了CB模块和SAM的CSA-ConvGRU结构相比于ConvLSTM结构能够获得更多的上下文特征信息,并且更加关注视频段中发生暴力冲突的片段,从而拥有了更多的关键且丰富的特征信息.如表2所示,CSA-ConvGRU模型大小与占用显存几乎与ConvLSTM持平,但是识别准确率大约提升了2.75%.图6b和图6c显示出新的结构在每次测试时均拥有更高的准确度.二者都说明了CSA-ConvGRU结构的优越性与泛化性.
3.5 与其他主流检测方法对比
为了进一步验证本文提出的模型的性能,我们分别在公开的暴力行为数据集RWF-2000和RLVS上进行训练和测试.数据集的稀缺极大程度阻碍了暴力检测的相关研究.为了全面评估本文提出模型的识别能力,本节将所对比的方法分为两类,分别是最新提出的暴力行为检测方法和近年来提出的先进的通用动作识别方法.其中,暴力行为检测方法包括Inception-Resnet-V2+DI[23]、Flow Gated[19]、SPIL[24]、X3D XS[25]、ECA-two cascade TSM[26]、SepConvLSTM-M[27]、SAM-GhostNet-ConvLSTM[6]和ViolenceNet OF[28].而通用动作识别方法包含C3D[8]、P3D[9]、TEA[29]、R(2+1)D[10]以及LRCN[12],所有方法的识别准确率在表3进行展示.
SAM-GhostNet-ConvLSTM是基于LRCN的改进模型,二者均使用了与本文模型类似的循环卷积神经网络.LRCN方法在RWF-2000上的效果并不理想,主要原因是该网络没有对各帧图像进行处理而是直接将其送入网络中并仅采用简单的LSTM提取时序特征,故时空特征中混入了大量的干扰信息,从而导致识别的准确率较低.SAM-GhostNet-ConvLSTM模型使用普通的帧差法对运动特征进行提取从而去除了无用的背景干扰,缓解LRCN中引入过多背景信息的问题.但是由于帧差法在复杂背景下的提取效果并不令人满意,同时ConvLSTM模块存在浅层语义信息丢失和无法利用上下文信息的问题,导致最后的识别准确率仍然无法令人满意.相较于上述两种方法,本文提出的MOE能够加强视频帧的运动特征,使CNN能够更加有效地对运动主体的特征进行提取,并且CSA-ConvGRU单元可以更加有效地提取全局特征,可以缓解上述两种方法中存在的问题.从结果来看,得益于MOE和CSA-ConvGRU单元有效建立不同帧间联系并自动化地对不同层级特征进行关注,所提出的模型得到了显著的效果提升,在两个公开的暴力行为检测数据集上均取得了最好的识别效果.
4 结 论
本文提出了一种时序边界注意力循环神经网络(TEAR-Net).该方法可以有效解决运动人体特征提取不足的难题,同时还使用具有语境化和注意力机制的CSA-ConvGRU结构进一步增加模型对于输入信息的上下文和全局特征的提取.所提出的TEAR-Net在RWF-2000和RLVS两个基于真实场景下所收集的公开数据集上的识别精度可以达到90.50%和97.75%.实验结果表明,相比于目前的暴力行为识别方法,TEAR-Net具有更高的识别率,能够适应监控场景下的暴力行为检测任务.
参考文献:
[1] Thys S, Van Ranst W, Goedemé T. Fooling automated surveillance cameras: adversarial patches to attack person detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach, CA, USA: IEEE, 2019.
[2] Vuran M C, AkanB, Akyildiz I F. Spatio-temporal correlation: theory and applications for wireless sensor networks [J].Comput Netw, 2004, 45: 245.
[3] Wang H, Klser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition [J]. Int J Comput Vis, 2013, 103: 60.
[4] 池涛, 王洋, 陈明.多层局部感知卷积神经网络的高光谱图像分类[J]. 四川大学学报: 自然科学版,2020, 57: 103.
[5] 李頔, 王艳, 马宗庆, 等.基于DenseASPP模型的超声图像分割[J]. 四川大学学报: 自然科学版,2020, 57: 741.
[6] Liang Q, Li Y, Yang K, et al. Long-term recurrent convolutional network violent behaviour recognition with attention mechanism [C]//MATEC Web of Conferences. Sanya, China:EDP Sciences, 2021, 336: 05013.
[7] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[J]. Adv Condens Matter Phys, 2014, 27: 1.
[8] Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015.
[9] Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3d residual networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017.
[10] Tran D,Wang H, Torresani L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018.
[11] Hochreiter S, Schmidhuber J. Long short-term memory [J].Neural Comput, 1997, 9: 1735.
[12] Donahue J, Anne Hendricks L, Guadarrama S, et al. Long-term recurrent convolutional networks for visual recognition and description [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015.
[13] Melis G, Koisk T, Blunsom P. Mogrifier LSTM[EB/OL].[2022-01-03].https://arxiv.org/abs/1909.01792.
[14] Cho K, van Merrinboer B, Gulehre , et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014.
[15] Shi X, Chen Z, Wang H, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[C]//Advances In Neural Information Processing Systems. Montréal, CANADA: MIT Press, 2015.
[16] Lin Z, Li M, Zheng Z, et al. Self-attention convlstm for spatiotemporal prediction[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020.
[17] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA: IEEE, 2016.
[18] Ulyanov D,Vedaldi A, Lempitsky V. Instance normalization: the missing ingredient for fast stylization[EB/OL].[2022-01-03].https://arxiv.org/abs/1607.08022.
[19] Cheng M, Cai K, Li M. Rwf-2000: An open large scale video database for violence detection [C]//Proceedings of the 25th International Conference on Pattern Recognition. Milan, Italy: IEEE, 2021.
[20] Soliman M M, Kamal M H, Nashed MAEM, et al. Violence recognition from videos using deep learning techniques [C]//Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems. New York, USA: IEEE, 2019.
[21] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks [J]. Commun ACM, 2017, 60: 84.
[22] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL].[2022-01-23].https://arxiv.org/abs/1409.1556.
[23] Jain A, Vishwakarma D K. Deep NeuralNet for violence detection using motion features from dynamic images[C]//Proceedings of the Third International Conference on Smart Systems and Inventive Technology. Tirunelveli, India: IEEE, 2020.
[24] Su Y, Lin G, Zhu J, et al. Human interaction learning on 3D skeleton point clouds for video violence recognition [C]//Proceedings of the European Conference on Computer Vision. Glasgow, UK: Springer, 2020.
[25] Santos F, Dures D, Marcondes F S, et al. Efficient violence detection using transfer learning [C]//Proceedings of the Practical Applications of Agents and Multi-Agent Systems. Salamanca, Spain: Spinger, 2021.
[26] Liang Q, Li Y, Chen B, et al. Violence behavior recognition of two-cascade temporal shift module with attention mechanism [J]. J Electron Imag, 2021, 30: 043009.
[27] Islam Z, Rukonuzzaman M, Ahmed R, et al. Efficient two-stream network for violence detection using separable convolutional LSTM [C]//International Joint Conference on Neural Networks. Shenzhen, China: IEEE, 2021.
[28] Rendón-Segador F J, lvarez-García J A, Enríquez F, et al. ViolenceNet: dense multi-head self-attention with bidirectional convolutional LSTM for detecting violence [J].Electronics, 2021, 10: 1601.
[29] Li Y, Ji B, Shi X, et al. Tea: Temporal excitation and aggregation for action recognition [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, Washington, USA: IEEE, 2020.
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年19期)2019-11-23 08:42:00
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
电子制作(2016年15期)2017-01-15 13:39:08
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
