
基于多资源协同优化的虚拟机整合方法
2023-04-21 13:25赵雪阳岳延奇王海晨
计算机技术与发展 2023年4期
赵雪阳,岳延奇,王海晨
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
随着数据中心应用业务日渐增长和规模不断扩大,能耗显著增加;同时,云服务提供商需要保证可靠的服务质量(Quality of Service,QoS),否则将受到惩罚[1]。因此,节能和保证服务质量是数据中心亟待解决的问题。
虚拟机整合是解决上述问题的重要方法。该方法利用动态虚拟机迁移来定期合并虚拟机,避免主机过载引起的性能下降、减少低载主机数量从而降低能耗。虚拟机整合的相关研究大多[2-7]将虚拟机整合分解为:过载主机检测、欠载主机检测、虚拟机选择、虚拟机放置。
在数据中心,主机资源的低利用率会浪费资源,而高利用率引起过载,进而影响性能[8]。Beloglazov等[9]提出双静态阈值算法,该算法设置了主机CPU利用率的过载阈值、欠载阈值,根据阈值将主机分为3类。但是,由于云数据中心的主机负载变化的动态特性,基于静态阈值的方法不能很好地适应这种动态的变化。为解决该问题,Buyya等[10]提出了两种稳健的统计估计来调整阈值,即中位数绝对偏差法和四分位距法。Farahnakian等[11]分别使用线性回归和K近邻(K-Nearest Neighbor,KNN)回归算法,根据从虚拟机生命周期中收集的数据来近似函数,从而预测过载、低载物理主机以减少SLA违规和能源的消耗。在虚拟机选择问题上,Jiang等[12]给出了一种包含GPU利用率和CPU利用率两个影响因素的能效评价模型。他们使用基于人工蜂群算法的虚拟机选择算法,选定可以使得能耗降低最多的虚拟机。徐胜超等[13]提出了一种基于皮尔逊系数的虚拟机选择策略,该策略引入了皮尔逊系数,将CPU利用率最高的虚拟机放入到待迁移虚拟机列表。在虚拟机放置阶段,能耗感知最适降序(Power-Aware Best Fit Decreasing,PABFD[9])算法在放置虚拟机时将虚拟机迁移到资源利用率高的主机上,容易导致过度的虚拟机整合,从而影响服务质量。Murtazaev等[14]提出了Sercon算法,该算法继承了首次适应(First Fit,FF)算法和最佳适应(Best Fit,BF)算法的一些属性,以最小化主机数量和迁移次数。
虚拟机整合会受到多种资源的约束,其中多种类型的资源相互关联、约束[15],使得同时保持所有资源类型的高利用率变得困难,可能导致不同资源利用失衡和过载风险。针对该问题,该文提出了基于多资源协同优化的虚拟机整合(Multi-Resource Collaborative Optimization-based Virtual Machine Consolidation,MRCO-VMC)方法。使用基于正态分布的多资源过载检测算法筛选出数据中心的过载主机;利用基于正态分布的最小迁移时间虚拟机选择算法选出过载主机中待迁移的虚拟机;采用基于正态分布的能耗感知最适降序算法将虚拟机从源主机迁移到目的主机;最后,采用贪心策略将运行物理主机数量进行收缩。经仿真实验验证,在虚拟机整合中,该方法有效地减少了迁移次数、减少了能耗并提高了服务质量,取得了较好的结果。
1 虚拟机整合问题描述
1.1 虚拟机放置问题描述

(1)

(2)
此时,虚拟机放置满足公式(3)所示的约束条件,即主机上的全部虚拟机的各类资源需求总量不能超过该主机的相应的各类资源的总量,并且每台虚拟机只能放置到一个物理主机上。
(3)
1.2 基于正态分布的主机负载模型
虚拟机所需资源来源于用户向云数据中心提交的任务请求,这些请求是随机的,这导致虚拟机的资源需求是动态变化的;物理主机的负载是其上虚拟机的所有资源的总和,随着虚拟机需求资源的变化,主机负载也随之变化。由于云数据中心负载的动态特性,很难准确地对物理主机负载进行预测。但有研究表明,虚拟机的资源利用率服从正态分布[16]。因此,该文采用正态分布模型估计虚拟机的资源利用率,计算虚拟机处于资源利用平衡状态的概率。
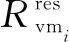
(4)
(5)

(6)

(7)

(8)
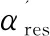
(9)
在虚拟机放置过程中,如何快速高效地识别虚拟机迁移所涉及的源主机和目标主机是首先要解决的关键问题。根据虚拟机资源利用率的历史记录,并且通过公式(7)~公式(9)计算f(hj)的值,如果从一个物理主机迁出虚拟机或向其部署虚拟机后的下一个虚拟机整合周期中f(hj)的值较高,则优先选择该物理主机作为源主机或目标主机,因此f(hj)可以作为一个量化指标来指导待迁移虚拟机的选择和放置。
2 基于多资源协同优化的虚拟机整合
2.1 过载主机检测算法
物理主机过载是导致云数据中心服务质量下降的主要原因之一,在虚拟机整合中预测主机的负载,从而减少避免主机过载的情况,将有利于服务质量的提升。该文提出了一种基于正态分布的多资源过载检测(Normal Distribution-based multi-resource Overload Host Detection,NDOHD)算法来检测过载主机。NDOHD算法时间复杂度为O(|H|),|H|为需要过载检测的主机数量。
NDOHD算法步骤如下:
(1)给定过载主机hi;
(2)根据物理主机中多维资源负载的历史数据,使用式(4)、式(5)为每个虚拟机建立正态分布模型;
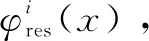
2.2 虚拟机选择算法
该文将云数据中心虚拟机资源利用率服从正态分布的特点与MMT算法结合,提出基于正态分布模型的最小迁移时间虚拟机选择(Normal Distribution Model-based Minimum Migration Time,NDMMMT)策略。在选择待迁移虚拟机时,必须充分考虑虚拟机内存的大小,因为虚拟机迁移会导致虚拟机宕机,虚拟机内存越大,对云数据中心的QoS产生的负面影响越大,所以尽量选择内存较小的虚拟机迁移。
具体计算公式如下:
vmi∈VMhj∣∀a∈VMhj
(10)
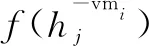
NDMMMT算法步骤如下:
(1)输入过载主机hover;
(2)对hover中每个虚拟机vmi执行以下步骤;
(3)计算选择虚拟机vmi的优先级priority,如式(11)所示,如果该值大于前一虚拟机的值,则更新待迁移虚拟机vmMig;
(11)
(4)循环结束后,得到待迁移的虚拟机vmMig。
2.3 虚拟机放置算法
虚拟机放置算法也被称为虚拟机映射或分配策略。在选择完要迁移的虚拟机之后,整合的最后一个阶段是为当前选定的待迁移虚拟机集合找到最佳的目标主机。为了确保迁移后不影响目标主机的稳定性,需要根据物理主机中未分配的资源数量和每台主机处于资源均衡利用的概率选择目标主机。
在PABFD算法的基础上,结合NDOHD检测算法,该文提出了ND-PABFD算法。该算法在PABFD算法的基础上结合了多资源协同优化。首先,将所有待迁移虚拟机按照CPU资源请求量进行降序排列。其次,为虚拟机匹配物理主机,并根据公式(12)计算虚拟机需要选择的物理主机的优先级;最后,选择优先级最高的物理主机放置虚拟机。重复以上步骤,直到所有的虚拟机都被放置到合适的目标物理主机上。ND-PABFD的算法复杂度为O(|Ha|·|VMa|)。
ND-PABFD算法步骤如下:
(1)非过载主机集合Ha、待迁移虚拟机VMa作为输入;
(2)迁移虚拟机按照CPU资源请求量进行降序排列;
(3)while vmi∈vmList,执行步骤(4)~(5);
(4)遍历所有主机hi,根据式(12)计算主机对应的PRI(vmi,hj),选择PRI(vmi,hj)最大值相应主机allocationHost作为vmi放置的主机:
(12)

(5)将(vmi,allocationHost)放入虚拟机映射集合allocation;
(6)输出虚拟机映射集合allocation。
2.4 活动主机规模收缩
由于云数据中心负载的不确定性,虚拟机放置完成后,云计算中心的部分主机上可能会出现负载不足的情况,必须将低负载物理主机上的所有虚拟机迁移出去并休眠该主机。
首先,选择出与其他主机相比利用率最低的主机,并尝试将此物理主机上的虚拟机放置在其他物理主机上,同时避免目标主机过载。如果可以完成此操作,则将虚拟机设置为迁移到确定的目标主机,并在所有迁移完成后将源主机切换到休眠模式。如果源主机上的所有虚拟机都无法放置到其他物理主机上,则将该物理主机保持活动状态。未被视为过载的主机则会重复此过程。
2.5 基于多资源协同优化的虚拟机整合策略
结合前文提出的NDOHD、NDMMMT、ND-PABFD算法以及活动主机规模收缩过程,提出了MRCO-VMC方法。MRCO-VMC策略的工作步骤如下:首先,该策略采用NDOHD算法计算运行中物理主机过载的概率,形成过载主机集合;其次,使用NDMMMT算法从过载的物理主机中选择向外迁移虚拟机,直到该主机上的负载降低到过载阈值以下,并将待迁移的虚拟机添加到向外迁移虚拟机集合中;第三,利用ND-PABFD算法为向外迁移的虚拟机找到合适的目标主机,即满足向外迁移虚拟机的资源需求和虚拟机放置后虚拟机的低过载风险需求的目标主机;最后,选择负载最低的物理主机,将其所有的虚拟机移动到合适的目标主机上,并休眠该物理主机,直到所有低载物理主机都被关闭为止,其伪代码见算法1。
算法1:MRCO-VMC算法。
1 Input:hostList
2 Output:Map〈host,vm〉
3 //过载检测
4 for eachhjin hostList
5 if NDOHD(hj) is true then
6 将hj加入过载主机集overHostList
7 end if
8 end for
9 //虚拟机选择
10 for eachhjin overHostList
11 While NDOHD(hj) is true do
12 NDMMMT(hj)
13 vmMigrateList←vm
14 end while
15 end for
16 //虚拟机放置
17 ND-PABFD算法输入:过载主机,待迁移虚拟机
18 使用贪心策略,关闭低载主机
19 return 虚拟机与主机映射关系Xm*n
3 仿真实验
3.1 实验环境配置
该文使用虚拟机整合的主要仿真平台CloudSim模拟云计算环境进行仿真。实验中使用的数据集来源于CoMon项目中PlabetLab平台,其拥有超1 000台虚拟机在10天运行的负载记录。模拟的数据中心有800台物理主机,为CloudSim提供的HP ProLiant ML110 G4和HP ProLiant ML110 G5;虚拟机参考Amazon Ec2,共四类:High-CPU medium、Extra large、Small、Micro[9-10]。
3.2 评估指标
采用文献[10]中的指标作为算法的评估标准,包括能源消耗(EC)、服务等级协议违背率(SLAV)以及二者组成的指标ESV,迁移引发的服务质量下降(PDM)、活动物理主机的平均等级协议违背率(SLATAH)。
3.3 MRCO-VMC策略性能分析
为了验证提出虚拟机整合策略的效果,选择了Beloglazov和Buyya教授放置在CloudSim中的三种基准算法[10]。三种算法所采用的过载主机检测方法分别是:四分位距(Inter Quartile Range,IQR)、局部回归(Local Regression,LR)以及绝对中位差(Median Absolute Difference,MAD)。文献[10]还介绍了三种虚拟机选择算法,分别为最少迁移时间算法(MMT)、随机选择算法(RS)、最大相关性系数算法(MC)。此外,CloudSim中又新增了最小利用率(MU)方法,该方法的思想是迁移对象为CPU利用率最小的虚拟机。通过对上文介绍的算法进行组合,选择了IQR-MMT、LR-RS、MAD-MU(对比算法)三种算法。根据“控制变量法”思想,将MRCO-VMC策略与对比算法在各个指标上进行比较。
能耗指标反映的是云数据中心电能消耗的情况,其值越小代表虚拟机整合算法产生的能耗越少。由图1可知,MRCO-VMC算法具有最低的能耗值,LR-RS算法次之,MAD-MU消耗的电能最多,而MRCO-VMC算法比对比算法中平均能耗最低的LR-RS算法还要低36.66%。由此看出,MRCO-VMC算法在降低能耗方面效果显著。
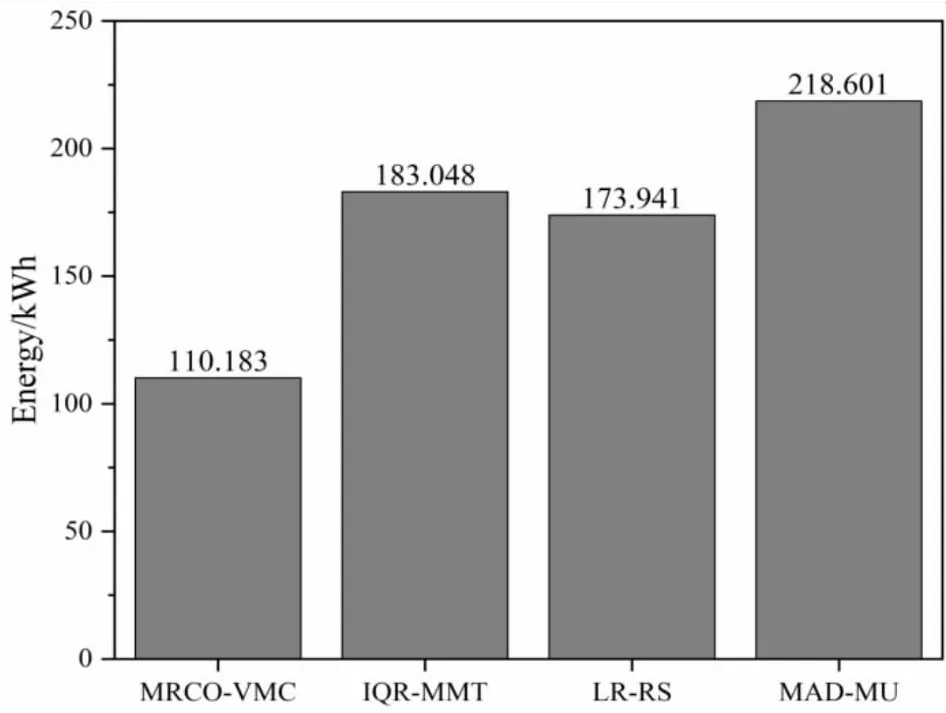
图1 EC指标平均值对比
SLAV指标代表服务水平协议违背率,它既表示由于过度利用物理主机而产生的SLA违规,也表示由于迁移虚拟机而产生的SLA违规,其值越低表示云计算中心服务质量越好。由图2可知,MRCO-VMC算法的平均服务等级协议违背率处于较低的水平,低于其他对比算法,IQR-MMT算法次之,LR_RS算法的SLAV指标最高,且MRCO-VMC算法的SLAV指标与IQR-MMT算法相比平均下降了64.1%。由此可知,MRCO-VMC算法的SLAV性能最好,服务质量提升最高。
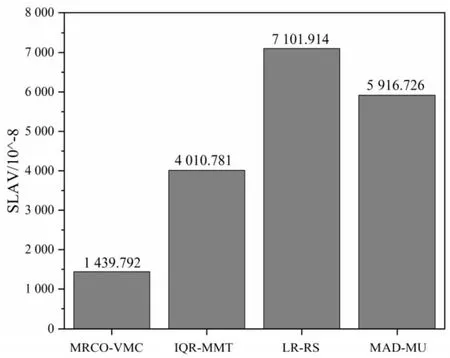
图2 SLAV指标平均值对比
由于SLAV指标是将PDM和SLATAH这两项指标综合评定之后云数据中心的整体服务质量,所以有必要对PDM和SLATAH这两项指标做出更深入的剖析。SLATAH指标是指由于活动物理主机运行时过载给服务质量带来的下降率。虚拟机整合过程中物理主机越少则SLATAH指标越小。由图3可知,MRCO-VMC算法的SLATAH指标最低,IQR-MMT算法和LR-RS算法次之,MAD-MU算法的指标值最高,这主要是因为IQR-MMT算法、LR-RS算法和MAD-MU算法在虚拟机整合时无法预测工作负载趋势,更容易导致物理主机过载,服务质量下降。由此可知,MRCO-VMC算法降低了活动物理主机过载的概率,保障了服务质量。PDM指标是指虚拟机整合过程中受到的虚拟机迁移次数和持续时间的影响,通常情况下,虚拟机迁移次数越少、迁移时间越短,PDM越低,即虚拟机迁移对云数据中心的服务质量的负面影响越小。当选择迁移虚拟机时,MRCO-VMC算法综合考虑了使迁移时间最小化的因素,它的最终目标是最大化物理主机处于资源均衡利用状态的概率,防止物理主机超载,虚拟机迁移更少,图5也验证了该算法迁移次数相比较少。因此,MRCO-VMC算法的PDM指标值要低于其他三种对比算法,如图4所示。

图3 SLATAH指标平均值对比

图4 PDM指标平均值对比
虚拟机在迁移时会被迫停止服务,因此需要尽量减少虚拟机的迁移次数。VMMs表示虚拟机整合过程中的迁移总次数,它的值越小说明相应的虚拟机整合策略对服务质量的影响越小。由图5可知,MRCO-VMC算法的虚拟机迁移次数远远低于其他三种对比算法,其次是LR-RS算法和IQR-MMT算法,MAD-MU算法的虚拟机迁移次数最多。这是由于MRCO-VMC算法利用正态分布模型估计云数据中心处于多资源均衡利用状态的概率,平衡了各种资源的工作负载,有效避免了物理主机频繁过载的风险,同时,避免了不必要的虚拟机迁移。

图5 虚拟机迁移次数平均值对比
ESV指标是在服务质量和能量消耗之间平衡的组合度量,ESV的值越低说明对应的算法综合性能越好。与其他三种方法相比,MRCO-VMC算法引起的SLAV和消耗的电能较少,从而降低了ESV。如图6所示,MRCO-VMC策略的ESV的值最低,且该策略的值要远低于对比算法,说明该策略在保证服务质量、降低能耗方面表现较好,其次是IQR-MMT算法和LR-RS算法,ESV值最高的是MAD-MU算法。

图6 ESV平均值对比
4 结束语
为解决主机多资源利用不平衡引起的数据中心能耗增加、服务质量下降,该文提出了一种基于多资源协同优化的虚拟机整合策略(MRCO-VMC)。该策略根据虚拟机的资源利用率呈现正态分布的特点,采用正态分布模型估计虚拟机的资源利用率,计算物理主机处于资源利用平衡状态的概率;使用基于正态分布的多资源过载检测算法预测物理主机过载的概率,筛选出数据中心的过载主机;基于正态分布的最小迁移时间虚拟机选择算法通过结合云数据中心虚拟机资源利用呈正态分布的特点和MMT算法,选取待迁移的虚拟机;基于正态分布的能耗感知最适降序算法将PABFD算法与正态分布模型相结合,将虚拟机从源主机迁移到目的主机;最后,采用贪心策略将运行物理主机数量进行收缩。
基于真实虚拟机负载数据进行仿真实验,实验结果表明MRCO-VMC能够有效地减少虚拟机迁移次数、提升系统服务质量。由于实验环境的局限性,该文仅在CloudSim仿真平台上进行了对比实验,无法保证其在真实实验环境中的效率,在未来工作中将进行更多仿真实验,评估提出的方法在实际负载中的性能表现。
猜你喜欢
中国煤炭(2020年2期)2020-01-21
收藏界(2019年2期)2019-10-12
中国化肥信息(2019年6期)2019-01-19
消费导刊(2017年24期)2018-01-31
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
环球市场信息导报(2016年41期)2017-01-19
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
印制电路信息(2015年6期)2015-12-30
湖北师范大学学报(自然科学版)(2015年3期)2015-12-05
学习月刊(2015年6期)2015-07-09
