
一种基于双流网络的行为识别方法
2023-04-29 05:56齐妙徐慧李森张宇孙慧
吉林大学学报(理学版) 2023年2期
关键词:卷积神经网络
齐妙 徐慧 李森 张宇 孙慧

摘要: 针对视频行为识别任务,提出一种基于双流网络的行为识别方法. 首先,该网络采用稀疏采样的策略,避免相邻帧的冗余信息对识别效果产生影响; 其次,利用卷积神经网络预测光流图,提高光流图的获取效率,并降低计算量; 最后,使用残差网络提取完成的视频信息,同时简化神经网络的训练过程. 为验证双流行为识别网络的有效性,在两个经典数据集上进行对比实验,实验结果表明,该双流行为识别网络识别效果较好,可应用于智能视频监控、 人机交互、 公共安全等领域.
关键词: 行为识别; 卷积神经网络; 双流网络; 稀疏采样
中图分类号: TP391.41 文献标志码: A 文章編号: 1671-5489(2023)02-0347-06
An Action Recognition Method Based on Two-Stream Network
QI Miao1,2,XU Hui1,LI Sen1,ZHANG Yu1,SUN Hui2
(1. College of Information Science and Technology,Northeast Normal University,Changchun 130117,China;
2. Institute of Technology,Changchun Humanities and Sciences College,Changchun 130117,China)
Abstract: Aiming at the task of video action recognition,we proposed an action recognition method based on two-stream network. Firstly,
a sparse sampling strategy was adopted to avoid the redundant information of adjacent frames from affecting the recognition effect. Secondly,the convolutional neur
al network was used to predict the optical flow map, improve the acquisition efficiency of the optical flow map and reduce the amount of calculation. Finally,the
residual network was used to extract the completed video information and simplify the training process of neural networks simultaneously. In order
to verify the effectiveness of the two-stream action recognition network,we carried out comparative experiments on two classical data sets. The
experimental results show that the proposed two-stream action recognition network has good recognition effect and can be applied to intelligent video surveillance,
human-computer interaction,public security and other fields.
Keywords: action recognition; convolutional neural network; two-stream network; sparse sampling
收稿日期: 2022-01-18.
第一作者简介: 齐 妙(1981—),女,满族,博士,副教授,从事机器视觉的研究,E-mail: qim
801@nenu.edu.cn. 通信作者简介: 孙 慧(1979—),女,汉族,硕士,教授,从事模式识别的研究,E-mail: 289368876@qq.com.
基金项目: 国家自然科学基金青年科学基金(批准号: 61907007)和吉林省科技厅工业领域项目(批准号: 20200401086GX; 20200401081GX).
卷积神经网络是深度学习的模型之一,在人工智能领域广泛应用,其可完全自动地逐层提取图像中的高阶特征,计算预测值与真实值之间的差距,通过反向传播修改参数,训练网络向更能获取高阶特征的方向优化,该过程完全无需人为参与. 因此,利用卷积神经网络帮助行为识别可提高行为识别的效率,无需手动提取特征,能处理更多的参数. 随着卷积神经网络在数据集ImageNet上取得的成果,卷积神经网络已逐渐被应用到行为识别领域,一些基于经典的行为识别算法包括C3D网络[1]、双流网络[2]和长短期记忆网络[3]的识别算法等. 行为识别任务相比于图像识别任务,需要关联前后帧间的信息,因此行为的时序维度信息对行为识别是十分重要. Simonyan等[2]提出了双流卷积神经网络用于行为识别,不仅提高了行为识别任务的精度,而且定义了一个新的、 高效的行为识别框架,可采用双流结构分别处理行为的空间信息和时序信息[3]. Feichtenhofer等[4]提出了融合的双流卷积神经网络,尝试多种融合方法并在不同的层对空间信息与时序信息进行融合实验,使空间信息与时序信息在最终层之前融合. Carreira等[5]提出了I3D卷积神经网络,将原始的双流卷积神经网络结构中的2D卷积扩展为3D卷积.
但现有的多数双流网络的空间信息均来自视频的单帧图像,时域信息来自短时间内的帧间光流. 因此,缺乏对长期信息的学习,并且在提取光流图时,存在计算量大、 耗时长的缺点. 为克服上述问题,本文提出一种新的双流行为识别网络. 在获取空间信息上,采用稀疏采样的方法,使获得的视频信息更全面,并保留了视频信息的完整性; 在获取时间信息上,使用FlowNet[6]提取光流,在一定程度上可减少空间的复杂度,通过卷积神经网络预测的方式减少光流图提取的时间,同时可减少背景因素的干扰. 最后,利用支持向量机(support vector machine,SVM)融合时间和空间信息进行行为识别.
1 双流网络结构设计
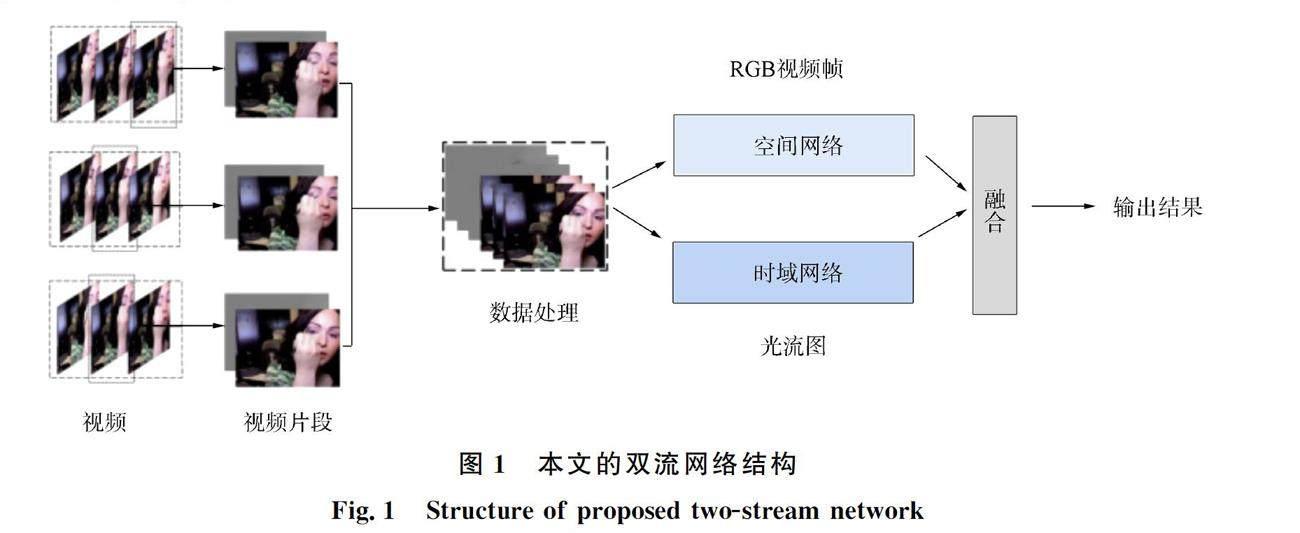
为提高双流网络的识别精度,本文对传统双流网络进行改进,设计一种新的双流行为识别网络. 双流网络的结构如图1所示. 由图1可见,在视频图像序列输入的过程中,首先采用稀疏采样的方法,将视频分成3个部分,并从每个片段中随机选择一帧RGB图像帧; 然后每个片段将使用FlowNet方法提取到的视频光流图像作为时域网络的输入,再将RGB帧和光流图输入到ResNet101网络中进行特征提取; 最后,对空间网络和时域网络两个分支利用SVM方法进行融合. 这样设计网络的优点如下: 1) 使双流网络获得更完整的视频信息; 2) 提高光流图的获取效率; 3) 保证视频信息的完整性,提高网络的识别准确度.
1.1 空间网络
单个RGB图像通常在特定时间点呈静态,并且缺少有关前一帧和后一帧的上下文信息,因此本文采用稀疏采样的方式,提取整段视频的特征信息,以获得更全面的信息,提高网络识别率. 首先,将视频分成k个部分并在视频分割后随机采样一些帧将其作为输入,应用于空间流分支的卷积神经网络; 然后融合来自每个采样段的信息,以获得完整的视频预测结果.
1.2 时域网络
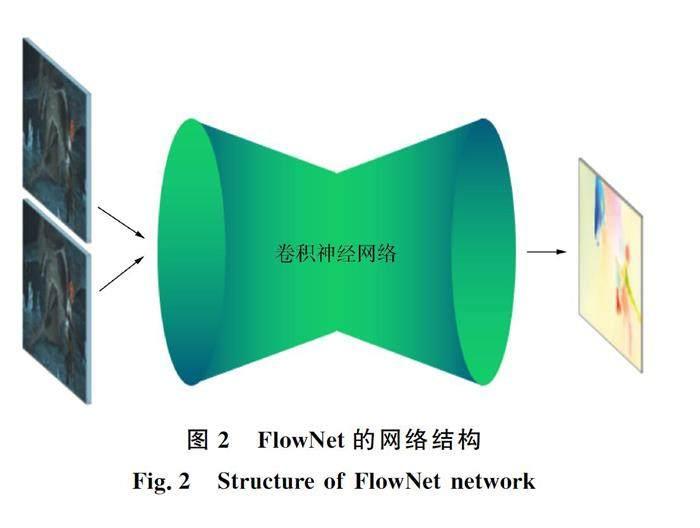
光流是用相邻帧之间的相关性和图像序列中像素的时间变化,通过查找前一帧和当前帧之间的对应关系计算相邻帧之间关系的一种物体运动信息方法. 随着深度神经网络技术在计算机视觉领域的成功应用,越来越多的研究人员开始尝试用深度学习技术预测光流图. FlowNet[6]将光流图预测问题视为可监督学习问题,其计算速度与其他提取光流方法的速度相比有较大提高,因此本文使用FlowNet方法提取光流图. 该网络输入两个RGB图像帧,先输入到收缩网络,再经过放大网络,输出的则是预测出的光流图. FlowNet结构如图2所示.
收缩部分由多个卷积层构成,视频帧通过收缩部分提取特征图,但会缩小图像,因此需要通过扩展层将其扩展到原始图像大小,以进行光流预测. 所以提取到的特征图最后再通过放大网络,将特征图扩展到原始图像大小,整个网络结构类似于全卷积网络由卷积层和反卷积层构成. 放大部分主要由逆卷积层组成,而逆卷积层又由逆池化层和一个卷积层组成. 对特征图执行逆卷积操作,并把它与之前收缩部分对应的特征图以及一个上采样的光流预测连接起来. 在解码过程中,不仅输入缩放网络的输出,同时还输入预测的光流图和对应的特征图. 这样可以获得深层的抽象信息,使获得的特征信息更丰富. 通过逆卷积操作,最终得到预测的光流图,如图3所示.
1.3 双流网络的融合
为有效地学习到多帧图像之间的静态特征以及光流图像的运动特征,本文在双流网络结构中对空间分支和时间分支进行融合,由如图4所示的双流网络结构可见,两支网络均使用ResNet101网络,输入的数据分别通过多个卷积层进行特征提取,两支网络都有Softmax层,最后将各自Softmax层的分数输出,使用SVM分类器进行融合得到最终的分类结果. SVM是一种常见的二分类模型,SVM分类模型的输入是两支网络Softmax层的分类值,输出是最终的动作识别结果. 使用SVM对空间网络和时域网络的分类结果融合,能进一步提升人体行为识别的精度.
2 实验结果与分析
使用两个标准的数据集UCF101(university of central Florida)[7]和HMDB51(human motion database)[8]验证本文方法的有效性. 数据集UCF101包括101种动作类型,每种动作类型包含25个组,每组有4~7个视频. 数据集HMDB51包含51种动作类型,共6 849个视频,每个动作至少包含51个分辨率为320×240的视频.
2.1 实验设置
实验配置为: CPU的型号是Intel Core i7-9700K,GPU的型號是NVIDIA GeForce GTX1080. 深度学习的操作系统为Windows10,Pytorch为深度学习的训练框架,使用CUDA8.0和Cudnn7.0.5的版本,编译器是Pycharm.
在实验过程中,采用ResNet101网络模型构建本文的双流网络. 表1列出了ResNet101网络结构,其中不同的行表示不同的卷积层,括号表示残差单元,括号中的数字,例如(1×1,64),分别表示卷积核的宽度、 高度和特征图的数量.
2.2 实验结果分析
1) 为验证双流网络中各分支的有效性,本文进行了消融实验,识别结果列于表2.
由表2可见:
① 本文提出的双流网络对数据集UCF101和HMDB51的识别准确率分别为90.6%和64.1%,表明本文提出的两个空间分支结构都有意义,因为其均可有效捕获外观特性和相邻帧之间的关系;② 相比于只采用单一分支的模型,时空网络的结合可极大提高动作识别的准确性,如空间网络和时域网络在数据集UCF101上分别获得了86.7%和87.1%的识别准确率,但当使用双流网络后,在数据集UCF101上获得90.6%的识别准确率,相比于仅采用单一分支进行识别准确率分别提高了3.9%和3.5%;③ 时域网络比空间网络的识别效果更好,表明运动信息对动作识别更重要;④ 使用SVM融合方法高于使用平均融合方法的准确率.
2) 本文將提出的双流网络与一些先进的视频动作识别方法进行对比,结果表明,本文提出的双流网络可获得更好的性能. 这是因为采用稀疏采样的方法获取空间信息使得网络获取视频的信息更丰富,同时使用卷积神经网络预测光流图的方法更准确快捷,从而在一定程度上提高了双流网络的识别效果. 因此,本文双流网络可确保同时提取到视频中的外观特征和运动特征,而且可捕获到连续帧的关系信息. 表3列出了本文方法与其他行为识别网络方法精度的对比实验结果. 由表3可见,本文方法在数据集UCF101上的识别效果均优于其他方法,而在数据集HMDB51上的效果低于Two-Stream+LSTM[3]方法和Dynamic ImageNets+IDT[9]方法,这是因为FlowNet在处理位移较小的动作时,预测效果会降低,导致时域网络的识别效果降低,而HMDB51数据存在一些位移较小的动作,因此导致最终的双流网络识别效果低于上述两种方法. 但IDT的性能仍然非常有竞争力,许多深度学习方法也与IDT相结合以实现更高的准确性,而表现较好的行为识别方法都是基于深度卷积神经网络的算法. 本文算法与原始双流网络以及其他行为识别方法相比,准确性有极大提高,同时本文的网络结构更符合端到端的设计. 在真实测试中,需要手工设计特征和处理数据的步骤相对较少. 与基于双流模型的其他算法相比,借助稀疏采样的方法可有效获取视频的长期信息,当前的网络融合方法仍然是初级的,但与其他双流算法相比效果更好.
3) 本文还与轻量化模型[15-16]和自监督模型进行了性能比较[17-18]. DMC-Net[15]是一个轻量级的生成器网络,其减少了运动向量中的噪声,并捕获了精细的运动细节,生成的运动线索更具鉴别性. DistInit[16]提出了一种图像到视频的蒸馏框架,利用训练好的图片模型迁移知识到视频模型中,将其作为初始化提升识别效果,其教师模块可利用丰富注释的图像数据集中编码的关于对象、 场景和潜在的其他语义(如属性、 姿势)的大量知识. 由表3可见,轻量化模型在识别精度上低于本文和非轻量化模型,但在数据集UCF101上展现了比本文更高的精度. 文献[17]提出了一种新的鲁棒的人体动作识别特征描述符,该描述符涉及多个特征并具有多样性的特点,但该方法在HMDB51上的精度低于本文方法约10%; 文献[18]提出了从视频和音频中学习视听表示的一种自监督学习方法,该研究表明,优化跨模态辨别对于从视频和音频中学习良好的表示很重要,在对动作识别任务进行微调时获得了极具竞争力的性能.
综上所述,针对视频行为识别任务,本文提出了一种基于双流网络的行为识别方法. 首先对视频进行稀疏采样,以获得更全面的视频特征信息; 然后使用FlowNet方法更准确、 快速地获取光流图,同时在网络结构中采用了ResNet101网络,加快了收敛训练的过程. 实验结果验证了本文方法的有效性和优越性.
参考文献
[1] TRAN D,BOURDEV L,FERGUS R,et al. Learning Spa
tiotemporal Features with 3D Cnvolutional Networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE,2015: 4489-4497.
[2] SIMONYAN K,ZISSERMAN A. Two-Stream Convolutional Network
s for Action Recognition in Videos [EB/OL]. (2014-11-12)[2021-11-01]. https://arxiv.org/abs/1406.2199.
[3] GAMMULLE H,DENMAN S,SRIDHARAN S,et al. Two Stream LST
M: A Deep Fusion Framework for Human Action Recognition [C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE,2017: 177-186.
[4] FEICHTENHOFER C,PINZ A,ZISSERMAN A. Convolutional Two
-Stream Network Fusion for Video Action Recognition [C]//Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2016: 1933-1947.
[5] CARREIRA J,ZISSERMAN A,QUO V. Action Recognition? A New Model and the Kinetics Dataset [C]//Proceedings of IEEE Conference on Co
mputer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2017: 6299-6308.
[6] ILG E,MAYER N,SAIKIA T,et al. Flownet 2.0: Evolution of Optical Flow Es
timation with Deep Networks [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2017: 2462-2470.
[7] SOOMRO K,ZAMIR A R,SHAH M. UCF101: A Dataset of 10
1 Human Action Classes from Videos in the Wild [EB/OL]. (2012-12-03)[2021-11-05]. https://arxiv.org/abs/1212.0402.
[8] KUEHNE H,JHUANG H,GARROTE E,et al. HMDB: A Large Vide
o Database for Human Motion Recognition [C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE,2011: 2556-2563.
[9] BILEN H,FERNANDO B,GAVVES E,et al. Dynamic Image
Networks for Action Recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2016: 3034-3042.
[10] DONAHUE J,HENDRICKS L A,GUADARRAMA S,et al. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description [C
]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2015: 2625-2634.
[11] CAI Z W,WANG L M,PENG X J,et al. Multi-view Super
Vector for Action Recognition [C]//ProceedinSgs of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2014: 596-603.
[12] JI S W,XU W,YANG M,et al. 3D Convolutional Neural Netwo
rks for Human Action Recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2012(35): 221-231.
[13] PENG X J,WANG L M,WANG X X,et al. Bag of Visual Words and
Fusion Methods for Action Recognition: Comprehensive Study and Good Practice [J]. Computer Vision & Image Understanding,2016,150(9): 109-125.
[14] QIU Z F,YAO T,MEI T. Learning Spatio-Temporal Representation with Pseudo-3d
Residual Networks [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2017: 5533-5541.
[15] SHOU Z,LIN X D,KALANTIDIS Y,et al. DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition [
C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2019: 1268-1277.
[16] GIRDHAR R,TRAN D,TORRESANI L,et al. DistInit: Learni
ng Video Representations without a Single Labeled Video [C]//IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE,2019: 852-861.
[17] PATEL C I,LABANA D,PANDYA S,et al. Histogram of
Oriented Gradient-Based Fusion of Features for Human Action Recognition in Action Video Sequences [J]. Sensors,2020,20(24): 7299-1-7299-32.
[18] MORGADO P,VASCONCELOS N,MISRA I. Audio-Visual Instance
Discrimination with Cross-Modal Agreement [C]//Proceedings of the IEEE Confe
rence on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE,2021: 12475-12486.
(責任编辑: 韩 啸)
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22
电脑知识与技术(2016年33期)2017-03-21
科技创新与应用(2017年5期)2017-03-16
电脑知识与技术(2016年30期)2017-03-06
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件(2016年5期)2016-08-30
电脑知识与技术(2016年10期)2016-06-16
