
结合特征增强和多尺度感受野的低照度目标检测
2023-04-19 18:33:34江泽涛翟丰硕张少钦
计算机研究与发展 2023年4期
江泽涛 翟丰硕 钱 艺 肖 芸 张少钦
1 (广西图像图形与智能处理重点实验室(桂林电子科技大学)广西桂林 541004)
2 (南昌航空大学土木建筑学院 南昌 330063)
(zetaojiang@126.com)
目标检测是计算机视觉领域的研究热点之一,目标检测近年来也取得了很大的进展,它广泛应用于机器人视觉[1]、车辆识别与跟踪[2]、行人检测[3]和军事视频监控[4]. 然而,在不利光照条件下,目标检测仍然具有挑战性.因为缺乏足够照明,采集到的图像会出现一系列退化,例如低亮度、低对比度、强烈的噪声等,目标检测的漏检率和误检率会大幅增加. 低照度目标检测需要克服低照度图像细节特征不明显的缺陷,充分提取利用有限特征,最后输出高精度的检测结果.
早期低照度目标检测[5]一般使用红外成像相机实现,红外热成像相机对物体的温度信息敏感,但无法区分温差较小的物体. 随着深度学习的快速发展,目前的低照度目标检测[6]主要依靠RGB 数码相机拍摄图像,再将数字图像输入计算机完成目标检测算法. 这种方法图像数据获取成本较低,图像的动态范围更大,进而可以捕获更多的视觉信息,因此检测精度也有了较大提升. 目前基于域适应的低照度目标检测算法[7]需要用到明暗成对的数据集训练生成对抗网络(generate against network, GAN)[8],再由通用目标检测算法输出检测结果. 这种方案模型较难拟合,实现条件较为苛刻,检测结果输出在原图上,人眼无法直观评估检测结果的好坏. 此外,低照度图像增强算法很好地实现了低照度图像到正常照度图像的转换,但是其模拟的增强效果是基于人眼视觉效果的,对于计算机而言,增强过后的图像目标特征信息会有所损失,将其直接送入主流目标检测模型,很难得到较好的检测精度.
针对上述不足,本文研究一种结构简单、精度较高且能够在正常照度风格图像上输出检测结果的端到端低照度目标检测算法. 该算法结合高清摄像机的数据优势和深度神经网络的强大学习能力,提出一种像素级高阶映射(pixel-level high-order mapping,PHM)模块去增强低照度图像特征,这个初步增强图像特征的过程视为粗调. 粗调之后的图像特征经过关键信息增强(key information enhancement, KIE)模块过滤噪声信息,再次对特征信息进行优化,这个再次增强图像特征的过程视为细调. 2 阶段调整使得网络输出更加显著的低照度图像特征信息,然后利用特征金字塔网络将全局特征和局部特征信息充分融合,提高每张特征图的特征表达能力. 此外,在特征金字塔中添加长距离特征捕获(long distance feature capture,LFC)模块,搜寻特征图中目标的长距离依赖关系,利用多种不同尺度的感受野,提高算法的目标检测精度. 最后,使用多个预测分支去直接回归目标检测框的位置和大小.
本文的主要贡献有3 点:
1) 提出PHM 模块,增大低照度图像待检测物体的局部特征梯度,进而提升目标检测精度;
2) 在富含大量特征信息的中等尺寸特征图上,添加KIE 模块,突出重要信息,过滤噪声信息,促进检测网络的快速收敛;
3) 提出LFC 模块,捕获孤立区域的长距离关系,提高对极端长宽比物体的检测能力.
1 相关工作
1.1 低照度图像增强
低照度图像普遍存在整体亮度不足、对比度较低等问题,人眼难以获取图像信息,低照度图像增强算法可以有效解决这些视觉难题. 目前已有大量图像增强算法被提出,早期基于直方图均衡化[9]的图像增强算法使用额外的先验和约束,试图放大相邻像素之间的灰度差,扩展了图像的动态范围. 基于去雾的图像增强算法[10]借鉴将图像求反然后去雾的思路,将低照度图像求反去雾再求反的方式进行处理,用于还原低照度图像更多的细节,但是基于去雾的算法丢失了过亮区域的细节. Retinex 理论[11]指出物体亮度由物体本身的反射分量和环境光照2 个因素构成. 基于该理论,RetinexNet[12],KinD[13]等算法通过处理环境光照分量来达到增强图像的效果. MBLLEN[14]算法在不同等级中提取出丰富的图像特征,利用多个子网络做图像增强,最后通过多分支融合产生输出图像,图像质量从不同的方向得到了提升,但有时会出现过曝光的增强结果. 这些算法都需要使用成对的明暗数据集训练端到端的低照度图像增强网络.Zero-DCE[15]使用一系列零参考的损失函数来引导低照度图像向正常照度和高质量视觉特征的方向转换,不需要使用成对的明暗数据集,该算法可以泛化到各种光照条件下,同时计算量很小,可以方便地应用到其他下游任务中,提高目标检测任务的检测精度.
1.2 目标检测
近年来,目标检测领域已经取得了长足的进步. 很多优秀的目标检测算法被提出:YOLO 系列目标检测算法(YOLOv1[16]、YOLOv2[17]、YOLOv3[18]、YOLOv4[19]、YOLOv5[20]、YOLOX[21]),该系列的主体框架为特征提取器和检测头. YOLOv1 中的检测头为2 个全连接层,直接预测边界框的位置和宽高,速度快,但是精度较低;YOLOv2 引入偏移量的概念,预先定义大量已知位置和宽高的锚框(anchor),降低直接预测边界框的位置和宽高的难度;YOLOv3 主要对YOLOv2 进行了改进,将检测头分成3 部分,分别负责检测大、中、小目标;YOLOv4 进一步对检测头进行了改进,并使用了CIOU[22]损失函数来进行网络模型的训练,还改进了特征提取和特征融合模块等;YOLOv5 采用了自适应的锚框,在特征融合部分添加FPN[23]和PAN[24]结构,损失函数使用GIOU[25]损失函数等;YOLOX 放弃先验框的设置,使用无锚框的训练方式,提升网络模型的通用性. 此外,R-CNN 系列目标检测算法(R-CNN[26]、Fast R-CNN[27]、Faster R-CNN[28])有着更高的检测精度,但是检测速度较慢,R-CNN 首先对图像选取若干建议区域并标注类别和边界框,然后对每个建议区域提取特征,进一步确定边界框和目标类别;Fast R-CNN对整幅图像进行特征提取,减少R-CNN 中对每个建议区域特征提取导致的重复计算;Faster R-CNN 将生成建议区域的算法从选择性搜索变成了区域建议网络. 另外,EfficientDet[29]为不同应用场景提供了7 种不同大小的模型,实现了速度和精度之间的均衡;Foveabox[30]、FCOS[31]、CornerNet[32]等基于关键点或中心域法的无锚框(anchor-free)目标检测算法也有较高检测精度和检测速度. 同时,特征金字塔、Focal loss[33]等关键技术被广泛应用到各个目标检测算法中. 但这些目标检测算法在低照度场景下都不能取得很好的检测精度,本文研究在这些目标检测算法的基础上构建一个端到端的低照度目标检测算法框架.
1.3 注意力机制
注意力机制已广泛应用于计算机视觉的各个领域,并取得了良好的效果. 注意力机制对输入数据的各个部分按照其对结果的影响程度分配不同的权重.Hu 等人[34]提出了通道注意力,对特征通道间的相关性进行建模,降低无关信息的影响,强化重要区域的特征,帮助网络模型具备更好的语义表达能力.
通道注意力机制的实现分为3 个部分:挤压、激励和注意. 通过挤压函数可以将H×W×C的特征图变换成1×1×C的特征向量,如式(1)所示:
其中H,W分别表示特征图的长和宽,将每个通道内所有的特征值相加再取平均,即得到代表每个通道信息的特征向量.
激励过程学习各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,得到权重向量:
其中 δ表示ReLU 激活函数,σ表示Sigmoid 激活函数,w1和w2分别表示激励阶段的前后2 个特征向量.
注意阶段将权重向量与特征图对应通道的每个特征值相乘,如式(3)所示:
其中,x表示输入特征图,w表示权重向量.
Wang 等人[35]提出了空间注意力,让网络关注图像特征中的特定区域,显著提升了图像分类任务的准确率. 在目标检测领域,除了语义信息外,位置信息也相当重要,Woo 等人[36]将空间注意力和通道注意力进行整合,使目标检测网络更积极地关注含有待检测目标信息的重要特征. Vaswani 等人[37]提出了自注意力机制,将特征图每个位置的更新都由计算特征图的加权和得到,这个权重来源于所有位置中的成对关联,这样可以建立长距离依赖.
2 低照度目标检测框架
2.1 基本思路和总体设计
本文提出结合特征增强和多尺度感受野(feature enhancement and multi-scale receptive field, FEMR)的低照度目标检测模型,将像素级高阶映射(PHM)模块、关键信息增强(KIE)模块、长距离特征捕获(LFC)模块与YOLOX 目标检测模型相结合. 首先输入低照度图像数据,通过人工设计的损失函数去拟合高阶映射模块的网络参数,使其在前向传播中向正常照度图像的特征分布逼近,得到初步增强的特征图,提升模型对低照度图像特征的利用效率. 其次在此基础上,使用特征提取网络对初步增强的特征图进行深层次特征提取,得到3 种不同大小尺度的特征图,该特征提取网络结构与YOLOX 模型结构保持一致,再利用通道空间注意力和外连接注意力机制的差异化特性,对特征图进行引导,让模型关注对检测结果贡献更大的关键特征,为多尺度感受野特征金字塔部分提供富含高层语义信息和浅层位置信息的高质量特征图. 在低照度图像中,观察发现孤立区域内经常存在极端比例的待检测目标,引入条状感受野可以加强对长距离特征关系的捕获能力,提升网络模型对该类目标的检测能力,同时不会带来过多的参数和计算量. 最后利用3 个检测头进行特征解码,去预测目标框的位置、高宽和对应的类别. 本文所提模型具备直接检测低照度图像中不易识别和极端比例目标物体的能力,并输出带有目标框信息的正常照度风格图像.
如图1 所示,模型整体可分为5 个部分,分别是图中上方的像素级高阶映射,下方左边的特征提取,中间的关键信息增强和多尺度感受野特征金字塔,右边的特征解码.各部分相互独立,因此该模型结构具有较高的灵活性.

Fig.1 Architecture for FEMR low illumination object detection algorithm图1 FEMR 低照度目标检测算法结构图
2.2 像素级高阶映射模块
低照度图像特征的不显著性严重影响目标检测算法的检测精度,因此本文设计图像特征增强模块去解决这个问题. 具有RGB 三通道的低照度图像,经过固定尺寸缩放和归一化后,作为模块的输入,输出为经过初步特征增强的三通道特征图. 该模块可以拟合出一个高阶映射曲线,为输入图像的每一个像素建立映射关系.
本文设计的PHM 模块结构细节如图2 所示,模块主要由4 层卷积构成,其中卷积核大小均为3×3,步长为1,卷积过程中保持与输入相同的尺度大小,前3 次卷积扩充通道数为32,并用ReLU 激活函数[38]激活,消除网络运算过程中得到的负值,第4 层卷积将通道数调整为24,并用tanh 激活函数[39]激活,将输出结果压缩到(0,1)区间范围内,并拆分成N张三通道的特征图,N=8.
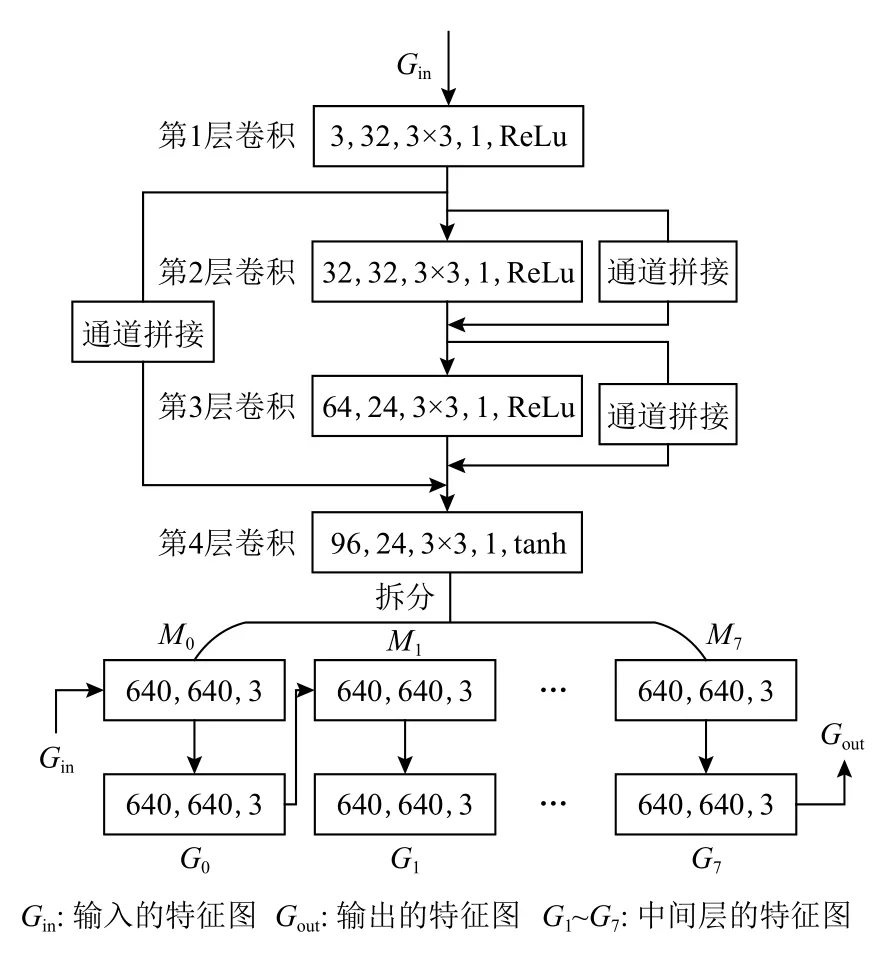
Fig.2 PHM module structure diagram图2 PHM 模块结构示意图
将输入图像与这N张特征图上对应的值进行运算,得到初步增强的特征图,该运算过程为
为了引导网络得到合理的增强映射关系,本文设计了3 个损失函数:曝光损失、光照平滑损失、色彩一致性损失. 曝光损失函数控制图像的曝光强度范围,首先预设一个正常光照强度[40]等级E,然后计算固定大小区域内的平均灰度值等级Yk与预设E之间的L1距离,本文设定的固定区域大小为16×16,同时设置E=0.6. 这个正常光照强度等级E是一个超参数,通过不断缩小该距离,让网络学习到将低光图像特征映射成正常光照图像特征的参数值. 该损失函数表示为
其中S表示特征图被划分的区域个数,Yk表示各个区域的平均灰度值等级,E表示预设的正常光照强度等级.
为了保持相邻像素之间的单调关系,本文设计了一个光照平滑损失函数,通过减小水平方向、竖直方向和对角方向的灰度差值,来达到光照平滑的效果.该光照平滑损失函数可以用式(6)表示:
其中H,W表示特征图的高和宽,Mi,j表示对应第i行第j列的灰度值大小.
图像的浅层特征主要包含颜色等信息,同时考虑到图像RGB 颜色三通道的色彩稳定性[41]. 因此本文设计了一个提升色彩一致性的损失函数,将RGB三通道拆分成(R,G),(R,B),(G,B)三个组合,然后不断减小每2 个通道之间平均强度的L2 距离,最后实现色彩的一致性. 该损失函数表示为
其中Jp和Jq分别表示对应p和q通道的整体灰度值强度大小,ϕ表示各通道进行组合的列表.
特征增强的高阶映射模块整体损失由式(5)(6)(7)3 个损失函数联合计算,可以用式(8)表示:
其中Wexposure和Wcolor表示对应损失函数的权重.
2.3 关键信息增强模块
如何充分利用从特征提取网络提取的低照度图像特征信息,是提高低照度目标检测性能的关键问题. 本文设计了KIE 模块,使网络能够关注重要信息;过滤噪声信息,从少数重要的凸显特征中获取所需要的类别和位置信息,其中包括通道空间注意力和外连接注意力机制.
通道空间注意力结构如图3 所示,其中的通道部分由2 个同时进行的平均池化和最大池化组成,将输出的2 个向量逐位相加,并分2 次使用全连接层整合特征信息,最后使用Sigmoid 激活函数,压缩它们的数值范围并进行输出,作为原始特征图各个通道的权重系数. 空间部分主要在通道维度上使用最大池化和平均池化,将得到的2 张单通道的特征图进行堆叠,再使用一个膨胀系数为2 的3×3 卷积调整通道数为1,每个位置的数值作为原始特征图对应空间位置的权重. 空间注意力机制加权引导后的特征图具有重点关注不同区域特征的能力;通道注意力机制加权引导后的特征图具有关注不同通道维度特征的能力,将它们逐像素相加,可以最大化利用低照度图像有限特征信息,使该模块具有识别目标检测关键信息的能力.
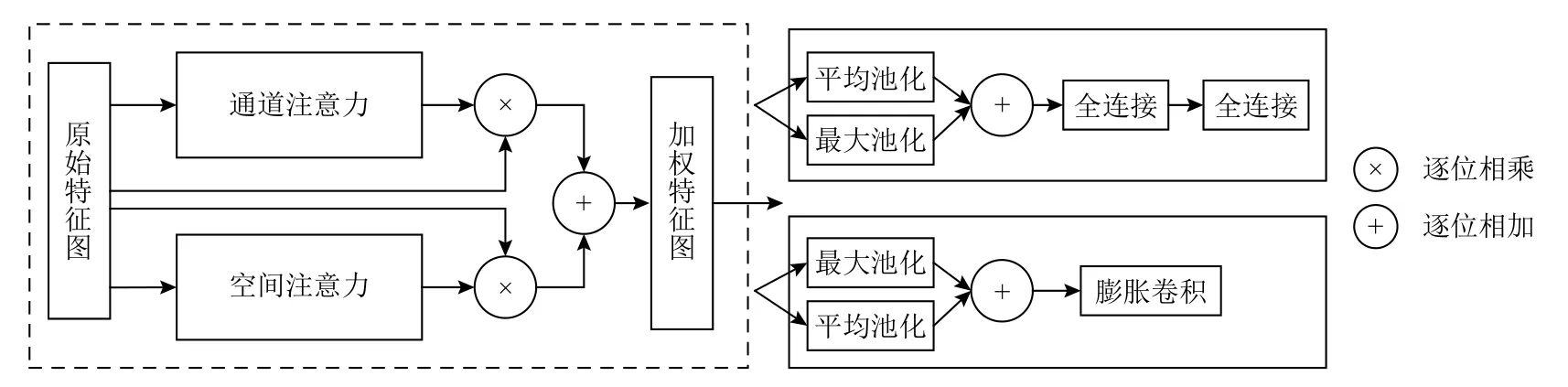
Fig.3 Channel spatial attention structure diagram图3 通道空间注意力结构示意图
通道空间注意力应用在40×40 的中等尺寸特征图上,该层级的特征图位置信息和高层语义信息都极为丰富,可以充分发挥注意力的自动分配权重的能力,以加快网络模型训练拟合速度.
对于大尺度特征图,本文设计外连接注意力去让网络利用自身样本内的信息,通过引入2 个外部记忆单元,隐式地学习整个数据集的特征,加强不同样本间的潜在特征关系,外连接注意力结构如图4所示. 首先,输入特征图经过维度变换,将特征图转换为特征向量,在全连接层中将其变换成其他维度大小,该层为线性层,不使用激活函数. 获得第1 个辅助记忆单元,将一些和任务相关的信息保存在辅助记忆中,在需要时再进行读取,这样可以有效地增加网络容量. 将第1 个记忆单元获得的先验知识经过线性变换得到第2 个记忆单元,增强网络的建模能力. 外连接注意力使用较少的训练参数,大幅增强特征信息的表达能力,并最终提高模型的检测精度.
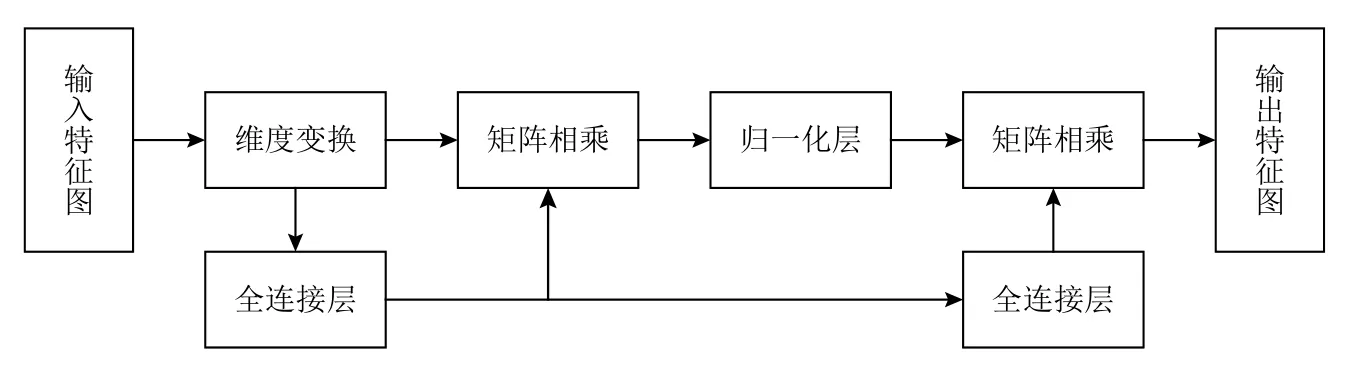
Fig.4 External connection attention structure diagram图4 外连接注意力结构示意图
2.4 长距离特征捕获模块
为了提高网络对特征远程依赖关系建模的能力,业界普遍采用自注意力机制和Non-Local 模块[42],但这类算法的复杂度是相当高的. 因此,本文设计将长距离特征捕获模块嵌入到特征金字塔中,让网络有意识地关注场景中极端比例,前后位置距离相差较远的特征信息.
LFC 模块的结构细节如图5 所示. 输入特征图经过2 个不同的卷积分支,得到同样尺寸的特征图,然后在2 个分支中采用不同的自适应池化策略. 上半部分分支中,第1 层特征图被进一步特征提取,依次是利用3×3 的感受野进行卷积操作,不改变特征图尺寸,使用自适应池化,将特征缩小为原来的1/3 倍和1/5 倍,对应着小感受野和稍大的感受野,然后通过上采样和通道堆叠再压缩,将多尺度感受野的特征信息进一步融合. 下半部分分支中,第1 层特征图被进一步变换为2 个特征向量,其中1 个将宽压缩为1,另一个将高压缩为1,分别对应特征图中每一行和每一列的远距离关系,然后通过上采样和通道堆叠再压缩得到能够捕获水平方向和竖直方向的远距离依赖关系的特征图,最后将2 个分支得到的特征图再次融合并输出. 集成长而狭窄的池化核,使网络可以同时聚合全局和局部上下文,在该模块的帮助下,多尺度感受野特征金字塔网络可以增强对孤立区域比例特殊目标的检测能力.
3 实验结果与分析
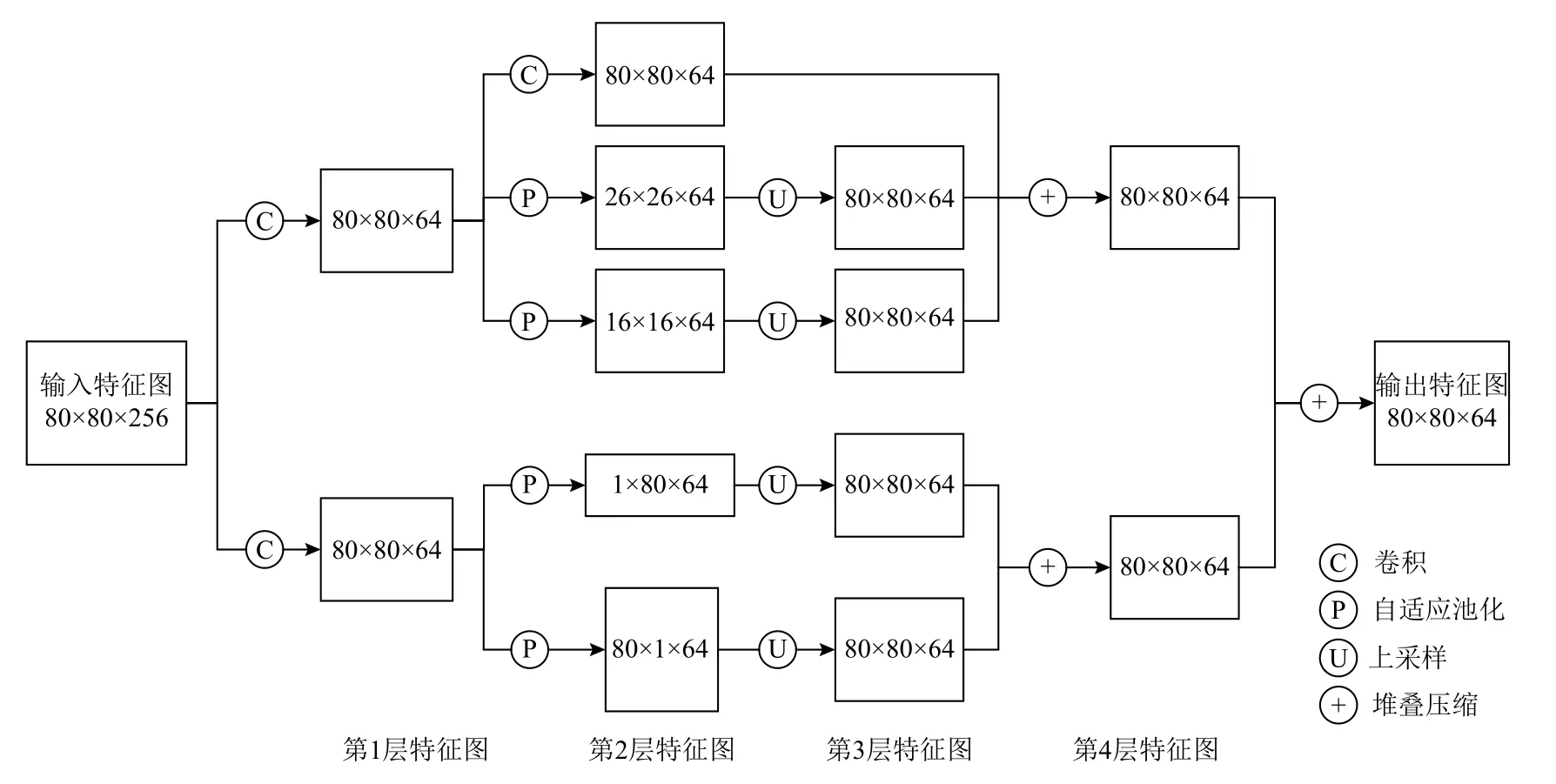
Fig.5 LFC module structure diagram图5 LFC 模块结构示意图
本节主要在ExDark 低照度图像数据集[43]上进行实验,采用平均精度(mean average precision, mAP)作为衡量本文提出算法在低照度目标检测性能上的评价指标. 本文所提出的低照度目标检测算法具有低照度特征增强、多尺度感受野等特点,可以有效解决低光照带来的问题. 本节重点讨论3 个部分:实现细节、检测性能、消融实验. 本文的算法主要针对低照度环境,因此以ExDark 数据集的实验结果作为主要的评价标准.
3.1 实现细节
本文的算法使用CSPDarknet53 作为主干特征提取网络特征,特征提取网络的预训练权重是在ImageNet 图像数据集[44]上训练得到的. 模型训练选择AdaBelief[45]优化器,训练分为前50 轮和后50 轮.前50 轮冻结主干特征提取网络的权重,只训练主干网络以外的部分权重,学习率设置为1×10−3,一次传入8 张图片数据;后50 轮释放主干特征提取网络的权重梯度,允许网络自动调整所有的训练参数,学习率设置为1×10−4,1 次传入4 张图片数据. 训练过程中使用余弦退火学习率算法[46],周期值设置为5,ETA最小值设置为1,使用标签平滑算法[47],默认参数值设置为0.01. 实验设备为Tesla P40 GPU,运行环境为Ubuntu 20.0.4.
3.2 检测性能
本文在低照度图像数据集(ExDark)上综合评估所提出的低照度目标检测算法,它包含12 个类别:单车、船、瓶子、公交、汽车、猫、椅子、杯子、狗、摩托、人和桌子. 在输入尺寸为640×640 的条件下,本文算法在测试集上取得了77.80%的mAP,相比于目前最先进的YOLOv5 和YOLOX 等目标检测算法,在检测精度mAP上有了较大的提升. 表1 展示了本文所提出的算法与目前主流目标检测算法的精度比较结果. 同时,本文还为模型设置了3 种不同版本的网络模型. 通过改变网络模型中的特征图通道数,增大或减小模型所使用参数数量,以此来达到让模型能够适应不同的显存大小显卡的目的.
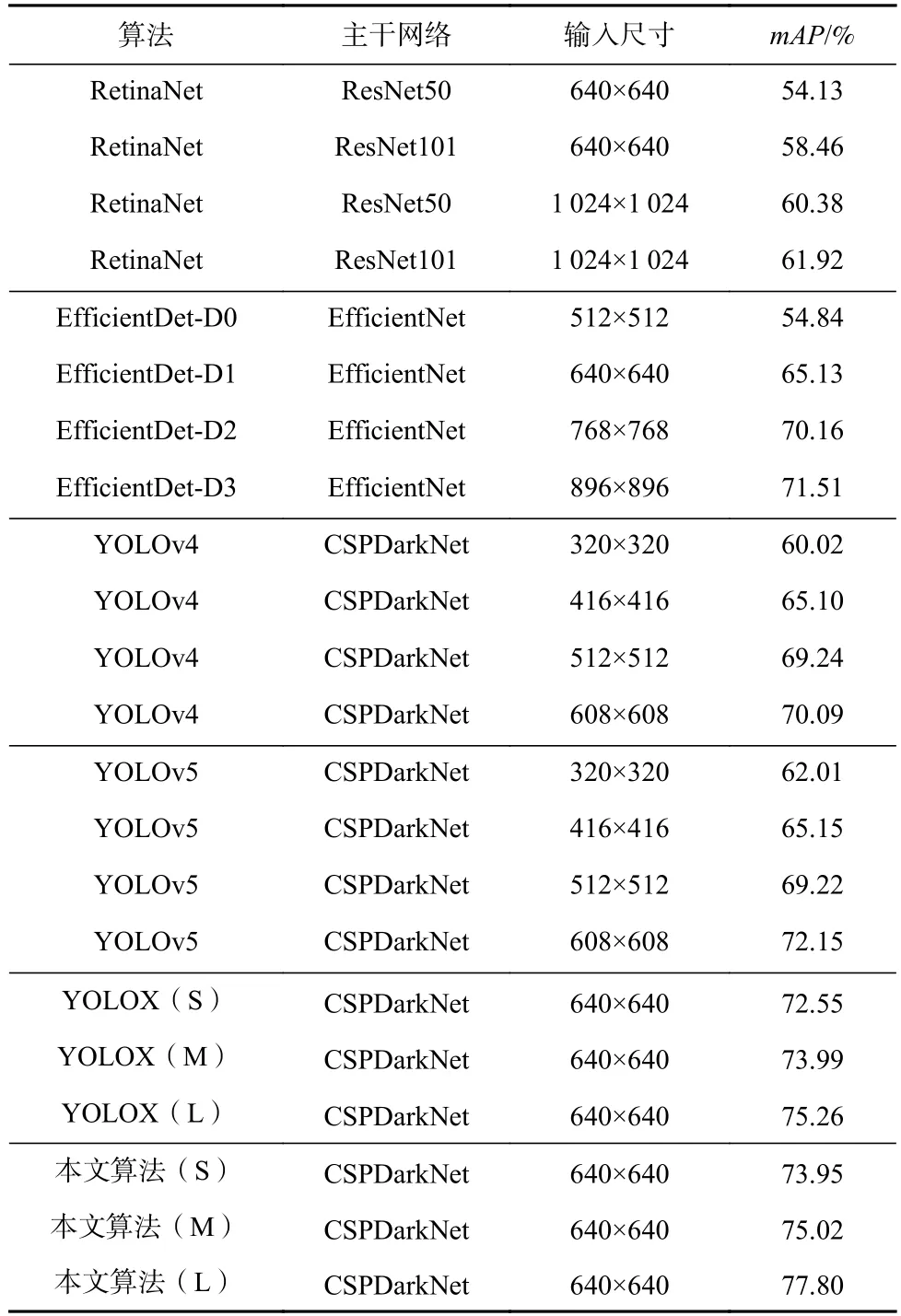
Table 1 Accuracy Comparison of Different Object Detection Algorithms on ExDark Dataset表1 在ExDark 数据集上不同物体检测算法的精度比较
图6 展示了本文提出的低照度目标检测算法与其他主流目标检测算法的比较,其中第1 行为标签对应的真实框,最后一行为FEMR 的输出结果,相比其他算法,可以直接由高阶映射模块得到的中间层输出便于人眼观察的增强图像,从图6 中可以看到本文提出的算法可以在低照度图像对应的正常照度风格图像上生成合理的目标边界框,漏检率和误检率相比前几种算法都有了一定程度的下降. 在共同检测到的物体上,本文提出的算法的识别准确率也会更高. 从第1 列对比图中,可以看出SSD 算法会漏检桌上大量杯子;EfficientDet 算法对桌上杯子的识别准确率较低;YOLOv4、YOLOv5 则会漏检旁边重叠的人,或是将桌上的餐具误检测成杯子,且识别准确率都相对较低. 从右边的4 列对比结果来看,也存在大量类似的问题.

Fig.6 Comparison of detection results of mainstream object detection algorithms图6 主流目标检测算法检测结果对比图
本节还通过对比图像增强算法+YOLO 系列的组合算法与本文提出的低照度目标检测算法在检测精度、训练时间和检测时间上进行对比,验证本文所提算法在低照度目标检测任务上的显著提升效果.
在实验中,本节在基础检测模型的基础上,分别组合了EnlightenGAN[48]、KinD[13]、MBLLEN[14]、Zero-DCE[15]这些基于深度学习的低照度图像增强算法[49],这些算法沿用原作者的设计方案,并按照作者提供的训练方案,重新训练对应图像增强网络的模型权重. 将ExDark 数据集中的测试集先进行图像增强,再送入YOLOv5 和YOLOX 目标检测器中,得出对应算法的mAP. 记录所有图像完成先增强后检测时间的总时间,最后取平均值得到该算法单张图像完成先增强后检测的时间,其中每种算法所用图像相同,检测时间仅包含模型前向运算时间,不包含模型导入和画框等时间,训练时间为模型训练所消耗的总时间.
通过表2 可以看出,本文提出的端到端低照度目标检测算法在检测精度、检测时间和训练时间等方面都具有显著优势,而由低照度图像增强算法增强过后的图像再送入目标检测器中,这种方式相比于直接送入对应目标检测器,检测精度还可能出现大幅下降的现象,说明经过增强的图像虽然在一定程度上在人眼视觉方面可以取得一定提升效果,但是对于计算机而言,损失掉了一部分有助于目标检测的重要特征信息. 同时生成图像的过程也占据了大量运算时间,不利于快速得到检测结果.
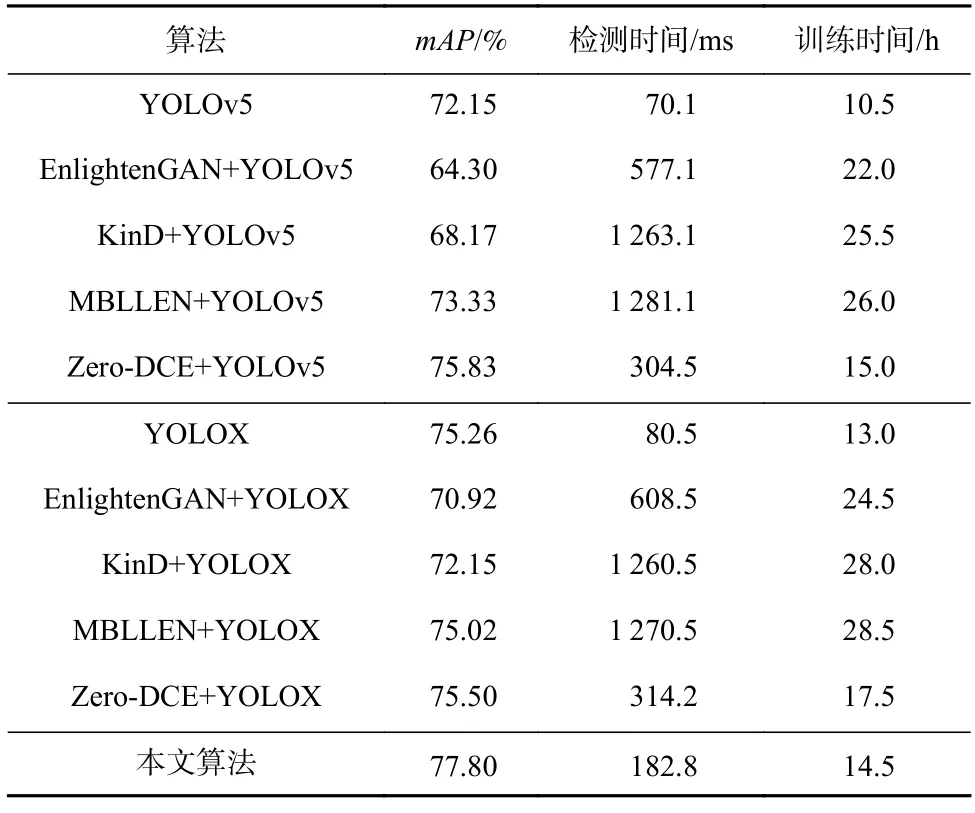
Table 2 Comparison of the Proposed Algorithm and Algorithms Enhanced Before Detection表2 本文算法与先增强后检测算法的比较
3.3 超参数设置实验与分析
本节对像素级高阶映射模块中的超参数N和E进行相关实验与理论分析,其中改变N的大小的同时需要改变上一层的特征图通道数,并与之匹配.
在实验中发现,通过8 轮及以上的增强过程,像素级高阶映射模块可以实现更大的曲率,应对不同的情况. 由图7 可以看出,增强次数过少会导致在训练阶段曝光损失、光照平滑损失和色彩一致性损失难以实现同步下降. 同时,表3 展现了当增大N值时,本文所提模型的检测精度呈现上升趋势,且N值增加会带来大量的运算,为了维持模型检测精度和检测速度的平衡,本文将设置N=8.
为了实现图像局部曝光强度处于正常状态,即不接近0(欠曝光)或1(过曝光). 本节分别将E值设置为0.2、0.3、0.4、0.5、0.6、0.7、0.8,由表4 可以看到,当E=0.6 时,模型检测性能较高,因此本文将设置E=0.6.
3.4 消融实验
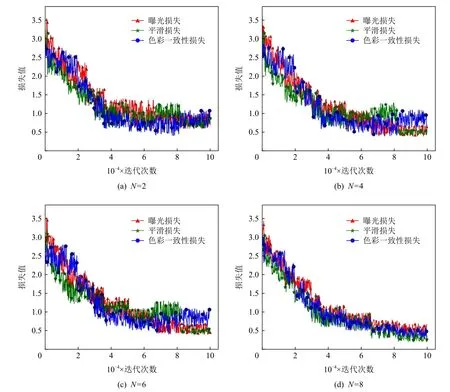
Fig.7 Loss curves of training processes图7 训练过程损失曲线图
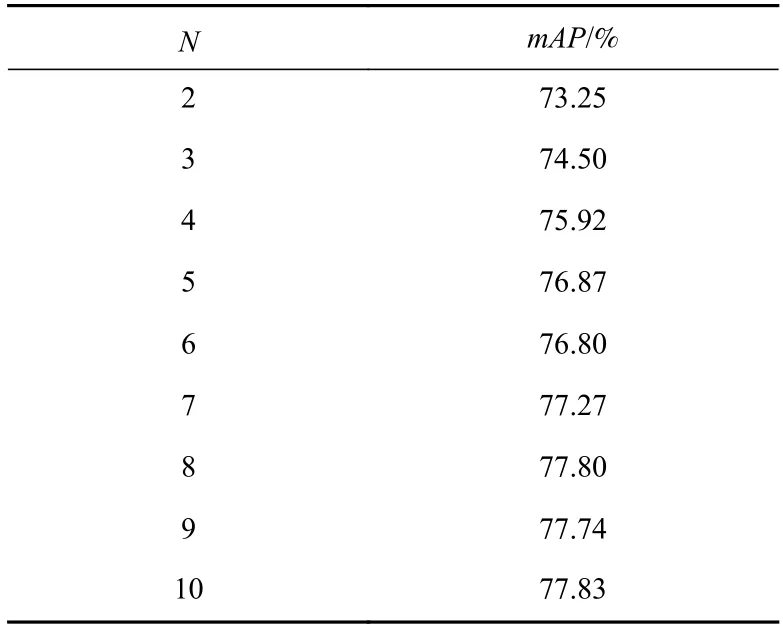
Table 3 Relationship Between Hyperparameter N and mAP表3 超参数N 与mAP 的关系
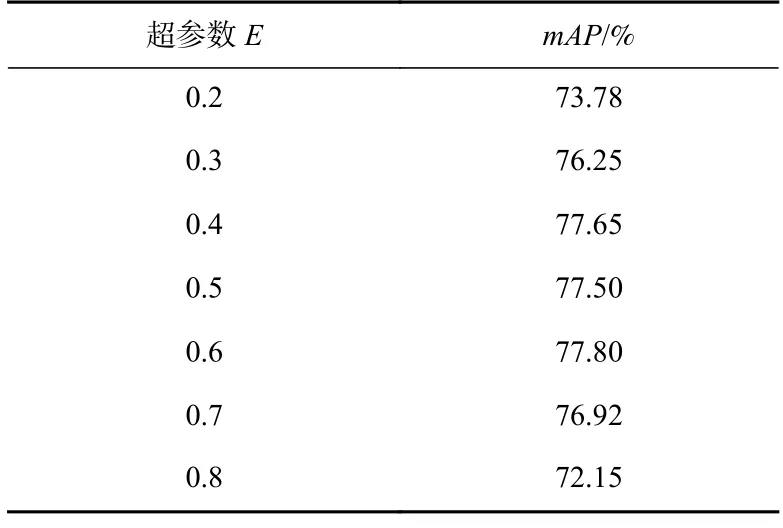
Table 4 Relationship Between Hyperparameter E and mAP表4 超参数E 与mAP 的关系
为了进一步探讨本文提出的算法的有效性,本节对像素级高阶映射(PHM)模块、关键信息增强(KIE)模块、长距离特征捕获(LFC)模块进行了消融实验,并对各个模块对实验结果的影响进行了分析,通过删减1 个或2 个模块,组合得到FEMR_del_KIE_LFC、FEMR_del_PHM_LFC、FEMR_del_PHM_KIE、FEMR_del_LFC、FEMR_del_KIE、FEMR_del_PHM 这6 种算法,还将各个模块嵌入到其他目标检测模型中,探讨其通用性. 在本节的实验中,只考虑算法模型对ExDark 数据集的性能影响,如表5 所示,其中以YOLOv5 算法作为基线模型,为了便于比较精度变化,各类别的mAP进行取整处理.
3.4.1 像素级高阶映射模块
本节增加像素级高阶映射模块后的检测模型,与基线模型相比,mAP提高了2.5%,有效提升了低照度图像的目标检测精度. 本节分析得出经过增强后的图像,其特征与正常光照的图像特征的差异较小,能够使网络在原始图像灰度梯度较小处能够得到更多的图像特征,以便于完成目标检测任务.
对该模块包含的3 个损失函数进行消融实验,通过删减1 项或2 项损失函数,组合得到FEMR_del_smooth_color、FEMR_del_exposure_color、FEMR_del_exposure_smooth、FEMR_del_color、FEMR_del_smooth、FEMR_del_exposure 这6 种算法. 由表6 可以看出,该模块的3 个损失函数的组合使用均对模型检测精度有不同程度的提升效果,侧面印证了提升图像质量对增强目标检测能力的帮助.
3.4.2 关键信息增强模块
本节增加关键信息增强模块后的检测模型与基线模型相比,mAP提高了1.68%,其中使用2 个注意力模块,分别对2 种特征尺寸的特征图进行关键信息的增强. 本文算法可以从2 个角度出发对特征图中目标的关键位置信息和语义信息,完成高效的激活,使网络更多地关注这类重要信息,消除噪声的干扰.
3.4.3 长距离特征捕获模块
本节增加长距离特征捕获模块后的建模与基线模型相比,mAP提高了2.12%,其中人和单车类别的mAP分别提升了5%和8%,提升最为明显,说明长距离特征捕获模块对这类比例较为特殊的目标的检测能力具有明显的加强,同时低照度数据集中这类目标占据的比重也较大,因此对整体检测精度有了较好的提升效果.
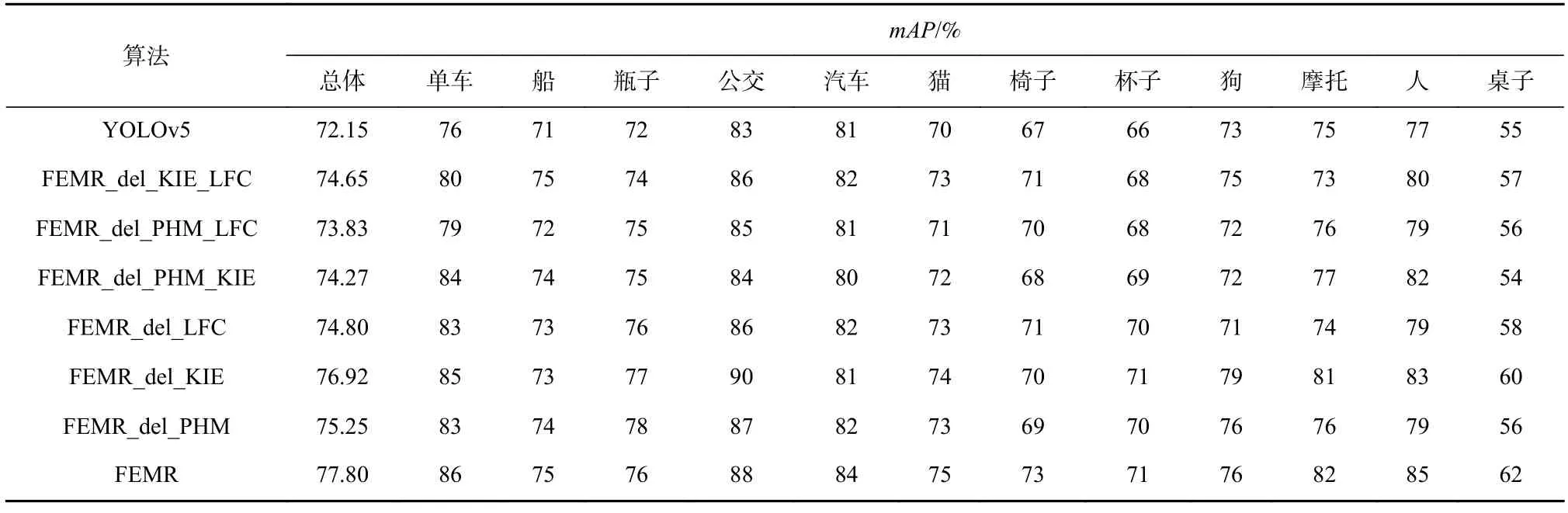
Table 5 Ablation Experiment of Each Algorithm on ExDark Dataset表5 在ExDark 数据集上各算法的消融实验

Table 6 Ablation Experiment of Loss Function表6 损失函数的消融实验
3.4.4 各模块通用性测试
表7 展示了向3 种其他目标检测模型中添加1 个、2 个或3 个模块时共得到21 种算法的检测结果.
从比较结果来看,本文提出的3 个模块均有一定的通用性,对大部分目标检测模型有精度上的提升.
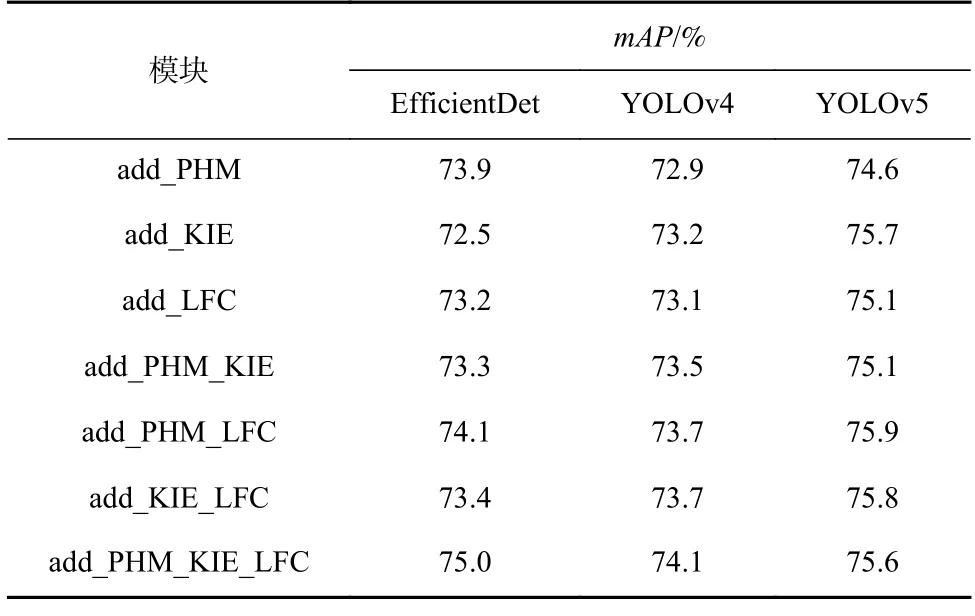
Table 7 Universality Test of Each Module表7 各模块通用性测试
4 结 论
本文针对低照度目标检测问题提出了结合特征增强和多尺度感受野的低照度目标检测算法.为了充分利用低照度图像中的不显著特征,设计了像素级的高阶映射模块和关键信息增强模块,分2 步去增强低照度图像特征,还设计了长距离特征捕获模块加强网络模型对长距离依赖关系的捕获能力,以此来共同提高模型的检测能力. 与其他经典目标检测算法在ExDark 数据集上的检测结果相比,本文提出的算法具有更高的检测精度. 然而本算法在检测速度、GPU 资源消耗方面有待提高,因此在后续的工作中也将针对网络的轻量化展开进一步研究.
作者贡献声明:江泽涛提出了文章整体思路并负责撰写与修改论文;翟丰硕负责完成算法设计与实验,并撰写与修改论文;钱艺修改论文;肖芸负责图表绘制;张少钦参与了论文的审阅与修改.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
光源与照明(2019年4期)2019-05-20 09:18:24
电子测试(2018年9期)2018-06-26 06:45:40
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
河南科技(2014年23期)2014-02-27 14:19:15
汽车与新动力(2012年1期)2012-03-25 10:09:23
