
基于机器学习的信贷违约预测研究
2023-04-06 22:14:58赵川鞠红梅王美玲
电脑知识与技术 2023年5期
赵川 鞠红梅 王美玲

关键词:大数据;风险预测;机器学习;信贷违约;投票算法
0 引言
为了响应国家稳经济的政策,金融机构对资金困难的企业和个人进行信贷支持,帮助供企业打通供应链资金需求,鼓励个人进行创业创新、开展副业、互联网办公等多种灵活就业方式,共渡难关,起到稳定市场经济作用。面对如此庞大的资金需求,金融机构需要依托机器学习模型,辅助进行风险评估和风险预测。
1 文献回顾
随着计算机技术在金融领域的应用,许多学者加入信贷风险的研究,其中Linwei Hu等人在相关文献中分析了监督学习算法在银行中的应用场景[1];XiaojunMa等人使用多观测数据清洗的LightGBM算法,表明该算法在预测违约方面具有较高的准确性[2];马海花针对性地在个人信用风险评估中,使用随机森林和XG?Boost模型进行对比分析,指出XGBoost模型更加适合处理大量高纬度的噪音和非线性信用风险的数据[3];陈红在文献中构建逻辑回归模型、朴素贝叶斯、支持向量机、决策树、组合模型进行综合对比,同时对违约客户进行客户画像分析,给出合理化建议和应用方向[4]。
国内外学者对于信贷风险预测的相关问题进行了大量的可行性分析与研究,不同学者选取的研究数据、评价指标和模型有所不同,最终得出不同的研究结果,这些研究具有重要的参考和借鉴意义。本文将结合银行数据集,以机器学习算法中XGBoost、Light?GBM模型、逻辑回归模型和随机森林模型为基础,结合Voting投票算法,进行个贷违约预测方面的研究。
2 算法及方案简介
2.1 算法简介与预备知识
1) 逻辑回归
逻辑回归是在线性回归的基础上进行改进的,增加了sigmoid激活函数[5]。线性回归模型为输入,f (x)为预测值,W T 为截线,b 为真实值和预测值的差值,具体公式为:
逻辑回归把预测值映射到0-1区间。当预测值y > 0.5时,判断为正例,y < 0.5时,判断为反例,以此进行分类。
2) 随机森林
随机森林的特点在于随机性和集成学习,通过随机采取样本,随机挑选特征,形成多棵决策树,每棵决策树都有自己判断权力,随机森林收集每一棵树投票结果,以少数服从多数的原理,进行最终分类判断[6]。
3) XGBoost
XGBoost的預测模型通过设定损失函数,并根据参数进行一阶、二阶导数计算,以提高泛化能力[7]。令k 表示全部树的数量,t 表示预测轮数,fk 是第k 颗预测结果,ft (xi )为第t 轮改善参数,Y ti 表示基于xi 样本第t轮预测结果,预测公式为
4) LightGBM
LightGBM由微软研究院研究开发,基于不牺牲速度的情况下,尽可能使用更多的数据运算,具有准确率高、区分能力强的特点[8]。基于直方图(Histogram)算法、基于梯度的单边采样算法(GOSS)和互斥特征捆绑算法(EFB),这3个算法的引入下,降低了叶子生成的复杂度,从而节约了大量的运行计算时间和存储空间。
5) Voting投票算法
Voting投票算法是集成算法中的一种,该算法又分为硬投票(Hard Voting) 和软投票(Soft Voting) 两种使用方式。其中硬投票是基于少数服从多数的原则,将不同分类器的结果分别进行统计,看最终哪个投票多来确定分类结果;而软投票可以为不同分类器设置不同权重,由于每个分类器都有独立估算分类的概率,软投票法将所有概率再进行平均,最后平均概率最大的作为分类结果。
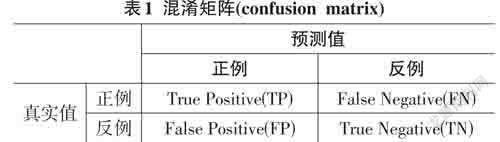
6) 淆矩阵(confusion matrix)
假如收到一些样本,倘若该样本集中只存在两种类别,即正例和反例。而当预测值为正例时,本文将其记为positive(P),而当预测值为反例的时候,本文将其记为negative(N)。此时如果预测值与真实值相同的时候,本文记为true(T),而当预测值和真实值相反不一样的时候,则记为false(F)。从而有了以下的混淆矩阵(confusion matrix),如表1所示。
7) ROC曲线
ROC曲线以假正例率(FPR)为X轴,以真正例率(TPR)为Y轴,进行图形的绘制。由于ROC曲线能够反映出分类效果,但从表现程度上还是不够直观,对此,通过AUC来直观地凸显出分类能力,即该指标实际为ROC曲线下的面积。
2.2 方案流程
本文研究的方案流程主要包括7个步骤:数据导入、数据预处理、模型训练、择优选择、集成、对比评估、总结,如图1所示。
3 数据处理及模型训练
3.1 数据描述
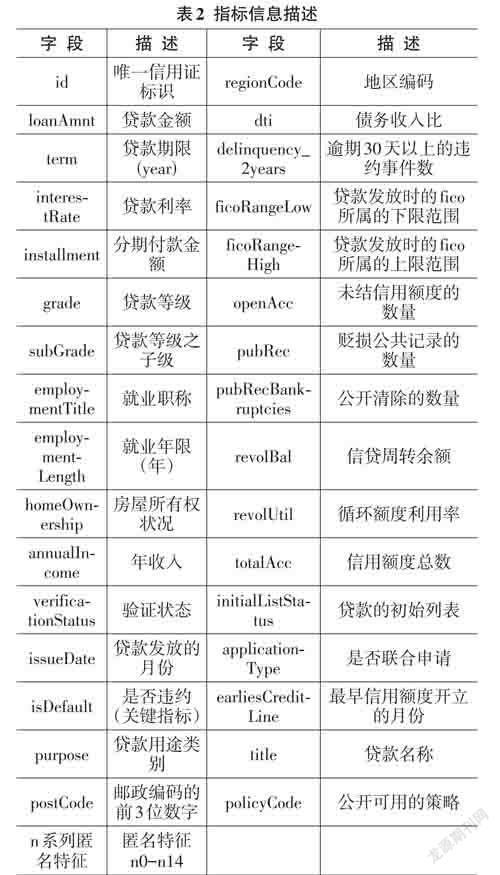
本文采用天池公开银行贷款数据集,该数据总量有47类指标信息,80万条用户数据。47类指标信息具体描述如表2所示。
3.2 数据处理
数据处理是模型训练的前提,围绕关键指标进行数据处理,通过对数据缺失值占比、数据异常值筛查进行多次降维,缺失部分采取为向上填充法的方式进行空值填充,特殊字符进行数字化处理。表3 为Grade指标数字化处理前后对比。
3.3 绘制相关性热力矩阵图
经过数据处理,最终将数据集降维至23项指标,并制作成相关性矩阵热力图,观察各个指标与关键指标之间的相关性。呈现如图2所示。
由相关性热力矩阵图可以看出,与isDefault关键性指标相关度较高的为loanAmnt、term、interestRate、installment、grade和dti,而其他指标起到相关性较小,用于提供辅助性作用。
3.4 模型训练及评分结果
数据集采取8:2的分配比例,即训练集为640000 条,测试集160000条,进行数据集的拆分,分别带入到模型中训练和测试,并记录逻辑回归、随机森林、XG?Boost、LightGBM这四种单一模型的AUC评分。单一模型评分结果如表4所示。
3.5 模型集成及对比结果
本文选择AUC评分较高的模型,即逻辑回归模型、LightGBM模型和随机森林模型,使用Voting硬投票算法进行模型融合,发现Voting模型融合后的AUC 评分有较大提升。对比数据如表5所示。
4 总结
通过对数据集的清洗筛选,选出部分相关联的特征值进行多种模型的训练,以数学原理阐述了不同模型的处理方式,本文测试中以最优的模型进行Voting 投票算法的融合,其结果表明十分优异,能够起到提升预测准确度的作用,具体得出以下结论。
1) 在进行数据集处理时,将数据字符类型进行定量数值化,能够更好地形成图像,进行指标的选择,比如在等级划分时,采用数值的形式,进行数据集优化。
2) 不同模型在处理同一数据集的处理效果差异性很大,如在XGBoost模型处理与随机森林模型在处理同一数据集时,AUC评分差距很大。
3) 作为Voting投票融合算法,将三种有效的单一模型进行融合,能够有效提升AUC评分,证明融合算法相较于单一的模型,能够发挥融合算法的强化性,提高准确度。
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
