
基于知识图谱的测井储层推荐算法研究
2023-04-21 13:10尚福华张月霞曹茂俊
计算机技术与发展 2023年4期
尚福华,张月霞,曹茂俊
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
随着计算机技术的飞速发展,计算机深度学习辅助石油勘探开发在石油工程中显得愈加重要,而且随着测井技术的进步和仪器探测设备的升级更新,包括岩性、岩相、储集物性参数[1](孔隙度、渗透率、泥质含量、含油气水饱和度[2]等)和地层压力等可用的测井信息类型和数量剧增,精度不断提高,测井数据的处理解释越来越精细,应用范围也越来越广。在这种形势下,利用大量有用测井和地质信息去探索从而推荐测井储层参数的新方法,将是测井解释技术发展的主要趋势[3]。
测井解释模型在油气评价方面无疑是最基础、最有价值的重要技术,但在实际的测井储层特性中仍然存在着不少解释不准、判断不灵的情况,严重地影响这些地区油气勘探的效率与成功率。常规测井解释在确定某种解释模式之前,需首先建立岩石体积模型,进而确定测井响应方程和统计经验公式[4],包括但孔隙度分析处理解释模型、复杂岩性分析处理解释模型、粘土矿物分析解释模型等。目前常规的测井解释分析程序通常都需要提供数十种预置参数,最优化测井解释程序所需预先提供的参数更多。随着测井技术的进步和仪器探测设备的升级更新,包括岩性、岩相、储集物性参数和地层压力等可用的测井信息越来越丰富。使用正确的解释模型,就可用有关的解释方程把测井信息加工成地质信息进而来辅助判断油气状况。因此,为了避免解释人员由于经验不足与测井解释模型中出现的参数选取不当或差错,并且克服参数选取中可能出现的诸多人为因素,推荐算法在地球物理测井储层参数的预测与推荐中显得尤为重要。其中传统的协同过滤推荐算法[5]以及改进算法,都仅考虑用户少量且单方面的个人偏好,容易忽略用户与其他有效信息的关联关系,例如社交网络或媒体里的信息等,具有较大的局限性,容易出现数据稀疏性和冷启动问题。所以,可在推荐系统中引入知识图谱[6]、神经网络[7]、注意力机制[8]、社交网络等辅助信息来增强测井领域知识上下文的关联性,来解决以上传统推荐算法中存在的两种问题,大大增强了推荐系统的整体性能。其中知识图谱作为一种可解释性非常强的语义网络,可在推荐领域中提供潜在的辅助信息。Gazzotti等人[9]提出一种基于知识图谱的算法来解决患者住院预测问题,通过不同的知识图谱中提取信息来丰富EMR的向量表示,以及利用其中的特征进行自动选择来区分噪声的特征和有利于决策的特征;Kang Yang等人[10]提出基于多模态知识图的推荐系统,在基于用户历史点击视频的基础上,构造相应的多模态知识图,然后利用此推荐系统模型逐层提取该图,最后进行推荐;Ye Qing等人提出了一种基于知识图和推荐系统的药物靶向相互作用预测框架[11](KGE_NFM)。该框架首先学习知识图谱中各种实体的低维表示,然后通过神经因子分解机集成多模态信息,最后进行准确的预测。同时,随着深度学习的发展,为解决数据稀疏性问题,神经网络和注意力机制也逐步引入到了推荐系统中。Chen Ming等人[12]提出基于神经网络的推荐算法(CoNet),它可有效地对协同过滤(CF)中的共现模式进行建模,进而提取出高度描述性的特征,从而获取更好的性能;Liang Zhang等人[13]提出一种集成神经网络的Top-N推荐算法,主要通过对互联网信号中Top-N推荐算法的干扰,达到保护人们隐私的目的。研究结果表明,当信号干扰强度为5,推荐算法为F时,网民的隐私保护效果最好,故集成神经网络的Top-N推荐算法在保护人们隐私方面具有重要的潜在价值。Jin Huang等人[14]提出一种基于注意机制的知识图谱完成的深度嵌入模型,旨在解决一系列的跨模型和语义匹配模型只关注知识图谱的阴影信息中无法捕捉到知识图谱中隐含的细粒度特征,称为方向多维注意卷积模型,该模型探索了方向信息和三元组固有的深层表达特征。
鉴于以上研究,该文将融合注意力机制的知识图谱及知识图谱补全与推荐算法相结合,主要贡献如下:(1)采用面向测井解释操作人员和某地区储层信息构建了测井领域的知识图谱,通过注意力机制强化地区储层信息和知识补全的测井领域知识图谱,充分挖掘储层信息和测井操作人员的低阶与高阶属性,通过知识图谱得到储层信息和测井操作人员的统一表示;(2)融合深度神经网络协同过滤算法(NeuralCF)和加入注意力机制的知识补全算法(TransR)来提取储层信息和测井解释操作人员的潜在特征,并在此基础上为测井操作人员预测和推荐测井领域储层参数信息。
1 算法基本原理
该文提出了一种基于知识图谱的测井储层特性推荐算法:A-KgNc(Attention-Knowledge Graph Network-Collaborative),测井解释人员在进行常规测井处理解释操作(孔隙度分析处理解释模型、复杂岩性分析处理解释模型、粘土矿物分析解释模型)时,根据该算法模型来为其推荐所需要的参数,例如:计算泥质含量时,GCUR(地区经验系数)对第三纪地层为3.7,对老地层是2。
1.1 A-KgNc模型的总体框架
算法模型如下:将构建好的测井领域知识图谱应用到解决测井领域中进行测井解释时的储层参数选取不当或差错的问题中,进而结合注意力机制用于补全并加强测井领域知识图谱中的统一信息,最后通过连接机制将推荐算法与知识图谱两者结合来有效并高精度地给测井解释人员推荐储层参数,对测井操作人员的历史行为以及推荐储层参数结果做出解释,提供相关依据,进而更加准确地判断储层油气状况。
首先,构造测井操作人员与储层信息的交互信息矩阵和已知内容包括的三元组(h,r,t)的测井领域知识图谱G;然后,使用知识补全算法(TransR)以及注意力机制对测井领域知识图谱进行补全,同时搭建神经网络协同过滤推荐算法;最后,通过交叉压缩机制融合测井领域知识图谱与推荐算法来完成测井储层参数的推荐。
模型整体框架如图1所示。

图1 A-KgNc模型框架
1.2 测井领域知识图谱的构建
1.2.1 知识图谱构建算法
首先,构造测井操作人员与储层信息的交互信息矩阵和已知内容包括的三元组(h,r,t)的测井领域知识图谱G,其中h表示头实体:包括测井解释操作人员或测井解释分析程序等;t表示尾实体:包括储层参数数据(孔隙度、渗透率、泥质含量、含油气水饱和度等)、油层数据、结论等;r表示头尾实体的连接关系:包括测井解释人员操作井数据、储层参数数据、地层参数数据等。例如,三元组(测井操作人员,操作,POR解释分析程序)表示测井操作人员操作测井解释分析程序[15]。
在许多推荐方案中,储层特性信息可能相关联于知识图谱中的一个或多个实体,比如:“解释程序”这一实体在知识图谱中就包含多种解释程序类型(孔隙度分析处理解释模型、复杂岩性分析处理解释模型、粘土矿物分析解释模型等)。
本课题构建的知识图谱有多个,包括测井操作人员-类型知识图谱、测井操作人员-储层参数知识图谱、储层参数-油层数据知识图谱等,例如测井操作人员-储层参数知识图谱(22 543条数据)(一位测井操作人员会操作多个地层参数数据)。
其中测井操作人员-储层参数知识图谱如图2所示。
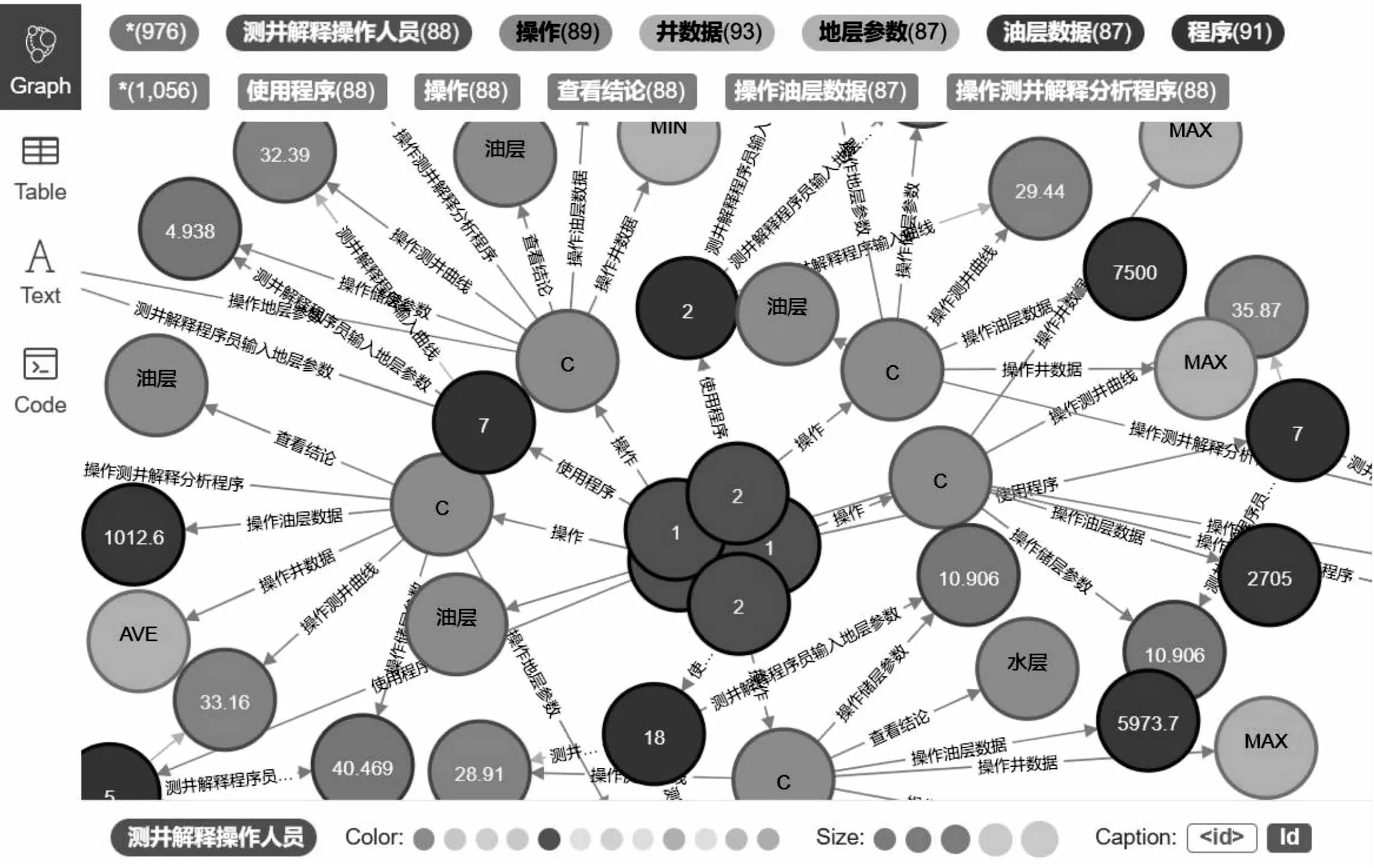
图2 测井操作人员-储层参数知识图谱
然后是储层参数-油层数据知识图谱(26 839条数据)(同一地区储层会分为干层、水层、地产油层、油层等)构建的知识图谱,如图3所示。
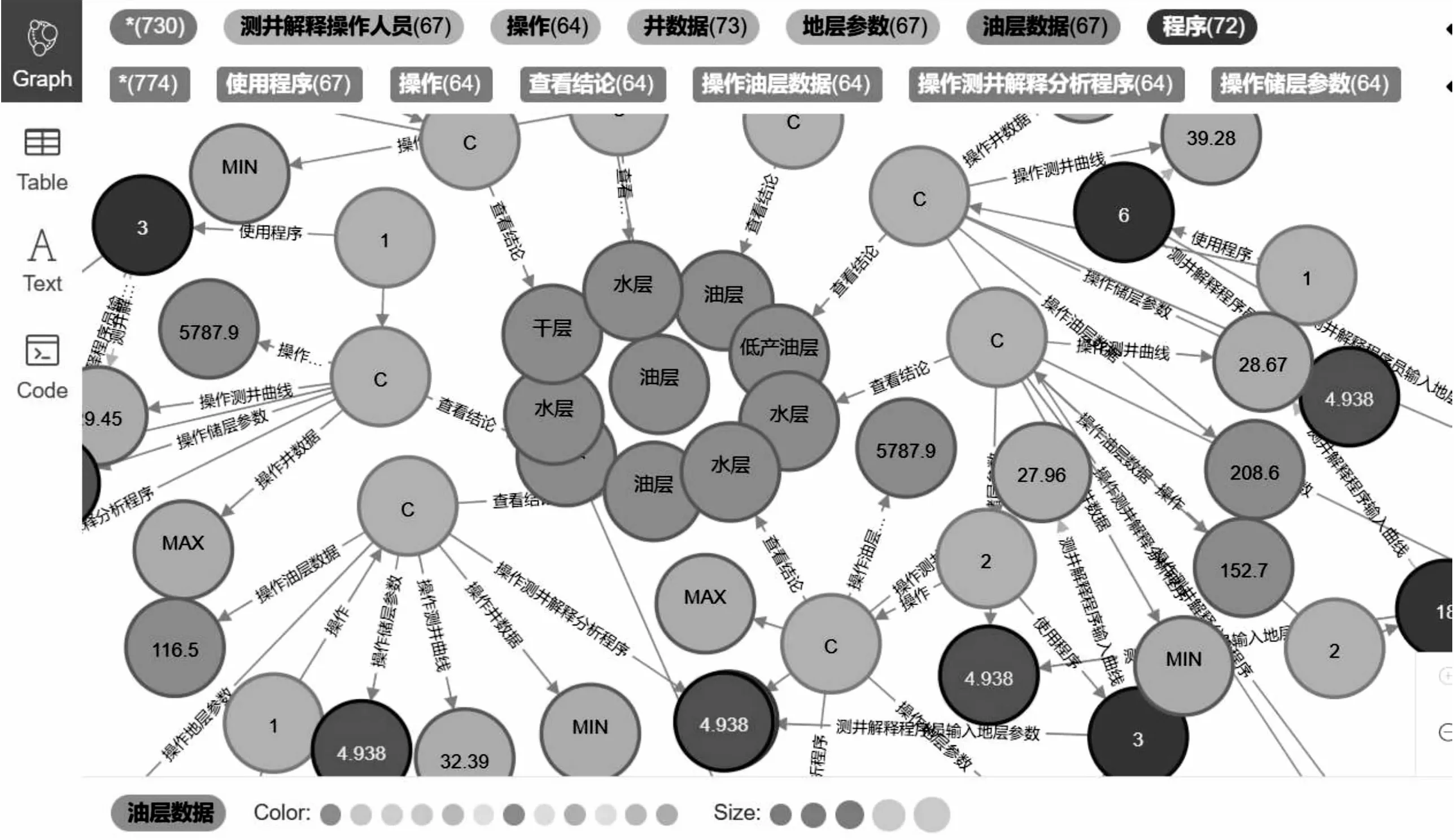
图3 储层参数-油层数据知识图谱
1.2.2 知识图谱补全算法
该文在测井领域储层特性的推荐任务中,将测井领域知识图谱作为辅助信息融入到推荐系统中,现有的大多数知识感知推荐算法都默认知识图谱是完整的,但现实中知识图谱实体间的关系有很多是缺失的,会影响推荐结果的准确性。为丰富测井领域知识图谱,将数据嵌入TransR模型中进行知识图谱补全,如图4所示。

图4 TransR模型
在TransR模型中,分别在测井领域知识图谱中的测井解释操作人员等的实体空间及其相关关系空间中对实体和关系进行建模,进而在关系空间中进行翻译。
其中,三元组(h,r,t)中h、t分别为头实体和尾实体,r为两者关系,即h,t∈Rk。
此模型认为不同的关系有不同的语义空间,h、t根据其关系r通过投影矩阵Mr映射到关系空间中,即h⊥、t⊥表示为:
t⊥=Mrt
(1)
然后,将得分函数定义为:
fTransR(h,r,t)=‖h⊥+r-t⊥‖2
(2)
通过在训练集上最小化基于边际的排序损失学习式(1)和式(2)中的嵌入:
(3)
其中,max(x,y)的目的是获取x和y之间的最大值,Sp∈S+表示测井领域知识图谱中的关系,补全后的知识图谱即为S-:
(4)
1.2.3 注意力机制
为了探索测井解释操作人员及其储层特性信息之间的交互信息,该文提出将注意力机制引入知识图谱中,与TransR算法模型结合,进而根据权重来补全测井领域知识图谱,获取其潜在信息。
注意力机制的模型如图5所示。

图5 注意力机制模型
相应的表达式如式(5)所示:
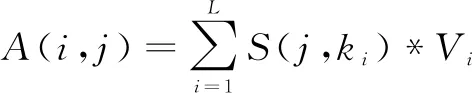
(5)
式中,A(i,j)是测井储层特性中已知地区储层信息j与目标地区储层信息i之间的Attention值,其中S(j,ki)是已知地区储层信息j与目标地区储层信息i对应的相似值,V是目标地区储层信息i的值。
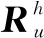
Au=∑S(j,Rim)*Vi
(6)
式中,Rim表示测井解释操作人员-储层特性信息集合,S(j,Rim)表示候选储层特性信息j与测井解释操作人员-储层特性信息集合中的储层信息之间的相似度,Vi表示储层信息i在目标测井解释操作人员-储层项目信息集合中的全值。
1.3 连接机制
为了对测井储层信息和测井操作人员之间的特征交互进行建模,设计了A-KgNc框架中的连接单元,如图6所示。

图6 连接机制
其中,第v项储层信息和关联解释人员e,首先在层l其潜在特征vl∈Rd和el∈Rd里的d×d对进行相互连接:
(7)
其中,Cl∈Rd×d是层l的连接矩阵。在连接特征矩阵中明确建模了解释人员v及其关联解释人员e之间的关系,之后通过把连接特征矩阵投影到其潜在表示空间中,最后输出下一层的测井储层信息和解释人员的特征向量:
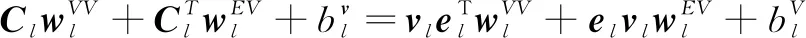
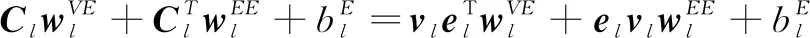
(8)
其中,wl..∈Rd和bl.∈Rd分别是可训练的权重、偏差向量,权重向量将连接特征矩阵从Rd×d空间投影[16]回特征空间Rd。
通过此连接机制,A-KgNc可以自适应地调整相关实体及关系的权重,并知推荐系统和知识图谱这两个任务之间的联系程度。
1.4 推荐算法设计
近年来,深度学习的应用改进了传统的协同过滤算法,大大提高了协同过滤算法的泛化能力和拟合能力,因此A-KgNc中推荐模块使用的是NeuralCF(神经网络协同过滤)算法,其输入由原始特征向量u和v组成,分别描述测井解释操作人员u及其项目v。
该文使用L层建立一个全连接层即嵌入层,与输入层连接,用MLP(多层感知机)提取其潜在的连接特征:
uL=M(M(…M(u)))=ML(u)
(9)
其中,M(x)=σ(Wx+b)是神经网络层,权重W,误差b和非线性激活函数,对于测井储层信息v,使用L个连接单元提取其特征[16]:
vL=Ee~S(v)[CL(v,e)[v]]
(10)
其中,S(v)是测井项目相关实体的集合v。
在获得测井解释操作人员u的潜在特征uL及其项目v的潜在特征vL之后,通过预测函数fR将这两种途径结合起来。为测井解释操作人员u推荐其项目v的储层参数最终预测概率:
(11)
2 实验结果及分析
2.1 矿场资料数据
实验数据来源于大庆油田、新疆油田某工区的三口水平井(Welldatalens)(分别为大庆油田的A、B井和新疆油田的C井),每口水平井均包含十条测井曲线、储层参数数据、地层参数数据、测井解释分析程序、井数据、油层数据、结论数据等,其中测井曲线为电阻率(RT)、密度(DEN)、中子(CNL)、声波时差(HAC)和井径(CAL),分别选取测井曲线662 m~930 m数据段(采样间隔为0.125 m)。测井解释模型选择的是:孔隙度分析处理解释模型、复杂岩性分析处理解释模型、粘土矿物分析解释模型。同时把以上数据构建为测井领域知识图谱:测井操作人员-类型知识图谱、测井操作人员-储层参数知识图谱、储层参数-油层数据知识图谱等来进行实验。
根据以上数据集,其对应的统计数据如表1所示,并且数据集的密度=(测井操作人员-储层参数交互数)/(测井操作人员数-储层数),因此数据集的稀释度=1-数据集密集度。

表1 数据集基本统计
2.2 实验对比模型
(1)NFM。
该模型[17]在传统的FM模型基础上,融合DNN的策略,进而引进特征交叉池化层的结构,使得FM与DNN进行连接,从而不仅吸取了FM的建模低阶特征交互能力,还结合了DNN学习高阶特征交互能力,提高了推荐的准确率。
(2)DIN。
该模型[18]将NLP中机器翻译的Attention机制引入CTR预估模型,即在计算用户兴趣向量的时候,根据候选广告的不同从而动态改变用户兴趣向量的值,大大提高了推荐系统的性能。
(3)KGCN。
该模型在传统的推荐模型中引入了知识图谱,结合图卷积网络的方法来辅助获取用户与物品之间的关系,为其推荐的结果提供了可解释性,提高了推荐系统的准确率[19]。
2.3 实验评价指标
本课题采用以下三个评价指标对模型TOP-10推荐性能进行判断。
准确率指标,对模型最终的TOP-10推荐进行的一个最直接的展示,如式(12)所示:
(12)
以上的准确率表示的是最终推荐列表中的测井操作人员的历史常用的储层参数占整体推荐的储层参数列表的比例。
召回率指标,如式(13)所示:
(13)
此召回率指标是指最终推荐列表的测井操作人员的推荐储层参数占整体测井操作人员历史交互列表的比例。其中,R(o)表示最终给测井操作人员o的储层参数列表,T(o)表示测井操作人员在历史交互列表中展现常用的储层参数集合。
归一化折损累积增益,如式(14)所示:
(14)
其中,DCG是折损累计增益,IDCG是将DCG进行归一化处理之后的指标,reli是候选储层数据与操作人员历史交互记录中储层数据之间的相似度,取值为[0,1],整个指标所表示的是用来衡量整体推荐算法对候选储层数据与操作人员历史交互记录中储层参数信息数据之间的相似度大小的指标。
2.4 实验环境及参数设置
本课题将构建好的测井领域知识图谱,融合注意力机制和TransR补全模型(对测井操作人员交互信息的潜在语义进行辅助与补充及深层次的信息挖掘),嵌入到神经网络协同过滤推荐算法模型中。
鉴于实验结果的可靠性,故需要对测井领域数据集Welldatales做预处理,将其80%用于训练模型,20%用于测试模型,经过多次实验取得平均值。
实验环境的配置如下:Windows10、英特尔-i7-2630QM@2Ghz、Visual Studio Code2020、Neo4j-community_win-dows-x64_3_3_1、python-3.8、sklearn-0.24.1,tensorflow-2.5.0。
其中神经网络部分的参数设置如下:关于NCF神经网络的过滤器数量设置为 64,嵌入维度设置为16,批次处理大小设置为256,权值设置为16,学习率为0.01,TOP-K推荐数为10。
2.5 结果分析
在所有参数默认设置的情况下,将文中算法与现在主流的推荐算法在测井领域数据集Welldatales上进行了相关指标的对比分析,具体数据见表2。

表2 算法对比分析
2.5.1 实验准确性分析
本课题实验结合大庆油田、新疆油田某工区的三口水平井数据的相关性分析结果设计如下实验,在测井操作人员进行操作测井解释模型(孔隙度分析处理解释模型、复杂岩性分析处理解释模型、粘土矿物分析解释模型)时,分别根据大庆两口井(A和B)的储层特征以及测井数据的含油状况来估计新疆未知井(C)的含油情况以推荐操作所需要的参数。
在以上模型默认参数的设置下,在测井数据集Welldatales上,与同类算法分别在三个指标上(召回率Recall、准确率Precision和归一化折损累积增益指标NDGC)进行相关测试,具体实验结果如图7~图9所示。
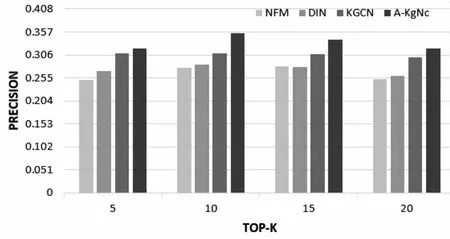
图7 Precision指标对比

图8 Recall指标对比
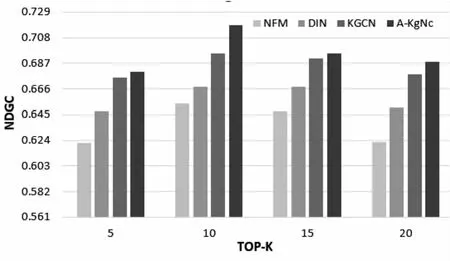
图9 NDGC指标对比
经过上面三个图对比分析可知,在测井领域数据集Welldatales上,所提A-KgNc算法在三个评价指标Precision、Recall和NDGC上均优于其他算法;另外,还可以看出,在K=15时,三个相关性能指标显示最好。
2.5.2 融合注意力机制的知识图谱有效性分析
为了验证本课题模型中融合注意力机制的知识图谱可缓解数据稀疏以及冷启动问题,实验如下:
将A-KgNc与NCF模型(去掉文中算法中融合注意力机制与知识图谱部分得到的)在数据集Welldatales上进行融合注意力机制的知识图谱有效性下的准确率Precision、召回率Recall和归一化折损累积增益指标NDGC的验证,其结果分布如图10~图12所示。
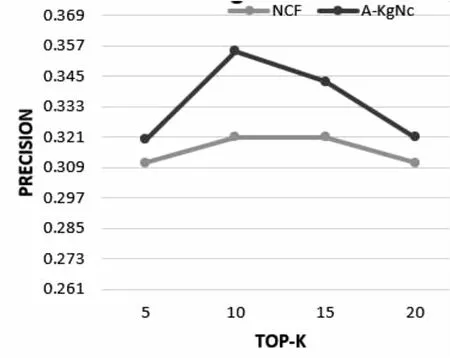
图10 融合注意力机制的知识图谱有效性验证Precision指标分布

图11 融合注意力机制的知识图谱有效性验证Recall指标分布

图12 融合注意力机制的知识图谱有效性验证TOP=K指标分布
经过以上三个指标的折线对比图分布可知,文中算法模型在测井领域数据集Welldatale的实验下,含注意力机制的知识图谱模型的三个指标均优于NCF模型,故可验证融入注意力机制的知识图谱的有效性。
3 结束语
考虑到实际应用中测井解释人员由于经验不足以及测井解释模型所选取的参数不当、差错等,所造成的测井处理解释结果的评价精度不准等问题,在测井储层参数推荐任务上,A-KgNc算法在补全后的测井领域知识图谱中针对测井储层参数预测问题具有很高的准确率,尤其是在加入了注意力机制的情况下,对比同类A-KgNc算法有了更高的准确率,说明了该算法具有较好的预测性能。
对比同类推荐算法的研究结果可知:知识图谱作为一种可解释性非常强的语义网络可在推荐算法领域中提供潜在的辅助信息。该文做了如下补充:(1)对知识图谱做了补全工作,使测井领域知识图谱更加完整;(2)算法中加入了注意力机制,增强了知识图谱与推荐算法的联系,可为测井解释人员提供潜在信息进而更准确的推荐。
A-KgNc算法将加入注意力机制及补全后的知识图谱作为辅助信息,引入到神经网络推荐算法中,其模型复杂度方面没有得到最优处理。因此,下一步工作就是将使用的NCF网络(神经网络协同过滤)换成GCN(图卷积神经网络)网络,并且结合专家经验来更加精确地捕捉储层参数信息,从而提高整体推荐算法性能。
猜你喜欢
测井技术(2022年3期)2022-11-25
小雪花·成长指南(2022年1期)2022-04-09
中国煤层气(2021年5期)2021-03-02
少先队活动(2020年12期)2021-01-14
传媒评论(2017年3期)2017-06-13
中成药(2017年3期)2017-05-17
第二课堂(课外活动版)(2016年2期)2016-10-21
领导科学论坛(2016年9期)2016-06-05
中国煤层气(2015年4期)2015-08-22
中国质量与标准导报(2015年2期)2015-02-28
